







摘要
这篇文章证明了使用从CNNs中学习到的深度特征可以提高轮廓检测的准确度。
对CNNs的训练采取二元变多元的策略,即提出把本来是二元分类问题的轮廓检测转化为一个多元分类问题,对每一个类使用不同的参数,区别对待。
同时为了获得更加有区分度的特征,提出了一个positive-sharing loss的损失函数,该损失函数引入了一个额外的正则化因子来强调 positive and negative classes(轮廓类和背景类)的区别。
实验结果在Berkeley Segmentation Dataset和BSDS500数据集上达到了最好的准确率,同时在NYUD dataset上也取得了很高的准确度。
简介
轮廓检测的意义
自然图片的轮廓检测是非常基础的一个问题,它是图像分割、场景识别、目标检测的基础。就目标检测来说:
目标检测任务可分为两个关键的子任务:目标分类和目标定位.目标分类任务负责判断输入图像中是否有感兴趣类别的物体出现,输出一系列带分数的标签表明感兴趣类别的物体出现在输入图像的可能性.目标定位任务负责确定输入图像中感兴趣类别的物体的位置和范围,输出物体的包围盒,或物体中心,或物体的闭合边界等,通常方形包围盒是最常用的选择.而这些都离不开对物体轮廓的准确检测。
什么是轮廓
边缘与线段包含丰富的图像信息, 代表了图像的特征, 边缘与线段的组合构成一幅图像区别于其他图像的特征集合。 物体的轮廓不同于边缘, 图像的边缘信息包含所有的轮廓信息, 轮廓包含着比位置更多的信息, 从图像的轮廓, 人们即可识别大量的物体。
轮廓检测的难点在哪里
难点在于怎样将物体本身的纹理和物体的轮廓区分开,因为纹理和物体的轮廓都会造成图像梯度的变化,对与计算机来说,这是很难区分的特征。
别人如何解决这个问题
传统的方法就是对每个图像像素,设计各种各样的梯度特征,在通过一个二元的分类器来决定该像素是否是轮廓。虽然传统的方法在过去的十几年当中,一直处于最好的准确率,但是对于语义上目标轮廓和急剧变化的纹理并没有很好的区分度。但是最近流行CNNs却表现出非常好的表现。
轮廓检测方面: P. Dollar 将随机森林用于轮廓检测,获得了real time级的速度以及达到了主流的准确率。Joseph J. Lim等人使用sketch tokens 学习轮廓的中间层特征并用于轮廓检测。Martin等人仔细设计了与自然边界相关的亮度,颜色和纹理的特征变化的features,并且让学习分类器来组合这些特征。
深度学习用于轮廓检测 Kivinen等人using RBM and classified multiple read-out layers。Ganin and Lempitsky首先让CNNs学习轮廓特征然后将学习到的特征输入到an annotation edge map using kd-tree。
作者如何解决这个问题的
作者想让CNNs学习到具有辨别力的特征,为此作者考虑到轮廓具有不同的特征和结构,所以对于不同的轮廓特征进行分类,采用不同的模型参数来表征。
由于轮廓之间的分类出错一般是可以忽略或者是容忍的,但是轮廓和背景之间分类出错是不可以容忍的,所以在loss function中强调了轮廓和背景出错所引起的费用,就是额外增加了轮廓错误分类到背景和背景错误分类到轮廓的费用。
通过以上这两个措施,从而让CNN学习到更加具有辨别力的特征。
具体实现
算法流程图
第一步:聚类
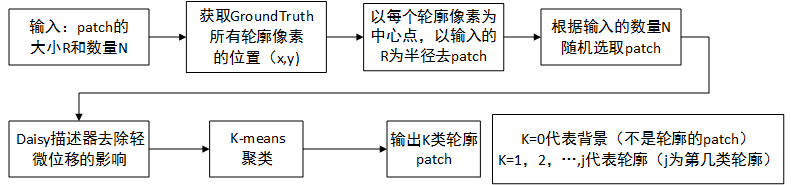
聚类的结果:

第二步:训练CNNs
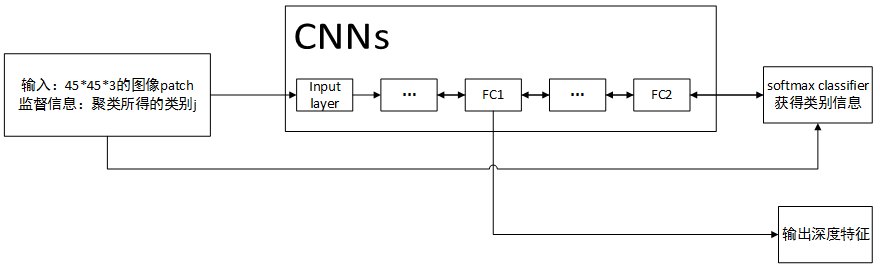
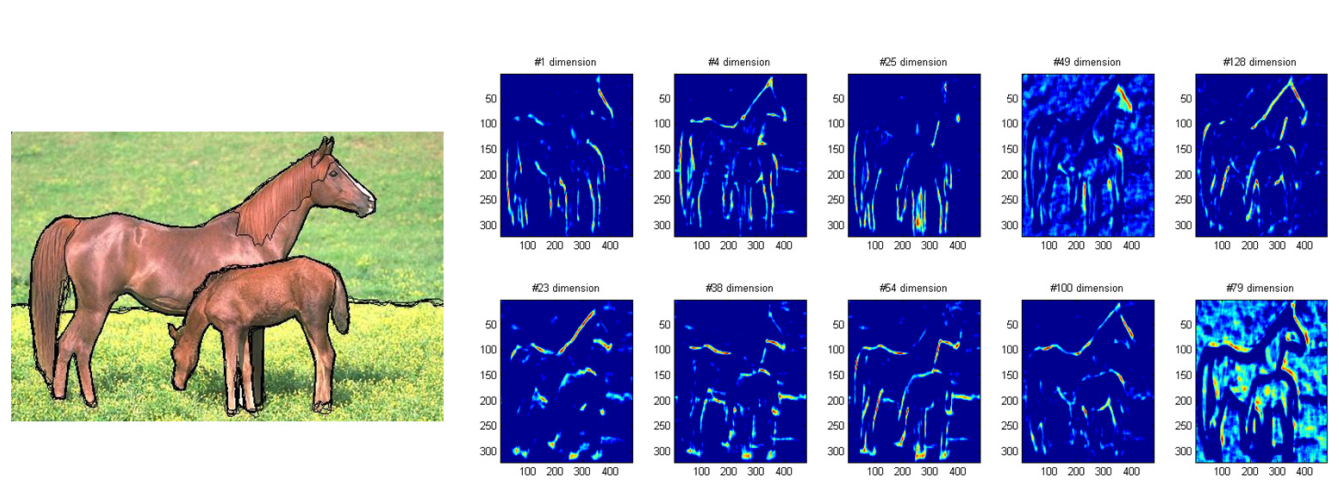
深度特征可视化结果:
第三步:使用随机森林

最终输出结果:

CNN的结构
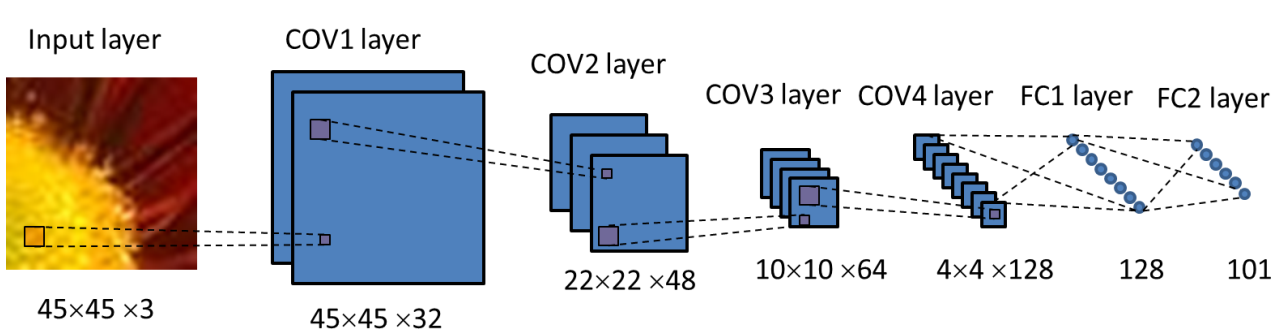
COV1(45 × 45 × 32)→LRN1 → MAXP1 →COV2(22 × 22 × 48) → LRN2 → MAXP2 →COV3(10 × 10 × 64) → LRN3 → MAXP3 →COV4(4 × 4 × 128) → MAXP4 → FC1(128) →RELU→DROPOUT→ FC2(101)→a softmax classifier(51类)
费用函数
预测结果为类别j的置信度
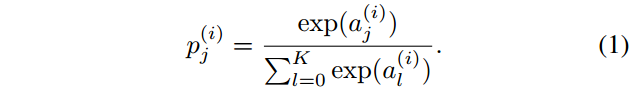
一般的softmax classifier的loss function
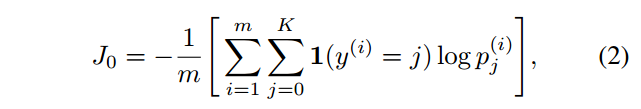
引入额外的正则化因子后的loss function
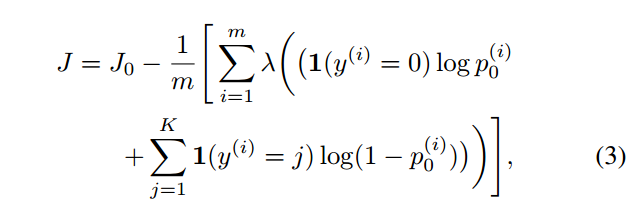
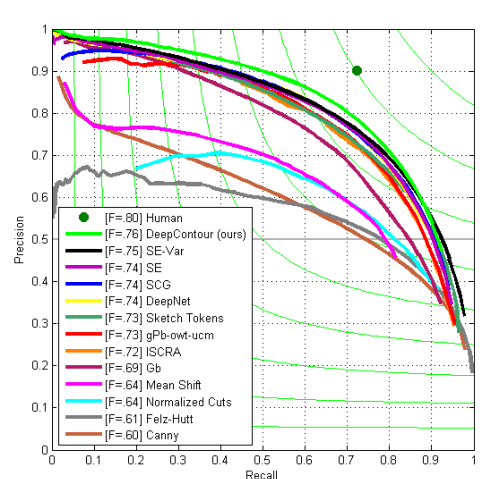
实验结果
在Berkeley Segmentation Dataset和BSDS500数据集上达到了最好的准确率,同时在NYUD dataset上也取得了很高的准确度。
PS:关于怎样使caffe网络可以接受任意大小的输入
我们都知道卷积操作是和输入图像的大小无关的,然而全链接层是和输入图像的大小关系的。因此,如果要可以接受任意大小的图像输入,我们可以将全链接层转变为卷积层,其他不变,这样就可实现接受任意大小图像输入了。具体实现请看这里。















 408
408

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









