







.collect
简写
sc.textFile(“file:///home/hadoop/data/hello.txt”)
.flatMap(.split(" "))
.map((, 1))
.reduceByKey(_ + _)
.collect
#### RDD、DAG、 Stage、 Task 、 Job
RDD(Resilient Distributed Datasets),弹性分布式数据集
DAG(Directed Acyclic Graph),有向无环图
**RDD** RDD 是 Spark 的灵魂,也称为**弹性分布式数据集**。一个 RDD 代表一个可以被分区的只读数据集。RDD 内部可以有许多分区(partitions),每个分区又拥有大量的记录(records)。
**DAG** Spark 中**使用 DAG 对 RDD 的关系进行建模**,描述了 RDD 的依赖关系,这种关系也被称之为 lineage(血缘),RDD 的依赖关系使用 Dependency 维护。
**Stage** 在 DAG 中又进行 Stage 的划分,划分的依据是依赖是否是 shuffle 的,每个 Stage 又可以划分成若干 Task。接下来的事情就是 Driver 发送 Task 到 Executor,Executor 线程池去执行这些 task,完成之后将结果返回给 Driver。
**Job** Spark 的 Job 来源于用户执行 action 操作(这是 Spark 中实际意义的 Job),就是从 RDD 中获取结果的操作,而不是将一个 RDD 转换成另一个 RDD 的 transformation 操作。
**Task** 一个 Stage 内,最终的 RDD 有多少个 partition,就会产生多少个 task。
#### Spark 作业提交流程
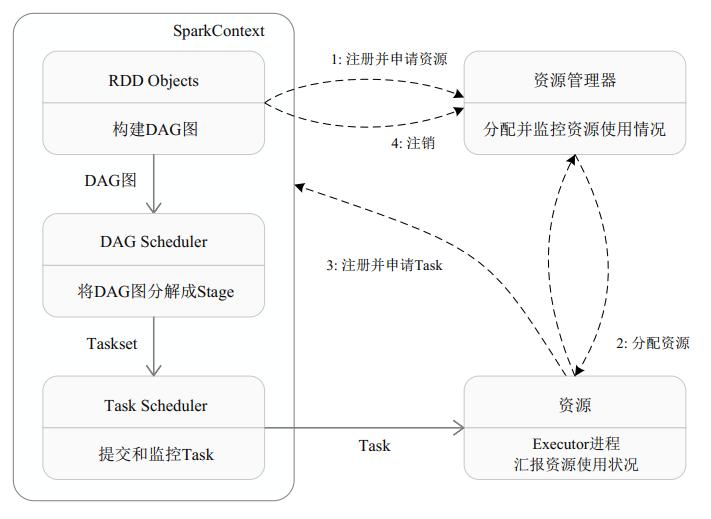
1. spark-submit 提交代码,执行 `new SparkContext()`,在 SparkContext 里构造 DAGScheduler 和 TaskScheduler。
2. TaskScheduler 会通过后台的一个进程,连接 Master,向 Master 注册 Application。
3. Master 接收到 Application 请求后,会使用相应的**资源调度算法**,在 Worker 上为这个 Application 启动多个 Executor
4. Executor 启动后,会自己反向注册到 TaskScheduler 中。所有 Executor 都注册到 Driver 上之后,SparkContext **结束初始化**,接下来往下执行我们自己的代码。
5. 每执行到一个 Action,就会创建一个 Job。Job 会提交给 DAGScheduler。
6. DAGScheduler 会将 Job 划分为多个 Stage,然后每个 Stage 创建一个 TaskSet。
7. TaskScheduler 会把每一个 TaskSet 里的 Task,提交到 Executor 上执行。
8. Executor 上有线程池,每接收到一个 Task,就用 TaskRunner 封装,然后从线程池里取出一个线程执行这个 task。(TaskRunner 将我们编写的代码,拷贝,反序列化,执行 Task,每个 Task 执行 RDD 里的一个 partition)
#### Spark 的 Local 和 Standalone
Spark一共有6种运行模式:Local,Standalone,Yarn-Cluster,Yarn-Client, Mesos, Kubernetes
1. Local: Local 模式即单机模式,如果在命令语句中不加任何配置,则默认是 Local 模式,在本地运行。这也是部署、设置最简单的一种模式,所有的 Spark 进程都运行在一台机器或一个虚拟机上面。
2. Standalone: Standalone 是 Spark 自身实现的资源调度框架。如果我们只使用 Spark 进行大数据计算,不使用其他的计算框架时,就采用 Standalone 模式就够了,尤其是单用户的情况下。Standalone 模式是 Spark 实现的资源调度框架,其主要的节点有 Client 节点、Master 节点和 Worker 节点。其中 Driver 既可以运行在 Master 节点上中,也可以运行在本地 Client 端。当用 spark-shell 交互式工具提交 Spark 的 Job 时,Driver 在 Master 节点上运行;当使用 spark-submit 工具提交 Job 或者在 Eclipse、IDEA 等开发平台上使用 `new SparkConf.setManager(“spark://master:7077”)` 方式运行 Spark 任务时,Driver 是运行在本地 Client 端上的。
Standalone 模式的部署比较繁琐,不过官方有提供部署脚本,需要把 Spark 的部署包安装到每一台节点机器上,并且部署的目录也必须相同,而且需要 Master 节点和其他节点实现 SSH 无密码登录。启动时,需要先启动 Spark 的 Master 和 Slave 节点。提交命令类似于:
./bin/spark-submit
–class org.apache.spark.examples.SparkPi
–master spark://Oscar-2.local:7077
/tmp/spark-2.2.0-bin-hadoop2.7/examples/jars/spark-examples_2.11-2.2.0.jar
100
其中 master:7077是 Spark 的 Master 节点的主机名和端口号,当然集群是需要提前启动。
不管使用什么模式,Spark应用程序的代码是一模一样的,只需要在提交的时候通过–master参数来指定我们的运行模式即可
* Client
Driver运行在Client端(提交Spark作业的机器)
Client会和请求到的Container进行通信来完成作业的调度和执行,Client是不能退出的
日志信息会在控制台输出:便于我们测试
* Cluster
Driver运行在ApplicationMaster中
Client只要提交完作业之后就可以关掉,因为作业已经在YARN上运行了
日志是在终端看不到的,因为日志是在Driver上,只能通过yarn logs -applicationIdapplication\_id
./bin/spark-submit
–class org.apache.spark.examples.SparkPi
–master yarn
–executor-memory 1G
–num-executors 1
/home/hadoop/app/spark-2.1.0-bin-2.6.0-cdh5.7.0/examples/jars/spark-examples_2.11-2.1.0.jar \
此处的yarn就是我们的yarn client模式
如果是yarn cluster模式的话,yarn-cluster
`Exception in thread "main" java.lang.Exception: When running with master 'yarn' either HADOOP_CONF_DIR or YARN_CONF_DIR must be set in the environment.`
如果想运行在YARN之上,那么就必须要设置HADOOP\_CONF\_DIR或者是YARN\_CONF\_DIR
1) `export HADOOP_CONF_DIR=/home/hadoop/app/hadoop-2.6.0-cdh5.7.0/etc/hadoop`
2) `$SPARK_HOME/conf/spark-env.sh`
./bin/spark-submit
–class org.apache.spark.examples.SparkPi
–master yarn-cluster
–executor-memory 1G
–num-executors 1
/home/hadoop/app/spark-2.1.0-bin-2.6.0-cdh5.7.0/examples/jars/spark-examples_2.11-2.1.0.jar
4
`yarn logs -applicationId application_1495632775836_0002`
#### 宽依赖、窄依赖
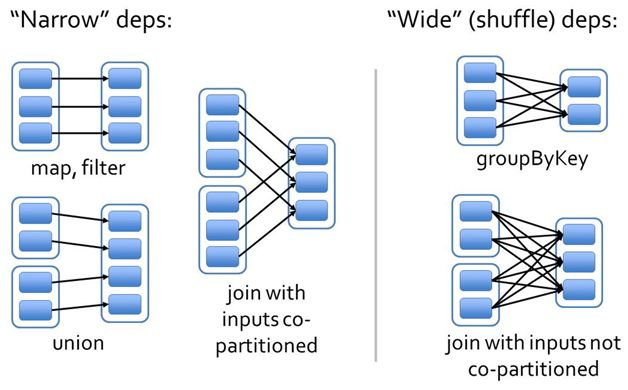
1. 窄依赖指的是每一个 Parent RDD 的 Partition 最多被子 RDD 的一个 Partition 使用(一子一亲)
2. 宽依赖指的是多个子 RDD 的 Partition 会依赖同一个 parent RDD的 partition(多子一亲)
RDD 作为数据结构,本质上是一个**只读的分区记录集合**。一个 RDD 可以包含多个分区,每个分区就是一个数据集片段。
首先,窄依赖可以支持在**同一个节点**上,以 pipeline 形式执行多条命令(也叫同一个 Stage 的操作),例如在执行了 map 后,紧接着执行 filter。相反,宽依赖需要所有的父分区都是可用的,可能还需要调用类似 MapReduce 之类的操作进行**跨节点传递**。
其次,则是从失败恢复的角度考虑。窄依赖的失败恢复更有效,因为它只需要重新计算丢失的 parent partition 即可,而且可以并行地在不同节点进行重计算(一台机器太慢就会重新调度到多个节点进行)。
#### Spark SQL比 Hive 快在哪
>
> 当Map的输出结果要被Reduce使用时,输出结果需要按key哈希,并且分发到每一个Reducer上去,这个过程就是shuffle。
> 由于shuffle涉及到了磁盘的读写和网络的传输,因此shuffle性能的高低直接影响到了整个程序的运行效率。
>
>
>
Spark SQL 比 Hadoop Hive 快,是有一定条件的,而且不是 Spark SQL 的引擎比 Hive 的引擎快,相反,Hive 的 HQL 引擎还比 Spark SQL 的引擎更快。其实,关键还是在于 Spark 本身快。
1. 消除了冗余的 HDFS 读写: Hadoop 每次 shuffle 操作后,必须写到磁盘,而 **Spark 在 shuffle 后不一定落盘**,可以 persist 到内存中,以便迭代时使用。如果操作复杂,很多的 shufle 操作,那么 Hadoop 的读写 IO 时间会大大增加,也是 Hive 更慢的主要原因了。
2. 消除了冗余的 MapReduce 阶段: Hadoop 的 shuffle 操作一定连着完整的 MapReduce 操作,冗余繁琐。而 Spark 基于 RDD 提供了丰富的算子操作,且 **reduce 操作产生 shuffle 数据,可以缓存在内存中** 。
3. JVM 的优化: Hadoop 每次 MapReduce 操作,启动一个 Task 便会启动一次 JVM,基于进程的操作。而 Spark 每次 MapReduce 操作是基于线程的,只在启动 Executor 是启动一次 JVM,内存的 Task 操作是在**线程复用**的。每次启动 JVM 的时间可能就需要几秒甚至十几秒,那么当 Task 多了,这个时间 Hadoop 不知道比 Spark 慢了多少。
#### 打包的注意事项
打包时要注意,pom.xml中需要添加如下plugin
`mvn assembly:assembly`
./bin/spark-submit
–class com.hiszm.log.SparkStatCleanJobYARN
–name SparkStatCleanJobYARN
–master yarn \
自我介绍一下,小编13年上海交大毕业,曾经在小公司待过,也去过华为、OPPO等大厂,18年进入阿里一直到现在。
深知大多数大数据工程师,想要提升技能,往往是自己摸索成长或者是报班学习,但对于培训机构动则几千的学费,着实压力不小。自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年大数据全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友。





既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,基本涵盖了95%以上大数据开发知识点,真正体系化!
由于文件比较大,这里只是将部分目录大纲截图出来,每个节点里面都包含大厂面经、学习笔记、源码讲义、实战项目、讲解视频,并且后续会持续更新
如果你觉得这些内容对你有帮助,可以添加VX:vip204888 (备注大数据获取)

学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,基本涵盖了95%以上大数据开发知识点,真正体系化!**
由于文件比较大,这里只是将部分目录大纲截图出来,每个节点里面都包含大厂面经、学习笔记、源码讲义、实战项目、讲解视频,并且后续会持续更新
如果你觉得这些内容对你有帮助,可以添加VX:vip204888 (备注大数据获取)
[外链图片转存中…(img-Y1Ju6i7i-1712891939736)]















 3817
3817

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









