







CAP理论
CAP(Consistency一致性、Availability可用性、Partition-tolerance分区可容忍性)理论普遍被当作是大数据技术的理论基础
分布式领域CAP理论,
Consistency(一致性), 数据一致更新,所有数据变动都是同步的
Availability(可用性), 好的响应性能
Partition tolerance(分区容错性) 可靠性
关系数据库的ACID模型拥有 高一致性 + 可用性 很难进行分区:
Atomicity原子性:一个事务中所有操作都必须全部完成,要么全部不完成。
Consistency一致性. 在事务开始或结束时,数据库应该在一致状态。
Isolation隔离性. 事务将假定只有它自己在操作数据库,彼此不知晓。
Durability持久性. 一旦事务完成,就不能返回。
定理:任何分布式系统只可同时满足二点,没法三者兼顾。
架构师不要将精力浪费在如何设计能满足三者的完美分布式系统,而是应该进行取舍。
CAP历史
- C(一致性):所有的节点上的数据时刻保持同步
- A(可用性):每个请求都能接受到一个响应,无论响应成功或失败
- P(分区容错):系统应该能持续提供服务,即使系统内部有消息丢失(分区)
- CA without P:如果不要求P(不允许分区),则C(强一致性)和A(可用性)是可以保证的。但其实分区不是你想不想的问题,而是始终会存在,因此CA的系统更多的是允许分区后各子系统依然保持CA。
- CP without A:如果不要求A(可用),相当于每个请求都需要在Server之间强一致,而P(分区)会导致同步时间无限延长,如此CP也是可以保证的。很多传统的数据库分布式事务都属于这种模式。
- AP wihtout C:要高可用并允许分区,则需放弃一致性。一旦分区发生,节点之间可能会失去联系,为了高可用,每个节点只能用本地数据提供服务,而这样会导致全局数据的不一致性。现在众多的NoSQL都属于此类。
目前流行的、对CAP理论解释的情形是从同一数据在网络环境中的多个副本出发的。为了保证数据不会丢失,在企业级的数据管理方案中,一般必须考虑数据的冗余存储问题,而这应该是通过在网络上的其他独立物理存储节点上保留另一份、或多份数据副本来实现的(如附图所示)。因为在同一个存储节点上的数据冗余明显不能解决单点故障问题,这与通过多节点集群来提供更好的计算可用性的道理是相同的。
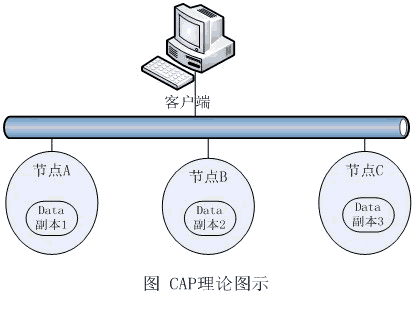
这样既然有三份数据,假设对节点A进行了数据修改,那么节点B和节点C也必须要对数据进行同步,否则会出现数据不一致的情况
那么要做到数据同步,很可能在同步的过程中发生异常从而不能及时正确的返回结果,所以就出现了两种不同的解决方法
第一种:
要求节点A、B、C的三份数据完全一致后返回。也就是说,这时从任何一个网络节点读取的数据都是一样的,这就是所谓的强一致性读。很明显,这时数据读取的Latency要高一些(因为要等数据在网络中的复制),同时A、B、C三个节点中任何一个宕机,都会导致数据不可用。也就是说,要保证强一致性,网络中的副本越多,数据的可用性就越差
第二种:
允许读操作立即返回,容忍B节点的读取与A节点的读取不一致的情况发生。这样一来,可用性显然得到了提高,网络中的副本也可以多一些,唯一得不到保证的是数据一致性
CAP理论的解释主要是从网络上多个节点之间的读写一致性出发考虑问题的。而这一点,对于关系型数据库意味着什么呢?当然主要是指通常所说的Standby(关于分布式事务,涉及到更多考虑,随后讨论)情况。对此,在实践中我们大多已经采取了弱一致性的异步延时同步方案,以提高可用性。这种情况并不存在关系型数据库为保证C、A而放弃P的情况;而对海量数据管理的需求,关系型数据库扩展过程中所遇到的性能瓶颈,似乎也并不是CAP理论中所描述的那种原因造成的。
关于对CAP理论中一致性C的理解,除了上述数据副本之间的读写一致性以外,分布式环境中还有两种非常重要的场景,如果不对它们进行认识与讨论,就永远无法全面地理解CAP,当然也就无法根据CAP做出正确的解释。但可惜的是,目前为止却很少有人提及这两种场景:那就是事务与关联。
当然,我们也可以说,最常使用的关系型数据库,因为这个原因,扩展性(分区可容忍性P)受到了限制,这是完全符合CAP理论的。但同时我们应该意识到,这对NoSQL数据库也是一样的。如果NoSQL数据库也要求严格的分布式事务功能,情况并不会比关系型数据库好多少。只是在NoSQL的设计中,我们往往会弱化甚至去除事务的功能,该问题才表现得不那么明显而已
从事务与关联的角度来关系型数据库的分区可扩展性为什么受限的原因是最为清楚的。而NoSQL数据库也正是因为弱化,甚至去除了像事务与关联(全面地讲,其实还有索引等特性)等在分布式环境中会严重影响系统可用性的功能,才获得了更好的水平可扩展性
在分布式系统做到分布式事务是有一定难度的及消费资源要比关系型数据库多的多,所以说NoSql一般也会弱化事务,
所以NoSql系统的主流还是主要保证AP,但是数据一致性又不能置之不顾,所以出现很多一致性方法
强一致性:用于分布式事务协议
弱一致性:能容忍更新后部分用户获取不到最新的数据
最终一致性:是弱一致性的一种特例,它可以保证用户最终获取的数据是最新的数据
NRW算法
假设总共有五个节点(N),我们只要保证写入数据的节点数(W)+ 读取数据的节点数(R)大于总节点数即可。即保证W+R>N,那就能保证对客户端而言,总是能读取到它最新写入的数据。比如,总节点数为5,写入节点数为3,读取节点数为3,那我们就能保证客户端总是能读取到它最新写入的数据。有了这样的数据公式的作为理论保证。我们就可以根据情况灵活选择W,R了。由于我们不需要保证5台机器全部都写入成功,只需要保证3台写入成功即可。这就意味着,我们允许5台机器中的2台出现问题,也就是提高了系统的可用性。这样的设计,虽然集群节点之间,也许有些节点的数据不是最新的,也就是没有做到CAP中的C,但对用户来说,数据总是一致的。

















 1074
1074

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









