









VarifocalNet: An IoU-aware Dense Object Detector

Motivation
文中第三章作者基于FCOS+ATSS网络的实验结果是本文的动机,首先对这个实验中的每个AP逐一解析:
1 38.5:训练时没有centerness(ctr)分支
2 39.2:训练和测试时加入ctr分支,该方法设为baseline
3 41.1:基于baseline,把测试时的ctr换成label值,AP小幅提升0.9
4 43.5:基于baseline,把测试时的ctr换成预测框与gt框的iou,AP提升了4.3,比使用ctr高。
5 56.1:没有ctr分支,将测试时的bbox推理结果替换为gt bbox,分类结果仍是网络的预测结果
6 56.3:与上一个为对比实验,训练测试时多加入ctr,多引入的ctr只将AP提升了0.2。
7 43.1:没有ctr分支,将预测的分类结果替换为gt的类别标签,AP为43.1,只比实验1高4.6
8 58.1:与上一个为对比实验,多引入ctr分支,AP提升了15
9 74.7:没有ctr分支,将预测的分类结果替换为gt与预测框的IoU。
'''基于实验1,对比该实验和实验5,说明定位很准的框已经被预测出来了,但由于做NMS时分数不是最高的所以被淘汰了'''
10 67.4:与上一个为对比实验,多引入ctr分支,AP反而降低了
上述发现了一个问题:
目标检测网络的设计中 分类与定位 的相关性低,低分类得分数但高定位精度的预测框可能会被nms掉。
也就说其实定位精度已经很高的,但可惜被nms淘汰掉了,实验中发现这很影响最后的AP值。因为如果NMS中的排序分数是 预测框与gt框的IoU 的话那么定位最准的框就会被保留下来,但在实际中,网络预测的分类分数与 预测框与gt框的IoU 的差别还是很大的。所以如果让NMS使用的排序分数与IoU更靠近,那么就能提升AP值。FCOS中的centerness方法对此提升很有限。这个问题算是老问题了,GFL中就有提到过,但本文的实验让我们见识到了这个问题的重要性,把它完全挑明了。作者把具有IoU感知功能的分类分数缩写为IACS( IoU-aware Classification Score)。
VarifocalNet
作者基于以上发现,设计了新的检测器,称作 VarifocalNet,有三个创新点:Varifocal Loss, 星形边界框特征表达(star-shaped bounding box feature representation) 和更精致化的边界框(bounding box refinement )。
1. Varifocal Loss
作者设计了一个新的VFL来训练检测器去预测IACS。
Focal loss:
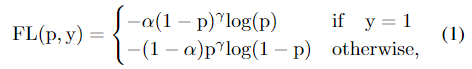 VarFocal loss:
VarFocal loss:
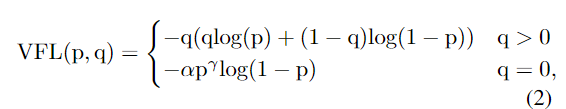
上式中p是预测的 IACS( IoU-aware classification score),q是目标分数,对于前景来说,q是 预测框与gt类的框 的IoU,背景则设置为0。
观察VFL,与GFL中的QFL相同,都是将交叉熵部分
−
log
(
p
)
- \log(p)
−log(p) 扩展为了
−
[
(
1
−
q
)
log
(
1
−
p
)
+
q
log
(
p
)
]
-[(1-q) \log (1-p)+q \log (p)]
−[(1−q)log(1−p)+qlog(p)], 即根据target q与0或1的距离对logp进行分解加权。
由于负样本远多于正样本,所以负样本项乘了
p
γ
p^{\gamma}
pγ降低比重,但对正样本并没有使用相同的项进行缩放,等于仍是加大了正样本对损失的贡献 。另一方面,前景却是乘了target q,这样训练更能关注到具有高质量bbox回归的正样本的分类分支的训练,因为这对得到高AP更重要。
最后,相比FL,整个式子使用α加权的方式也是不同的,只对负样本乘了α。
2. 星形的边界框特征表达
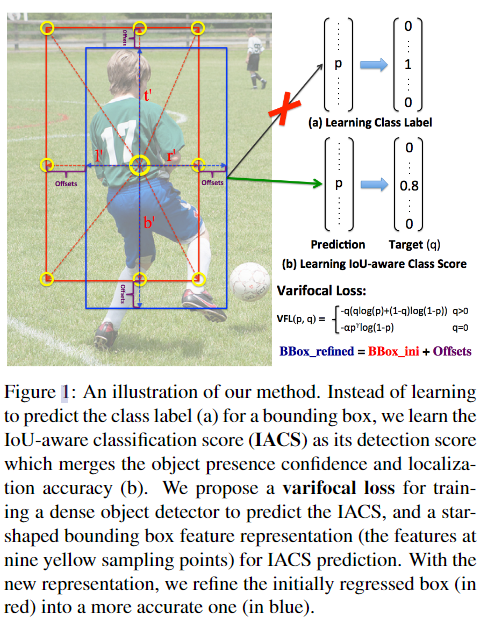
如上图红色的预测框属于最大的黄色中心锚点,蓝色框是本文另一个创新点微调后的最终预测框。现有anchor free的目标检测头(如FCOS),每个预测框对应的cls的预测是基于预测框所属锚点上抽取的特征做的,但预测框所属锚点所做的cls预测可能会感受野有限,无法精准覆盖整个预测框内的特征,更好的cls预测应该是基于预测的红框上的采样点去做。
新的九个采样点(图中黄圈)包含1个中心锚点,以及基于中心锚点和预测框的偏移量(l’, t’, r’, b’)得到的8个采样点,这八个点相对中心锚点的偏移量就作为可变形卷积的偏移量。最后将这9个采样点的特征用可变形卷积进行运算来表示一个边界框。由于是手选的采样点,没有多余预测负担,所以计算是很高效的。
3. Bounding Box Refinement
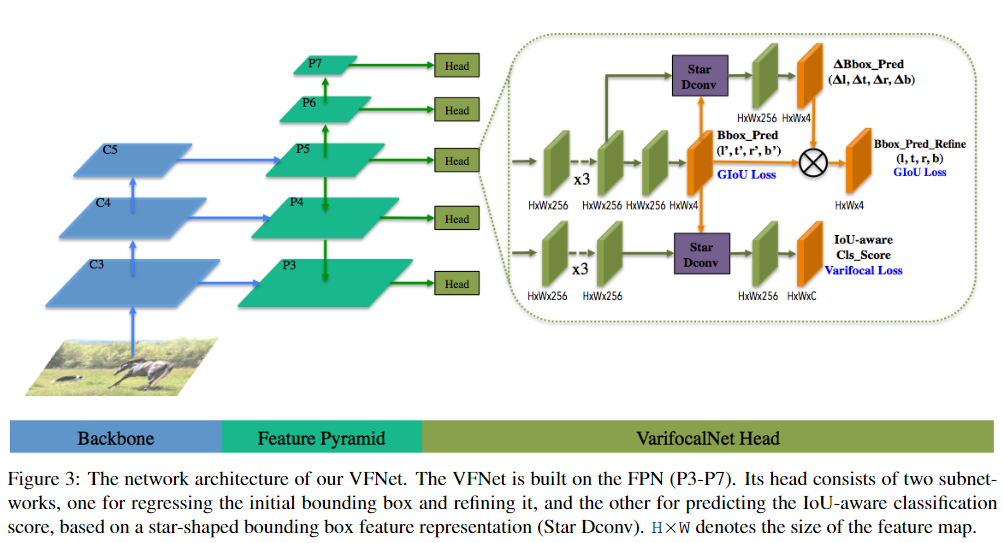
文章将Bounding Box Refinement作为一个残余学习问题( residual learning problem)进行建模(看head的这个结构就是像resnet的残差结构)。
如上图的head部分,模型首先进行回归预测得到一个初始的bbox(一般网络结构就是这样了),该初始bbox有(l’, t’, r’, b’)四个参数,
然后对该初始bbox使用星形表达进行编码。之后基于该表达,学习到四个距离缩放因子 (∆l, ∆t, ∆r, ∆b) ,去调整初始的bbox, 公式为(l, t, r, b) = (∆l×l’, ∆t×t’, ∆r×r’,∆b×b’),这样最后得到的bbox就更接近gt了(如figure1中初始框的offset被缩放了,形成了最终的蓝色预测框)。
这样关于bbox该网络会学到两组4D向量,也就会有两个有关bbox回归的损失函数。
损失函数
最后看一下损失:
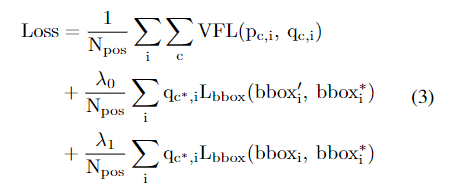
正负样本是用ATSS确定的,分类就用VFL,
L
b
b
o
x
L_{bbox}
Lbbox是GIoU损失,
λ是初始bbox和最终bbox损失的平衡系数,分别取1.5和2.0。注意
L
b
b
o
x
L_{bbox}
Lbbox有乘gt_IoU这一项,这个gt_IoU是当前bbox与gt bbox的交并比。
剩下就是实验结果啥的,不赘述了。
我的感受:
- IACS应该尽可能位于预测框上做,这样相关度更高,感受野更准确,那更好的做法不应该是在图一中的蓝色框上做吗?毕竟红色框还只是中间结果,最终的蓝色框是由Bounding Box Refinement进行了微调才得到的。
- 我其实对这个星形边界框表征比较感兴趣,使判断类别和估计框质量时使用的特征更完整,但消融实验中却没有分开做,是和精细化的边界框这个trick一起提高了0.9AP。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









