 Apache JMeter入门:性能测试全攻略
Apache JMeter入门:性能测试全攻略







1. 什么是JMeter?
JMeter是由Apache软件基金会开发的一款开源性能测试工具,主要使用Java语言编写。它最初设计用于测试Web应用程序,但随着时间的发展,现在可以用来测试几乎所有类型的服务器、网络协议和服务。JMeter支持多种协议,包括HTTP、HTTPS、FTP、SMTP、POP3等,并且能够模拟大量用户对系统进行并发访问,以评估系统的性能和稳定性。
官网:Apache JMeter - Apache JMeter™
说明:
jmeter添加位置不同,影响范围不同,后续将不再赘述。以下是详细的说明:
1. 线程组(Thread Group):
- 作用:测试计划是 JMeter 测试的根节点,包含了整个测试的所有配置和元素。
- 添加位置:测试计划的根节点。
- 影响:全局范围,影响所有请求。
2. 线程组(Thread Group):
- 作用:线程组定义了一组虚拟用户(线程)的行为,包括启动和停止时间、循环次数等。
- 添加位置:线程组内部。
- 影响:线程组范围,影响线程组内的所有请求。
3. HTTP 请求(HTTP Request Sampler):
- 作用:HTTP 请求用于向服务器发送 HTTP 请求。
- 添加位置:HTTP 请求内部。
- 影响:请求范围,仅影响该请求。
2. 安装与配置
注意:
- JMeter 是一个 100% Java 应用程序,运行前需要安装Java运行环境
- JMeter 与 Java 8 或更高版本兼容。出于安全和性能原因,强烈建议你安装主要版本的最新次要版本。
- 虽然可以使用 JRE,但最好安装 JDK 来记录 HTTPS,JMeter 需要 JDK 的 keytool 实用程序。
1. 下载JMeter:下载地址:Index of /jmeter/binaries
2. 启动JMeter:在解压后的JMeter的bin目录中,通过双击jmeter.bat(Windows)或./jmeter.sh(Linux/Mac)来启动JMeter。
bin目录下部分脚本说明:
脚本文件
说明
jmeter.bat
运行 JMeter(默认在 GUI 模式下)
jmeterw.cmd
在没有 Windows shell 控制台的情况下运行 JMeter(默认在 GUI 模式下)
jmeter-n.cmd
在此放置一个 JMX 文件以运行 CLI 模式测试
jmeter-nr.cmd
在此放置一个 JMX 文件以远程运行 CLI 模式测试
jmeter-t.cmd
在此放置一个 JMX 文件以在 GUI 模式下加载它
jmeter-server.bat
以服务器模式启动 JMeter
mirror-server.cmd
在 CLI 模式下运行 JMeter 镜像服务器
shutdown.cmd
运行 Shutdown 客户端以优雅地停止 CLI 模式实例
stoptest.cmd
运行 Shutdown 客户端突然停止 CLI 模式实例
jmeter.sh
运行 JMeter(默认在 GUI 模式下)
mirror-server.sh
在 CLI 模式下运行 JMeter 镜像服务器
shutdown.sh
运行 Shutdown 客户端以优雅地停止 CLI 模式实例
stoptest.sh
运行 Shutdown 客户端突然停止 CLI 模式实例
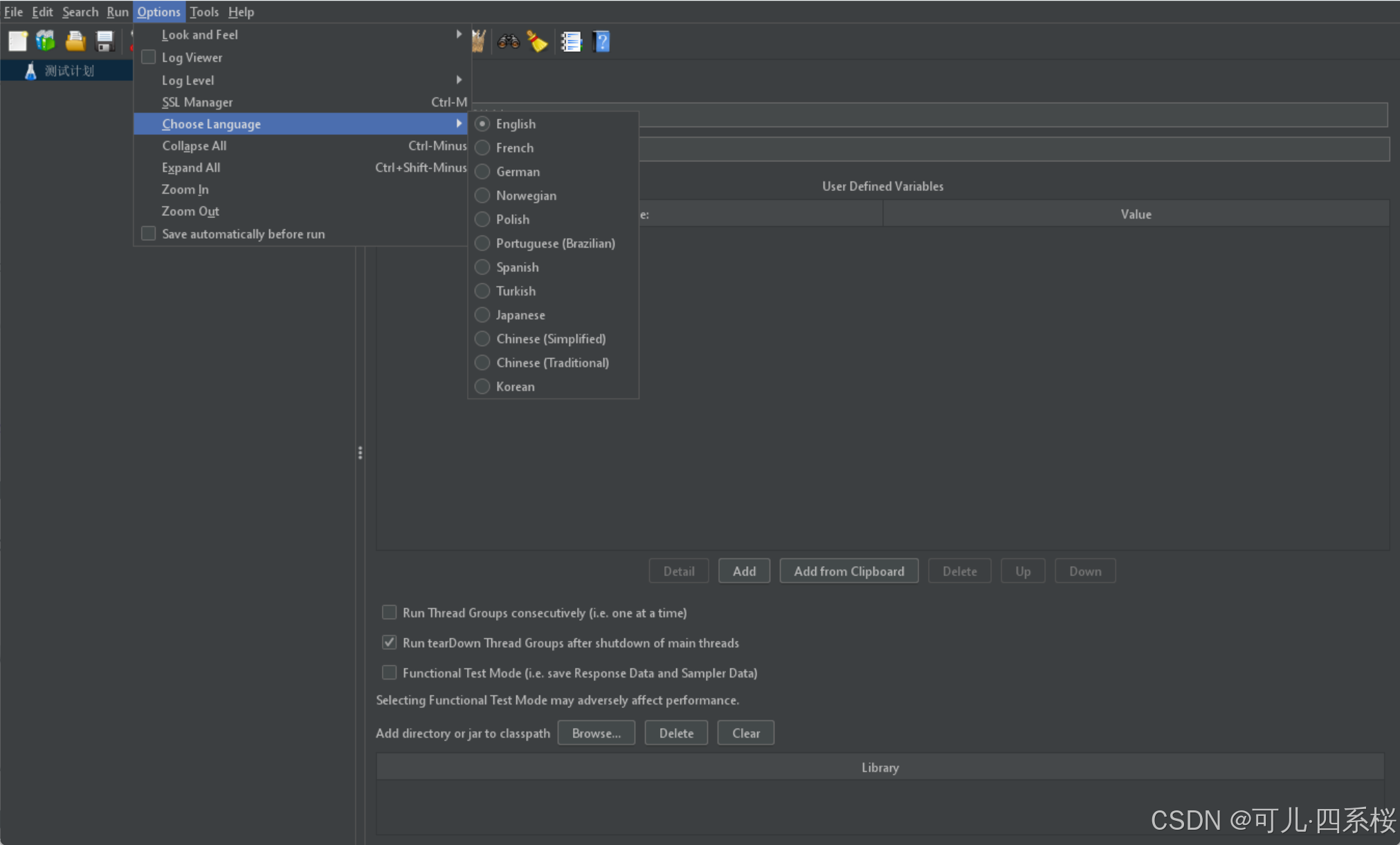
3. 设置中文:
- 方案一(临时修改):图形化界面修改:Options -> Choose Language -> Chinese (Simplified)
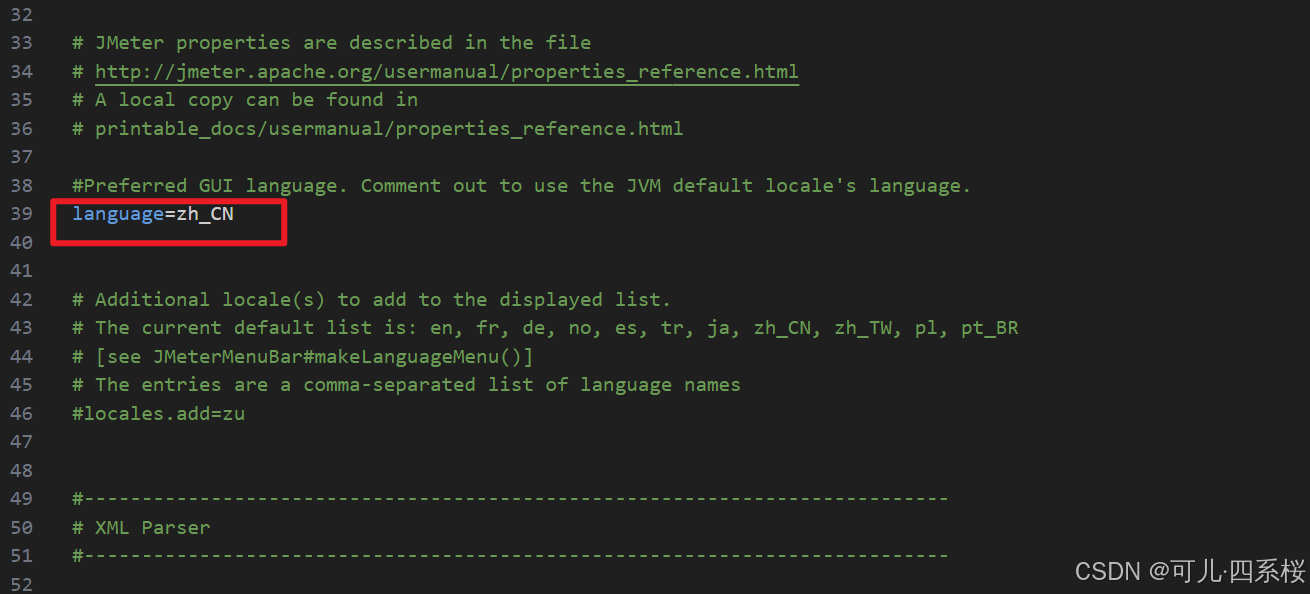
- 方案二(永久修改):配置文件修改:在bin/jmeter.properties文件里添加属性 language=zh_CN。
汉化后的界面:
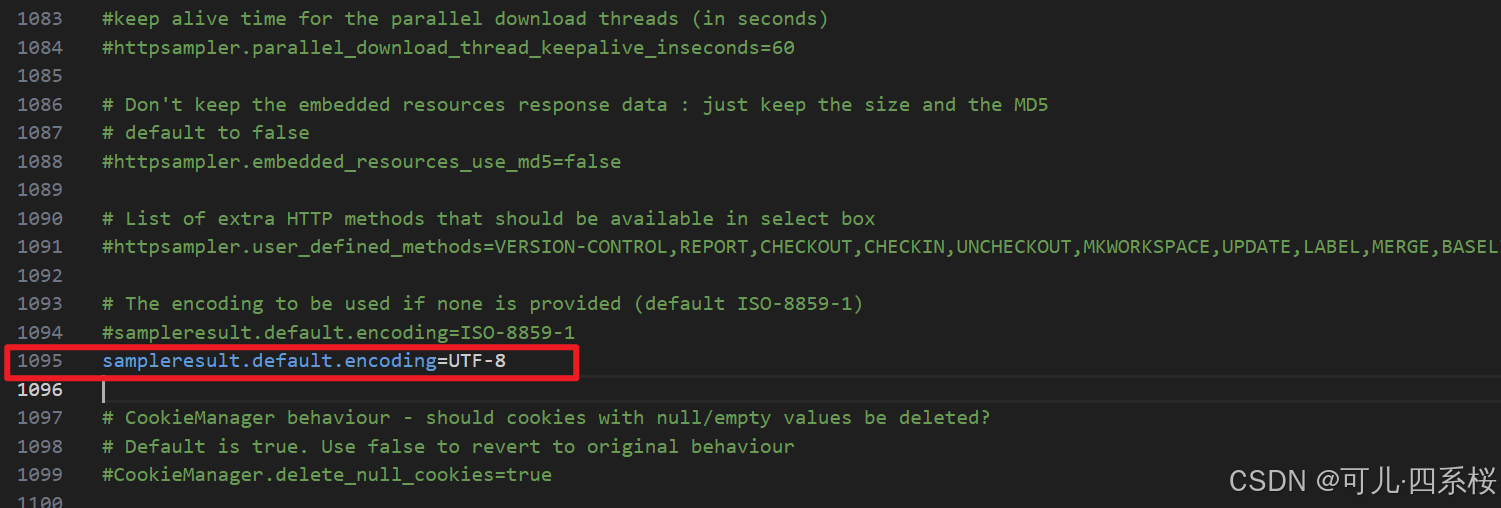
4. 返回内容中文乱码问题:
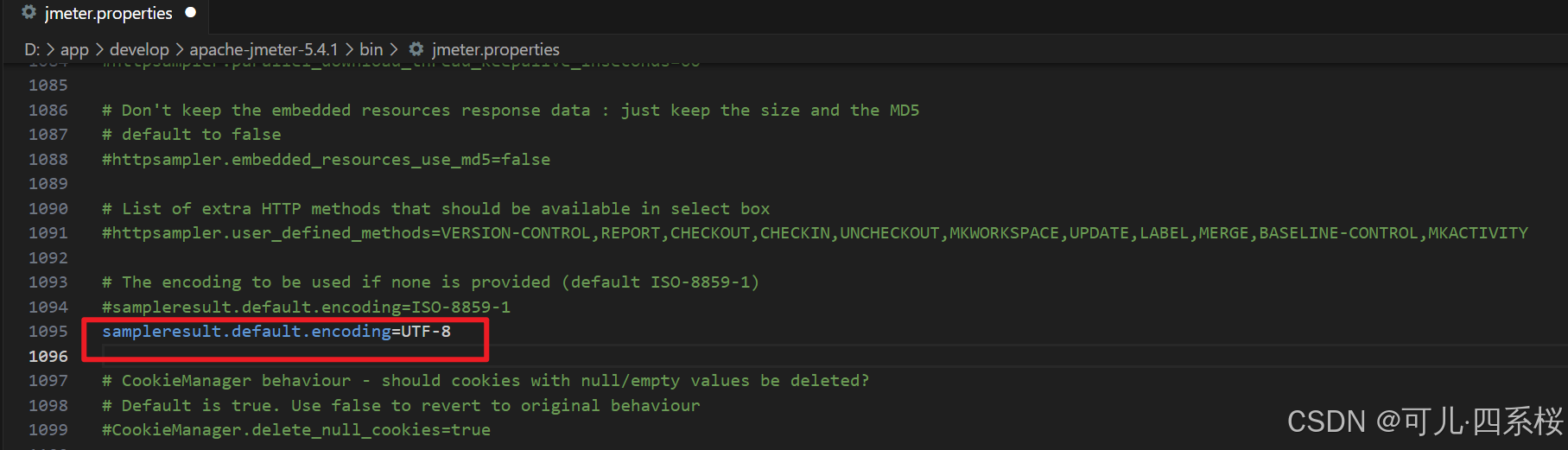
JMeter 的默认编码是 ISO-8859-1,可以通过修改 bin/jmeter.properties 文件添加属性sampleresult.default.encoding=UTF-8 。
3. 接口测试
3.1 编辑测试计划名称(可跳过)
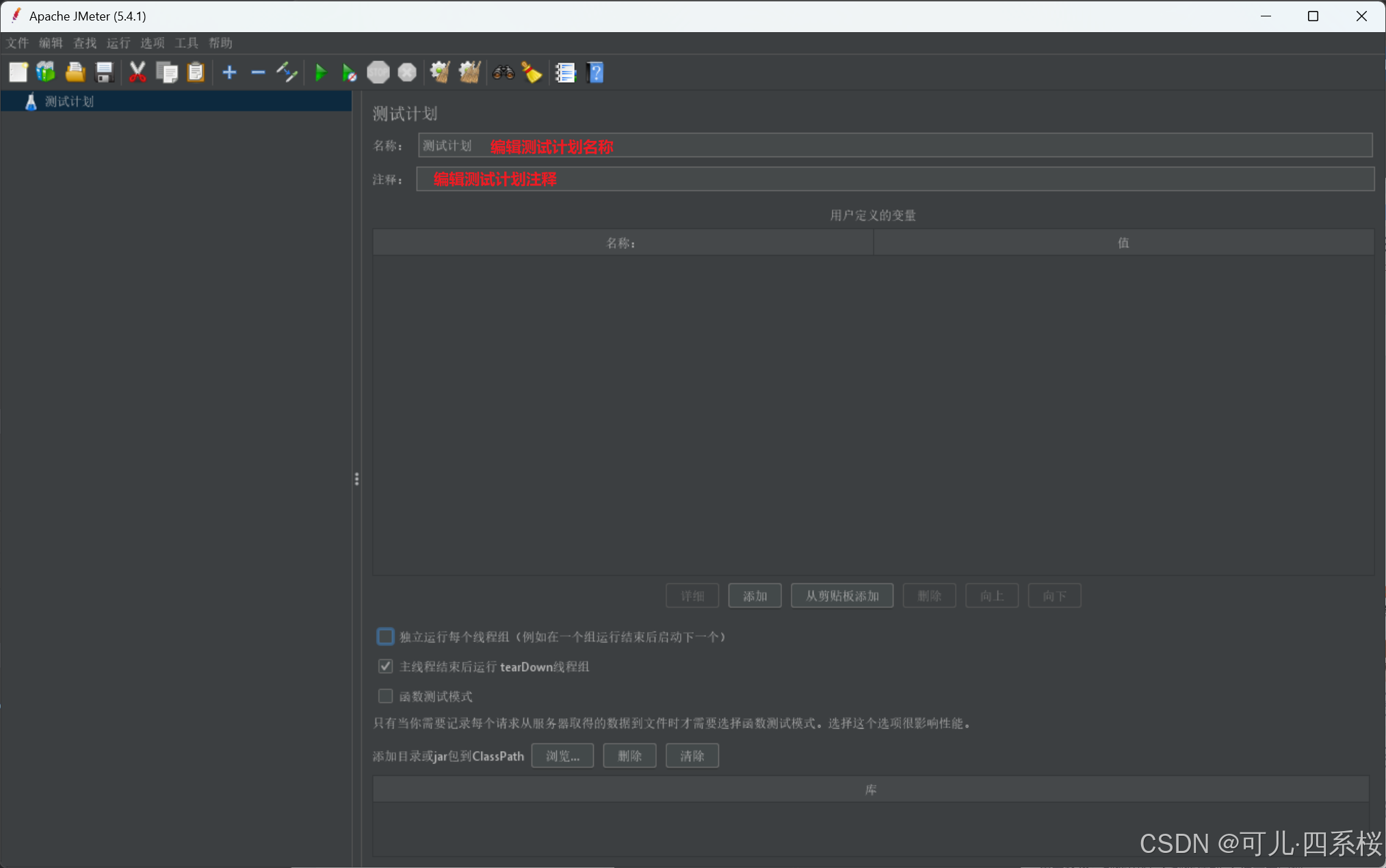
3.2 添加测试组
1. 中文版:右击测试计划 -> 添加 -> 线程(用户) -> 线程组
英文版:Test Plan -> Add -> Threads(Users) -> Thread Group
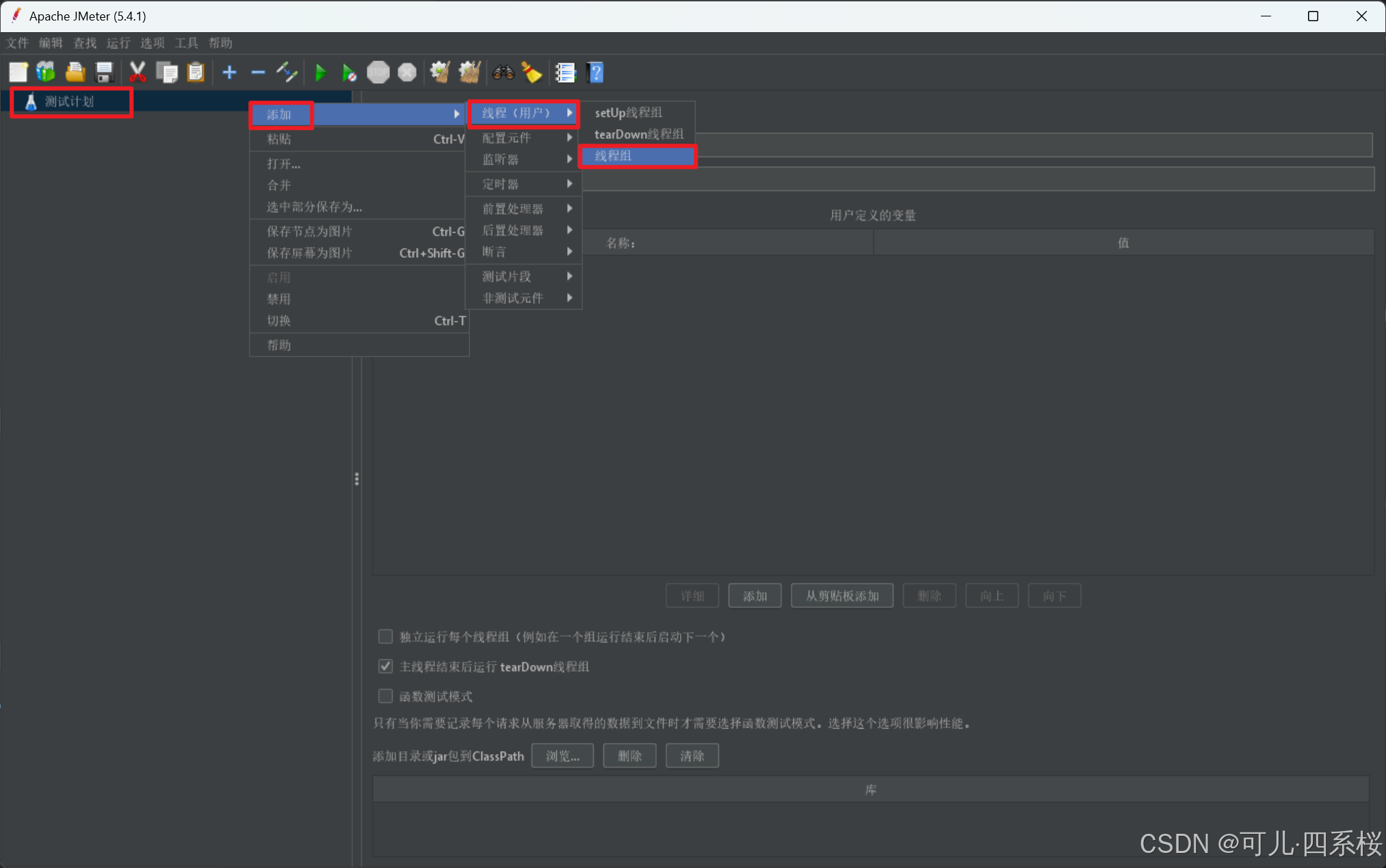
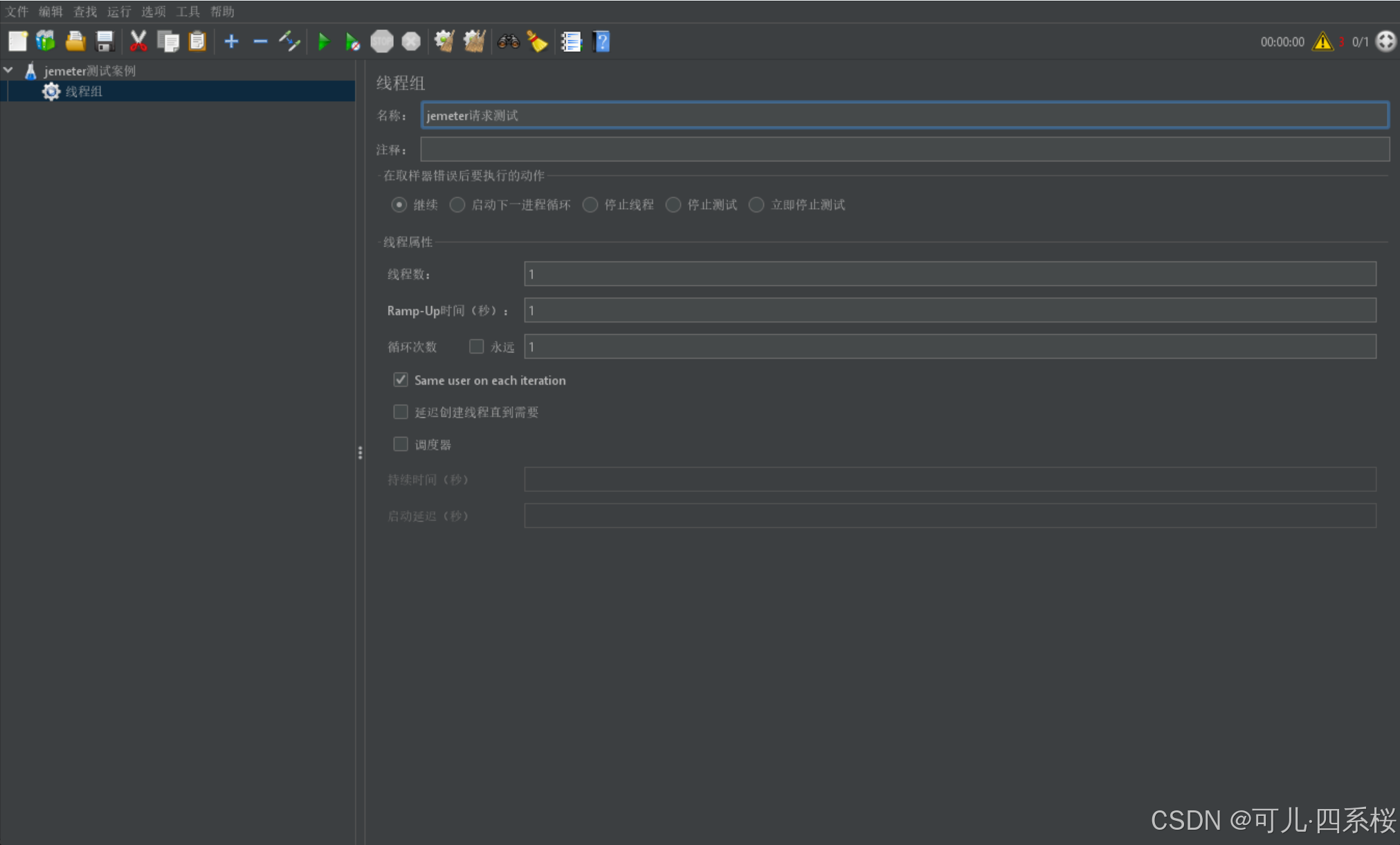
2. 编辑线程组(Thread Group)信息
参数说明:
- 线程数(Number of Threads (users)):并发的线程数
- Ramp-Up时间(秒) (Ramp-up period (seconds)): 多长时间之内,把所有的线程启动起来,因此,QPS = 线程数(Number of Threads (users)) / Ramp-Up时间(秒) (Ramp-up period (seconds))
- 循环次数(loop count): 执行多少次
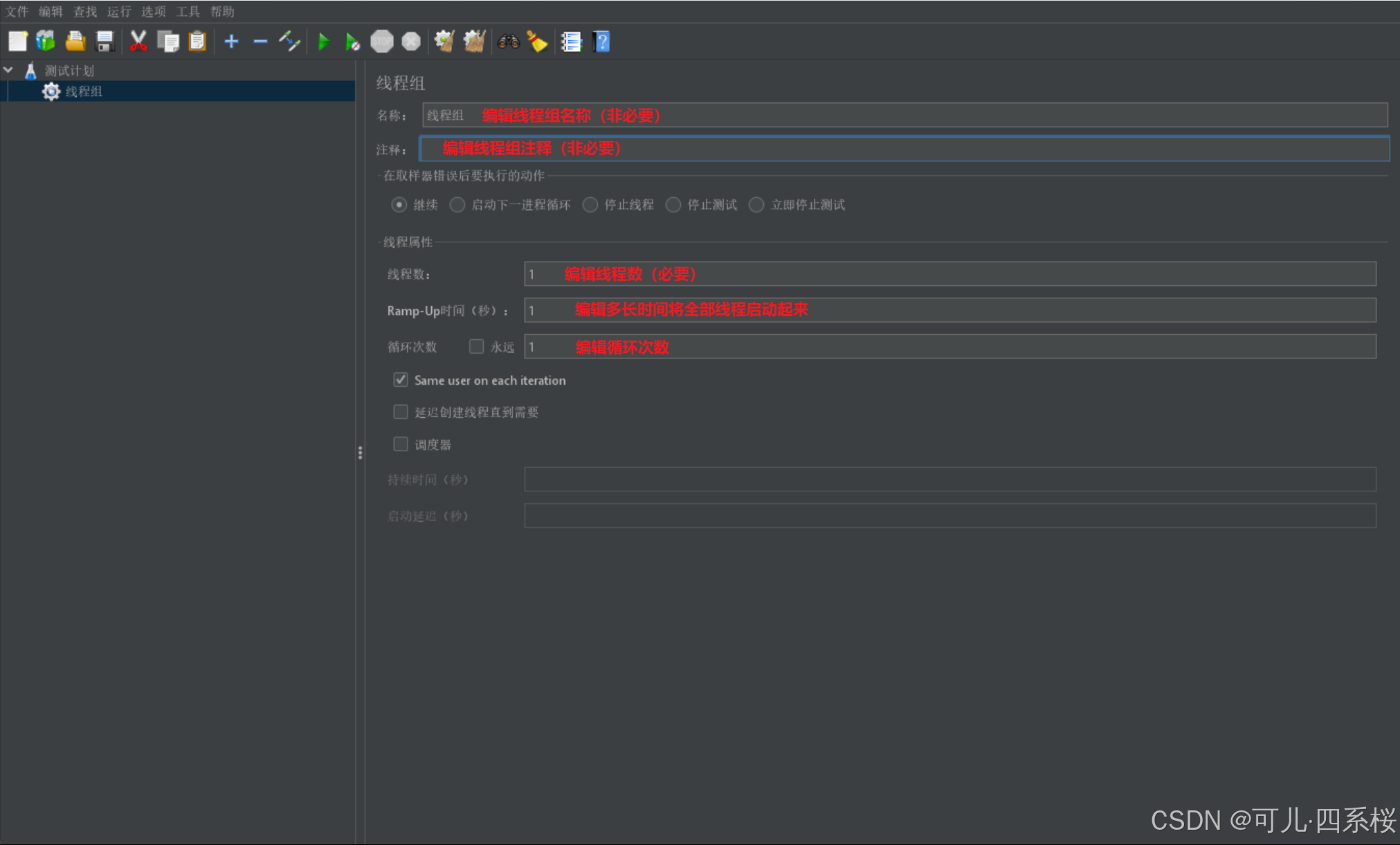 3.3 新建http的取样器
3.3 新建http的取样器
1. 中文版:右击线程组 -> 添加 -> 取样器 -> HTTP请求
英文版:右击Thread Group -> Add -> Sampler -> HTTP Request
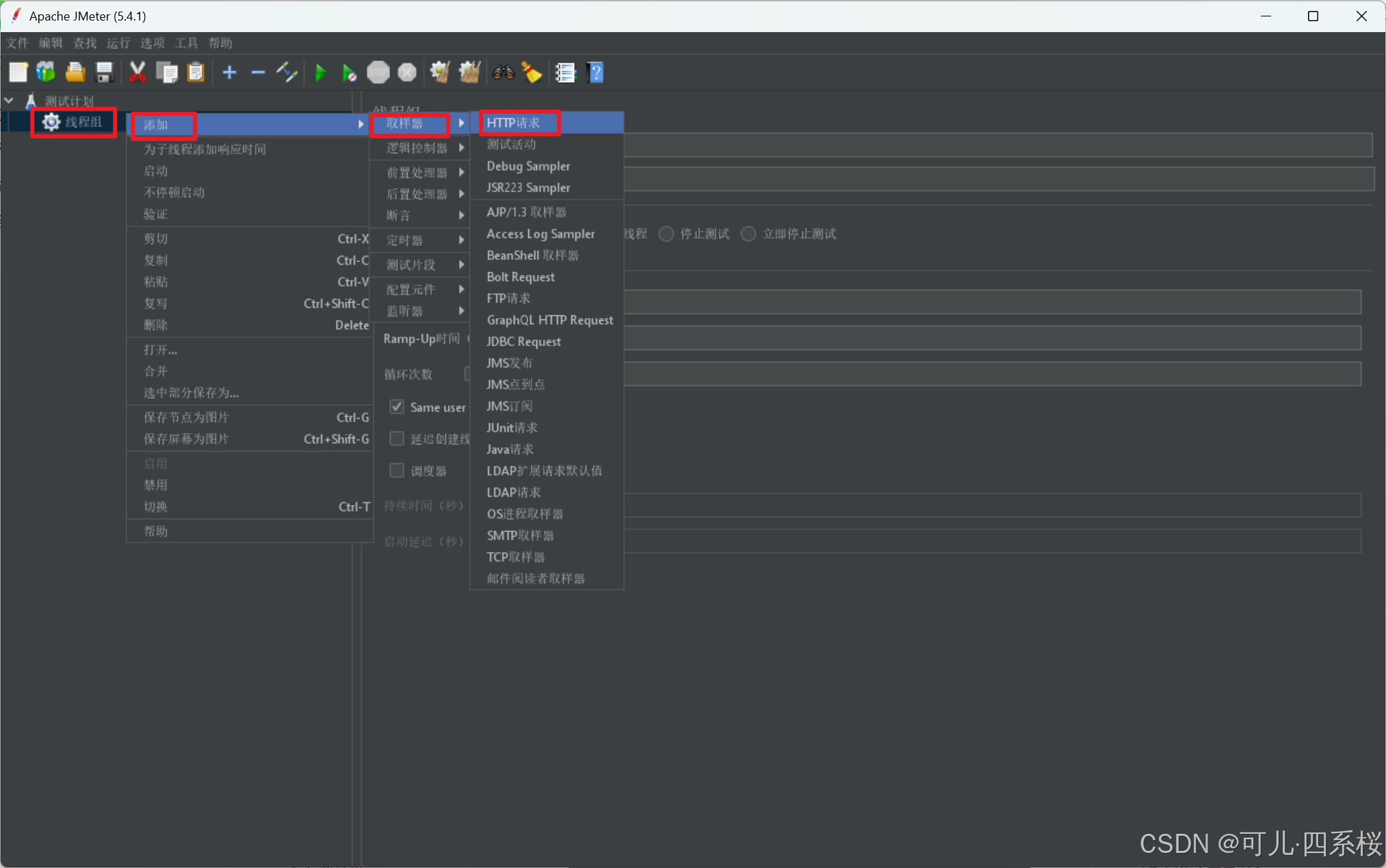
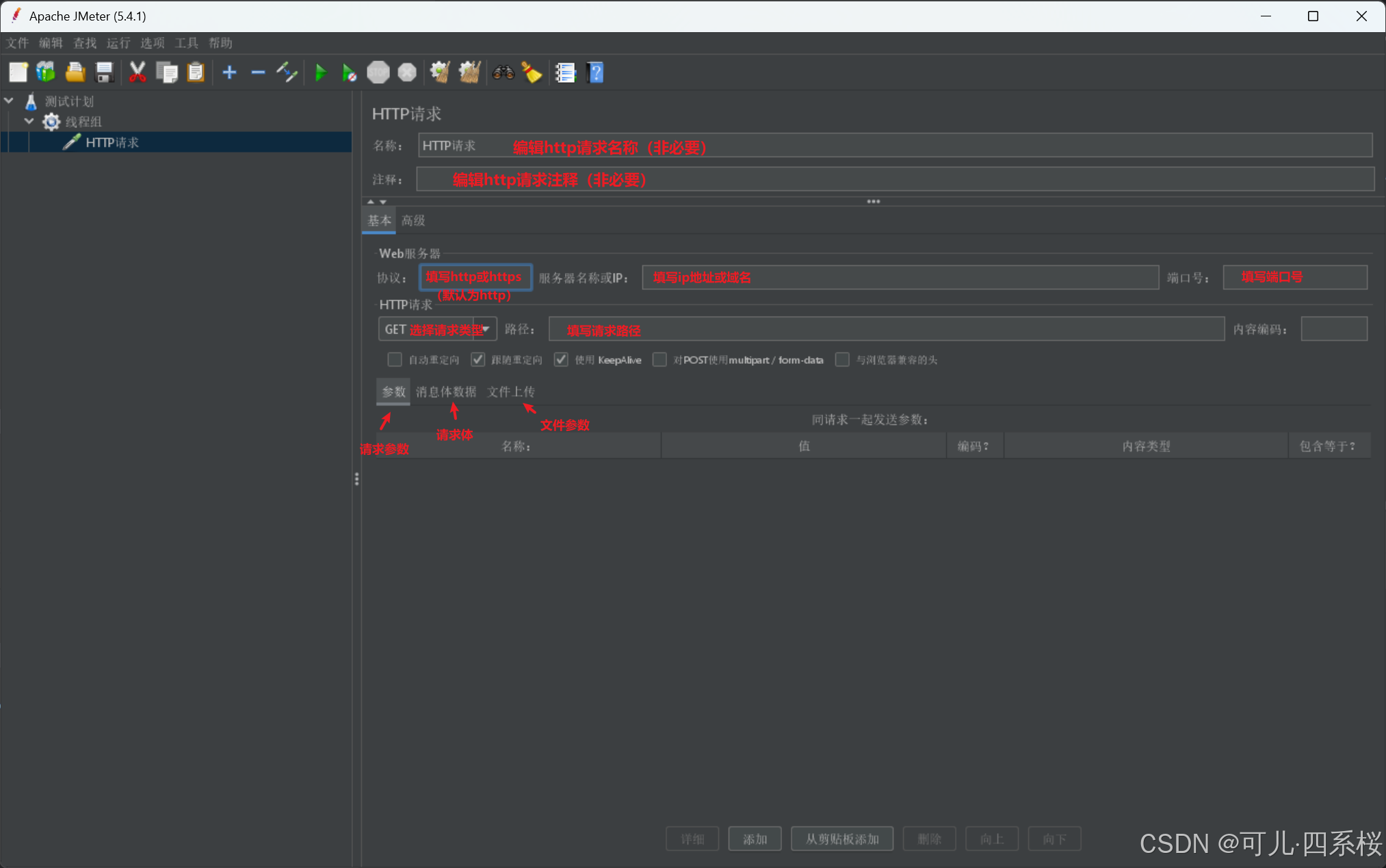
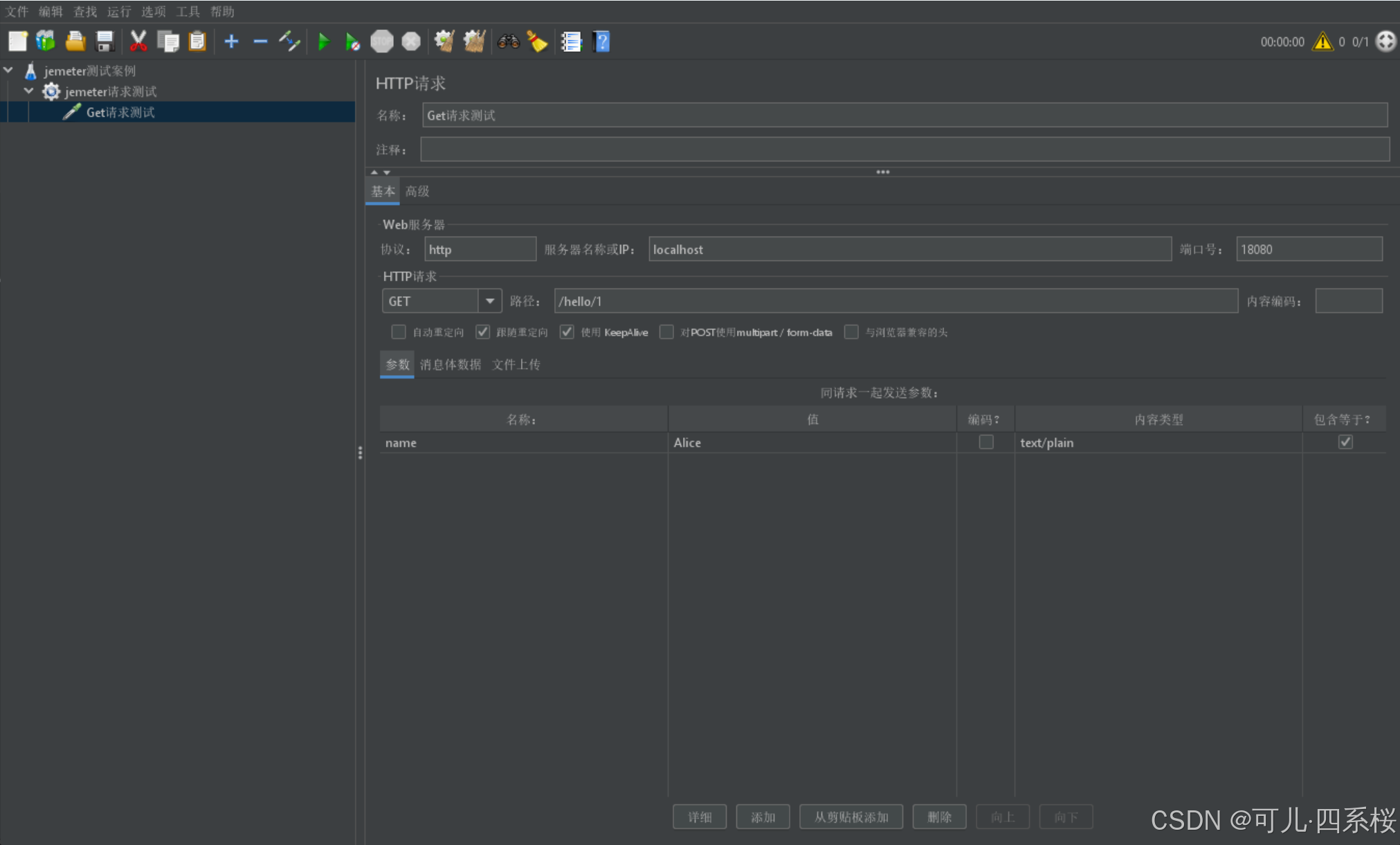
2. 编辑http请求
注意:
- 参数(Params)和消息请求体数据(Body Data)选项是互斥关系,不能同时使用。如果想同时配置,则需要将参数放到路径(Path)那栏填写。
- 如果有文件上传,则需要将请求参数放到路径(Path)那栏填写,请求体放到参数(Params)那栏填写,文件放到文件上传(Files Upload)那栏填写。
- 协议(Protocol [http])可不填写,若不填写默认协议为http。
- 服务器名称或IP(Server Name or lP)如果填写的是域名,则端口号(Port Number)可不填写
3.4 添加请求头(按需添加)
3.4.1 添加线程组(Thread Group)的全局请求头
1. 中文版:右击线程组 -> 添加 -> 配置元件 -> HTTP信息头管理器
英文版:右击Thread Group -> Add -> Config Element -> HTTP Header Manager
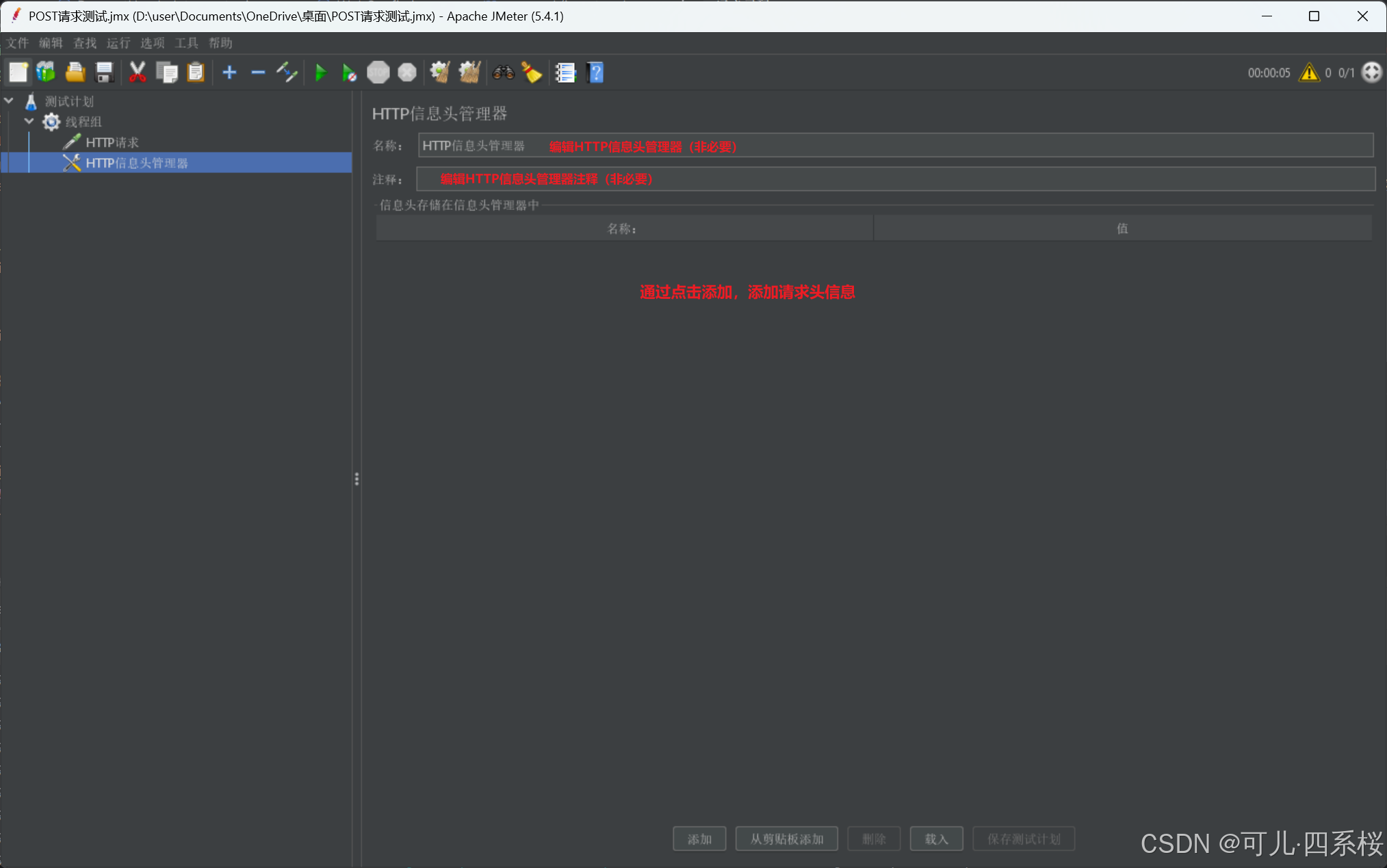
2. 编辑HTTP信息头管理器(HTTP Header Manager)信息
3.4.2 添加单个http请求(HTTP Request)的请求头
1. 中文版:右击HTTP请求 -> 添加 -> 配置元件 -> HTTP信息头管理器
英文版:右击HTTP Request -> Add -> Config Element -> HTTP Header Manager
2. 编辑HTTP信息头管理器(HTTP Header Manager)信息
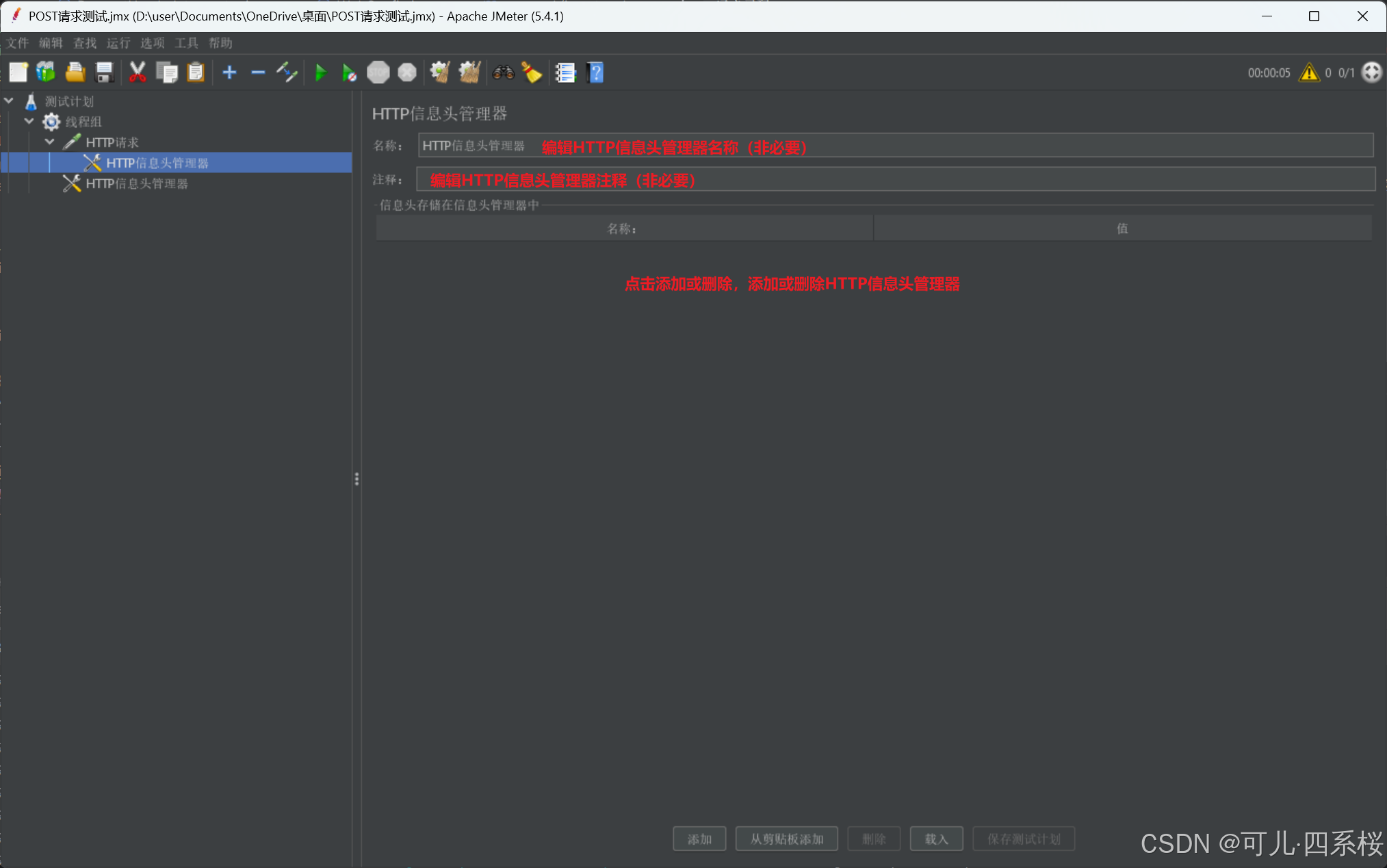
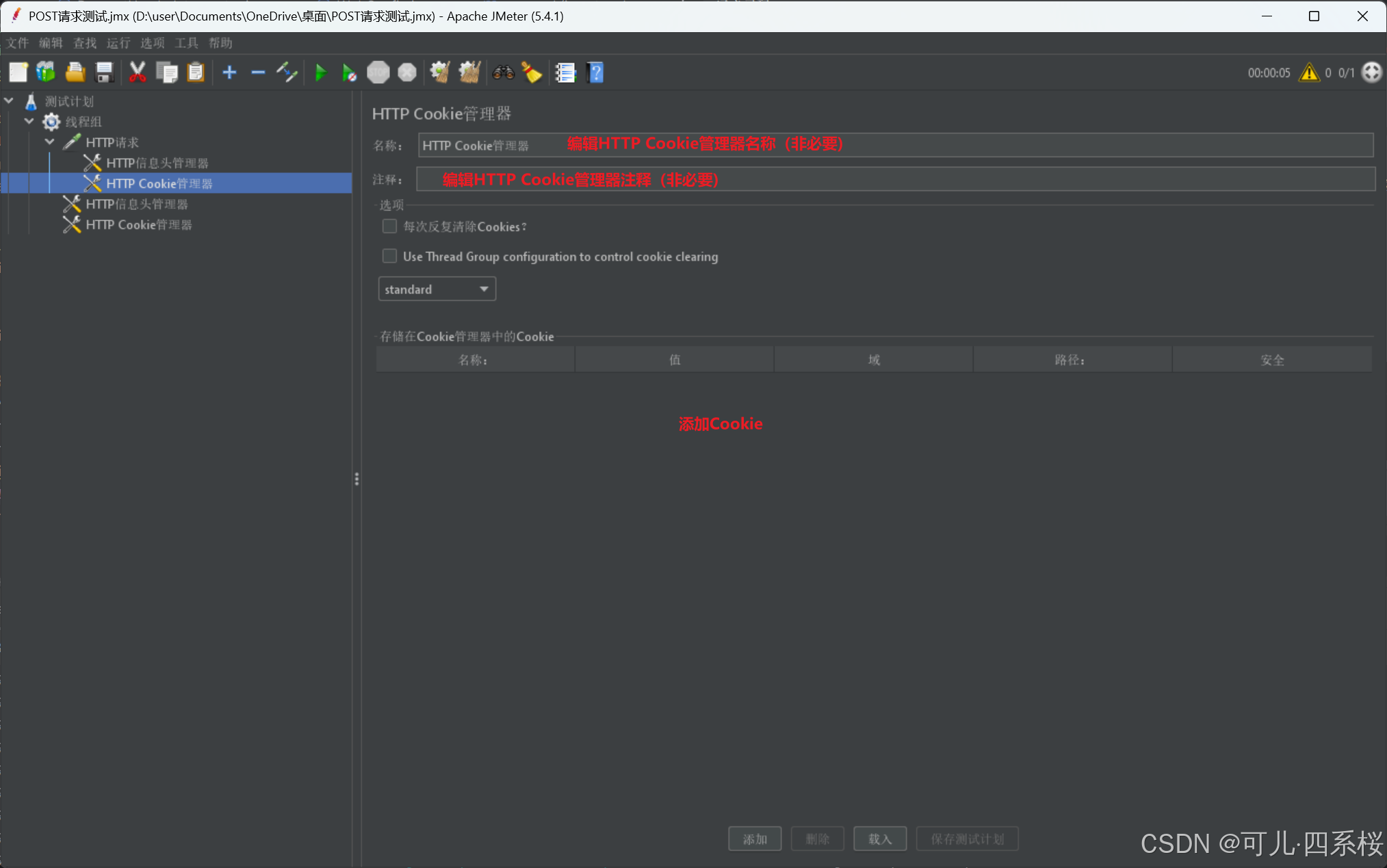
3.5 添加Cookie(按需添加)
3.5.1 添加线程组(Thread Group)的全局Cookie
1. 中文版:右击线程组 -> 添加 -> 配置元件 -> HTTP Cookie管理器
英文版:右击Thread Group -> Add -> Config Element -> HTTP Cookie Manager
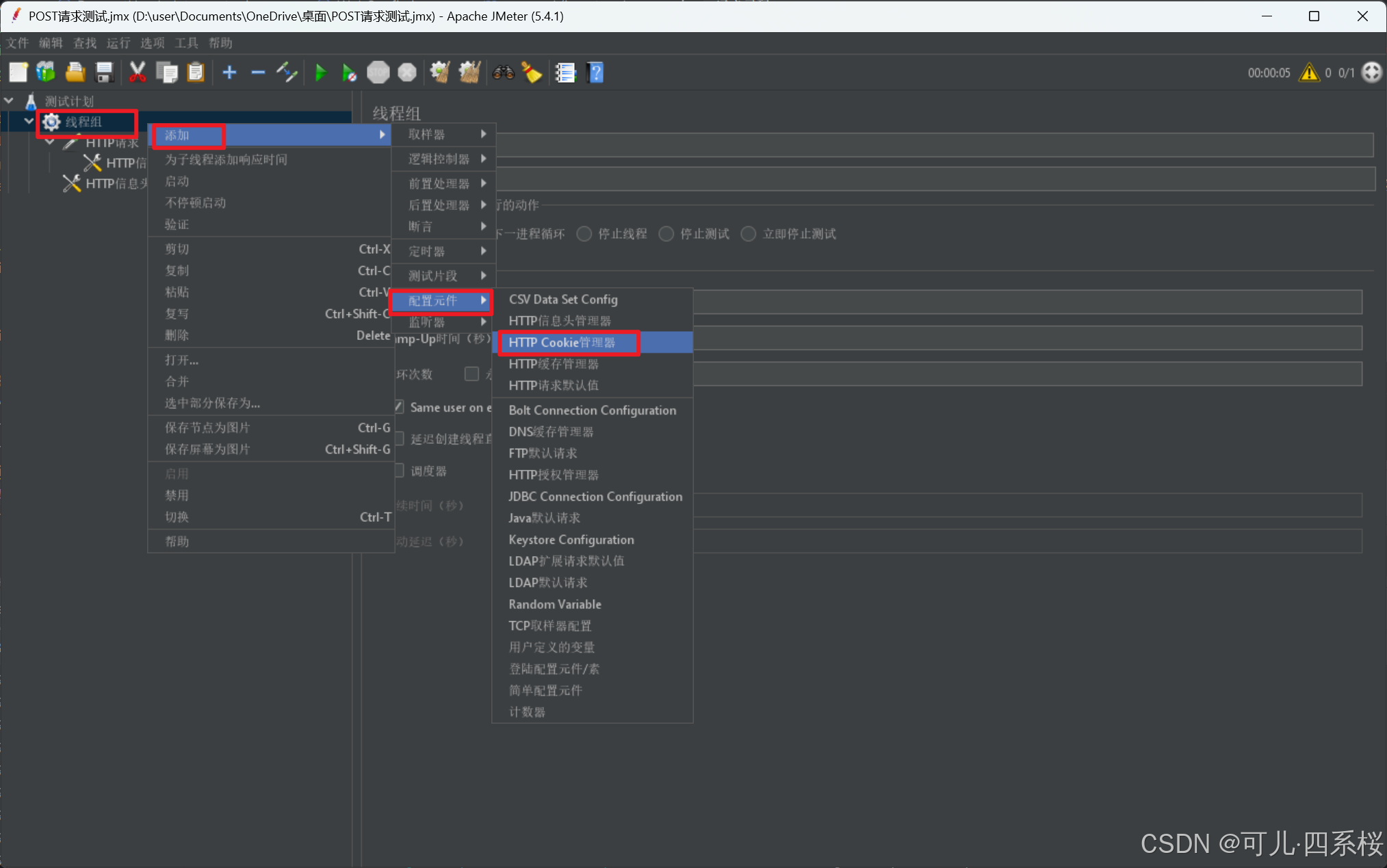
2. 编辑HTTP Cookie管理器(HTTP Cookie Manager)信息
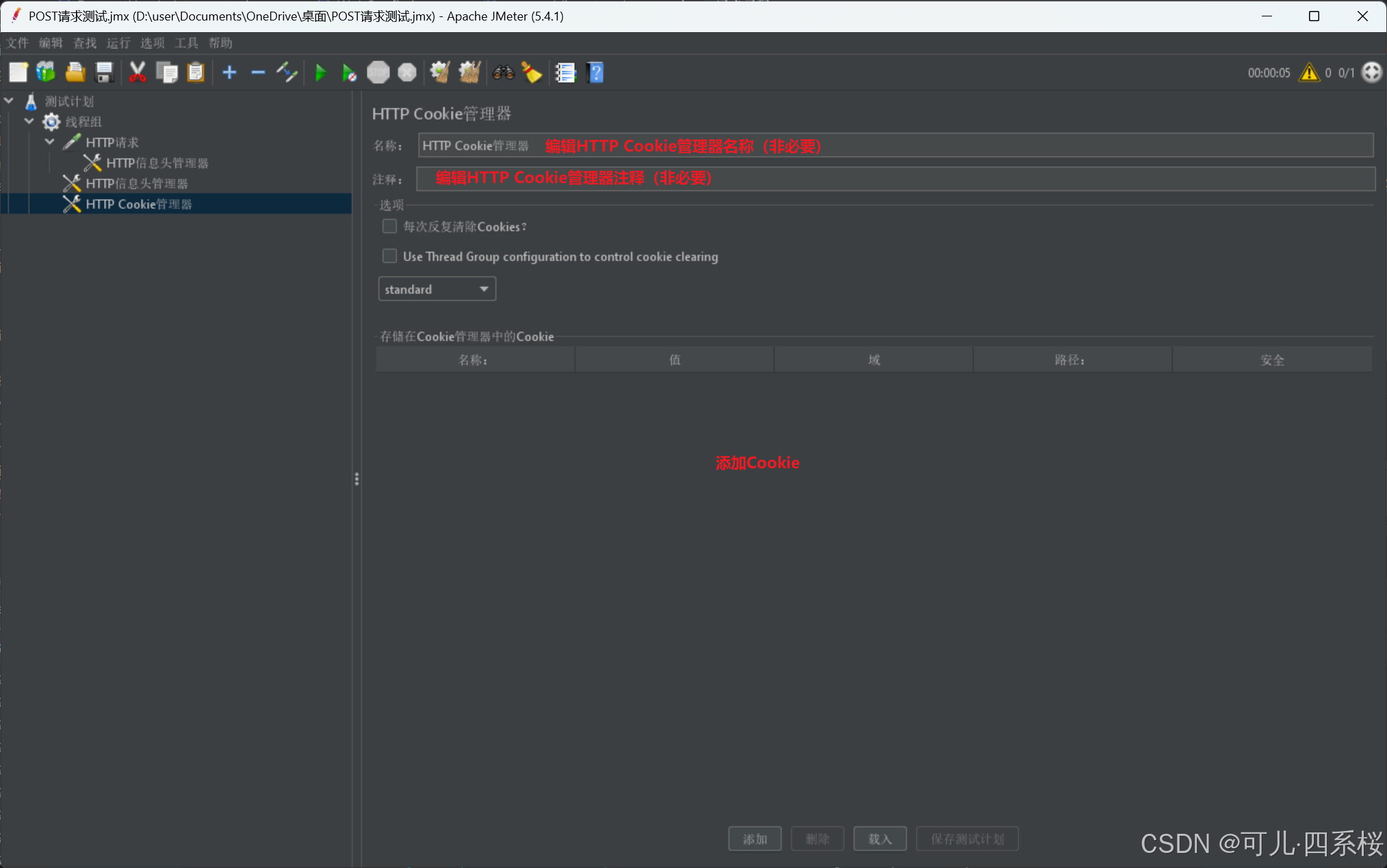
3.5.2 添加单个http请求(HTTP Request)的Cookie
1. 中文版:右击HTTP请求 -> 添加 -> 配置元件 -> HTTP Cookie管理器
英文版:右击HTTP Request -> Add -> Config Element -> HTTP Cookie Manager
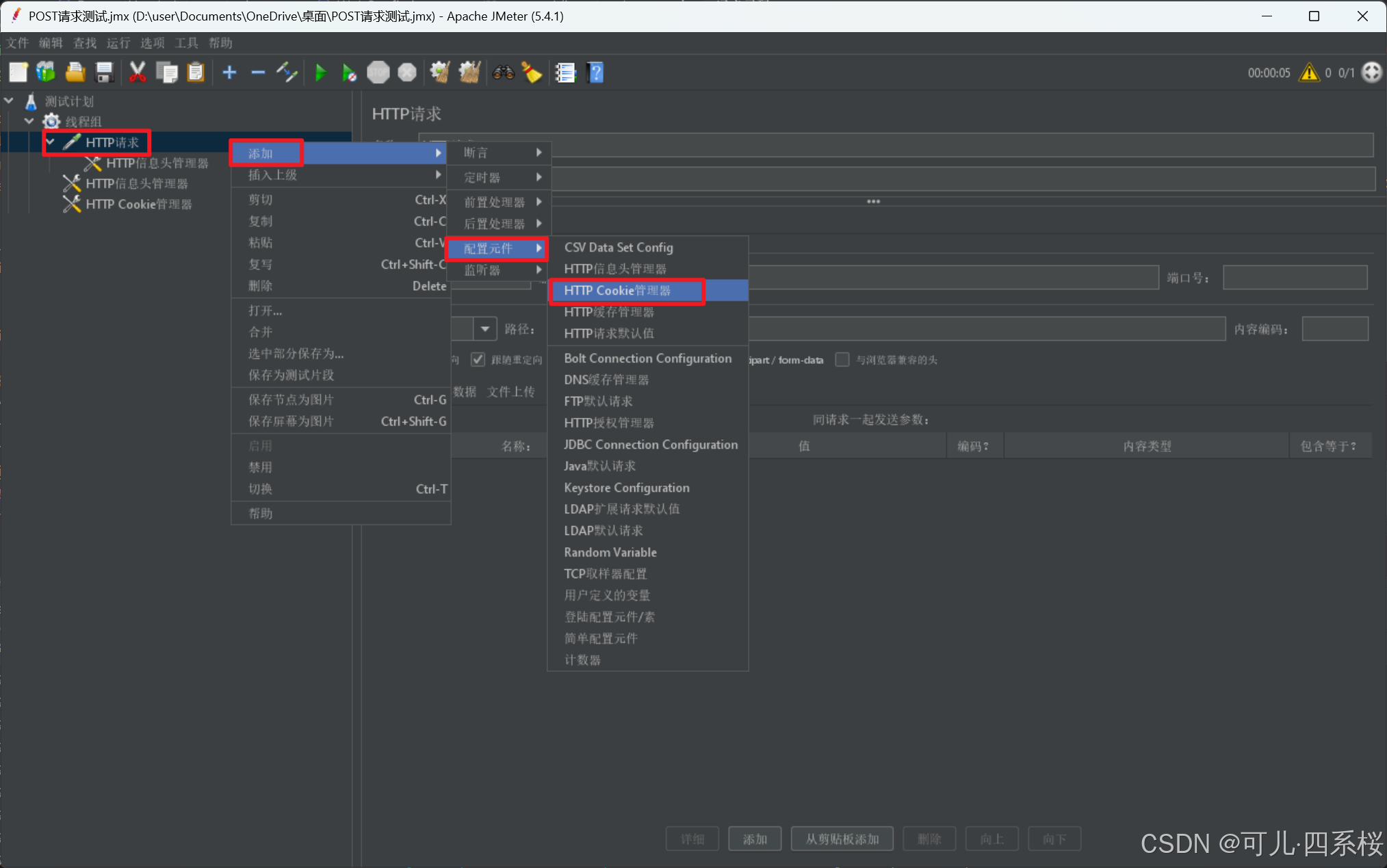
2. 编辑HTTP Cookie管理器(HTTP Cookie Manager)信息
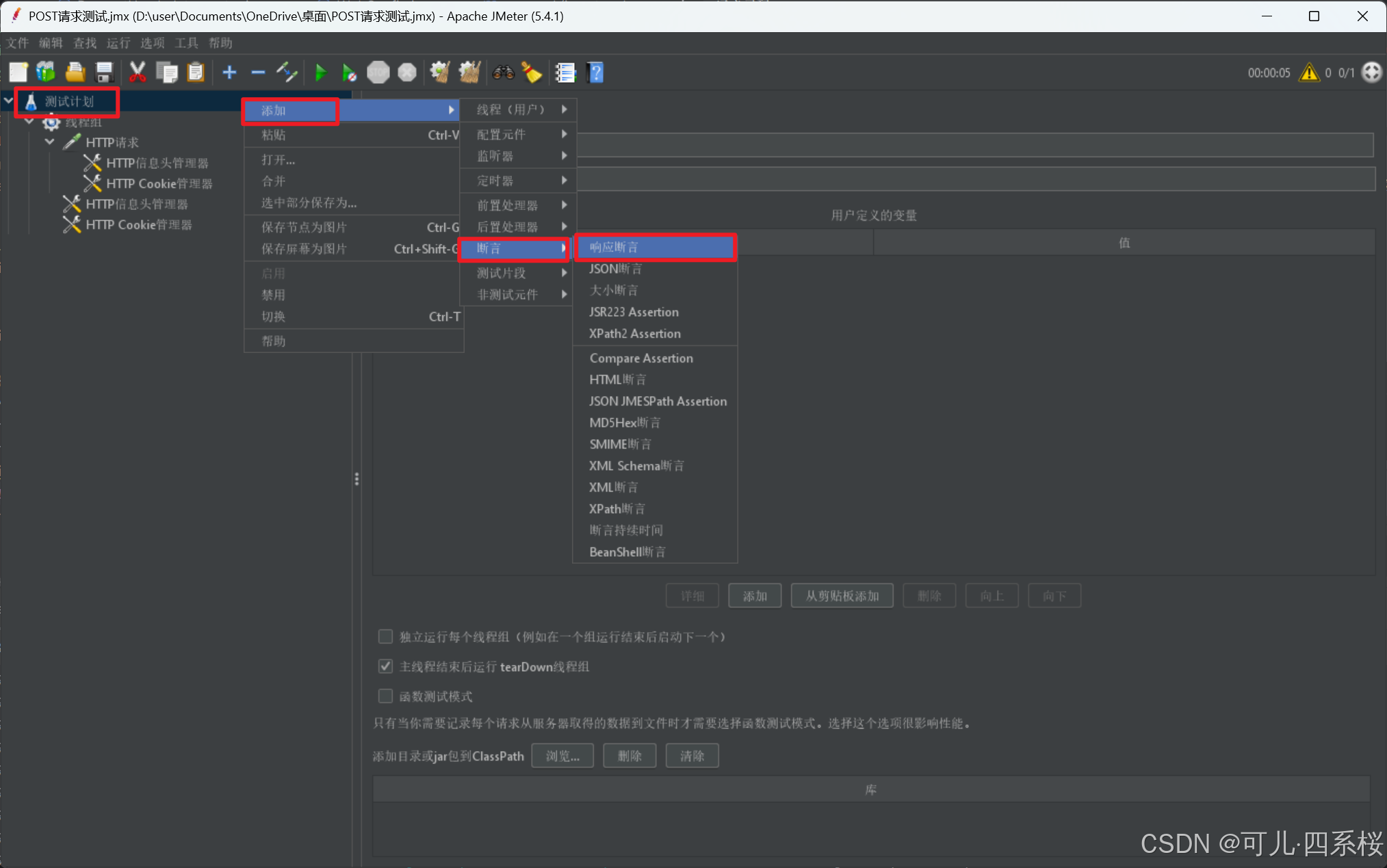
3.6 添加断言(按需添加)
以响应断言为例
3.6.1 添加全局断言
1. 中文版:右击测试计划 -> 添加 -> 断言 -> 响应断言
英文版:右击Test Plan -> Add -> Assertions -> Response Assertion
2. 编辑断言信息
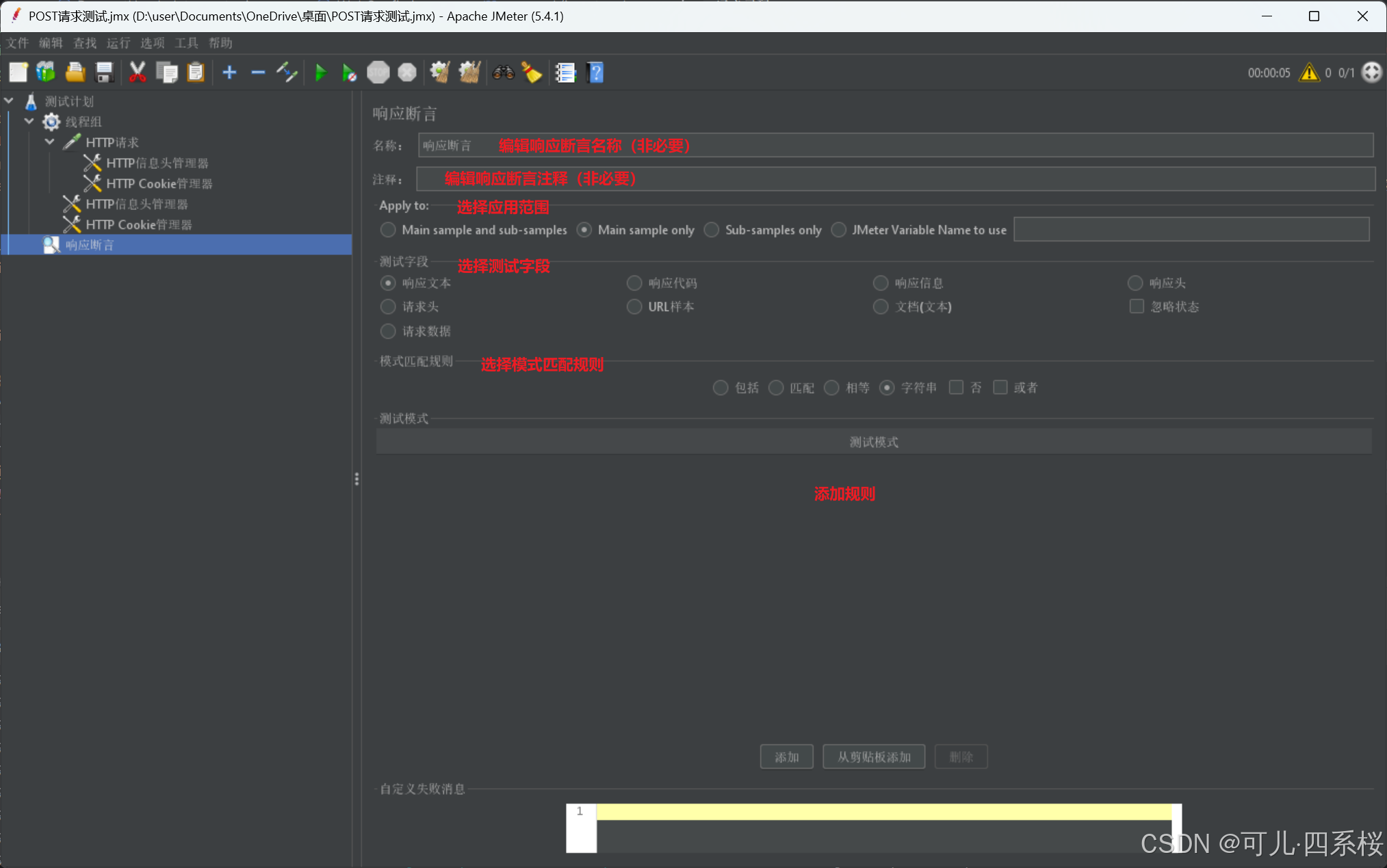
3.6.2 添加线程组(Thread Group)的全局Cookie
1. 中文版:右击线程组 -> 添加 -> 断言 -> 响应断言
英文版:右击Thread Group -> Add -> Assertions -> Response Assertion
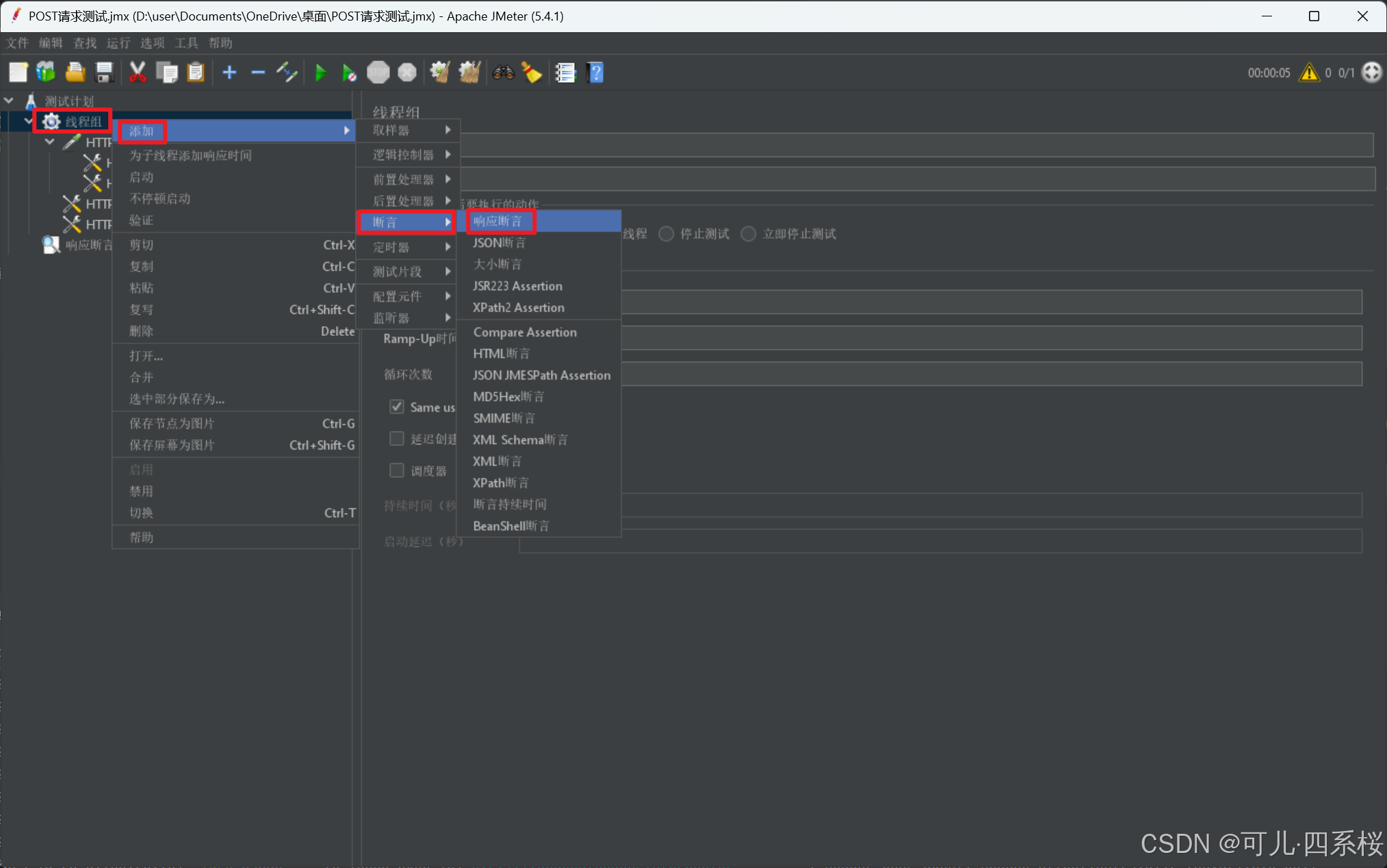
2. 编辑断言信息
3.6.3 添加单个http请求(HTTP Request)的Cookie
1. 中文版:右击HTTP请求 -> 添加 -> 断言 -> 响应断言
英文版:右击HTTP Request -> Add -> Assertions -> Response Assertion
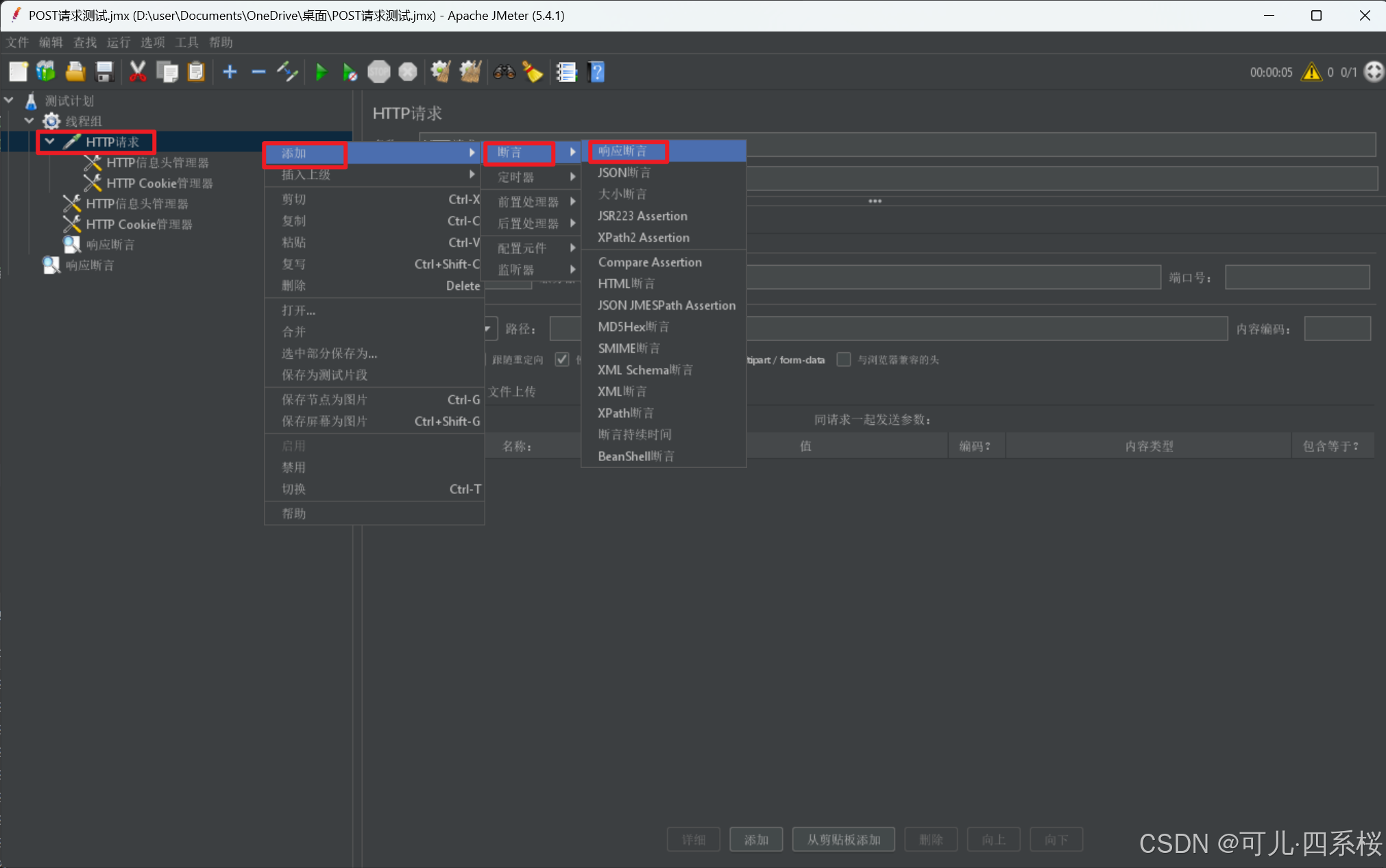
2. 编辑断言信息
3.7 添加定时器(按需添加)
注意事项:
- 定时器会增加测试的复杂性和执行时间,因此在设计测试计划时需要权衡性能和准确性。
- 某些定时器(如同步定时器)会影响多个线程的行为,需要仔细考虑其对整体测试的影响。
3.7.1 定时器添加步骤
1. 中文版:右击测试计划/线程组/HTTP请求 -> 添加 -> 定时器 -> 选择所需的定时器
英文版:右击Test Plan/Thread Group/HTTP Request -> Add -> Timer -> 选择所需的定时器
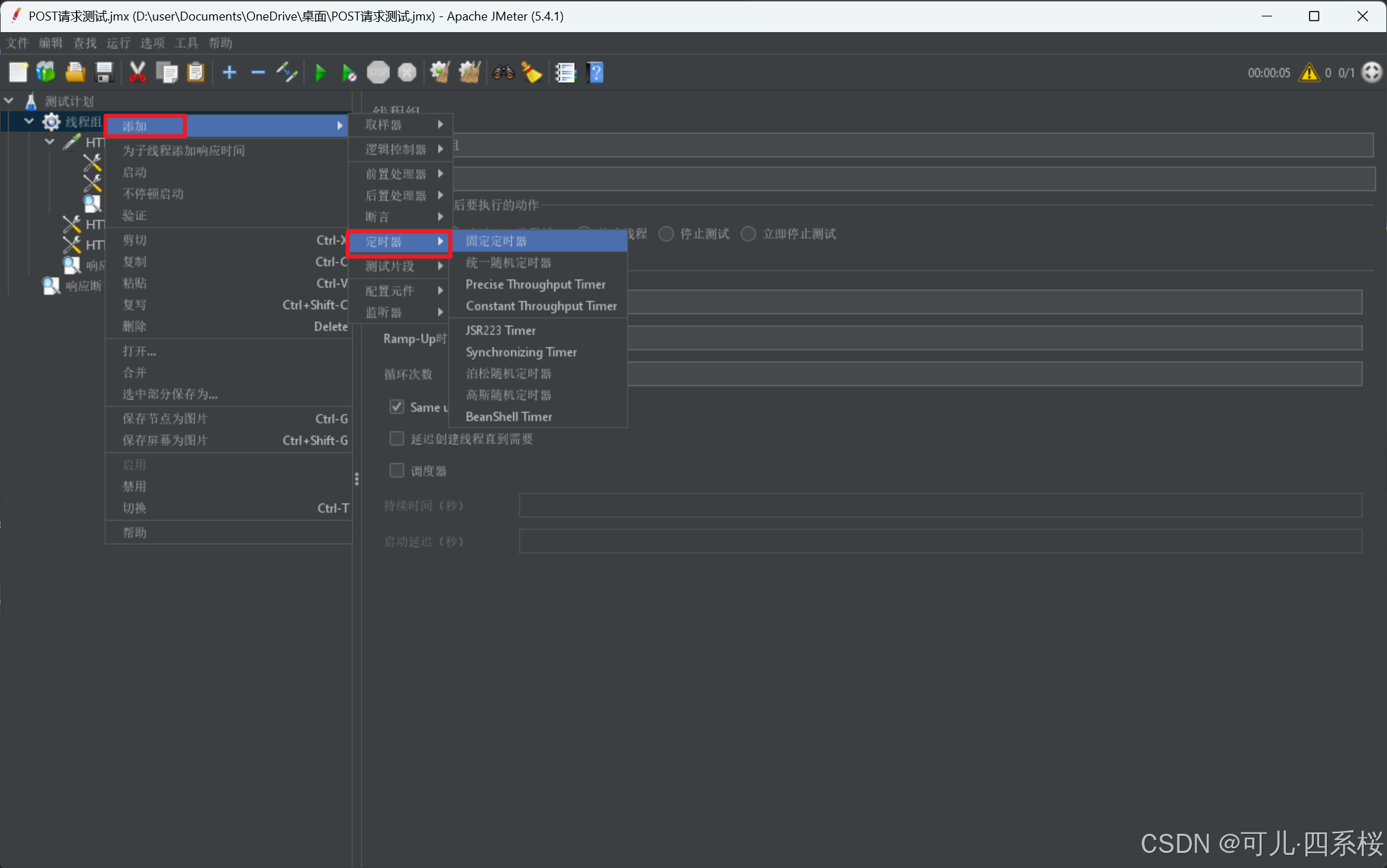
2. 编辑定时器内容
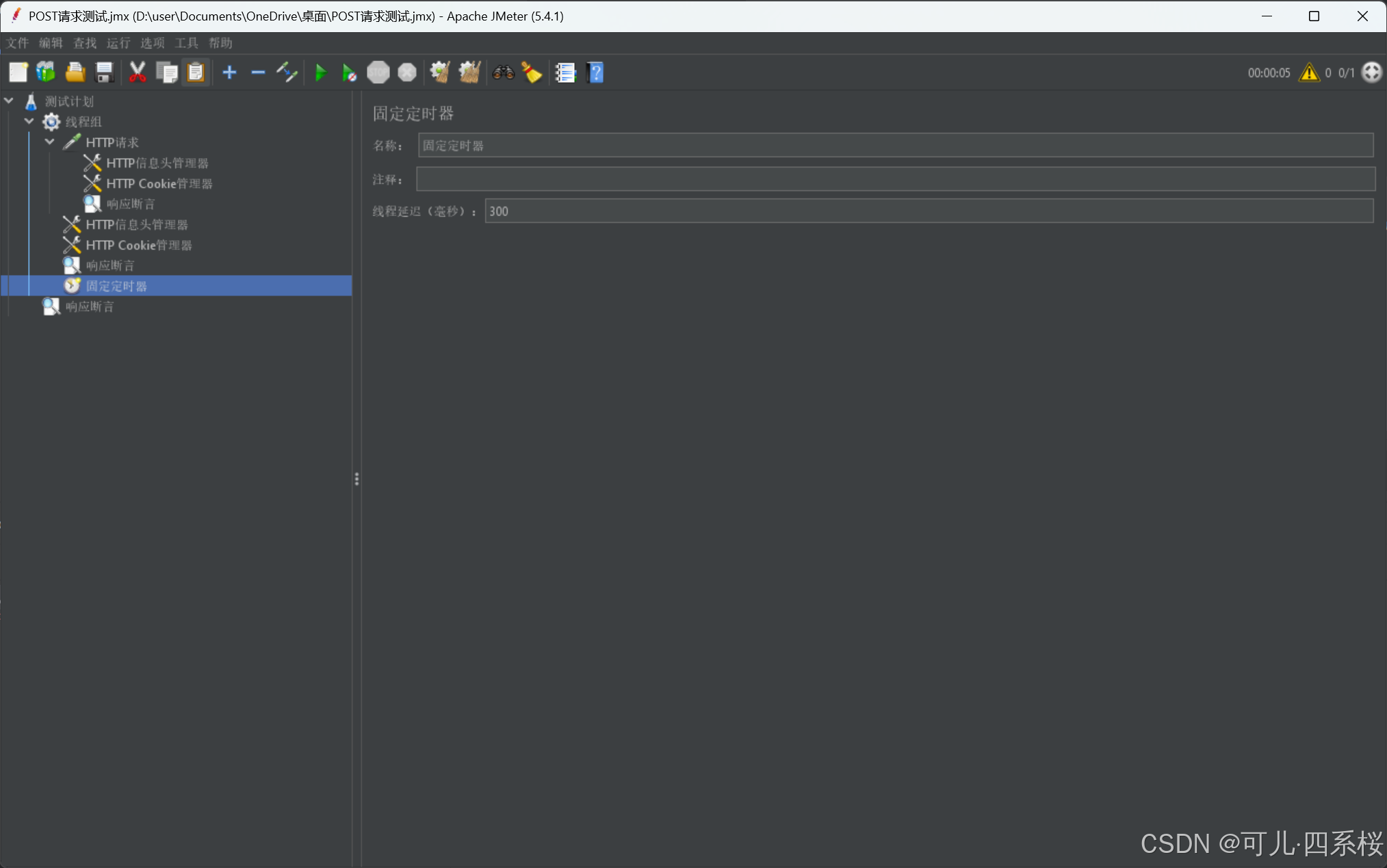
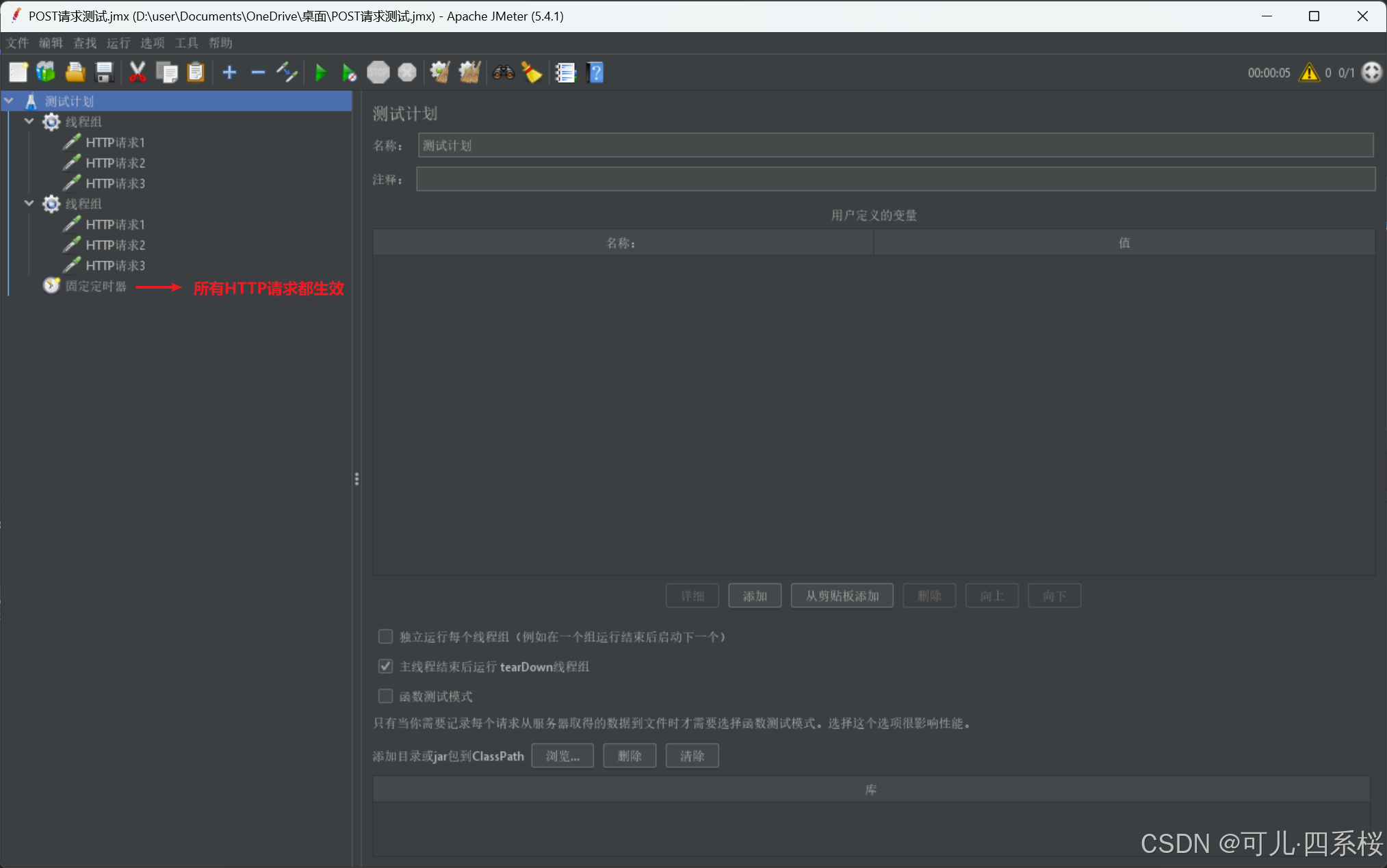
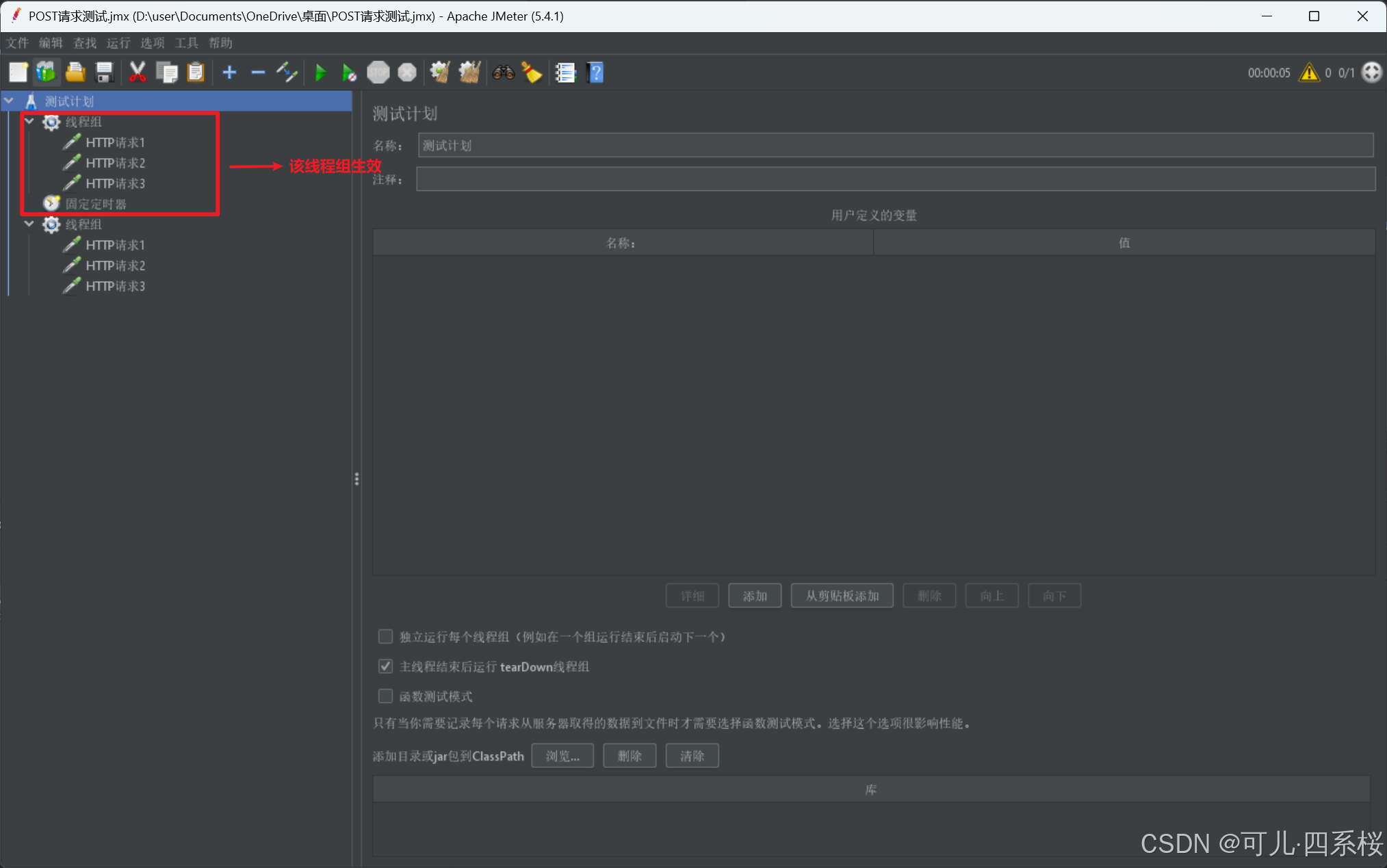
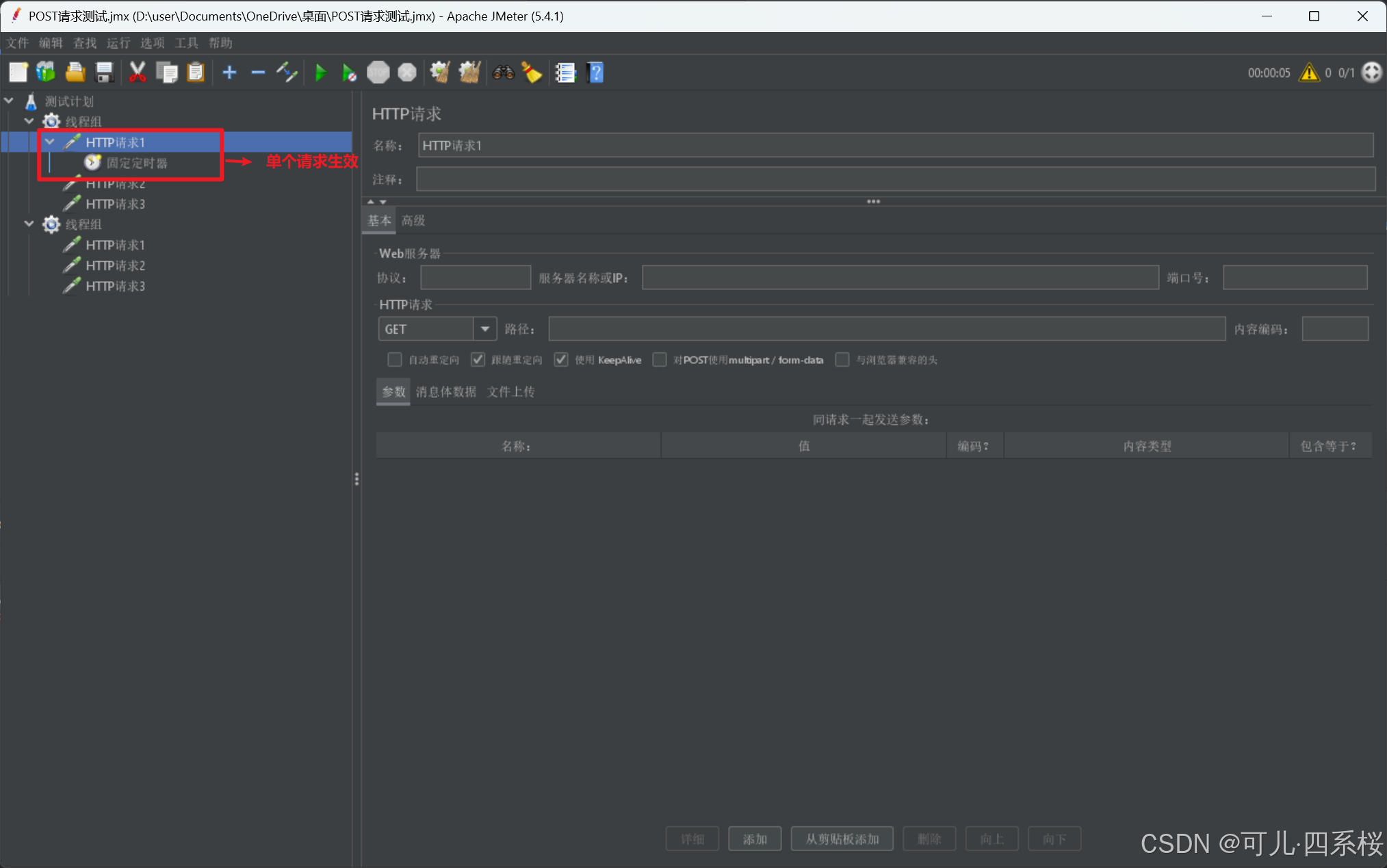
说明:
1. 如果所有请求都需要延迟,则需要放在测试计划(Test Plan)下,如下图:
2. 如果某个线程组(Thread Group)的所有请求都需要延迟,则需要放在该线程组(Thread Group)下,如下图:
3. 如果某个HTTP请求(HTTP Request)需要延迟,则需要放在该HTTP请求(HTTP Request)下,如下图:
3.7.2 定时器分类
| 定时器类型 | 描述 | 主要参数 | 适用场景 | 示例 |
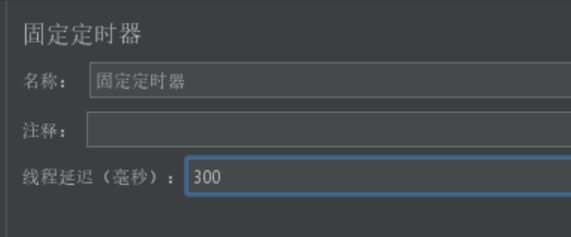
| 常量定时器 (Constant Timer) | 在每个请求之前等待固定的时间 | Thread Delay(线程延迟) | 模拟用户思考时间或网络延迟 | 时间延迟300ms
|
| 高斯随机定时器 (Gaussian Random Timer) | 在指定的平均值基础上增加一个随机的偏移量 | Deviation(偏差)、Constant Delay Offset(固定延迟偏移) | 模拟更自然的用户行为 | 时间延迟300-400ms
|
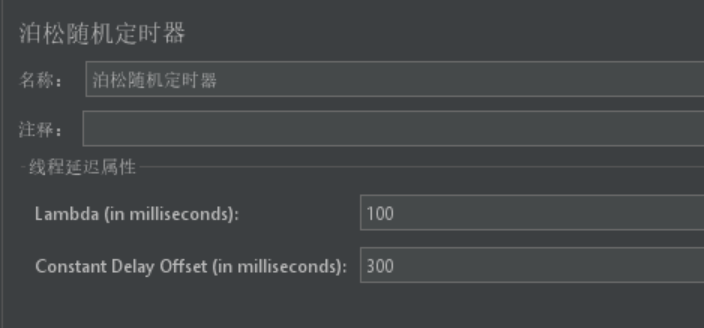
| 泊松随机定时器 (Poisson Random Timer) | 基于泊松分布生成随机等待时间 | Lambda(λ值)、Calculate Throughput(计算吞吐量) | 模拟突发流量或不均匀的用户访问模式 | 时间延迟100-400ms
|
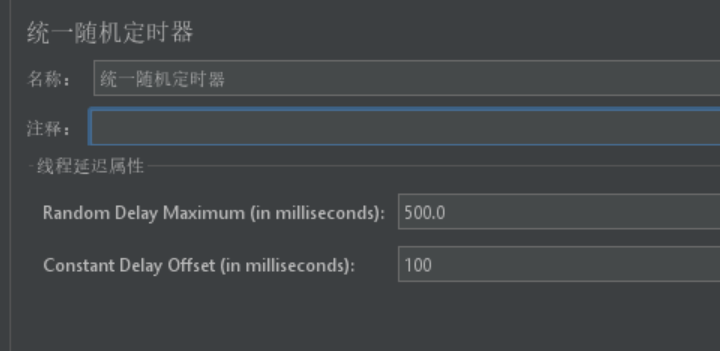
| 统一随机定时器 (Uniform Random Timer) | 在指定的范围内生成一个随机的等待时间 | Random Delay Maximum(随机延迟最大值)、Constant Delay Offset(固定延迟偏移) | 模拟用户行为的不确定性 | 时间延迟100-600ms
|
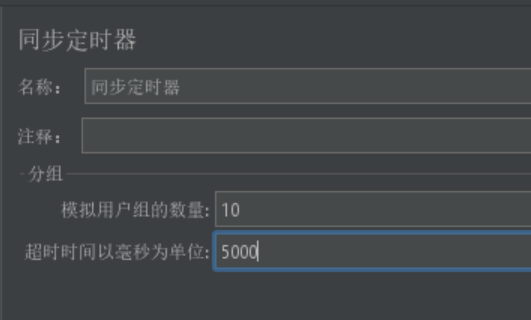
| 同步定时器 (Synchronizing Timer) | 使多个线程同时执行某个请求 | Number of Simulated Users to Group by(模拟用户数) | 模拟大量用户同时访问某个资源的情况,如抢购场景 |
|
| BeanShell 定时器 (BeanShell Timer) | 使用 BeanShell 脚本动态计算等待时间 | 脚本代码 | 需要根据特定条件或逻辑动态调整等待时间的场景 | 时间延迟5000ms
|
| JSR223 定时器 (JSR223 Timer) | 支持多种脚本语言(如 Groovy、JavaScript 等)来编写定时器逻辑 | 脚本语言、脚本代码 | 需要复杂逻辑处理的定时器需求 | 时间延迟1000-3000ms
|


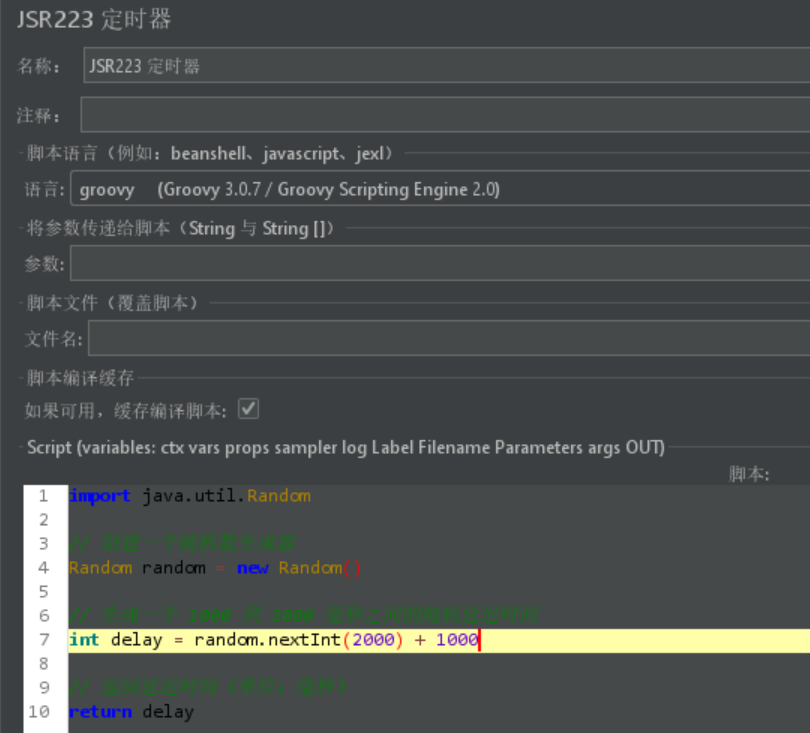
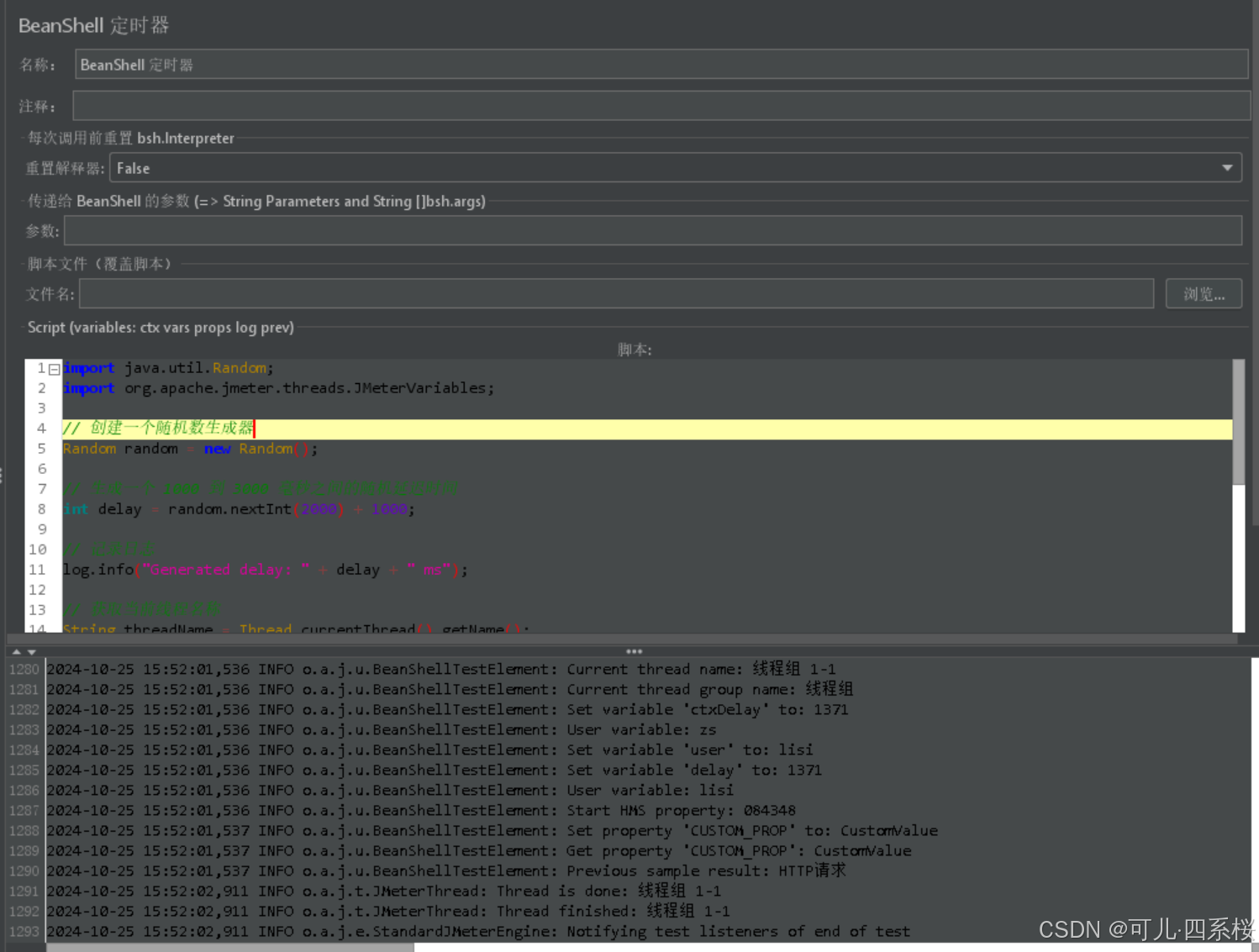
关于BeanShell 定时器 (BeanShell Timer)和JSR223 定时器 (JSR223 Timer)补充说明:
1. 调用脚本之前,在 BeanShell解释器中设置一些变量:
- log - (Logger) - 可以用来写入日志文件
- ctx - (JMeterContext) - 提供对上下文的访问
- vars - (JMeterVariables) - 提供对变量的读/写访问
vars.get(key); vars.put(key,val); vars.putObject("OBJ1",new Object());
- props - (JMeterProperties - class java.util.Properties) - 例如:props.get("START.HMS"); props.put("PROP1","1234");
- prev - (SampleResult) - 允许访问之前的SampleResult(如果有的话)
例如:
脚本内容如下:
import java.util.Random; import org.apache.jmeter.threads.JMeterVariables; // 创建一个随机数生成器 Random random = new Random(); // 生成一个 1000 到 3000 毫秒之间的随机延迟时间 int delay = random.nextInt(2000) + 1000; // 记录日志 log.info("Generated delay: " + delay + " ms"); // 获取当前线程名称 String threadName = Thread.currentThread().getName(); log.info("Current thread name: " + threadName); // 获取当前线程组名称 String threadGroupName = ctx.getThreadGroup().getName(); log.info("Current thread group name: " + threadGroupName); // 获取和设置变量 JMeterVariables variables = ctx.getVariables(); variables.put("ctxDelay", String.valueOf(delay)); String delayVar = variables.get("ctxDelay"); log.info("Set variable 'ctxDelay' to: " + delayVar); // 读取和写入变量 String userVar = variables.get("user"); log.info("User variable: " + userVar); // 设置新的变量 variables.put("user", String.valueOf("lisi")); log.info("Set variable 'user' to: lisi"); // 设置和获取变量 vars.put("delay", String.valueOf(delay)); String delayVar = vars.get("delay"); log.info("Set variable 'delay' to: " + delayVar); // 读取和写入变量 String userVar = vars.get("user"); log.info("User variable: " + userVar); // 读取和写入属性 String startHMS = props.get("START.HMS"); log.info("Start HMS property: " + startHMS); // 设置新的属性 props.put("CUSTOM_PROP", "CustomValue"); log.info("Set property 'CUSTOM_PROP' to: CustomValue"); // 获取刚刚设置的属性 String customProp = props.get("CUSTOM_PROP"); log.info("Get property 'CUSTOM_PROP': " + customProp); // 获取上一个 SampleResult if (prev != null) { log.info("Previous sample result: " + prev.toString()); } else { log.info("No previous sample result available."); } // 返回延迟时间(单位:毫秒) return delay;
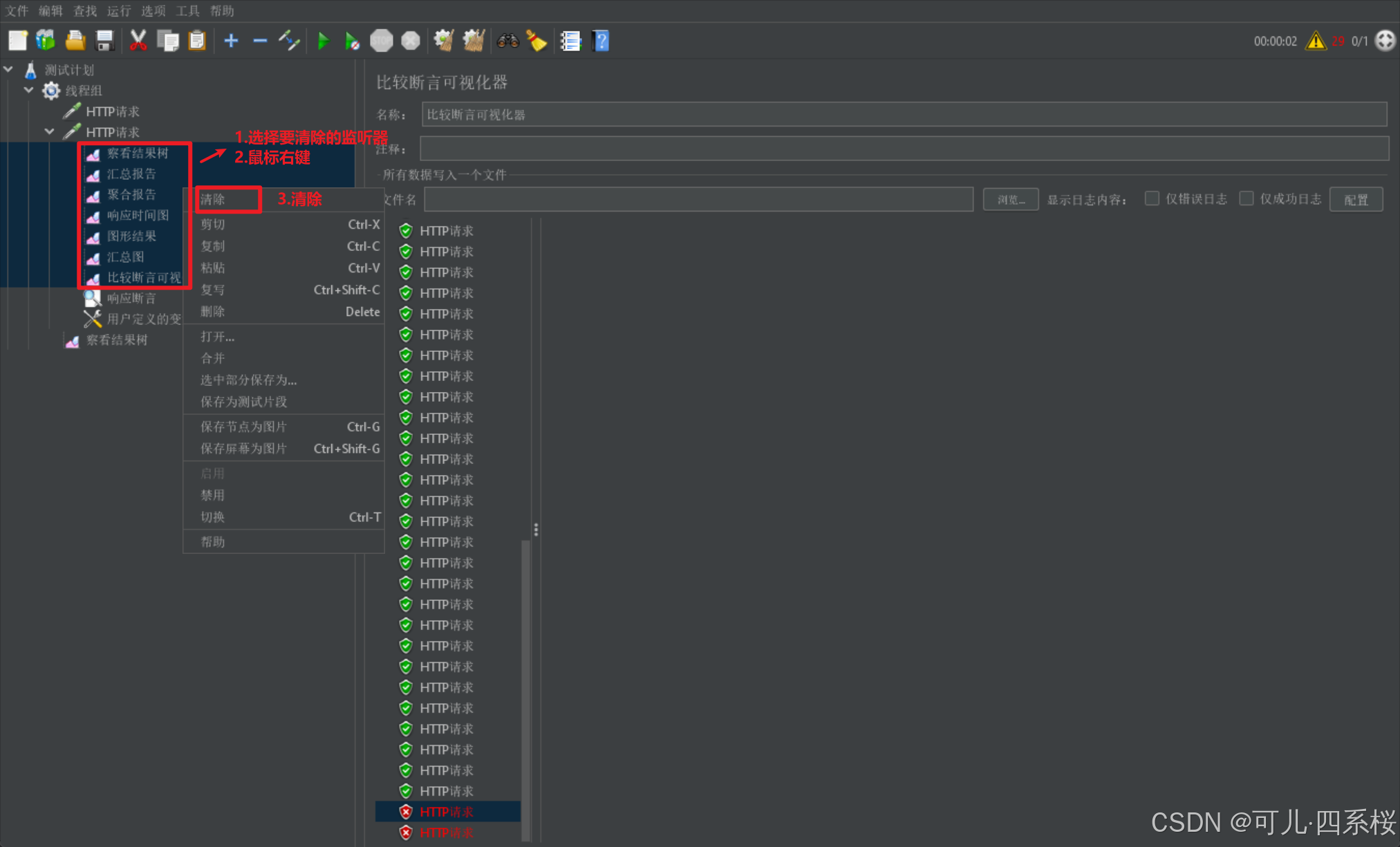
3.8 添加监听器(查询访问结果)
注意:
每次请求时,监听器并不会清除之前访问的记录,需要手动清理,清理方法:选中要清理的监听器(批量清除则需要按住shift或ctrl键选择多个),右键点击清除(clear)。
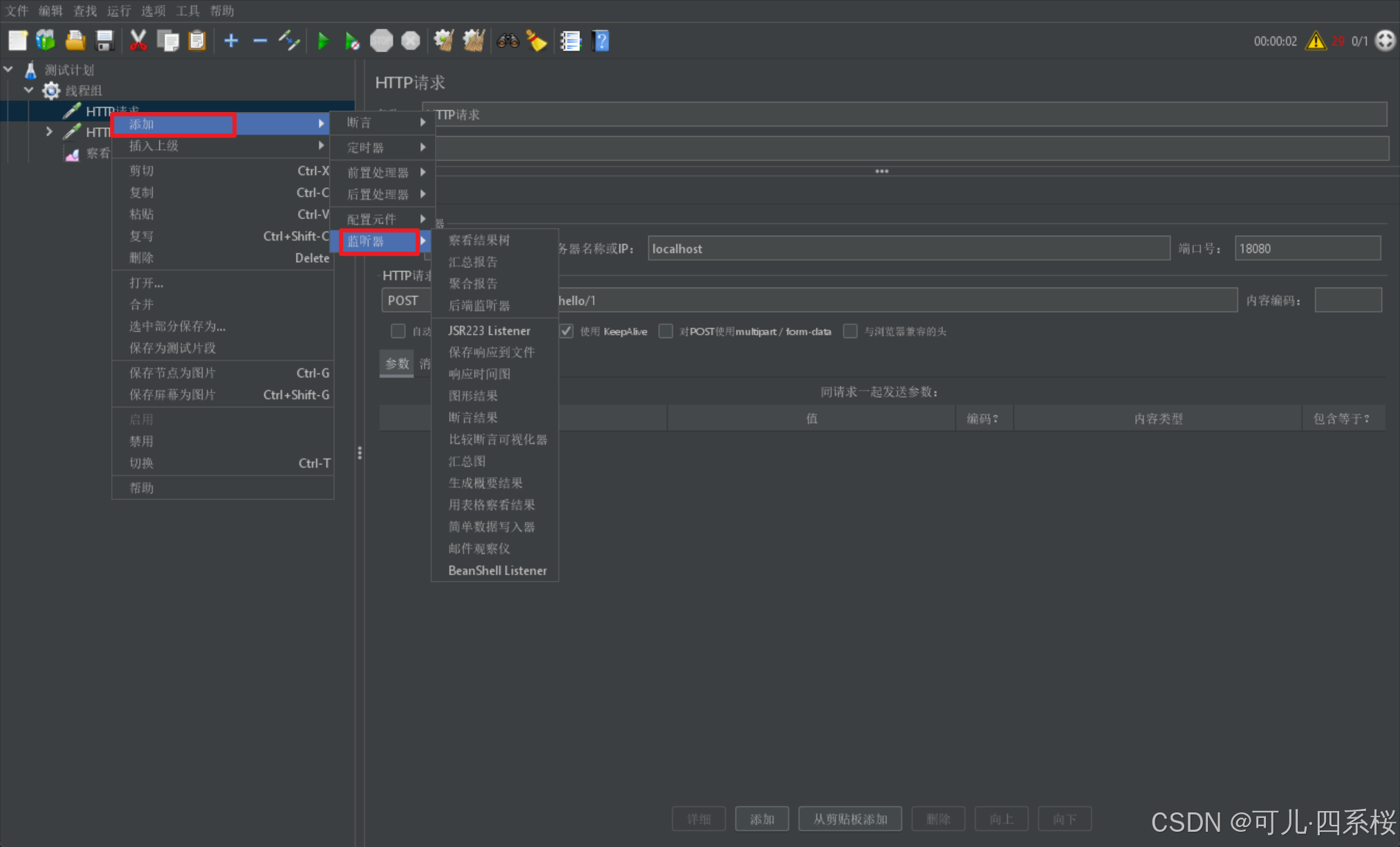
3.8.1 监听器添加步骤
1. 中文版:右击测试计划/线程组/HTTP请求 -> 添加 -> 监听器 -> 选择所需的监听器
英文版:右击Test Plan/Thread Group/HTTP Request -> Add -> Listener -> 选择所需的监听器
 2. 编辑监听器内容
2. 编辑监听器内容
3.8.2 监听器分类
| 监听器名称 | 功能描述 | 主要用途 |
| 聚合报告 (Aggregate Report) | 提供了一个汇总的性能报告,包括平均响应时间、最小响应时间、最大响应时间、吞吐量、错误率等。 | 快速了解整个测试的总体性能情况。 |
| 视图结果树 (View Results Tree) | 以树状结构显示每个请求的详细结果,包括请求和响应的内容。 | 调试单个请求,查看请求和响应的具体内容。 |
| 聚合图形 (Aggregate Graph) | 以图形的方式显示聚合报告中的数据,包括平均响应时间、最小响应时间、最大响应时间等。 | 可视化性能数据,便于分析趋势。 |
| 响应时间图 (Response Time Graph) | 以图形的方式显示每个请求的响应时间。 | 分析响应时间的变化趋势。 |
| 响应时间 vs 请求 (Response Time vs. Request) | 显示每个请求的响应时间,以表格形式展示。 | 详细分析每个请求的响应时间。 |
| 直方图 (Histogram) | 以直方图的形式显示响应时间的分布情况。 | 分析响应时间的分布情况,识别性能瓶颈。 |
| 监听器 - 保存响应到文件 (Save Responses to a file) | 将响应内容保存到文件中。 | 保存响应内容,以便后续分析或存档。 |
| 监听器 - 断言结果 (Assertion Results) | 显示所有断言的结果,包括成功和失败的断言。 | 验证测试结果是否符合预期。 |
| 监听器 - 监控结果 (Monitor Results) | 显示服务器的监控数据,如 CPU 使用率、内存使用率等。 | 监控服务器的性能指标。 |
| 监听器 - 通过/失败 (Pass/Fail Assertion) | 根据预设条件判断测试是否通过或失败。 | 确定测试是否达到预期标准。 |
| 监听器 - 采样器结果 (Sample Result Save Configuration) | 配置采样器结果的保存选项,如保存哪些数据字段。 | 控制测试结果的详细程度和存储需求。 |
| 监听器 - 通过/失败计数器 (Pass/Fail Counter) | 统计通过和失败的请求数量。 | 快速了解测试的通过率。 |
| 监听器 - 通过/失败阈值 (Pass/Fail Threshold) | 根据预设的阈值判断测试是否通过或失败。 | 确定测试是否达到性能标准。 |
| 监听器 - 通过/失败断言 (Pass/Fail Assertion) | 根据预设条件判断测试是否通过或失败。 | 确定测试是否达到预期标准。 |
| 监听器 - 通过/失败计数器 (Pass/Fail Counter) | 统计通过和失败的请求数量。 | 快速了解测试的通过率。 |
下面是针对部分常用的监听器介绍。
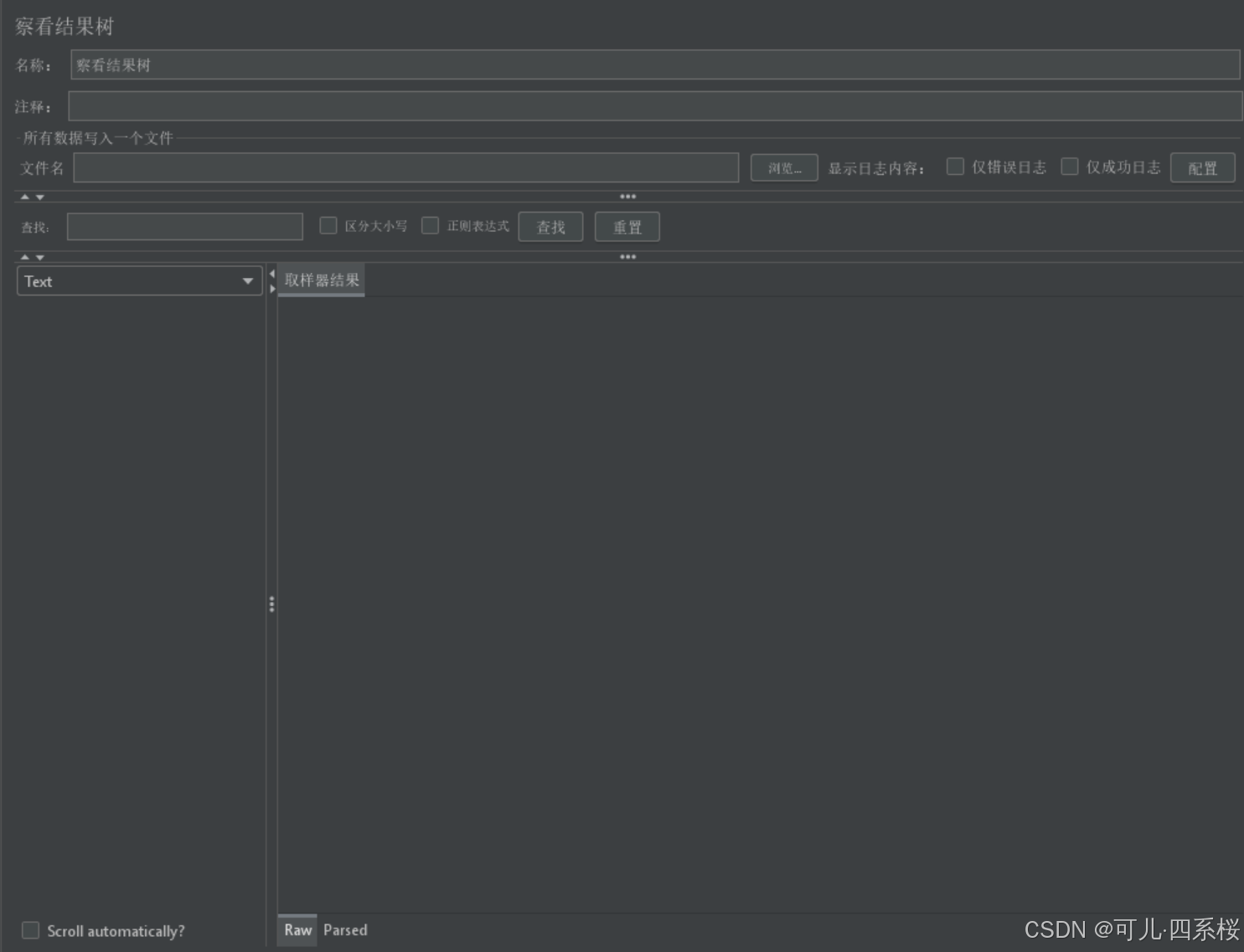
3.8.2.1 查看结果树(View Results Tree)
查看结果树(View Results Tree) 是 JMeter 中一个非常强大的监听器,主要用于调试和分析 HTTP 请求和响应的详细信息。它的主要作用包括以下几个方面:
1. 调试请求和响应
- 请求头:显示发送给服务器的请求头信息,帮助确认请求的格式和内容是否正确。
- 请求体:显示发送给服务器的请求体内容,对于 POST、PUT 等请求尤为重要,可以检查请求数据是否正确。
- 响应头:显示从服务器返回的响应头信息,帮助确认服务器的响应格式和状态。
- 响应体:显示从服务器返回的响应体内容,可以检查服务器返回的数据是否符合预期。
2. 验证响应状态
- 显示 HTTP 响应状态码(如 200、404 等),帮助确认请求是否成功。
- 显示 HTTP 响应状态消息(如 OK、Not Found 等),提供更详细的响应信息。
3. 性能分析
- 响应时间:
- Latency:从请求发送到接收到第一个字节的时间。
- Elapsed Time:从请求发送到接收到最后一个字节的总时间。
- 这些时间指标有助于分析请求的性能,识别性能瓶颈。
4. 故障排除
- 当请求失败时,查看结果树可以显示失败的原因,帮助快速定位问题。
- Failure Message:显示请求失败的具体原因,如超时、连接失败等。
5. 子请求分析
- 如果请求包含多个子请求(如嵌套的 HTTP 请求),可以查看每个子请求的详细信息,帮助分析复杂的请求链路。
6. 数据验证
- 可以查看响应数据的详细内容,验证服务器返回的数据是否符合预期。
- 对于 JSON、XML 等结构化数据,可以使用内置的解析器进行格式化显示,方便阅读和分析。
3.8.2.2 聚合报告(Aggregate Report)
聚合报告(Aggregate Report) 是 JMeter 中一个非常重要的监听器,用于汇总和分析性能测试结果。它提供了详细的性能统计数据,帮助测试人员快速了解测试的整体情况和性能表现。以下是聚合报告的各个字段含义:
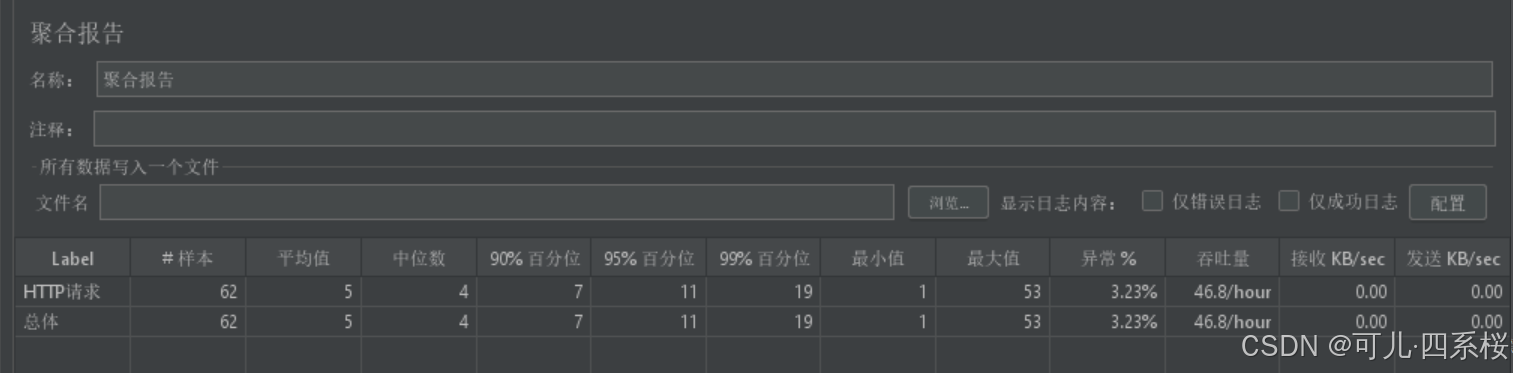
| 字段名称 | 含义 |
| Label (Label) | 请求的标签名称,通常是采样器的名称。 |
| 样本 (# Samples) | 执行该请求的总次数。 |
| 平均值 (Average) | 平均响应时间(单位:毫秒)。 |
| 中位数 (Median) | 中位数,表示响应时间的中间值。 |
| 90%百分位 (90% Line) | 90% 的请求的响应时间不超过这个值。 |
| 95%百分位 (95% Line) | 95% 的请求的响应时间不超过这个值。 |
| 99%百分位 (99% Line) | 99% 的请求的响应时间不超过这个值。 |
| 最小值 (Min) | 最小响应时间(单位:毫秒)。 |
| 最大值 (Max) | 最大响应时间(单位:毫秒)。 |
| 异常 % (Error %) | 错误请求的百分比。计算方法:(错误请求数 / 总请求数) * 100%。 |
| 吞吐量 (Throughput) | 吞吐量,表示每秒处理的请求数(单位:请求/秒)。 |
| 接收 KB/sec (Received KB/sec) | 接收到的数据量(单位:字节)。 |
| 发送 KB/sec (Sent KB/sec) | 发送的数据量(单位:字节)。 |
3.8.2.3 用表格察看结果(View Results in Table)
用表格查看结果(View Results in Table) 是 JMeter 中一个非常实用的监听器,用于以表格形式展示每个请求的详细信息。这种形式的展示方式使得测试结果更加直观和易于分析。以下是 V用表格查看结果(View Results in Table) 监听器的各个字段含义:
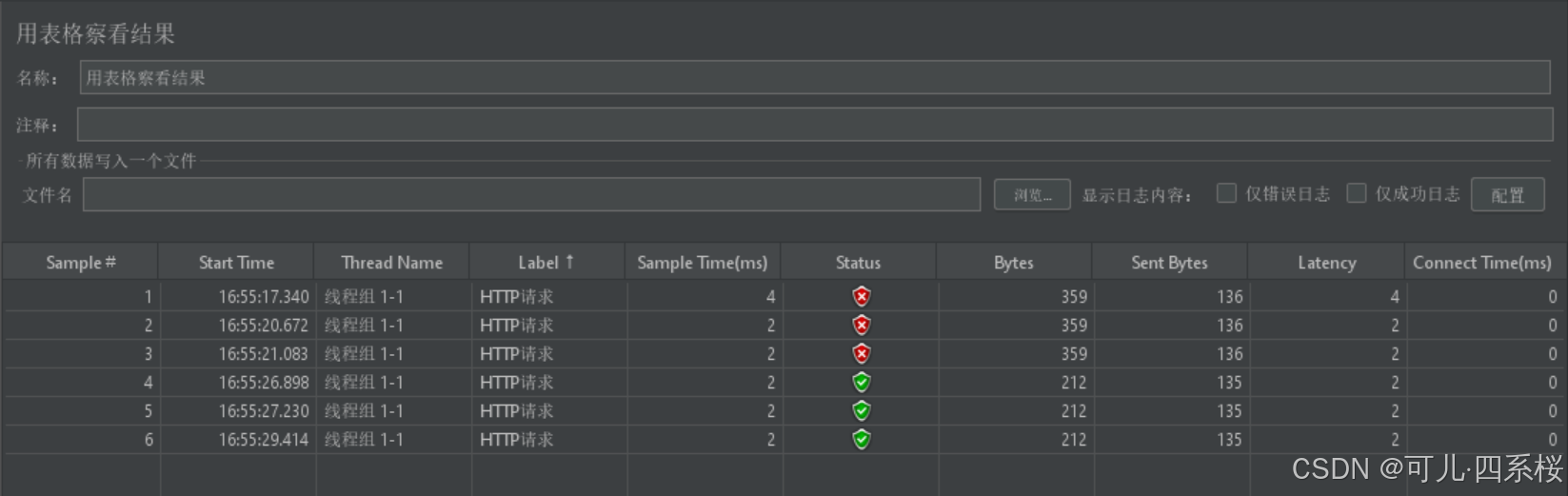
| 字段名称 | 含义 |
| Samples # | 该请求的样本数量。 |
| Start Time | 请求开始的时间戳。 |
| Thread Name | 执行该请求的线程名称。 |
| Label | 请求的标签名称,通常是采样器的名称。 |
| Sample Time(ms) | 请求的总响应时间(单位:毫秒)。 |
| Status | 请求是否成功。 |
| Bytes | 数据量(单位:字节)。 |
| Sent Bytes | 发送的数据量(单位:字节)。 |
| Latency | 从请求发送到接收到第一个字节的时间(单位:毫秒)。 |
| Connect Time(ms) | 建立连接的时间(单位:毫秒)。 |
3.9 开启日志(按需开启)
点击选项(Options)-> 勾选日志查看(Log Level) -> 选择所需的日志级别
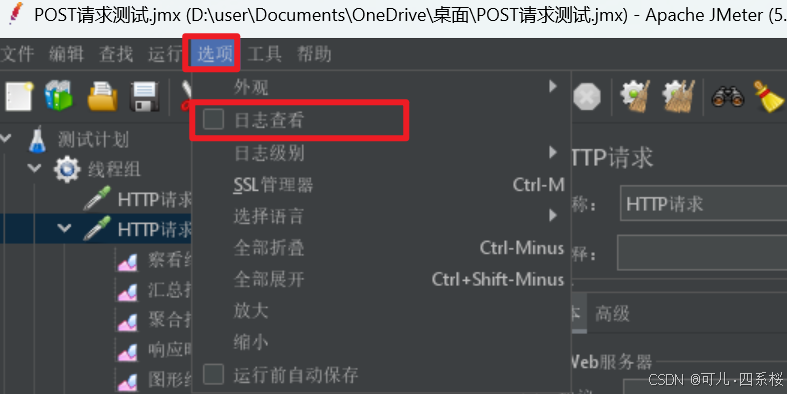
3.10 修改日志级别
点击选项(Options)-> 日志级别(Log Viewer)
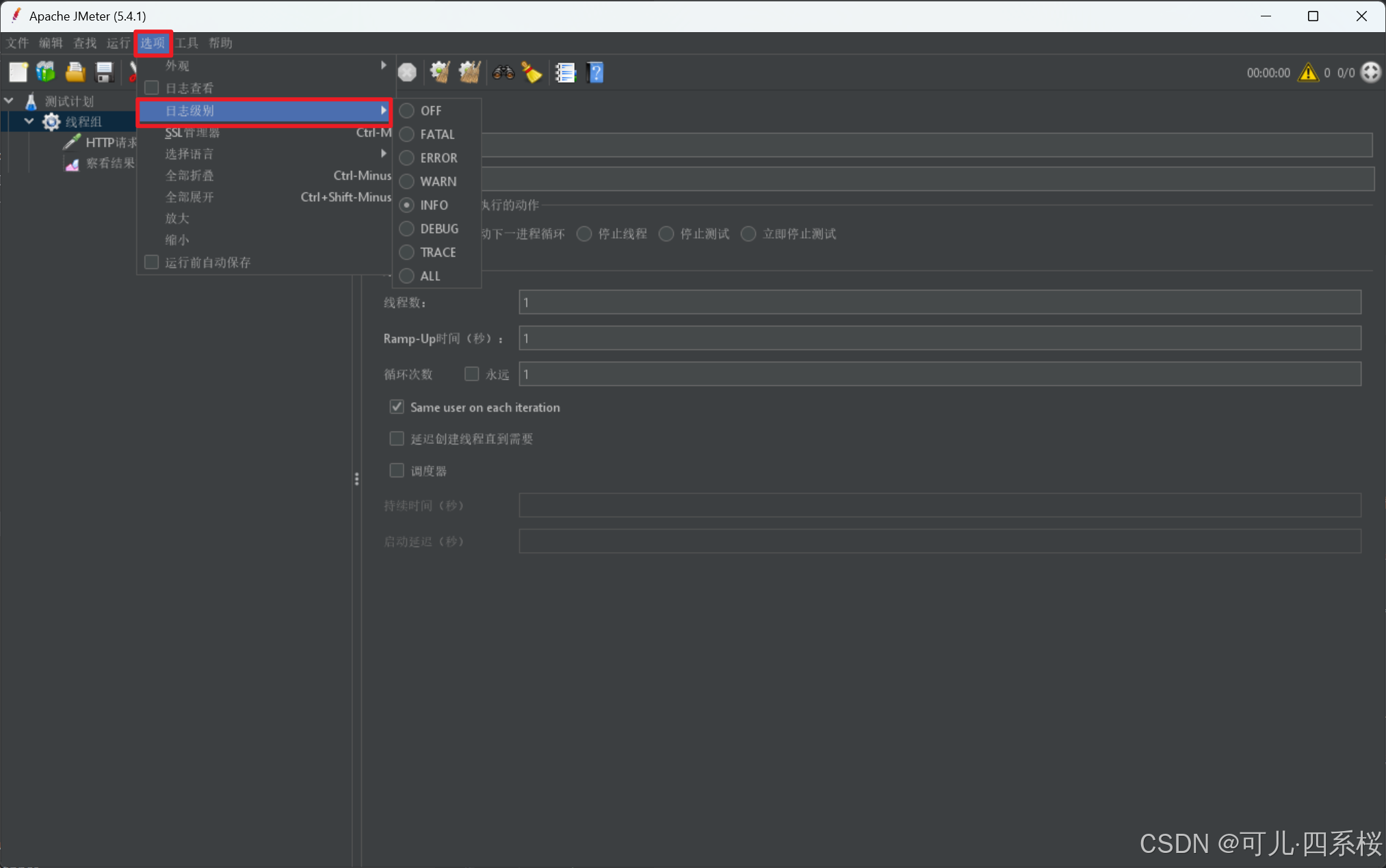
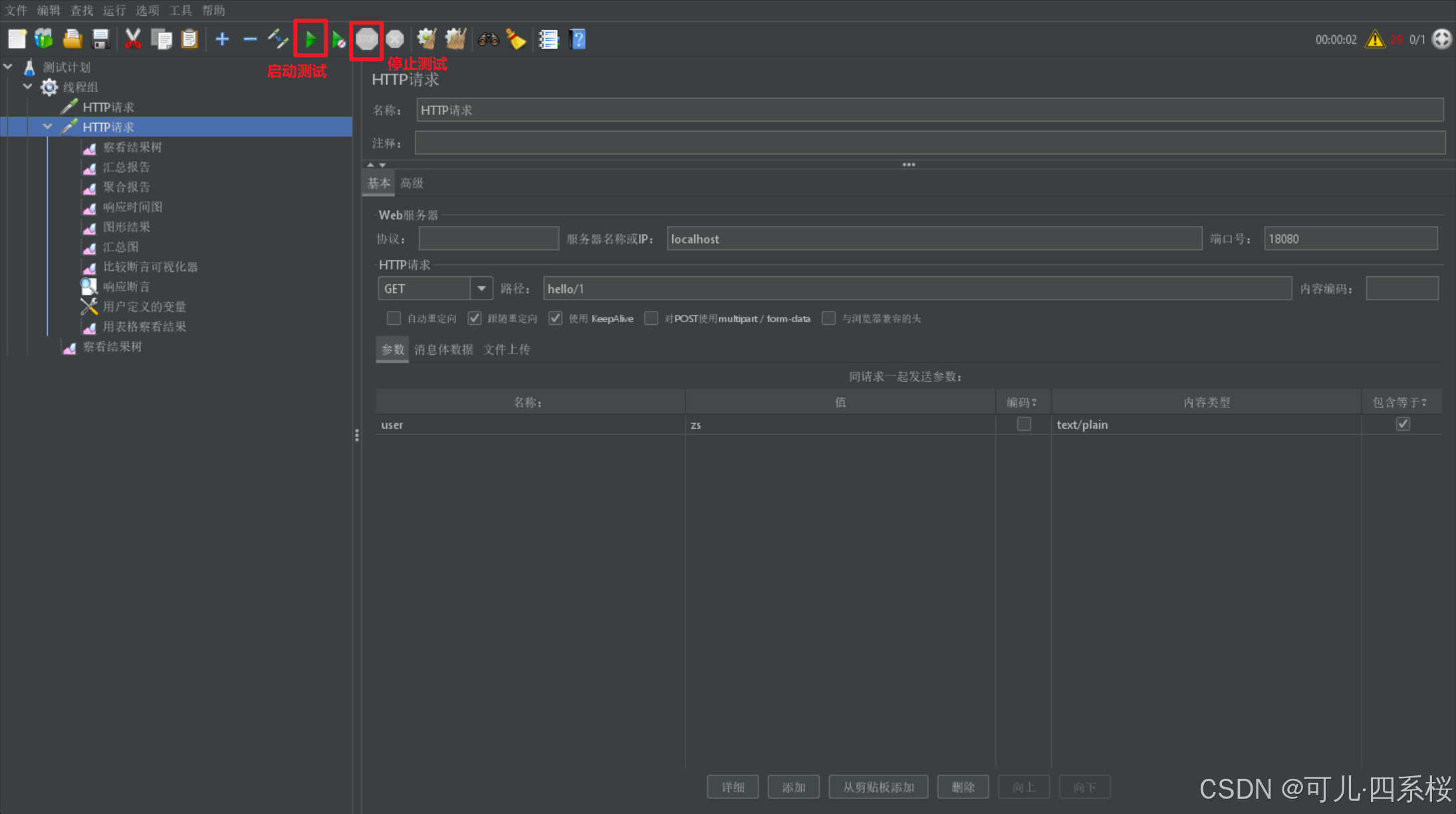
3.11 启动/停止测试
如下图所示:
4. 能力提升
4.1 用户定义的变量
4.1.1 监听器添加步骤
1. 中文版:右击测试计划/线程组/HTTP请求 -> 添加 -> 配置元件 -> 用户定义的变量
英文版:右击Test Plan/Thread Group/HTTP Request -> Add -> Config Element -> User Defined Variables
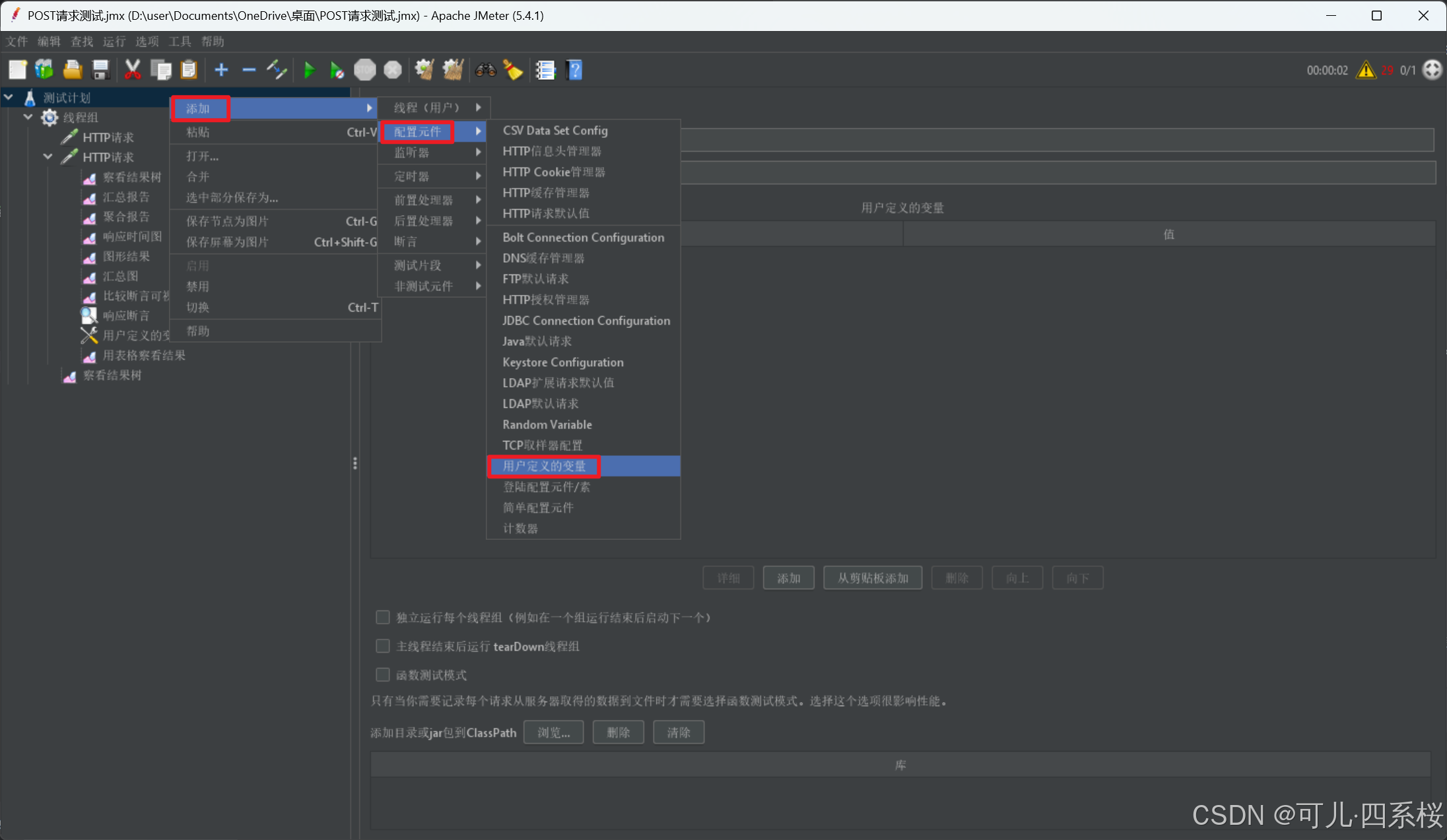
2. 编辑用户定义的变量
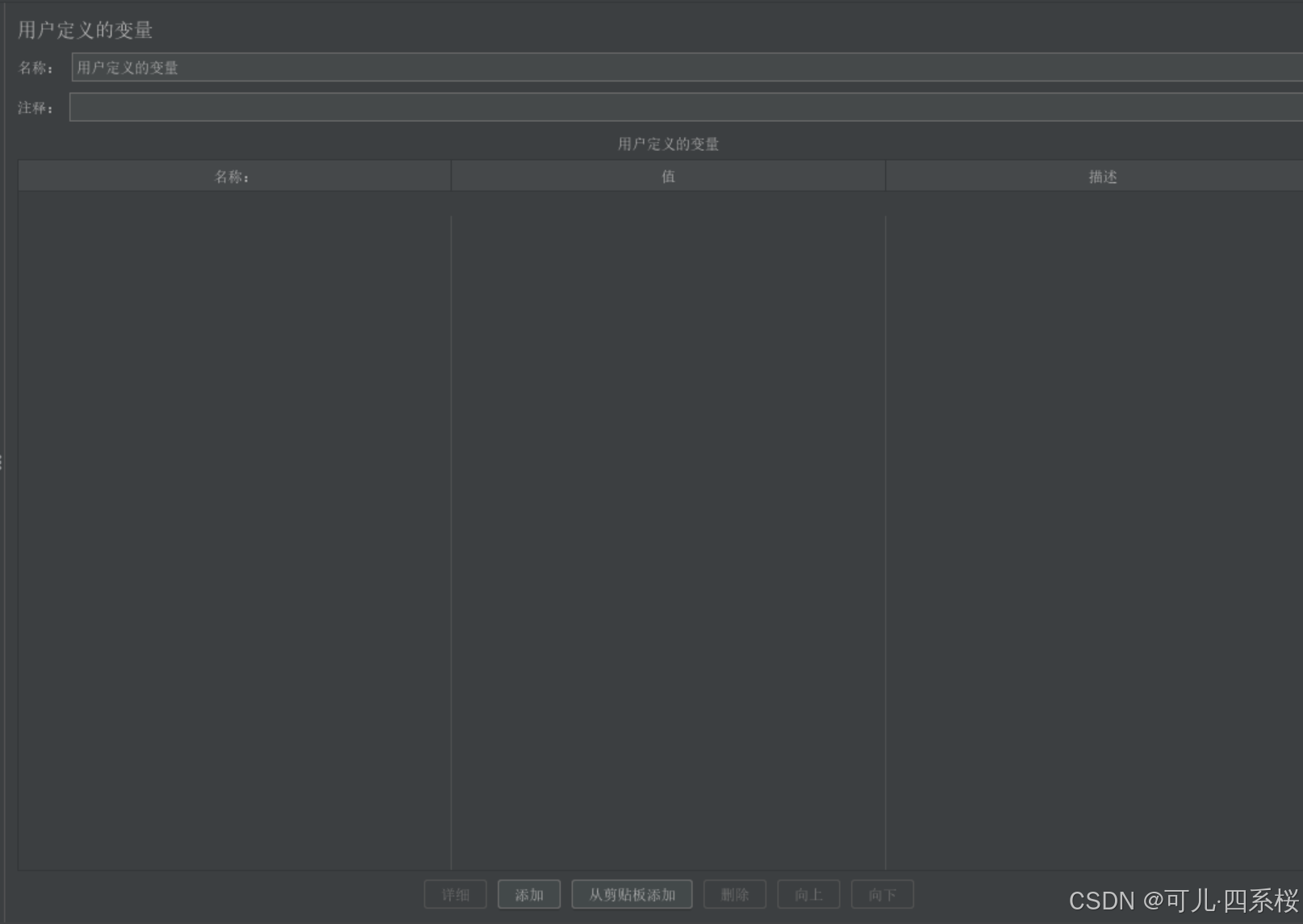
4.1.2 引用变量
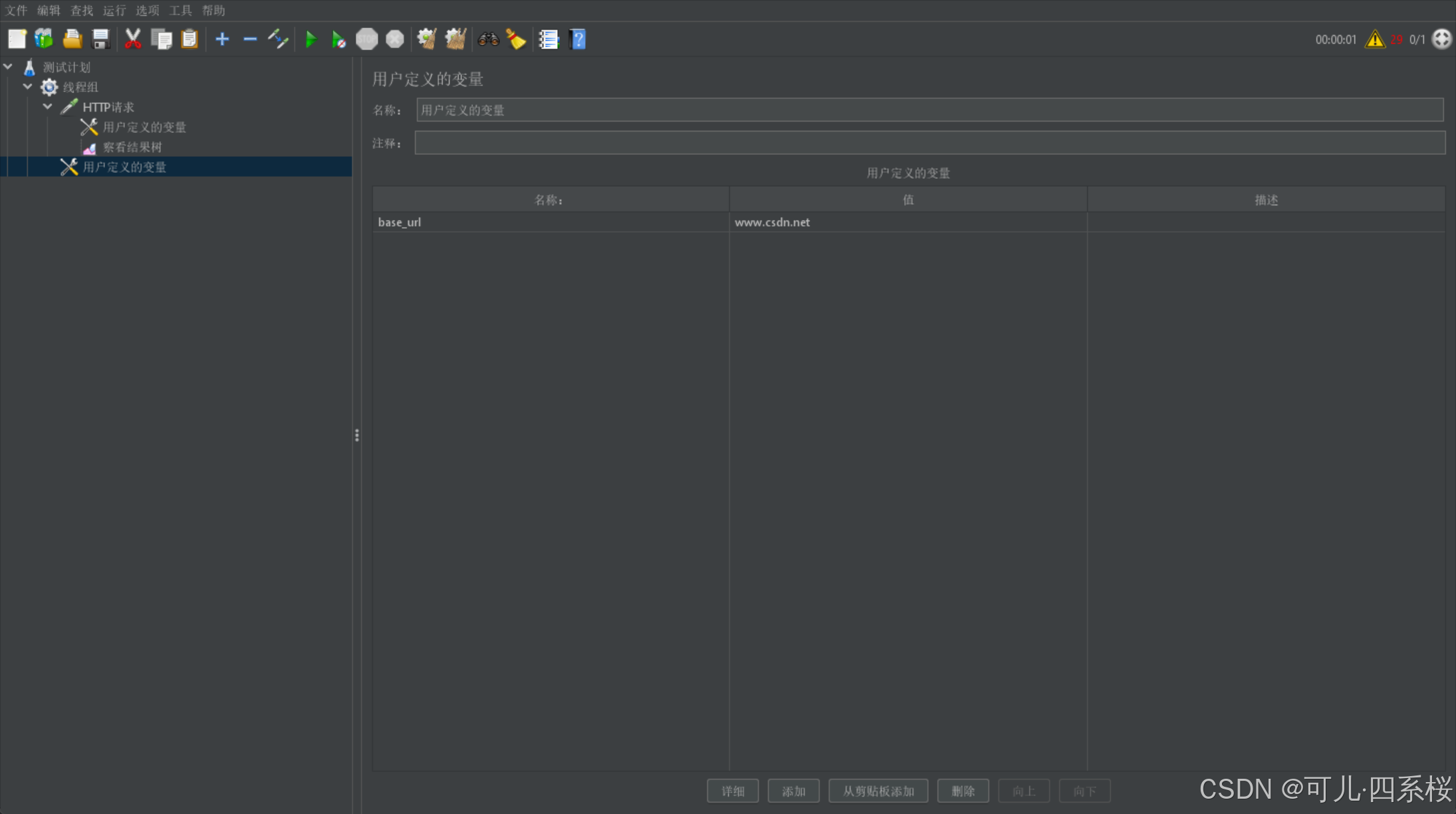
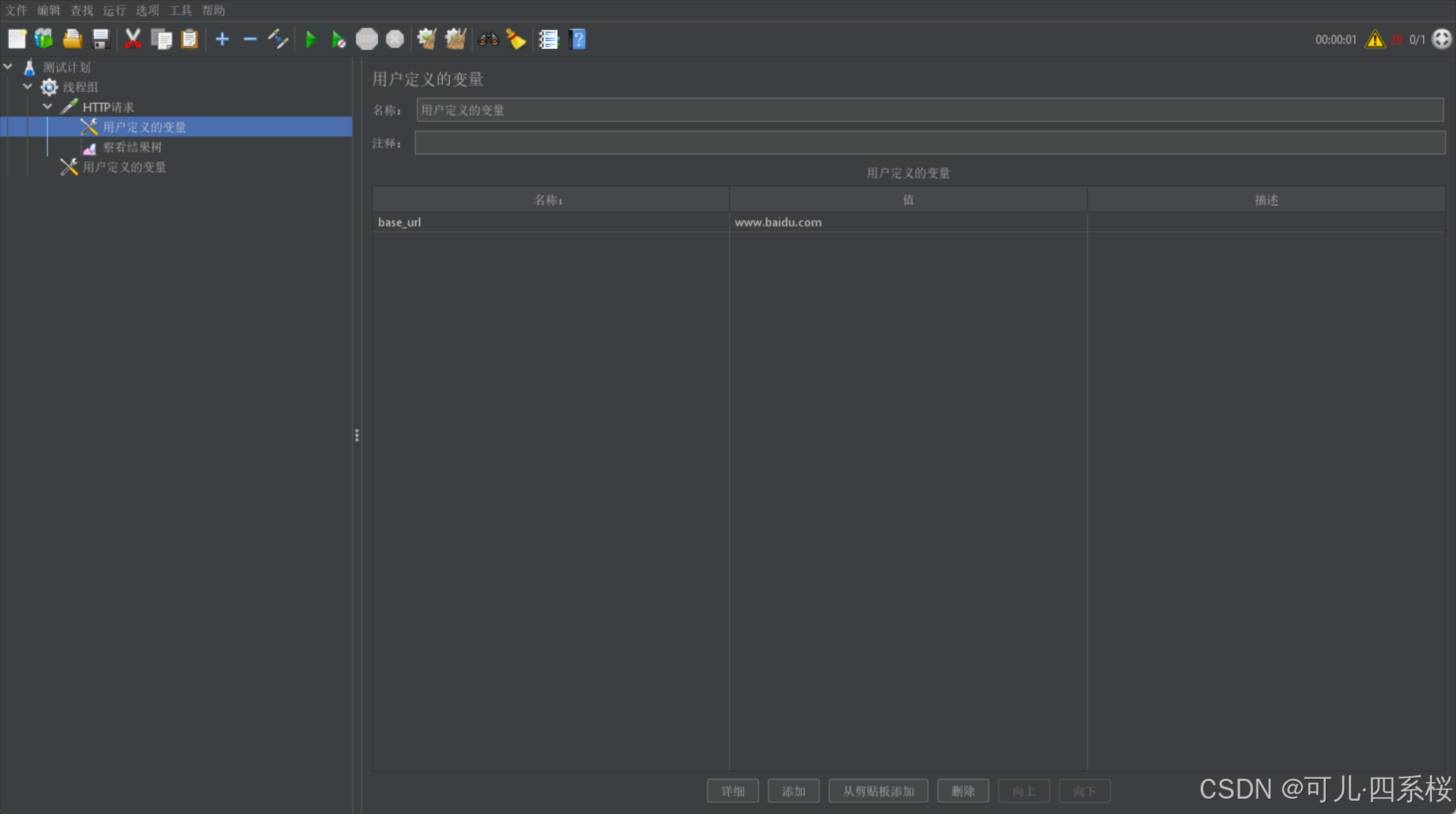
在测试脚本中,使用 ${变量名} 的语法来引用定义的变量。例如,如果定义了一个变量 base_url,其值为 www.baidu.com,则可以在 HTTP 请求中使用 ${base_url} 来引用这个变量。以请求头引用为例:
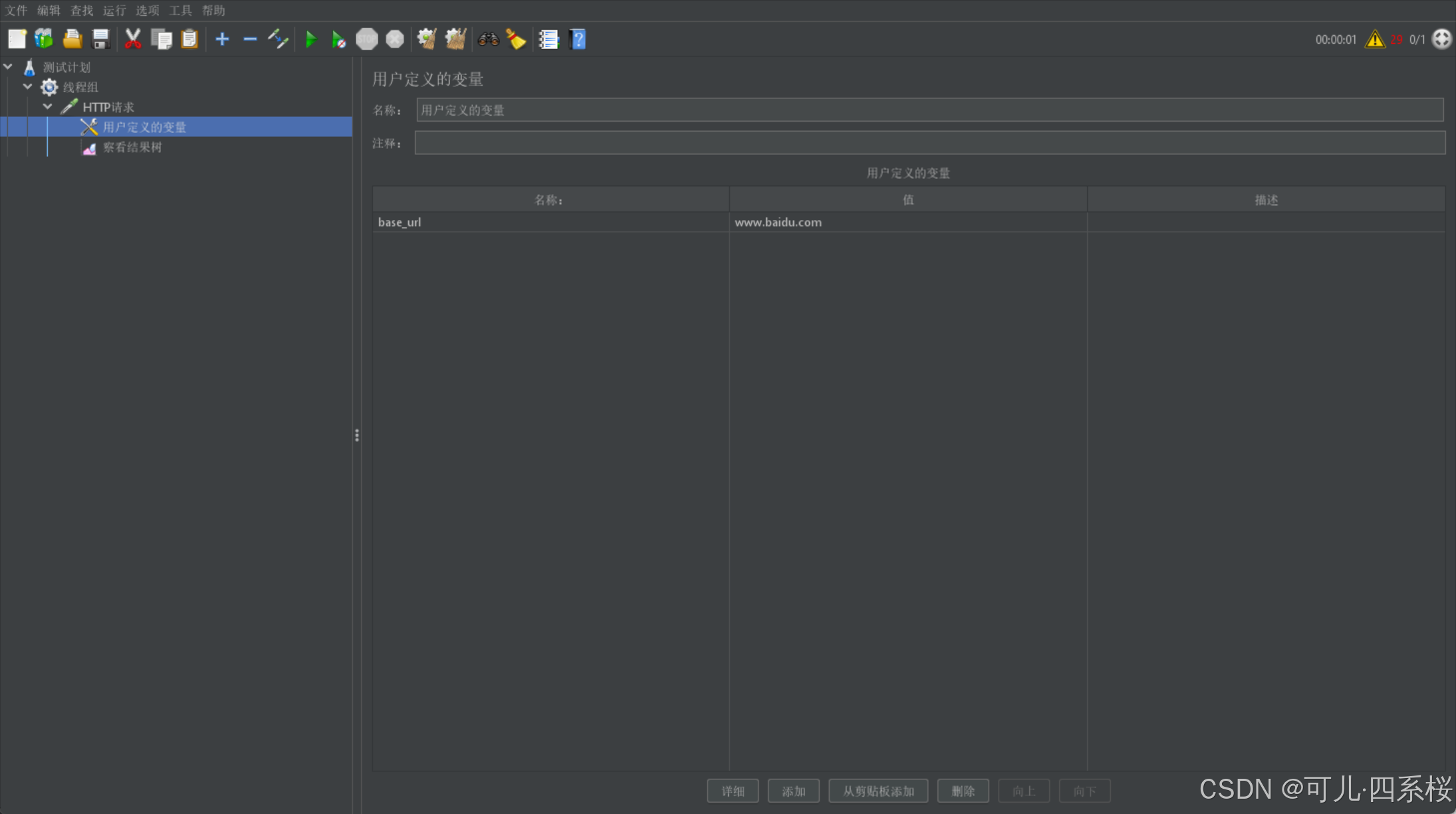
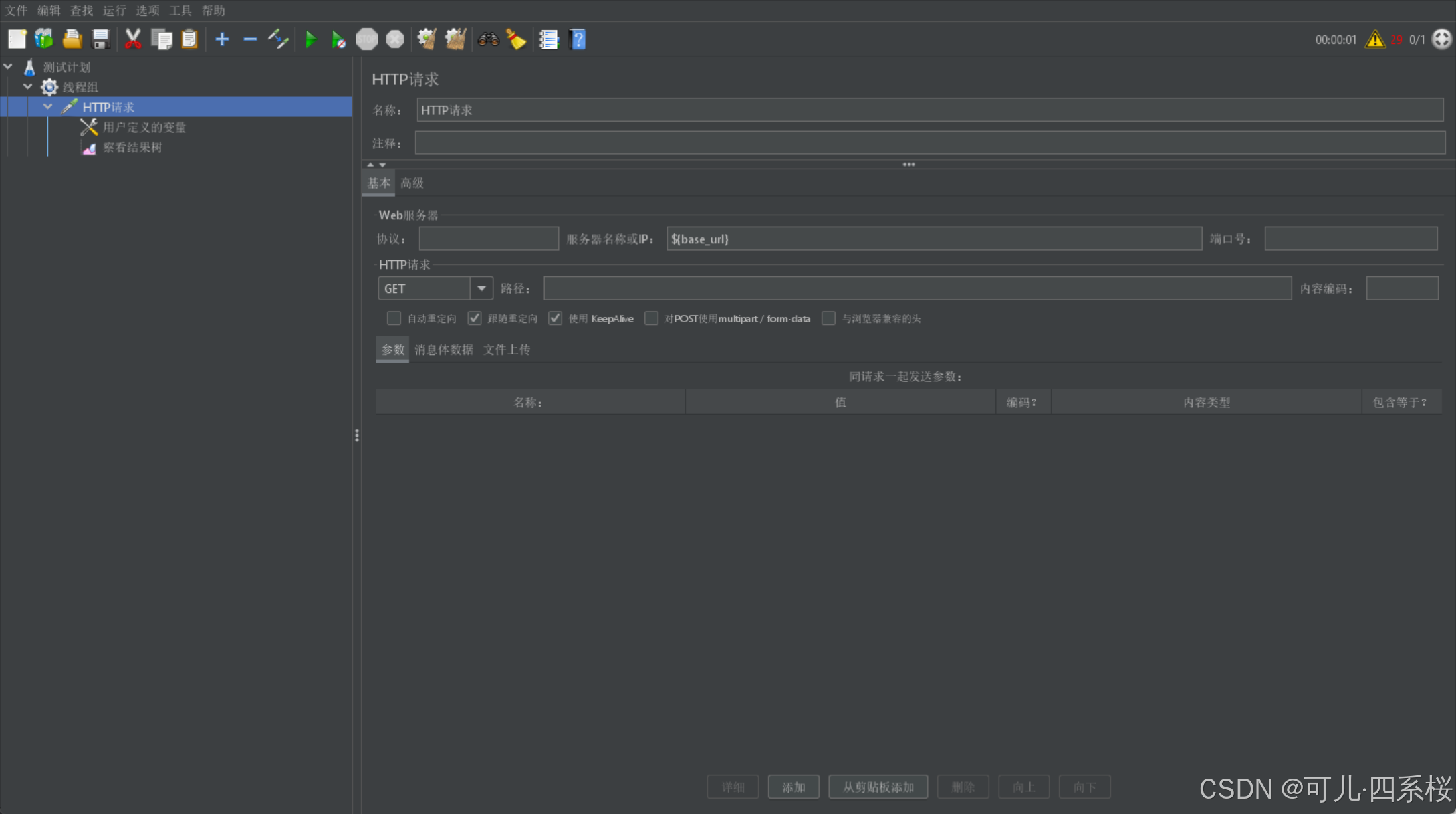
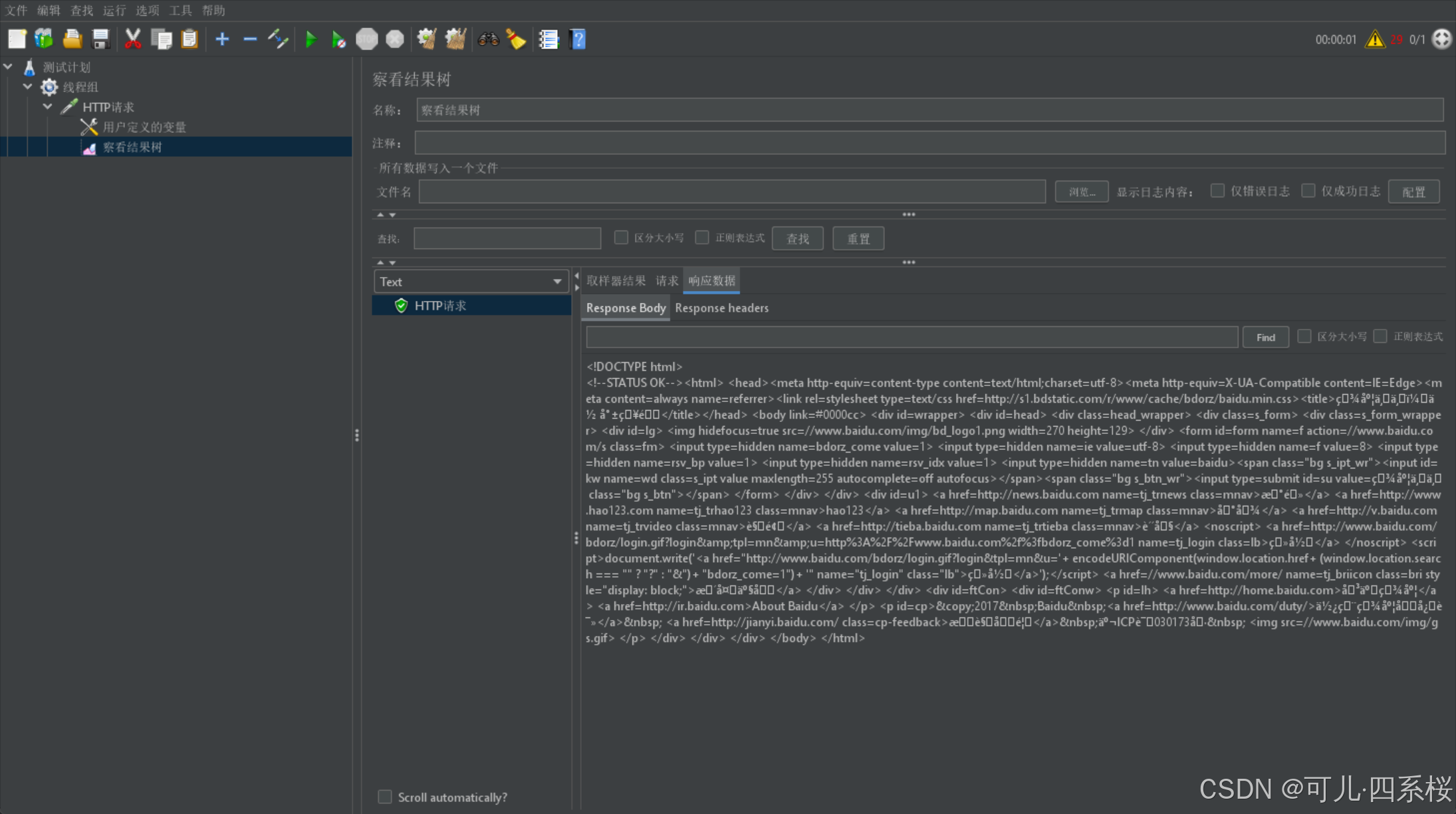
注意:
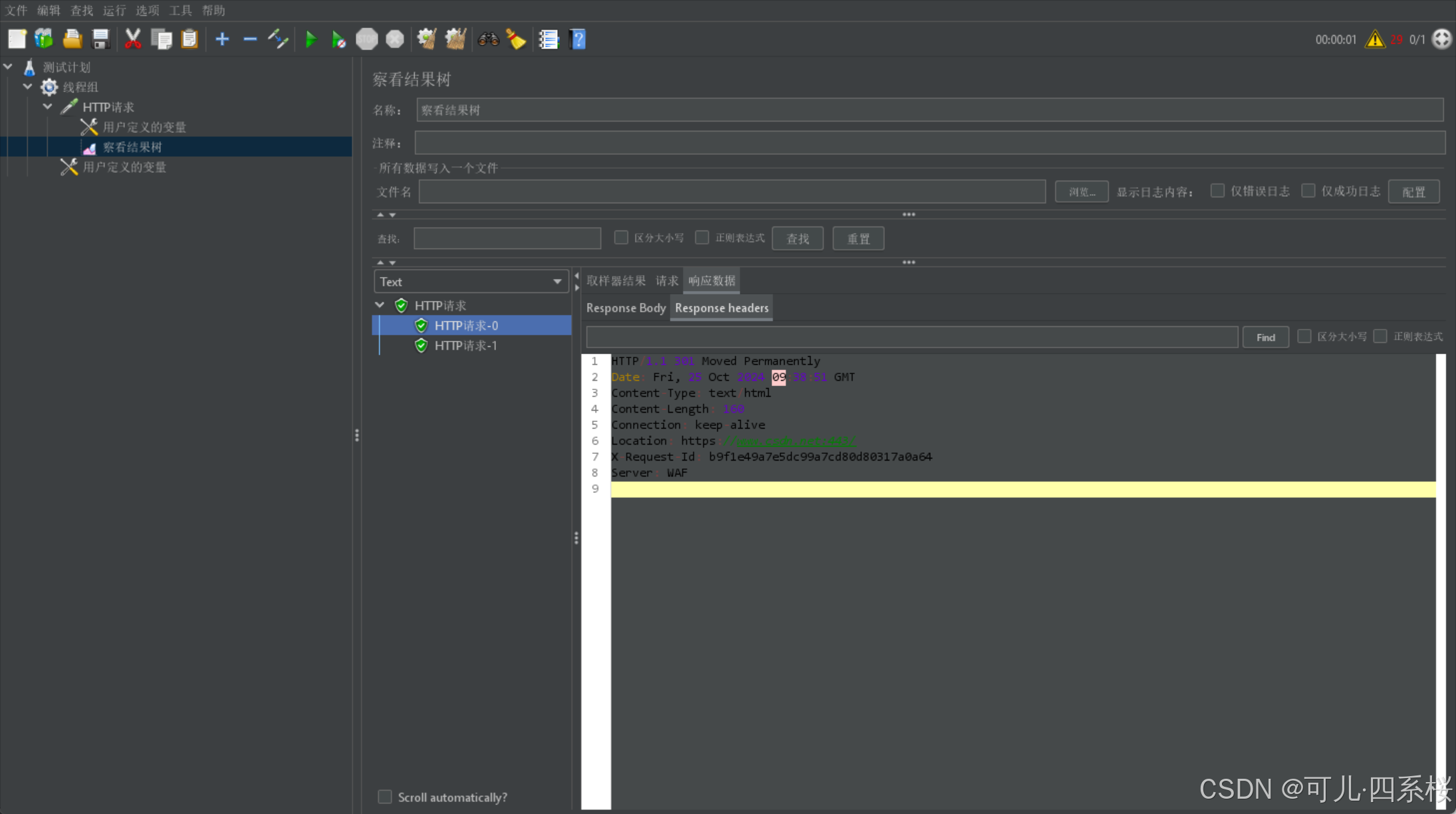
配置多个相同名称的用户变量,则它会同时发多个请求。
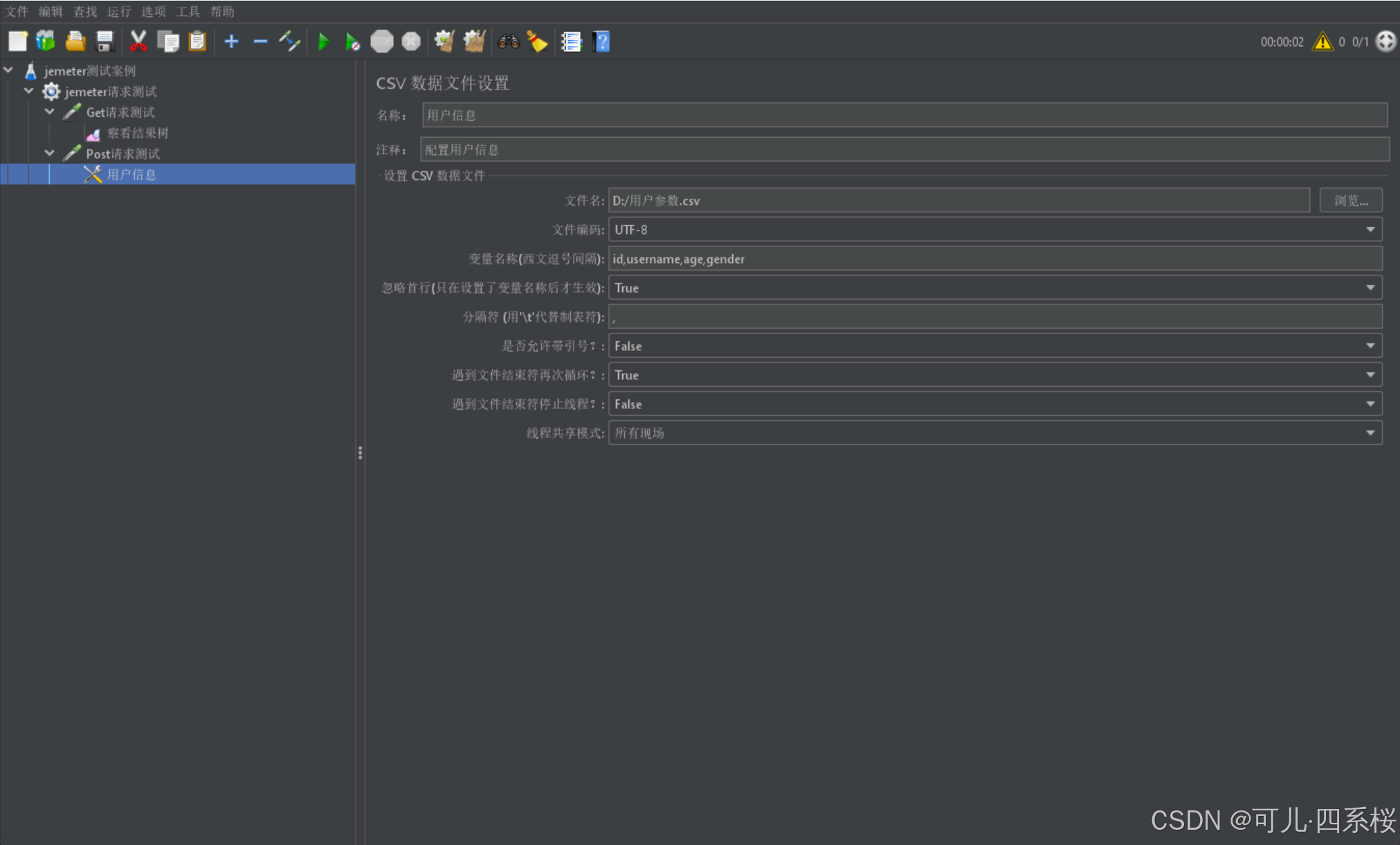
4.2 CSV 数据文件设置
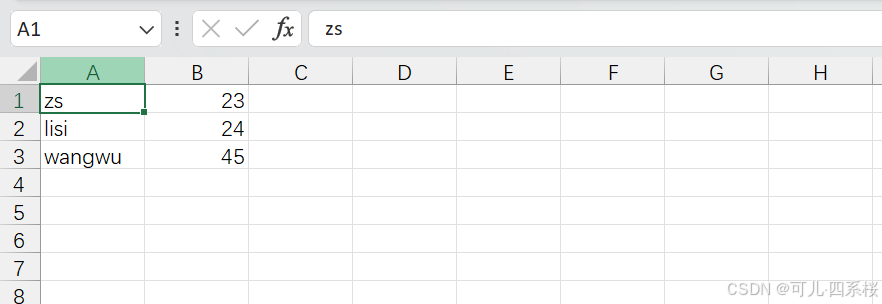
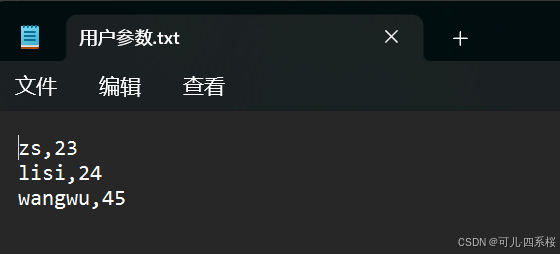
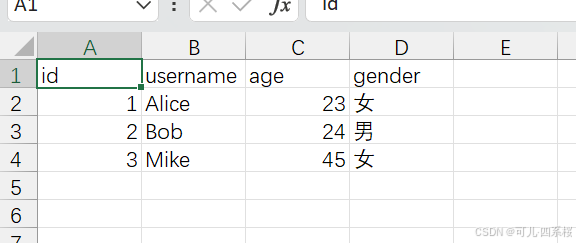
例如,创建一个用户参数.csv的文件,内容如下:
 4.2.1 CSV 数据文件设置添加步骤
4.2.1 CSV 数据文件设置添加步骤
1. 中文版:右击测试计划/线程组/HTTP请求 -> 添加 -> 配置元件 -> CSV Data Set Config
英文版:右击Test Plan/Thread Group/HTTP Request -> Add -> Config Element -> CSV Data Set Config
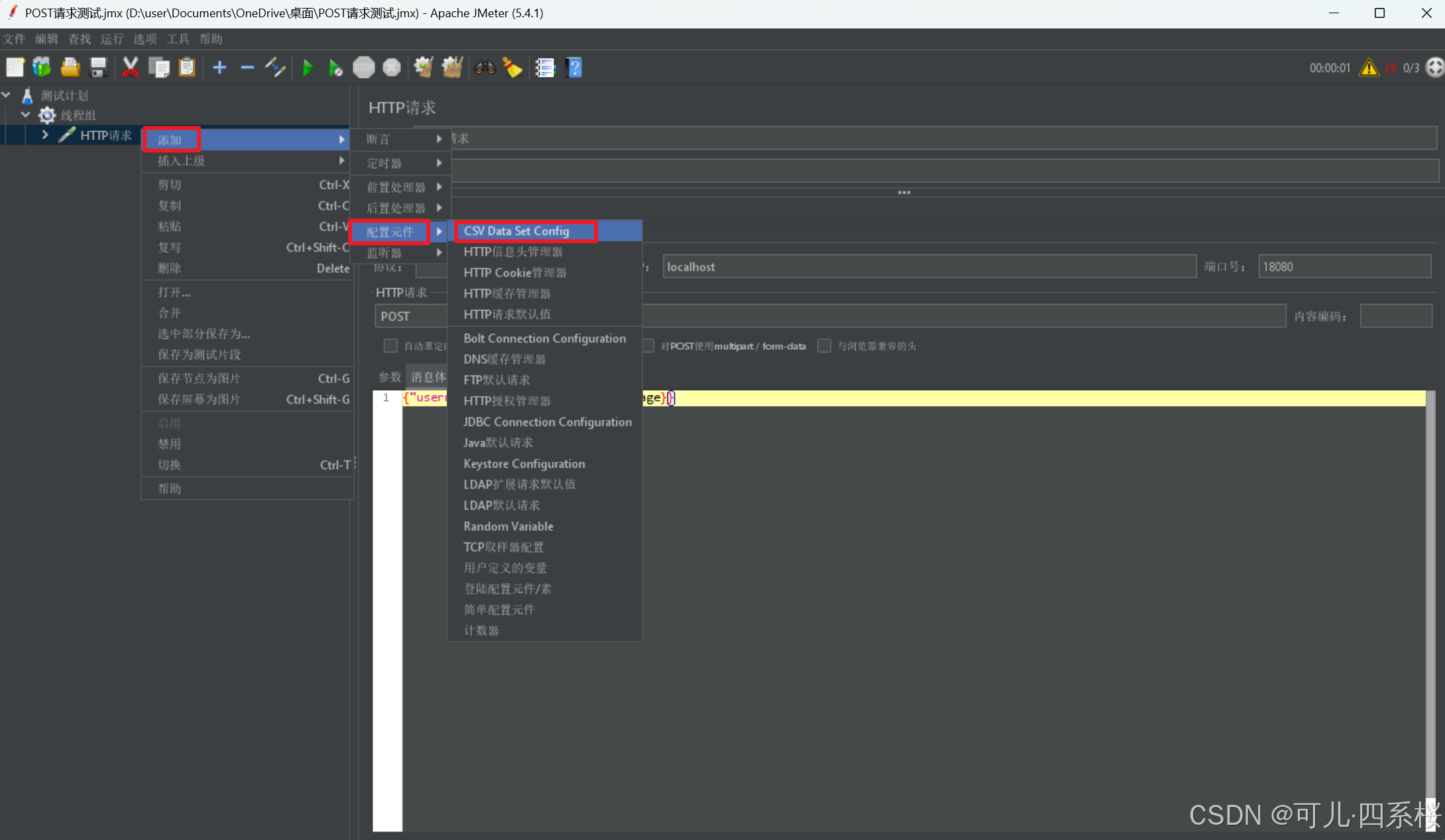
2. 编辑CSV 数据文件设置内容

4.2.2 使用参数
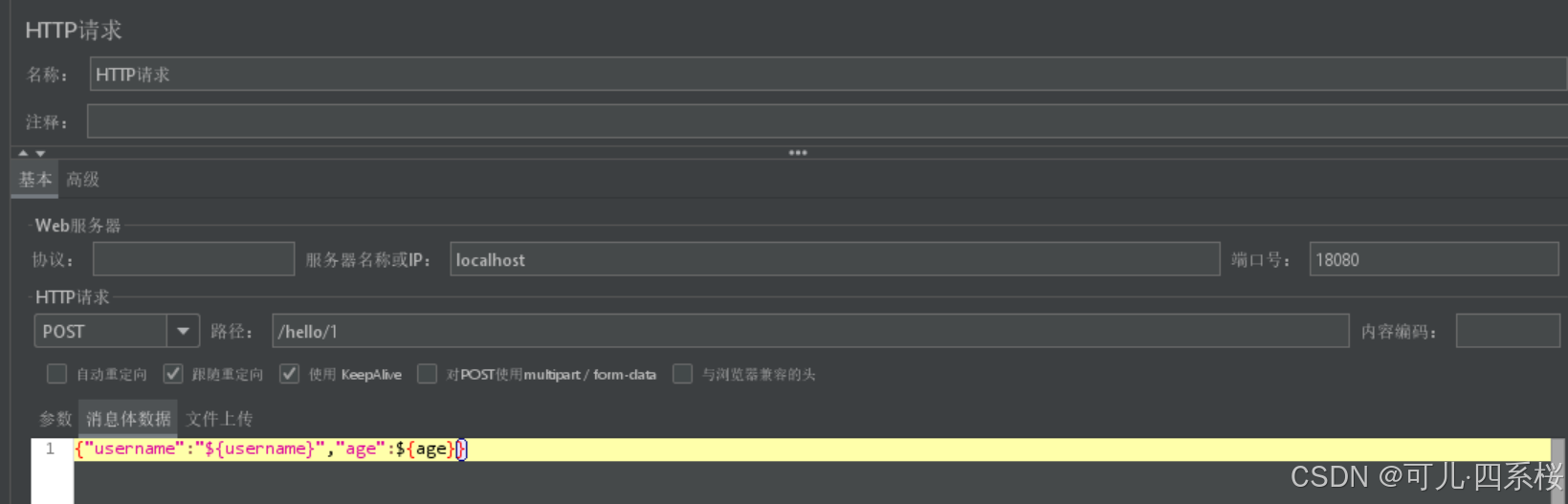
以POST http://localhost:18080/hello/1 http/1.1请求为例,给请求体动态赋值,如下图所示:
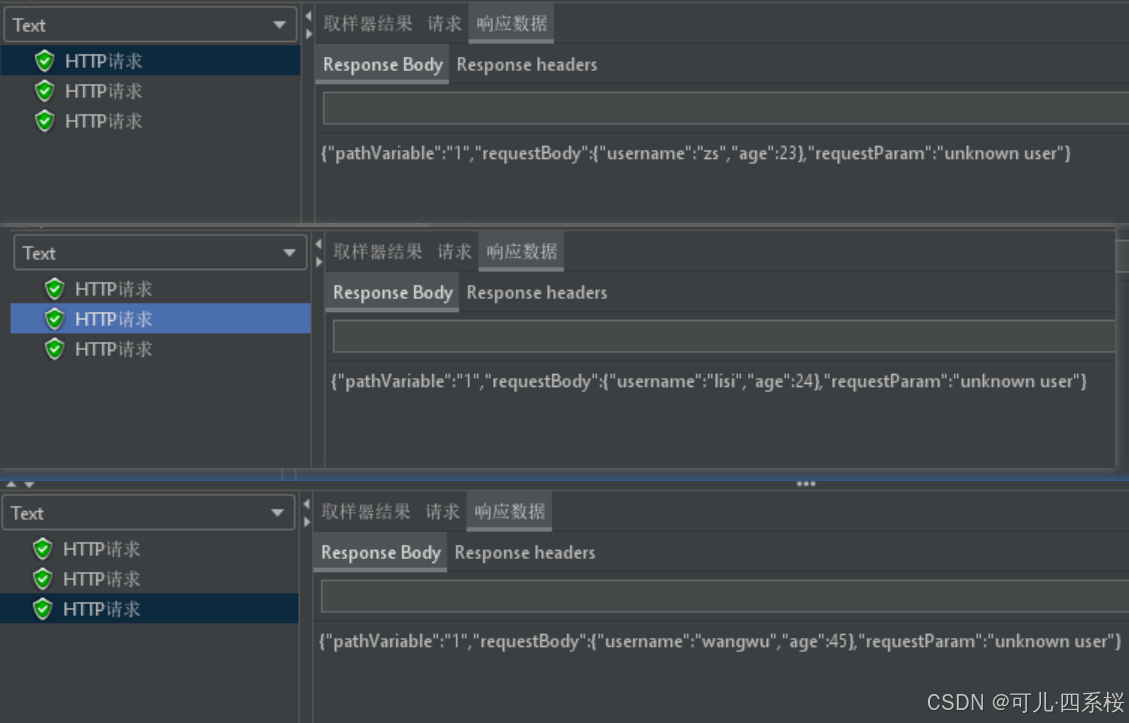
 循环三次,会发现请求结果不相同:
循环三次,会发现请求结果不相同:
注意:
文件可以换成txt文件,分隔方式按配置的分隔方式分隔即可,如下图所示:
4.3 后置处理器(Post Processors)
JMeter 的后置处理器主要用于从服务器响应中提取数据,并将这些数据存储为变量,供后续的请求或断言使用。常见的后置处理器包括 Json 提取器、正则表达式提取器和边界提取器。添加后置处理器流程如下:
1. 添加后置处理器:
中文版:右击测试计划/线程组/HTTP请求 -> 添加 -> 后置处理器 -> 选择所需的后置处理器
英文版:右击Test Plan/Thread Group/HTTP Request -> Add -> Post Processors -> 选择所需的后置处理器
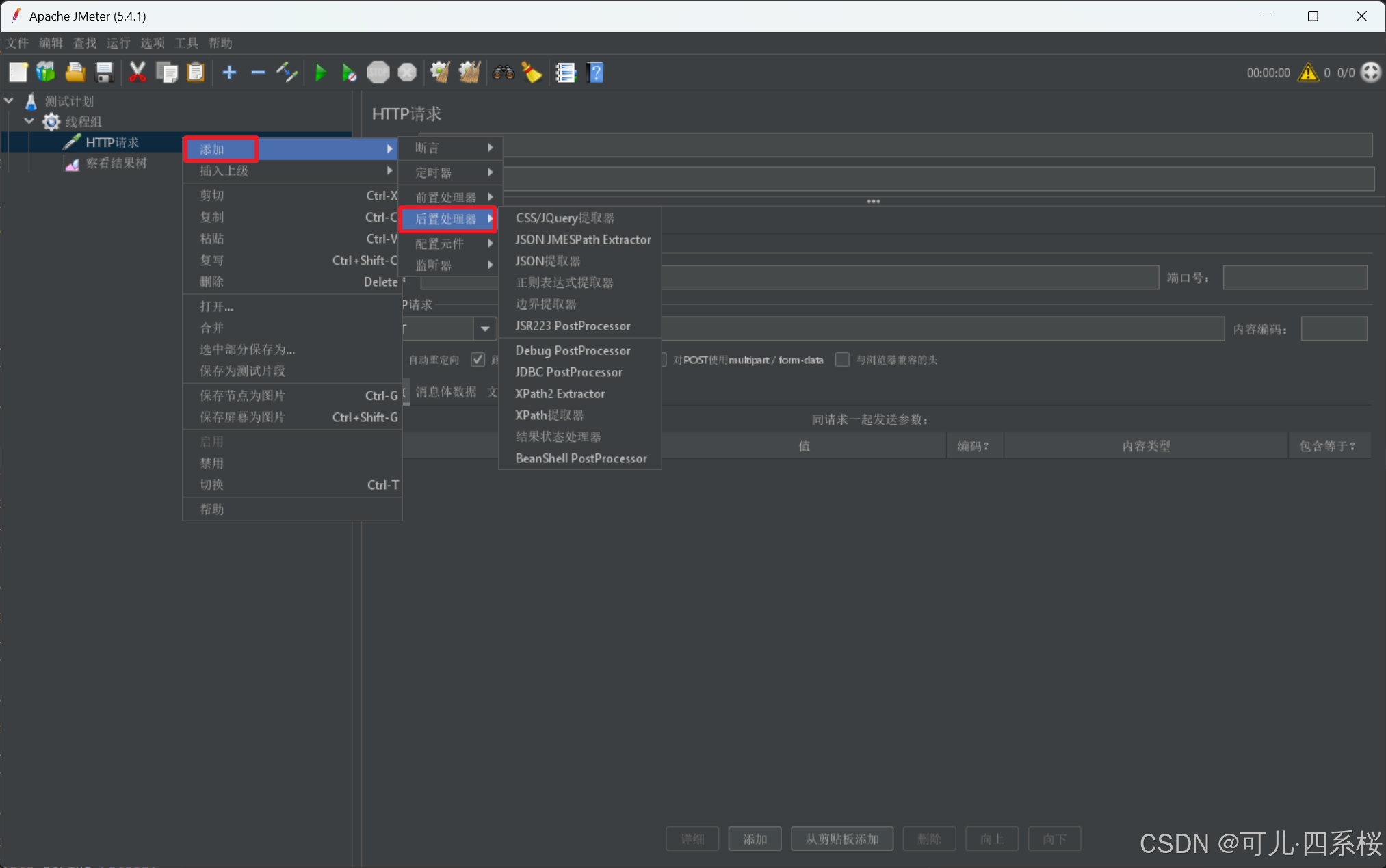
2. 配置后置处理器
具体配置详见后续讲解。其中,对公共配置Apply to 选项进行说明:
| 选项 | 说明 | 作用范围 |
| Main sample and sub-samples | 同时应用于主采样器和子采样器。主采样器通常是发送HTTP请求的那个采样器,子采样器是由主采样器生成的嵌套请求或响应。 | 主采样器的响应数据和所有子采样器的响应数据。 |
| Main sample only | 仅应用于主采样器。主采样器通常是发送HTTP请求的那个采样器。 | 仅主采样器的响应数据。 |
| Sub-samples only | 仅应用于子采样器。子采样器通常是由主采样器生成的嵌套请求或响应。 | 仅所有子采样器的响应数据。 |
| JMeter Variable Name to use | 应用于指定的JMeter变量。你需要在变量名称框中输入变量名,表达式将应用于该变量的值。 | 指定的JMeter变量的值。 |
主采样器 (Main Sample):主采样器是直接由用户创建并执行的采样器。它通常是发送HTTP请求、FTP请求、数据库查询等操作的采样器。主采样器负责发起请求并接收响应。例如:一个HTTP请求采样器就是一个主采样器。它发送HTTP请求并接收HTTP响应。
子采样器 (Sub-Sample):子采样器是由主采样器生成的嵌套请求或响应。子采样器通常是在主采样器执行过程中产生的额外请求或响应。子采样器可以是嵌套的HTTP请求、嵌套的HTTP响应、重定向请求等。例如:当一个HTTP请求采样器发送一个请求并接收到一个包含多个嵌套资源(如图片、CSS文件、JavaScript文件)的HTML页面时,这些嵌套资源的请求和响应就是子采样器。重定向请求也是一个常见的子采样器示例。当服务器返回一个重定向响应(如302状态码)时,JMeter会自动发送一个新的请求来处理重定向,这个新的请求就是子采样器。
3. 引用变量
在测试脚本中,使用 ${变量名} 的语法来引用定义的变量。例如,如果定义了一个变量 city_name,则可以在 HTTP 请求中使用 ${city_name} 来引用这个变量。 以请求头引用为例:
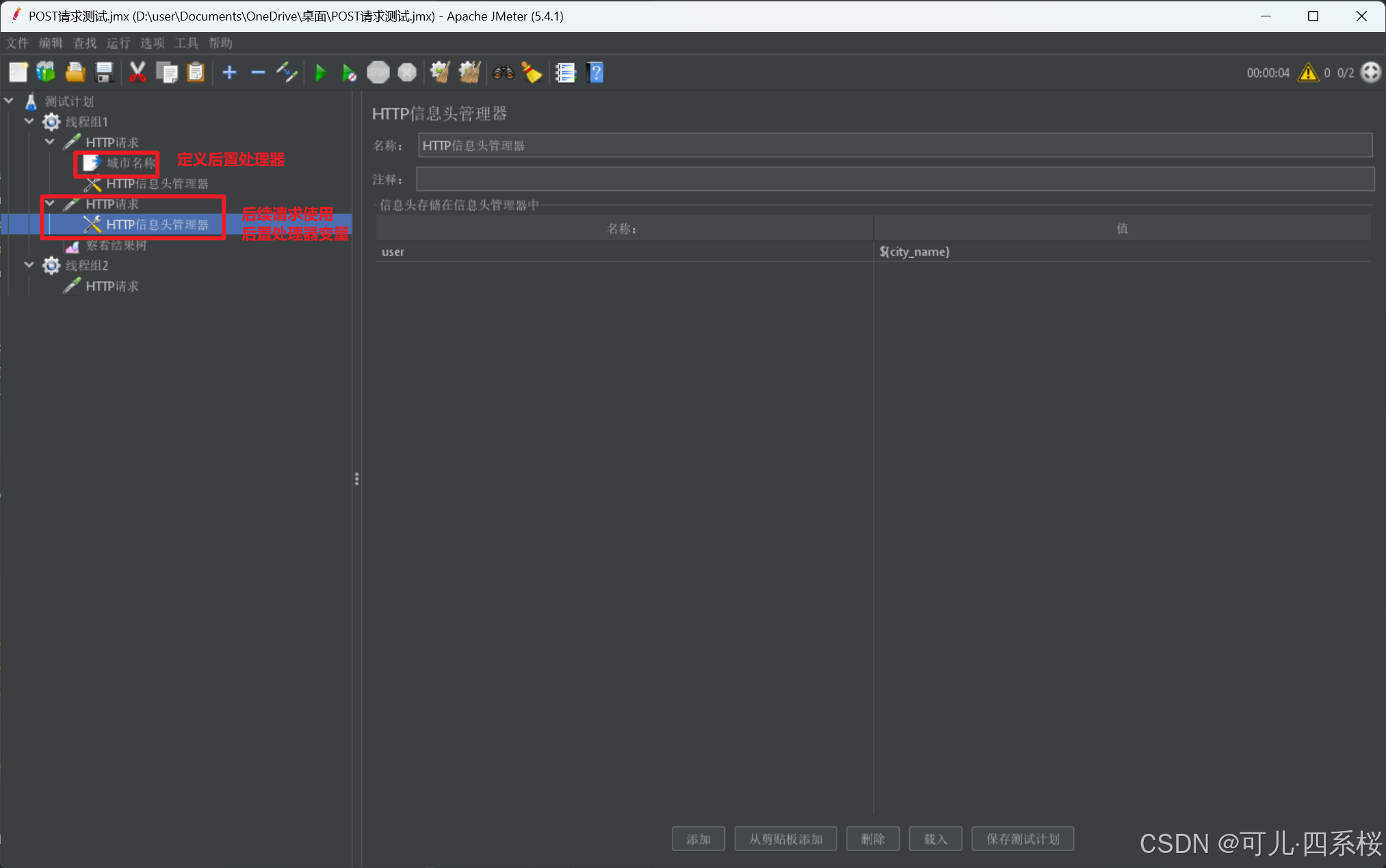
4.3.1 Json 提取器(JSON Extractor)
4.3.1.1 JSONPath表达式
JsonPath 表达式可用于解析 JSON 结构的数据。
官方 API 文档:GitHub - json-path/JsonPath: Java JsonPath implementation
本章节摘录自中文文档。
4.3.1.1.1 基础运算符
JsonPath 的根元素总是被称为 $,无论它是一个对象还是数组。
在 JsonPath 表达式中,可以使用点符号,例如:$.store.book[0].title;也可以使用方括号,例如:$['store']['book'][0]['title']。
| 运算符 | 描述 |
|---|---|
| $ | 根元素 |
| . 或 [] | 获取子元素 如:store.book 或 store["book"] |
| .. | 后代选择器,用来选取所有符合条件的元素 |
| [,] | 合并操作符,用于选取若干个元素 如:book[0,1] 或 $..book[0].["category","author"] |
| [start:end] | 切片运算符,索引的起始值为 0 ,左闭右开 如:book[0:2] 或 book[-2:0] |
| ?() | 过滤器标识,用于筛选数组,可以将过滤条件写在括号中 |
| @ | 表示当前正在被过滤器处理的元素,通常和过滤器配合使用 如:book[?(@.price<10)] |
| * | 通配符。可以用于通配元素的名称或索引 如:book.* 或 book[*] 也可以和过滤结合使用,作为正则表达式的元素 如:book[?(@.author =~ /.*ees/)] |
4.3.1.1.2 过滤运算符
过滤器是用于筛选数组的逻辑表达式,一个典型的过滤器是[?(@.age > 18)] ,其中,@ 表示当前正被过滤器处理的元素。通过加入逻辑运算符 && 和 || ,可以创造出更复杂的过滤器。字符串的值必须使用单引号或双引号括起来,如 ([?(@.color == 'blue')] 或[?(@.color == "blue")])。
| 运算符 | 描述 |
|---|---|
| == | 左右相等 注:会对比数据类型,如 1 和 '1' 不相等 |
| != | 左右不相等 |
| < | 左侧小于右侧 |
| <= | 左侧小于或等于右侧 |
| > | 左侧大于右侧 |
| >= | 左侧大于或等于右侧 |
| =~ | 左侧符合右侧的正则表达式 如:[?(@.name =~ /foo.*?/i)] |
| in | 左侧存在于右侧 如:[?(@.size in ['S', 'M'])] |
| nin | 左侧不存在于右侧 |
| subsetof | 左侧是右侧的子集 如:[?(@.sizes subsetof ['S', 'M', 'L'])] |
| anyof | 左侧和右侧有交集 如:[?(@.sizes anyof ['M', 'L'])] |
| noneof | 左侧和右侧没有交集 如:[?(@.sizes noneof ['M', 'L'])] |
| size | 左侧和右侧(数字/字符串)一样大 |
| empty | 左侧(数字/字符串)为空 |
4.3.1.1.3 函数
可以在路径的末端调用函数。
| 函数 | 描述 | 输出类型 |
|---|---|---|
| min() | 对于一个数值型数组,找到最小值 | 双精度 |
| max() | 对于一个数值型数组,找到最大值 | 双精度 |
| avg() | 对于一个数值型数组,求平均值 | 双精度 |
| stddev() | 对于一个数值型数组,求标准差 | 双精度 |
| length() | 求数组的长度 | 整型 |
| sum() | 对于一个数值型数组,求总和 | 双精度 |
示例:
假设有这样一个 JSON 结构:
{
"store": {
"book": [
{
"category": "reference",
"author": "Nigel Rees",
"title": "Sayings of the Century",
"price": 8.95
},
{
"category": "fiction",
"author": "Evelyn Waugh",
"title": "Sword of Honour",
"price": 12.99
},
{
"category": "fiction",
"author": "Herman Melville",
"title": "Moby Dick",
"isbn": "0-553-21311-3",
"price": 8.99
},
{
"category": "fiction",
"author": "J. R. R. Tolkien",
"title": "The Lord of the Rings",
"isbn": "0-395-19395-8",
"price": 22.99
}
],
"bicycle": {
"color": "red",
"price": 19.95
}
},
"expensive": 10
}| JsonPath 表达式 | 结果 |
|---|---|
| $.store.book[*].author | 找到 store 元素下的所有书籍,输出他们的作者 |
| $..author | 根元素下所有的作者 |
| $.store.* | store 元素下所有的东西,无论是书籍还是自行车 |
| $.store..price | store 元素下的所有东西的价格 |
| $..book[2] | 第 3 本书 |
| $..book[-2] | 倒数第 2 本书 |
| $..book[0,1] $..book[:2] | 前2本书 |
| $..book[:2] | 前2本书(注意:第一本书的索引是0) |
| $..book[1:2] | 第2本书 |
| $..book[-2:] | 最后第2本和最后第1本书 |
| $..book[2:] | 第3到最后1本书 |
| $..book[?(@.isbn)] | 所有书籍中,含有 isbn 属性的书籍 |
| $.store.book[?(@.price < 10)] | 所有书籍中,价格低于10的书籍 |
| $..book[?(@.price <= $['expensive'])] | 所有数据中,价格没有超过 expensive 的书籍( expansive 的值为10) |
| $..book[?(@.author =~ /.*REES/i)] | 找出符合正则表达式的书籍。 此正则表达式的含义:作者名以REES结尾,REES不区分大小写 |
| $..* | 输出根元素下的所有内容 |
| $.store.book.length() | 书籍的总数 |
4.3.1.2 Json 提取器(JSON Extractor)添加步骤
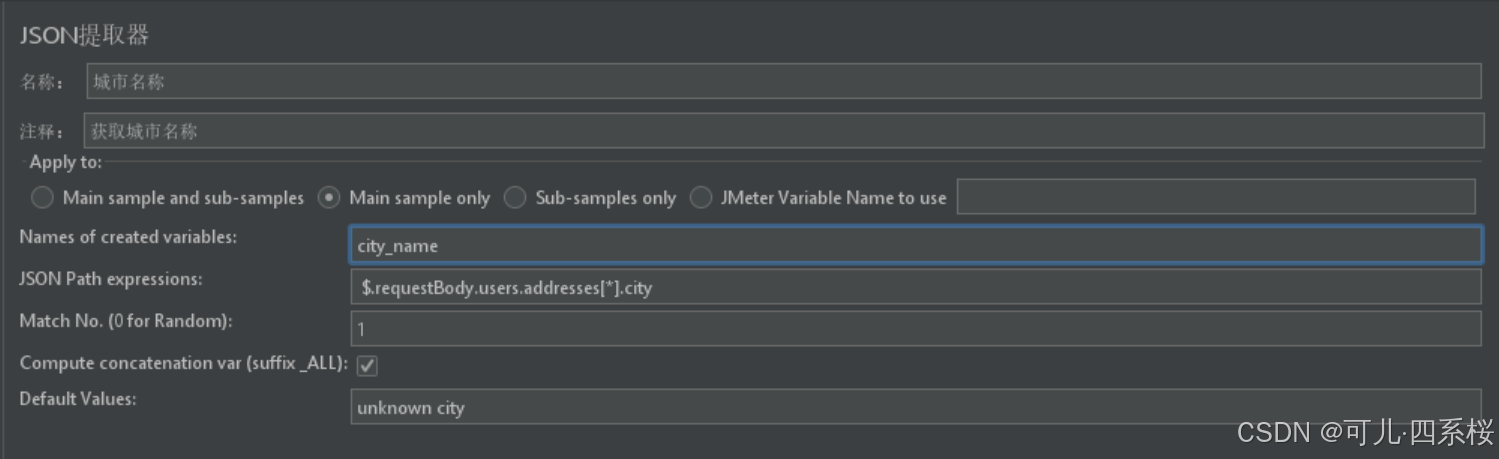
以下面的请求体为例,获取city这个名字作为用户定义的变量。
{
"users": [
{
"name": "Alice",
"addresses": [
{ "city": "New York", "zip": "10001" },
{ "city": "Los Angeles", "zip": "90001" }
]
},
{
"name": "Bob",
"addresses": [
{ "city": "Chicago", "zip": "60601" },
{ "city": "Houston", "zip": "77001" }
]
}
]
}
jmeter的配置如下: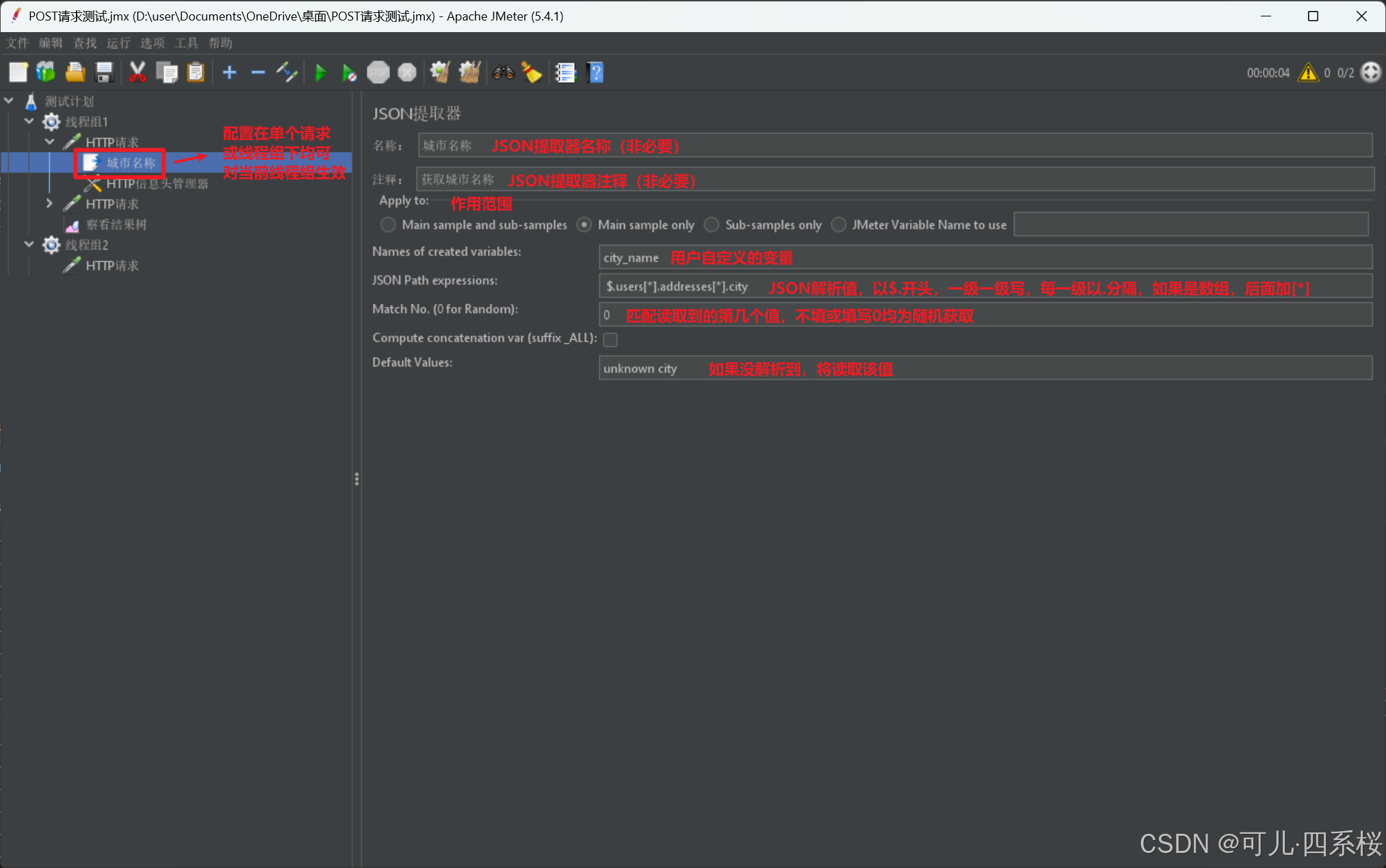
4.3.2 正则表达式提取器(Regular Expression Extractor)
4.3.2.1 正则表达式语法
| 字符 | 说明 |
| \ | 将下一字符标记为特殊字符、文本、反向引用或八进制转义符。例如, n匹配字符 n。\n 匹配换行符。序列 \\\\ 匹配 \\ ,\\( 匹配 (。 |
| ^ | 匹配输入字符串开始的位置。如果设置了 RegExp 对象的 Multiline 属性,^ 还会与"\n"或"\r"之后的位置匹配。 |
| $ | 匹配输入字符串结尾的位置。如果设置了 RegExp 对象的 Multiline 属性,$ 还会与"\n"或"\r"之前的位置匹配。 |
| * | 零次或多次匹配前面的字符或子表达式。例如,zo* 匹配"z"和"zoo"。* 等效于 {0,}。 |
| + | 一次或多次匹配前面的字符或子表达式。例如,"zo+"与"zo"和"zoo"匹配,但与"z"不匹配。+ 等效于 {1,}。 |
| ? | 零次或一次匹配前面的字符或子表达式。例如,"do(es)?"匹配"do"或"does"中的"do"。? 等效于 {0,1}。 |
| {n} | n 是非负整数。正好匹配 n 次。例如,"o{2}"与"Bob"中的"o"不匹配,但与"food"中的两个"o"匹配。 |
| {n,} | n 是非负整数。至少匹配 n 次。例如,"o{2,}"不匹配"Bob"中的"o",而匹配"foooood"中的所有 o。"o{1,}"等效于"o+"。"o{0,}"等效于"o*"。 |
| {n,m} | m 和 n 是非负整数,其中 n <= m。匹配至少 n 次,至多 m 次。例如,"o{1,3}"匹配"fooooood"中的头三个 o。'o{0,1}' 等效于 'o?'。注意:您不能将空格插入逗号和数字之间。 |
| ? | 当此字符紧随任何其他限定符(*、+、?、{n}、{n,}、{n,m})之后时,匹配模式是"非贪心的"。"非贪心的"模式匹配搜索到的、尽可能短的字符串,而默认的"贪心的"模式匹配搜索到的、尽可能长的字符串。例如,在字符串"oooo"中,"o+?"只匹配单个"o",而"o+"匹配所有"o"。 |
| . | 匹配除"\r\n"之外的任何单个字符。若要匹配包括"\r\n"在内的任意字符,请使用诸如"[\s\S]"之类的模式。 |
| (pattern) | 匹配 pattern 并捕获该匹配的子表达式。可以使用 $0…$9 属性从结果"匹配"集合中检索捕获的匹配。若要匹配括号字符 ( ),请使用"\("或者"\)"。 |
| (?:pattern) | 匹配 pattern 但不捕获该匹配的子表达式,即它是一个非捕获匹配,不存储供以后使用的匹配。这对于用"or"字符 (|) 组合模式部件的情况很有用。例如,'industr(?:y|ies) 是比 'industry|industries' 更经济的表达式。 |
| (?=pattern) | 执行正向预测先行搜索的子表达式,该表达式匹配处于匹配 pattern 的字符串的起始点的字符串。它是一个非捕获匹配,即不能捕获供以后使用的匹配。例如,'Windows (?=95|98|NT|2000)' 匹配"Windows 2000"中的"Windows",但不匹配"Windows 3.1"中的"Windows"。预测先行不占用字符,即发生匹配后,下一匹配的搜索紧随上一匹配之后,而不是在组成预测先行的字符后。 |
| (?!pattern) | 执行反向预测先行搜索的子表达式,该表达式匹配不处于匹配 pattern 的字符串的起始点的搜索字符串。它是一个非捕获匹配,即不能捕获供以后使用的匹配。例如,'Windows (?!95|98|NT|2000)' 匹配"Windows 3.1"中的 "Windows",但不匹配"Windows 2000"中的"Windows"。预测先行不占用字符,即发生匹配后,下一匹配的搜索紧随上一匹配之后,而不是在组成预测先行的字符后。 |
| x|y | 匹配 x 或 y。例如,'z|food' 匹配"z"或"food"。'(z|f)ood' 匹配"zood"或"food"。 |
| [xyz] | 字符集。匹配包含的任一字符。例如,"[abc]"匹配"plain"中的"a"。 |
| [^xyz] | 反向字符集。匹配未包含的任何字符。例如,"[^abc]"匹配"plain"中"p","l","i","n"。 |
| [a-z] | 字符范围。匹配指定范围内的任何字符。例如,"[a-z]"匹配"a"到"z"范围内的任何小写字母。 |
| [^a-z] | 反向范围字符。匹配不在指定的范围内的任何字符。例如,"[^a-z]"匹配任何不在"a"到"z"范围内的任何字符。 |
| \b | 匹配一个字边界,即字与空格间的位置。例如,"er\b"匹配"never"中的"er",但不匹配"verb"中的"er"。 |
| \B | 非字边界匹配。"er\B"匹配"verb"中的"er",但不匹配"never"中的"er"。 |
| \cx | 匹配 x 指示的控制字符。例如,\cM 匹配 Control-M 或回车符。x 的值必须在 A-Z 或 a-z 之间。如果不是这样,则假定 c 就是"c"字符本身。 |
| \d | 数字字符匹配。等效于 [0-9]。 |
| \D | 非数字字符匹配。等效于 [^0-9]。 |
| \f | 换页符匹配。等效于 \x0c 和 \cL。 |
| \n | 换行符匹配。等效于 \x0a 和 \cJ。 |
| \r | 匹配一个回车符。等效于 \x0d 和 \cM。 |
| \s | 匹配任何空白字符,包括空格、制表符、换页符等。与 [ \f\n\r\t\v] 等效。 |
| \S | 匹配任何非空白字符。与 [^ \f\n\r\t\v] 等效。 |
| \t | 制表符匹配。与 \x09 和 \cI 等效。 |
| \v | 垂直制表符匹配。与 \x0b 和 \cK 等效。 |
| \w | 匹配任何字类字符,包括下划线。与"[A-Za-z0-9_]"等效。 |
| \W | 与任何非单词字符匹配。与"[^A-Za-z0-9_]"等效。 |
| \xn | 匹配 n,此处的 n 是一个十六进制转义码。十六进制转义码必须正好是两位数长。例如,"\x41"匹配"A"。"\x041"与"\x04"&"1"等效。允许在正则表达式中使用 ASCII 代码。 |
| \num | 匹配 num,此处的 num 是一个正整数。到捕获匹配的反向引用。例如,"(.)\1"匹配两个连续的相同字符。 |
| \n | 标识一个八进制转义码或反向引用。如果 \n 前面至少有 n 个捕获子表达式,那么 n 是反向引用。否则,如果 n 是八进制数 (0-7),那么 n 是八进制转义码。 |
| \nm | 标识一个八进制转义码或反向引用。如果 \nm 前面至少有 nm 个捕获子表达式,那么 nm 是反向引用。如果 \nm 前面至少有 n 个捕获,则 n 是反向引用,后面跟有字符 m。如果两种前面的情况都不存在,则 \nm 匹配八进制值 nm,其中 n 和 m 是八进制数字 (0-7)。 |
| \nml | 当 n 是八进制数 (0-3),m 和 l 是八进制数 (0-7) 时,匹配八进制转义码 nml。 |
| \un | 匹配 n,其中 n 是以四位十六进制数表示的 Unicode 字符。例如,\u00A9 匹配版权符号 (©)。 |
4.3.2.2 正则表达式提取器添加步骤
以下面的请求体为例,获取city这个名字作为用户定义的变量。
{
"users": [
{
"name": "Alice",
"addresses": [
{ "city": "New York", "zip": "10001" },
{ "city": "Los Angeles", "zip": "90001" }
]
},
{
"name": "Bob",
"addresses": [
{ "city": "Chicago", "zip": "60601" },
{ "city": "Houston", "zip": "77001" }
]
}
]
}
jmeter的配置如下:
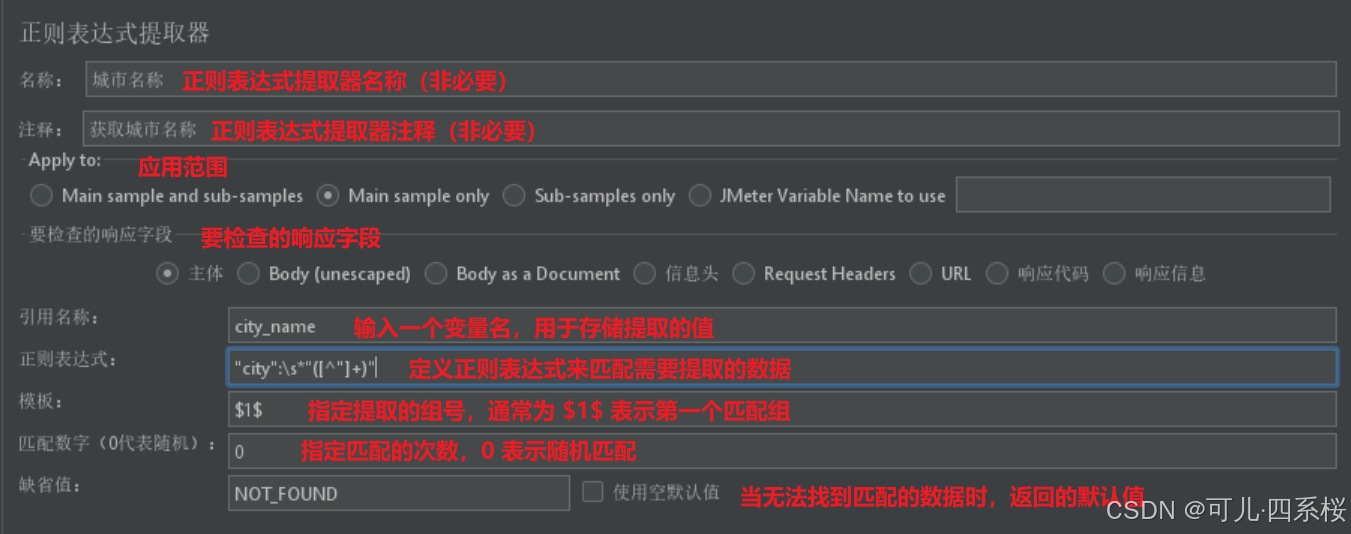
说明:
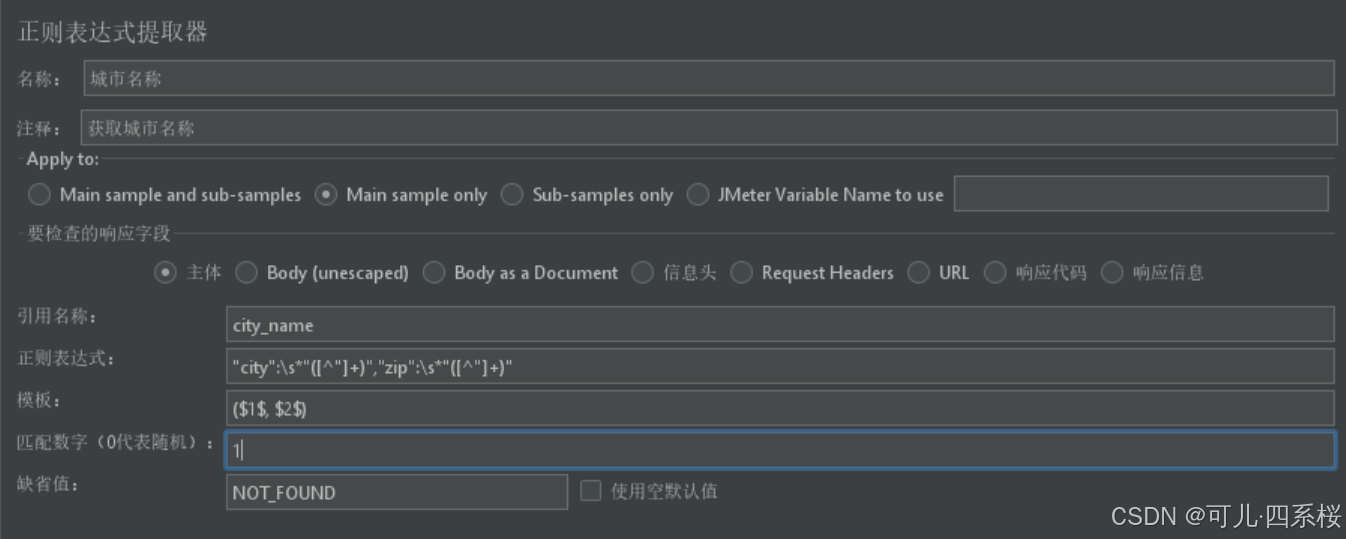
正则表达式提取器可以提取多个数据,如提取(New York, 10001),则配置如下:
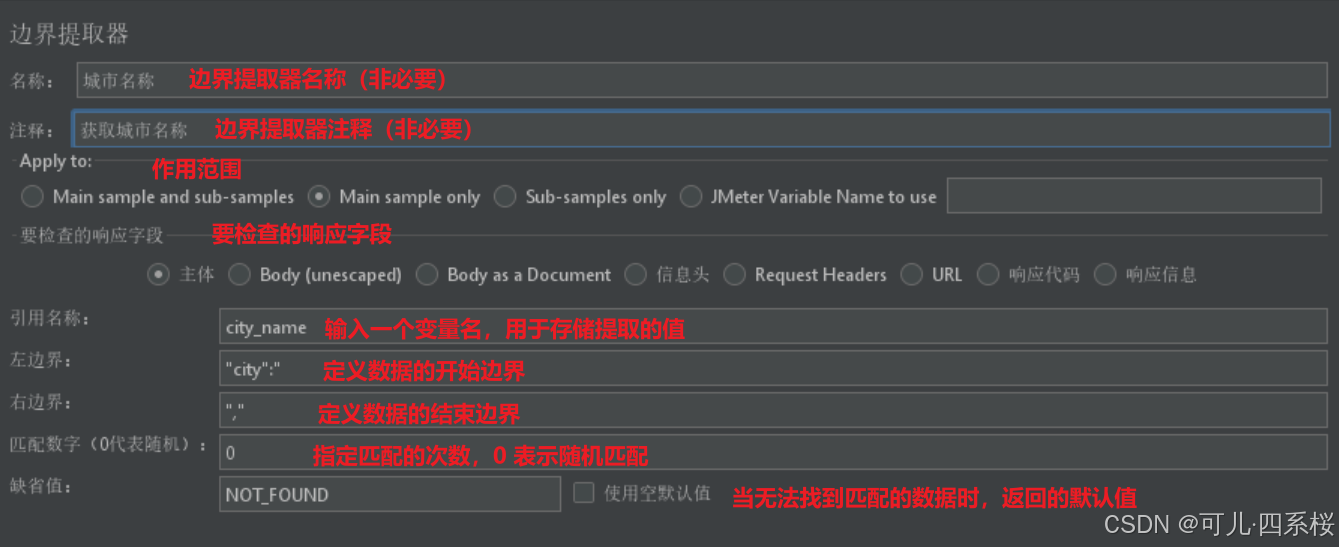
4.3.3 边界提取器(Boundary Extractor)
以下面的请求体为例,获取city这个名字作为用户定义的变量。
{
"users": [
{
"name": "Alice",
"addresses": [
{ "city": "New York", "zip": "10001" },
{ "city": "Los Angeles", "zip": "90001" }
]
},
{
"name": "Bob",
"addresses": [
{ "city": "Chicago", "zip": "60601" },
{ "city": "Houston", "zip": "77001" }
]
}
]
}
jmeter的配置如下:
5. 实战测试
接口来源:https://github.com/kerrsixy/jmeter-demo
5.1 Get请求测试(Delete请求与Get类似)
以下面接口为例:
import com.alibaba.fastjson2.JSON;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.web.bind.annotation.*;
import java.util.HashMap;
import java.util.Map;
@RestController
public class BasicController {
private static final Logger logger = LoggerFactory.getLogger(BasicController.class);
@RequestMapping("/hello/{id}")
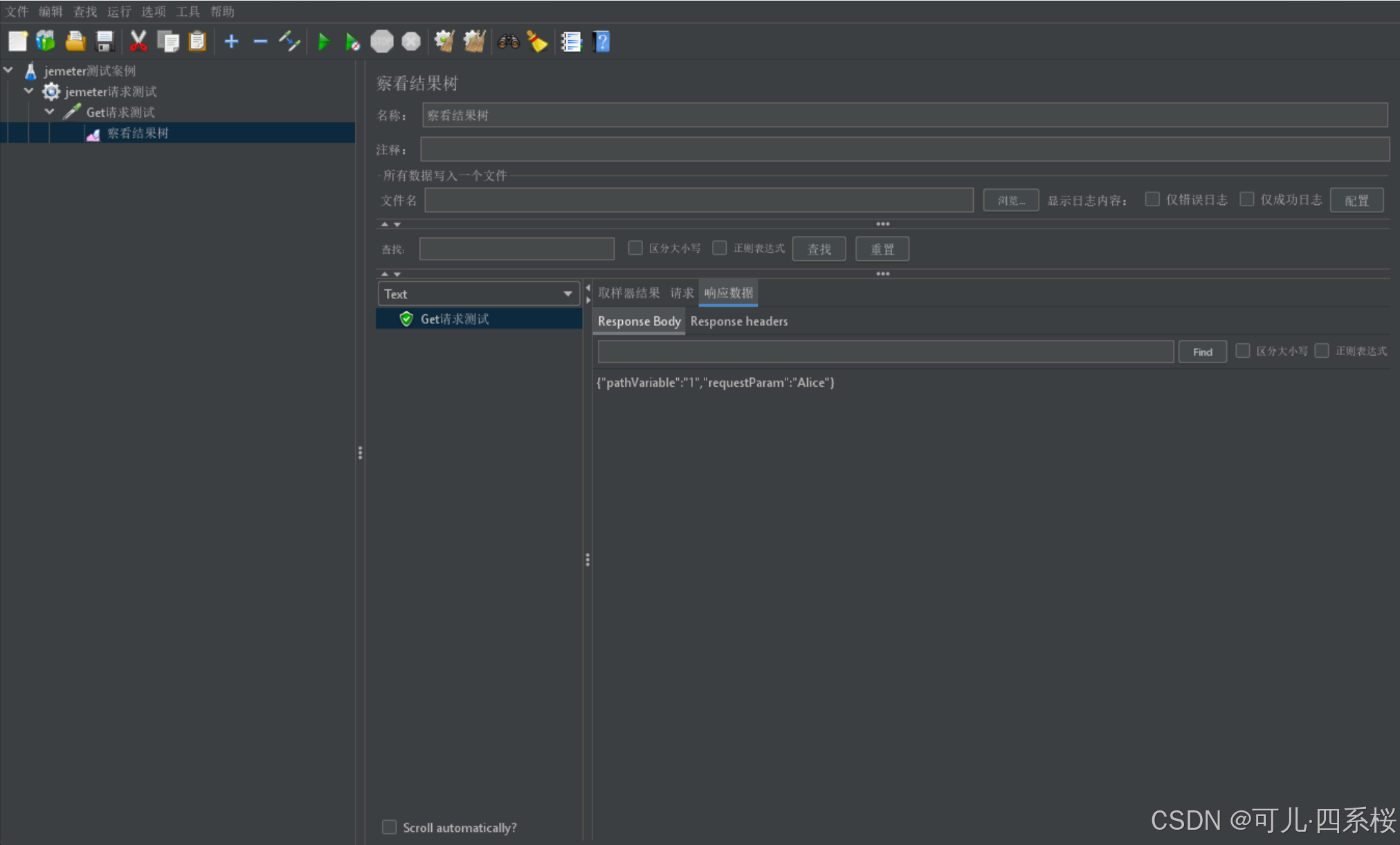
public String hello(@RequestParam(name = "name", defaultValue = "unknown user") String name,
@PathVariable("id") String pathVariable,
@RequestBody(required = false) Map<String, Object> requestBody) {
if ("fail".equals(name)) {
throw new RuntimeException("fail test");
}
Map<String, Object> result = new HashMap<>();
result.put("requestParam", name);
result.put("pathVariable", pathVariable);
if (requestBody != null) {
result.put("requestBody", requestBody);
}
logger.info("result:{}", JSON.toJSONString(result));
return JSON.toJSONString(result);
}
}1. 编辑测试计划(Test Plan)
2. 创建线程组(Thread Group)
3. 创建HTTP请求(HTTP Request)
4. 添加查看结果树(View Results Tree)
5. 发送请求,查看结果
5.2 Post请求测试(Put请求与Post类似)
以下面接口为例:
import com.alibaba.fastjson2.JSON;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.web.bind.annotation.*;
import java.util.HashMap;
import java.util.Map;
@RestController
public class BasicController {
private static final Logger logger = LoggerFactory.getLogger(BasicController.class);
@RequestMapping("/hello/{id}")
public String hello(@RequestParam(name = "name", defaultValue = "unknown user") String name,
@PathVariable("id") String pathVariable,
@RequestBody(required = false) Map<String, Object> requestBody) {
if ("fail".equals(name)) {
throw new RuntimeException("fail test");
}
Map<String, Object> result = new HashMap<>();
result.put("requestParam", name);
result.put("pathVariable", pathVariable);
if (requestBody != null) {
result.put("requestBody", requestBody);
}
logger.info("result:{}", JSON.toJSONString(result));
return JSON.toJSONString(result);
}
}1. 编辑测试计划(Test Plan)
2. 创建线程组(Thread Group)
3. 创建HTTP请求(HTTP Request)
可以直接传参,也可以动态参数,下面以动态参数为例:
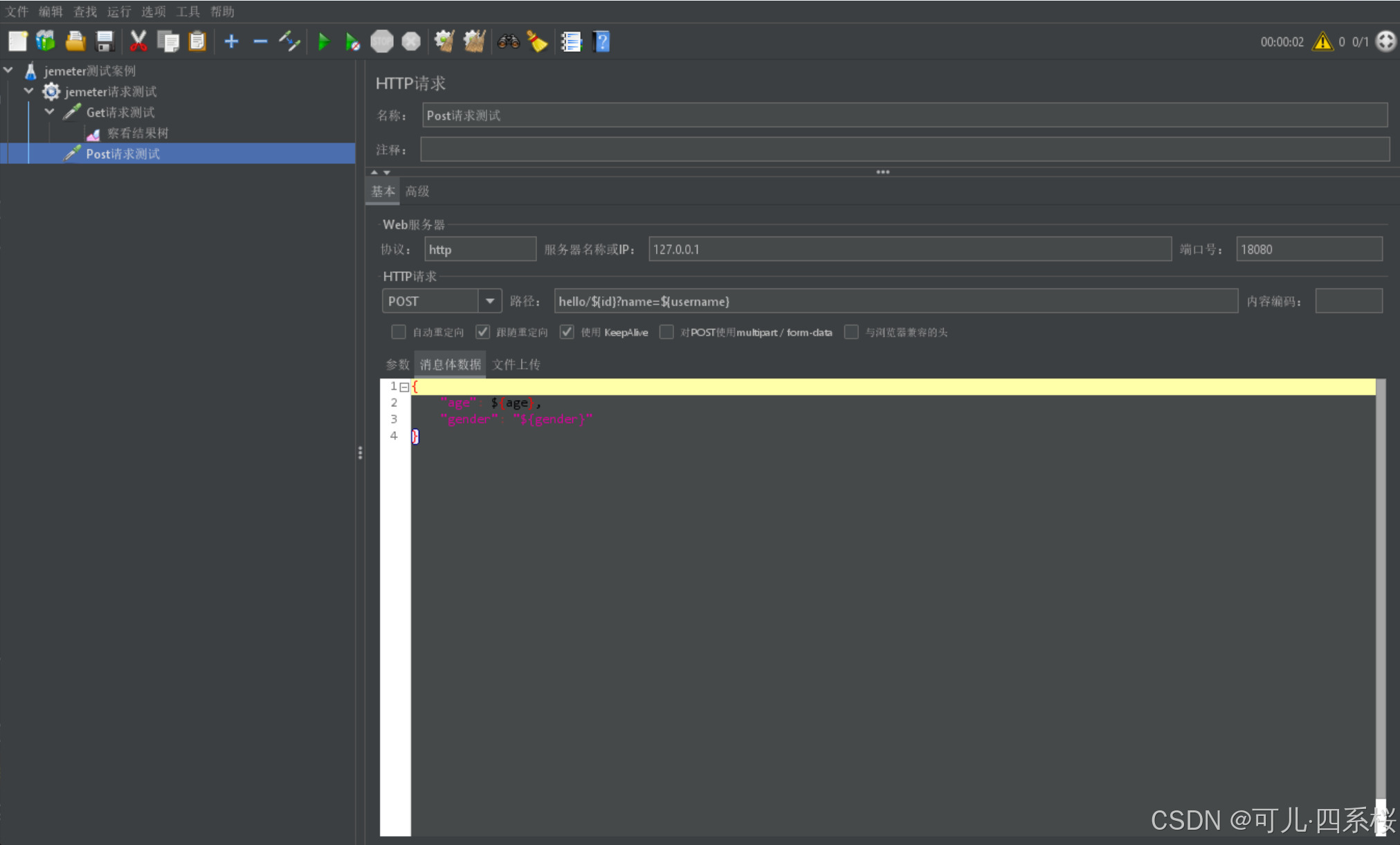
动态参数为:
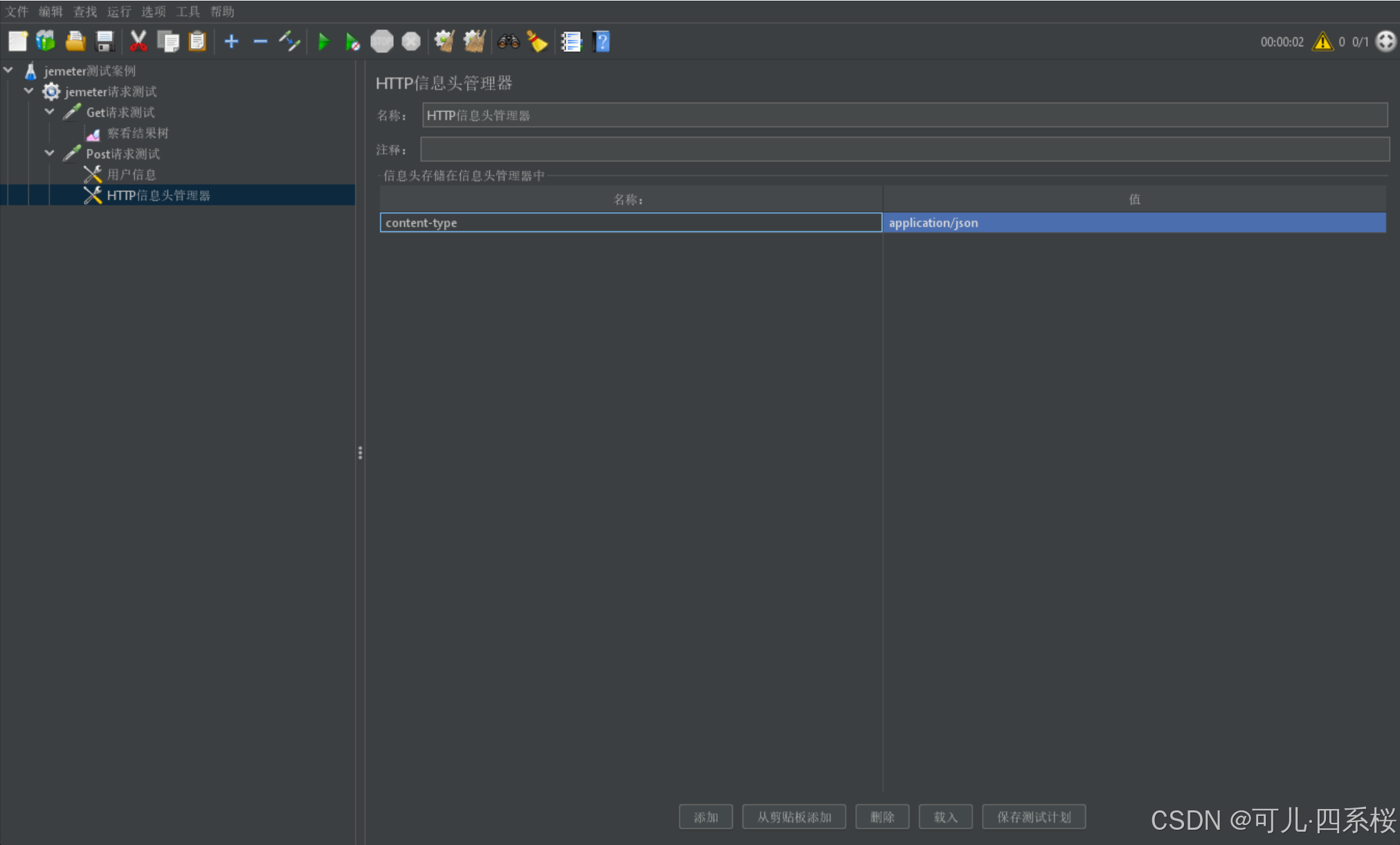
4. (必要)添加请求头:content-type=application/json
5. 发送请求,查看结果
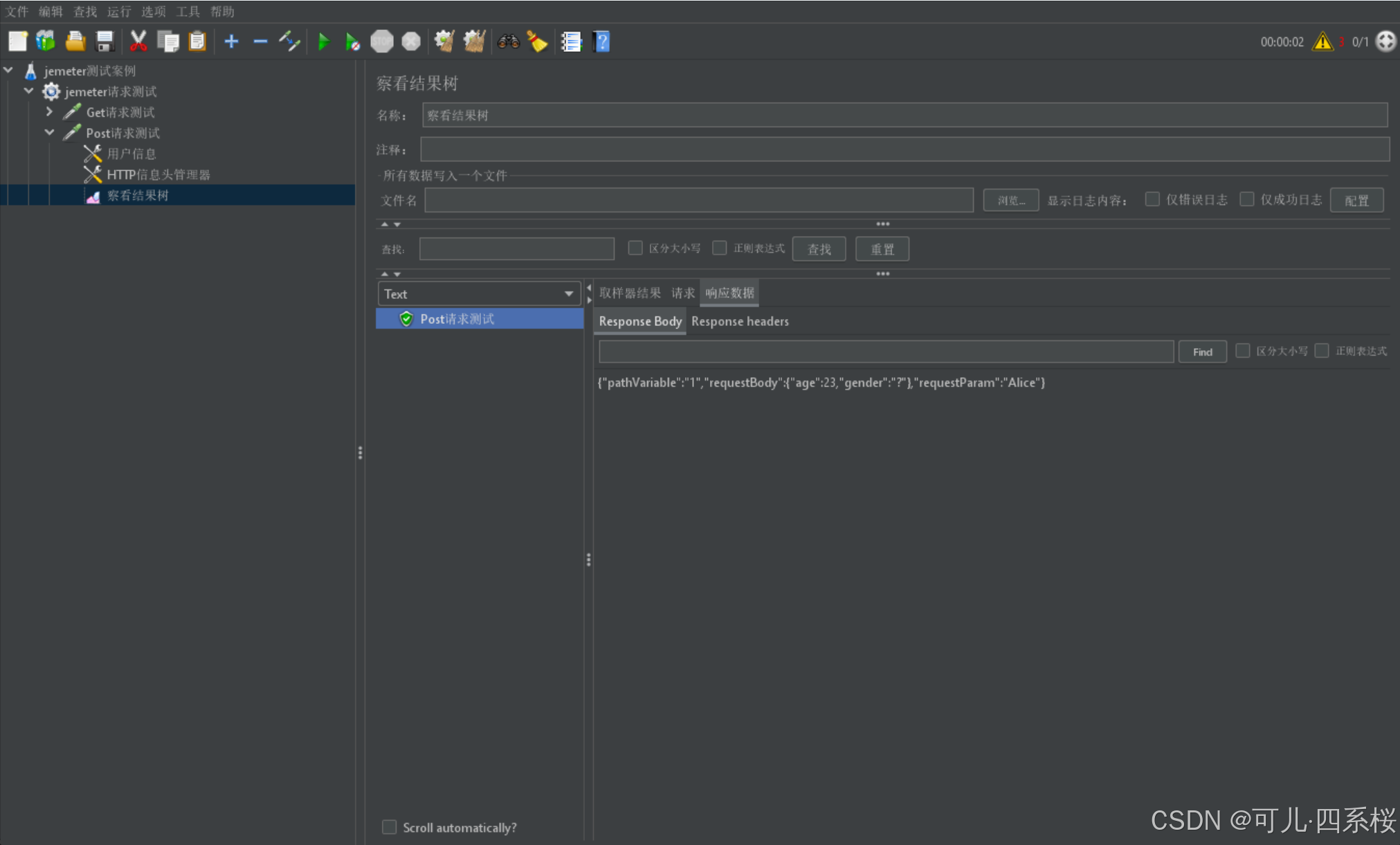 6. 解决乱码问题:
6. 解决乱码问题:
(1)在bin/jmeter.properties文件中添加sampleresult.default.encoding=UTF-8
(2) 修改文件字符集为UTF-8
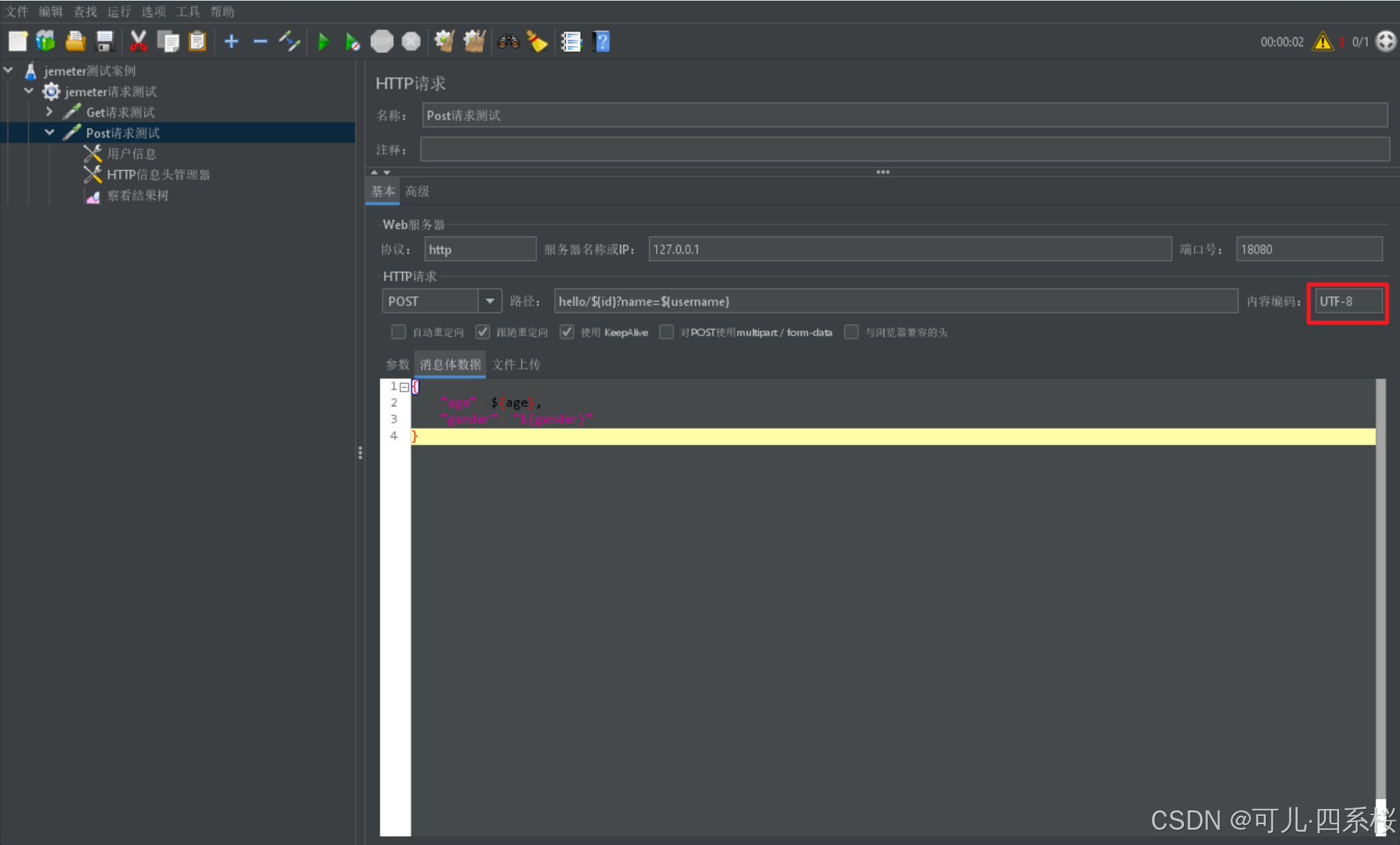
(3) HTTP请求里的内容编辑指定字符集UTF-8
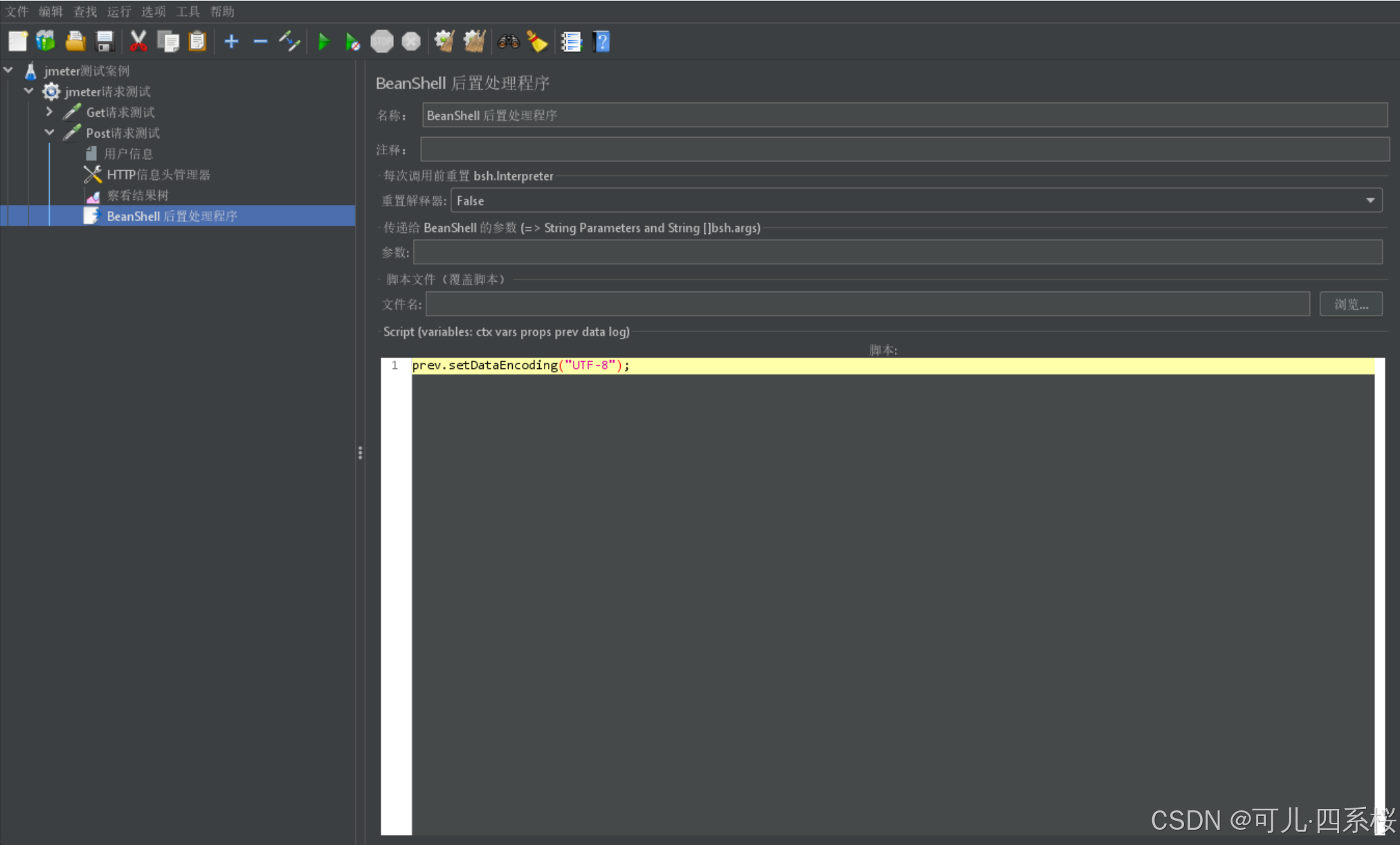
 (4) 中文版:右击测试计划/线程组/HTTP请求 -> 添加 -> 后置处理器 -> BeanShell PostProcessor
(4) 中文版:右击测试计划/线程组/HTTP请求 -> 添加 -> 后置处理器 -> BeanShell PostProcessor
英文版:右击Test Plan/Thread Group/HTTP Request -> Add -> Post Processors -> BeanShell PostProcessor
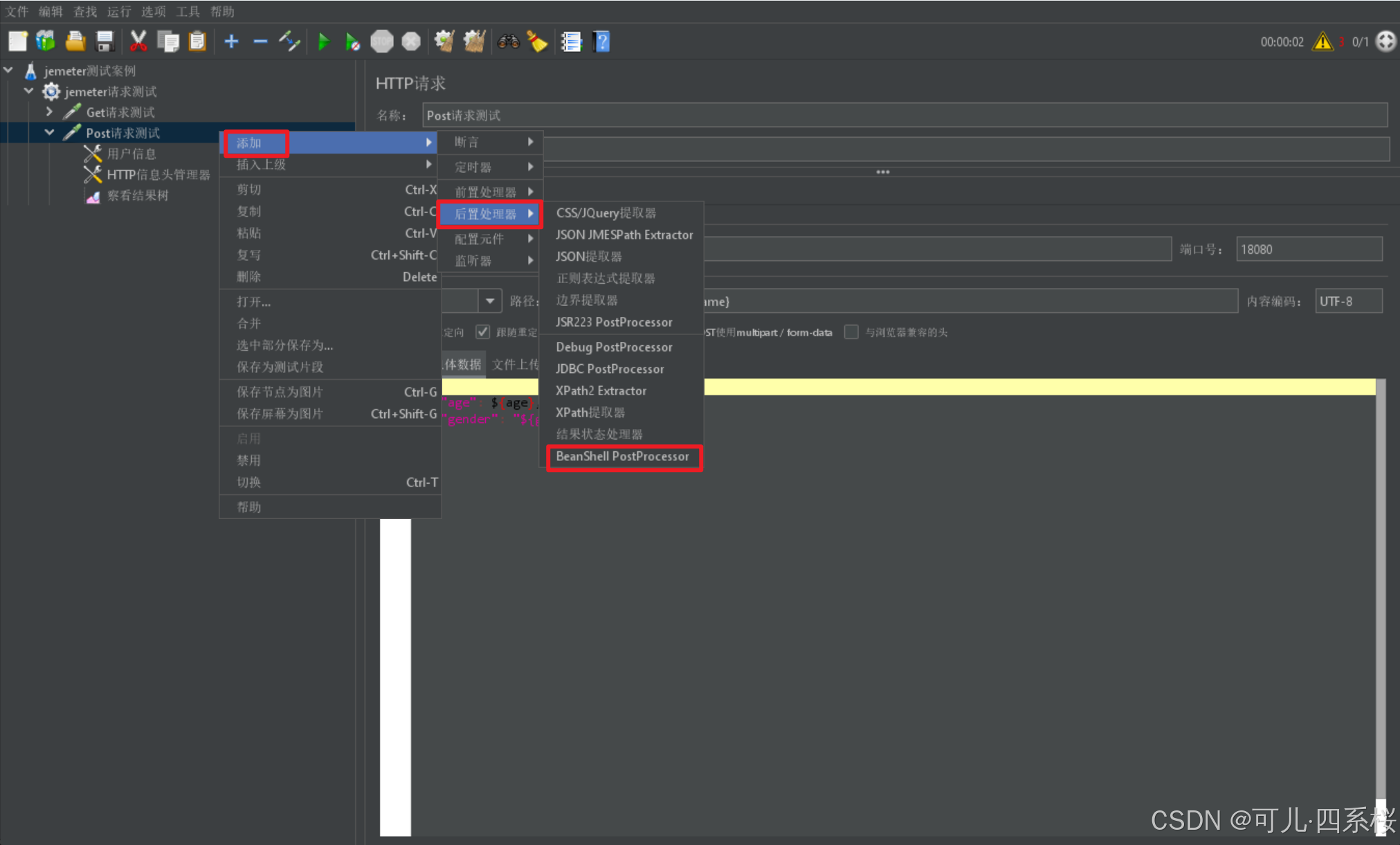
脚本里输入prev.setDataEncoding("UTF-8");
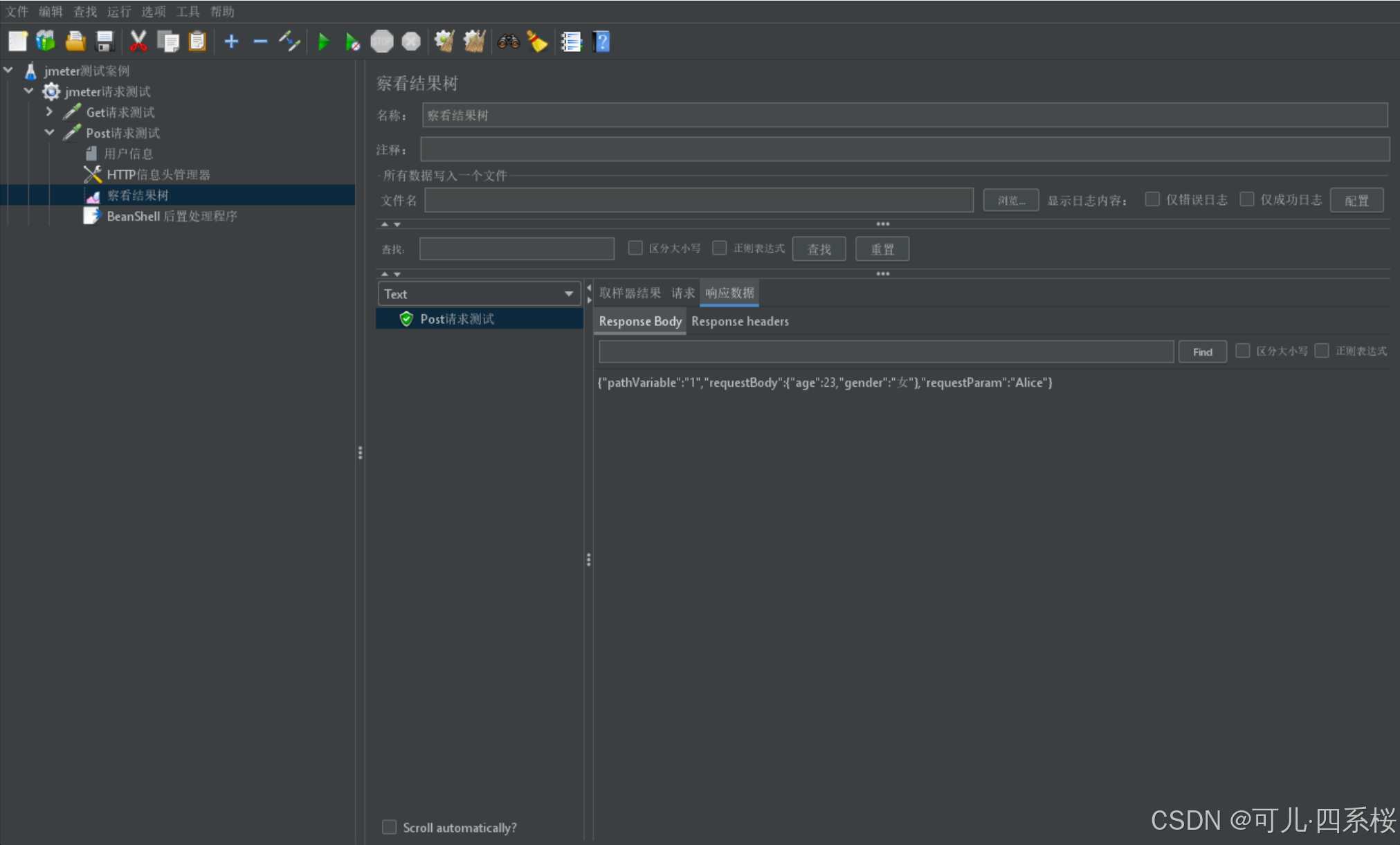
再次发送请求,就发现配置成功:
5.3 文件上传
以下面接口为例:
import com.alibaba.fastjson2.JSON;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.web.bind.annotation.*;
import org.springframework.web.multipart.MultipartFile;
import java.util.HashMap;
import java.util.Map;
@RestController
public class BasicController {
private static final Logger logger = LoggerFactory.getLogger(BasicController.class);
@PostMapping("/file/{id}")
public String file(@RequestParam(name = "name", defaultValue = "unknown user") String name,
@PathVariable("id") String pathVariable,
@RequestParam("file") MultipartFile file,
@RequestPart(value = "requestBody", required = false) String requestBody) {
Map<String, Object> result = new HashMap<>();
result.put("requestParam", name);
result.put("pathVariable", pathVariable);
if (file != null) {
result.put("filename", file.getOriginalFilename());
result.put("contentType", file.getContentType());
result.put("size", file.getSize());
}
if (requestBody != null) {
result.put("requestBody", requestBody);
}
logger.info("result:{}", JSON.toJSONString(result));
return JSON.toJSONString(result);
}
}1. 编辑测试计划(Test Plan)
2. 创建线程组(Thread Group)
3. 创建HTTP请求(HTTP Request)
可以直接传参,也可以动态参数,下面以直接传参为例:
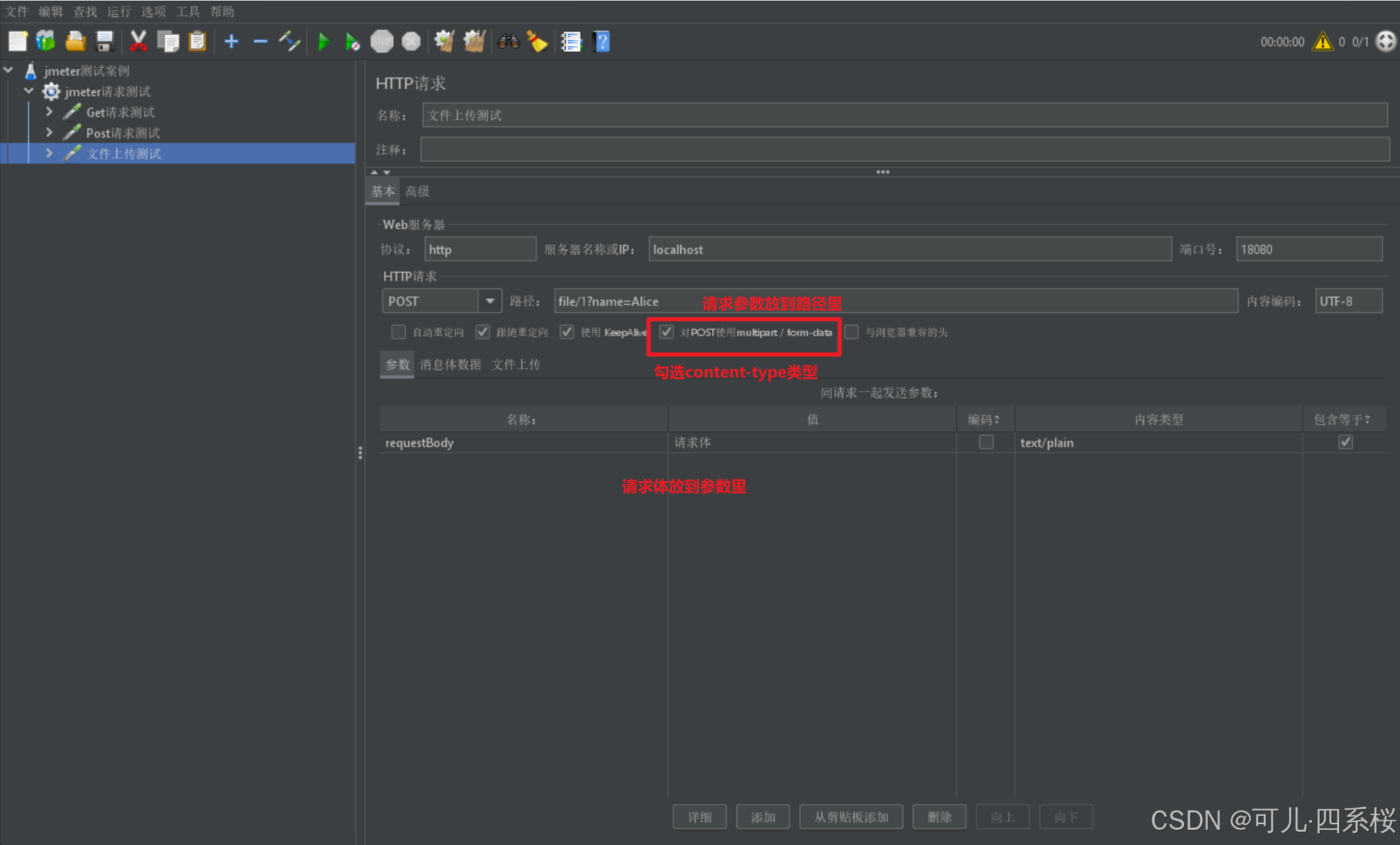
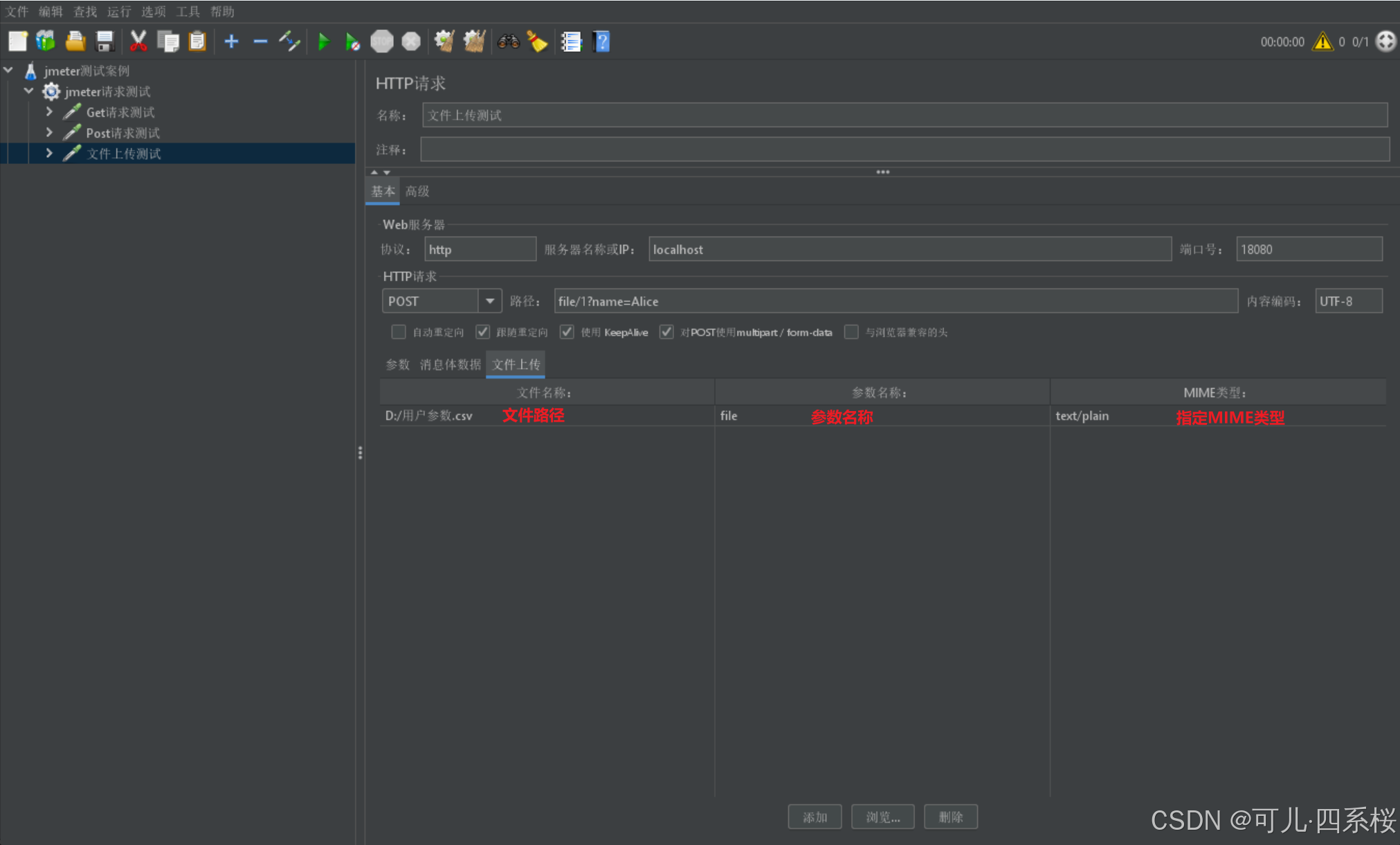
4. 添加监听器并启动测试
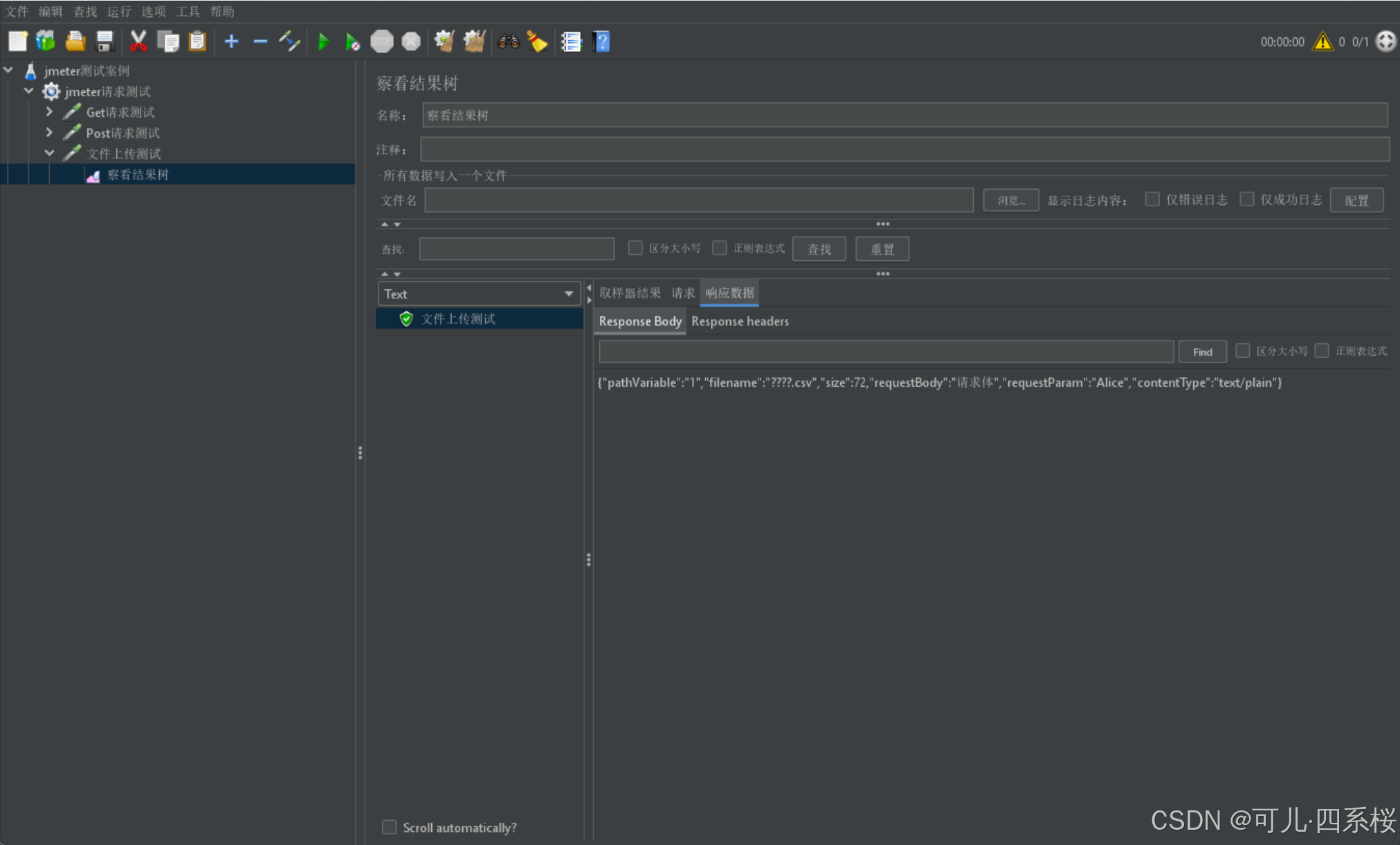
6. 脚本录制
对应官网文档:https://jmeter.apache.org/usermanual/component_reference.html#HTTP(S)_Test_Script_Recorder
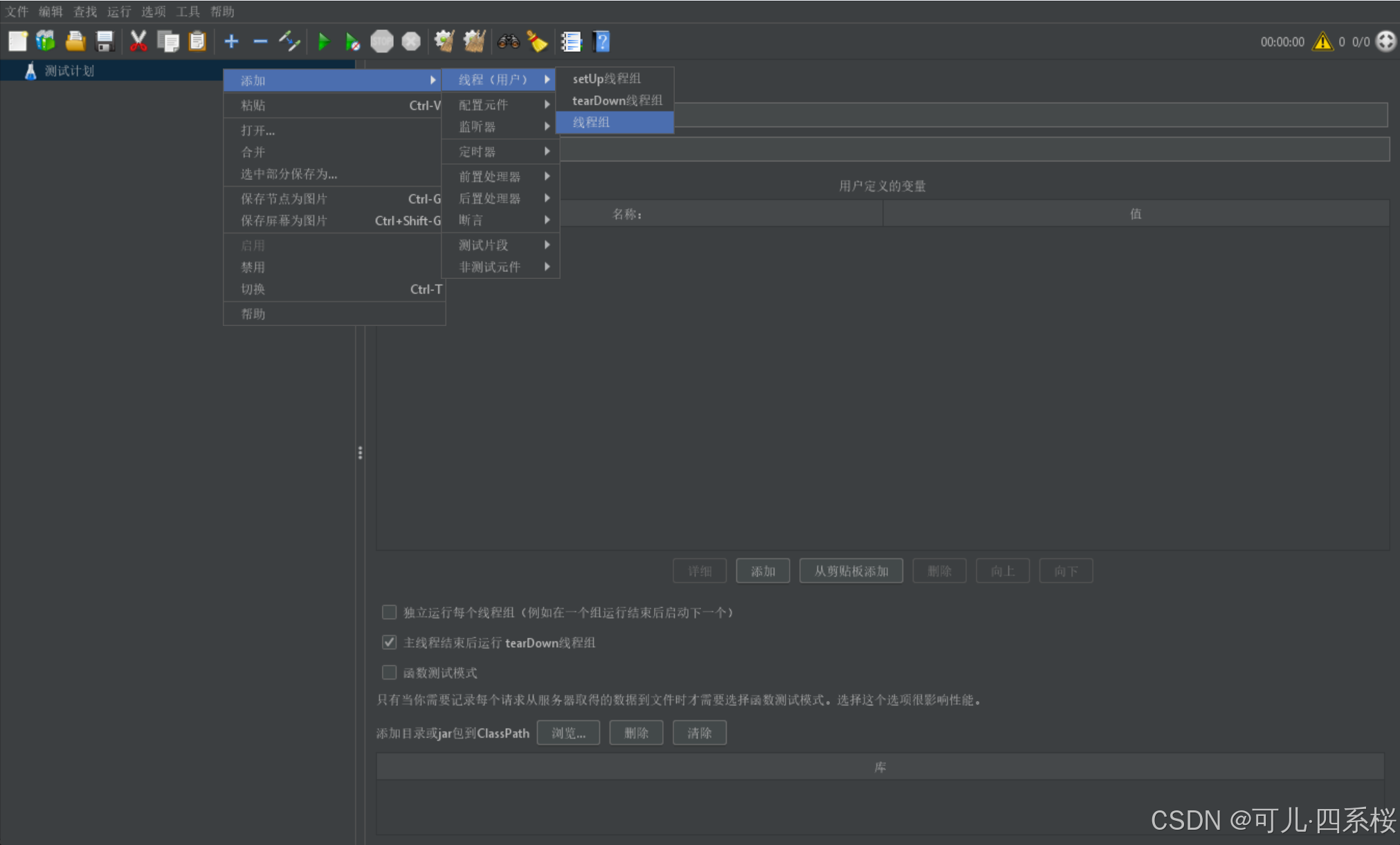
6.1 添加线程组
1. 中文版:右击测试计划 -> 添加 -> 线程(用户) -> 线程组
英文版:Test Plan -> Add -> Threads(Users) -> Thread Group
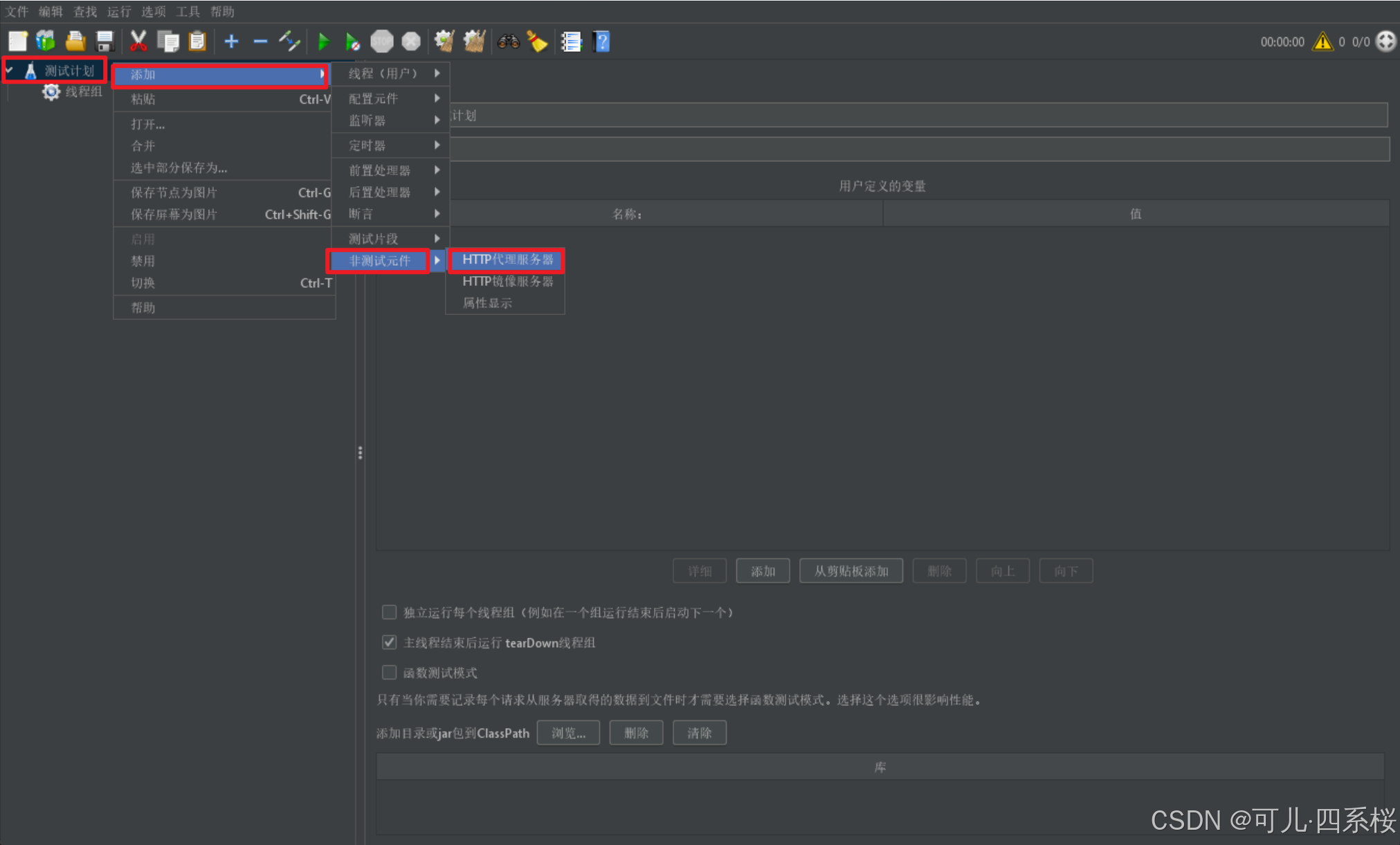
6.2 添加HTTP代理服务器
1. 中文版:右击测试计划 -> 添加 -> 线程(用户) -> 线程组
英文版:Test Plan -> Add -> Non-Test Elements -> HTTP(S) Test Script Recorder
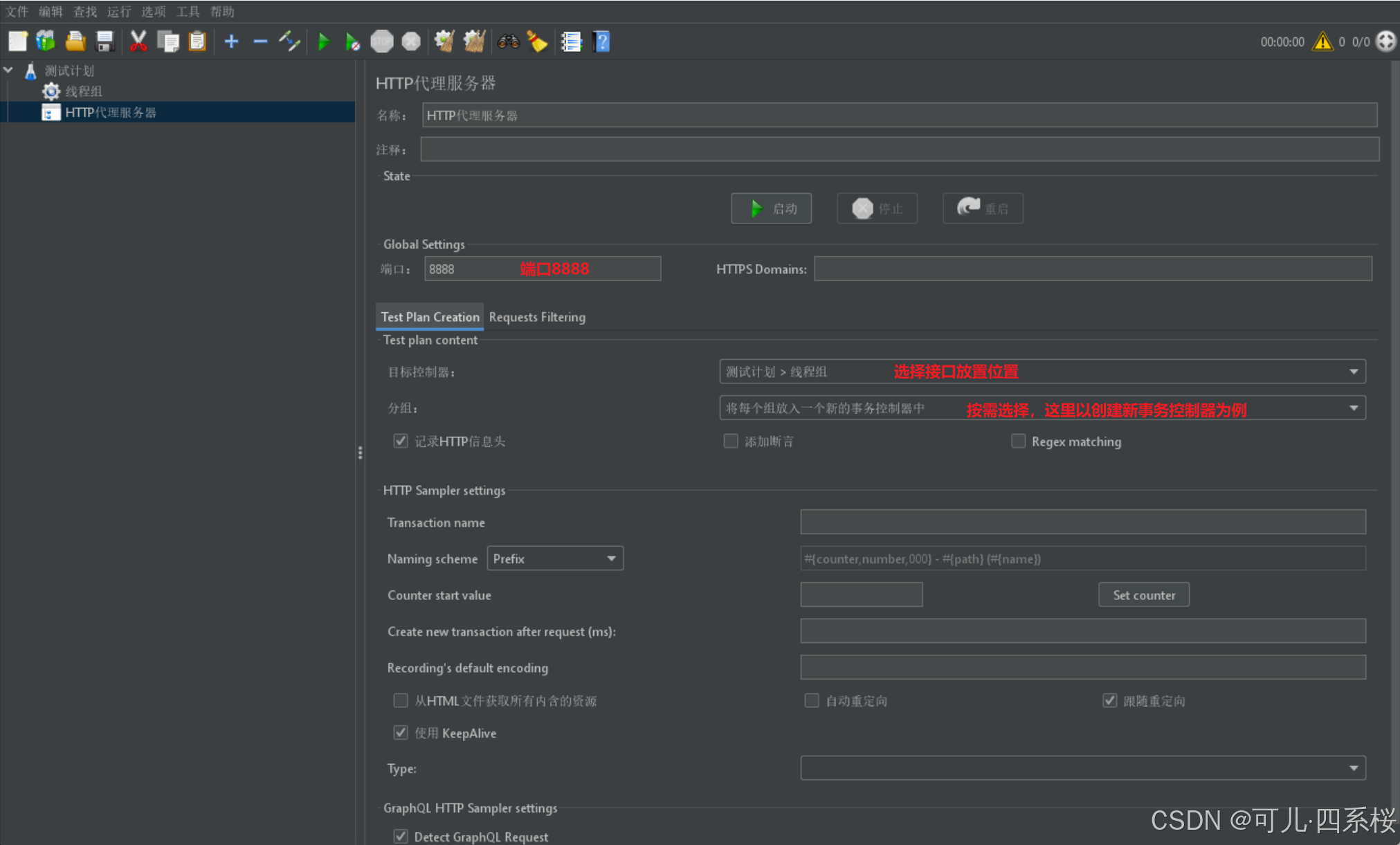
2. 配置 Test Plan Creation
1) 设置端口为 8888;
2) 选择目标控制器;
3) 选择分组;
4) 配置包含模式(选做,填写正则表达式,该步骤可以只获取匹配的接口);
5) 配置排除模式(选做,填写正则表达式,该步骤可以排除匹配的接口),如 (?i).*\.(bmp|css|js|gif|ico|jpe?g|png|swf|woff|woff2|htm|html). 表示过滤js、图片、html等资源文件请求。
6.3 打开要访问的网页
如果没有配置包含模式,为了避免获取到无用请求,这里需要提前打开网页,避免下一步导致网页无法访问。
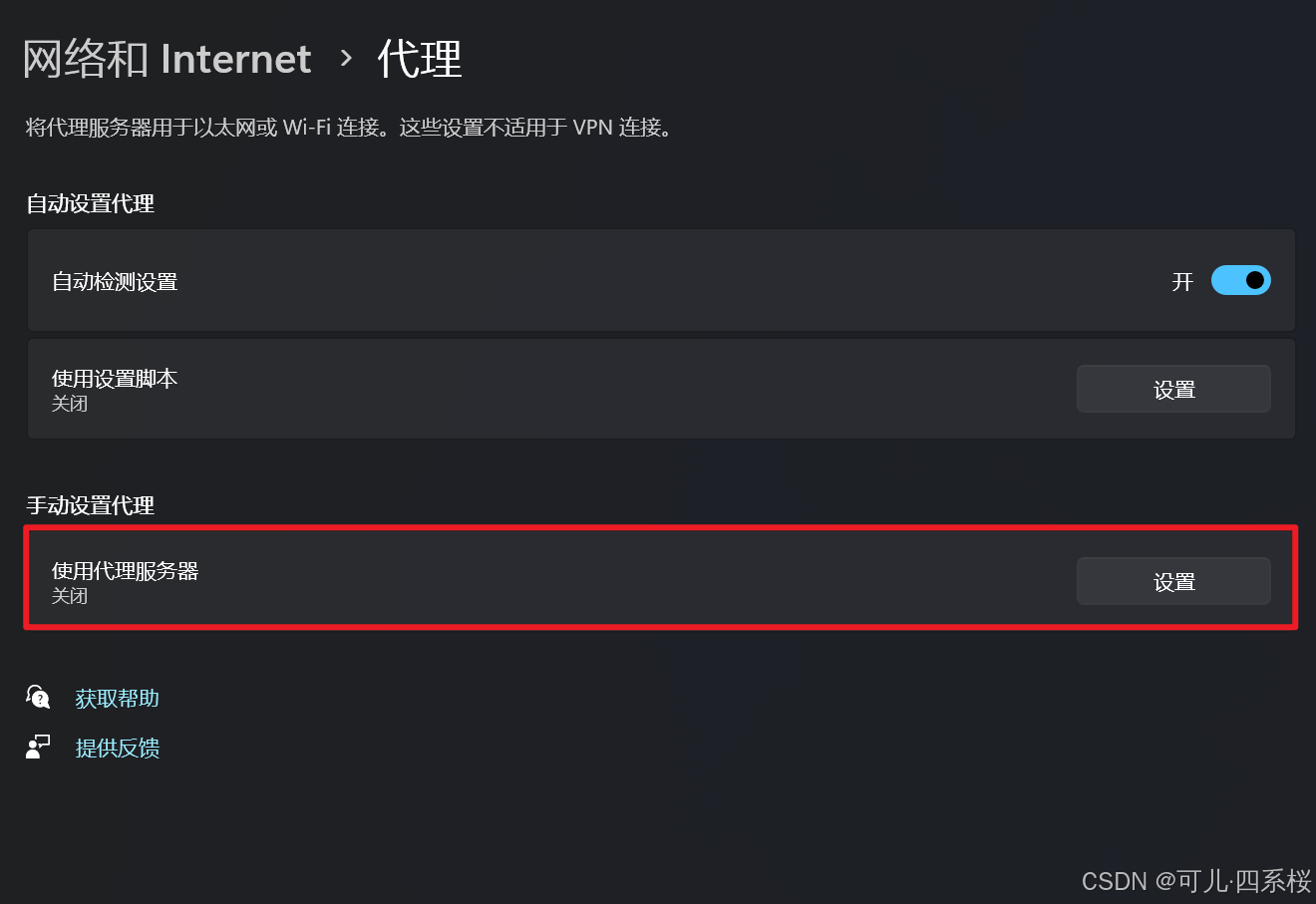
6.4 设置代理
以 win11 为例,点击网络和 Internet,点击代理,配置代理服务器。
注意:开启代理之后可能要访问的网页会打不开。

6.5 启动 HTTP代理服务器
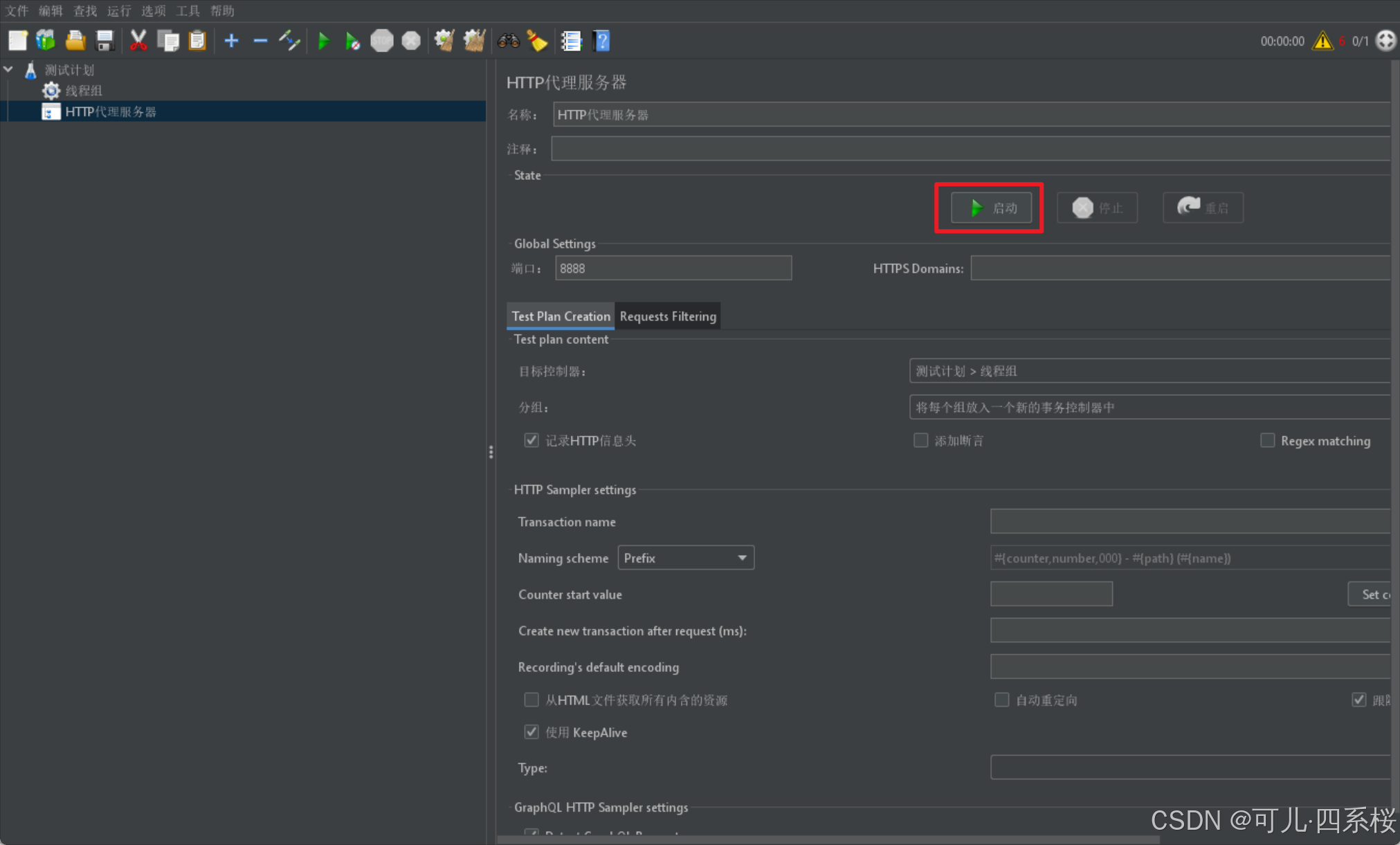
点击ok。
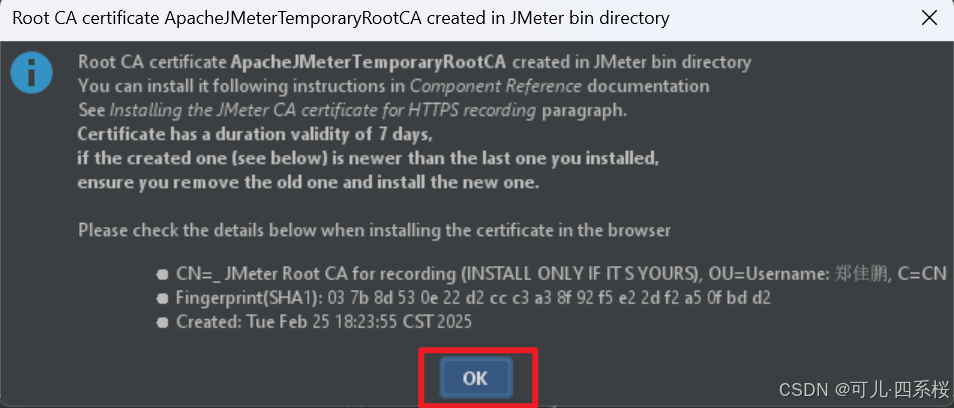 弹出该界面说明开始获取接口,请勿关闭该页面。
弹出该界面说明开始获取接口,请勿关闭该页面。
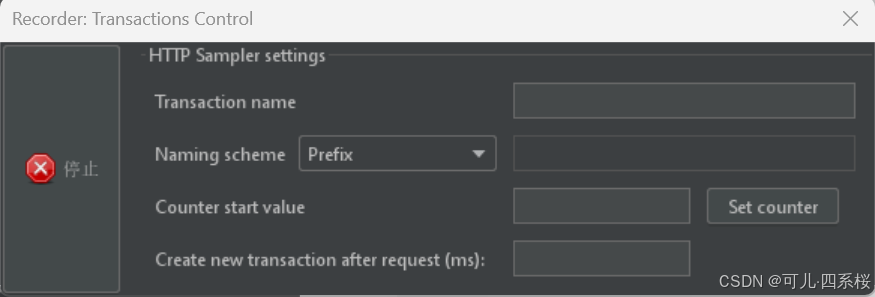
6.6 刷新网页并停止录制
刷新要获取请求的网页,页面加载完毕后,点击Recorder: Transactions Control的停止按钮。
可以看到请求成功
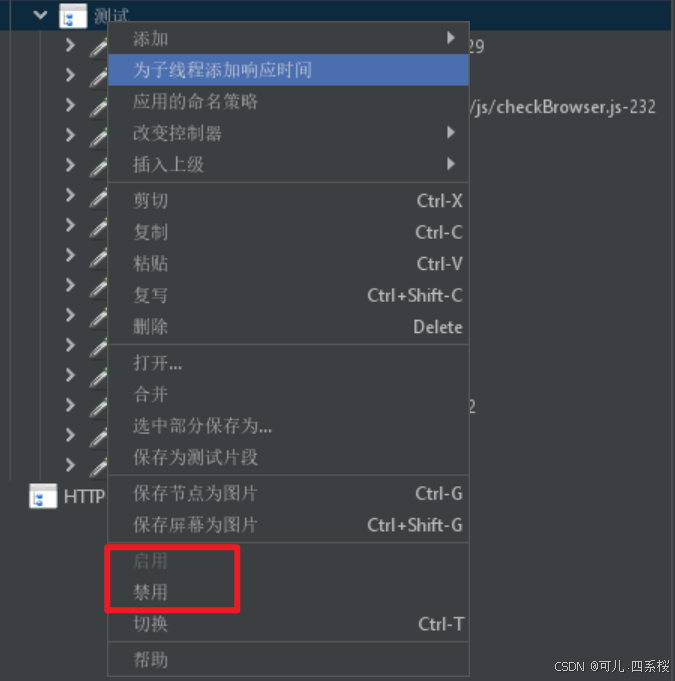
6.7 关于接口压测的启用和禁用
对想要 不压测/压测 的请求或事务控制器右键,点击 禁用/启用,这样请求就可以 不被压测/被压测


















 85
85

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











