









在大数据处理中,PySpark 提供了强大的工具来处理海量数据,特别是在数据清洗和转换方面。本文将介绍如何使用 PySpark 进行数据清洗,并将数据格式转换为 JSON 格式的实践。
简介
PySpark 是 Apache Spark 的 Python API,可用于处理大规模数据集。它提供了丰富的功能和库,使得数据清洗和转换变得更加高效和便捷。
代码实践
本文将以一个示例数据集为例,演示如何使用 PySpark 对数据进行清洗和转换。以下是代码实现的主要步骤:
步骤 1:连接到远程 Spark 服务器
# Author: 冷月半明
# Date: 2023/12/14
# Description: This script does XYZ.
from pyspark.sql import SparkSession
spark = SparkSession.builder \
.appName("RemoteSparkConnection") \
.master("yarn") \
.config("spark.pyspark.python", "/opt/apps/anaconda3/envs/myspark/bin/python") \
.config("spark.sql.warehouse.dir", "/hive/warehouse") \
.config("hive.metastore.uris", "thrift://node01:9083") \
.config("spark.sql.parquet.writeLegacyFormat", "true") \
.enableHiveSupport() \
.getOrCreate()
当使用 PySpark 进行大数据处理时,首先需要建立与 Spark 集群的连接。在这段代码中,我们使用了 SparkSession 类来创建一个与远程 Spark 服务器的连接,并设置了连接所需的参数。
-
导入必要的库: 我们首先导入了
SparkSession类,这是 PySpark 中用于管理 Spark 应用程序的入口点。 -
建立连接: 在接下来的代码中,我们使用
SparkSession.builder来创建一个SparkSession对象。这个对象允许我们设置应用程序的名称、集群的主节点、配置项等参数。在这个例子中:.appName("RemoteSparkConnection"):为我们的 Spark 应用程序设置了一个名称,这有助于在集群中识别应用程序。.master("yarn"):指定 Spark 应用程序的主节点,这里使用的是 YARN 资源管理器,用于分配和管理集群资源。.config("spark.pyspark.python", "/opt/apps/anaconda3/envs/myspark/bin/python"):设置了 PySpark 使用的 Python 解释器路径,确保在集群中使用正确的 Python 环境。(因为所使用的环境为anaconda创建的虚拟环境,先进入虚拟环境,然后使用which python查看解释器位置).config("spark.sql.warehouse.dir", "/hive/warehouse"):指定了 Spark SQL 的仓库目录,这对于数据存储和管理非常重要。如果不指定的话使用sparksql获取hive的时候可能会出现问题。.config("hive.metastore.uris", "thrift://node01:9083"):配置 Hive 元数据存储的 URI,Hive 是 Hadoop 生态系统中的一部分,用于管理数据仓库。如果不指定的话使用sparksql获取hive的时候可能会出只能获取define默认仓库的情况。.config("spark.sql.parquet.writeLegacyFormat", "true"):设置了写入 Parquet 格式数据时使用传统格式,确保兼容性和向后兼容性。因为spark写入和hive不同,使用该配置可保证spark写入hive的数据,hive能正常访问。.enableHiveSupport():启用了对 Hive 的支持,允许在 Spark 中使用 Hive 的功能和特性。.getOrCreate():最后使用.getOrCreate()方法创建或获取 SparkSession 实例。
总而言之,这段代码建立了与远程 Spark 服务器的连接,并配置了各种参数以确保应用程序能够正确地运行和访问集群资源。这是使用 PySpark 开展大数据处理工作的第一步,为后续的数据处理和分析创建了必要的环境和基础设施。
步骤 2:加载数据
df = spark.sql("SELECT * FROM cjw_data.xiecheng;")
使用 PySpark 的 spark.sql() 函数执行 SQL 查询,将查询结果加载到 DataFrame 中,为后续的数据操作和分析做好准备。这种灵活性和强大的数据处理能力是 PySpark 在大数据处理中的关键优势之一。
步骤 3:数据清洗与 JSON 格式转换
from pyspark.sql.functions import udf
import json
def json_clean(commentlist):
try:
jsonstr = str(commentlist)
s = jsonstr.replace("'", '"')
s = '[' + s.replace('}{', '},{') + ']'
python_obj = json.loads(s, strict=False)
json_str = json.dumps(python_obj)
return json_str
except:
return None
json_clean_udf = udf(json_clean, StringType())
df = df.withColumn("new_commentlist", json_clean_udf(df["commentlist"]))
newdf = df.withColumn("commentlist", df["new_commentlist"])
newdf = newdf.drop("new_commentlist")
在 PySpark 中定义并应用一个用户自定义函数(UDF)来对数据进行清洗和转换。
-
定义数据清洗函数:
json_clean()函数接收一个名为commentlist的参数,这个函数用于将从数据库中检索到的评论数据进行清洗。具体来说:jsonstr = str(commentlist):将传入的commentlist转换为字符串格式。s = jsonstr.replace("'", '"'):将字符串中的单引号替换为双引号,以满足 JSON 格式的要求。s = '[' + s.replace('}{', '},{') + ']':在字符串中的每个对象之间添加逗号,并将整个字符串包含在一个数组中,以满足 JSON 格式。python_obj = json.loads(s, strict=False):将字符串解析为 Python 对象。json_str = json.dumps(python_obj):将 Python 对象转换回 JSON 字符串格式。return json_str:返回清洗后的 JSON 字符串,如果清洗失败则返回None。
-
创建用户定义函数(UDF): 使用
udf()函数将 Python 函数json_clean()封装为 PySpark 的用户定义函数(UDF),以便在 Spark 中使用。 -
应用函数到 DataFrame:
df.withColumn()函数将定义的 UDF 应用于 DataFrame 中的commentlist列,并将处理后的结果存储到名为new_commentlist的新列中。 -
更新 DataFrame: 创建了一个新的 DataFrame
newdf,通过在原始 DataFramedf的基础上添加了经过清洗的commentlist列,并删除了原始的new_commentlist列。
步骤 4:保存清洗后的数据
newdf.write.mode("overwrite").saveAsTable("cjw_data.xiechengsentiment")
- 使用
write方法:write方法用于将 DataFrame 中的数据写入外部存储,可以是文件系统或数据库。 - 指定保存模式(Mode): 在这个例子中,
.mode("overwrite")指定了保存模式为 “overwrite”,即如果目标位置已存在同名的表或数据,将覆盖(重写)已有的内容。 - 保存为表(
saveAsTable):saveAsTable()方法将 DataFrame 中的数据保存为一个新的表,名为cjw_data.xiechengsentiment。这意味着,如果该表不存在,它将会被创建;如果表已存在,根据指定的模式进行重写或追加。
步骤 5:统计数据
comment_count = newdf.filter(newdf.commentlist != "[]").count()
total_count = newdf.count()
print("有效长度:", comment_count)
print("总长度:", total_count)
- 筛选非空数据行:
newdf.filter(newdf.commentlist != "[]")这部分代码使用filter()方法筛选出newdfDataFrame 中commentlist列不为空的行。这里使用的条件是commentlist != "[]",即不等于空列表的行。也就是筛选出之前udf函数里返还为空的那些解析JSON异常的行。 - 统计有效数据长度: 通过
count()方法统计筛选后的 DataFrame 中的行数,即得到了符合条件的有效数据的长度,并将结果存储在变量comment_count中。 - 统计总长度:
newdf.count()统计了整个 DataFrame 的行数,即获取了总长度,并将结果存储在变量total_count中。
截图示例
清洗后示意图:
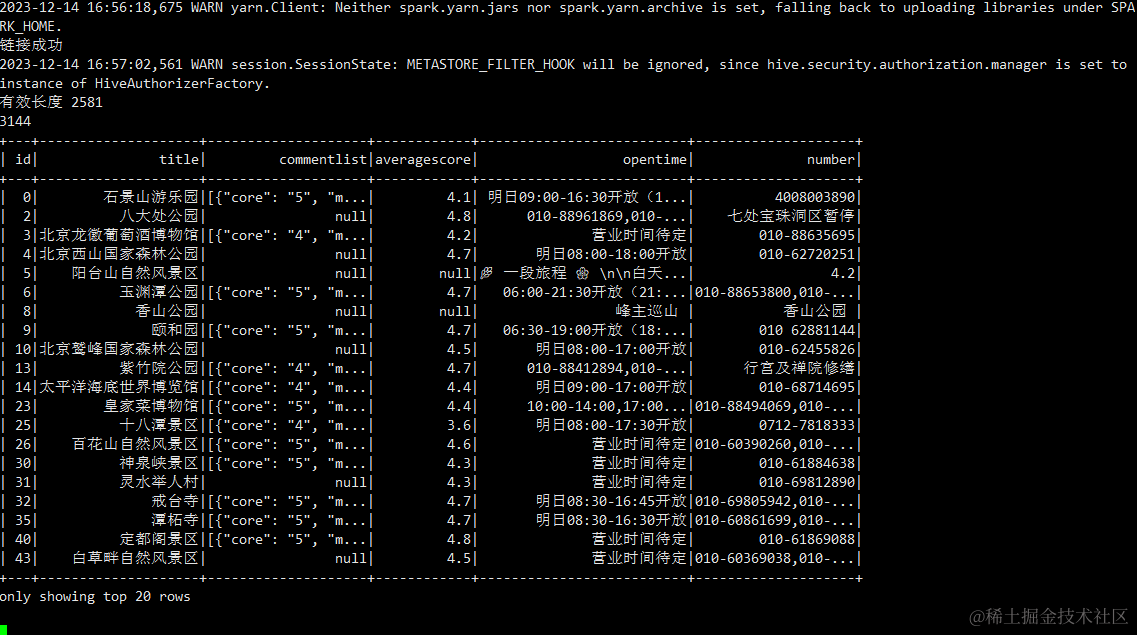
hive表中查看清洗后的数据:
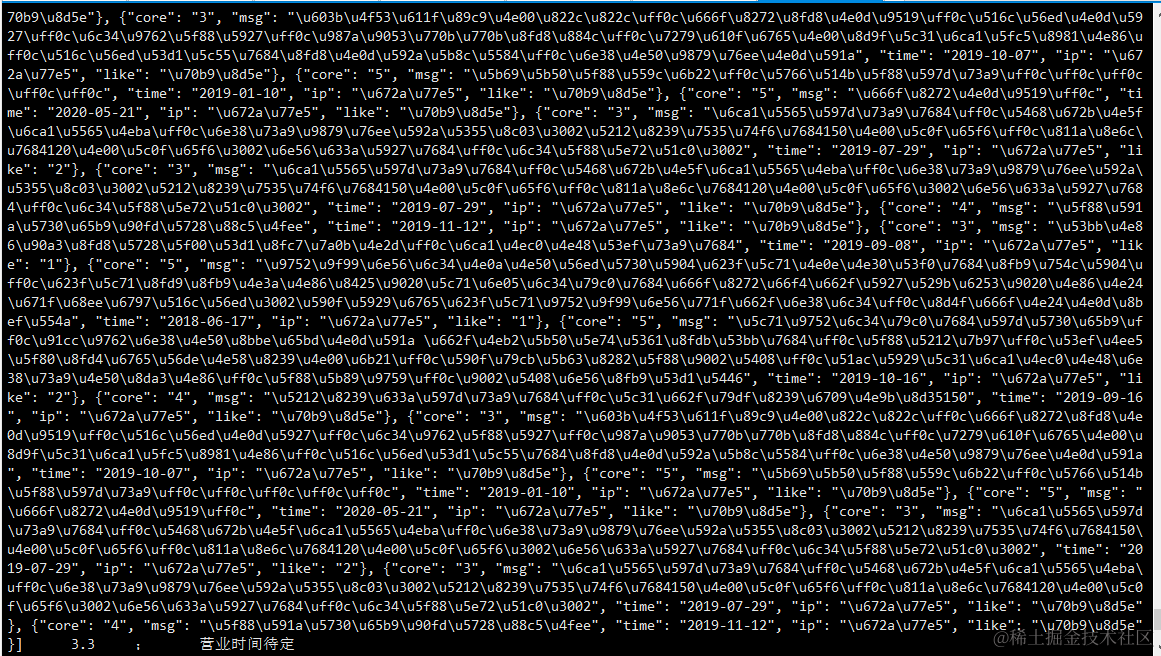
输出的字符串中包含了转义字符(例如 \u597d),这些字符实际上是 Unicode 字符的表示方式,而不是真正的乱码。
Python 中的 json.dumps() 方法默认将非 ASCII 字符串转换为 Unicode 转义序列。这种转义是为了确保 JSON 字符串可以被准确地传输和解析,但可能会在输出时显示为 Unicode 转义字符。
JSON 是一种数据交换格式,它使用 Unicode 转义序列(比如 \uXXXX)来表示非 ASCII 字符。在默认情况下,json.dumps() 将非 ASCII 字符转义为 Unicode 字符以确保其正确性,并且这种转义对于网络传输和解析是非常重要的
总结
本文介绍了使用 PySpark 对数据进行清洗和 JSON 格式转换的过程。通过上述步骤,我们可以连接到远程 Spark 服务器,加载数据,应用自定义函数对数据进行清洗和格式转换,并最终保存清洗后的数据。这个流程展示了 PySpark 在数据处理中的强大功能,特别是在大规模数据集的处理和转换方面的优势。如果本篇文章对您有所帮助,敬请收藏、点赞、















 2821
2821











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











