






MD5步骤详解及c++实现
文章目录
1.步骤详解
操作
一个字就是32位的二进制字符串,介于 0 0 0与 2 3 2 − 1 2^32-1 232−1之间的整数可以表示为一个字。
X和Y分别为一个字
-
X AND Y = X和Y按位与
-
X OR Y = X和Y按位或
-
X XOR Y = X和Y按位异或
-
NOT X = X取非
-
X+Y = X+Y后的结果模 2 32 2^{32} 232
第一步:将字符串转换为ASCII码的二进制串
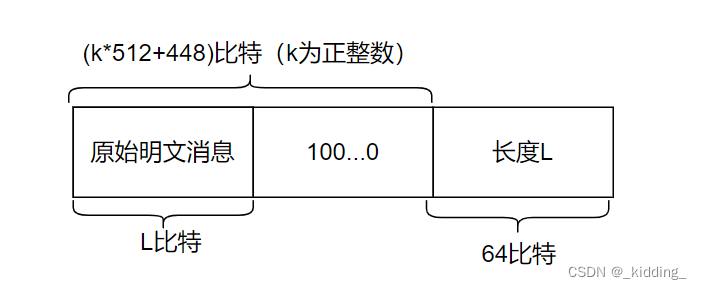
第二步:消息填充
填充规则:
- 在原始明文消息后补100…0,直到满足 总长度 ≡ 448 m o d 512 总长度\equiv448 \mathrm{mod }512 总长度≡448mod512为止。
- 设原始明文消息的长度为 L b i t L \ bit L bit,将 L L L表示为64位二进制串的形式,添加在最后。
经过上面两个步骤的处理,最终得到的处理后的数据如下图所示:
第三步:计算消息摘要
将数据按512比特一块进行分块,得到n块数据,记作 M ( 1 ) , M ( 2 ) , ⋯ , M ( n ) M(1),M(2),\cdots,M(n) M(1),M(2),⋯,M(n).
一些操作和常量如下
对于四个32位字A,B,C,D,有
A_ = 0x01234567; B_ = 0x89ABCDEF; C_ = 0xFEDCBA98; D_ = 0x76543210; //但是在在实际编程中,A,B,C,D的值如下。因为大小端的转换问题,MD5中默认使用大端编址,而Windows和Linux系统默认使用小端编址。 A = 0x67452301; B = 0xEFCDAB89; C = 0x98BADCFE; D = 0x10325476;对于三个32位字X,Y,Z,有
F(X,Y,Z) = (X AND Y) OR ((NOT X) AND Z) G(X,Y,Z) = (X AND Z) OR (Y AND (NOT Z)) H(X,Y,Z) = X XOR Y XOR Z I(X,Y,Z) = Y XOR (X OR (NOT Z)T[i]=4294967296*abs(sin(i));//1=<i<=64 //注:由于T[i]是定值,因此在实现时往往用常数代替
计算摘要的伪代码如下:
//对于每块数据M[i](一块为512bit)
for i = 1 to n do{
将M[i]分为16个32位字X[0],X[1],...,X[15],其中X[0]是最左侧的字;
AA = A,BB = B,CC = C,DD = D;
/* 第一轮 */
/* 令[abcd k s i] 代表如下操作
a = b + ((a + F(b,c,d) + X[k] + T[i]) <<< s). */
/* 对于下面的数,依次执行上述操作 (注:一般把这个操作记作FF)*/
[ABCD 0 7 1] [DABC 1 12 2] [CDAB 2 17 3] [BCDA 3 22 4]
[ABCD 4 7 5] [DABC 5 12 6] [CDAB 6 17 7] [BCDA 7 22 8]
[ABCD 8 7 9] [DABC 9 12 10] [CDAB 10 17 11] [BCDA 11 22 12]
[ABCD 12 7 13] [DABC 13 12 14] [CDAB 14 17 15] [BCDA 15 22 16]
/* 第二轮 */
/* 令[abcd k s i] 代表如下操作
a = b + ((a + G(b,c,d) + X[k] + T[i]) <<< s). */
/* 对于下面的数,依次执行上述操作 (注:一般把这个操作记作GG)*/
[ABCD 1 5 17] [DABC 6 9 18] [CDAB 11 14 19] [BCDA 0 20 20]
[ABCD 5 5 21] [DABC 10 9 22] [CDAB 15 14 23] [BCDA 4 20 24]
[ABCD 9 5 25] [DABC 14 9 26] [CDAB 3 14 27] [BCDA 8 20 28]
[ABCD 13 5 29] [DABC 2 9 30] [CDAB 7 14 31] [BCDA 12 20 32]
/* 第三轮 */
/* 令[abcd k s i] 代表如下操作
a = b + ((a + H(b,c,d) + X[k] + T[i]) <<< s). */
/*对于下面的数,依次执行上述操作 (注:一般把这个操作记作HH)*/
[ABCD 5 4 33] [DABC 8 11 34] [CDAB 11 16 35] [BCDA 14 23 36]
[ABCD 1 4 37] [DABC 4 11 38] [CDAB 7 16 39] [BCDA 10 23 40]
[ABCD 13 4 41] [DABC 0 11 42] [CDAB 3 16 43] [BCDA 6 23 44]
[ABCD 9 4 45] [DABC 12 11 46] [CDAB 15 16 47] [BCDA 2 23 48]
/* 第四轮 */
/* 令[abcd k s i] 代表如下操作
a = b + ((a + I(b,c,d) + X[k] + T[i]) <<< s). */
/* 对于下面的数,依次执行上述操作 (注:一般把这个操作记作II)*/
[ABCD 0 6 49] [DABC 7 10 50] [CDAB 14 15 51] [BCDA 5 21 52]
[ABCD 12 6 53] [DABC 3 10 54] [CDAB 10 15 55] [BCDA 1 21 56]
[ABCD 8 6 57] [DABC 15 10 58] [CDAB 6 15 59] [BCDA 13 21 60]
[ABCD 4 6 61] [DABC 11 10 62] [CDAB 2 15 63] [BCDA 9 21 64]
A = A + AA,B = B + BB,C = C + CC,D = D + DD;
}
输出ABCD 120位比特串,即为消息摘要
大坑:大小端的转换问题(如果不想自己实现MD5,可以跳过)
大端小端的概念见https://www.ruanyifeng.com/blog/2022/06/endianness-analysis.html
MD5默认使用大端模式计算消息摘要,而Windows和Linux都默认使用小端模式,因此就需要将数据在大小端之间转换。
我在这里卡了三四个小时,因此特意列出来,避免大家犯同样的错误。
-
消息填充时的转换
-
下面的数字默认使用16进制,数字中‘-’的作用和空格类似。
-
为了方便回忆,把“第二步:消息填充”中的图片贴在了这里。
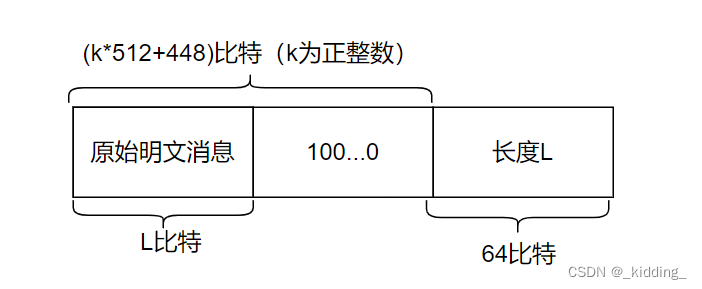
-
长度L的转换:例如,原始明文消息的长度为32bit,那么L的16进制表示为
00 ... 00-20,转换为大端存储变为20-00 ... 00 -
除长度L之外的其他部分的转换:MD5中以一个32位字为基本单位,因此大小端转换时,只改变32位字内部的字节的顺序,而字和字之间的相对顺序不变。
例如,字符abcd,转换为ASCII码,依次为
62-63-64-65,转换为大端存储后,变为65-64-63-62。又例如,字符abcdef,转换为ASCII码,依次为
62-63-64-65 66-67-00-00,转换为大端存储后,变为65-64-63-62 00-00-67-66. -
注意:对于长度L,以64比特为一个整体进行大小端转换。大小端转换时“字和字之间相对顺序不变”的规则,不适合于长度L的转换。
下面以一个例子进一步说明消息填充时的转换
例如字符串“apple”:
- 字符串转换为ASCII码:“apple”转换为ASCII码后为
61-70-70-6c 65,这串数字就是原始明文消息。 - 消息填充:消息填充后,变为
61-70-70-6c 65-80-00-00 .. 00-00-00-28。(80 00 … 00就是十六进制下的100…0;原始明文消息的长度为40比特,即0x28比特) - 长度L的转换:将长度
00... 00-28变为28-00...00。因此消息变为61-70-70-6c 65-80-00-00 .. 00-28-00-00 .. 00 - 除长度L之外的其他部分的转换:第1个32位字中,
61-70-70-6c变为6c-70-70-61。第2个32位字中,65-80-00-00变为00-00-80-65。依次做相似的变换。最终消息变为6c-70-70-61-00 00-80-65-00... 00-28-00-00 ... 00
-
-
计算摘要时的转换:将常量A,B,C,D的值变动一下。在“第三步:计算消息摘要”部分已经说明
-
输出时的转换:将计算后的结果A,B,C,D换成小端存储的格式后输出
2.c++实现
#include<iostream>
#include<vector>
#include<string>
#include<sstream>
using namespace std;
//定义一些操作
#define F(x,y,z) ((x & y) | (~x & z))
#define G(x,y,z) ((x & z) | (y & ~z))
#define H(x,y,z) (x^y^z)
#define I(x,y,z) (y ^ (x | ~z))
#define ROTATE_LEFT(x,n) ((x << n) | (x >> (32-n)))
#define FF(a,b,c,d,x,s,ac) { \
a += F(b, c, d) + x + ac; \
a = ROTATE_LEFT(a, s); \
a += b; \
}
#define GG(a,b,c,d,x,s,ac) { \
a += G(b, c, d) + x + ac; \
a = ROTATE_LEFT(a, s); \
a += b; \
}
#define HH(a,b,c,d,x,s,ac) { \
a += H(b, c, d) + x + ac; \
a = ROTATE_LEFT(a, s); \
a += b; \
}
#define II(a,b,c,d,x,s,ac) { \
a += I(b, c, d) + x + ac; \
a = ROTATE_LEFT(a, s); \
a += b; \
}
//填充函数
//m为原始明文,填充后的数据长度为512*n bit,填充后的数据在output中保存
void padding(vector<unsigned char>& output, int& n, string m) {
n = (m.size() + 8) / 64 + 1;
output.resize(n * 64);
int i = 0;
//原始明文消息
for (; i < m.size(); i++) {
output[i] = m[i];
}
//填充10...0
output[i++] = 0x80;
while (i < output.size() - 8) {
output[i] = 0;
i++;
}
//填充长度,完成长度L的大小端转换。
long long int len = m.size() * 8;
for (i = output.size() - 8; i < output.size(); ++i) {
output[i] = len % 256;
len /= 256;
}
}
//生成第n块的X数组,完成“除长度L之外其他部分”的大小端转换
void setX(unsigned int X[], vector<unsigned char> m, int n) {
n *= 64;
for (int i = 0; i < 16; i++) {
X[i] = (m[n + 4 * i+3] << 24) + (m[n + 4 * i + 2] << 16)
+ (m[n + 4 * i + 1] << 8) + m[n + 4 * i ];
}
}
string md5(string text) {
vector<unsigned char> message;//填充后的消息
int n;//按512比特一块,message可以分为n块
padding(message, n, text);
unsigned int A, B, C, D;
unsigned int AA, BB, CC, DD;
unsigned int X[16];
A = 0x67452301;
B = 0xEFCDAB89;
C = 0x98BADCFE;
D = 0x10325476;
for (int i = 0; i < n; ++i) {
setX(X, message, i);
AA = A, BB = B, CC = C, DD = D;
FF(A, B, C, D, X[0], 7, 0xd76aa478);
FF(D, A, B, C, X[1], 12, 0xe8c7b756);
FF(C, D, A, B, X[2], 17, 0x242070db);
FF(B, C, D, A, X[3], 22, 0xc1bdceee);
FF(A, B, C, D, X[4], 7, 0xf57c0faf);
FF(D, A, B, C, X[5], 12, 0x4787c62a);
FF(C, D, A, B, X[6], 17, 0xa8304613);
FF(B, C, D, A, X[7], 22, 0xfd469501);
FF(A, B, C, D, X[8], 7, 0x698098d8);
FF(D, A, B, C, X[9], 12, 0x8b44f7af);
FF(C, D, A, B, X[10], 17, 0xffff5bb1);
FF(B, C, D, A, X[11], 22, 0x895cd7be);
FF(A, B, C, D, X[12], 7, 0x6b901122);
FF(D, A, B, C, X[13], 12, 0xfd987193);
FF(C, D, A, B, X[14], 17, 0xa679438e);
FF(B, C, D, A, X[15], 22, 0x49b40821);
GG(A, B, C, D, X[1], 5, 0xf61e2562);
GG(D, A, B, C, X[6], 9, 0xc040b340);
GG(C, D, A, B, X[11], 14, 0x265e5a51);
GG(B, C, D, A, X[0], 20, 0xe9b6c7aa);
GG(A, B, C, D, X[5], 5, 0xd62f105d);
GG(D, A, B, C, X[10], 9, 0x2441453);
GG(C, D, A, B, X[15], 14, 0xd8a1e681);
GG(B, C, D, A, X[4], 20, 0xe7d3fbc8);
GG(A, B, C, D, X[9], 5, 0x21e1cde6);
GG(D, A, B, C, X[14], 9, 0xc33707d6);
GG(C, D, A, B, X[3], 14, 0xf4d50d87);
GG(B, C, D, A, X[8], 20, 0x455a14ed);
GG(A, B, C, D, X[13], 5, 0xa9e3e905);
GG(D, A, B, C, X[2], 9, 0xfcefa3f8);
GG(C, D, A, B, X[7], 14, 0x676f02d9);
GG(B, C, D, A, X[12], 20, 0x8d2a4c8a);
HH(A, B, C, D, X[5], 4, 0xfffa3942);
HH(D, A, B, C, X[8], 11, 0x8771f681);
HH(C, D, A, B, X[11], 16, 0x6d9d6122);
HH(B, C, D, A, X[14], 23, 0xfde5380c);
HH(A, B, C, D, X[1], 4, 0xa4beea44);
HH(D, A, B, C, X[4], 11, 0x4bdecfa9);
HH(C, D, A, B, X[7], 16, 0xf6bb4b60);
HH(B, C, D, A, X[10], 23, 0xbebfbc70);
HH(A, B, C, D, X[13], 4, 0x289b7ec6);
HH(D, A, B, C, X[0], 11, 0xeaa127fa);
HH(C, D, A, B, X[3], 16, 0xd4ef3085);
HH(B, C, D, A, X[6], 23, 0x4881d05);
HH(A, B, C, D, X[9], 4, 0xd9d4d039);
HH(D, A, B, C, X[12], 11, 0xe6db99e5);
HH(C, D, A, B, X[15], 16, 0x1fa27cf8);
HH(B, C, D, A, X[2], 23, 0xc4ac5665);
II(A, B, C, D, X[0], 6, 0xf4292244);
II(D, A, B, C, X[7], 10, 0x432aff97);
II(C, D, A, B, X[14], 15, 0xab9423a7);
II(B, C, D, A, X[5], 21, 0xfc93a039);
II(A, B, C, D, X[12], 6, 0x655b59c3);
II(D, A, B, C, X[3], 10, 0x8f0ccc92);
II(C, D, A, B, X[10], 15, 0xffeff47d);
II(B, C, D, A, X[1], 21, 0x85845dd1);
II(A, B, C, D, X[8], 6, 0x6fa87e4f);
II(D, A, B, C, X[15], 10, 0xfe2ce6e0);
II(C, D, A, B, X[6], 15, 0xa3014314);
II(B, C, D, A, X[13], 21, 0x4e0811a1);
II(A, B, C, D, X[4], 6, 0xf7537e82);
II(D, A, B, C, X[11], 10, 0xbd3af235);
II(C, D, A, B, X[2], 15, 0x2ad7d2bb);
II(B, C, D, A, X[9], 21, 0xeb86d391);
A = A + AA, B = B + BB, C = C + CC, D = D + DD;
}
stringstream ss;
//将A,B,C,D由大端格式变为小端格式
ss << hex
<< (A & 0xffU) << ((A >> 8) & 0xffU) << ((A >> 16) & 0xffU) << ((A >> 24) & 0xffU)
<< (B & 0xffU) << ((B >> 8) & 0xffU) << ((B >> 16) & 0xffU) << ((B >> 24) & 0xffU)
<< (C & 0xffU) << ((C >> 8) & 0xffU) << ((C >> 16) & 0xffU) << ((C >> 24) & 0xffU)
<< (D & 0xffU) << ((D >> 8) & 0xffU) << ((D >> 16) & 0xffU) << ((D >> 24) & 0xffU);
return ss.str();
}
int main() {
cout << md5("apple") << endl;
}















 1091
1091











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









