







首先,我们要理解KKT条件是用来干嘛的?
KKT条件用来判断一个解是否属于一个非线性优化问题。
求最优解:
约束条件分为
1、等式约束
2、不等式约束
对于等式约束的优化问题,可以直接应用拉格朗日乘子法去求取最优值;
对于含有不等式约束的优化问题,可以转化为在满足 KKT 约束条件下应用拉格朗日乘子法求解。
拉格朗日求得的并不一定是最优解,只有在凸优化的情况下,才能保证得到的是最优解,所以我们说拉格朗日乘子法得到的为可行解,其实就是局部极小值。
下面分成一个方面来讨论求最优解:
1)无约束条件
如果没有任何条件,那么变量 的函数
的函数 的极值问题就是
的极值问题就是
直接求导 即可。
即可。
2)等式约束的优化
如在 的条件下使得最小
的条件下使得最小
约束条件就会将解的范围限定在一个可行域,此时要找的点只需要在限定的可行域中找到的最小值就好了。
方法:
拉格朗日乘子法
首先,
引入拉格朗日乘子
然后,构建拉格朗日函数
求解拉格朗日函数:
对 和
和 求导
求导
令导数为0,这时候得到相应的和的值,把的值代入到中即得到约束条件 下的可行解。
下的可行解。
举个例子:
在二维条件下,对目标函数 画出等高线,如下图所示,
画出等高线,如下图所示, 为约束条件,如下图绿线。
为约束条件,如下图绿线。

那么目标函数的值,也就是等高线跟约束条件有三种情况:相交,相切和没有交集。那么相交和相切的情况是相应的我们要求的解。并且相切是最优解或者局部最优解。
结论:
拉格朗日乘子法取得极值的必要条件是目标函数和约束函数相切,两者法向量平行。
所以只要满足上述等式,且满足之前的约束 ,即可得到解,联立起来,正好得到就是拉格朗日乘子法。
,即可得到解,联立起来,正好得到就是拉格朗日乘子法。
3)不等式约束条件
如下式:
同样做拉格朗日变换和画图:
给出等高线和约束条件之后,可行解也要落在 区域内。
区域内。
上图有,可行解只能落在 或者
或者 的区域里获得。
的区域里获得。
- 当可行解 落在 的区域内,此时直接极小化 即可;
- 当可行解 落在 即边界上,此时等价于等式约束优化问题.
当约束区域包含目标函数原有的的可行解时,此时加上约束可行解扔落在约束区域内部,对应 的情况,这时约束条件不起作用;当约束区域不包含目标函数原有的可行解时,此时加上约束后可行解落在边界 上。下图分别描述了两种情况,右图表示加上约束可行解会落在约束区域的边界上。
以上两种情况就是说,要么可行解落在约束边界上即得 ,要么可行解落在约束区域内部,此时约束不起作用,另  消去约束即可,所以无论哪种情况都会得到:
消去约束即可,所以无论哪种情况都会得到:
还有一个问题是  的取值,在等式约束优化中,约束函数与目标函数的梯度只要满足平行即可,而在不等式约束中则不然,若
的取值,在等式约束优化中,约束函数与目标函数的梯度只要满足平行即可,而在不等式约束中则不然,若  ,这便说明 可行解 是落在约束区域的边界上的,这时可行解应尽量靠近无约束时的解,所以在约束边界上,目标函数的负梯度方向应该远离约束区域朝向无约束时的解,此时正好可得约束函数的梯度方向与目标函数的负梯度方向应相同:
,这便说明 可行解 是落在约束区域的边界上的,这时可行解应尽量靠近无约束时的解,所以在约束边界上,目标函数的负梯度方向应该远离约束区域朝向无约束时的解,此时正好可得约束函数的梯度方向与目标函数的负梯度方向应相同:
上式需要满足的要求是拉格朗日乘子  ,这个问题可以举一个形象的例子,假设你去爬山,目标是山顶,但有一个障碍挡住了通向山顶的路,所以只能沿着障碍爬到尽可能靠近山顶的位置,然后望着山顶叹叹气,这里山顶便是目标函数的可行解,障碍便是约束函数的边界,此时的梯度方向一定是指向山顶的,与障碍的梯度同向,下图描述了这种情况 :
,这个问题可以举一个形象的例子,假设你去爬山,目标是山顶,但有一个障碍挡住了通向山顶的路,所以只能沿着障碍爬到尽可能靠近山顶的位置,然后望着山顶叹叹气,这里山顶便是目标函数的可行解,障碍便是约束函数的边界,此时的梯度方向一定是指向山顶的,与障碍的梯度同向,下图描述了这种情况 :

可见对于不等式约束,只要满足一定的条件,依然可以使用拉格朗日乘子法解决,这里的条件便是 KKT 条件。接下来给出形式化的 KKT 条件 首先给出形式化的不等式约束优化问题:
列出 Lagrangian 得到无约束优化问题:
经过之前的分析,便得知加上不等式约束后可行解 需要满足的就是以下的 KKT 条件:
满足 KKT 条件后极小化 Lagrangian 即可得到在不等式约束条件下的可行解。 KKT 条件看起来很多,其实很好理解:
(1) 拉格朗日取得可行解的必要条件;
(2) 这就是以上分析的一个比较有意思的约束,称作松弛互补条件;
(3) ∼∼ (4) 初始的约束条件;
(5) 不等式约束的 Lagrange Multiplier 需满足的条件。
主要的KKT条件便是 (3) 和 (5) ,只要满足这俩个条件便可直接用拉格朗日乘子法, SVM 中的支持向量便是来自于此,需要注意的是 KKT 条件与对偶问题也有很大的联系。
拉格朗日对偶
在优化理论中,目标函数 会有多种形式:如果目标函数和约束条件都为变量 的线性函数, 称该问题为线性规划;
如果目标函数为二次函数, 约束条件为线性函数, 称该最优化问题为二次规划; 如果目标函数或者约束条件均为非线性函数, 称该最优化问题为非线性规划。每个线性规划问题都有一个与之对应的对偶问题,对偶问题有非常良好的性质,以下列举几个:
- 对偶问题的对偶是原问题;
- 无论原始问题是否是凸的,对偶问题都是凸优化问题;
- 对偶问题可以给出原始问题一个下界;
- 当满足一定条件时,原始问题与对偶问题的解是完全等价的;
比如下边这个例子,虽然原始问题非凸,但是对偶问题是凸的:

原始问题
首先给出不等式约束优化问题:
定义 Lagrangian 如下:
根据以上 Lagrangian 便可以得到一个重要结论:
上式很容易验证,因为满足约束条件的 会使得  ,因此第二项消掉了;而
,因此第二项消掉了;而  ,并且使得
,并且使得  ,因此会有
,因此会有  ,所以最大值只能在它们都取零的时候得到,这个时候就只剩下 了。反之如果有任意一个约束条件不满足,则只需令其相应的乘子
,所以最大值只能在它们都取零的时候得到,这个时候就只剩下 了。反之如果有任意一个约束条件不满足,则只需令其相应的乘子  ,则会得到
,则会得到  ,这样将导致问题无解,因此必须满足约束条件。经过这样一转变,约束都融合到了一起而得到如下的无约束的优化目标:
,这样将导致问题无解,因此必须满足约束条件。经过这样一转变,约束都融合到了一起而得到如下的无约束的优化目标:
对偶问题
上式与原优化目标等价,将之称作原始问题 , 将原始问题的解记做 ,如此便把带约束问题转化为了无约束的原始问题,其实只是一个形式上的重写,方便找到其对应的对偶问题,首先为对偶问题定义一个对偶函数(dual function) :
,如此便把带约束问题转化为了无约束的原始问题,其实只是一个形式上的重写,方便找到其对应的对偶问题,首先为对偶问题定义一个对偶函数(dual function) :
有了对偶函数就可给出对偶问题了,与原始问题的形式非常类似,只是把 min 和 max 交换了一下:
然后定义对偶问题的最优解即关于 α β 的函数:
对偶问题和原始问题的最优解并不相等,而是满足的如下关系:
直观地,可以理解为最小的里最大的那个要比最大的中最小的那个要大。具体的证明过程如下:
证明,首先这里的约束要全部满足,对偶问题与原始问题的关系如下:
即
,所以自然而然可得:
即现在通过对偶性,为原始问题引入一个下界,


这个性质便叫做弱对偶性(weak duality),对于所有优化问题都成立,即使原始问题非凸。这里还有两个概念: 叫做对偶间隔(duality gap),
叫做对偶间隔(duality gap),  叫做最优对偶间隔(optimal duality gap)。
叫做最优对偶间隔(optimal duality gap)。
之前提过无论原始问题是什么形式,对偶问题总是一个凸优化的问题,这样对于那些难以求解的原始问题 (甚至是 NP 问题),均可以通过转化为偶问题,通过优化这个对偶问题来得到原始问题的一个下界, 与弱对偶性相对应的有一个强对偶性(strong duality) ,强对偶即满足: 。
。
强对偶是一个非常好的性质,因为在强对偶成立的情况下,可以通过求解对偶问题来得到原始问题的解,在 SVM 中就是这样做的。当然并不是所有的对偶问题都满足强对偶性 ,在 SVM 中是直接假定了强对偶性的成立,其实只要满足一些条件,强对偶性是成立的,比如说 Slater 条件与KKT条件。
Slater 条件
若原始问题为凸优化问题,且存在严格满足约束条件的点
中的“ ≤ ”严格取到“ < ”,即存在
,
,则存在
使得
是原始问题的解,
是对偶问题的解,且满足:

也就是说如果原始问题是凸优化问题并且满足 Slater 条件的话,那么强对偶性成立。需要注意的是,这里只是指出了强对偶成立的一种情况,并不是唯一的情况。例如,对于某些非凸优化的问题,强对偶也成立。SVM 中的原始问题 是一个凸优化问题(二次规划也属于凸优化问题),Slater 条件在 SVM 中指的是存在一个超平面可将数据分隔开,即数据是线性可分的。当数据不可分时,强对偶是不成立的,这个时候寻找分隔平面这个问题本身也就是没有意义了,所以对于不可分的情况预先加个 kernel 就可以了。
KKT条件
假设 与 分别是原始问题(并不一定是凸的)和对偶问题的最优解,且满足强对偶性,则相应的极值的关系满足:
这里第一个不等式成立是因为 为  的一个极大值点,最后一个不等式成立是因为
的一个极大值点,最后一个不等式成立是因为  ,且
,且 ,( 是之前 (*) 式的约束条件)因此这一系列的式子里的不等号全部都可以换成等号。根据公式还可以得到两个结论:
,( 是之前 (*) 式的约束条件)因此这一系列的式子里的不等号全部都可以换成等号。根据公式还可以得到两个结论:
1)第一个不等式成立是因为 为 的一个极大值点,由此可得:
2)第二个不等式其实就是之前的 (*) 式, 都是非正的,所以这里有:
都是非正的,所以这里有:
也就是说如果 ,那么必定有
,那么必定有  ;反过来,如果
;反过来,如果  那么可以得到
那么可以得到  ,即:
,即:
这些条件都似曾相识,把它们写到一起,就是传说中的 KKT (Karush-Kuhn-Tucker) 条件:
总结来说就是说任何满足强对偶性的优化问题,只要其目标函数与约束函数可微,任一对原始问题与对偶问题的解都是满足 KKT 条件的。即满足强对偶性的优化问题中,若 为原始问题的最优解, 为对偶问题的最优解,则可得  满足 KKT 条件。不知道够不够清楚,书中原话(P243)是这样的:
满足 KKT 条件。不知道够不够清楚,书中原话(P243)是这样的:

上面只是说明了必要性,当满足原始问题为凸优化问题时,必要性也是满足的,也就是说当原始问题是凸优化问题,且存在满足 KKT 条件,那么它们分别是原始问题和对偶问题的极值点并且强对偶性成立,证明如下:
首先原始问题是凸优化问题,固定之后对偶问题  也是一个凸优化问题, 是 的极值点:
也是一个凸优化问题, 是 的极值点:
最后一个式子是根据 KKT 条件中的  与
与  得到的。这样一来,就证明了对偶间隔为零,也就是说,强对偶成立。 所以当原始问题为凸优化问题时,书中的原话(P244)如下:
得到的。这样一来,就证明了对偶间隔为零,也就是说,强对偶成立。 所以当原始问题为凸优化问题时,书中的原话(P244)如下:
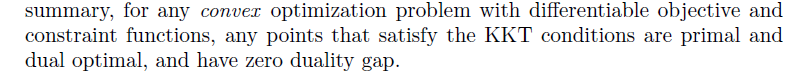















 1772
1772

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









