







目录
论文连接:[1311.2524] Rich feature hierarchies for accurate object detection and semantic segmentation
如果你之前了解过RNN,很容易混淆认为R-CNN也具有RNN的时序循环功能,这种理解是错误的:
- RCNN 里的 “R” 是 Region(区域),它其实是一种 目标检测结构,和循环无关;
- 它属于 区域提议 + CNN分类器 的思路,而不是时间序列建模。
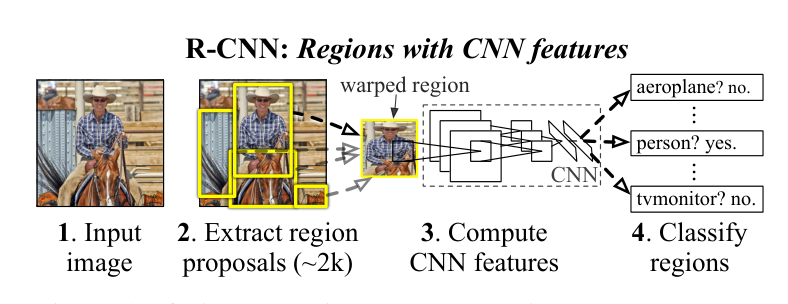
RCNN(Regions with Convolutional Neural Networks)是 Ross Girshick 等人在 2014 年提出的目标检测方法,它是深度学习在目标检测领域的早期重要成果之一。RCNN 将传统目标检测方法与卷积神经网络(CNN)结合起来,实现了更高的检测精度。
它把 图像分类器(CNN) 与 目标检测(Region Proposal + 分类 + 回归) 结合在一起,流程清晰但处理效率不高。
一、R-CNN整体流程
下面是完整的 RCNN 整体流程梳理:
+----------------+
| 输入图像 |
+--------+-------+
|
v
+---------------------------+
| 候选区域提取 (Selective Search) |
+---------------------------+
|
v
+------------------------------+
| 每个候选区域裁剪并缩放成固定大小 |
+------------------------------+
|
v
+---------------------------+
| CNN(如 AlexNet)特征提取 |
+---------------------------+
|
v
+---------+ +----------------+
| SVM 分类 | <---> | 边界框回归(BBox) |
+---------+ +----------------+
|
v
+----------------+
| 检测结果输出 |
+----------------+
此处需要注意R-CNN利用CNN完成特征提取后,SVM分类,和边界框BBOX偏移量的计算是相互独立的。
🔵 RCNN 的主要流程
1️⃣ 候选框生成(Region Proposal)
使用选择性搜索(Selective Search)从整张图像中生成大约 2000 个候选框(region proposals)。
- 输入:整张图像
- 输出:若干个可能包含目标的候选框(bounding boxes)
特点:
- 这一步是纯传统算法,和深度学习无关
- 每个候选框区域尺寸不同
2️⃣ 候选框裁剪与特征提取
对每个候选框区域裁剪、缩放到固定尺寸(如 224×224),然后输入到 CNN 中提取特征。
- CNN 使用 ImageNet 上预训练的分类网络(如 AlexNet)
- 特征来自全连接层前(如 fc7 层输出)
- 每个候选框 → 得到一个固定长度的特征向量(例如 4096 维)
结果形式:
特征向量列表: [f_1, f_2, ..., f_N],每个 f_i ∈ ℝ^4096
3️⃣ 分类
使用提取到的 CNN 特征向量,训练一个类别分类器(通常是 SVM)
- 对每个类别都训练一个二分类 SVM(one-vs-rest)
- 判断一个框是不是某个类(狗、猫、飞机...)
4️⃣ 边界框回归(BBOX Regression)
训练一个线性回归器(bbox regressor)对框的位置做微调
- 输入:特征向量
- 输出:位置偏移(t_x, t_y, t_w, t_h),对原始框做微调
- 每类一个回归器
边界框回归通常使用四个值(t_x, t_y, t_w, t_h)表示相对的调整:
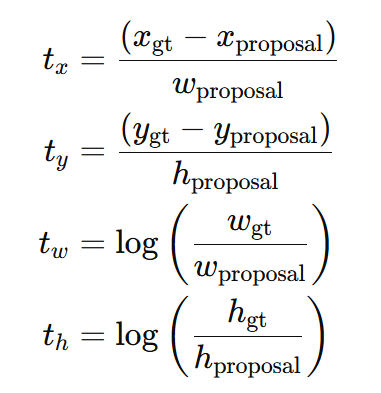
在预测阶段,网络预测出 (t_x, t_y, t_w, t_h),再反算出 refined BBOX
解码公式(decode):
p_x = t_x * d_w + d_x
p_y = t_y * d_h + d_y
p_w = exp(t_w) * d_w
p_h = exp(t_h) * d_h
✅ 结果形式:
每个 region → 分类分数 + 位置偏移量
模型训练时的准备工作:
| 内容 | 说明 |
| 候选框准备 | 使用 Selective Search 生成候选框(约2000个) |
| 标注匹配 | 将候选框与 ground truth 计算 IOU,设定正负样本阈值(如 IOU>0.5为正) |
| CNN 特征提取 | 将正负样本图像送入 CNN,提取特征 |
| 训练分类器(SVM) | 用 CNN 特征 + 标签训练若干个二分类 SVM |
| 训练BBOX回归器 | 用 CNN 特征 + 偏移量训练 bbox 回归器 |
二、需要注意的地方
1. RCNN 的流程中,特征向量(fc7)是怎么同时用于分类(SVM)和边界框回归(BBOX regression)的?
RCNN 本身(2014 年)没有端到端的多任务学习,它的处理是分开的,流程是这样的:
CNN 提取特征
输入:候选框(裁剪+resize)
输出:fc7 特征向量(4096 维)
SVM 分类
-
对所有候选框,使用提取的 fc7 特征向量,分别送到不同的 SVM(每个类别一个 SVM + 一个背景类别)。
-
这个步骤不在神经网络中,是离线训练的。
回归器
-
同样使用 fc7 特征向量,单独训练一个线性回归器(或者每个类别一个回归器),回归框的偏移量 (Δx, Δy, Δw, Δh)。
也就是说,SVM 分类和 BBOX 回归是完全分开的,它们只共享 CNN 的 fc7 特征向量,而不是神经网络内部“多任务”输出。
所以在 RCNN:
-
网络本身只负责提取 fc7 特征。
-
SVM 分类和 BBOX 回归是独立的模型,单独训练,单独使用。
🔴 RCNN 中容易被忽略的细节
1️⃣ CNN 不是端到端训练
-
RCNN 的 CNN(例如 AlexNet)是用 ImageNet 分类数据集预训练的。
-
在 RCNN 里,CNN 只做特征提取,不会在目标检测任务上更新权重。
-
这意味着 RCNN 检测任务中的 CNN 权重是冻结的(不会 end-to-end 训练)。
2️⃣ SVM 和 BBOX 回归器是分开的
-
SVM 分类器和边界框回归器在 RCNN 中是离线训练的,和 CNN 特征提取完全分开。
-
这导致 RCNN 训练步骤很繁琐,要单独训练三部分:CNN(预训练),SVM(每类一个),BBOX 回归器(每类一个)。
3️⃣ 训练样本采样的不平衡问题
-
RCNN 用到 Selective Search 生成 2000+ 候选框,但大多数都是背景(负样本)。
-
训练 SVM 和回归器时,需要采样一部分负样本和正样本来避免类别极不平衡。
4️⃣ ROI(Region of Interest)裁剪和变形
-
RCNN 把候选框直接裁剪成固定大小(如 227x227)。
-
这会导致几何变形(原始候选框长宽比和 227x227 不一样)。
-
变形会影响后续检测精度。
5️⃣ 不同类别 SVM 的处理
-
RCNN 为每个类别都单独训练一个二分类 SVM。
-
最终推断时,多个 SVM 各自给分数,通常取分最高的类别。
-
这个和后来端到端网络中常见的 softmax 多分类不同。
6️⃣ 速度极慢
-
因为每个候选框都要跑一次 CNN,导致非常低效(在 GPU 上也是每张图要几秒)。
-
这是后来 SPPNet、Fast RCNN、Faster RCNN 诞生的主要动因。
另外:
✅候选框质量对结果影响巨大
-
Selective Search 是基于分割的启发式算法,质量有限。
-
如果候选框漏掉了物体(召回率不够),再好的 CNN 也没用。
✅ 训练和推理步骤分裂
-
RCNN 在训练时用的是裁剪过的图像(Warping),和真实推断时可能有 domain gap。
-
也就是推断时依赖 CNN 提取的全局图像特征,训练时是局部 warp 后的框,可能会有些微 mismatch。
✅ 多阶段训练带来的复杂性
-
RCNN 训练时流程比较长:
1️⃣ CNN 预训练(ImageNet)
2️⃣ SVM 训练
3️⃣ BBOX 回归训练 -
每步都有很多超参数,容易出错。
🟢 小结:RCNN 的易错点/易忽略点
| 项目 | 细节或坑 |
|---|---|
| CNN 训练 | 只在 ImageNet 上预训练,不在检测数据上 finetune。 |
| 分类 vs 回归 | SVM(离线) vs 回归器(离线),CNN 只提特征。 |
| ROI 裁剪 | 固定尺寸裁剪(如 227x227),导致几何变形。 |
| 多阶段训练 | 不同阶段需单独训练,容易数据集不匹配或忘记某一步。 |
| 速度问题 | 每个候选框都跑 CNN,推理速度非常慢。 |
| 负样本比例 | 需要好好处理负样本采样,否则 SVM 训练偏移(负样本占大多数)。 |
| SVM 结果处理 | 推断时是多 SVM 二分类结果合并(不是 softmax)。 |
🔵 总结
RCNN 是目标检测从 region proposal + CNN 特征提取起步的里程碑,但它的多阶段训练、慢速推断和非端到端的结构在后续被 Fast RCNN / Faster RCNN 所改进。
补充:
BBOX回归器:
在 RCNN 里,回归器只在“正样本”候选框上做训练。
所谓“正样本”= 与 GT 框的 IoU ≥ 0.5 的候选框。
流程:
1️⃣ 先对所有候选框(从 Selective Search 来的)和真值框(GT)算 IoU。
2️⃣ 每个候选框,找与它 IoU 最大的 GT 框。
3️⃣ 如果这个最大 IoU ≥ 0.5,认为它是“正样本”。否则,认为是“负样本”。
在回归器训练时,只保留正样本,用它们的特征和回归目标(偏移量)做训练。
所以,回归器的 Loss 只对正样本计算:
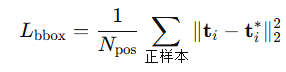
(负样本直接跳过,不参与计算 Loss)
BBOX 回归器结构示意
+-----------------+
| fc7 特征向量 | (4096,)
+-----------------+
|
|
v
+------------------------+
| 线性回归层(仿全连接) |
| W: (4096, 4) |
| b: (4,) |
+------------------------+
|
v
+-----------------+
| 4 维 BBOX 偏移量 | (tₓ, tᵧ, t_w, t_h)
+-----------------+
训练阶段
输入:
-
4096 维的 fc7 特征向量(由 CNN 提取出来)
目标: -
4 维的 GT 偏移量 (Δx*, Δy*, Δw*, Δh*)
优化: -
最小化 L2 回归损失(只对正样本)
推理阶段(测试)
在测试时:
将 proposal(候选框)经过 CNN 提取 fc7 特征
用回归器预测 4 维偏移量
把原候选框 (x, y, w, h) 和预测的 (tₓ, tᵧ, t_w, t_h) 反算出最终的 refined BBOX
关键点
-
这个回归器其实是一个非常简单的“全连接层”结构(线性层),没有隐藏层或激活函数。
-
只不过在 RCNN 中它是单独训练(不是网络 end-to-end 联合优化)。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









