







1 多维特征(Multiple features)
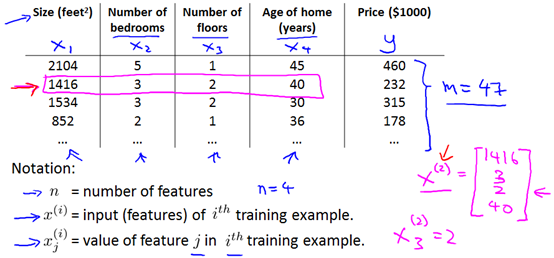
假设房价与图中四个变量(特征)有关,此时的假设函数为:
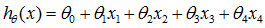
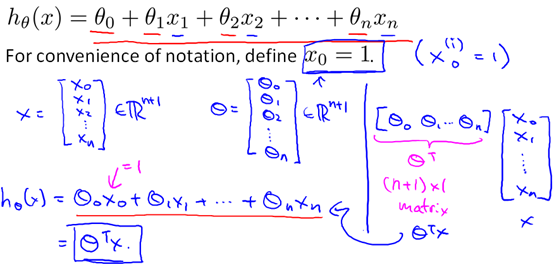
更具一般性的,假设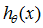
2 多变量梯度下降
下图分别为单变量梯度下降与多变量梯度下降算法:

3 梯度下降法实践1:特征收缩(Feature Scaling)
特征收缩是在处理多维变量(特征)时,确保这些变量具有相近的尺度。下图是预测房价的例子,房屋的尺寸(0-2000)跟卧室的数量(1-5),这两个特征的尺度差距较大,若不进行处理就会像下边的左图一样,等高线图很窄,梯度下降需要很多次迭代才能收敛。
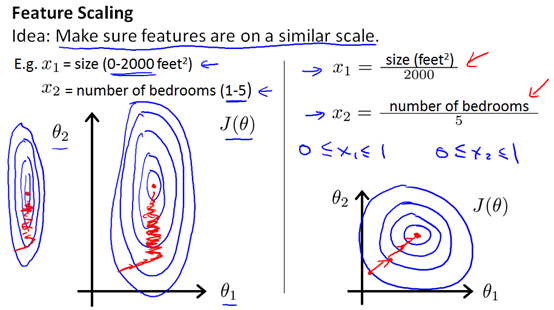
特征收缩是让每个特征都近似在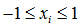
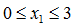

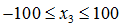
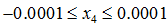
均值归一化(Mean normalization)
特征收缩不需要太精确(比如卧室的最大值-最小值=4或者5 关系不大),特征收缩可以将梯度下降的速度变得更快,让梯度下降收敛所需的迭代次数更少。
4 梯度下降法实践2:学习率(learning rate)
梯度下降算法收敛所需要的迭代次数根据模型的不同而不同,我们不能提前预知,我们可以绘制迭代次数和代价函数的图表来观测算法在何时趋于收敛。

从图中可以看出迭代300次后,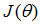
下图所示的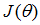


5 特征选择、多项式回归
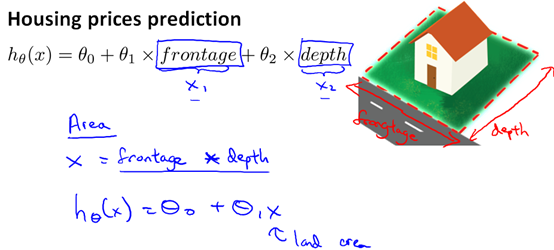
房屋价格预测问题,在选择特征时选临街宽度(frontage)和深度(depth)两个特征就不如选择房屋面积(frontage*depth)一个特征
在选择多项式进行拟合时,以房屋价格预测为例,收集的数据集如下图所示,如果选择二次多项式进行拟合,就会出现房价达到最大值后开始随着房屋面积的增大而减小,这时可以考虑用三次多项式进行拟合
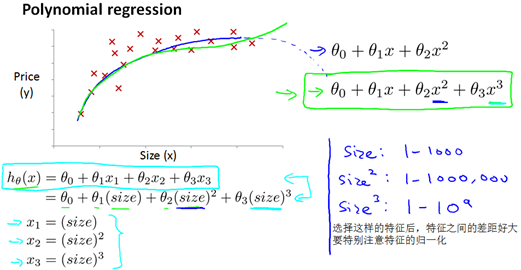
或者采用下边开根号的方式进行拟合
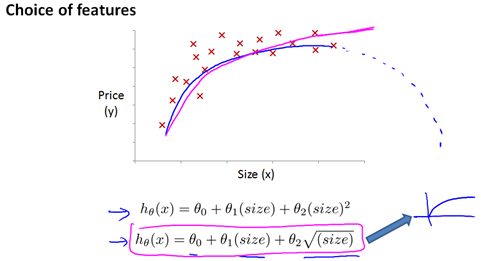
6 标准方程(normal equation)
一种求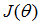
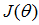
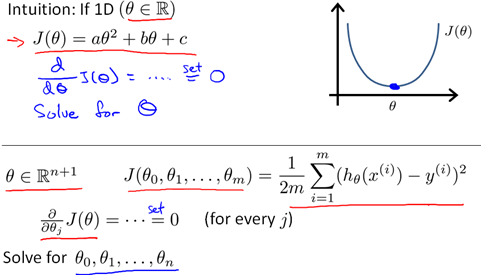
通过标准方程可以解得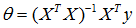

在Octave或者Matlab里命令为:pinv(X'*X)*X'*y
m个训练样本,n个特征时,梯度下降与标准方程的对比如下:

通过对比可以看出:表面上标准方程法比较方便一些,但是当n很大时计算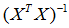
对于以后要学到的更复杂的算法比如分类算法、逻辑回归算法,不能使用标准方程法,对于更复杂的学习算法我们不得不使用梯度下降法。因此,梯度下降法是一个非常有用的算法,可以用于有大量特征的线性回归问题。对于特定的线性回归问题,特征量不是特别大的时候,标准方程法是一个比梯度下降法更快的算法。
7 标准方程及不可逆性(选修)
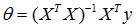
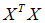
在Octave里,有两个函数可以求解矩阵的逆,一个被称为pinv(),另一个是inv(),这两者之间的差异是些许计算过程上的,一个是所谓的伪逆,另一个被称为逆。使用pinv() 函数可以展现数学上的过程,这将计算出θ的值,即便矩阵X'X是不可逆的。
当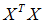

比如图中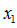
















 668
668

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









