






难产的笔记。。。本来打算用1天 结果前前后后拖了5天
§9.1 静态查找表
9.1.1 顺序表的查找
各种扫 自己脑补吧 复杂度O(n)
9.1.2 有序表的查找
若表是单调的,则可以利用二分查找。复杂度O(logn)
9.1.3 静态树表的查找
见
http://blog.csdn.net/area_52/article/details/43795837
9.1.4 索引顺序表的查找
建立索引表查找
§9.2 动态查找表
动态查找表的特点是,表结构本身是在查找过程中动态生成的,即对于给定值key,若表中存在其关键字等于key的记录,则查找成功返回,否则插入关键字等于key的记录。
9.2.1 二叉排序树和平衡二叉树
①二叉排序树及其查找过程
二叉排序树(BST)或者是一棵空树;或者是具有下列性质的二叉树:
⑴若它的左子树不空,则左子树上所有节点的值均小于它的根结点的值
⑵若它的右子树不空,则右子树上所有节点的值均大于它的根结点的值
⑶它的左右子树也分别为二叉排序树
查找代码如下
<code class=" hljs java"><span class="hljs-javadoc">/** 递归实现二叉搜索树的查找操作Find */</span>
Position Find( ElementType X,BinTree BST)
{
<span class="hljs-keyword">if</span>(!BST) <span class="hljs-keyword">return</span> NULL;<span class="hljs-comment">//空树</span>
<span class="hljs-keyword">if</span>(X > BST->Data) <span class="hljs-keyword">return</span> Find(X,BST->Right);
<span class="hljs-keyword">if</span>(X < BST->Data) <span class="hljs-keyword">return</span> Find(X,BST->Left);
<span class="hljs-keyword">return</span> BST;<span class="hljs-javadoc">/**找到了*/</span>
}</code>
<code class=" hljs java"><span class="hljs-javadoc">/** 迭代实现二叉搜索树的查找操作Find */</span>
Position Find( ElementType X,BinTree BST)
{
<span class="hljs-keyword">while</span>(BST) {
<span class="hljs-keyword">if</span>(X > BST->Data) {
BST = BST->Right;
}<span class="hljs-keyword">else</span> <span class="hljs-keyword">if</span>(X < BST->Data) {
BST = BST->Left;
}<span class="hljs-keyword">else</span> <span class="hljs-keyword">return</span> BST;<span class="hljs-comment">//找到了</span>
}
<span class="hljs-keyword">return</span> NULL;<span class="hljs-comment">//查找失败</span>
}</code>
<code class=" hljs java"><span class="hljs-javadoc">/** 递归找二叉搜索树元素最小值 */</span>
Position FindMin( BinTree BST )
{
<span class="hljs-keyword">if</span>(!BST) <span class="hljs-keyword">return</span> NULL;
<span class="hljs-keyword">else</span> <span class="hljs-keyword">if</span>(!BST->Left)
<span class="hljs-keyword">return</span> BST;<span class="hljs-comment">//如果没有左孩子就是最小值</span>
<span class="hljs-keyword">else</span> <span class="hljs-keyword">return</span> FindMin( BST->Left );<span class="hljs-comment">//沿左分支继续查找</span>
}</code>
<code class=" hljs java"><span class="hljs-javadoc">/** 迭代找二叉搜索树元素最大值 */</span>
Position FindMax( BinTree BST )
{
<span class="hljs-keyword">if</span>( BST ) {
<span class="hljs-keyword">while</span>(BST->Right) BST = BST->Right;
}
<span class="hljs-keyword">return</span> BST;
}</code>
②二叉排序树的插入和删除
⑴BST中结点的插入
新插入的结点一定是一个新添加的叶子结点,并且是查找不成功时查找路径上访问的最后一个结点的左孩子或者右孩子。因此把查找算法改一下就可以了。
一个无序序列可以通过构造一棵二叉排序树而变成一个有序序列,构造树的过程即为对无序序列进行排序的过程。
⑶BST中结点的删除
分三种情况处理:
1.删除的是叶子结点,那么直接删除即可。
2.删除的结点只有左子树或右子树,那么直接删除然后把子树放到它父亲上即可。
3.删除的结点左子树和右子树均不空。有两种做法,一是左子树接上来,右子树放到左子树的最右边。二是用直接前驱(后继)代替它,然后删除它的直接前驱(后继)(具体见P230)
删除的代码如下
<code class=" hljs lasso">Status DeleteBST(BiTree <span class="hljs-subst">&</span>T, KeyType key)
{
<span class="hljs-comment">//若二叉排序树T中存在关键字等于key的数据元素时,</span>
<span class="hljs-comment">//则删除该数据元素结点,并返回TRUE,否则返回FALSE</span>
<span class="hljs-keyword">if</span>(<span class="hljs-subst">!</span>T) <span class="hljs-keyword">return</span> <span class="hljs-literal">FALSE</span>;<span class="hljs-comment">//不存在关键字等于key的数据元素</span>
<span class="hljs-keyword">if</span>(<span class="hljs-literal">EQ</span>(key,T<span class="hljs-subst">-></span><span class="hljs-built_in">data</span><span class="hljs-built_in">.</span>key)) <span class="hljs-keyword">return</span> Delete(T);<span class="hljs-comment">//找到关键字等于key的数据元素</span>
<span class="hljs-keyword">else</span> <span class="hljs-keyword">if</span>(<span class="hljs-literal">LT</span>(key,T<span class="hljs-subst">-></span><span class="hljs-built_in">data</span><span class="hljs-built_in">.</span>key)) <span class="hljs-keyword">return</span> DeleteBST(T<span class="hljs-subst">-></span>lchild,key);
<span class="hljs-keyword">else</span> <span class="hljs-keyword">return</span> DeleteBST(T<span class="hljs-subst">-></span>rchild,key);
}
Status Delete(BiTree <span class="hljs-subst">&</span>p)
{
<span class="hljs-comment">//从二叉排序树中删除结点p,并重接它的左子树或右子树</span>
<span class="hljs-keyword">if</span>(<span class="hljs-subst">!</span>p<span class="hljs-subst">-></span>rchild) {<span class="hljs-comment">//右子树空则只需要重接它的左子树</span>
q <span class="hljs-subst">=</span> p;
p <span class="hljs-subst">=</span> p<span class="hljs-subst">-></span>lchild;
free(q);
}<span class="hljs-keyword">else</span> <span class="hljs-keyword">if</span>(<span class="hljs-subst">!</span>p<span class="hljs-subst">-></span>lchild) {<span class="hljs-comment">//只需重接它的右子树</span>
q <span class="hljs-subst">=</span> p;
p <span class="hljs-subst">=</span> p<span class="hljs-subst">-></span>rchild;
free(q);
}<span class="hljs-keyword">else</span> {<span class="hljs-comment">//左右子树都不空</span>
q <span class="hljs-subst">=</span> p;
s <span class="hljs-subst">=</span> p<span class="hljs-subst">-></span>lchild;
<span class="hljs-keyword">while</span>(s<span class="hljs-subst">-></span>rchild) {<span class="hljs-comment">//转左,然后向右到尽头</span>
q <span class="hljs-subst">=</span> s;
s <span class="hljs-subst">=</span> s<span class="hljs-subst">-></span>rchild;
}
p <span class="hljs-subst">-></span><span class="hljs-built_in">data</span> <span class="hljs-subst">=</span> s <span class="hljs-subst">-></span><span class="hljs-built_in">data</span>;<span class="hljs-comment">//s指向被删除结点的前驱</span>
<span class="hljs-keyword">if</span>(q <span class="hljs-subst">!=</span> p) q <span class="hljs-subst">-></span>rchild <span class="hljs-subst">=</span> s<span class="hljs-subst">-></span>lchild;<span class="hljs-comment">//重接*q的右子树</span>
<span class="hljs-keyword">else</span> q <span class="hljs-subst">-> </span>lchild <span class="hljs-subst">=</span> s <span class="hljs-subst">-> </span>lchild; <span class="hljs-comment">//重接*q的左子树</span>
delete s;
}
<span class="hljs-keyword">return</span> <span class="hljs-literal">TRUE</span>;
}</code>
③二叉排序树的查找分析
对ASL的计算发现,如果二叉树趋于”平衡”,那么它的ASL就可以有效降低,效率提高。在某些情况下,尚需在构成二叉排序树的过程中进行”平衡化”处理,称为二叉平衡树。
④平衡二叉树(AVL树)
平衡二叉树又称AVL树。它或者是一棵空树,或者是具有下列性质的二叉树:它的左子树和右子树都是平衡二叉树,且左子树和右子树的深度之差的绝对值不超过1。
若将二叉树上结点的平衡因子BF定义为该结点的左子树的深度减去它的右子树的深度,则平衡二叉树上所有结点的平衡因子只可能是-1,0,1。只要二叉树上有一个结点的平衡因子的绝对值大于1,则该二叉树就是不平衡的。
n层的AVL树的最小结点数符合类斐波那契。
1层的AVL树最小需要1个结点,2层的AVL树最小需要2个结点,3层的至少需要4个结点,4层的最小需要7个结点…
以此类推n层的最少结点=(n-1)层最少结点+(n-2)层最少结点+1
在AVL树中,插入一个新结点很有可能意味着失去平衡。在这种情况下要找出失去平衡的最小树根结点的指针,然后再调整这个子树中有关结点之间的链接关系,使之成为新的平衡子树。当失去平衡的最小子树被调整为平衡子树后,原有其他所有不平衡子树无序调整,整个二叉排序树就又成为一颗平衡二叉树。
失去平衡的最小子树是指以离插入节点最近且平衡因子异常(绝对值>1)的结点作为根的子树。
假设用A来表示失去平衡最小子树的根结点,则调整该子树的操作无外乎有下面4种情况
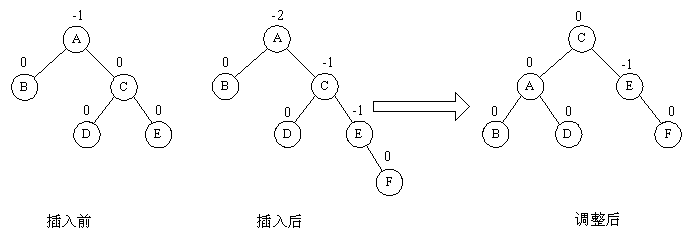
⑴RR旋转
新的结点插在了A的右子树的右子树上(不管插在左还是插在右),那么将A的右子树提上去当树根,原A的右子树的左子树插在A的右边。如图所示
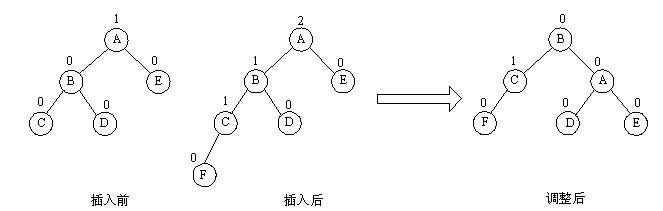
⑵LL旋转
新的结点插在了A的左子树的左子树上(不管插在左还是插在右),那么将A的左子树提上去当树根,原A的左子树的右子树拿到A的左子树上。如图所示
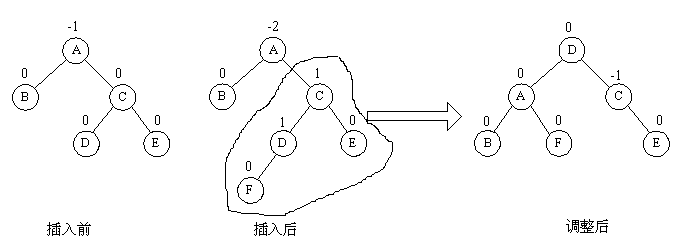
⑶RL旋转
新的结点插在了A的右子树的左子树上(不管插在左还是插在右),此时的重点是要把A C D三个结点调平衡。D是三个结点中中间大的,所以D去做树根,A做左子树,C做右子树。剩下的结点按照大小顺序找到位置即可。
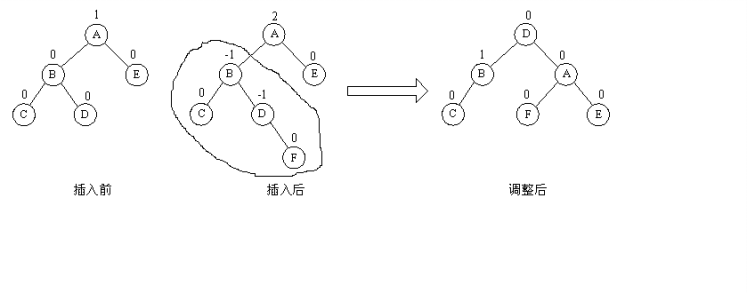
⑷LR旋转
新的结点插在了A的左子树的右子树上(不管插在左还是插在右),此时的重点是要把A B D三个结点调平衡。D是三个结点中中间大的,所以D去做树根,B做左子树,A做右子树。剩下的结点按照大小顺序找到位置即可。
⑤平衡树查找的分析
查找的时间复杂度为O(logn)
9.2.2 B-树和B+树
B树待补充….
①B-树及其查找
②B-树查找分析
③B-树的插入和删除
④B+树
9.2.3 键树
键树又称数字查找树(DST)。它是一棵度>=2的树,树中的每个节点中不是包含一个或几个关键字,而是只含有组成关键字的符号。
例如,若关键字是数值,则结点中只包含一个数位;若关键字是单词,则结点中只包含一个字母字符。
这种书会给某种类型关键字的查找带来方便。
如图就是一棵键树,从根到叶子结点路径中结点的字符组成的字符串表示一个关键字。
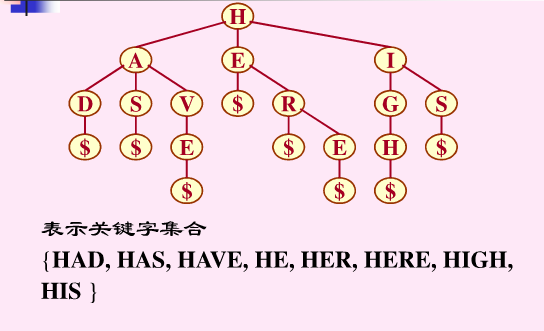
我们约定,键树是有序树
键树有两种存储结构,从而产生了两种键树
①孩子兄弟表示法的双链树
每个分支结点包括3个域
symbol域 存储关键字的一个字符。
first域 存储指向第一棵子树根的指针。
next域 存储指向右兄弟的指针。
同时,叶子结点的first域存储指向该关键字记录的指针。
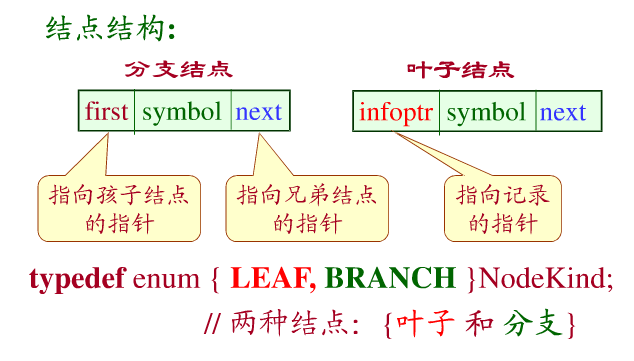
双链树的实现代码
<code class=" hljs cpp"><span class="hljs-preprocessor">#define MAXKEYLEN 16 <span class="hljs-comment">//关键字的最大长度</span></span>
<span class="hljs-keyword">typedef</span> <span class="hljs-keyword">struct</span> {
<span class="hljs-keyword">char</span> ch[MAXKEYLEN];<span class="hljs-comment">//关键字</span>
<span class="hljs-keyword">int</span> num;<span class="hljs-comment">//关键字长度</span>
}KeysType;<span class="hljs-comment">//关键字类型</span>
<span class="hljs-keyword">typedef</span> <span class="hljs-keyword">enum</span> {LEAF,BRANCH} NodeKind;<span class="hljs-comment">//结点种类:{叶子,分支}</span>
<span class="hljs-keyword">typedef</span> <span class="hljs-keyword">struct</span> DLTNode {
<span class="hljs-keyword">char</span> symbol;
<span class="hljs-keyword">struct</span> DLTNode *next;<span class="hljs-comment">//指向兄弟结点的指针</span>
NodeKind kind;
<span class="hljs-keyword">union</span> {
Record *infoptr;<span class="hljs-comment">//叶子结点的记录指针</span>
<span class="hljs-keyword">struct</span> DLTNode *first;<span class="hljs-comment">//分支结点的孩子链指针</span>
};
}DLTNode, *DLTree;<span class="hljs-comment">//双链树的类型</span></code>
双链树的查找代码
<code class=" hljs php">Record *SearchDLTree(DLTree T,KeysType K)
{
<span class="hljs-comment">//在非空双链树T中查找关键字等于K的记录,若存在,则</span>
<span class="hljs-comment">//返回指向该记录的指针,否则返回空指针</span>
p = T->first;
i = <span class="hljs-number">0</span>;<span class="hljs-comment">//初始化</span>
<span class="hljs-keyword">while</span>(p && i < K.num) {
<span class="hljs-keyword">while</span>(p && p -> symbol != K.ch[i]) p = p->next;<span class="hljs-comment">//查找关键字的第i位</span>
<span class="hljs-keyword">if</span>(p && i < K.num-<span class="hljs-number">1</span>) p = p->first;<span class="hljs-comment">//准备查找下一位</span>
++ i;
}<span class="hljs-comment">//查找结束</span>
<span class="hljs-keyword">if</span>(!p) <span class="hljs-keyword">return</span> <span class="hljs-keyword">NULL</span>;<span class="hljs-comment">//查找不成功</span>
<span class="hljs-keyword">else</span> <span class="hljs-keyword">return</span> p->infoptr;<span class="hljs-comment">//查找成功</span>
}<span class="hljs-comment">//Search DLTree</span></code>
键树中每个节点的最大度d和关键字的”基”有关,若关键字是单词,则d=27;若关键字是数值,则d=11。键树的深度h则取决于关键字中字符或数位的个数。
②多重链表表示的Trie树(字典树)
若以树的多重链表表示键树,则树的每个节点中应含有d个指针域,此时的键树又称Trie(读音同Try)树或前缀树。Trie树可以看做是确定有限状态的自动机。
如下图就是一个Trie树
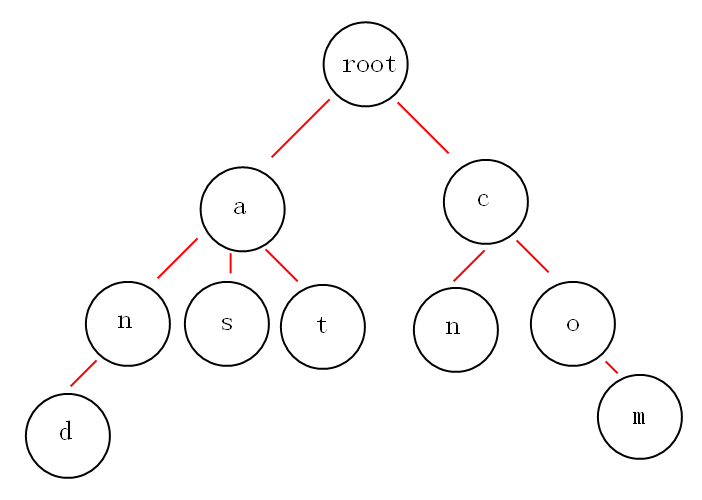
Trie树的性质:
①根节点不包含字符,除根节点外每一个节点都只包含一个字符。
②从根节点到某一节点,路径上经过的字符连接起来,为该节点对应的字符串。
③每个节点的所有子节点包含的字符都不相同。
在Trie树上进行查找的过程为:
从根结点出发,沿和给定值相应的指针逐层向下,直至叶子结点,若叶子结点中的关键字和给定值相等,则查找成功,若分支结点中和给定值相应的指针为空,则查找不成功。
查找算法代码如下
<code class=" hljs objectivec"><span class="hljs-keyword">typedef</span> <span class="hljs-keyword">struct</span> TrieNode {
NodeKind kind;
<span class="hljs-keyword">union</span> {
<span class="hljs-keyword">struct</span> {KeysType K; Record *infoptr;} lf;<span class="hljs-comment">//叶子结点</span>
<span class="hljs-keyword">struct</span> {TrieNode *ptr[<span class="hljs-number">27</span>]; <span class="hljs-keyword">int</span> num;} bh;<span class="hljs-comment">//分支结点</span>
};
}TrieNode, * TrieTree;
Record *SearchTrie(TrieTree T,KeysType K)
{
<span class="hljs-comment">//在字典树T中查找关键字等于K的记录</span>
<span class="hljs-keyword">for</span>(p = T,i = <span class="hljs-number">0</span>;<span class="hljs-comment">//对K的每个字符逐个查找</span>
p && p -> kind == BRANCH && i < K<span class="hljs-variable">.num</span>;<span class="hljs-comment">//*p为分支结点</span>
p = p->bh<span class="hljs-variable">.ptr</span>[ord(K<span class="hljs-variable">.ch</span>[i])], ++i;);<span class="hljs-comment">//ord求字符在字母表中序号</span>
<span class="hljs-keyword">if</span>(p && p->kind == LEAF && p->lf<span class="hljs-variable">.K</span> == K) <span class="hljs-keyword">return</span> p -> lf<span class="hljs-variable">.infoptr</span>;<span class="hljs-comment">//查找成功</span>
<span class="hljs-keyword">else</span> <span class="hljs-keyword">return</span> <span class="hljs-literal">NULL</span>;<span class="hljs-comment">//查找不成功</span>
}<span class="hljs-comment">//SearchTrie</span></code>
§9.3 哈希表
9.3.1 什么是哈希表
根据设定的哈希函数H(key)和处理冲突的方法将一组关键字映像到一个有限的连续的地址集(区间)上,并以关键字在地址集中的”像”作为记录在表中的存储位置,这种表变称为哈希表。这一映像过程称为哈希造表或散列,所得存储位置称哈希地址或散列地址。
9.3.2 哈希函数的构造方法
①直接定址法
取key或者key的某个线性函数值为哈希地址。即
H(key) = key 或 H(key) = A*key+B
直接定址法使用很少
②数字分析法
取key的若干数位组成哈希地址。(如身份证可以使用最后四位组成哈希地址)
③平方取中法
取key的平方的中间几位为哈希地址(具有随机性)
④折叠法
将key分割成位数相同的几部分(最后一部分的位数可以不同),然后取这几部分的叠加和作为哈希地址。
如H(123456) = 12+34+56 = 102 这样可以使每一位都对结果有影响,增加随机性
※⑤除留余数法
取关键字被某个不大于哈希表表长m的数p(通常取素数)除后所得余数为哈希地址。即
* H(key) = key%p(p<=m) *
⑥随机数法
通常用于key长度不等
9.3.3 处理冲突的方法
①开放定址法
即LOC = (H(key) + di)%m (i=1,2,…,m-1)
可以取
⑴线性探测再散列(最常用)
(di = 1,2,….,m-1)
⑵平方探测再散列
(di = 1^2,-1^2,2^2,-2^2,…,k^2,-k^2)(k<=m/2)
②再哈希法
在哈希函数寻址的基础上再建立一个哈希函数
Hi = RHi(key) i = 1,2,…,k
RHi均是不同的哈希函数,即在同义词产生地址冲突时计算另一个哈希函数地址,直到冲突不再发生。这种方法不易产生”聚集”,但增加了计算的时间。
③链地址法(拉链法) (第二常用)
为了可以重复放入,所有位置均为链表形式,初始状态是空指针,凡是哈希函数是i的记录都插入第i个链表的末尾。
△④建立一个公共溢出区
9.3.4 哈希表的查找及其分析
在哈希表上进行查找的过程和哈希造表的过程基本一致。
哈希表的装填因子α定义为
α = 表中填入的记录数/哈希表的长度
哈希表的平均查找长度时α的函数,而不是n的函数。由此,不管n多大,我们总可以选择一个合适的装填因子以便将平均查找长度限定在一个范围内。
【至此第9章整理完毕】















 2132
2132











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









