







首先是deploy.prototxt文件的生成,deploy.prototxt和train_val.prototxt文件类似,只是头尾有些区别而已。没有了第一层的数据层,也没有最后的accuracy层(用于反向传播),但最后多了一个Softmax概率层(Softmax直接计算前向的概率),所以deploy文件没有了反向传播部分。
一般不推荐用代码来生成,熟悉train_val.prototxt的可以将其复制一份进行相应的修改。
删除原有train_val.prototxt中开始用于训练的两个数据层,因为利用模型分类将不再需要用到标签数据:


为了使网络能够接受输入数据,添加如下的一个数据层(注意这里第三第四个dim和原有数据层的crop_size大小要一致):

删除train_val.prototxt中的Accuracy层:

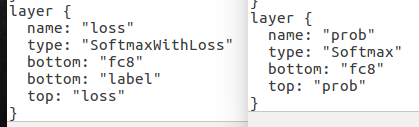
为了使网络能够输出正确的分类结果,将train_val.prototxt中原有的loss层改成Softmax,并把名字和输出改为prob:
编写好deploy文件后,就可以利用它还有我们训练好的caffemodel进行预测啦!
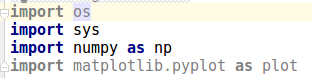
首先,导入各种库:
接着,设置caffe路径,并切换到CPU模式:

添加deploy和caffemodel的路径,以及很关键的均值文件ilsvrc_2012_mean.npy(这个是caffe自带的,所以这里的路径可以不用改),之后载入图片(这里需要注意的是caffe.io.load_image()载入图片文件时,内部已经除以255了,返回值是0到1之间的浮点数):

接下来就可以直接加载model和network,并设置图片的预处理操作,最后对输入图片执行预处理操作,载入到blob中:

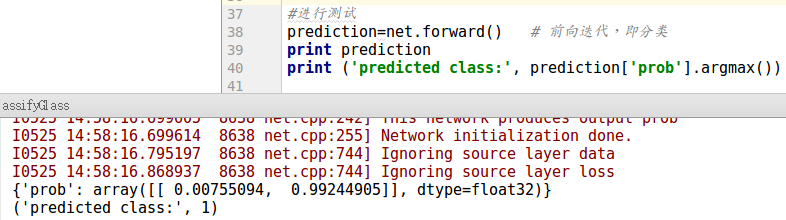
最后进行测试,测试结果如下(需要注意的是net.forward()返回的是字典,需要用prediction['prob']才能输出正确的分类标签):
后期为了对文件夹里面的数据进行分类,将整个预测框架封装成一个函数,对文件夹图片进行遍历预测,根据预测结果将图片分到不同文件夹:
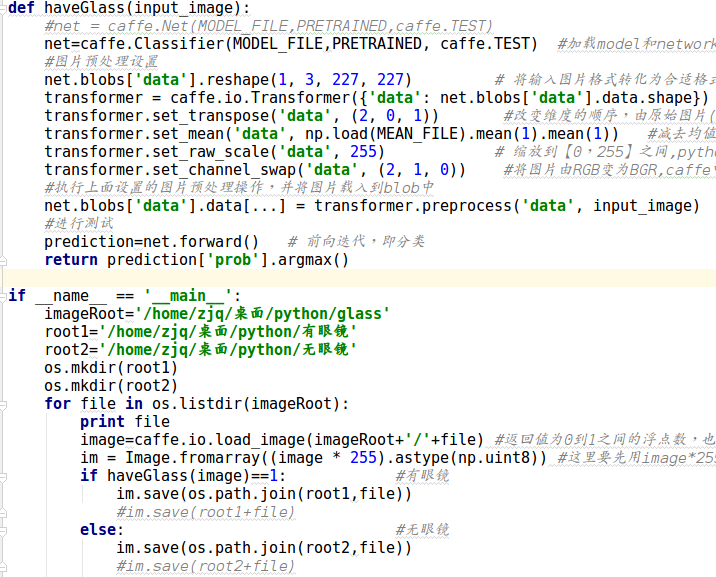
注意上面的 im = Image.fromarray((image * 255).astype(np.uint8)),因为caffe.io.load_image返回的image是[0,1]之间的浮点数,为了调用image.save()将图片保存至相应路径,需要先经过类型转换。先将image*255,再将图片转换成uint8格式的数据,最后利用fromarray将数组数据转换成image类型的数据,才可以调用image.save()保存。














 2870
2870











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









