






初始化一个scrapy项目
scrapy startproject ifengHotNews 用scrapy初始化一个爬虫项目
import scrapy
class getIfengNews(scrapy.Spider):
name = "hotNews"
start_urls = ["http://www.ifeng.com/"]
def parse(self, response):
for con in response.xpath('//div[@id="headLineDefault"]/ul/ul[2]/li'):
txt = con.xpath('a/text()').extract_first()
yield {'title': txt}
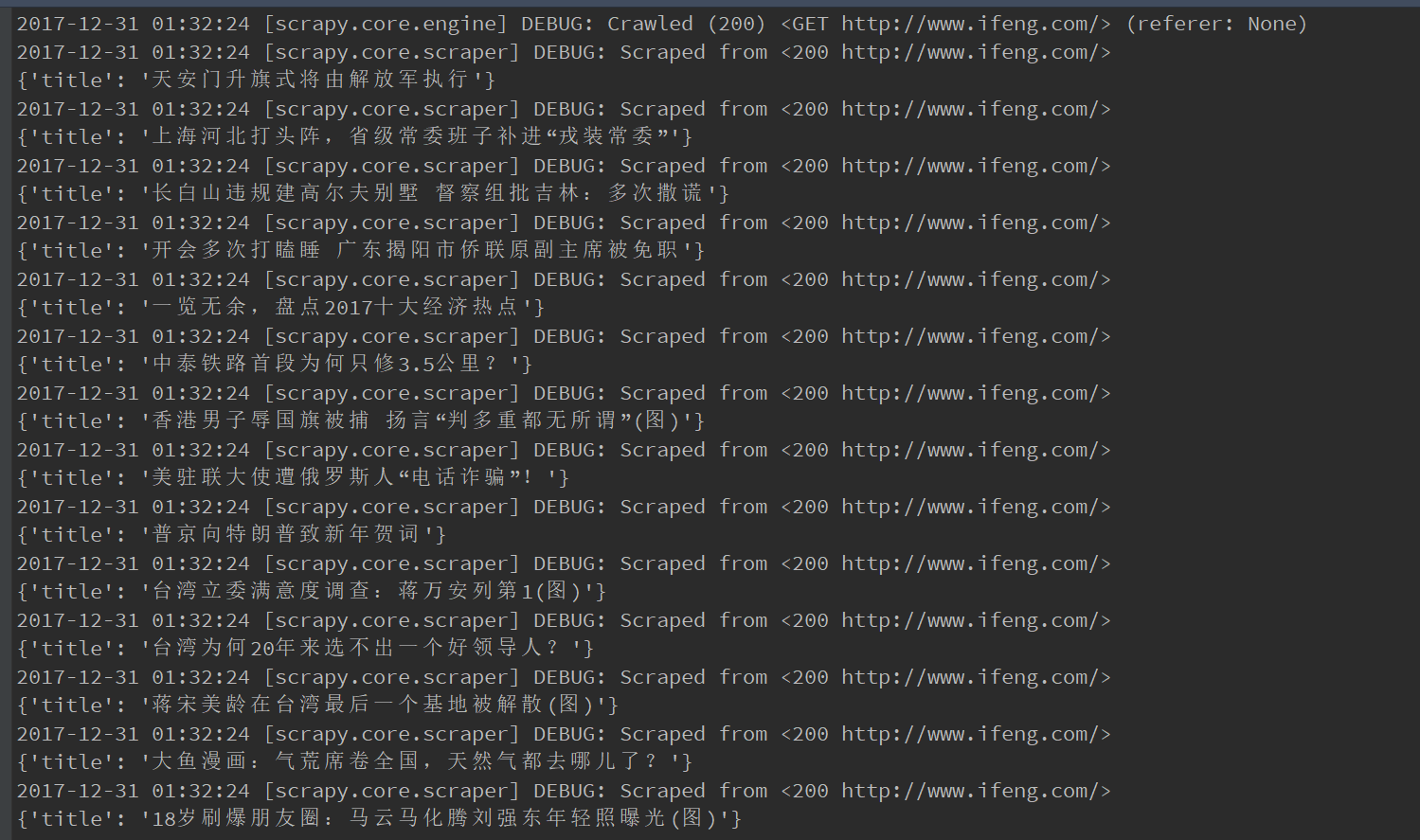
执行 scrapy runspider hotNews.py -o ./ifengHotNews.json
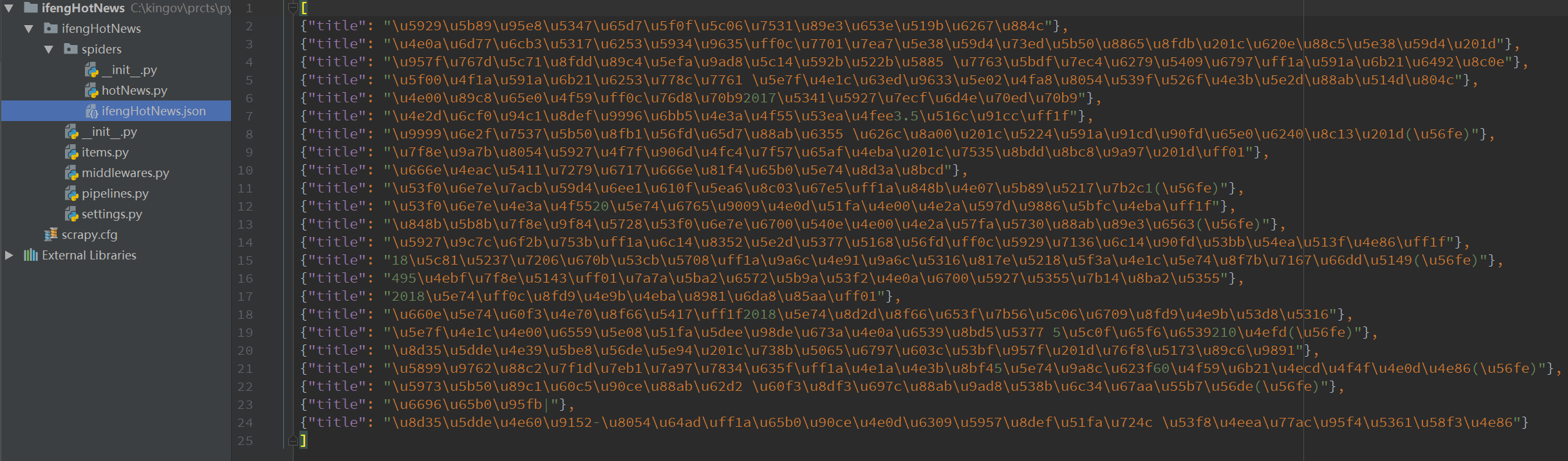
生成的文件















 1062
1062

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









