







爬虫开发步骤
一、环境介绍
开发工具:pycharm(社区版本)
python版本:3.7.4
scrapy版本:1.7.3
二、整体步骤
1.创建项目:scrapy startproject xxx(项目名字,不区分大小写)
2.明确目标 (编写items.py):明确你想要抓取的目标
3.制作爬虫 (spiders/xxspider.py):制作爬虫开始爬取网页
4.存储内容 (pipelines.py):设计管道存储爬取内容
5.设置settings.py:
- USER_AGENT=网页中-F12-网络-找到爬取地址的请求-右侧看消息头-找到USER_AGENT填写到该处;
- ROBOTSTXT_OBEY=False忽略被爬取网站的允许爬取列表限制,Ture根据授权列表爬取,没有权限的不去爬取
- DOWNLOAD_DELAY=下载延迟,数值
- ITEM_PIPELINES=多个管道处理时设置优先级,根据:xx冒号后面的数值大小排序
6.启动程序的py文件(start.py):等同于此命令(scrapy crawl xxx -o xxx.json)
三、开发准备
1.在pycharm工具setting中安装scrapy插件
2.项目右键选择打开终端
3.在终端中输入爬虫创建命令
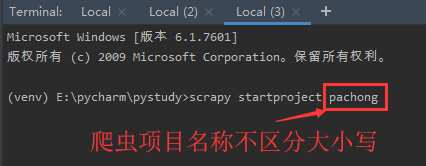
执行成功后在项目目录下生成爬虫项目
项目结构如下
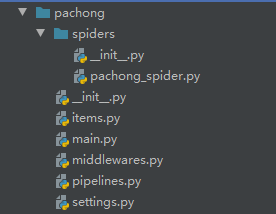
3.各个文件功能介绍
(1)iterms.py是用于封装爬虫爬取内容的实体,具体如下:
import scrapy
class PachongItem(scrapy.Item):
# define the fields for your item here like:
date = scrapy.Field()
open = scrapy.Field()
close = scrapy.Field()
height = scrapy.Field()
low = scrapy.Field()
updownd = scrapy.Field()
turnrate = scrapy.Field()
count = scrapy.Field()
如果要集成django,使用django的持久化对象以及其数据库操作能力的话,需要安装scrapy_djangoitem插件,然后做如下引用
import scrapy
from scrapy_djangoitem import DjangoItem
import blog.models as m # 保证django项目与爬虫项目在一个工程下,然后引用django的实体模型
class PachongItem(DjangoItem): # scrapy.Item
# define the fields for your item here like:
# date = scrapy.Field()
# open = scrapy.Field()
# close = scrapy.Field()
# height = scrapy.Field()
# low = scrapy.Field()
# updownd = scrapy.Field()
# turnrate = scrapy.Field()
# count = scrapy.Field()
django_model = m.Spider # m.spider是django中定义的实体
(2)pachong_spider.py爬虫主体方法,文件名可以自定义
from 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 2595
2595











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









