







在继续之前,先说些别的。
有人问我最近在忙些什么,为什么会研究起NLP(自然语言处理)。这和工作有一定关系,但也不全是。
总结一下我这三年来做的事情,围绕着三个技术核心,一个是如何写好代码,一个是存储技术,一个是数据挖掘。
在写代码方面,主要是实战和理论学习相结合,在实战中不断改进,去粗存精,进一步从思想上改变认识,以期取得更深的体会。
存储方面的研究,始于今年年初,通过这一年来几次重要的存储方案设计,我总结出存储设计即索引设计的观点。一切存储关键在于索引,无论是使用数据库,还是独立的存储方案,索引问题解决了,所有问题也就差不多了。我在这一方面并不太深入,这一方面技术也相对稳定,说实话,也是最容易的,因为存储设计是相对最不抽象的事儿。但是存储开发却是我认为最重要的工作,是其他工作的基础,做到完美并不容易,我会在这块更深入下去,要能够升华思想,我也会在后面写一些存储设计和数学的那些事儿。
而数据挖掘,是工作项目把我引入了这一领域,两年前我就开始做统计相关的工作,通过这些工作对数据逐渐从感性到理想认识的升华,我现在有比较丰富的统计系统设计经验了,一条龙的统计系统开发轻易就可以完成。是ted老大启蒙了我做数据挖掘的想法,今年初ted老大让我做用户行为方面的研究,我狠狠的啃了一个星期的论文和书籍,把数据挖掘的理论知识丰富了起来。而我真正认真的去思考并开始做数据挖掘相关工作是在我来到架构组之后,我开始了一个探索性的项目,这也是让我研究NLP的原因,我参考了大量的paper和文章,系统的了解了NLP的相关理论和研究成果,并且也结合目前的项目做了一些尝试,比如我用一周时间开发了中文分词引擎,读了几十篇paper之后,我信心大增,最终实现了一个有一定工业强度的引擎,虽然这种引擎已经有人开发过,但是我还是决定自己去实现,因为我接下来的研究和尝试会比较深入的依赖于NLP,所以我需要深入细节。NLP只是一个方向,我同时还在研究自动推荐的相关技术,关联规则挖掘和协同过滤算法,这些都是数据挖掘相关的技术,我也会在后面作出成绩之后把他们都写下来。
NLP和自动推荐等数据挖掘算法的研究并非我工作的全部,之前也只是用了40%的时间在这上面,下周开始,仅仅只会再用20%时间在这方面,之前的60%和以后的80%是用在产品的开发上面,理论研究是长线投入,最大的收获可能是技术和思路的积累,工作的重点应该是开发能够满足用户需求的产品。
这些研究是一个厚积薄发的过程,借用李小龙的一句话:剪枝蔓,立主脑。先掌握尽可能多的相关技术,然后结合实际项目的需要,抽取关键技术深耕。这就是我最单纯直接的想法。
脑中的数学是抽象的,手中的数学是简单的。
上篇已经介绍了隐马尔科夫模型,我们知道HMM是一个五元组:(N,M,A,B,PI)。
N是一组状态的集合。N={1,2,3,..n}。
M是一组观察值组成的集合。M={v1,v2,..,vm}。
A是状态转移概率矩阵,描述状态转移概率分布,n行n列。
A=[aij],aij=P(qt+1 = j | qt = i),1<=i,j<=n。
B是发射概率矩阵,描述观察值的概率分布。
B={bj(k)},bj(k)表示在状态j时第k个观察值vk的概率。即bj(k)=P(vk|j),1<=k<=m,1<=j<=n。
PI是初始概率,描述初始状态概率分布,PI={PIi}。
PIi=P(q1=i)表示时刻1选择某个状态i的概率。
隐马尔科夫模型可解决三类问题。如下:
1)给定HMM=(A,B,PI),并给定观察序列O=O1O2..OT,如何计算P(O|HMM),即观察序列O的概率?
2)给定HMM=(A,B,PI),并给定观察序列O=O1O2..OT,如何选择一个状态转换序列S=q1q2..qT,使得S最可能产生观察序列O,即求P(S|O,HMM)?
3)在模型参数未知或不确定的情况下,如何根据观察序列O=O1O2..OT求得模型参数或调整模型参数,即如何确定一组模型参数,使得P(O|HMM)最大?
这三个问题都不容易解决,基本方法的计算量是计算机无法接受的,我们主要讨论前两个问题的解法,而第三个问题是关于参数的训练过程,在介绍N元模型的时候讨论。
为了方便表述,我用一个例子来贯穿说明。
考虑水藻预测天气的模型。民间的传说告诉我们水藻的状态和天气有一定的概率关系,此时,我们就有了状态集合和观察值集合,观察值集合就是水藻的状态(dry,damp,soggy),即干、潮、湿,状态集合就是天气的状况(sunny,cloudy,rainy),即晴、多云、雨。我们就可以通过HMM模型,通过观察水藻的状态变化得到天气的变化情况。
对于水藻和天气的关系,可以用穷举搜索方法得到下面的状态转移图:
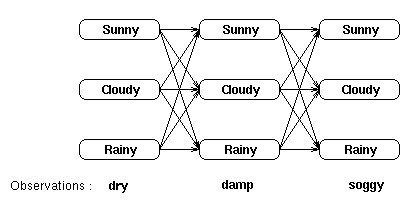
图中,每两个相邻列各状态之间的路径长度由转移概率决定,通过状态转移概率矩阵A获得,而每一列的状态和对应的观察值则由发射概率决定,通过发射概率矩阵B决定。如果用穷举法求某一观察序列的概率,就要求所有可能的状态转换序列下的概率之和,图中共有3*3=27个可能的状态转换序列,即:
P(dry,damp,soggy|HMM)=
P(dry,damp,soggy|sunny,sunny,sunny)+
P(dry,damp,soggy|sunny,sunny,cloudy)+
P(dry,damp,soggy|sunny,sunny,rainy)+..+
P(dry,damp,soggy|rainy,rainy,rainy)
计算复杂度很高,特别是当状态空间较大,观察序列较长的时候。
我们可以利用概率的时间不变性解决复杂度的问题。
我们采用动态规划的方法计算观察序列的概率,我们引入部分概率的概念,部分概率是到达某一中间状态时的概率与该状态下发射概率之积,可以认为是要求的观察序列概率的一个局部概率。
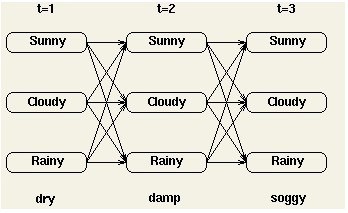
而到达某一中间状态的概率可以用所有可能到达该中间状态的路径之和表示。比如在t=2时刻,到达中间状态cloudy的概率可以用如下的三条路径之和计算:
用
@t(j)表示在时刻t,状态j的部分概率。则:
@t(j)=P(observation | state is j) * P(all paths to state j at time t)
即时刻t,状态j的发射概率bj(Ot)乘以到达中间状态j的概率。
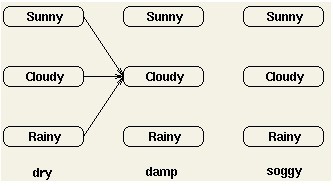
结束时刻状态的部分概率表示经过所有可能路径到达这些结束状态的概率,比如:
结束时刻状态的部分概率的和即为图中所有可能的路径的和,也就是当前HMM下观察序列的概率。
我们看看具体如何计算。
在初始状态,没有路径到达这些状态,我们令:
@1(j)=PI(j)bj(O1),这样初始时刻状态的部分概率就只与初始概率和该时刻发射概率有关。
如何计算t>1时刻的部分概率呢?我们已经知道了计算部分概率公式:
@t(j)=P(observation | state is j) * P(all paths to state j at time t)
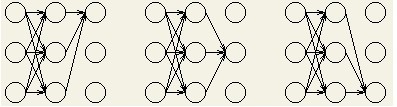
看下图的计算路径示意图:
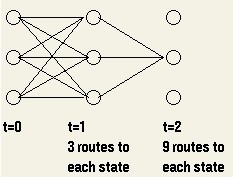
从图中可以看出,随着观察序列数的增长(时刻递增),计算的路径数呈指数增长。但是在时刻t我们已经计算出任何状态的部分概率,因此t+1时刻状态的部分概率利用时刻t的计算结果进行计算,而不用再重复计算时刻t之前的路径。
@t+1(j)=bj(Ot+1)[@t(1)a1j+@t(2)a2j+..+@t(n)anj]
对于观察序列长度T,穷举法复杂度为T的指数级,而上述方法的复杂度为T的线性。
这个算法叫做前向算法,采用动态规划的思想,把求解全局概率分解成求解局部概率来化简问题。
多数情况下,我们更希望能够根据一个给定的HMM模型,通过观察序列找到产生这个序列的最可能的状态转换序列(隐含的)。
通过穷举法,列出所有可能的状态转换序列,并计算出每种状态转换序列对应的观察序列的概率,概率最大的情况对应的就是最可能的状态转换序列。
比如水藻预测天气模型中,最有可能的状态转换序列是使得概率:
P(dry,damp,soggy|sunny,sunny,sunny),
P(dry,damp,soggy|sunny,sunny,cloudy),
P(dry,damp,soggy|sunny,sunny,rainy),..,
P(dry,damp,soggy|rainy,rainy,rainy)
得到最大值的序列。
这种穷举法的计算量很大。为了解决这个问题,我们利用和前向算法一样的原理--概率的时间不变性来减少计算量。
我们同样定义一个部分概率。这个部分概率和前向算法定义的部分概率类似,都是局部概率,但是这里的部分概率是到达某一中间状态的概率最大的路径而不是所有路径之和。
对于每个中间状态和结束状态,都存在一条到达它的最优路径,它可能是如下图这样:
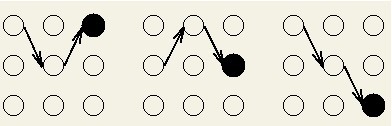
这些路径为部分最优路径,每一条部分最优路径都对应一个关联概率--部分概率$。与前向算法不同,$是最有可能到达该状态的一条路径的概率。
$t(i)是时刻t,状态i的部分概率,它对应的那条路径就是部分最优路径。$t(i)在任何时刻都存在,这样就可以在时刻T(结束时刻)找到全局的最优路径。
我们看看具体如何计算。
由于在t=1不存在任何部分最优路径,可以计算:$1(i)=PI(i)bi(O1)。与前向算法相同。
那么如何计算t>1时刻的部分概率呢?
同样我们只用时刻t-1的结果来得到时刻t的部分概率。
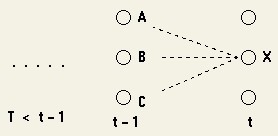
图中可以看出到达X的最优路径是下面其中一条:
(sequence of states),..,A,X
(sequence of states),..,B,X
(sequence of states),..,C,X
我们希望找到一条概率最大的。回想马尔科夫模型的假设,一个状态只和它前一时刻的状态有关。
$t(i)=max{$t-1(1)*a1i*bi(Ot),$t-1(2)*a2i*bi(Ot),..,$t-1(n)*ani*bi(Ot)}
其中第一部分是时刻t-1的部分概率,第二部分是状态转移概率,第三部分是发射概率。
现在我们已经得到到达每一个中间或者结束状态的概率最大的路径,但是我们需要采取一些方法来记录这条路径,这就需要在每个状态记录最优路径的前一个状态。
&t(i)=argmax{$t-1(1)*a1i,..,$t-1(n)*ani}
argmax操作符会选择使得括号中式子最大的索引j(1<=j<=n)。这里没有乘以发射概率是因为我们关心的是在到达当前状态的最优路径中前一状态的信息,而与它对应的观察值无关。
这个算法叫做viterbi算法,很著名的一个解码算法,也是信息论中的一个重要算法。它的思路就是动态规划,把寻找全局最优解分解成寻找局部最优解来化简问题。
待续...

















 1721
1721

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









