







笔者最近学习算法,学了很久也只弄懂了几个排序算法,在这里晒一下下,作为以后参考之用。
一、为什么要研究排序问题
许多计算机科学家认为,排序算法是算法学习中最基本的问题,原因有以下几点:
l 有时候应用程序本身需要对信息进行排序,如为了准备客户账目,银行需要对支票账号进行排序
l 很多算法将排序作为关键子程序
l 现在已经有很多排序算法,它们采用各种技术
l 排序时一个可以证明其非平凡下界的问题,并可以利用排序问题的下界证明其他问题的下界
l 在实现排序算法是很多工程问题即浮出水面
二、排序问题的形式化定义
输入:由n个数组成的一个序列<a1,a2,……,an>
输出:对输入序列的一个排列(重排)<a1’,a2’,……,an’>,使得a1’ ≤a2’ ≤……≤an’
【说明】在实际中,待排序的数很少是孤立的值,它们通常是成为激励的数据集的一个部分,每个记录有一个关键字key,是待排序的值,其他数据位卫星数据,它们通常以key为中心传递。
三、相关概念
1. 排序的稳定性:在待排序的文件中,若存在多个关键字相同的记录,经过排序后这些具有相同关键字的记录之间的相对次序保持不变,该排序方法是稳定的;若具有相同关键字的记录之间的相对次序发生变化,则称这种排序方法是不稳定的。
A. 稳定排序:插入排序、冒泡排序、鸡尾酒排序、计数排序、合并交换排序、归并排序、基数排序、桶排序、鸽巢排序
B. 不稳定排序:选择排序、堆排序、希尔排序、快速排序
2. 内部、外部排序:在排序过程中,若整个文件都是放在内存中处理,排序时不涉及数据的内、外存交换,则称之为内部排序(简称内排序);反之,若排序过程中要进行数据的内、外存交换,则称之为外部排序。
3. 待排文件的常用存储方式:
A. 顺序表:对记录本身进行物理重排(即通过关键字之间的比较判定,将记录移到合适的位置
B. 链表:无须移动记录,仅需修改指针
C. 用顺序的方式存储待排序的记录,但同时建立一个辅助表:对辅助表的表目进行物理重排(即只移动辅助表的表目,而不移动记录本身)。
4. 影响排序效果的因素
A. 待排序的记录数目n
B. 记录的大小(规模)
C. 关键字的结构及其初始状态
D. 对稳定性的要求
E. 语言工具的条件
F. 存储结构
G. 时间和辅助空间复杂度等
四、排序算法的分类(内部排序)
1. 比较类排序:排序结果中各元素的次序基于输入元素间的比较
A. 比较排序算法的下界
比较排序可以被抽象为决策树。一棵决策树是一棵满二叉树,表示某排序算法作用于给定输入所做的所有比较,而忽略控制结构和数据移动。
在决策树中,对每个节点都注明i,j(1≤i,j≤n),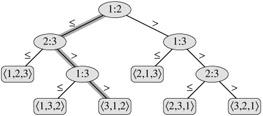 对每个叶节点都注明排列<π(1), π(2),……, π(n)>。排序算法的执行对应于遍历一条从根到叶节点的路径。在每个内节点作比较ai≤aj,其左子树决定ai≤aj之后的比较,其右子树决定ai>aj之后的比较。当到达一个叶节点时排序算法就已经确定了顺序。要使排序算法能正确的工作,其必要条件是n个元素的n!种排列都要作为决策树的一个叶节点出现。在决策树中,从根到任意一个可达叶节点之间最长路径的长度(决策树的高度)表示对应的排序算法中最坏情况下的比较次数。对于一棵高度为h,具有l个可达叶节点的决策树有n! ≤l≤2h,则有h≥lg(n!)=Ω(nlgn)
对每个叶节点都注明排列<π(1), π(2),……, π(n)>。排序算法的执行对应于遍历一条从根到叶节点的路径。在每个内节点作比较ai≤aj,其左子树决定ai≤aj之后的比较,其右子树决定ai>aj之后的比较。当到达一个叶节点时排序算法就已经确定了顺序。要使排序算法能正确的工作,其必要条件是n个元素的n!种排列都要作为决策树的一个叶节点出现。在决策树中,从根到任意一个可达叶节点之间最长路径的长度(决策树的高度)表示对应的排序算法中最坏情况下的比较次数。对于一棵高度为h,具有l个可达叶节点的决策树有n! ≤l≤2h,则有h≥lg(n!)=Ω(nlgn)
B. 常见的比较类排序
a) 选择类排序:选择排序、堆排序
b) 插入类排序:插入排序、二叉插入、两路插入、希尔排序
c) 交换类排序:冒泡排序、鸡尾酒排序、合并交换排序、快速排序
d) 归并排序
2. 非比较类排序:计数排序、基数排序、桶排序、鸽巢排序
五、常用的排序算法
1. 比较类排序
A. 选择类排序
a) 选择排序(Selection Sort)——原地排序、不稳定排序
【思路】首先找出A中最小元素,并将其与A[0]中元素交换;接着找出A中次最小元素,并将其与A[1]中元素交换;对A中头n-1个元素继续这一过程
【代码】
【时间复杂度分析】选择排序的比较操作为n(n − 1) / 2次,交换操作介于0和n(n − 1) / 2次之间,故其时间复杂度为Θ(n2)
b) 堆排序(Heap Sort)
六、代码
【二叉堆】(二叉)堆数据结构是一种数组对象,可以被视为一棵完全二叉树。二叉堆有两种:大顶堆和小顶堆(最大堆和最小堆)。大顶堆中每个节点的值不大于其父节点的值,这样,堆中最大的元素就存放在根节点中。
【思路】首先将输入数组构造成大顶堆;由于数组中最大元素为A[0],将其与A[n]交换使其达到最终正确位置;在堆中除去A[n],并将A[1…n]保持为大顶堆;重复上述过程,直到堆大小降为2。
【代码】由思路知堆排序中应包含构造大顶堆和保持大顶堆子程序。MaxHeapify方法被用来保持大顶堆,其时间复杂度为O(lgn)
BuildMaxHeap方法被用来构造大顶堆,其时间复杂度为O(n)
堆排序代码如下:
【时间复杂度分析】调用BuildMaxHeap时间为O(n),n-1次调用MaxHeapify,每次时间为O(lgn),故堆排序时间复杂度为O(nlgn)















 2195
2195

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









