







本篇文章主要参考了以下内容:
1.http://blog.csdn.net/zouxy09/article/details/8775524
2.http://ufldl.stanford.edu/wiki/index.php/UFLDL%E6%95%99%E7%A8%8B
AutoEncoder是采用无监督学习方式进行训练学习的(如果不知道什么是无监督学习,请看这篇http://blog.csdn.net/kevin_bobolkevin/article/details/50539693)。它是是一种尽可能复现输入信号的神经网络。为了实现这种复现,自动编码器就必须捕捉可以代表输入数据的最重要的因素,就像PCA那样,找到可以代表原信息的主要成分。
一、AutoEncoder算法的思路
1)给定无标签数据,用非监督学习学习特征:
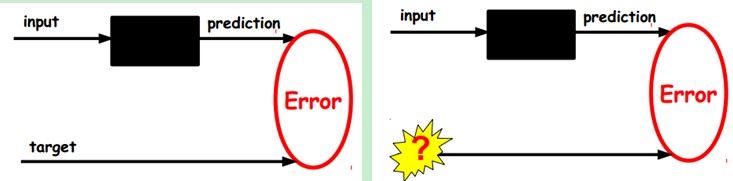
在我们之前的神经网络中,如第一个图,我们输入的样本是有标签的,即(input, target),这样我们根据当前输出和target(label)之间的差去改变前面各层的参数,直到收敛。但现在我们只有无标签数据,也就是右边的图。那么这个误差怎么得到呢?
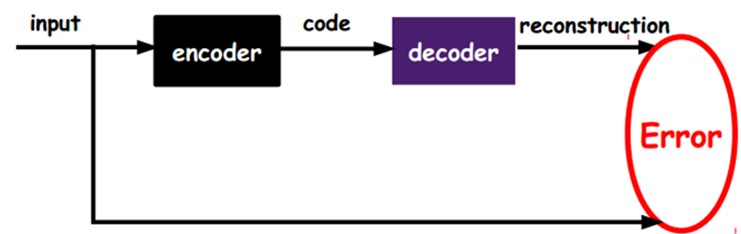
如上图,我们将input输入一个encoder编码器,就会得到一个code,这个code也就是输入的一个表示,那么我们怎么知道这个code表示的就是input呢?我们加一个decoder解码器,这时候decoder就会输出一个信息,那么如果输出的这个信息和一开始的输入信号input是很像的(理想情况下就是一样的),那很明显,我们就有理由相信这个code是靠谱的。所以,我们就通过调整encoder和decoder的参数,使得重构误差最小,这时候我们就得到了输入input信号的第一个表示了,也就是编码code了。因为是无标签数据,所以误差的来源就是直接重构后与原输入相比得到。
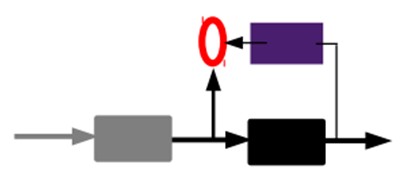
2)通过编码器产生特征,然后训练下一层。这样逐层训练:
那上面我们就得到第一层的code,我们的重构误差最小让我们相信这个code就是原输入信号的良好表达了,或者牵强点说,它和原信号是一模一样的(表达不一样,反映的是一个东西)。那第二层和第一层的训练方式就没有差别了,我们将第一层输出的code当成第二层的输入信号,同样最小化重构误差,就会得到第二层的参数,并且得到第二层输入的code,也就是原输入信息的第二个表达了。其他层就同样的方法炮制就行了(训练这一层,前面层的参数都是固定的,并且他们的decoder已经没用了,都不需要了)。
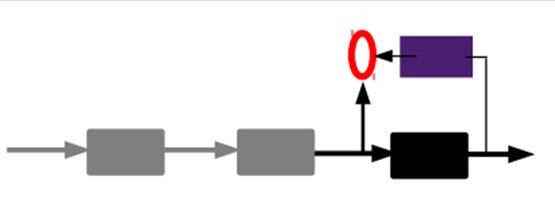
3)有监督微调:
经过上面的方法,我们就可以得到很多层了。至于需要多少层(或者深度需要多少,这个目前本身就没有一个科学的评价方法)需要自己试验调了。每一层都会得到原始输入的不同的表达。当然了,我们觉得它是越抽象越好了,就像人的视觉系统一样。
到这里,这个AutoEncoder还不能用来分类数据,因为它还没有学习如何去连结一个输入和一个类。它只是学会了如何去重构或者复现它的输入而已。或者说,它只是学习获得了一个可以良好代表输入的特征,这个特征可以最大程度上代表原输入信号。那么,为了实现分类,我们就可以在AutoEncoder的最顶的编码层添加一个分类器(例如罗杰斯特回归、SVM等),然后通过标准的多层神经网络的监督训练方法(梯度下降法)去训练。
也就是说,这时候,我们需要将最后层的特征code输入到最后的分类器,通过有标签样本,通过监督学习进行微调,这也分两种,一个是只调整分类器(黑色部分):
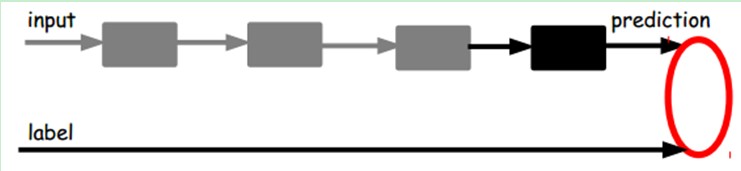
另一种:通过有标签样本,微调整个系统:(如果有足够多的数据,这个是最好的。end-to-end learning端对端学习)
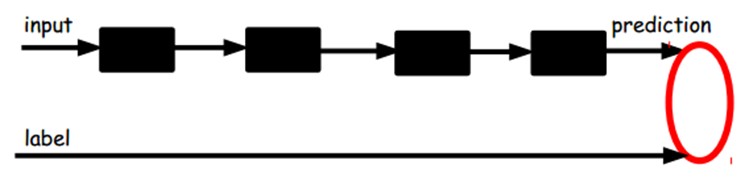
一旦监督训练完成,这个网络就可以用来分类了。神经网络的最顶层可以作为一个线性分类器,然后我们可以用一个更好性能的分类器去取代它。
二、AutoEncoder算法步骤
1)求各神经层的激活值
2)计算W和B的残差,用梯度下降法更新W和B,使输出不断接近输入
这个“神经元”是一个以  及截距
及截距  为输入值的运算单元,其输出为
为输入值的运算单元,其输出为  ,其中函数
,其中函数  被称为“激活函数”。在本教程中,我们选用sigmoid函数作为激活函数
被称为“激活函数”。在本教程中,我们选用sigmoid函数作为激活函数 

可以看出,这个单一“神经元”的输入-输出映射关系其实就是一个逻辑回归(logistic regression)。
虽然本系列教程采用sigmoid函数,但你也可以选择双曲正切函数(tanh):

以下分别是sigmoid及tanh的函数图像


 函数是sigmoid函数的一种变体,它的取值范围为
函数是sigmoid函数的一种变体,它的取值范围为 ![\textstyle [-1,1]](https://i-blog.csdnimg.cn/blog_migrate/48206c1bfeae599afe99ca87f92bbb9e.png) ,而不是sigmoid函数的
,而不是sigmoid函数的 ![\textstyle [0,1]](https://i-blog.csdnimg.cn/blog_migrate/cba90ef16cbed41127ea3456127d0a09.png) 。
。
注意,这里我们不再令  。取而代之,我们用单独的参数
。取而代之,我们用单独的参数  来表示截距。
来表示截距。
最后要说明的是,有一个等式我们以后会经常用到:如果选择  ,也就是sigmoid函数,那么它的导数就是
,也就是sigmoid函数,那么它的导数就是
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1751
1751











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









