






目录
工程背景
首先发表一个"暴论"
eBPF在可观测方面的应用,就是各种google。
不需要学习内核,只要掌握ebpf开发套路。
好比你开发 web 开发网站, 你了解socket 底层和内核吗? 一样不了解。 知道怎么调用就行了。
而且 eBPF 的开发也没多少复杂度, 更多的是 在内核态拦截(简化的c语言) 内核数据(不管是网络数据还是tracepoint数据), 最终都是要发给用户态(可以理解为java、golang),然后用户态具体做业务处理。
所以c语言也不需要怎么学,学了也没啥用。
更多的是要学会一些Linux知识。 譬如拦截网络数据,那就得 对tcp/ip协议了解的很清楚,知道怎么寻址。
至于说寻址代码怎么写,chatgpt都能把你生成。
因此,我们就只从其如何使用切入,用短平快的方式上手掌握。目标是用c语言处理内核态,发送到用户态用golang处理,至于把监控数据塞到mysql、prom之类的,那都属于可扩展内容。
另外,通过eBPF,我们可以做到一些应用层做不到或者不应该做到的事情。譬如ddos拦截应该放在eBPF,即网卡协议层面就应该拦截。而不是放在nginx上拦截,因为进入nginx已经到用户层了,这无疑会对系统负载造成巨大压力 。
对于网络流量控制和管理,一般有traffic control、tracepoint、XDP两种常用方式,区别如下:
- Traffic Control(TC):Traffic Control 是 Linux 内核中的一个子系统,用于网络流量的控制和管理。eBPF 可以与 TC 结合使用,通过编写 eBPF 程序来对网络流量进行更细粒度的控制和处理,例如流量分类、队列管理、带宽控制等。eBPF 可以在 TC 的不同阶段插入自定义的程序逻辑,以实现高级的流量控制功能。
- Tracepoint:Tracepoint 是 Linux 内核中的一种跟踪工具,用于收集系统和应用程序的运行时信息。eBPF 提供了一种机制,可以在 Tracepoint 上运行自定义的 eBPF 程序,以收集、分析和处理 Tracepoint 产生的事件数据。通过 eBPF,可以对系统的各种事件进行跟踪和监控,例如进程创建、系统调用、网络流量等,而无需修改内核代码。
- XDP(eXpress Data Path):XDP 是 Linux 内核中的一种高性能数据包处理框架,用于在网络驱动程序接收数据包之前对其进行处理。eBPF 可以与 XDP 结合使用,编写 eBPF 程序对数据包进行高效的过滤、修改和重定向操作。XDP 允许在数据包进入网络协议栈之前进行快速的数据包处理,适用于高性能网络应用,如防火墙、负载均衡和数据包捕获。
简而言之,
- Tracepoint也可以用于网络,但是其并不修改内核,因此只能对一些事件进行跟踪监控。
- tc作用在linux流量控制器traffic controller,既可作ingress又可作egress;而xdp作用在设备驱动上,一般就作ingress,同时性能更高。
- tc是本身存在的,因此只需要创建一个clsact类型的队列作为程序挂载的入口,就像hook一样,可以更方便地修改报文,端口,地址等。而xdp需要将上下文从链路层、网络层、传输层一步步获取。
所以我们就通过TC去拦截veth设备上通过的网卡流量,甚至去篡改数据包以实现伪造源ip或者目标端口转发。
环境准备
eBPF依赖高内核版本的linux,所以我准备了:
- 操作系统 ubuntu22 内核5.15
- 安装docker golang openssl3(这里直接使用了腾讯云的容器专用的虚拟机镜像)
安装工具
go get github.com/cilium/ebpf/cmd/bpf2go
go install github.com/cilium/ebpf/cmd/bpf2go需要添加/go/bin到环境变量中,用于执行生成的工具文件
这是转换程序,允许在Go 代码中编译和嵌入eBPF 程序
安装依赖包
sudo apt install llvm
sudo apt install clang安装C依赖库
sudo apt install libelf-dev
git clone --depth 1 https://github.com/libbpf/libbpf
cd src
make install这个库运行报错,拿软链接尝试解决了问题
sudo ln -s /usr/include/x86_64-linux-gnu/asm /usr/include/asm操作步骤
简要地描述一下操作的步骤
1.项目目录下执行make把操作内核态的c文件编译生成.go和.o文件 2.编写方法来加载bpf program对象,创建队列,挂载网卡,最后供main函数调用 3.go run cmd/tc/main.go运行 4.命令行查看go的输出 或者 cat /sys/kernel/debug/tracing/trace_pipe查看bpf_printk输出(限于使用tc工具创建队列和挂载网卡)
tips: 1.通过perf list|grep sys_exit_execve 查看具体的tracepoint 2.通过cat /sys/kernel/debug/tracing/available_filter_functions|grep finish_task_switch 查看具体的kprobe(这里的名称用于用户态去link) 3.如需读取内核数据,如获取父进程pid,可以执行 bpftool btf dump file /sys/kernel/btf/vmlinux format c > vmlinux.h 包含了系统运行Linux 内核源代码中使使用的所有类型定义 4.https://github.com/torvalds/linux 查看源码获取内核函数的签名
目录结构
. ├── Makefile `用来加载环境变量并执行编译` ├── cebpf │ ├── headers `用于存放bpf相关的头文件` 下载自源码 │ └── docker `容器间网络互访,包含了xdp,tc` │ ├── doc.go `实际的编译命令存放的地方,通过makefile来指向` │ ├── loader.go `创建队列,绑定网卡,从内核获取数据` │ ├── dockertc.bpf.c `原始bpf代码` │ ├── mydockertc_bpfeb.o `⬆️ 编译生成的文件` │ ├── mydockertc_bpfeb.go `⬇️ 包含了所要加载的bpf程序对象` ├── cmd │ └── tc │ └── main.go `主函数入口`
代码展示
1.Makefile
CLANG ?= clang
CFLAGS ?= -O2 -g -Wall -Werror
EBPF_ROOT = /home/ubuntu/app/goebpf/cebpf
MY_HEADERS = $(EBPF_ROOT)/headers
all: generate
generate: export BPF_CLANG=$(CLANG)
generate: export BPF_CFLAGS=$(CFLAGS)
generate: export BPF_HEADERS=$(MY_HEADERS)
generate:
go generate ./...
调用 go:generate 关键词来进行编译
2.doc.go
package docker
//go:generate bpf2go -cc $BPF_CLANG -cflags $BPF_CFLAGS -target amd64 mydockertc dockertc.bpf.c -- -I $BPF_HEADERS通过这步编译命令,我们可以将 dockertc.bpf.c 编译出 .go 和 .o文件。
.go文件包含了bpg program对象,用于golang的用户态调用。
.o文件可以执行用于命令行tc可执行程序挂载网卡
有如下:
traffic control入门——命令行方式加载bpf程序 1.tc qdisc add dev docker0 clsact ---使用docker0创建一个队列 2.tc filter add dev docker0 ingress bpf direct-action obj mydockertc_x86_bpfel.o 清理命令 tc qdisc del dev docker0 clsact 查看命令 tc filter show dev docker0 ingress
3.dockettc.bpf.c
//go:build ignore
#include <vmlinux.h>
#include <bpf_helpers.h>
#include <bpf_endian.h>
#include <bpf_tracing.h>
#include <bpf_legacy.h>
#define ETH_HLEN 14 //以太网头部长度
#define IP_CSUM_OFF (ETH_HLEN + offsetof(struct iphdr, check))
#define TOS_OFF (ETH_HLEN + offsetof(struct iphdr, tos))
#define TCP_CSUM_OFF (ETH_HLEN + sizeof(struct iphdr) + offsetof(struct tcphdr, check)) //csum的偏移量
#define IP_SRC_OFF (ETH_HLEN + offsetof(struct iphdr, saddr))
#define TCP_DPORT_OFF (ETH_HLEN + sizeof(struct iphdr) + offsetof(struct tcphdr, dest)) //目标端口的偏移量
#define TCP_SPORT_OFF (ETH_HLEN + sizeof(struct iphdr) + offsetof(struct tcphdr, source)) //目标端口的偏移量
#define IS_PSEUDO 0x10
char LICENSE[] SEC("license") = "GPL";
struct tc_data_ip {
__u32 sip; //源IP地址
__u32 dip; //目的IP地址
__u32 sport; //源端口
__u32 dport; //目的端口
};
//ringbuf
struct { //ringbuf,环形缓冲区,算是一种用户内核交互的优先选择
__uint(type, BPF_MAP_TYPE_RINGBUF);
__uint(max_entries,1<<20); //大概是10M大小
} tc_ip_map SEC(".maps");
//从skb获取ip头部
static inline int iph_dr(struct __sk_buff *skb, struct iphdr *iph) //内连函数,编译时直接展开,减少函数调用开销
{
int offset = sizeof(struct ethhdr); //计算以太网头部的偏移量
return bpf_skb_load_bytes(skb, offset, iph, sizeof(*iph));
}
//从skb获取tcp头部
static inline int tcph_dr(struct __sk_buff *skb, struct tcphdr *tcph) //内连函数,编译时直接展开,减少函数调用开销
{
int offset = sizeof(struct ethhdr) + sizeof(struct iphdr); //计算以太网头部和ip头部的偏移量
return bpf_skb_load_bytes(skb, offset, tcph, sizeof(*tcph));
}
//改源ip的,没用上,先注释了
//todo 使用目标ip重定向的问题在于,就是old_ip一定得要真实存在才可以,否则连二层arp都通过不了,需要做arp欺骗
//static inline void set_tcp_ip_src(struct __sk_buff *skb, __u32 new_ip)
//{
// __u32 old_ip = bpf_htonl(load_word(skb, IP_SRC_OFF));
//
// bpf_l4_csum_replace(skb, TCP_CSUM_OFF, old_ip, new_ip, IS_PSEUDO | sizeof(new_ip));
// bpf_l3_csum_replace(skb, IP_CSUM_OFF, old_ip, new_ip, sizeof(new_ip));
// bpf_skb_store_bytes(skb, IP_SRC_OFF, &new_ip, sizeof(new_ip), 0);
//}
static inline void set_tcp_dest_port(struct __sk_buff *skb, __u16 new_port)
{ //源码 —— https://github.com/torvalds/linux/blob/master/samples/bpf/tcbpf1_kern.c
__u16 old_port = bpf_htons(load_half(skb, TCP_DPORT_OFF));
bpf_l4_csum_replace(skb, TCP_CSUM_OFF, old_port, new_port, sizeof(new_port)); //1.修改校验和csum
bpf_skb_store_bytes(skb, TCP_DPORT_OFF, &new_port, sizeof(new_port), 0); //2.重新存储到skb
}
static inline void set_tcp_src_port(struct __sk_buff *skb, __u16 new_port)
{
__u16 old_port = bpf_htons(load_half(skb, TCP_SPORT_OFF));
bpf_l4_csum_replace(skb, TCP_CSUM_OFF, old_port, new_port, sizeof(new_port));
bpf_skb_store_bytes(skb, TCP_SPORT_OFF, &new_port, sizeof(new_port), 0);
}
SEC("classifier") //代表tc的流量分类
int mytc(struct __sk_buff *skb)
{
struct iphdr ip;
iph_dr(skb, &ip);
struct tcphdr tcp;
tcph_dr(skb, &tcp);
//打包网络数据
//如果ip包是tcp协议,才发送数据
if(ip.protocol != IPPROTO_TCP){
return 0;
}
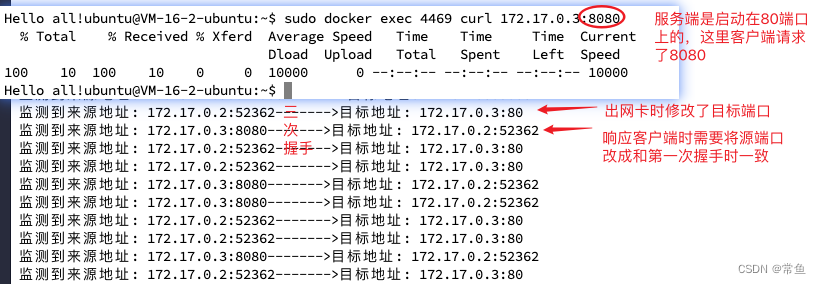
//作用:将访问到172.17.0.3:8080重定向到172.17.0.3:80
__u16 watch_port = bpf_ntohs(tcp.dest); //目标端口
__u32 watch_ip = bpf_ntohl(0xAC110003); //172.17.0.3
if (watch_port == 8080 && ip.daddr == watch_ip) {
set_tcp_dest_port(skb, bpf_htons(80)); //修改目标端口 A -> B 8080 -> 80
tcph_dr(skb, &tcp); //重新读取skb数据到tcp
}
//这次修改的是tcp三次握手中第二次也就是服务端响应的端口,否则客户端接收到的源端口与目标端口不一致,会重置请求
__u16 src_port = bpf_ntohs(tcp.source); //源端口
if (src_port == 80 && ip.saddr == watch_ip) {
set_tcp_src_port(skb, bpf_htons(8080)); //修改源端口 B -> A 80 -> 8080
tcph_dr(skb, &tcp);
}
struct tc_data_ip *ipdata;
ipdata=bpf_ringbuf_reserve(&tc_ip_map, sizeof(*ipdata), 0); //在ringbuf中预留缓冲区大小
if(!ipdata){
return 0;
}
ipdata->sip = bpf_ntohl(ip.saddr); //网络字节序转换为主机字节序 否则转换成xxx.xxx.xxx.xxx后会颠倒
ipdata->dip = bpf_ntohl(ip.daddr);
ipdata->sport = bpf_ntohs(tcp.source);
ipdata->dport = bpf_ntohs(tcp.dest);
bpf_ringbuf_submit(ipdata, 0); //提交数据
return 0; //代表放行,是action的一种,混合了action和classifer,分类器类型需要指定成direct-action
}
源码+chatgpt,你懂的
4.mydockertc_x86_bpfel.go
// Code generated by bpf2go; DO NOT EDIT.
//go:build 386 || amd64
package docker
import (
"bytes"
_ "embed"
"fmt"
"io"
"github.com/cilium/ebpf"
)
// loadMydockertc returns the embedded CollectionSpec for mydockertc.
func loadMydockertc() (*ebpf.CollectionSpec, error) {
reader := bytes.NewReader(_MydockertcBytes)
spec, err := ebpf.LoadCollectionSpecFromReader(reader)
if err != nil {
return nil, fmt.Errorf("can't load mydockertc: %w", err)
}
return spec, err
}
// loadMydockertcObjects loads mydockertc and converts it into a struct.
//
// The following types are suitable as obj argument:
//
// *mydockertcObjects
// *mydockertcPrograms
// *mydockertcMaps
//
// See ebpf.CollectionSpec.LoadAndAssign documentation for details.
func loadMydockertcObjects(obj interface{}, opts *ebpf.CollectionOptions) error {
spec, err := loadMydockertc()
if err != nil {
return err
}
return spec.LoadAndAssign(obj, opts)
}
// mydockertcSpecs contains maps and programs before they are loaded into the kernel.
//
// It can be passed ebpf.CollectionSpec.Assign.
type mydockertcSpecs struct {
mydockertcProgramSpecs
mydockertcMapSpecs
}
// mydockertcSpecs contains programs before they are loaded into the kernel.
//
// It can be passed ebpf.CollectionSpec.Assign.
type mydockertcProgramSpecs struct {
Mytc *ebpf.ProgramSpec `ebpf:"mytc"`
}
// mydockertcMapSpecs contains maps before they are loaded into the kernel.
//
// It can be passed ebpf.CollectionSpec.Assign.
type mydockertcMapSpecs struct {
TcIpMap *ebpf.MapSpec `ebpf:"tc_ip_map"`
}
// mydockertcObjects contains all objects after they have been loaded into the kernel.
//
// It can be passed to loadMydockertcObjects or ebpf.CollectionSpec.LoadAndAssign.
type mydockertcObjects struct {
mydockertcPrograms
mydockertcMaps
}
func (o *mydockertcObjects) Close() error {
return _MydockertcClose(
&o.mydockertcPrograms,
&o.mydockertcMaps,
)
}
// mydockertcMaps contains all maps after they have been loaded into the kernel.
//
// It can be passed to loadMydockertcObjects or ebpf.CollectionSpec.LoadAndAssign.
type mydockertcMaps struct {
TcIpMap *ebpf.Map `ebpf:"tc_ip_map"`
}
func (m *mydockertcMaps) Close() error {
return _MydockertcClose(
m.TcIpMap,
)
}
// mydockertcPrograms contains all programs after they have been loaded into the kernel.
//
// It can be passed to loadMydockertcObjects or ebpf.CollectionSpec.LoadAndAssign.
type mydockertcPrograms struct {
Mytc *ebpf.Program `ebpf:"mytc"`
}
func (p *mydockertcPrograms) Close() error {
return _MydockertcClose(
p.Mytc,
)
}
func _MydockertcClose(closers ...io.Closer) error {
for _, closer := range closers {
if err := closer.Close(); err != nil {
return err
}
}
return nil
}
// Do not access this directly.
//
//go:embed mydockertc_x86_bpfel.o
var _MydockertcBytes []byte
编译出来的文件,代码都是自动生成的
5.tc_loader.go
package docker
import (
"errors"
"fmt"
"github.com/cilium/ebpf/ringbuf"
"github.com/vishvananda/netlink"
"goebpf/pkg/helpers/nethelper"
"golang.org/x/sys/unix"
"log"
"os"
"os/signal"
"syscall"
"unsafe"
)
type TcDataIp struct { //对应mydockertc.bpf.c中的struct
Sip uint32
Dip uint32
Sport uint32
Dport uint32
}
// 在目标网卡添加clsact队列,使其成为eBPF监听的对象,来源——cillium源码
func attachIface(linkIndex int, fd int, name string) (deferFuncs []func()) {
//2.1初始化队列
attrs := netlink.QdiscAttrs{
LinkIndex: linkIndex,
// 0xffff 表示 “根”或“无父”句柄的队列规则
Handle: netlink.MakeHandle(0xffff, 0),
Parent: netlink.HANDLE_CLSACT, //eBPF专用 clsact
}
qdisc := &netlink.GenericQdisc{
QdiscAttrs: attrs,
QdiscType: "clsact",
}
//2.2添加队列 —— 好比执行了 tc qdisc add dev docker0 clsact
if err := netlink.QdiscAdd(qdisc); err != nil {
log.Fatalln("QdiscAdd err: ", err)
}
deferFuncs = append(deferFuncs, func() { //监测完删除,否则下次无法创建
if err := netlink.QdiscDel(qdisc); err != nil {
fmt.Println("QdiscDel err: ", err.Error())
}
})
//3.1初始化 eBPF分类器
filterattrs := netlink.FilterAttrs{
LinkIndex: linkIndex,
Parent: netlink.HANDLE_MIN_INGRESS | netlink.HANDLE_MIN_EGRESS,
Handle: netlink.MakeHandle(0, 1),
Protocol: unix.ETH_P_ALL, //所有协议
Priority: 1,
}
filter := &netlink.BpfFilter{
FilterAttrs: filterattrs,
Fd: fd,
Name: name,
DirectAction: true,
}
//3.2添加分类器 —— 好比执行了 tc filter add dev docker0 ingress bpf direct-action obj dockertcxdp_bpfel_x86.o
if err := netlink.FilterAdd(filter); err != nil {
log.Fatalln("FilterAdd err: ", err)
}
deferFuncs = append(deferFuncs, func() {
err := netlink.FilterDel(filter)
if err != nil {
fmt.Println("FilterDel err : ", err.Error())
}
})
return
}
// 加载tc ebpf 程序
func LoaderTC() {
veth := nethelper.GetVeths()
//1 这步和其他的eBPF程序一样,加载转化过来的eBPF程序
objs := &mydockertcObjects{}
err := loadMydockertcObjects(objs, nil)
if err != nil {
log.Fatalln("loadDockertcxdpObjects err: ", err)
}
//2-3 给所有veth网卡添加clsact队列
for _, v := range veth {
deferFuncs := attachIface(v.Index, objs.Mytc.FD(), "mytc")
for _, f := range deferFuncs {
defer f()
}
}
//4开个信号阻塞住并循环读取
fmt.Println("开始TC监听")
go func() {
rd, err := ringbuf.NewReader(objs.TcIpMap)
if err != nil {
log.Fatalf("creating event reader: %s", err)
}
defer rd.Close()
for { //循环读取内核map
record, err := rd.Read()
if err != nil {
if errors.Is(err, ringbuf.ErrClosed) {
log.Println("Received signal, exiting..")
return
}
log.Printf("reading from reader: %s", err)
continue
}
//对内核态传来的数据进行解析
if len(record.RawSample) > 0 {
data := (*TcDataIp)(unsafe.Pointer(&record.RawSample[0])) //经过两次强制转换
//转换成网络字节序
saddr := nethelper.ResolveIP(data.Sip, true)
daddr := nethelper.ResolveIP(data.Dip, true)
fmt.Printf("监测到来源地址: %s:%d------->目标地址: %s:%d\n",
saddr.To4().String(), data.Sport,
daddr.To4().String(), data.Dport,
)
}
}
}() //循环读取内核态传来的数据
//开信号 好处是能执行defer
ch := make(chan os.Signal)
signal.Notify(ch, syscall.SIGINT, syscall.SIGTERM, syscall.SIGKILL, syscall.SIGQUIT, syscall.SIGHUP)
<-ch
fmt.Println("TC监听结束")
}
参考cilium源码
效果展示
拓展提升
其实,我们拿到了整一个数据包,可以进一步获得报文中的Payload,将其发送到用户态。用户态进行逐字节解析,仅需要知道http协议,mysql报文, redis报文的规定格式。即可判断,并通过一系列操作保存,并作审计用。
















 614
614











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











