






web工作流程
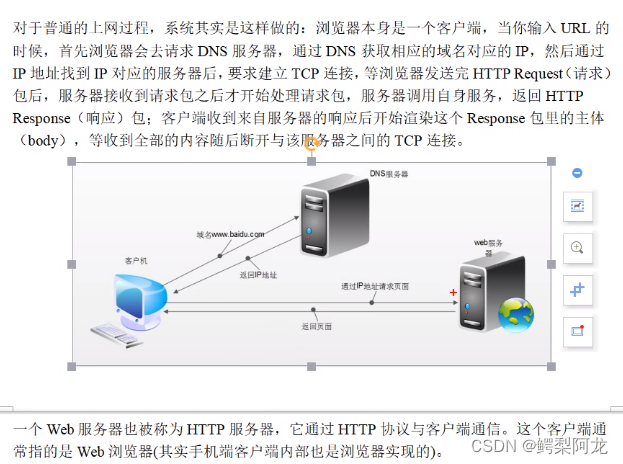

http协议
超文本传输协议,是互联网上最广泛的一种网络协议。
规定浏览器和服务器之间互相通信的规则

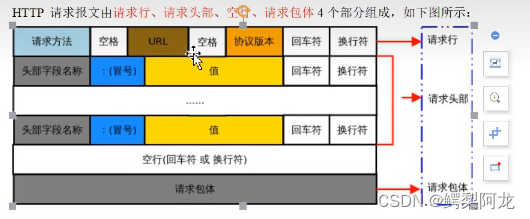
http请求报文
通过GO 网络编程 TCP、UDP from李文周-CSDN博客中客户端来进行测试,在edge浏览器中输入监听的ip和端口,得到信息如下:
#GET / HTTP/1.1
Host: 127.0.0.1:20000
Connection: keep-alive
Cache-Control: max-age=0
sec-ch-ua: "Microsoft Edge";v="117", "Not;A=Brand";v="8", "Chromium";v="117"
sec-ch-ua-mobile: ?0
sec-ch-ua-platform: "Windows"
Upgrade-Insecure-Requests: 1
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/117.0.0.0 Safari/537.36 Edg/117.0.2045.43
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7
Sec-Fetch-Site: none
Sec-Fetch-Mode: navigate
Sec-Fetch-User: ?1
Sec-Fetch-Dest: document
Accept-Encoding: gzip, deflate, br
Accept-Language: zh-CN,zh;q=0.9,en;q=0.8,en-US;q=0.7,en-GB;q=0.6
#第一行为请求行,这里可以得到请求方法为GET,一般用于获取/查询资源信息,post会附带用户数据,一般用于更新资源信息
之后为请求头

最后一行为空行,发送回车或换行符,通知服务器以下不再有请求头
user-agent部分:
User Agent中文名为用户代理,简称 UA,它是一个特殊字符串头,使得服务器能够识别客户使用的操作系统及版本、CPU 类型、浏览器及版本、浏览器渲染引擎、浏览器语言、浏览器插件等。
标准格式为: 浏览器标识 (操作系统标识; 加密等级标识; 浏览器语言) 渲染引擎标识 版本信息
Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/95.0.4638.69 Safari/537.36 Edg/95.0.1020.53
请求包体不再GET方法中使用,而是在post方法中使用。
更多user-agent部分:浏览器的“套娃行为”有多凶残? 3 分钟解惑 - 少数派 (sspai.com)
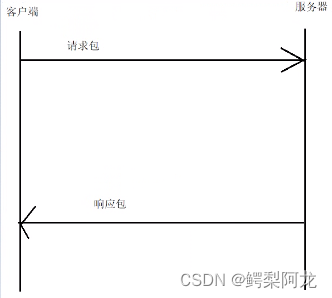
http响应报文
服务器测试代码
package main
import (
"fmt"
"net/http"
)
func myHandler(w http.ResponseWriter, r *http.Request) {
fmt.Fprintln(w, "hello world")
}
func main() {
http.HandleFunc("/go", myHandler)
//在指定的地址进行监听,开启一个http
http.ListenAndServe("127.0.0.1:8000", nil)
}
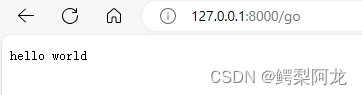
请求代码:
通过之前得到的请求报文,向服务器发出,得到相应报文
package main
import (
"fmt"
"net"
)
func main() {
conn, err := net.Dial("tcp", "127.0.0.1:8000")
if err != nil {
fmt.Println("err =", err)
return
}
fmt.Println("connect")
//
defer conn.Close()
requestHeader := "GET /go HTTP/1.1\r\nHost: 127.0.0.1:8000\r\nConnection: keep-alive\r\nCache-Control: max-age=0\r\nUpgrade-Insecure-Requests: 1\r\nUser-Agent: Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36\r\nAccept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3\r\nAccept-Encoding: gzip, deflate, \r\nAccept-Language: zh-CN,zh;q=0.9,ja;q=0.8,en;q=0.7\r\n\r\n"
// 先发请求包,服务器才会回响应包
_, writeErr := conn.Write([]byte(requestHeader))
fmt.Println("request")
if err != nil {
fmt.Println("writeErr =", writeErr)
}
// 接收服务器回复的响应包
buf := make([]byte, 1024*4)
n, readErr := conn.Read(buf)
if readErr != nil {
if readErr != nil {
fmt.Println("readErr =", readErr)
} else {
fmt.Println("null response")
}
return
}
//
responseStr := string(buf[:n])
fmt.Printf("#%v#", responseStr)
}
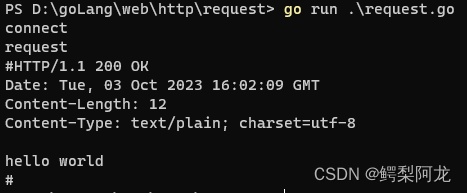
报文内容
成功
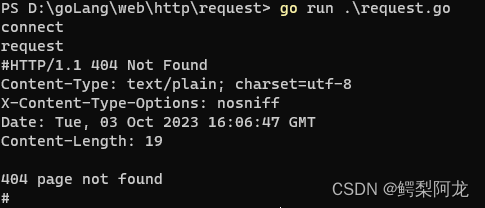
失败
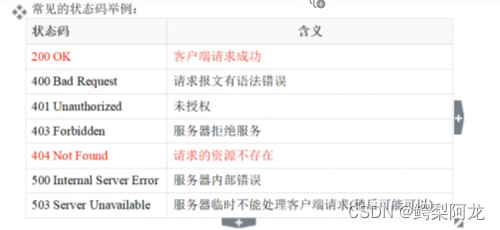
都由:
响应头
相应行
空行
包体
组成
http编程
func HandleFunc
func HandleFunc(pattern string, handler func(ResponseWriter, *Request))
HandleFunc注册一个处理器函数handler和对应的模式pattern(注册到DefaultServeMux)。ServeMux的文档解释了模式的匹配机制。
func ListenAndServe
func ListenAndServe(addr string, handler Handler) error
ListenAndServe监听TCP地址addr,并且会使用handler参数调用Serve函数处理接收到的连接。handler参数一般会设为nil,此时会使用DefaultServeMux。
一个简单的服务端例子:
package main
import (
"io"
"net/http"
"log"
)
// hello world, the web server
//w:给客户端回复数据 req:给客户端发送数据
func HelloServer(w http.ResponseWriter, req *http.Request) {
io.WriteString(w, "hello, world!\n")
}
func main() {
//注册处理函数,用户连接,自动调用指定处理函数
http.HandleFunc("/hello", HelloServer)
//监听绑定
err := http.ListenAndServe(":12345", nil)
if err != nil {
log.Fatal("ListenAndServe: ", err)
}
}客户端编写
package main
import (
"fmt"
"net/http"
)
func main() {
r, err := http.Get("www.baidu.com")
if err != nil {
fmt.Printf("err: %v\n", err)
return
}
defer r.Body.Close()
buf := make([]byte, 1024)
n, _ := r.Body.Read(buf)
fmt.Printf("buf: %v\n", string(buf[:n]))
fmt.Printf("r.Header: %v\n", r.Header)
}错误提示:
err: Get "www.baidu.com": unsupported protocol scheme ""
通过在get部分前加入http解决,需要添加完整的协议。如https或者http。
r, err := http.Get("http://www.baidu.com")package main
import (
"fmt"
"io"
"net/http"
)
func main() {
//发出HTTP/ HTTPS请求。
r, err := http.Get("http://www.baidu.com")
// r, err := http.Get("127.0.0.1:8000")
if err != nil {
fmt.Printf("err: %v\n", err)
return
}
//程序在使用完回复后必须关闭回复的主体。
defer r.Body.Close()
//使用io。readall进行读取
b, _ := io.ReadAll(r.Body)
fmt.Printf("b: %v\n", string(b))
//循环读取,直到读完所有内容
// buf := make([]byte, 1024)
// var temp string
// for {
// n, err := r.Body.Read(buf)
// if err == io.EOF {
// break
// }
// temp += string(buf[:n])
// }
// fmt.Printf("r.Body: %v\n", r.Body)
// fmt.Printf("response: %v\n", temp)
fmt.Printf("r.Header: %v\n", r.Header)
}由此可以获取服务器返回的包体中的内容
爬虫部分
四个步骤:
1.明确目标:知道在哪个范围或网址去搜索
2.爬:将网站所有的内容爬下来
3.取:取出对我们有用的 或者 去掉对我们没用的数据
4.处理数据:按照我们想要的方式存储和使用
爬取百度贴吧 内容
海贼王 吧 首页
https://tieba.baidu.com/f?kw=海贼王&ie=utf-8&pn=0
海贼王 吧 第二页
https://tieba.baidu.com/f?kw=海贼王&ie=utf-8&pn=50
孙笑川 吧 第二页
https://tieba.baidu.com/f?kw=孙笑川&ie=utf-8&pn=50
可以得到贴吧格式:
根据贴吧名和起始页进行爬取。并进行文件保存
我的版本
package main
import (
"fmt"
"io"
"net/http"
"os"
"strconv"
)
func main() {
//发出HTTP/ HTTPS请求。
var name string
var page, page2 int
fmt.Println("请输入要爬取的贴吧名,开始页数和结束页数,中间用空格隔开")
fmt.Scan(&name, &page, &page2)
for i := page; i < page2+1; i++ {
n := (i - 1) * 50
// fmt.Printf("n: %v\n", n)
s := strconv.Itoa(n)
website := "https://tieba.baidu.com/f?kw=" + name + "&ie=utf-8&pn=" + s
r, err := http.Get(website)
if err != nil {
fmt.Printf("err: %v\n", err)
return
}
//程序在使用完回复后必须关闭回复的主体。
defer r.Body.Close()
//使用io。readall进行读取
b, _ := io.ReadAll(r.Body)
// fmt.Printf("b: %v\n", string(b))
fmt.Println("-----------------------------------------------------------------------------------")
filename := name + "吧" + "第" + strconv.Itoa(i) + "页" + ".html" //页数从int类型转string,可以使用strconv。itoa来进行
f, err2 := os.Create(filename)
if err2 != nil {
fmt.Printf("create file failed ,err2: %v\n", err2)
}
f.Write(b)
fmt.Println(website)
defer f.Close()
}
}
原版
package main
import (
"fmt"
"net/http"
"os"
"strconv"
)
/**
* 实际上爬虫一共就四个主要步骤
* 1)明确目标(要知道你准备在哪个范围或者网站去搜索)
* 2)爬(将所有的网站的内容全部爬下来)
* 3)取(去掉对我们没用的数据)
* 4)处理数据(按照我们想要的方式存储和利用)
*/
// http://tieba.baidu.com/f?kw=%E8%A1%A1%E6%B0%B4%E5%AD%A6%E9%99%A2&ie=utf-8&pn=0
// http://tieba.baidu.com/f?kw=%E8%A1%A1%E6%B0%B4%E5%AD%A6%E9%99%A2&ie=utf-8&pn=50
// http://tieba.baidu.com/f?kw=%E8%A1%A1%E6%B0%B4%E5%AD%A6%E9%99%A2&ie=utf-8&pn=100
func main() {
var start, end int;
fmt.Printf("请输入起始页(>= 1):");
fmt.Scan(&start);
fmt.Printf("请输入终止页(>= 起始页):");
fmt.Scan(&end);
//
SpiderPages(start, end);
}
func SpiderPages(start, end int) {
baseUrl := "http://tieba.baidu.com/f?kw=%E8%A1%A1%E6%B0%B4%E5%AD%A6%E9%99%A2&ie=utf-8&pn=";
fmt.Printf("正在爬取 %d 到 %d 的页面", start, end);
//
for i := start; i <= end; i++ {
// 1)明确目标(要知道你准备在哪个范围或者网站去搜索)
url := baseUrl + strconv.Itoa((i-1)*50);
fmt.Println("url =", url);
// 2)爬(将所有网站的内容抓取下来
result, httpGetErr := HttpGet(url);
if httpGetErr != nil {
fmt.Println("HttpGetErr =", httpGetErr);
}
// 3)把内容写进文件
fileName := "./iofiles/tieba.hsnc-" + strconv.Itoa(i) + ".html";
f, fCreateErr := os.Create(fileName);
if fCreateErr != nil {
fmt.Println("fCreateErr =", fCreateErr);
continue; // 这里不能用return,要不后面的也没法存了
}
f.WriteString(result);
f.Close();
}
}
func HttpGet(url string) (result string, err error) {
resp, httpGetErr := http.Get(url);
if httpGetErr != nil {
return "", httpGetErr;
}
//
defer resp.Body.Close();
//
buf := make([]byte, 1024*4);
result = "";
for {
n, respReadErr := resp.Body.Read(buf);
if n == 0 { // 读取结束或者出问题
fmt.Println("respReadErr =", respReadErr);
break;
}
//
result += string(buf[:n]);
}
return result, nil;
}
并发版
若只是单纯通过将函数封包使用go routine来玩完成并发,会使主协程提前结束,若最会以for循环来使所有协程结束,会使cpu、内存使用率过高
因此我们需要使用管道阻塞来保证主协程运行到最后
package main
import (
"fmt"
"io"
"net/http"
"os"
"strconv"
)
var baseUrl string = "http://tieba.baidu.com/f?kw=孙笑川&ie=utf-8&pn="
func main() {
var start, end int
fmt.Printf("请输入起始页(>= 1):")
fmt.Scan(&start)
fmt.Printf("请输入终止页(>= 起始页):")
fmt.Scan(&end)
//
SpiderPages(start, end)
}
// 根据起始页对网站进行爬取并保存内容
func SpiderPages(start, end int) {
fmt.Printf("正在爬取 %d 到 %d 的页面", start, end)
//通过管道确保所有协程运行完毕
page := make(chan int)
//
for i := start; i <= end; i++ {
go spider(i, page)
// // 1)明确目标(要知道你准备在哪个范围或者网站去搜索)
// url := baseUrl + strconv.Itoa((i-1)*50)
// fmt.Println("url =", url)
// // 2)爬(将所有网站的内容抓取下来
// result, httpGetErr := HttpGet(url)
// if httpGetErr != nil {
// fmt.Println("HttpGetErr =", httpGetErr)
// }
// // 3)把内容写进文件
// fileName := "孙笑川吧" + strconv.Itoa(i) + ".html"
// f, fCreateErr := os.Create(fileName)
// if fCreateErr != nil {
// fmt.Println("fCreateErr =", fCreateErr)
// continue // 这里不能用return,要不后面的也没法存了
// }
// f.WriteString(result)
// f.Close()
}
//每当爬完一页之后,将读完的page传回,结束这里阻塞的通道
for i := start; i <= end; i++ {
fmt.Printf("第%d个页面爬取完成\n", <-page)
}
}
// 向url发出请求相应,并读取消息体中内容
func HttpGet(url string) (result string, err error) {
resp, httpGetErr := http.Get(url)
if httpGetErr != nil {
return "", httpGetErr
}
//
defer resp.Body.Close()
//
r, err2 := io.ReadAll(resp.Body)
if err2 != nil {
fmt.Printf("read failed,err2: %v\n", err2)
}
result = string(r)
return result, nil
}
func spider(i int, page chan int) {
// 1)明确目标(要知道你准备在哪个范围或者网站去搜索)
url := baseUrl + strconv.Itoa((i-1)*50)
fmt.Println("url =", url)
// 2)爬(将所有网站的内容抓取下来
result, httpGetErr := HttpGet(url)
if httpGetErr != nil {
fmt.Println("HttpGetErr =", httpGetErr)
}
// 3)把内容写进文件
fileName := "孙笑川吧" + strconv.Itoa(i) + ".html"
f, fCreateErr := os.Create(fileName)
if fCreateErr != nil {
fmt.Println("fCreateErr =", fCreateErr)
return // 这里不能用return,要不后面的也没法存了
}
f.WriteString(result)
defer f.Close()
page <- i
}
后续对爬取内容的筛选可以参考it黑马的视频,因为原来的网站失效,这里不再演示,通过正则表达式来完成即可


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









