







一、并查集。
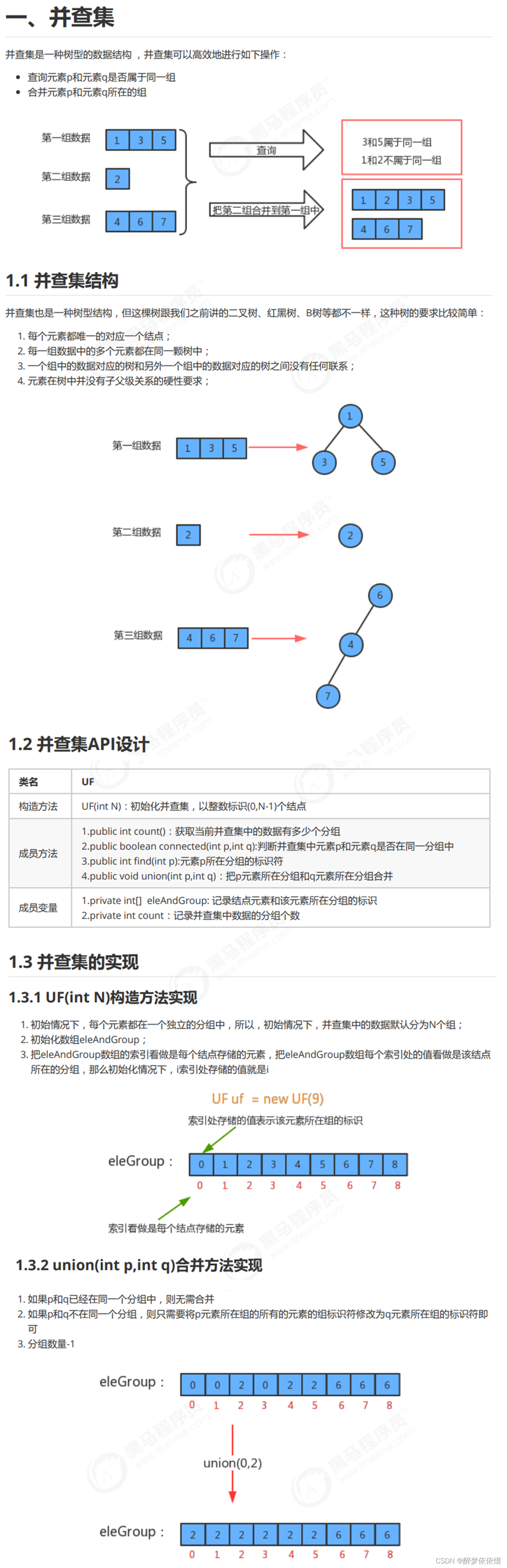
package 并查集;
public class UF {
//记录结点元素和该元素所在分组的标识
private int[] eleAndGroup;
//记录并查集中数据的分组个数
private int count;
//初始化并查集
public UF(int N){
//初始化分组的数量,默认情况下,有N个分组
this.count = N;
//初始化eleAndGroup数组
this.eleAndGroup = new int[N];
//初始化eleAndGroup中的元素及其所在的组的标识符,让eleAndGroup数组的索引作为并查集的每个结点的元素,
// 并且让每个索引处的值(该元素所在的组的标识符)就是该索引
for (int i = 0; i < eleAndGroup.length; i++) {
eleAndGroup[i] = i;
}
}
//获取当前并查集中的数据有几个分组
public int count(){
return count;
}
//元素p所在分组的标识符
public int find(int p){
return eleAndGroup[p];
}
//判断并查集中元素p和元素q是否在同一分组中
public boolean connected(int p,int q){
return find(p) == find(q);
}
//把p元素所在分组和q元素所在分组合并
public void union(int p,int q){
//判断元素q和p是否已经在同一分组中,如果已经在同一分组中,则结束方法就可以了
if (connected(p,q)){
return;
}
//找到p所在分组的标识符
int pGroup = find(p);
//找到q所在分组的标识符
int qGroup = find(q);
//合并组,让p所在组的所有元素的组标识符变为q所在分组的标识符
for (int i = 0; i < eleAndGroup.length; i++) {
if (eleAndGroup[i] == pGroup){
eleAndGroup[i] = qGroup;
}
}
//分组个数-1
this.count--;
}
}
测试代码:
package 并查集;
import java.util.Scanner;
public class UFTest {
public static void main(String[] args) {
//创建并查集对象
UF uf = new UF(5);
System.out.println("默认情况下,并查集中有:"+uf.count()+"个分组");
//从控制台录入两个要合并的元素,调用union方法合并,观察合并后并查集中的分组是否减少
Scanner sc = new Scanner(System.in);
while (true){
System.out.println("请输入第一个要合并的元素:");
int p = sc.nextInt();
System.out.println("请输入第二个要合并的元素:");
int q = sc.nextInt();
//判断这两个元素是否已经在同一组了
if (uf.connected(p,q)){
System.out.println(p+"元素和"+q+"元素已经在同一个组中了");
continue;
}
uf.union(p,q);
System.out.println("当前并查集中还有:"+uf.count()+"个分组");
}
}
}
二、并查集优化。

package 并查集;
public class UF_Tree {
//记录结点元素和该元素所在分组的标识
private int[] eleAndGroup;
//记录并查集中数据的分组个数
private int count;
//初始化并查集
public UF_Tree(int N){
//初始化分组的数量,默认情况下,有N个分组
this.count = N;
//初始化eleAndGroup数组
this.eleAndGroup = new int[N];
//初始化eleAndGroup中的元素及其所在的组的标识符,让eleAndGroup数组的索引作为并查集的每个结点的元素,
// 并且让每个索引处的值(该元素所在的组的标识符)就是该索引
for (int i = 0; i < eleAndGroup.length; i++) {
eleAndGroup[i] = i;
}
}
//获取当前并查集中的数据有几个分组
public int count(){
return count;
}
//元素p所在分组的标识符
public int find(int p){
while (true){
if (p == eleAndGroup[p]){
return p;
}
p = eleAndGroup[p];
}
}
//判断并查集中元素p和元素q是否在同一分组中
public boolean connected(int p,int q){
return find(p) == find(q);
}
//把p元素所在分组和q元素所在分组合并
public void union(int p,int q){
//找到p元素和q元素所在组对应树的根节点
int pRoot = find(p);
int qRoot = find(q);
//如果p和q已经在同一组,则不需要合并了
if (pRoot == qRoot){
return;
}
//让p所在树的根节点的父节点为q所在树的根节点即可
eleAndGroup[pRoot] = qRoot;
//组的个数-1
count--;
}
}
测试代码:
package 并查集;
import java.util.Scanner;
public class UF_TreeTest {
public static void main(String[] args) {
//创建并查集对象
UF_Tree uf = new UF_Tree(5);
System.out.println("默认情况下,并查集中有:"+uf.count()+"个分组");
//从控制台录入两个要合并的元素,调用union方法合并,观察合并后并查集中的分组是否减少
Scanner sc = new Scanner(System.in);
while (true){
System.out.println("请输入第一个要合并的元素:");
int p = sc.nextInt();
System.out.println("请输入第二个要合并的元素:");
int q = sc.nextInt();
//判断这两个元素是否已经在同一组了
if (uf.connected(p,q)){
System.out.println(p+"元素和"+q+"元素已经在同一个组中了");
continue;
}
uf.union(p,q);
System.out.println("当前并查集中还有:"+uf.count()+"个分组");
}
}
}
三、路径压缩。
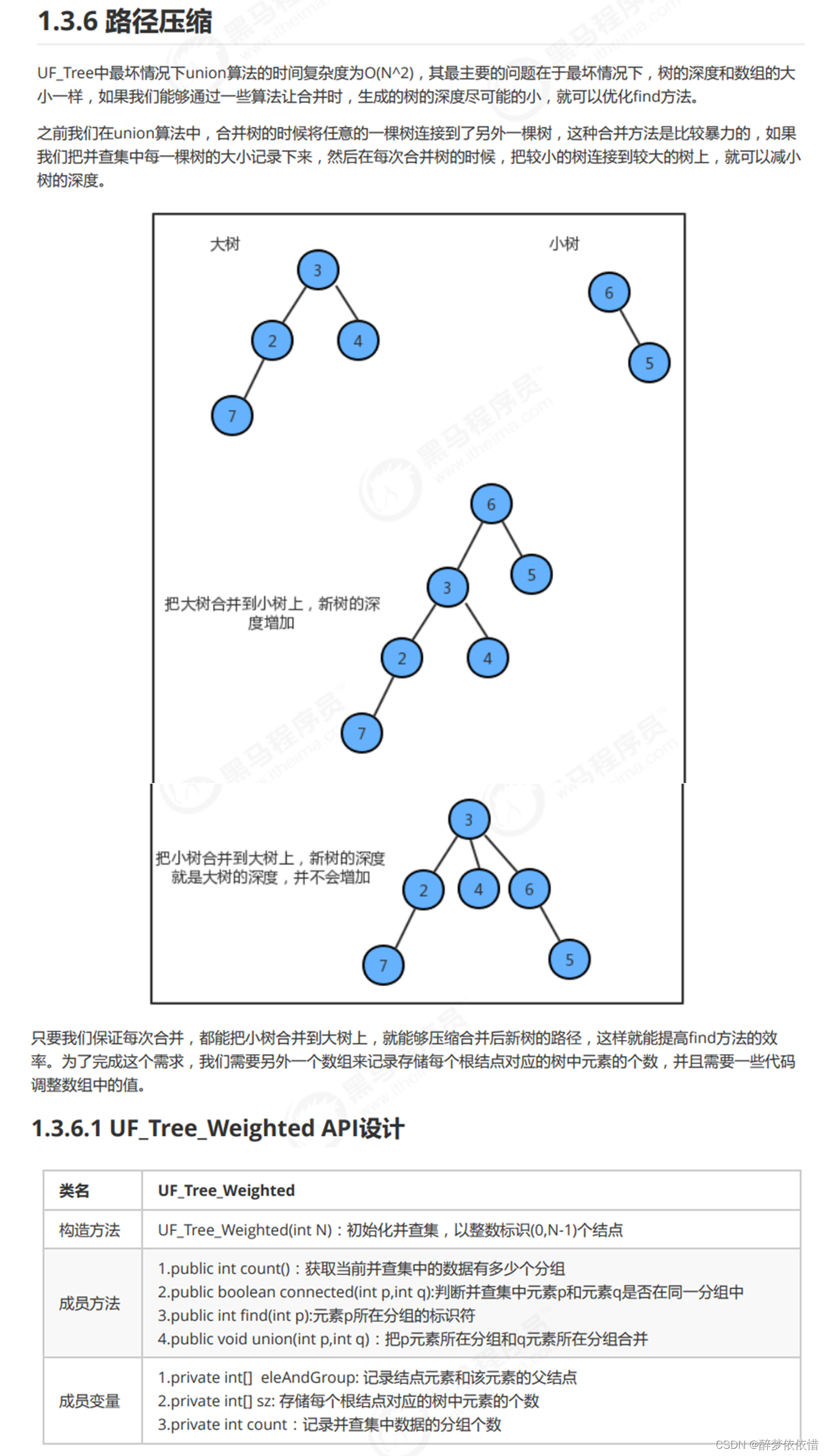
package 并查集;
public class UF_Tree_Weighted {
//记录结点元素和该元素所在分组的标识
private int[] eleAndGroup;
//记录并查集中数据的分组个数
private int count;
//用来存储每一个根节点对应的树中保存结点的个数
private int[] sz;
//初始化并查集
public UF_Tree_Weighted(int N){
//初始化分组的数量,默认情况下,有N个分组
this.count = N;
//初始化eleAndGroup数组
this.eleAndGroup = new int[N];
//初始化eleAndGroup中的元素及其所在的组的标识符,让eleAndGroup数组的索引作为并查集的每个结点的元素,
// 并且让每个索引处的值(该元素所在的组的标识符)就是该索引
for (int i = 0; i < eleAndGroup.length; i++) {
eleAndGroup[i] = i;
}
this.sz = new int[N];
//默认情况下,sz中每个索引处的值都是1
for (int i = 0; i < sz.length; i++) {
sz[i] = 1;
}
}
//获取当前并查集中的数据有几个分组
public int count(){
return count;
}
//元素p所在分组的标识符
public int find(int p){
while (true){
if (p == eleAndGroup[p]){
return p;
}
p = eleAndGroup[p];
}
}
//判断并查集中元素p和元素q是否在同一分组中
public boolean connected(int p,int q){
return find(p) == find(q);
}
//把p元素所在分组和q元素所在分组合并
public void union(int p,int q){
//找到p元素和q元素所在组对应树的根节点
int pRoot = find(p);
int qRoot = find(q);
//如果p和q已经在同一组,则不需要合并了
if (pRoot == qRoot){
return;
}
//判断proot对应的树大还是qroot对应的树大,最终需要把较小的树合并到较大的树中
if (sz[pRoot] < sz[qRoot]){
eleAndGroup[pRoot] = qRoot;
sz[qRoot] += sz[pRoot];
}else {
eleAndGroup[qRoot] = pRoot;
sz[pRoot] += sz[qRoot];
}
//组的个数-1
count--;
}
}
测试代码:
package 并查集;
import java.util.Scanner;
public class UF_Tree_WeightTest {
public static void main(String[] args) {
//创建并查集对象
UF_Tree_Weighted uf = new UF_Tree_Weighted(5);
System.out.println("默认情况下,并查集中有:"+uf.count()+"个分组");
//从控制台录入两个要合并的元素,调用union方法合并,观察合并后并查集中的分组是否减少
Scanner sc = new Scanner(System.in);
while (true){
System.out.println("请输入第一个要合并的元素:");
int p = sc.nextInt();
System.out.println("请输入第二个要合并的元素:");
int q = sc.nextInt();
//判断这两个元素是否已经在同一组了
if (uf.connected(p,q)){
System.out.println(p+"元素和"+q+"元素已经在同一个组中了");
continue;
}
uf.union(p,q);
System.out.println("当前并查集中还有:"+uf.count()+"个分组");
}
}
}
四、案例-畅通工程。

package 并查集.案例_畅通工程;
import 并查集.UF_Tree_Weighted;
import java.io.BufferedReader;
import java.io.FileReader;
import java.io.IOException;
public class Traffic_Project_Test {
public static void main(String[] args) throws IOException {
//构建一个缓冲读取流BufferedReader
BufferedReader br = new BufferedReader(new FileReader("D:\\数据结构与算法资料\\代码\\algorithm\\src\\traffic_project.txt"));
//读取第一行数据20
Integer tptalNumber = Integer.valueOf(br.readLine());
//构建一个并查集对象
UF_Tree_Weighted uf = new UF_Tree_Weighted(tptalNumber);
//读取第二行数据7
int roadNumber = Integer.parseInt(br.readLine());
//循环读取7条道路
for (int i = 1; i <= roadNumber; i++) {
String line = br.readLine();
String[] str = line.split(" ");
int p = Integer.parseInt(str[0]);
int q = Integer.parseInt(str[1]);
//调用并查集对象的union方法让两个城市相通
uf.union(p,q);
}
//获取当前并查集中分组的数量-1就可以得到还需要修建的道路的数目
int roads = uf.count() - 1;
System.out.println("还需要修建"+roads+"条道路,才能实现畅通工程");
}
}














 2031
2031











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









