







前言
在知乎上看到这样一段话:
为什么需要Collection
Java是一门面向对象的语言,就免不了处理对象
为了方便操作多个对象,那么我们就得把这多个对象存储起来
想要存储多个对象(变量),很容易就能想到一个容器
常用的容器我们知道有–>StringBuffered,数组(虽然有对象数组,但是数组的长度是不可变的!)
所以,Java就为我们提供了集合(Collection)~
前面学习List时查找到的好文章
Set集合实际上就是HashMap来构建的,就先搞懂Map
跟随大佬的脚步
Map(映射)
Collection叫做集合,它可以快速查找现有的元素
Map叫做映射,就和数学的映射一样,通过key可以得到value
而且也是键(key)与值(value)一 一对应的
可以看出两者的主要区别:Collection中存储了一组对象,而Map存储键/值对
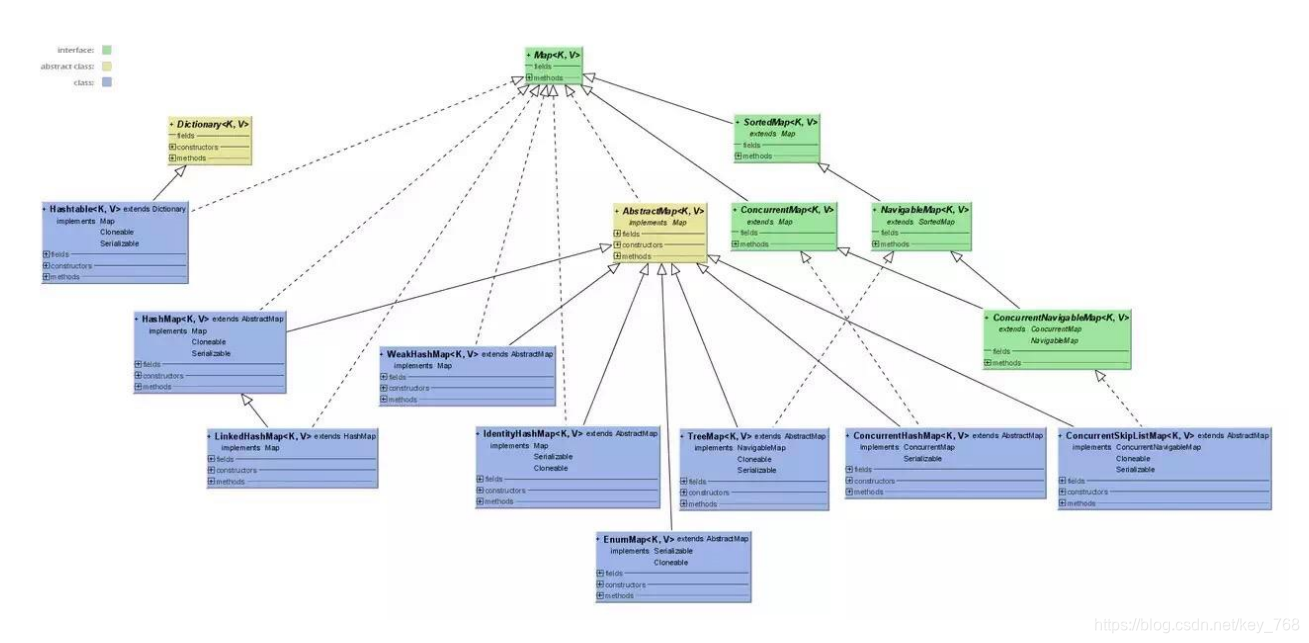
Map没有继承Collection接口

Map的常用方法
//构造方法
Map map = new HashMap();
//1.增加元素
map.put(key,"value");
//2.通过key查找元素
map.get(key);
//3.修改元素
map.replace(key,"oldValue","newValue");
//4.通过key删除元素
map.remove(key);
//5.查找所有键和值
Object key = map.keySet();
Object value = map.values();
//6.删除所有键和值
map.clear();
Map有5个子类:

HashMap(数组+链表+红黑树)
里面还有很多知识点需要学习
HashMap 根据键的 hashCode 值存储数据,大多数情况下可以直接定位到它的值,因而具有很快的访问速度,但遍历顺序却是不确定的
要理解需要一定的数据结构知识:HashCode(散列码)、红黑树(Red Black Tree) 是一种自平衡二叉查找树(具体还是查找大佬的解释)
散列表:不在意元素的顺序,能够快速的查找元素的数据
散列码:散列表为每个对象计算出的一个整数,让同一个类的对象按照自己不同的特征尽量的有不同的散列码
根据这些计算出来的整数(散列码)保存在对应的位置上,所以说遍历顺序是不确定的
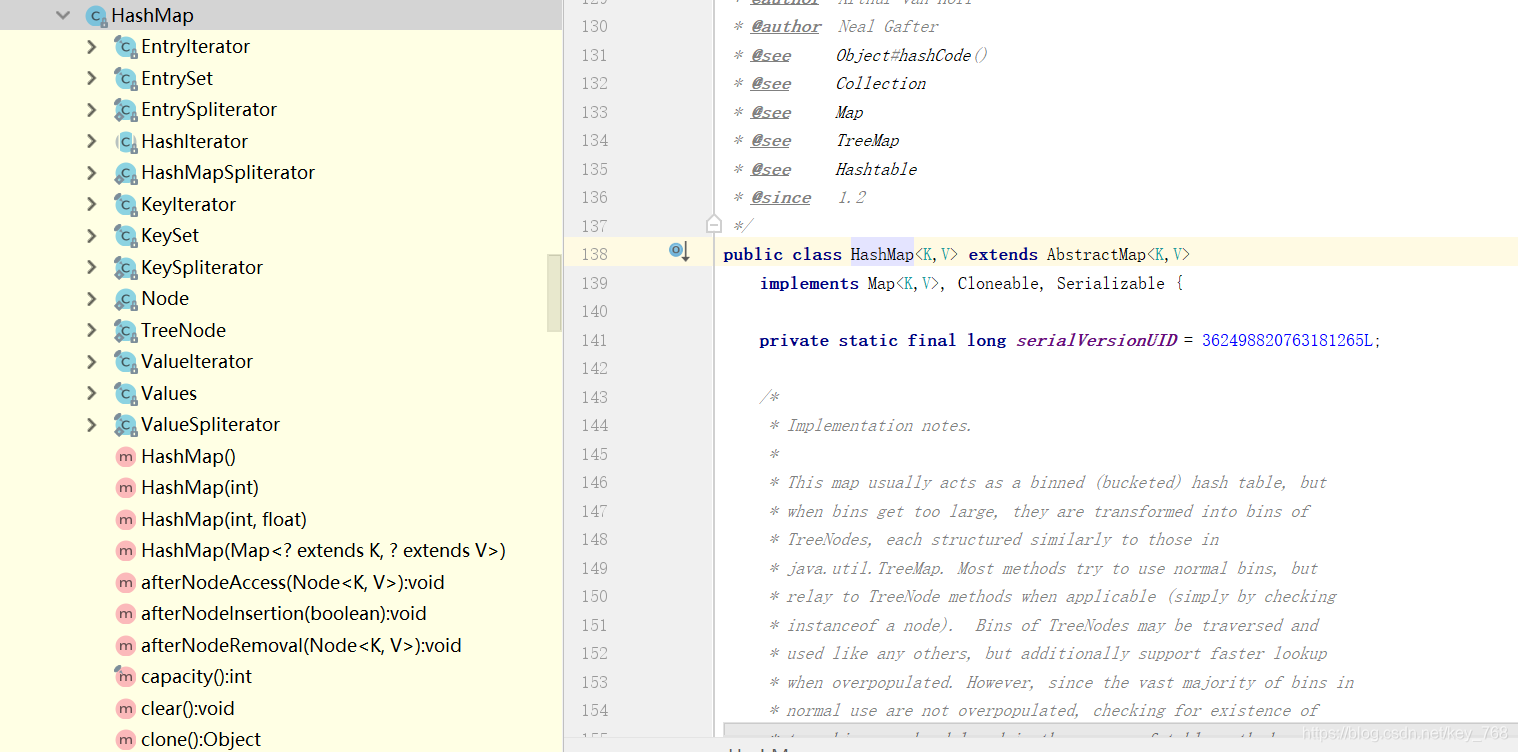 HashMap详解
HashMap详解
总结HashMap:
无序,允许为null,非同步
底层由散列表(哈希表)实现
初始容量和装载因子对HashMap影响挺大的,设置小了不好,设置大了也不好
四个构造方法对应不同情况:
 put方法:
put方法:
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
调用putVal方法,以hash()方法计算散列码,传入key、value
具体的putVal方法:
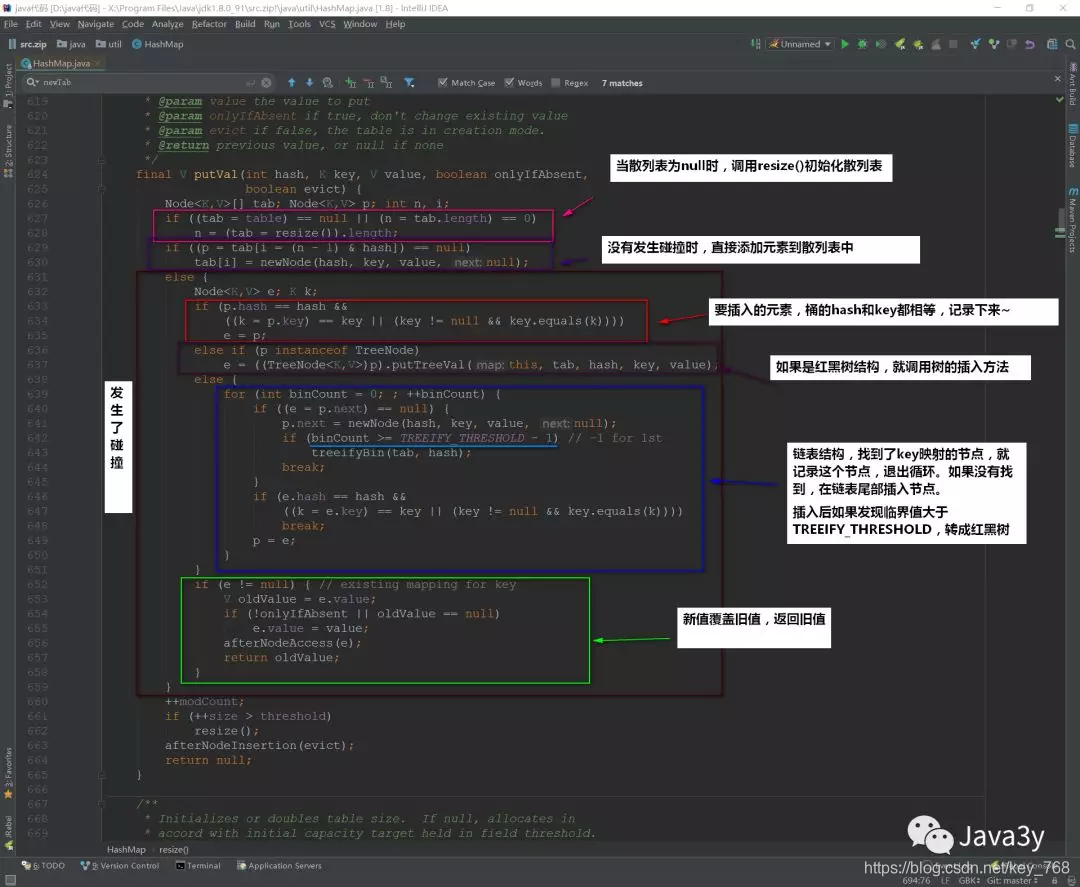 小结:
小结:
JDK8中HashMap由 数组+链表(散列表)+红黑树 组成
根据 hash 值我们能够快速定位到数组的具体下标,但是之后的话,需要顺着链表一个个比较下去才能找到我们需要的,时间复杂度取决于链表的长度,为 O(n)。
为了降低这部分的开销,在 JDK8 中,当链表中的元素超过了 8 个同时满足散列表容量大于64以后,会将链表转换为红黑树,在这些位置进行查找的时候可以降低时间复杂度为 O(logN)
在散列表中有装载因子这么一个属性,当装载因子*初始容量小于散列表元素时,该散列表会再散列,扩容2倍!
装载因子的默认值是0.75,无论是初始大了还是初始小了对我们HashMap的性能都不好
装载因子初始值大了,可以减少散列表再散列(扩容的次数),但同时会导致散列冲突的可能性变大(散列冲突也是耗性能的一个操作,要得操作链表(红黑树)!
装载因子初始值小了,可以减小散列冲突的可能性,但同时扩容的次数可能就会变多!
初始容量的默认值是16,它也一样,无论初始大了还是小了,对我们的HashMap都是有影响的:
初始容量过大,那么遍历时我们的速度就会受影响~
初始容量过小,散列表再散列(扩容的次数)可能就变得多,扩容也是一件非常耗费性能的一件事~
从源码上我们可以发现:HashMap并不是直接拿key的哈希值来用的,它会将key的哈希值的高16位进行异或操作,使得我们将元素放入哈希表的时候增加了一定的随机性
ConcurrentHashMap
ConcurrentHashMap详解
ConCurrentHashMap的底层是:散列表+红黑树,与HashMap是一样的,但是因为它支持并发操作,所以要复杂一
些
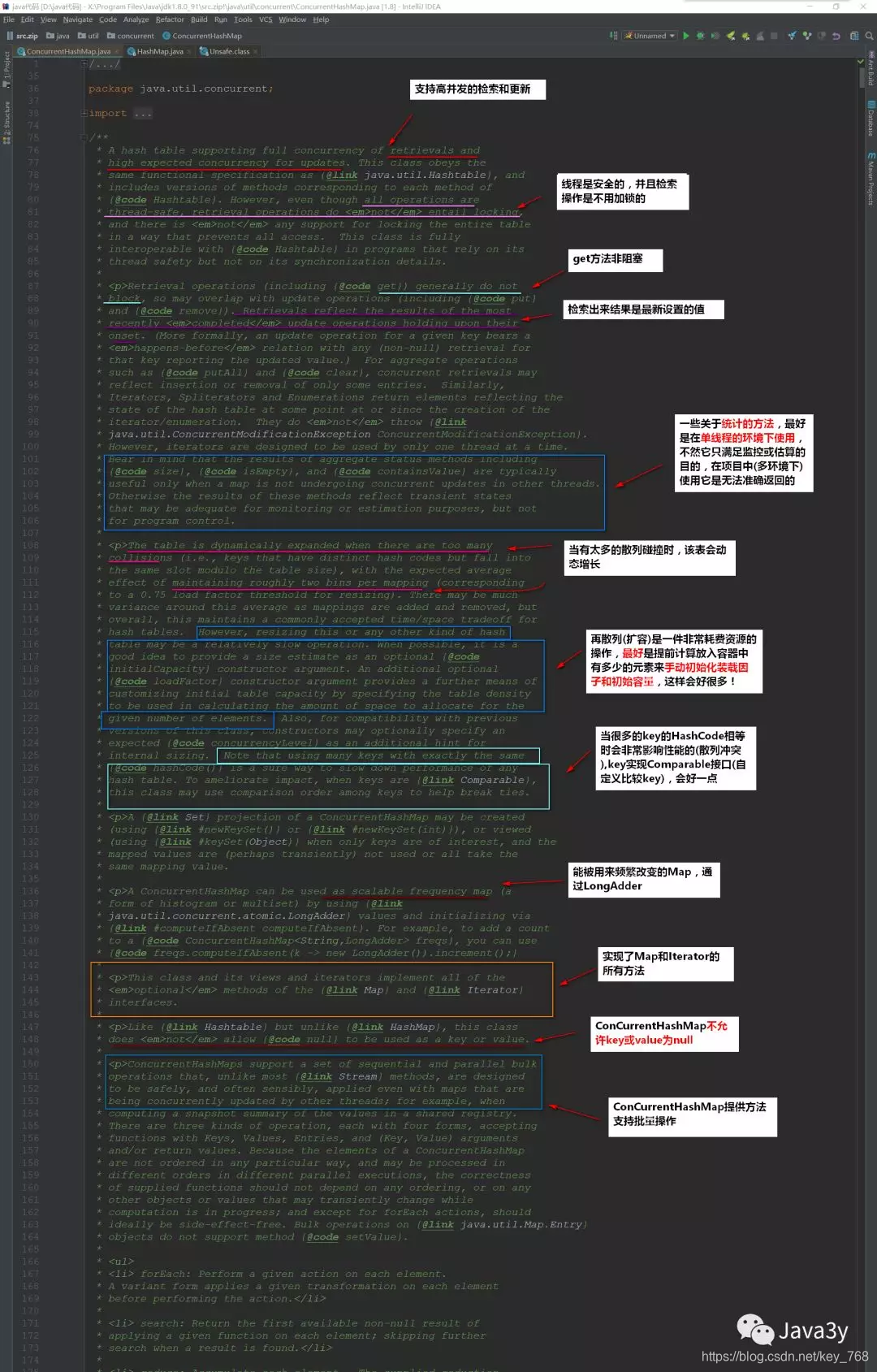
ConcurrentHashMap的核心要点:
-
底层结构是散列表(数组+链表)+红黑树,这一点和HashMap是一样的。
-
Hashtable是将所有的方法进行同步,效率低下。而ConcurrentHashMap作为一个高并发的容器,它是通过部分锁定+CAS算法来进行实现线程安全的。CAS算法也可以认为是乐观锁的一种~
-
在高并发环境下,统计数据(计算size…等等)其实是无意义的,因为在下一时刻size值就变化了。
-
get方法是非阻塞,无锁的。重写Node类,通过volatile修饰next来实现每次获取都是最新设置的值
-
ConcurrentHashMap的key和Value都不能为null
ConcurrentHashMap与HashMap的使用方法大致相同
两者的最大的区别在于线程安全性:ConcurrentHashMap对整个桶数组进行了分段,在每一个分段上都用锁进行保护,从而让锁的粒度更精细一些,并发性能更好,而HashMap没有锁机制,不是线程安全的
HashTable(线程安全)-不建议用
不需要线程安全的场合可以用 HashMap 替换,需要线程安全的场合可以用 ConcurrentHashMap 替换
TreeMap(可排序)
TreeMap详解
TreeMap 实现 SortedMap 接口,能够把它保存的记录根据键排序,默认是按键值的升序排序,也可以指定排序的比较器,当用 Iterator 遍历 TreeMap 时,得到的记录是排过序的。
如果使用排序的映射,建议使用 TreeMap。
在使用 TreeMap 时,key 必须实现 Comparable 接口或者在构造 TreeMap 传入自定义的Comparator,否则会在运行时抛出java.lang.ClassCastException 类型的异常。
TreeMap的方法:
- 构造方法(排序比较器):可以自己写排序的比较方法

//TreeMap的构造方法2,创建一个空TreeMap,按照指定的comparator排序
TreeMap<Integer, String> treeMap = new TreeMap<>(Comparator.reverseOrder());
- 插入方法put(K key, V value)
想要key为自定义类型,需要在构造时使用类型和排序比较器
key为Integer,按照数字升序排序,为String,按照字母表排序
treeMap.put(1,"hello");
System.out.println(treeMap);
//显示:{1=hello}
TreeMap要点:
-
由于底层是红黑树,那么时间复杂度可以保证为log(n)
-
key不能为null,为null为抛出NullPointException的
-
想要自定义比较,在构造方法中传入Comparator对象,否则使用key的自然排序来进行比较
-
TreeMap非同步的,想要同步可以使用Collections来进行封装
LinkedHashMap
LinkedHashMap详解
这个解释也挺好的
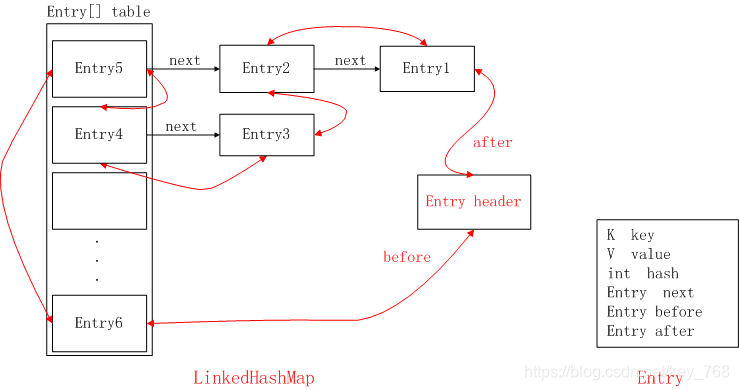
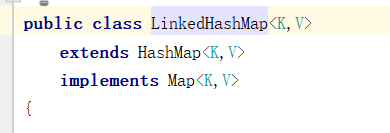
首先LinkedHashMap继承了HashMap,与HashMap相似
 LinkedHashMap比HashMap多了一个双向链表的维护,在数据结构而言它要复杂一些
LinkedHashMap比HashMap多了一个双向链表的维护,在数据结构而言它要复杂一些
LinkedHashMap里的排序:
构造方法中accessOrder =false表示采用插入排序(默认插入排序):
public LinkedHashMap() {
// 调用HashMap的构造方法,其实就是初始化Entry[] table
super();
// 这里是指是否基于访问排序,默认为false
accessOrder = false;
}
插入排序:
LinkedHashMap<String,String> linkedHashMap=new LinkedHashMap<>();
linkedHashMap.put("name1","zhangsan");
linkedHashMap.put("name2","lisi");
linkedHashMap.put("name3","wangwu");
System.out.println(linkedHashMap);
linkedHashMap.get("name1");
System.out.print(linkedHashMap);
尽管后面get(“name1”)访问过一次,排序依然不变

访问排序
LinkedHashMap3参数构造方法:initialCapacity(初始容量)、loadFactor(装载因子)、accessOrder(排序方式)
LinkedHashMap<String,String> linkedHashMap=new LinkedHashMap<>(16,0.75f,true);
linkedHashMap.put("name1","zhangsan");
linkedHashMap.put("name2","lisi");
linkedHashMap.put("name3","wangwu");
System.out.println(linkedHashMap);
linkedHashMap.get("name1");
System.out.print(linkedHashMap);
get(“name1”)访问了一次,访问排序把name1对应的Entry放到了表尾

小结:
- LinkedHashMap是继承于HashMap,是基于HashMap和双向链表来实现的。
- HashMap无序;LinkedHashMap有序,可分为插入顺序和访问顺序两种。如果是访问顺序,那put和get操作已存在的Entry时,都会把Entry移动到双向链表的表尾(其实是先删除再插入)。默认是插入顺序
- LinkedHashMap存取数据,还是跟HashMap一样使用的Entry[]的方式,双向链表只是为了保证顺序。
- LinkedHashMap是线程不安全的。
总结
Map的五个子类
- HashMap有数组+链表(散列表)+红黑树,根据键的hashCode存储数据有较快的访问速度,较常用
- ConcurrentHashMap与HashMap相似,但是支持并发操作,线程安全,比较复杂,速度较慢
- TreeMap底层是红黑树,可以按键值的升序排序,也可以指定排序的比较器
- LinkedHashMap继承HashMap,基于HashMap+双链表,有序,可分为插入顺序和访问顺序两种,遍历的时候会比HashMap慢
- HashTable:不需要线程安全的场合可以用 HashMap 替换,需要线程安全的场合可以用 ConcurrentHashMap 替换,HashTable不推荐用
在学习过程中,需要翻看源码,多查找学习,尽管一知半解,还是感觉懂了一些















 6221
6221











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









