







 本文介绍了基于知识图谱的问答系统(KBQA)原理和流程,包括实体检测、目的获取、关系预测和查询构建。知识图谱是Google提出的用于增强搜索引擎功能的数据结构,通过RDF数据模型表示。文中通过诗词问答的实例,展示了如何使用D2RQ和Apache Jena的TDB、Fuseki进行数据映射和SPARQL查询。最后,讨论了KBQA在实际项目中的优缺点。
本文介绍了基于知识图谱的问答系统(KBQA)原理和流程,包括实体检测、目的获取、关系预测和查询构建。知识图谱是Google提出的用于增强搜索引擎功能的数据结构,通过RDF数据模型表示。文中通过诗词问答的实例,展示了如何使用D2RQ和Apache Jena的TDB、Fuseki进行数据映射和SPARQL查询。最后,讨论了KBQA在实际项目中的优缺点。
最近因为工作原因暂时停止机器学习方面知识的学习,研究了一段KBQA。,下面是一个简单的关于中小学生需要掌握的诗词的demo,各位看官有兴趣的可以瞅瞅,欢迎来信一起交流。

1. 原理
KBQA简单讲就是将问题带入提前准备好的知识库寻求答案的一种基于知识库的问答系统。该问答系统可以解析输入的自然语言问句,主要运用REFO库的对象正则表达式匹配得到结果,然后利用对应的SPARQL查询语句,请求后台基于TDB知识谱图数据库的服务,最终得到我们想要的结果。
2. 流程
1.实体检测,获取问题的关键词,比如问题“李白写了哪些诗?”,那么首先必须找到李白,才可以进行下一步。
2.目的获取,一个问题,我们只获取了实体还不够,比如上面,只有李白,还要有目的,不然可能我是想问李白是哪个朝代的人,哪里的人等等,所以需要找到问题的真实目的。
3.关系预测,有了实体和目的,那么我们就需要在知识库里面寻找双方的关系,想办法联系起来。
4.查询构建,将处理好的三元组带入知识库搜索答案。
3. 知识图谱
1.介绍
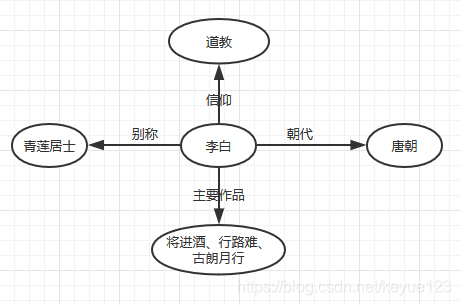
知识图谱由google于2012年率先提出,其初衷是用以增强自家的搜索引擎的功能和提高搜索结果质量,使得用户无需通过点击多个连接就可以获取结构化的搜索结果,并且提供一定的推理功能。这里我还是用《将进酒》这首诗举个例子,很多人看到《将进酒》,估计第一时间想不到这是哪个年代的诗歌,但是不妨看看作者,李白,很多人对李白就比较耳熟能详了,那么就来了,很多人都知道李白是唐朝人(这里假设没人不知道哈),那么自然而然就知道《将进酒》这首诗写在唐朝了。说了这些,我们发现,如果知识库里面有这些信息,那么就很容易找到答案。如果我们再多加一些相关属性,就可以构成一张简单的知识图了,如下图,具体的我就不描述了,大家可以看看知识图谱介绍这篇文章,讲述的非常明白,我就不在关公门前耍大刀了。
2. 数据格式
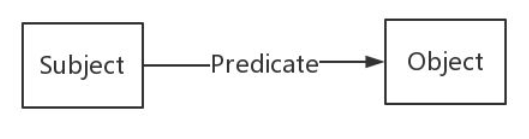
在知识图谱中,数据一般以RDF形式的三元组表示。
RDF(Resource Description Framework)即资源描述框架,其本质是一个数据模型。它提供了一个统一的标准,用于描述实体/资源。简单来说,就是表示事物的一种方法和手段。RDF形式上表示为SPO三元组,知识图谱中我们也称其为一条知识。RDF由节点和边组成,节点表示实体/资源、属性,边则表示了实体和实体之间的关系以及实体和属性的关系。如下图所示:
RDF数据集方式主要有以下几种,主要使用Turtle。
1、RDF/XML,用XML的格式来表示RDF数据。之所以提出这个方法,是因为XML的技术比较成熟,有许多现成的工具来存储和解析XML。然而,对于RDF来说,XML的格式太冗长,也不便于阅读,通常我们不会使用这种方式来处理RDF数据。
2、N-Triples,即用多个三元组来表示RDF数据集,是最直观的表示方法。在文件中,每一行表示一个三元组,方便机器解析和处理。开放领域知识图谱DBpedia通常是用这种格式来发布数据的。
3、Turtle, 应该是使用得最多的一种RDF序列化方式了。它比RDF/XML紧凑,且可读性比N-Triples好。
4、RDFa, 是HTML5的一个扩展,在不改变任何显示效果的情况下,让网站构建者能够在页面中标记实体,像人物、地点、时间、评论等等。也就是说,将RDF数据嵌入到网页中,搜索引擎能够更好的解析非结构化页面,获取一些有用的结构化信息。
5、JSON-LD,用键值对的方式来存储RDF数据。
但是RDF的表达能力有限,无法区分类和对象,也无法定义和描述类的关系/属性,这个时候就有人提出RDFS和OWL这两种技术或者说模式语言/本体语言来解决了RDF表达能力有限的困境,详细介绍参考知识图谱基础之RDF,RDFS与OWL。后面的实例分析就是使用OWL来存储数据。
4. 实例分析
知识图谱这个专栏讲的非常详细,我也是参考这位前辈的专栏实现的小demo,所以我就不在这里花过多的时间描述相关方面的知识了,避免理解错误,误导大家。下面就直接开始我自己的实例。本demo实现是为了展示知识图谱,所以将数据分开,其实也可以直接将诗词名、作者、朝代、诗词内容放在一起,全部作为属性,不需要在SQL中创建多个数据表,所以希望大家不要觉得麻烦,感兴趣的可以使用一张表试着做一下。
-
数据准备
数据是中小学必背诗词,其中信息有诗词名、作者、朝代、诗词内容。
作者信息:姓名、朝代
诗词信息:诗词名、诗词内容
诗句使用scrapy在百度上爬取,如果想自己动手的,可以参考一下前面的博客scrapy学习(一):scrapy框架(爬古诗词)。 -
数据建模
这步是非必须的,但是为了后面数据映射更容易理解,我还是在这里简述一下。构建数据结构一般使用工具protégé,构建过程参考本体建模,根据我们自己的功能需要,创建三个类Poem(诗词)、Poet(诗人)、Verse(诗句):
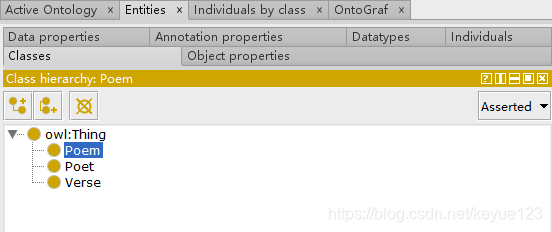
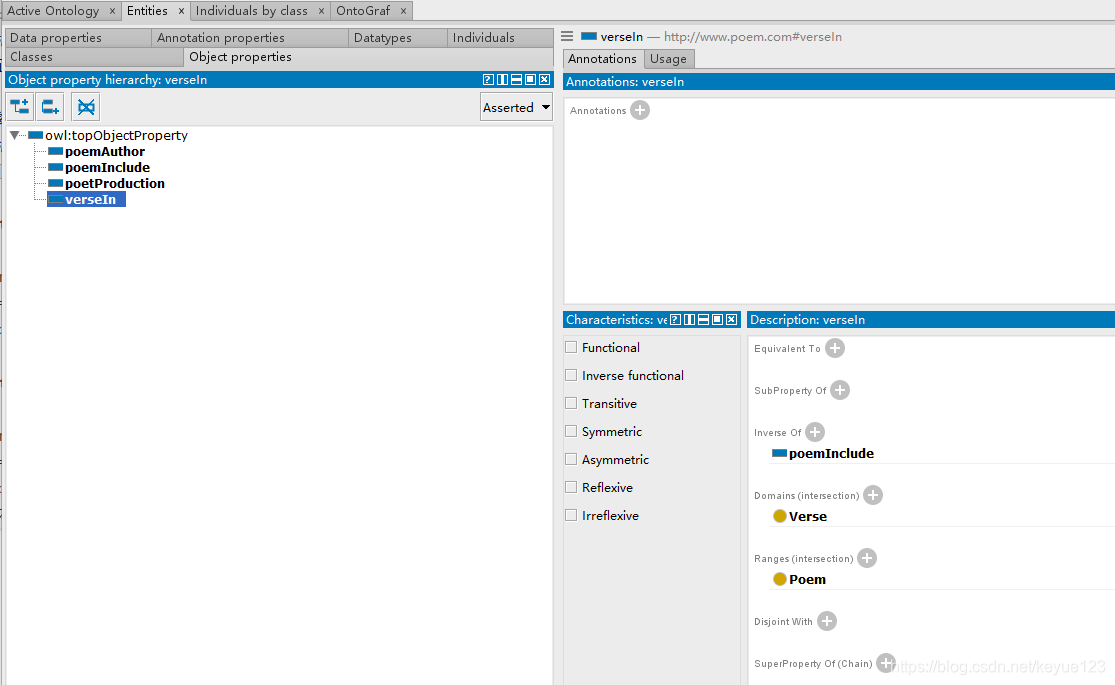
上面的类和推理都创建好了,接下来就需要定义每个类里面的属性:poemContent(诗词内容)、poemName(诗词名)、poetDynasty(诗人朝代)、poetName(诗人名)、sentenceId(诗句ID)、verseId(诗词ID)、sentenceContent(诗句内容)、verseLen(诗词长度)。同样右下角也需要定义属性,Domain为属于哪个类,Range与前面关系的Domain有区别,这里表示的是数据类型。
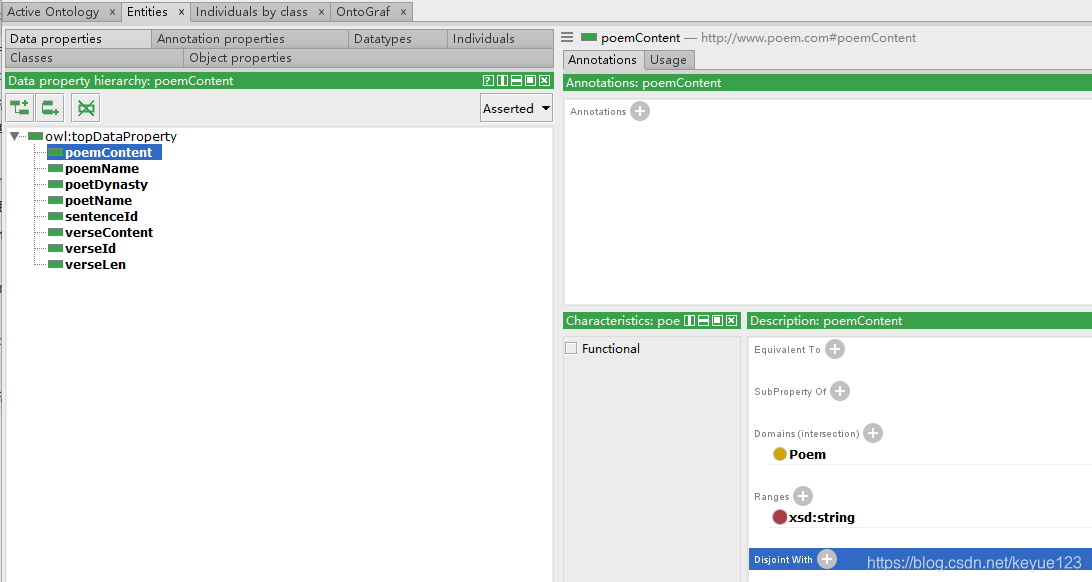
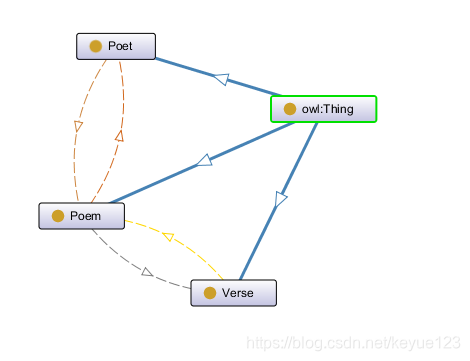
类、关系、属性都定义好之后,就组成了一个简单的数据模型,点击"Window–>Tabs–>OntoGraf",就可以在protégé中很明了的看出相互之间的关系。
将我们构建好的关系导出备用,导出格式如下,文件名随意,我这里取为poem_kbqa.owl
- 数据映射
现在数据有了,关系也有了,如何将两者联系起来呢,我们以mysql中的诗词名为例,将poem这个表映射到我们在protege中定义的Peom类上,poem title映射到poemName上。
map:poem a d2rq:ClassMap;
d2rq:dataStorage map:database;
d2rq:uriPattern "poem/@@poem.poem_id@@";
d2rq:class :Poem; # 类名
d2rq:classDefinitionLabel "poem"; # sql数据表
.
map:poem_title a d2rq:PropertyBridge;
d2rq 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 567
567

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









