






准备阶段
在大数据环境搭建之前我们需要以下软件及镜像【可前往我的网盘获取(所有软件无需付费)】:
提取码均为:KITE
VMware Workstation Pro(虚拟机):
vm虚拟机.zip官方版下载丨最新版下载丨绿色版下载丨APP下载-123云盘
Xmanager Power Suite 8(主要使用Xshell):
xshell-8全家桶.zip官方版下载丨最新版下载丨绿色版下载丨APP下载-123云盘
CentOS-7镜像及所需相应模块:
CentOS-7 ISO官方版下载丨最新版下载丨绿色版下载丨APP下载-123云盘
正式开始
第一步

创建虚拟机
一.创建虚拟机并导入镜像
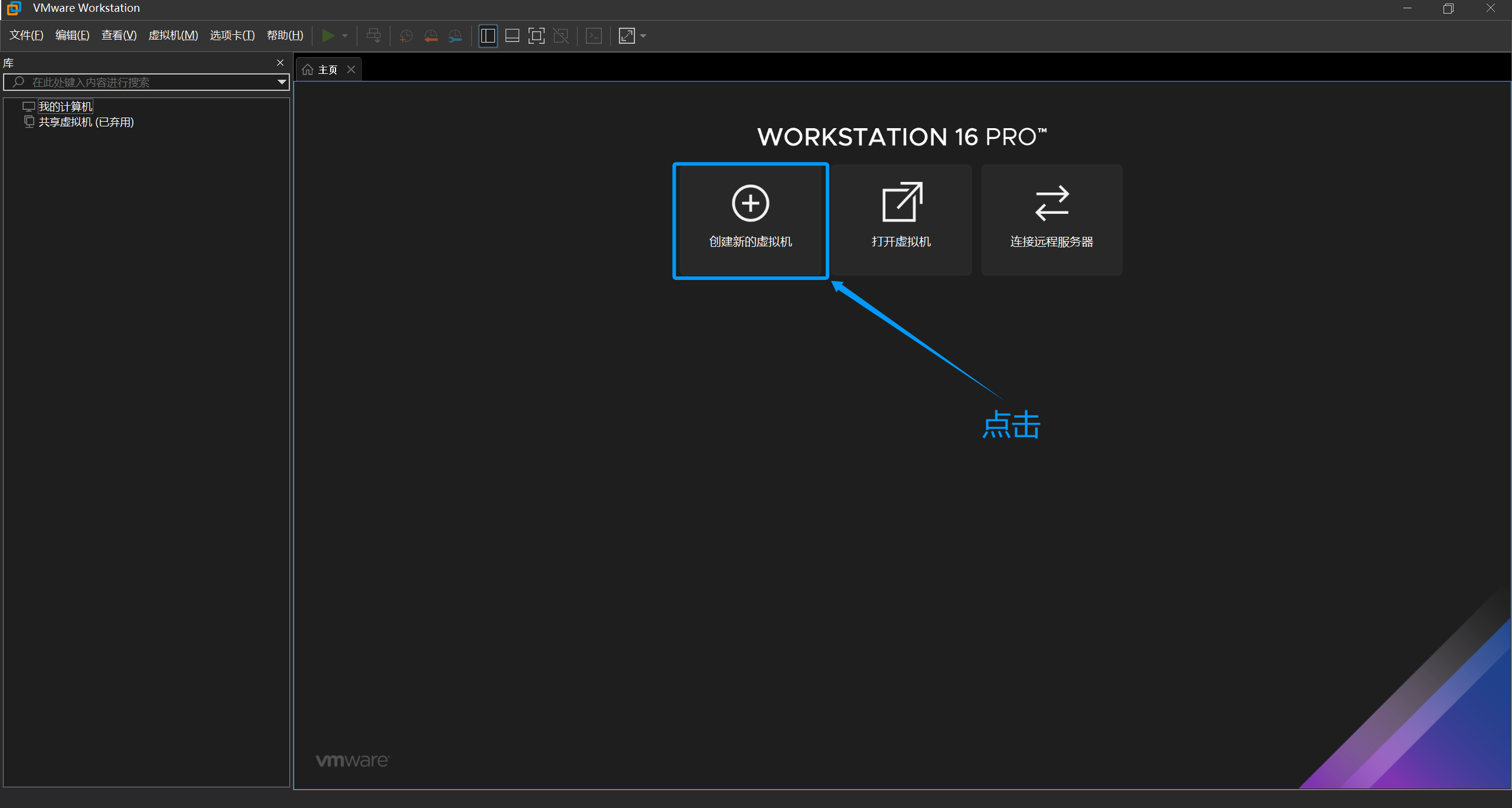
1.点击创建虚拟机
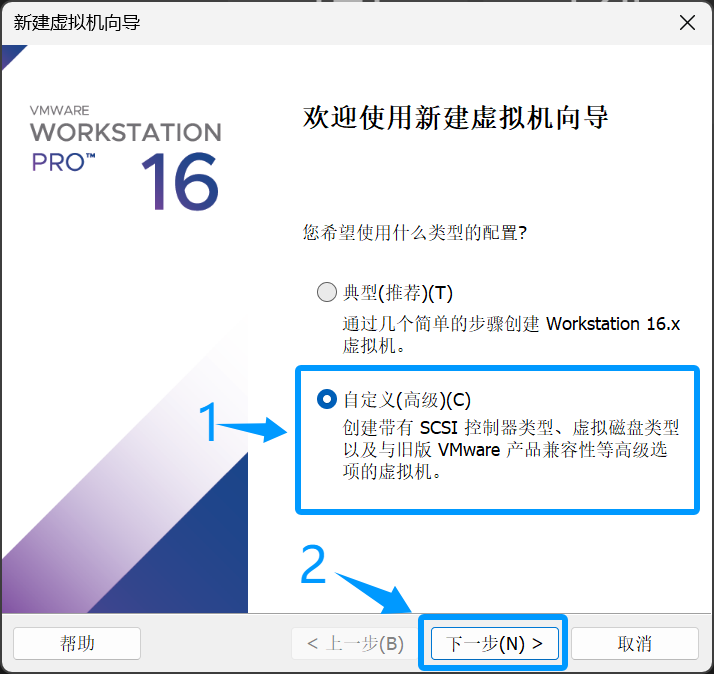
2.选择自定义点击下一步
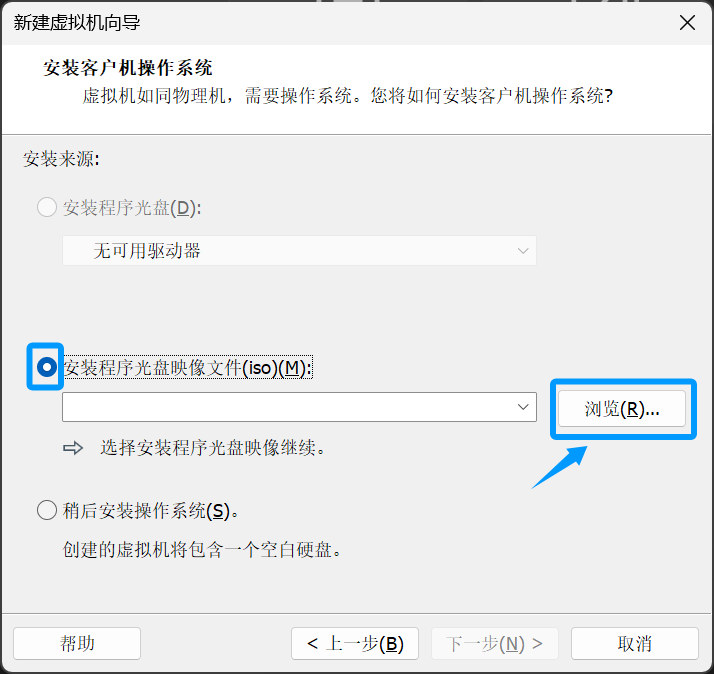
点击浏览后找到并选择镜像文件
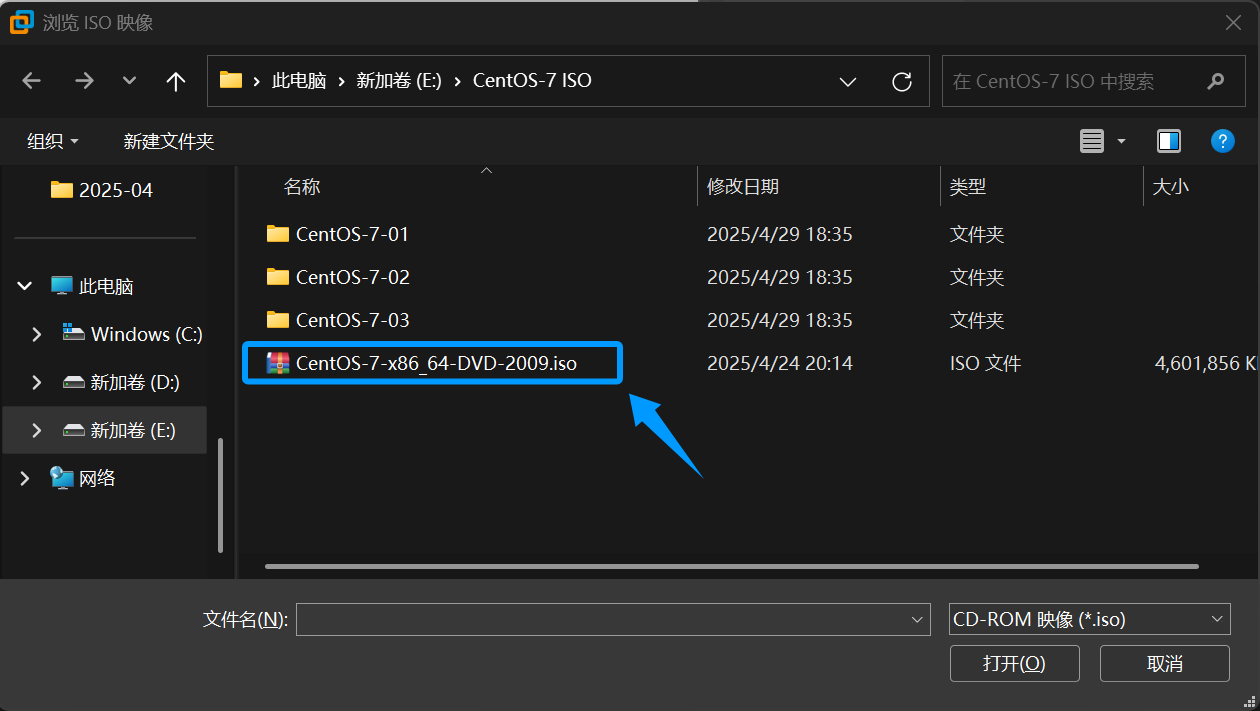
选择后,并出现如图 绿框 提示后点击下一步
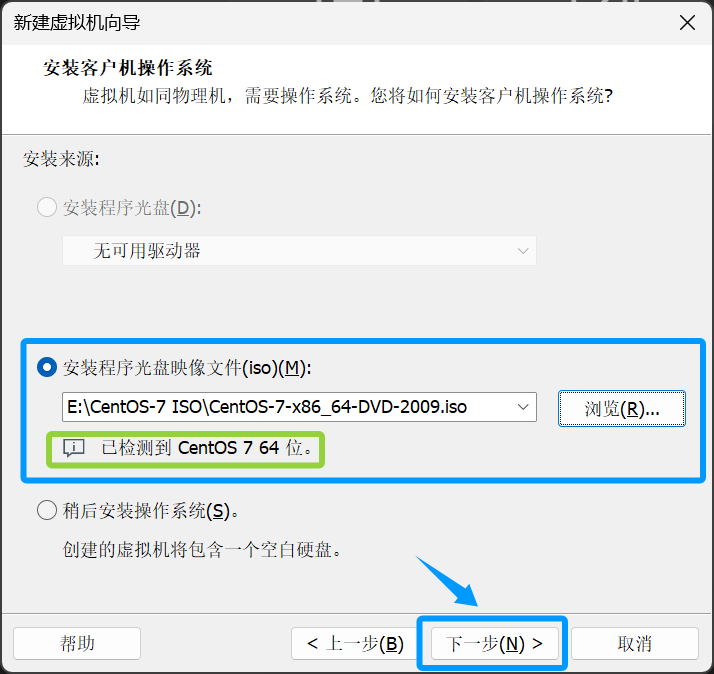
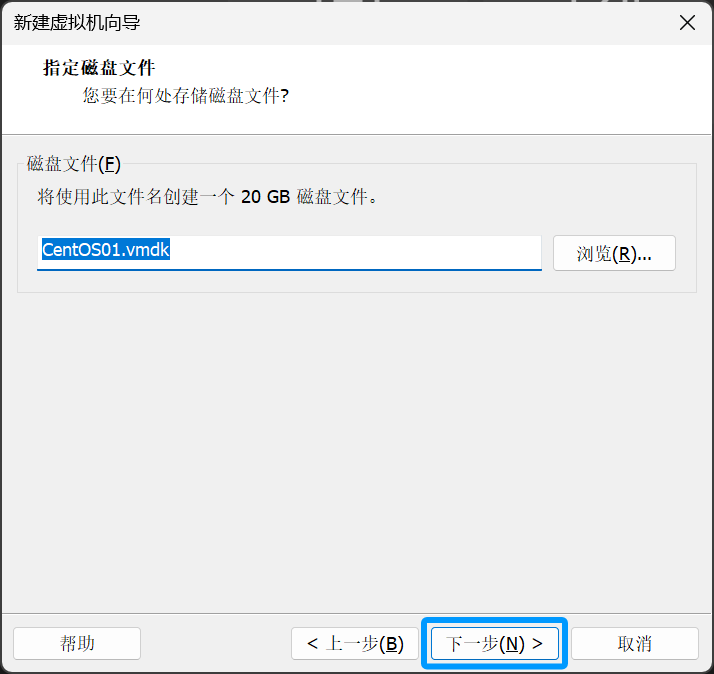
起个名字并点击浏览
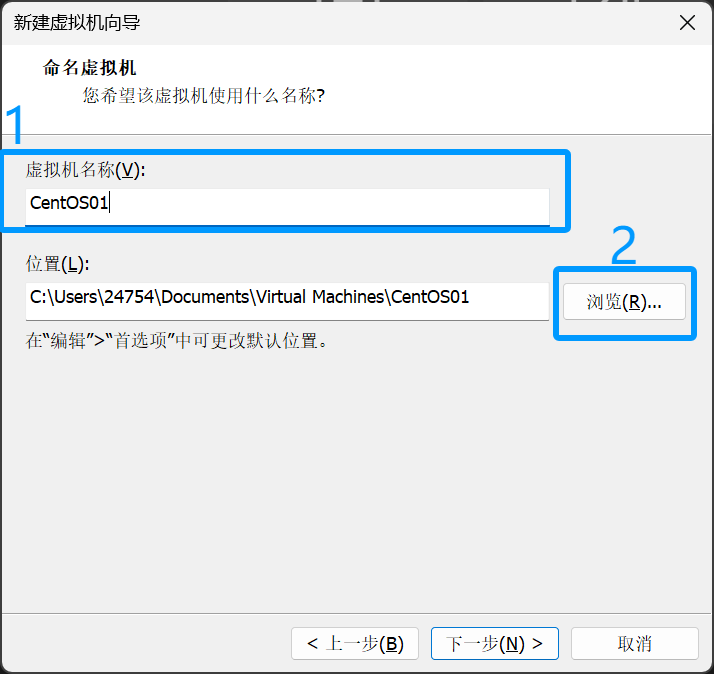
选择好虚拟机文件,所要存放的文件夹位置后点击下一步

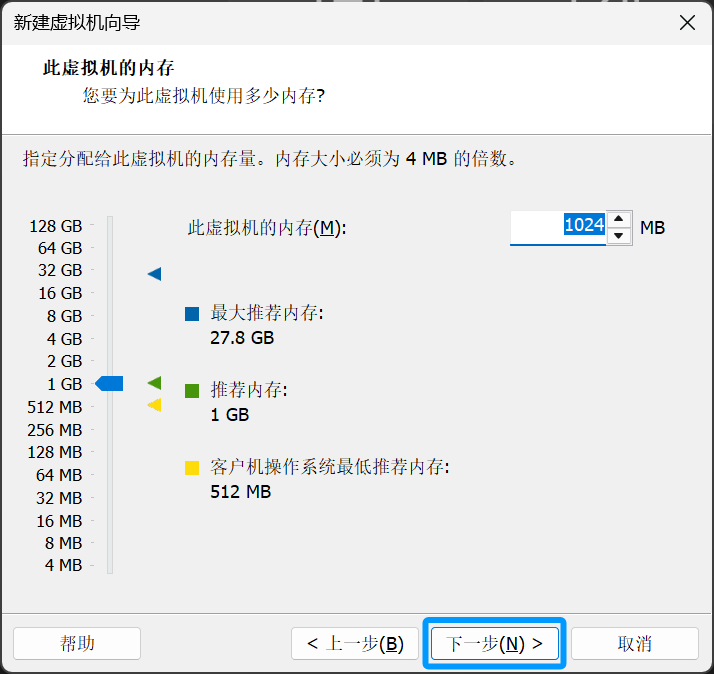
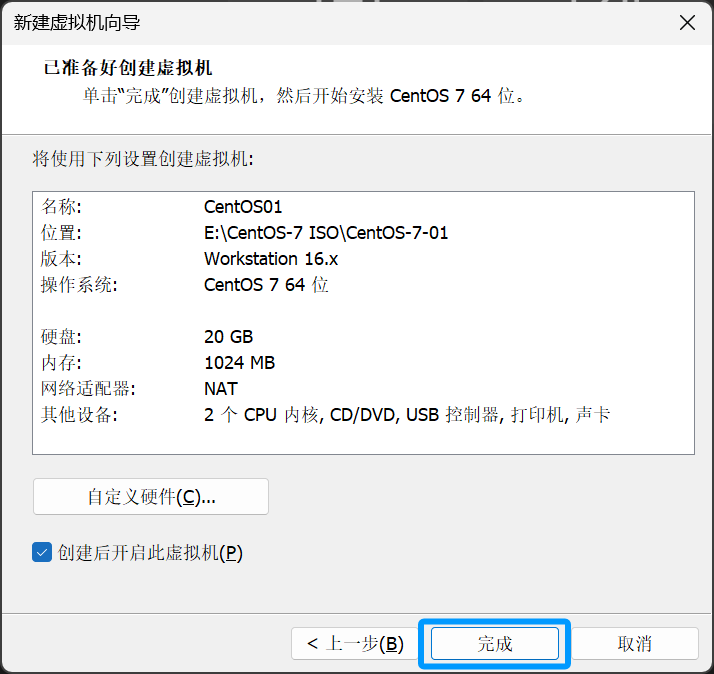
处理器内核总数最少要有 "2"个 调整好后 点击下一步
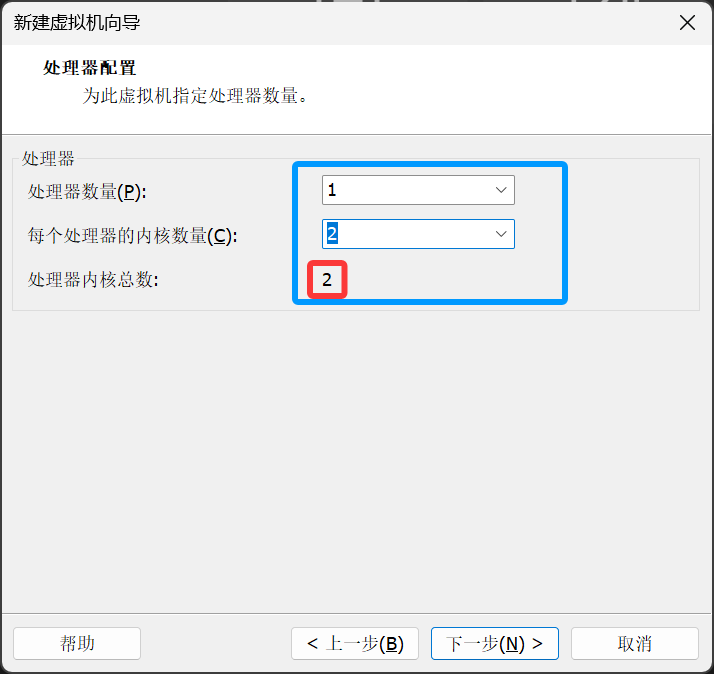
这里直接点击下一步
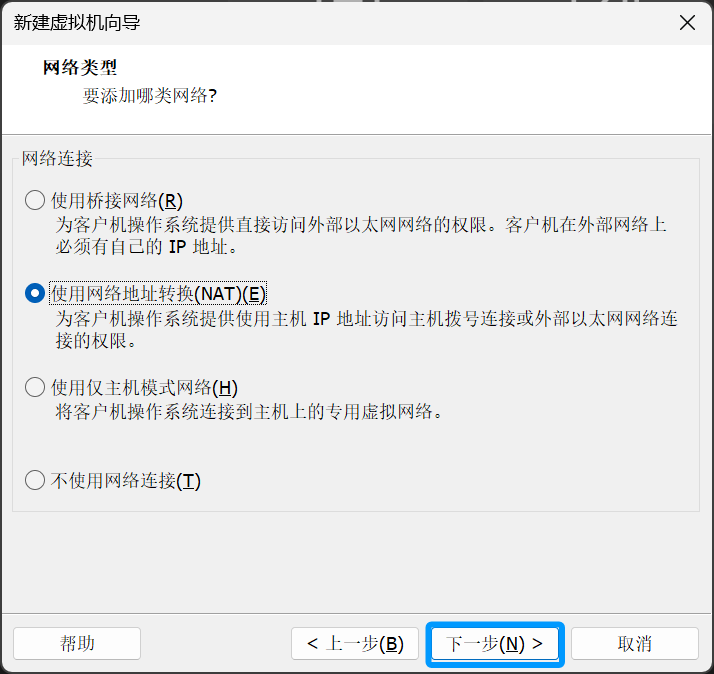
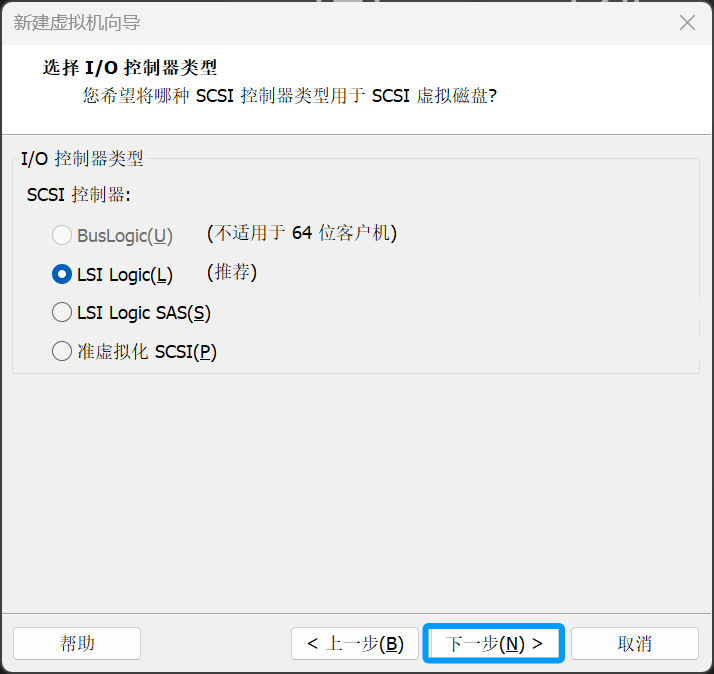
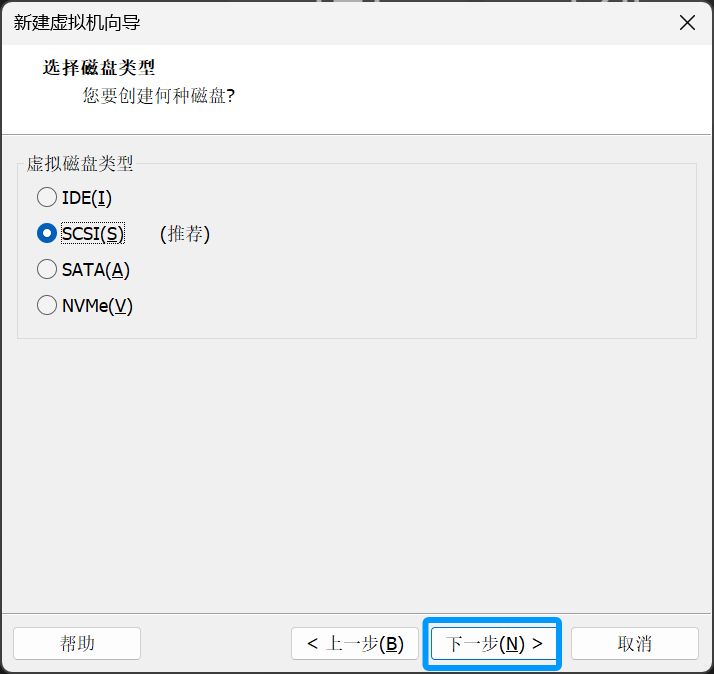
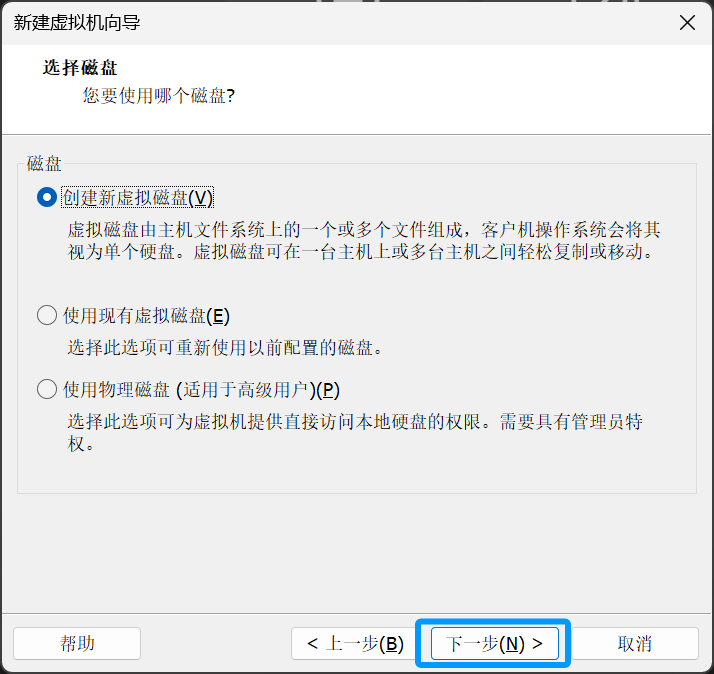
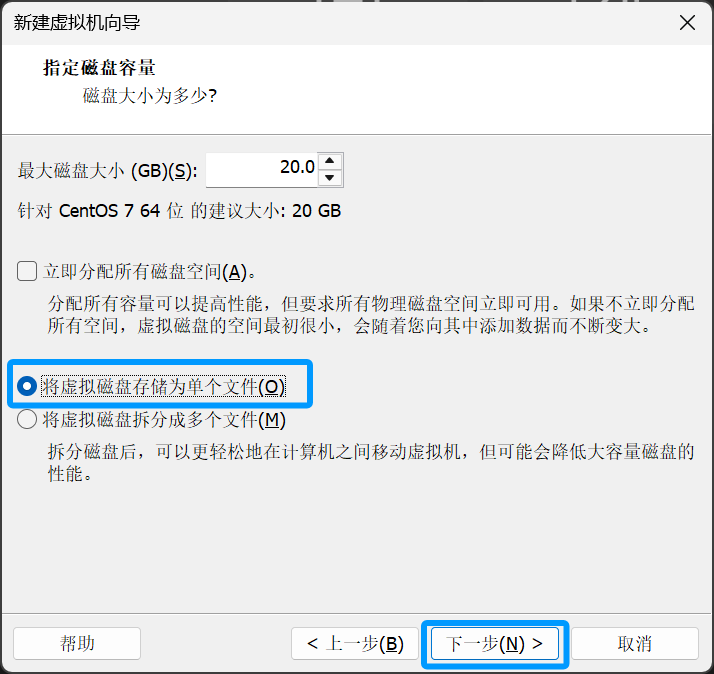
选择第一个
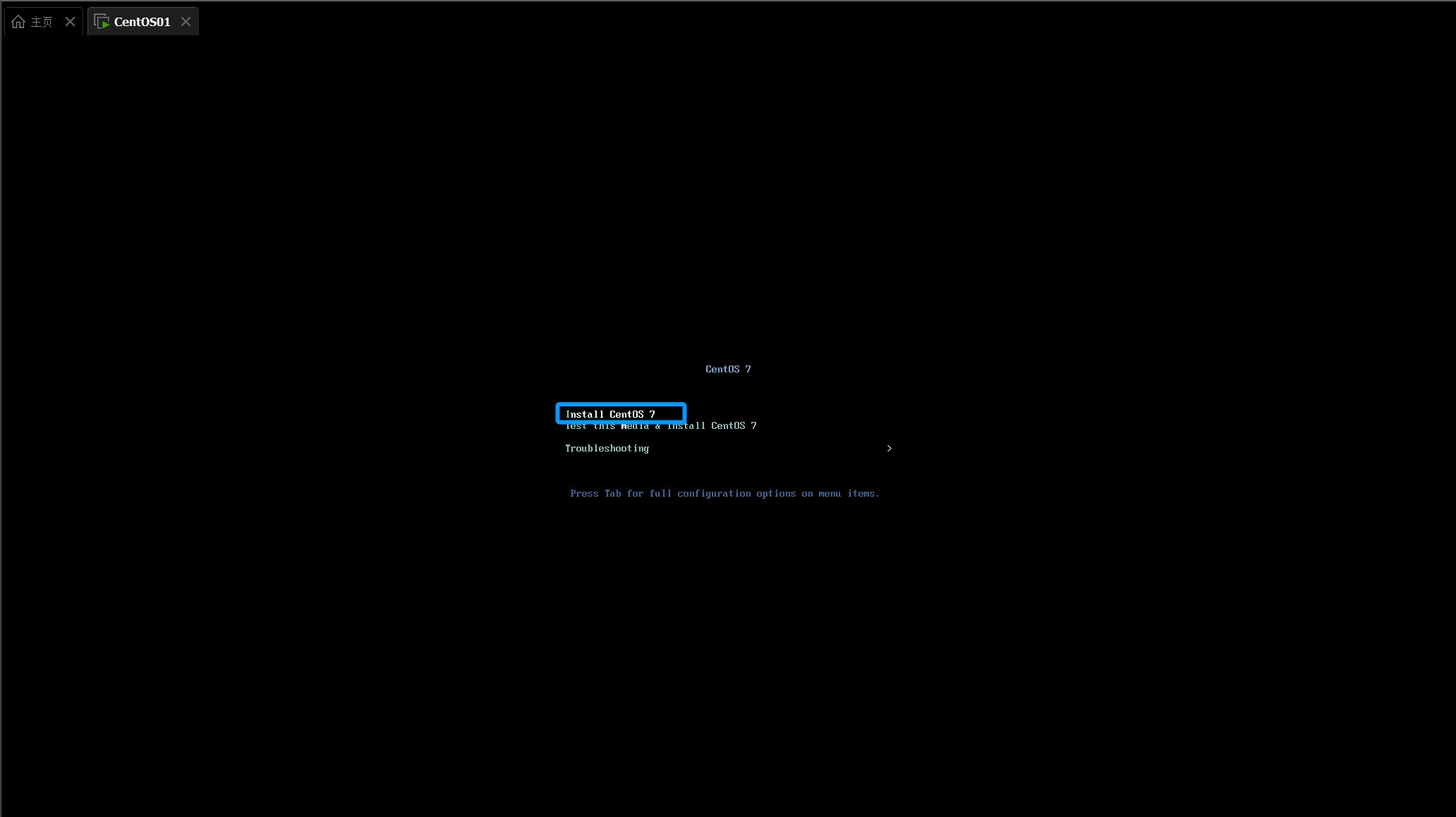
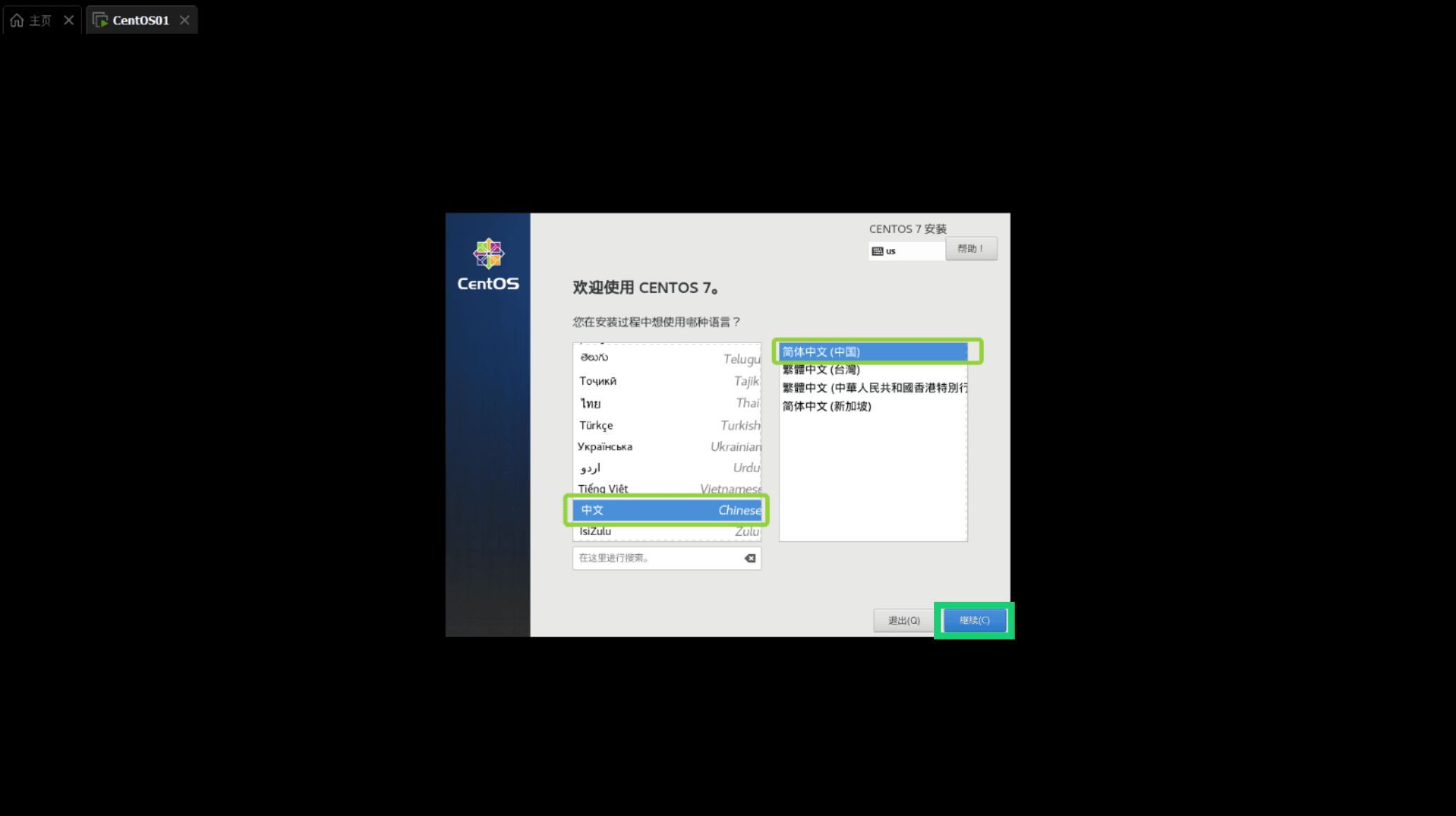
这里看自己选择我英语不好所以选择中文
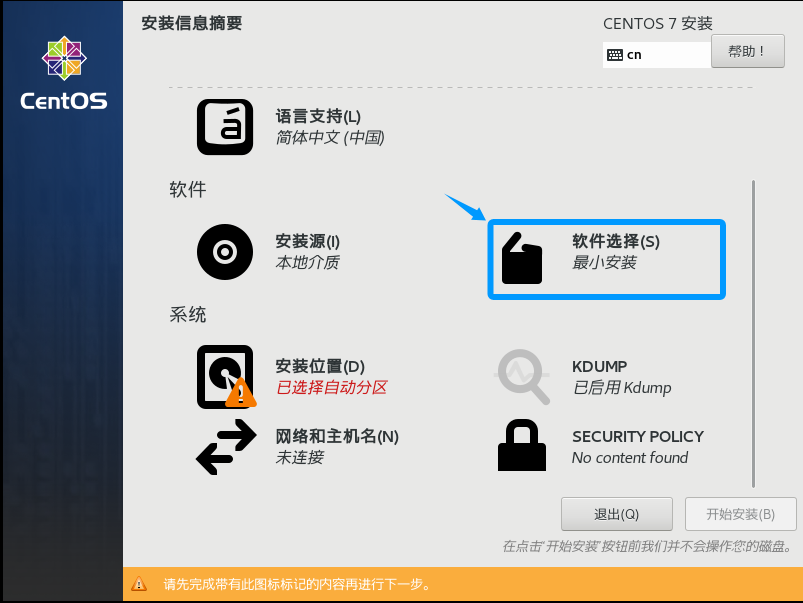
点击软件选择
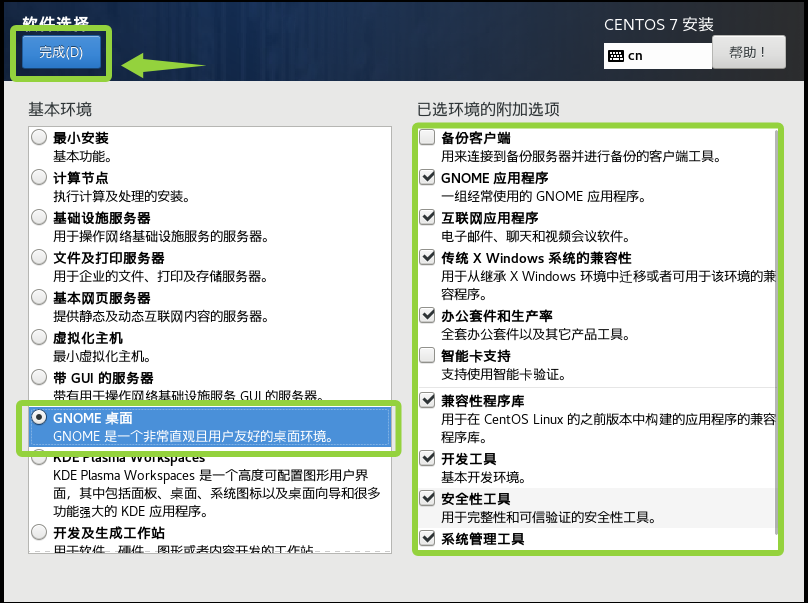
像这样选择后,点击完成
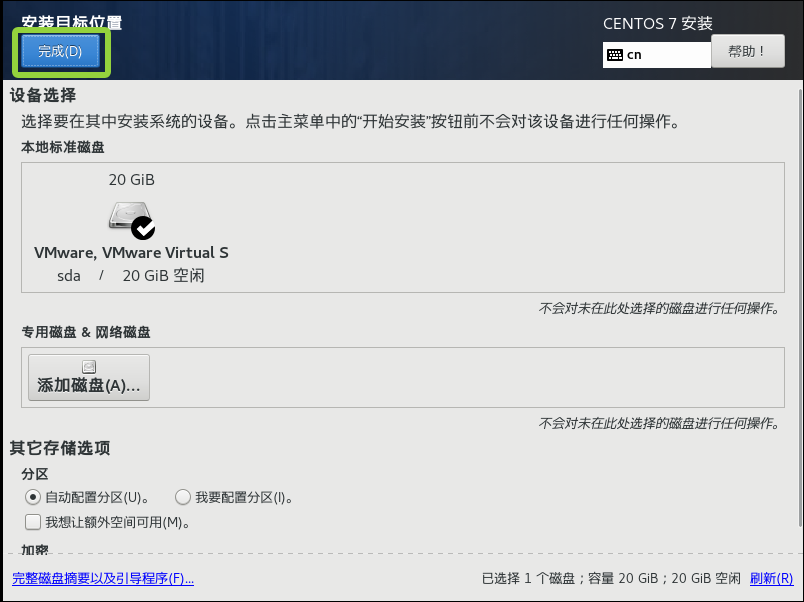
点击安装位置
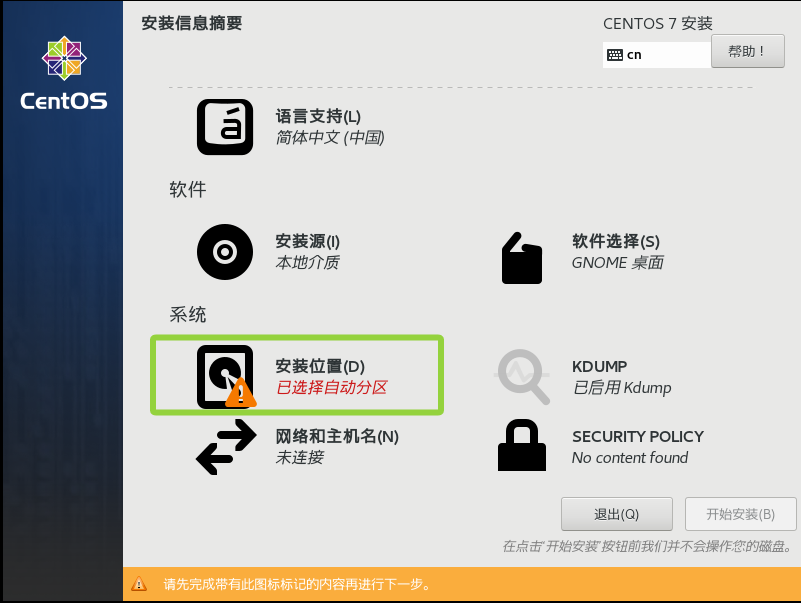
进入后直接点击完成
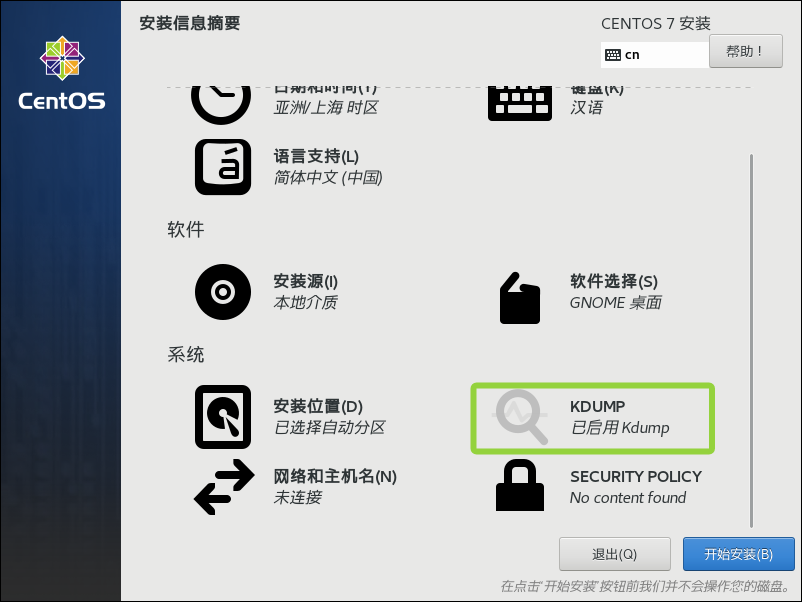
点击KDUMP
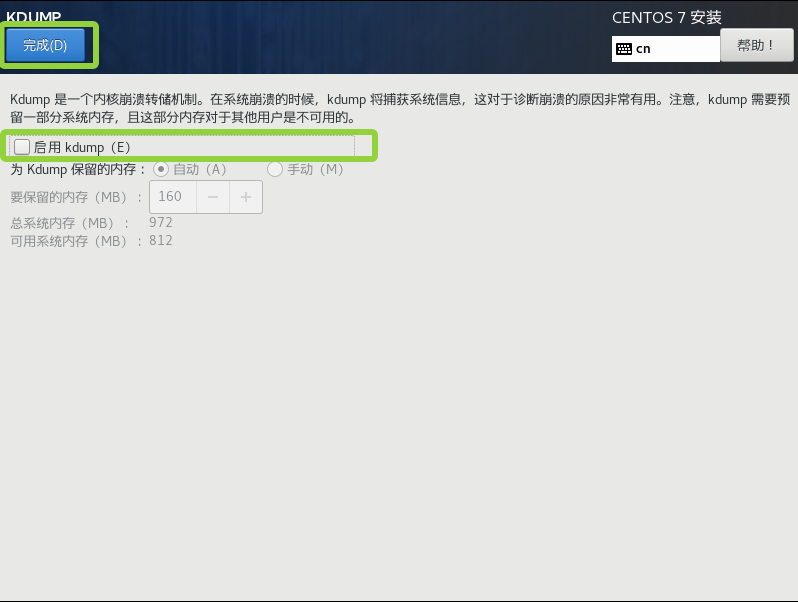
把启用关闭后点击完成
点击网络和主机名
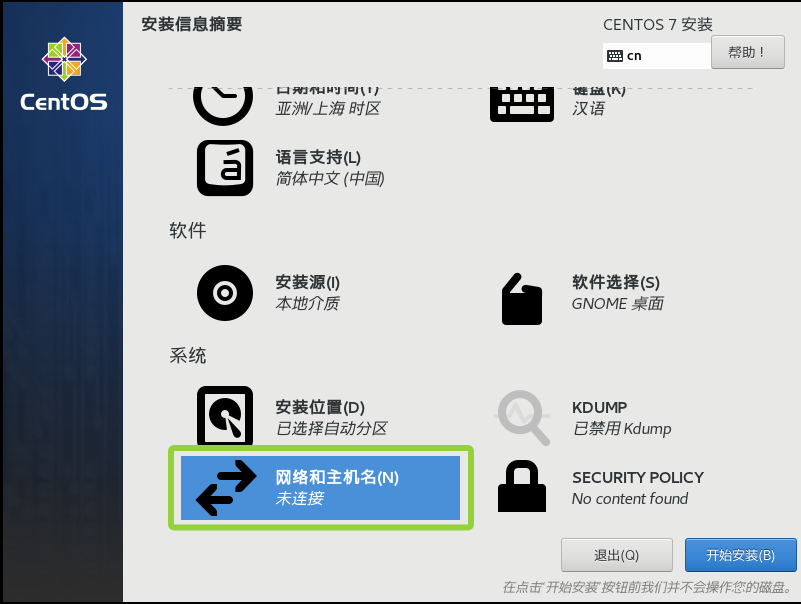
将以太网开启后,点击完成
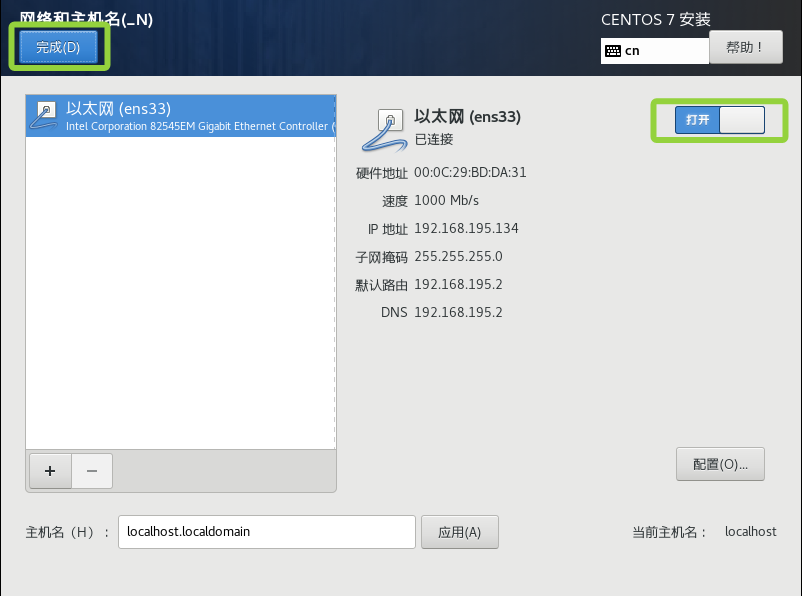
最后点击开始安装
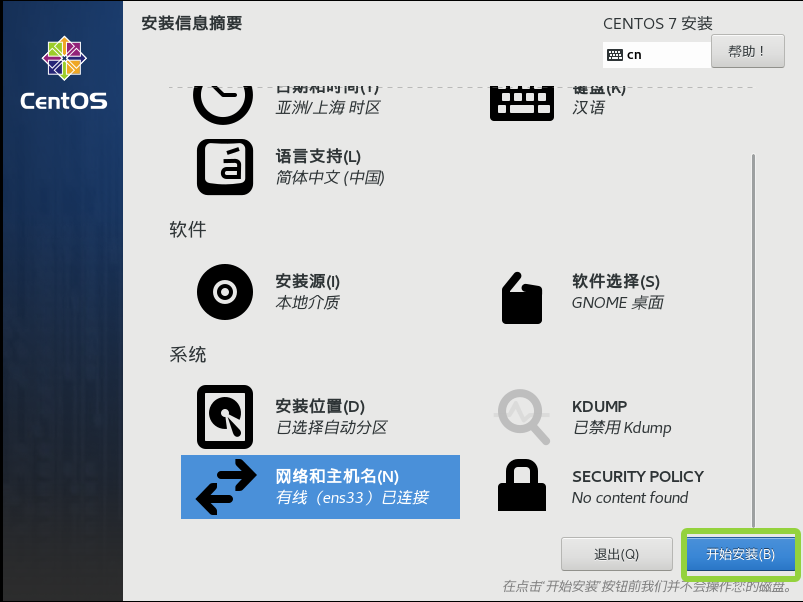
点击ROOT密码
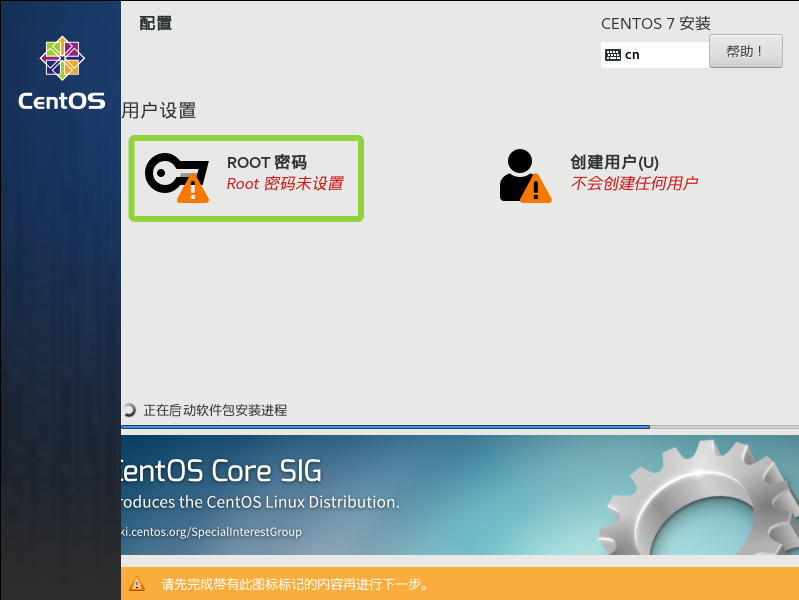
进来以后,自己设置好属于自己的ROOT密码,密码要求使用字母和数字组合
重点:"一定是要自己能记住的,并且后面还会要求创建普通用户密码,普通用户密码最好与ROOT密码一致这样不容易混淆"
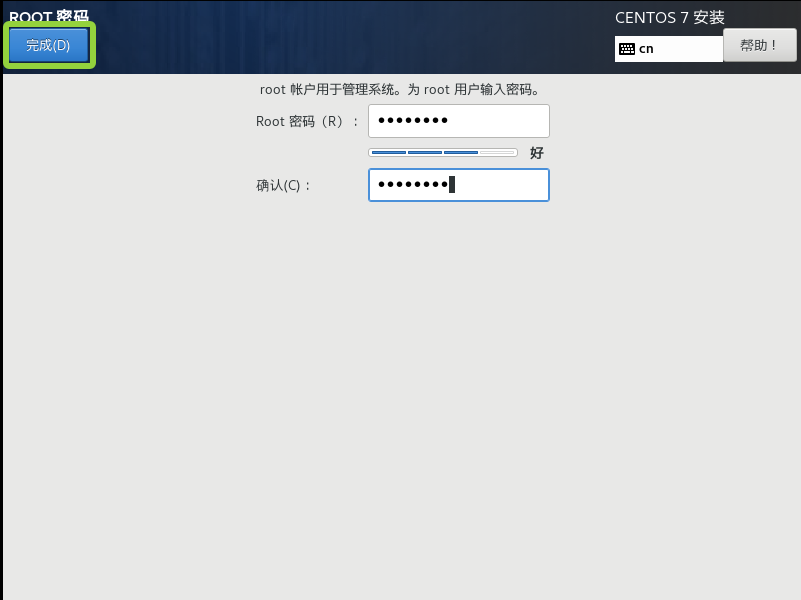
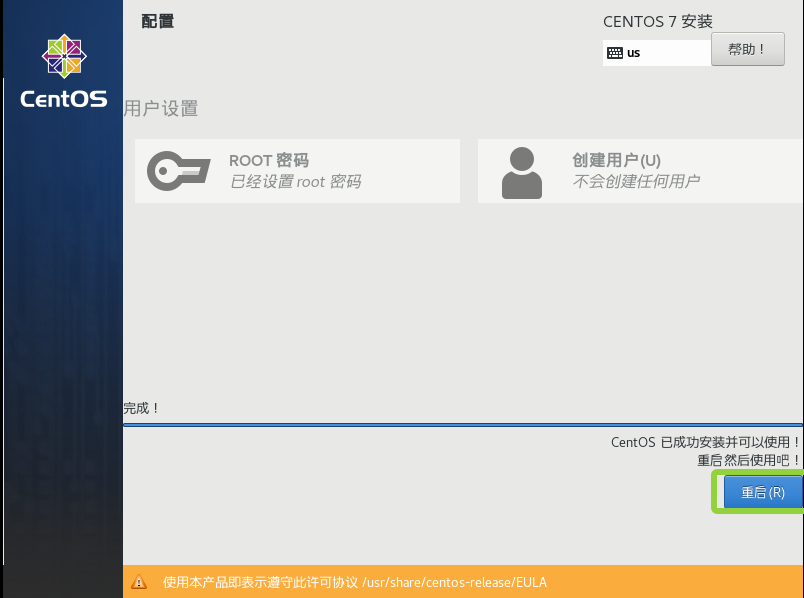
安装完成后点击重启
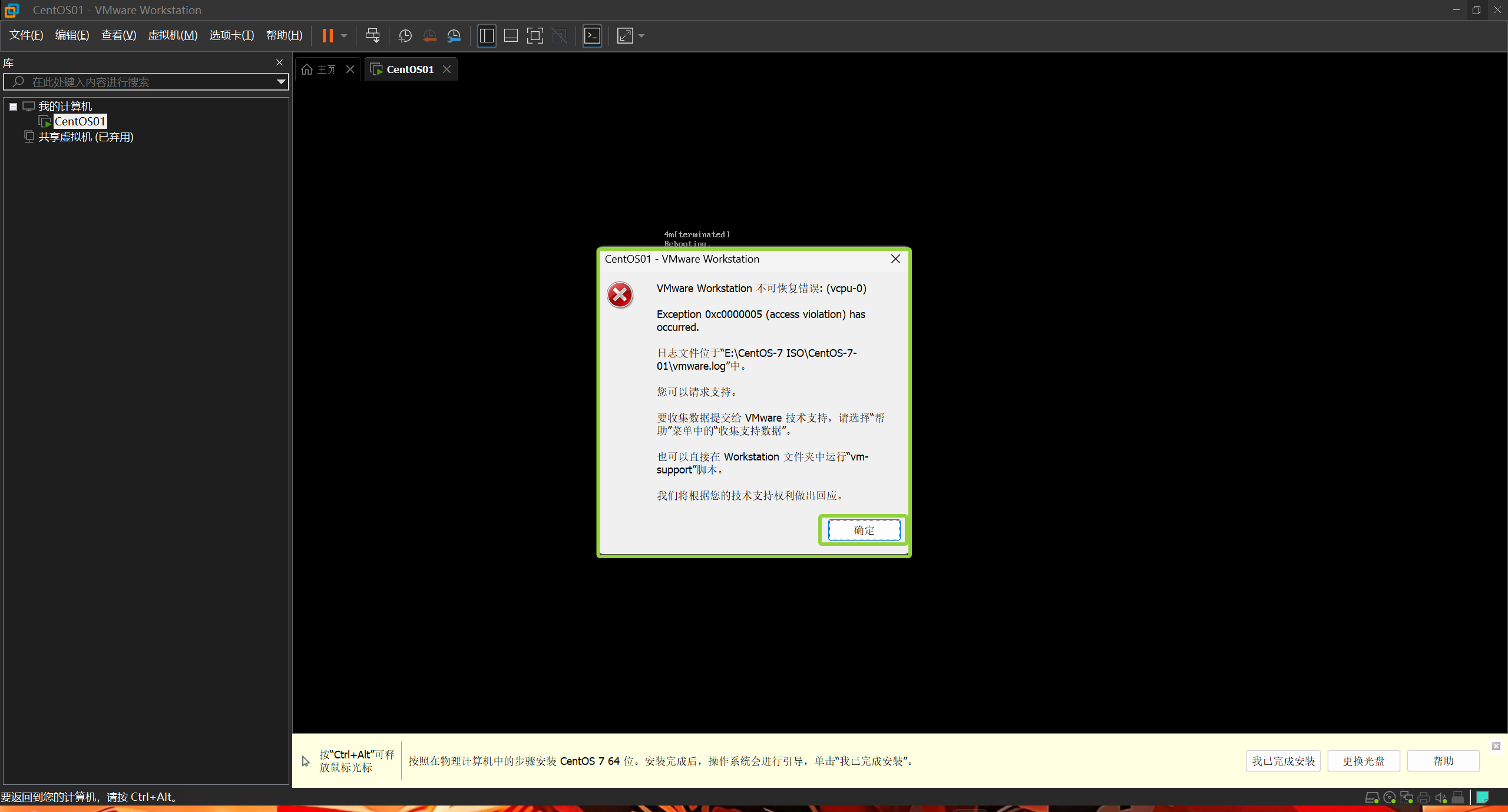
点击重启后出现这样的报错提醒不用担心,直接点击确定即可,然后自己手动启动即可
手动启动
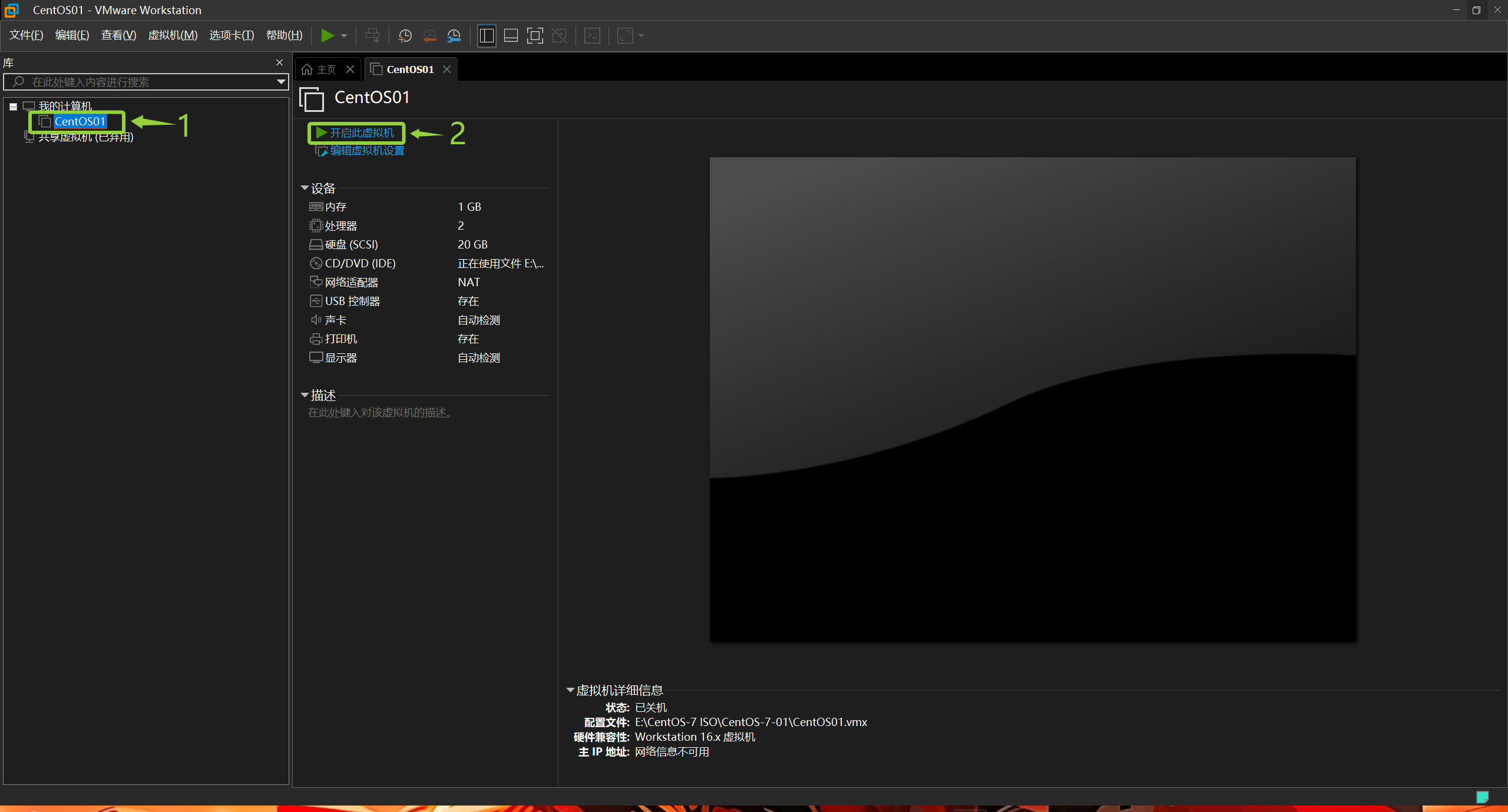
这里我们选择第一个
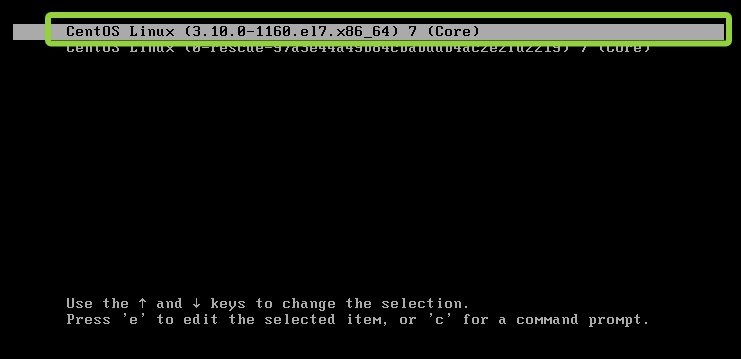
点击"未授权许可"这个地方
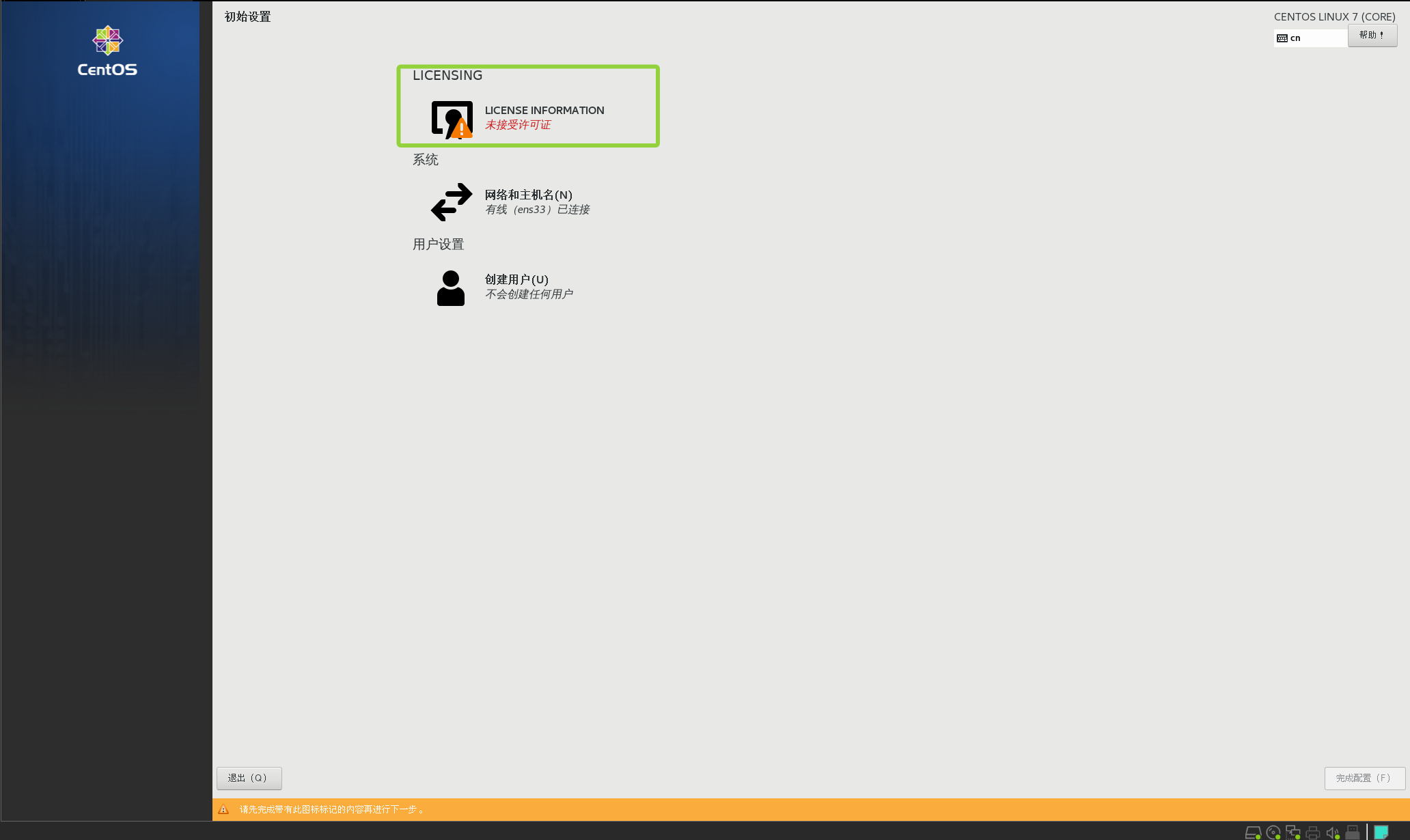
勾选我同意许可协议
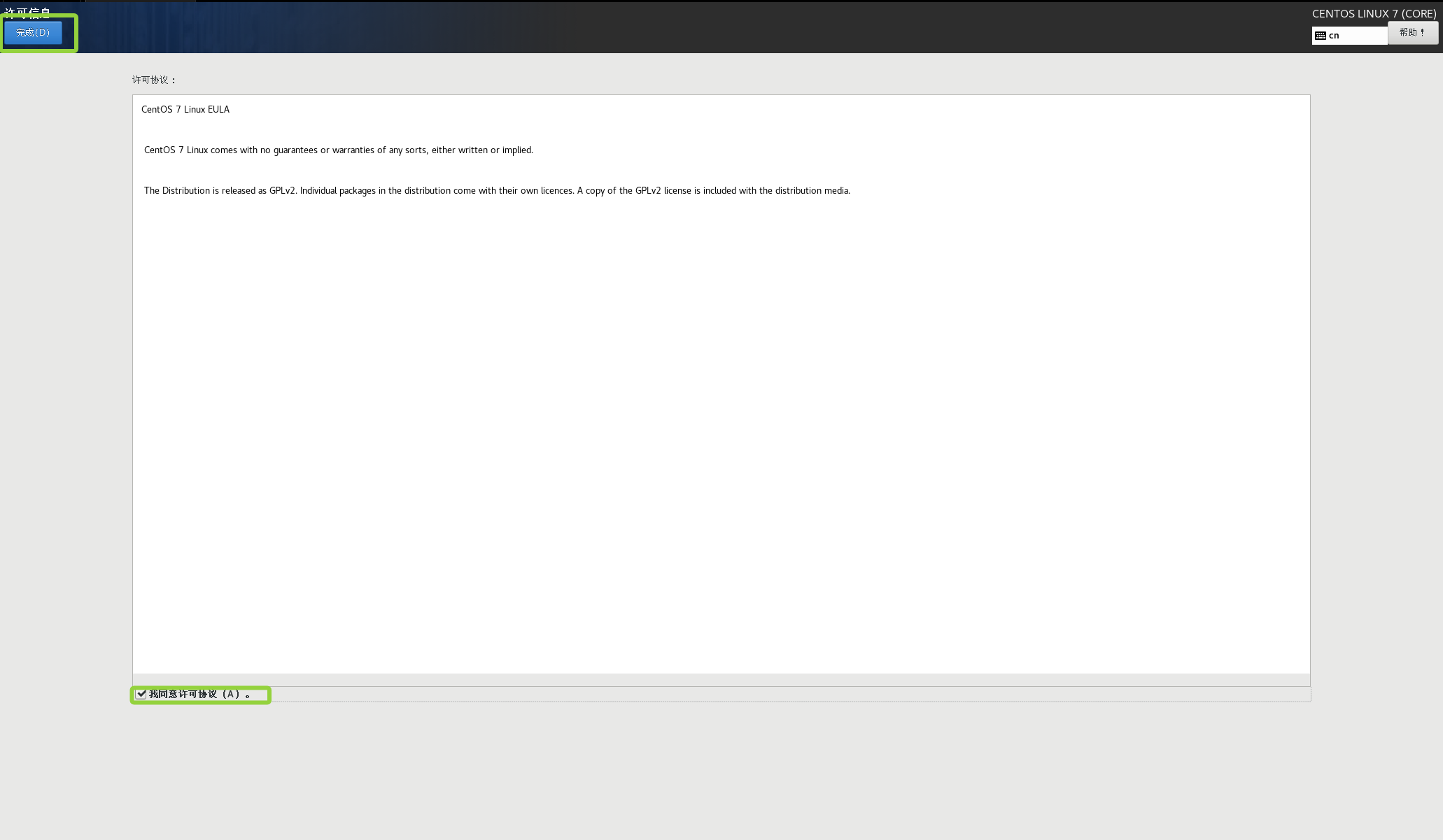
然后点击完成配置
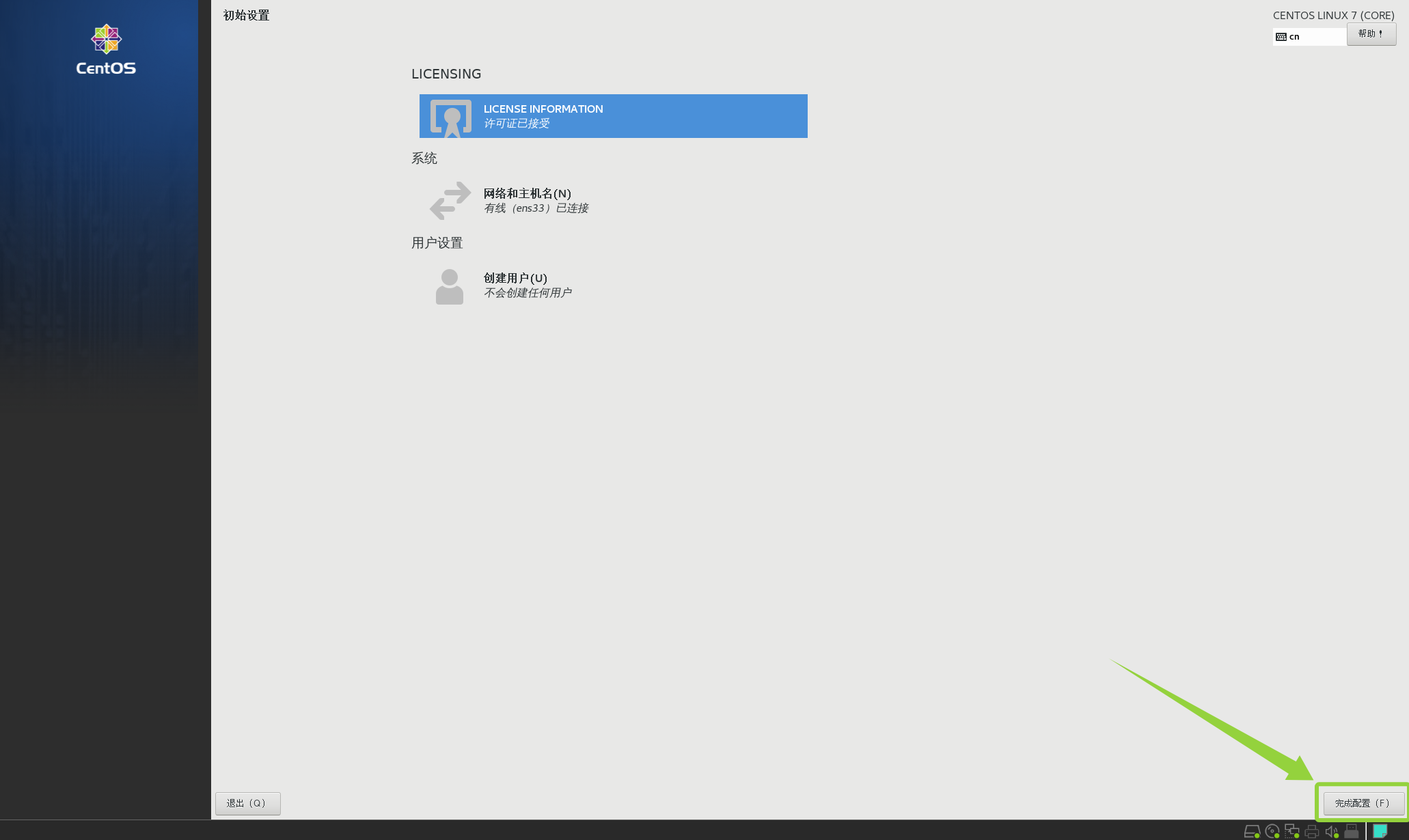
选择汉语后点击前进
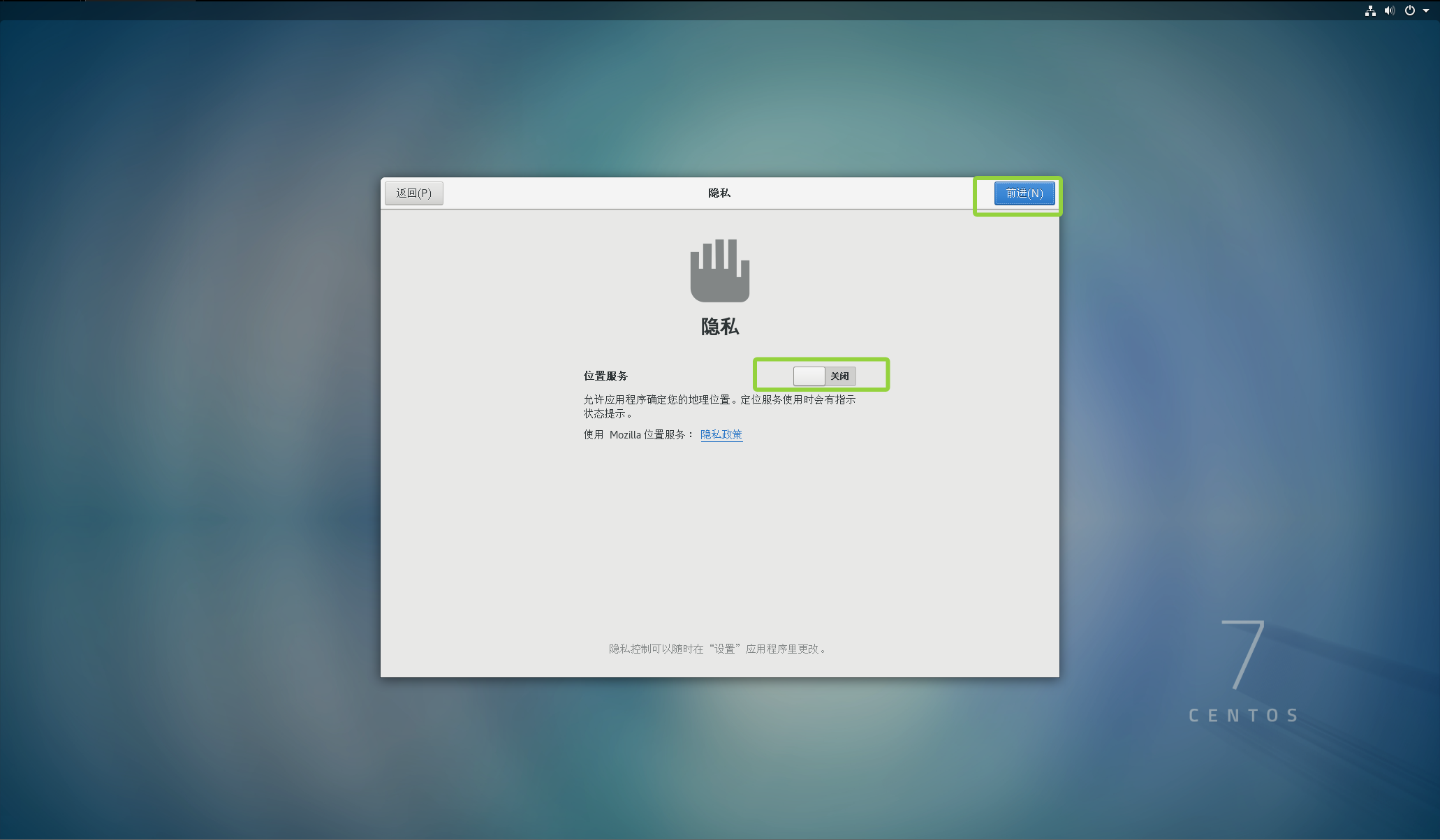
这里关闭位置服务点击前进
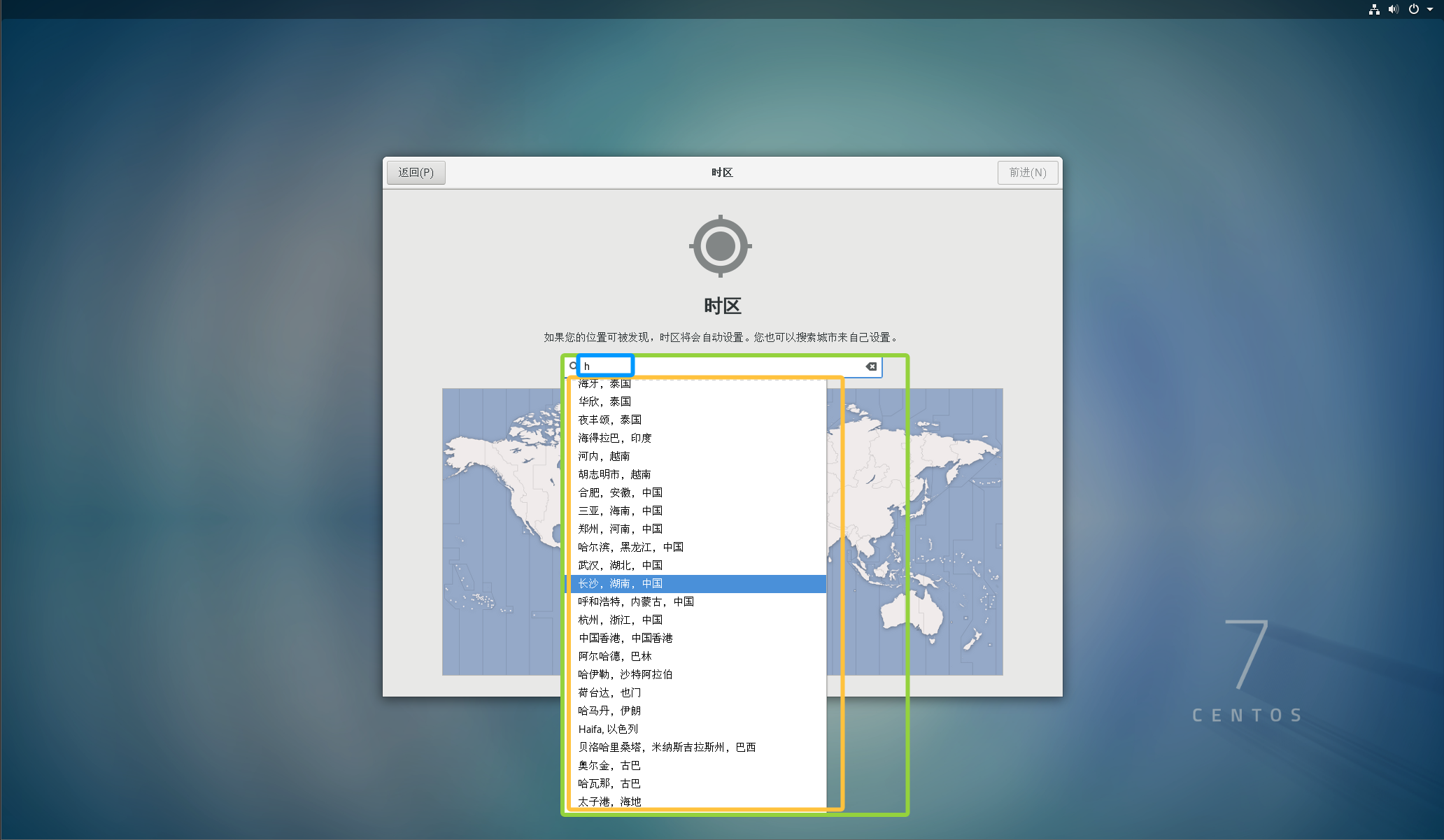
这里输入自己所在省份的首字母,然后去下面寻找并选择
选择好以后点击前进
出现这个在线账号就直接点击跳过
自己起个名字
然后设置密码,可以跟前面设置的ROOT密码一致
完成以上操作后就进入首页系统首页了

二.克隆虚拟机并查询IP地址
1.给这个虚拟机关机
输入关机命令:
shutdown -h now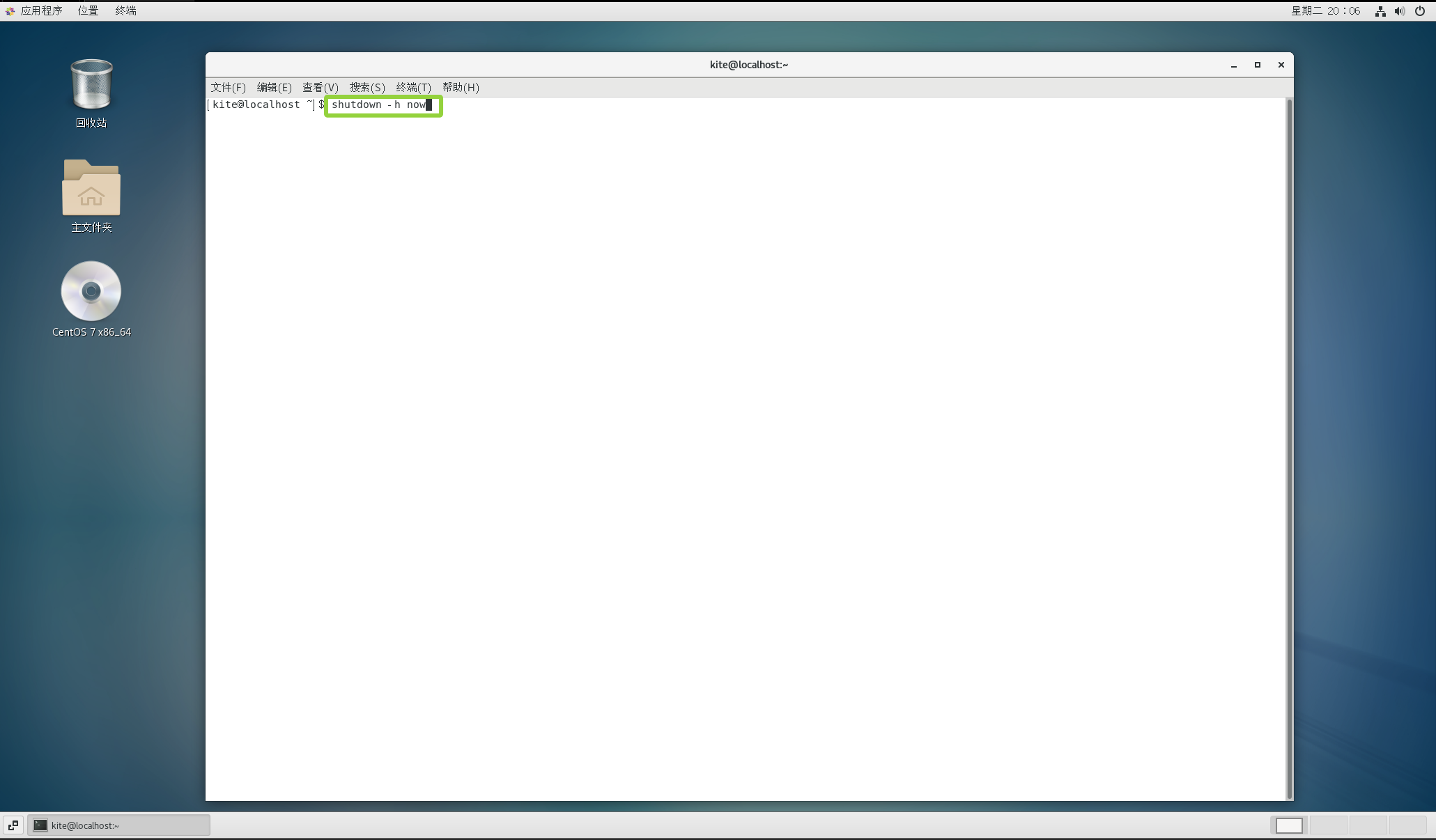
2.克隆虚拟机
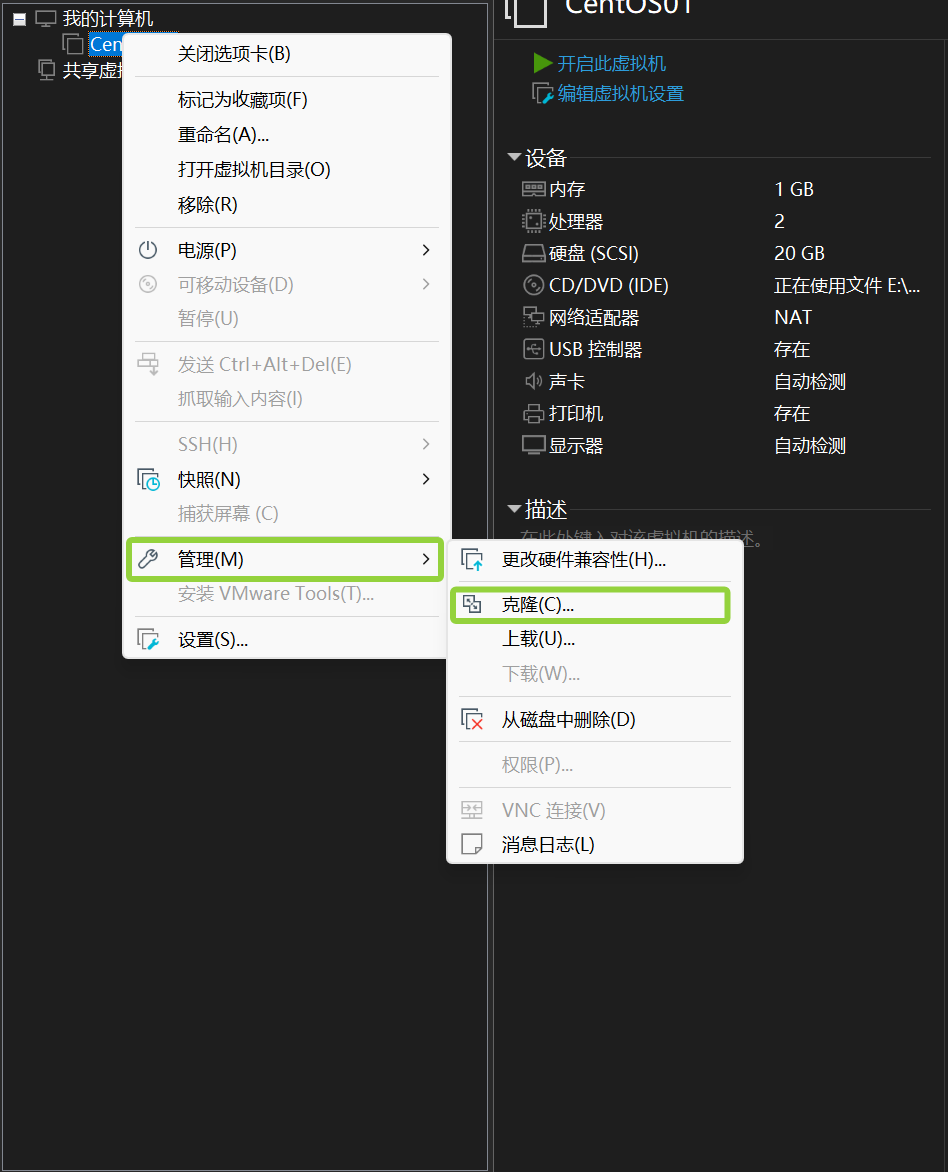
鼠标移入虚拟机后右键,找到管理,在管理找到克隆后,点击克隆
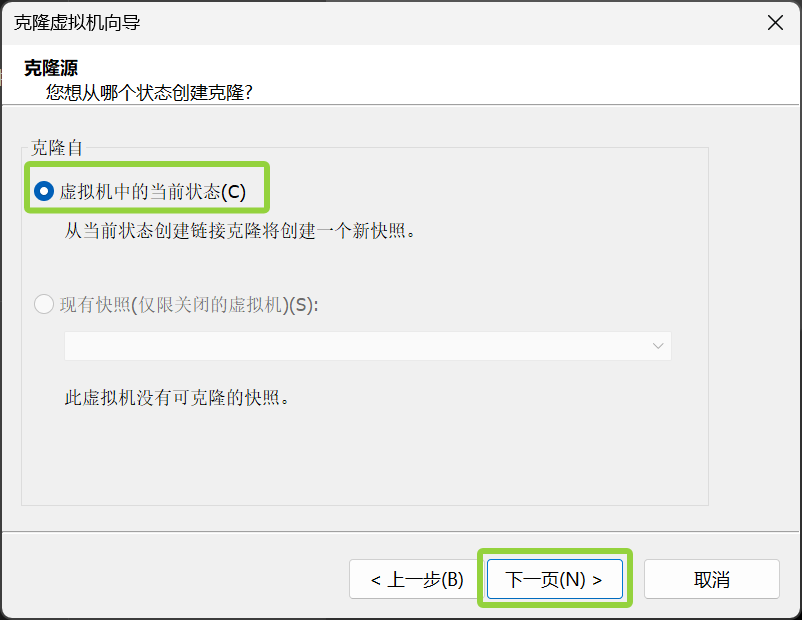
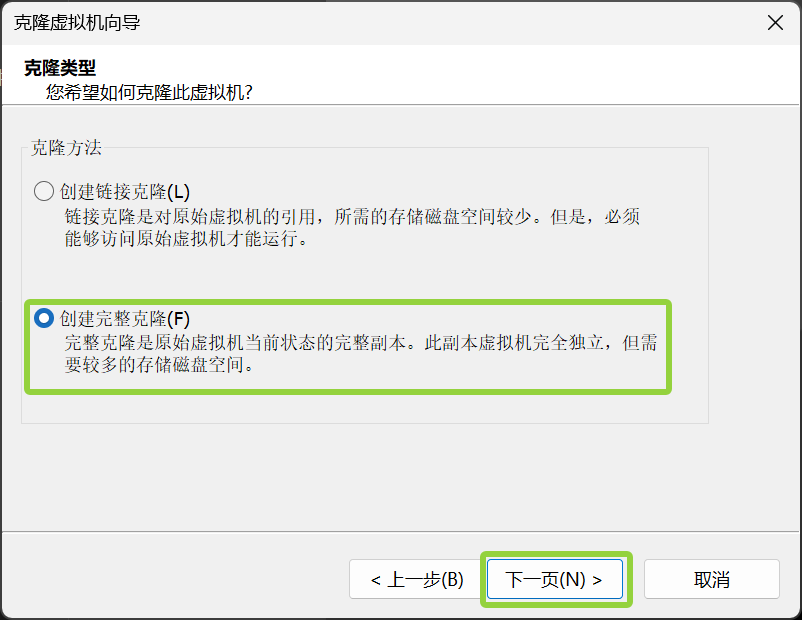
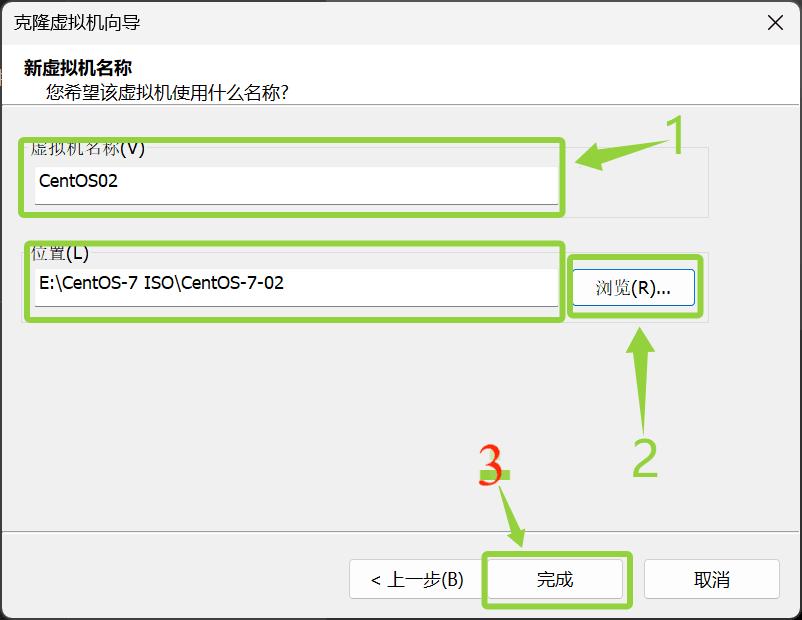
给第二个虚拟机起个名字,然后点击浏览,选择一个文件夹,也就是克隆机的存储位置
这里等待它克隆完成后点击"关闭"即可
同以上操作克隆好两台虚拟机
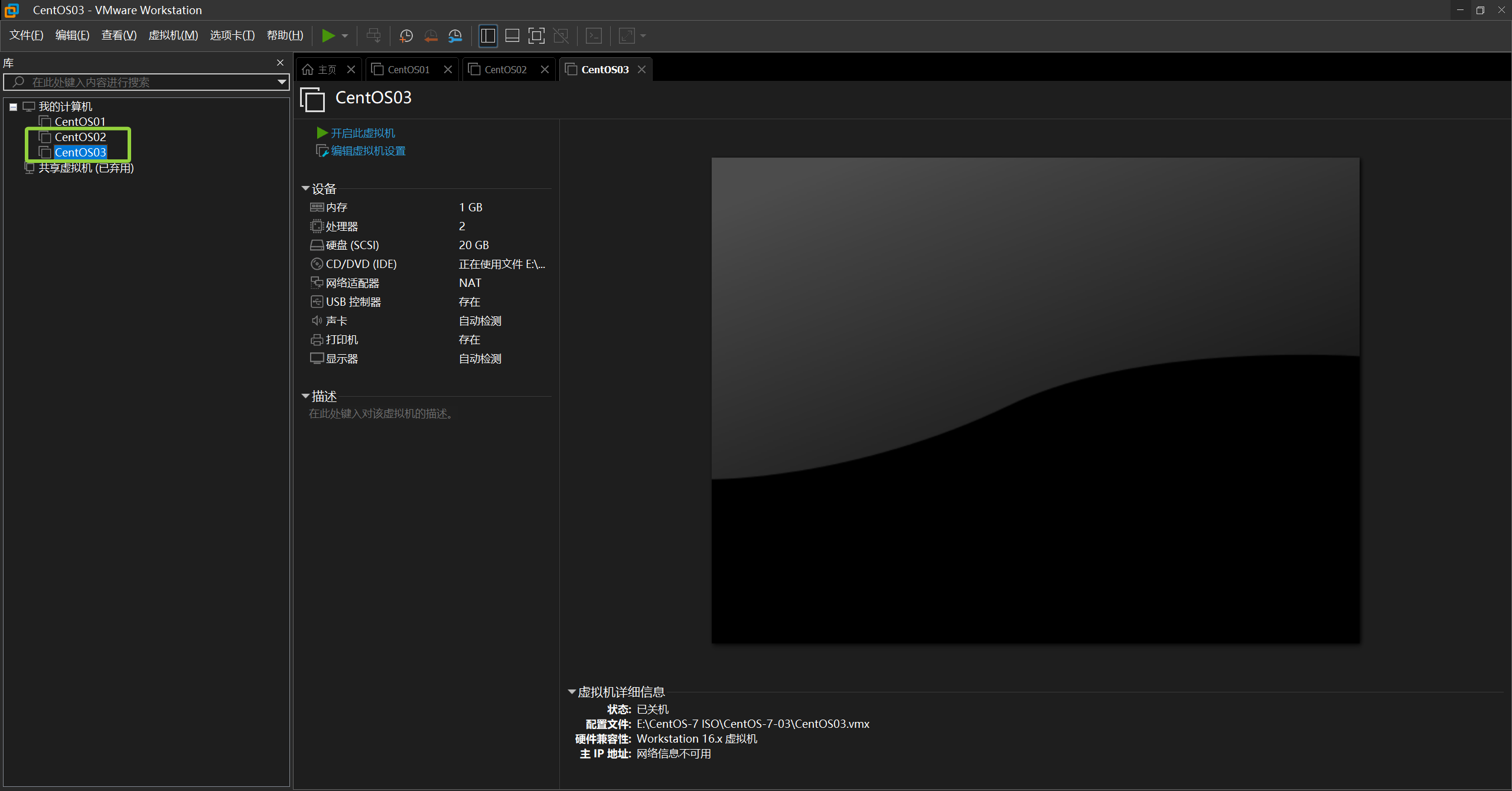
接下启动虚拟机(三台都要启动)
要求选择的时候选择第一个(三台同等操作)
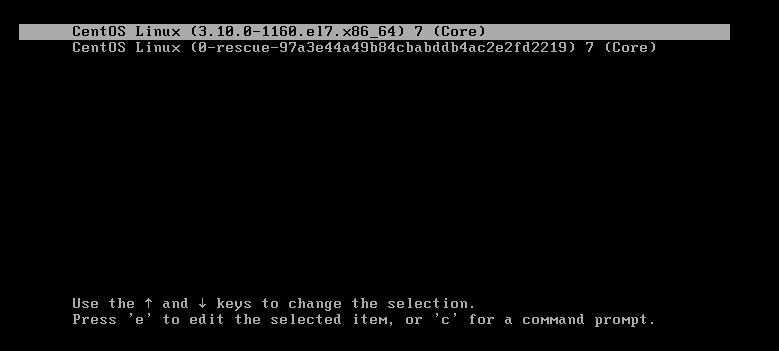
如下图,操作可直接进入ROOT模式,后续操作可省去很多赋予权限的操作
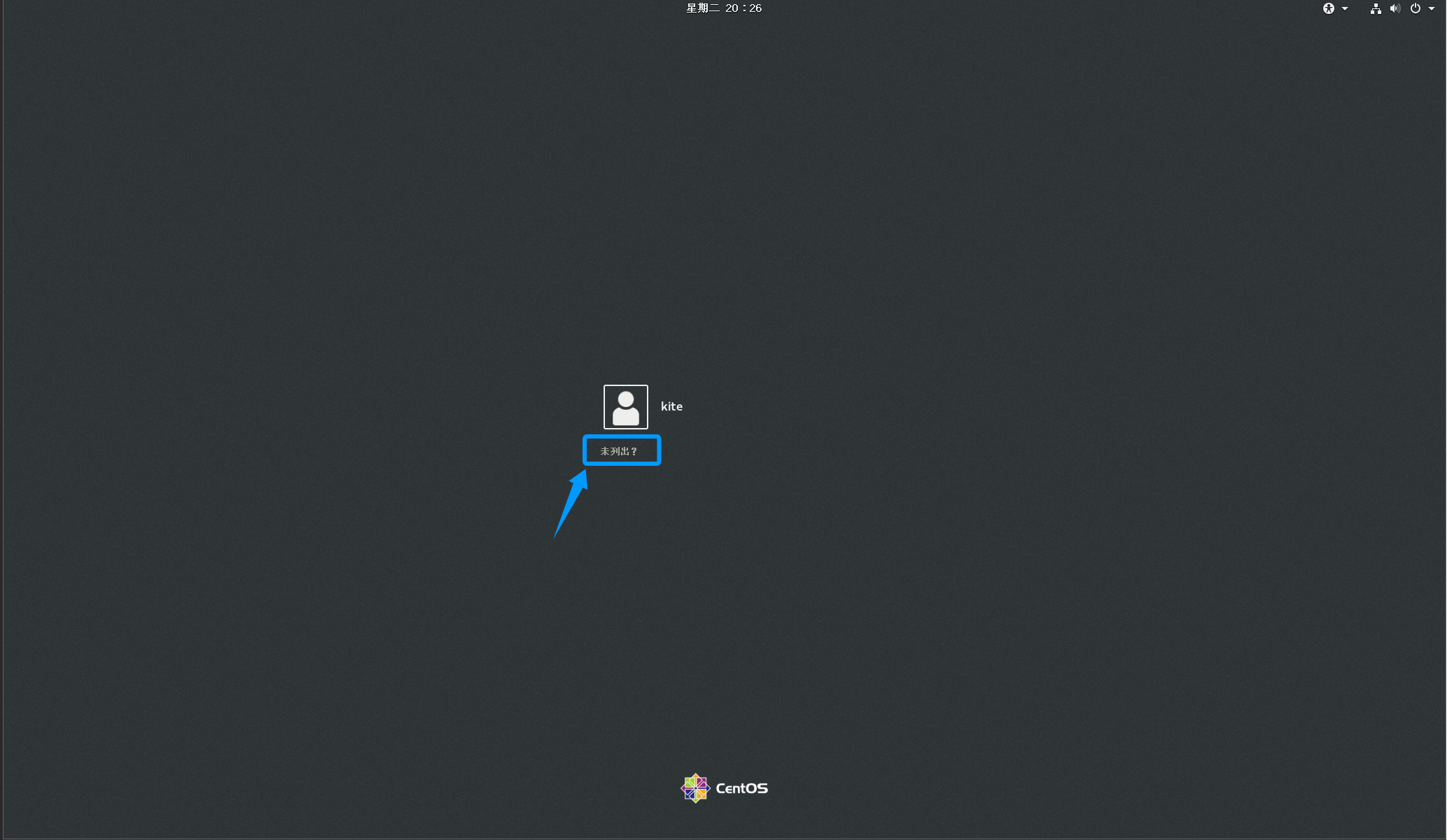
点击未列出的用户名一律输入root
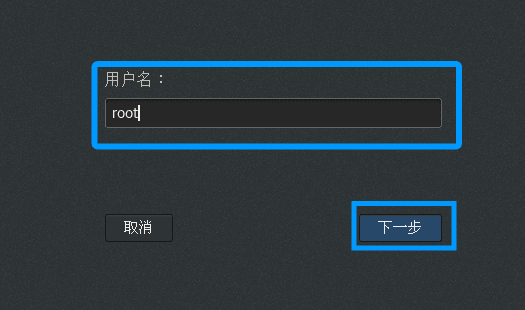
密码就是之前自己定义的root密码
注意:"因为后面两台虚拟机都是克隆出来的所以密码是相同的"
第一次以ROOT身份进入会弹出以下选项,提示操作即可
这里关闭位置服务点击前进
打开终端后可以看到有root字样,说明此时此刻就已经是ROOT模式了
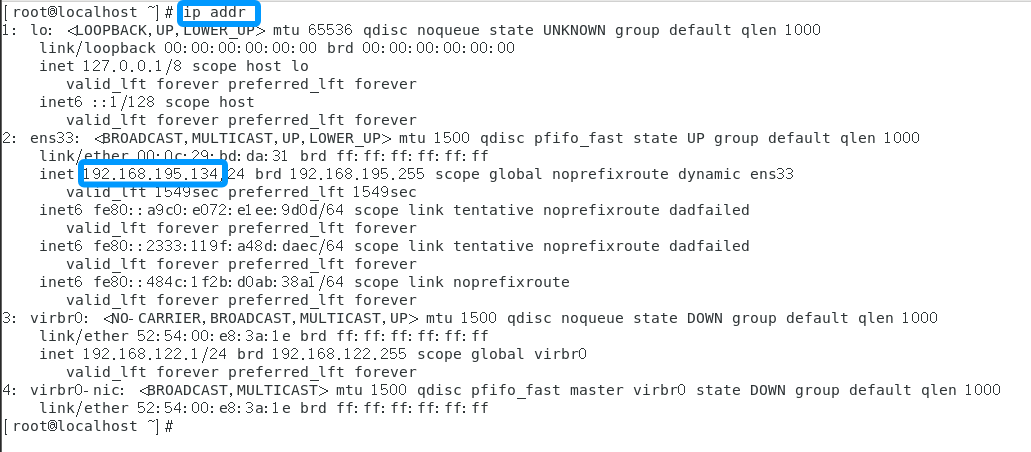
接下来查询三台虚拟机的IP地址
输入以下命令:
ip addr以下就是第一台虚拟机的IP地址了
提示:"每个人的IP地址可能不一样"
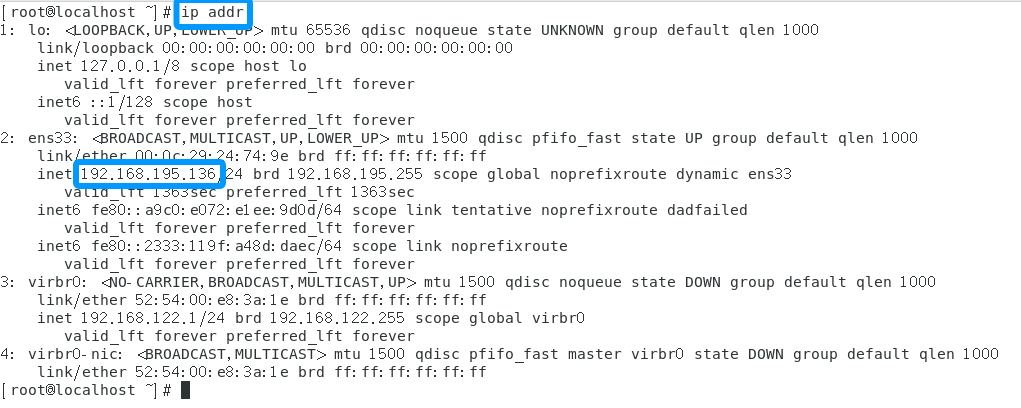
第二台

第三台
三.打开Xshell并连接所有虚拟机(修改主机名 配置静态IP)
1.连接所有虚拟机
进入该软件后点击新建
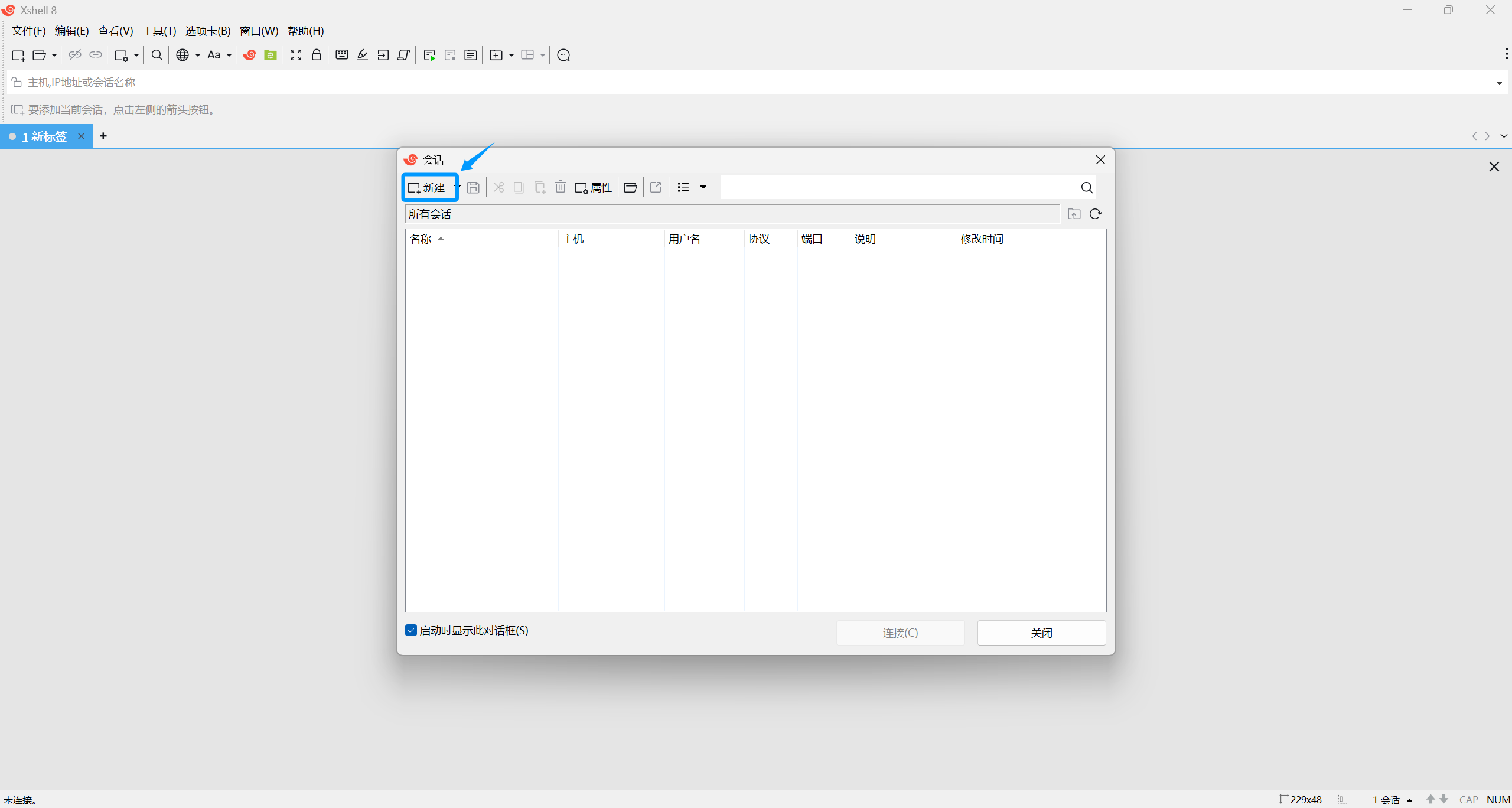
输入名称 "名称尽量与虚拟机名相同"
其次名称尽量不要包含特殊符号
IP地址,输入的是所查询出来的IPV4地址,每个人查询出来的IP可能不一样
输入好以后点击连接
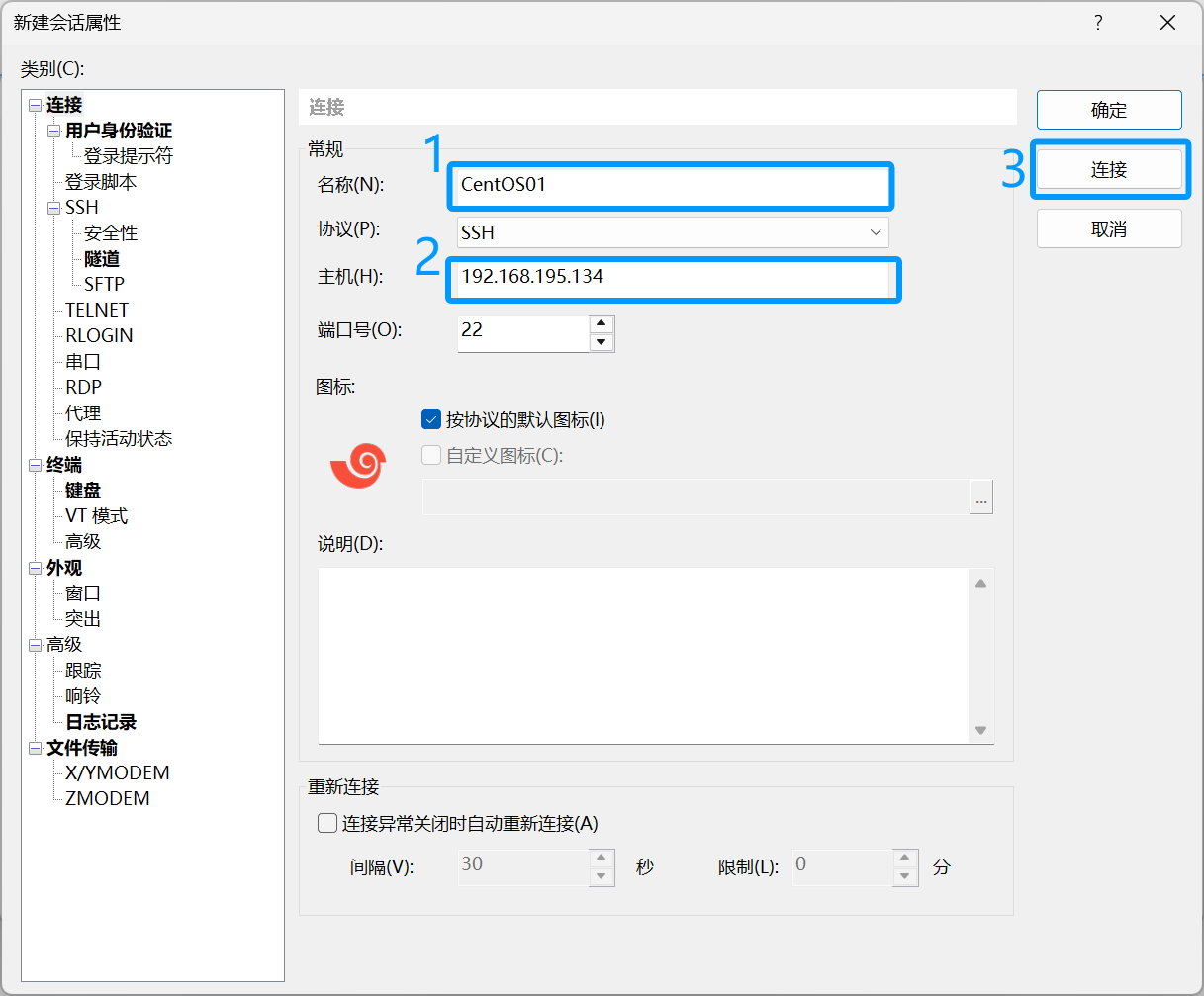
弹出如图对话框点击接收并保持
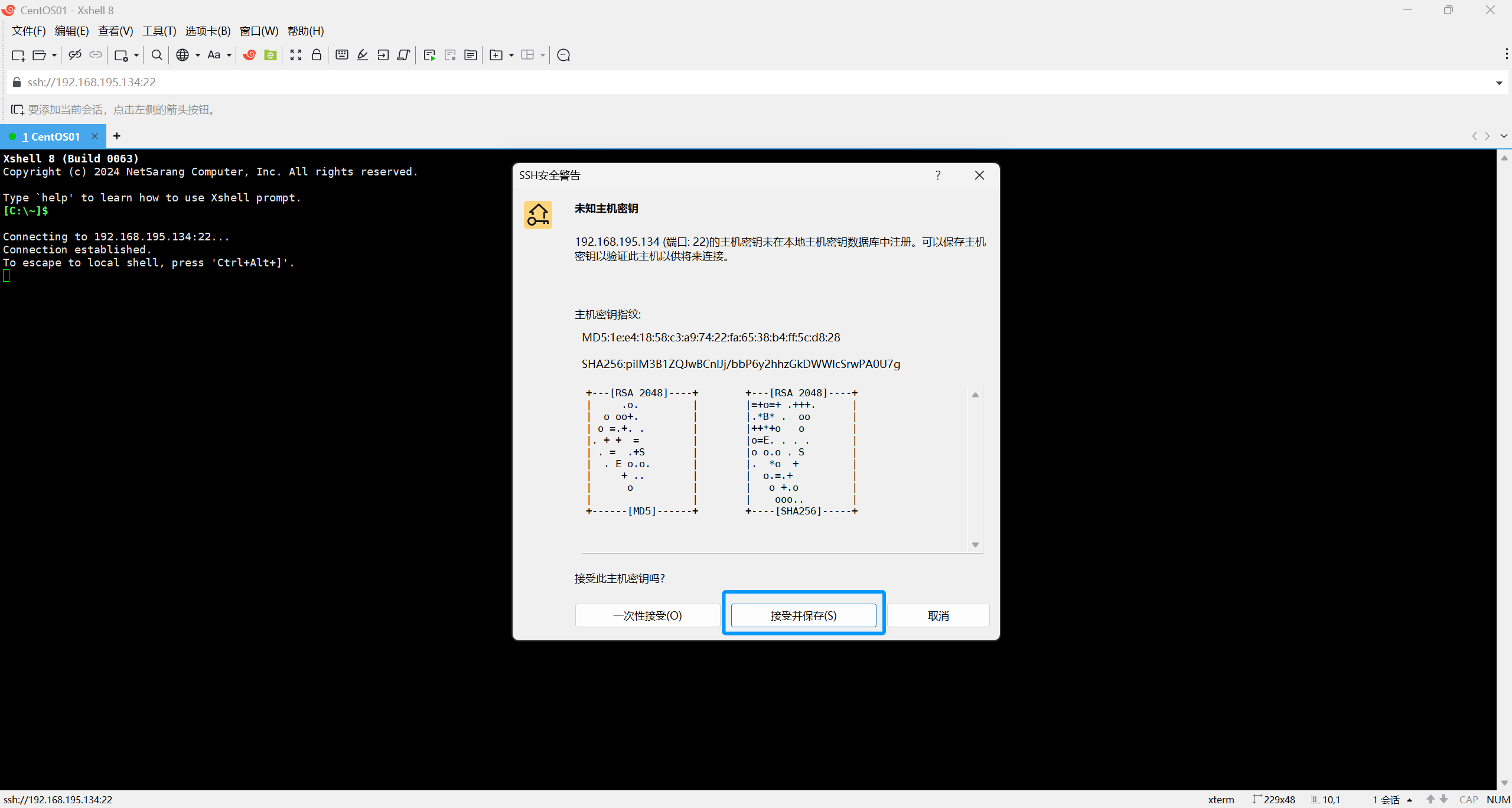
这里一定要输入root,且要勾选记住用户名
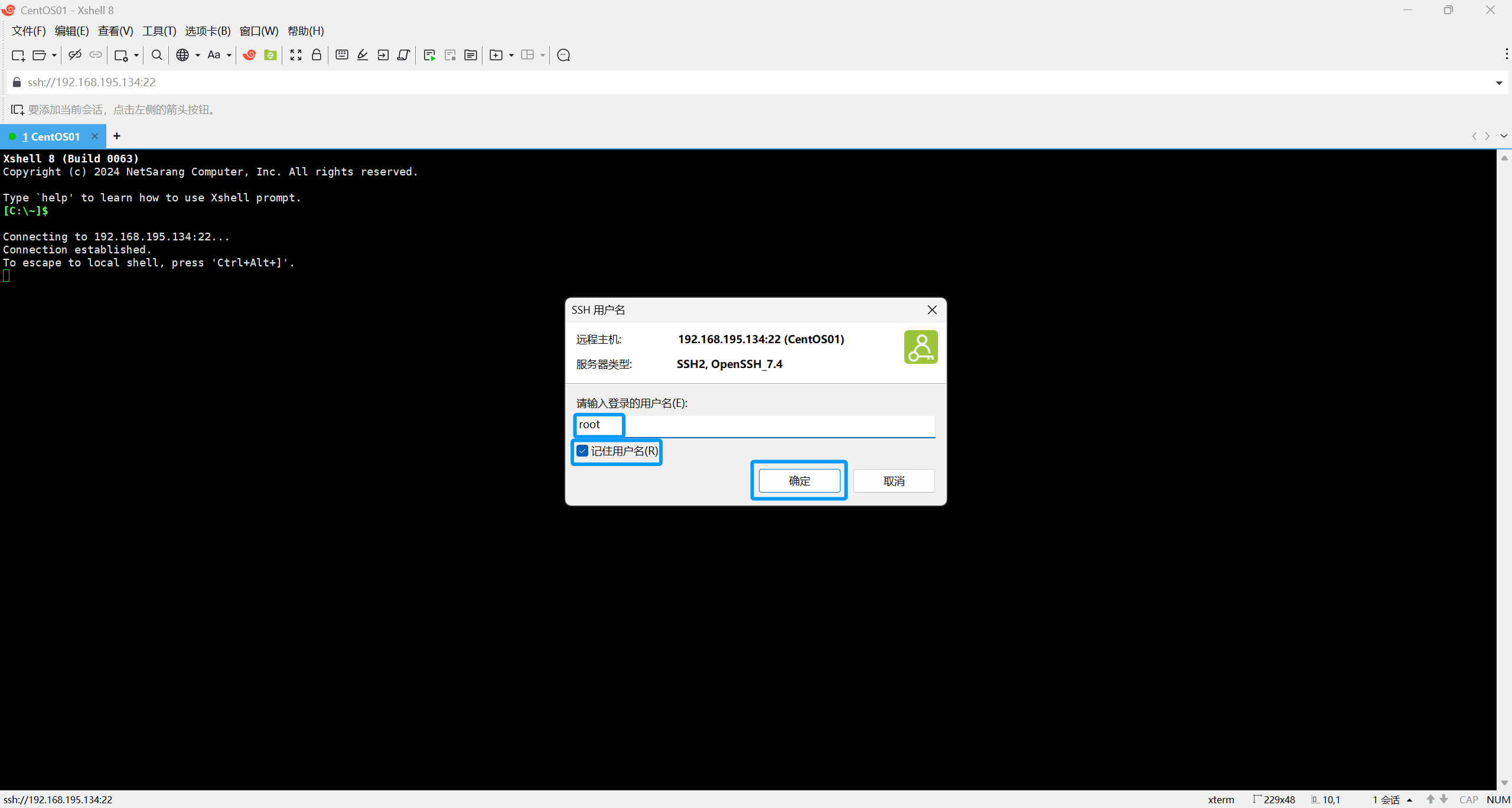
密码是自己之前所设置的虚拟机root密码,输入好以后要勾选记住密码。
接下来点击确定即可。
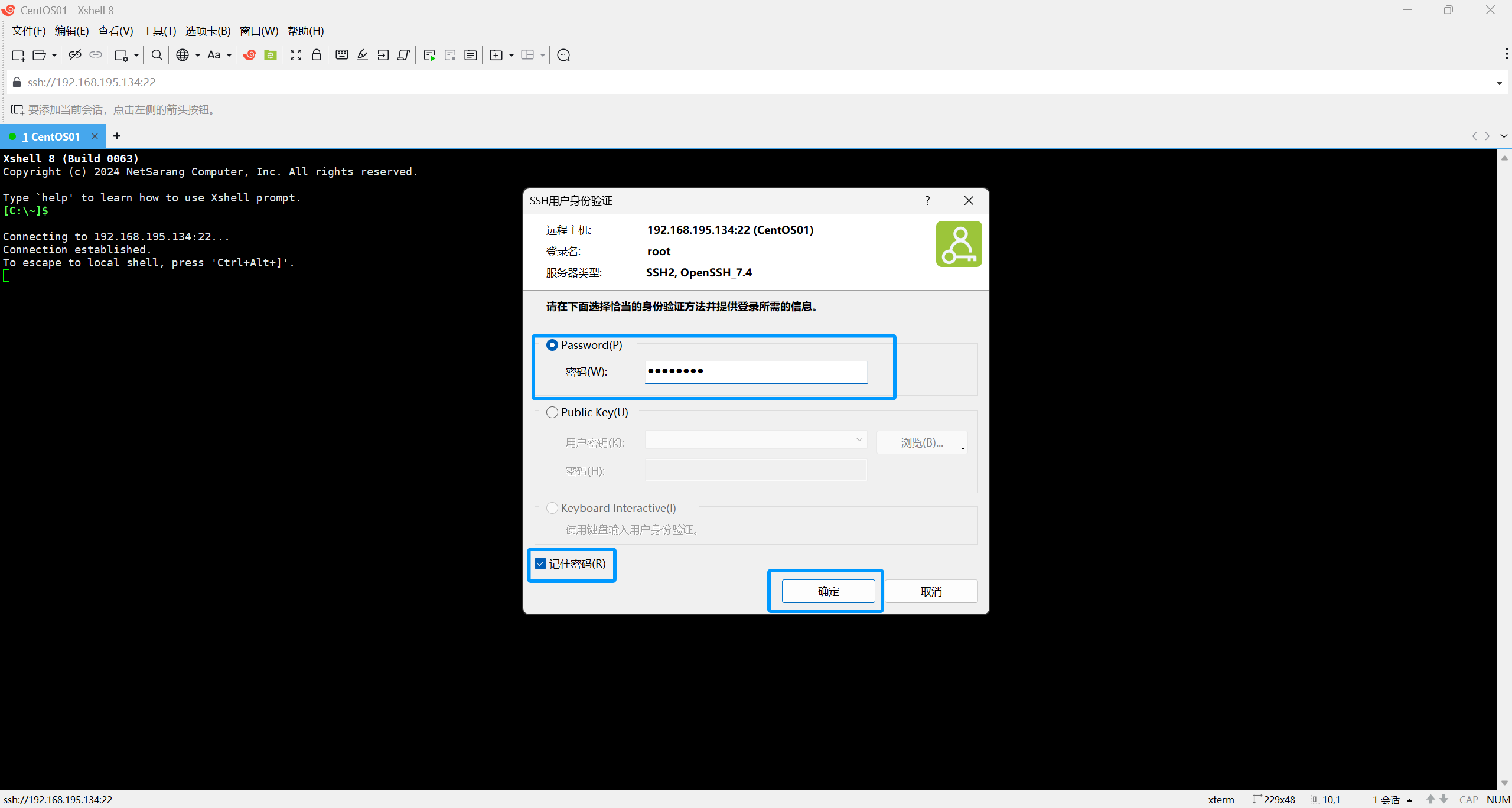
出现像这样的字样说明连接成功了
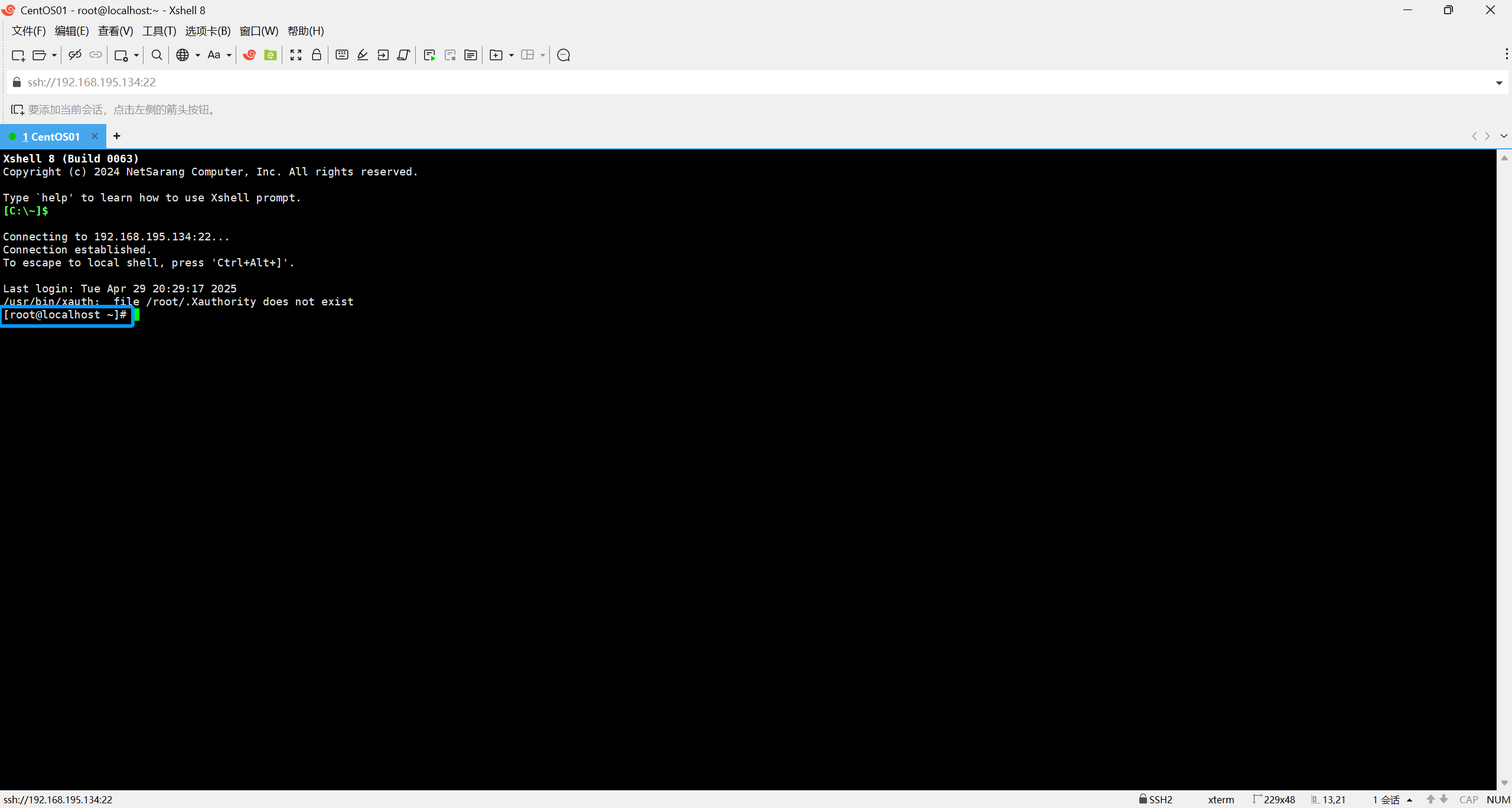
接下来的操作与上面相同,只是IP地址跟名称不一样:
这里点击"+"号
出现了一个新标签以后点击新建
然后按要求输入第二台虚拟机的IP和名称后点击确定,后续操作同上
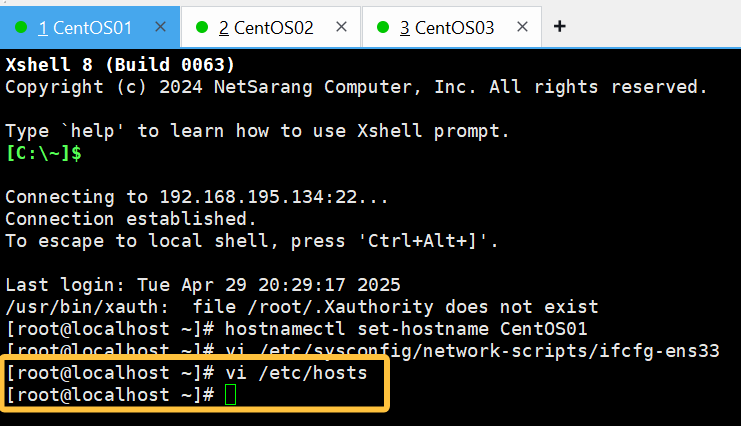
2.修改主机名
输入以下命令:
hostnamectl set-hostname +主机名(是自己给予的新名字)像这样输入就可以了(其余几台也是同等操作,只是主机名要变换一下),
尽量让主机名与虚拟机名相同,这样好分辨,但是主机名不能有特殊符号。
我在上面也提到过,在给虚拟机命名时不要包含特殊符号
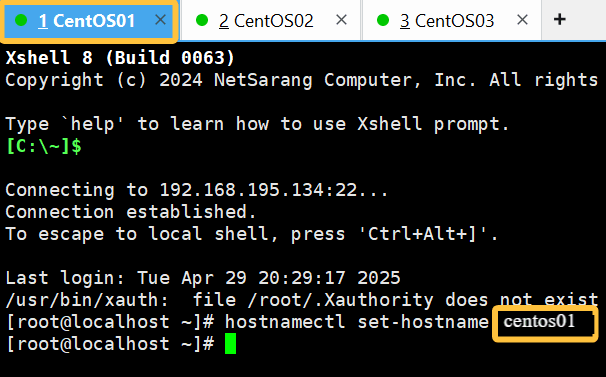
如上可以看出主机重命名命令已经执行了,但是"root@"后面没有发生改变,
这很正常,因为虚拟机没有重启,接下来给他配置好静态IP后重启一下,主机名就会改变了。
3.配置静态IP
输入以下命令(其余几台同等操作):
vi /etc/sysconfig/network-scripts/ifcfg-ens33输入命令后会进入该页面

按"i"键可变成插入模式,在插入模式中不要使用滚轮滑动,
要移动只能使用 "上" "下" "左" "右"方向键进行操作。
在插入模式里编译完成后"Esc"键可退出插入模式,
然后输入"Shift+:"可进行以下操作
输入"wq"保存并退出,"w"保存不退出,"q"退出不保存,"q!"强行退出。
把"BOOTPROTO"里的单词修改为"static",
"ONBOOT"里的单词修改为"yes"
如图所示
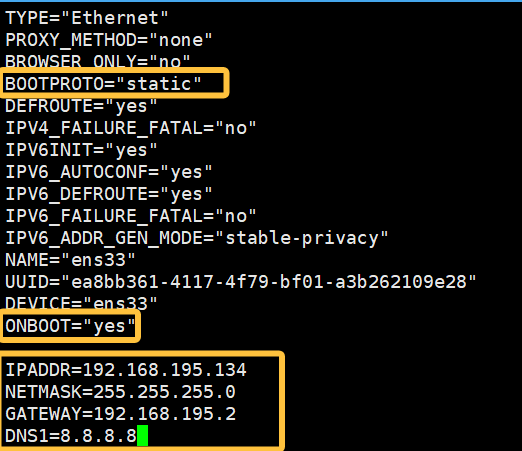
并在''' ONBOOT="yes" '''下面添加以下内容
IPADDR=写自己虚拟机的IP
NETMASK=255.255.255.0
GATEWAY=根据自己虚拟机的IP变换.2
DNS1=8.8.8.8例子:
'''
IPADDR=192.168.195.134
NETMASK=255.255.255.0
GATEWAY=192.168.195.2
DNS1=8.8.8.8
'''
其余几台也是同等操作
4.修改主机映射并重启
输入以下命令:
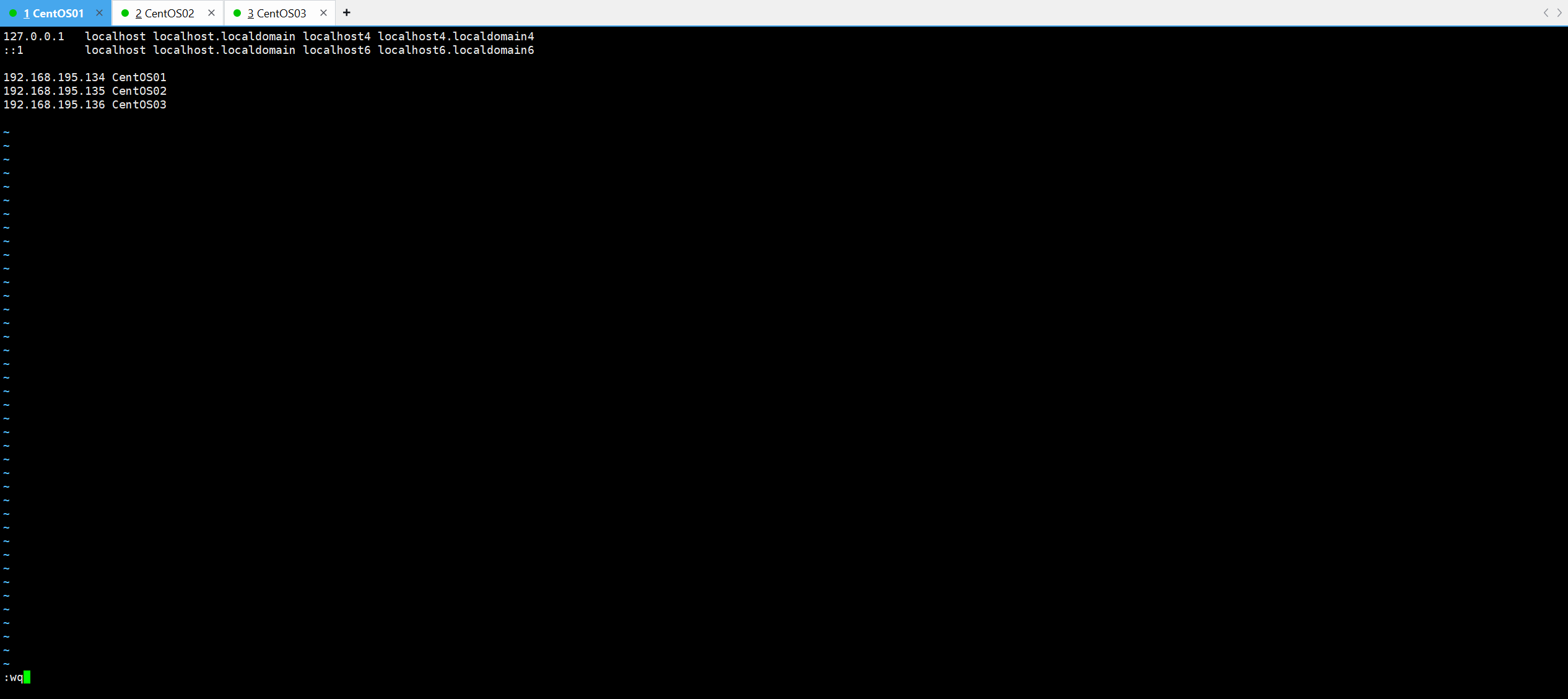
vi /etc/hosts进入以下界面后
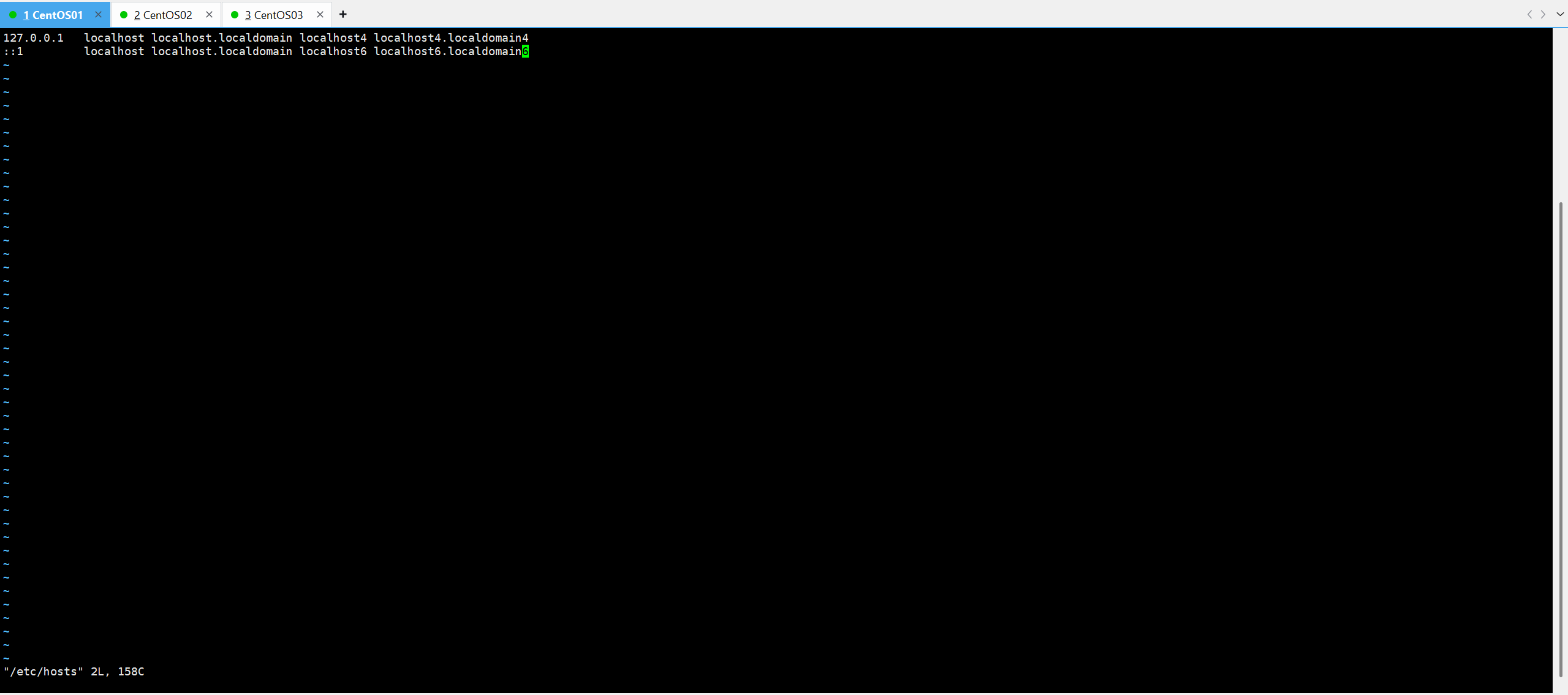
“i”键 插入“主机IP+虚拟机名称”然后 "Esc"键 ,再"Shift+:"键,输入"wq" 保存并退出;
如图所示

重启输入以下命令
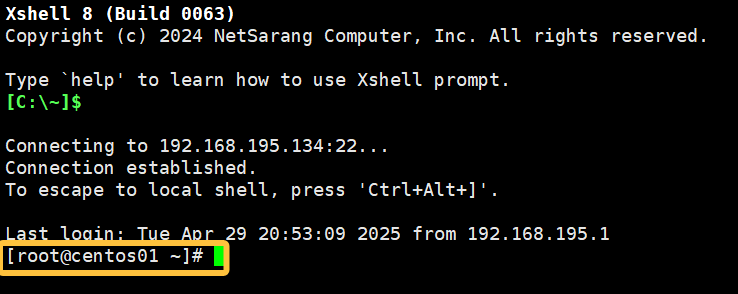
reboot可以看到重启以后root@后面的字样发生了变化
其余几台同等操作
第二步

一.连通性测试
使用以下命令:
ping +网址
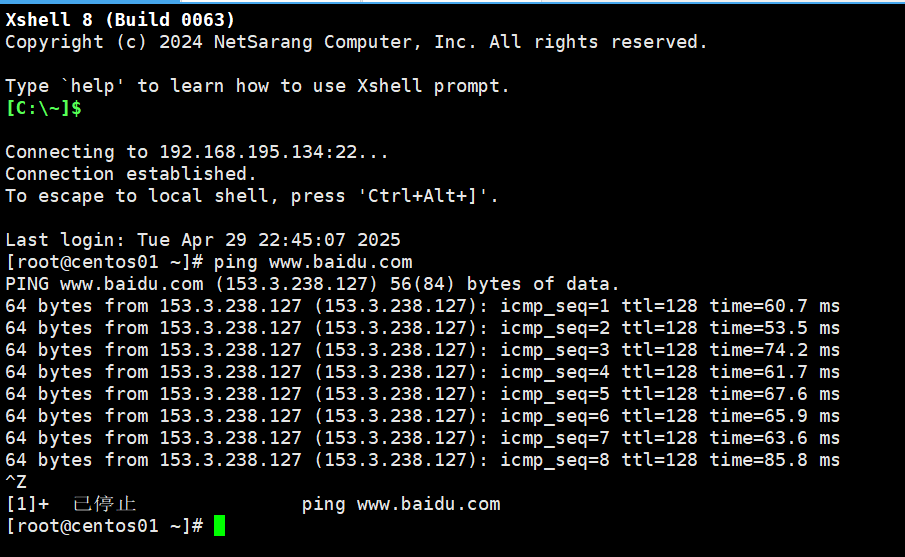
我就来访问一下百度:
ping www.baidu.com
如果有返回值说明连通正常,
使用Ctrl+z停止
如图所示
其余几台同等操作
二.安装SSH服务
安装SSH服务镜像源
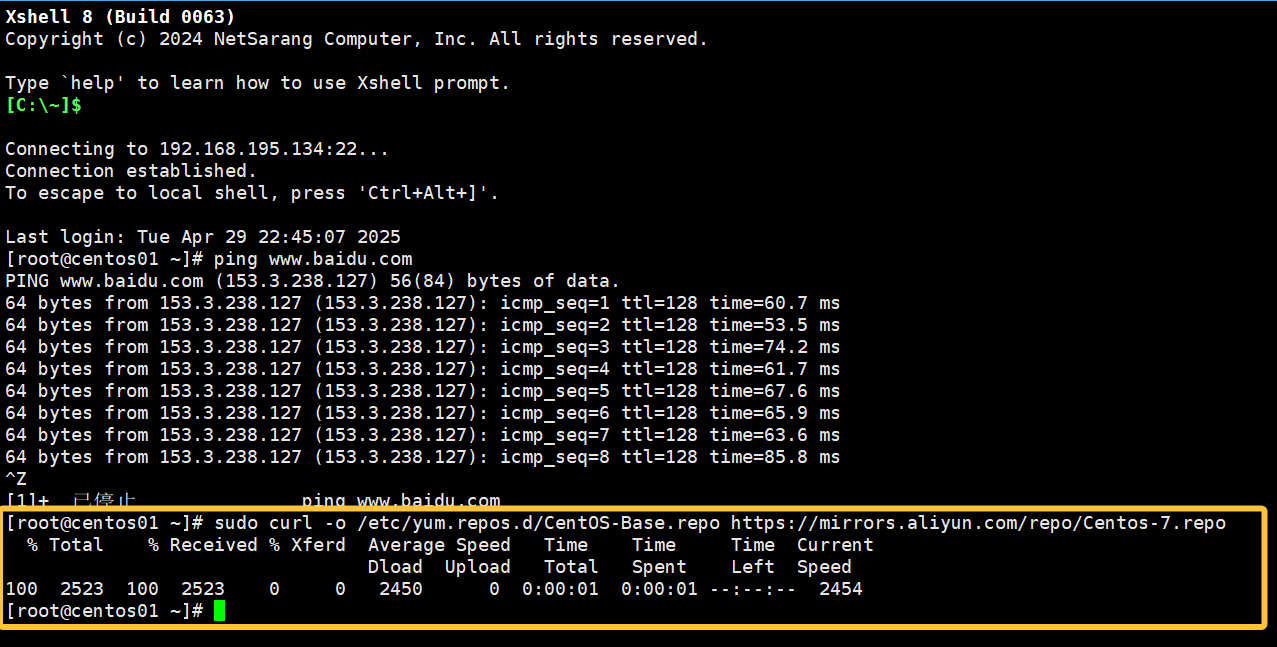
sudo curl -o /etc/yum.repos.d/CentOS-Base.repo https://mirrors.aliyun.com/repo/Centos-7.repo为了防止SSH服务安装失败,所以先转换一下镜像源
如图所示像这样,就说明成功更换镜像源了
接下来输入命令:
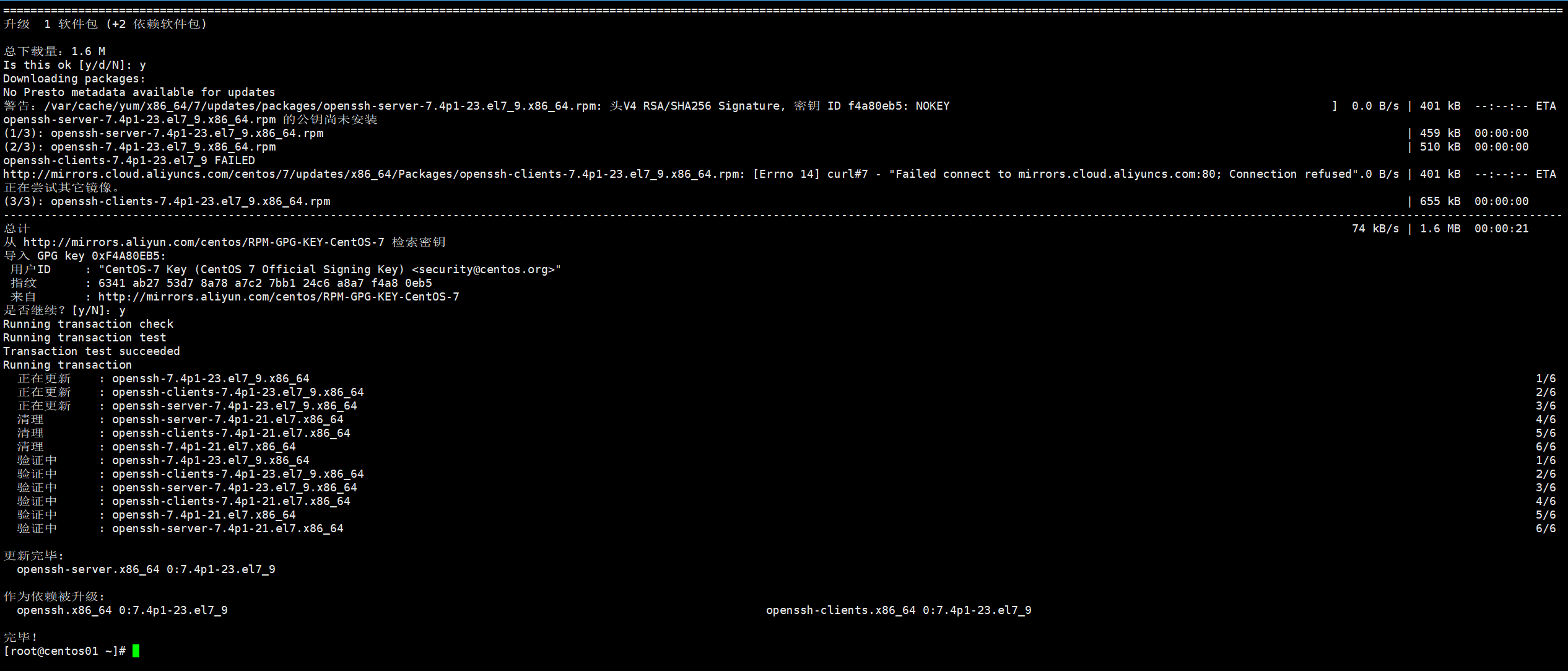
yum install openssh-server出现选择的时候就输入“y”就行
如图所示就说明安装成功了
密钥生成
命令如下:
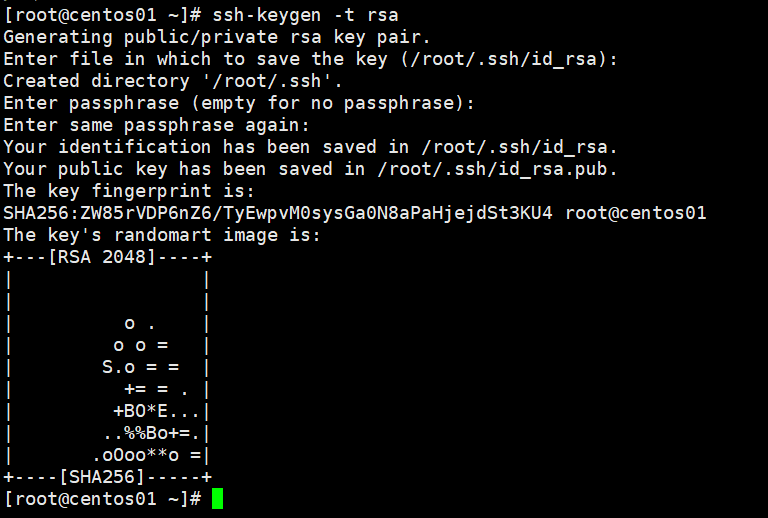
ssh-keygen -t rsa输入该命令会给出3次提示不用管,直接拍3次回车即可
如图所示,就说明成功了
其余几台同等操作
三.目录创建
1.放置相关数据文件
命令如下:
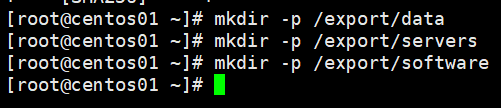
mkdir -p /export/data2.软件安装目录
命令如下:
mkdir -p /export/servers3.放置软件包
命令如下:
mkdir -p /export/software如图所示表示成功
其余几台同等操作
四.公钥拷贝
拷贝公钥到同一台虚拟机
命令如下:
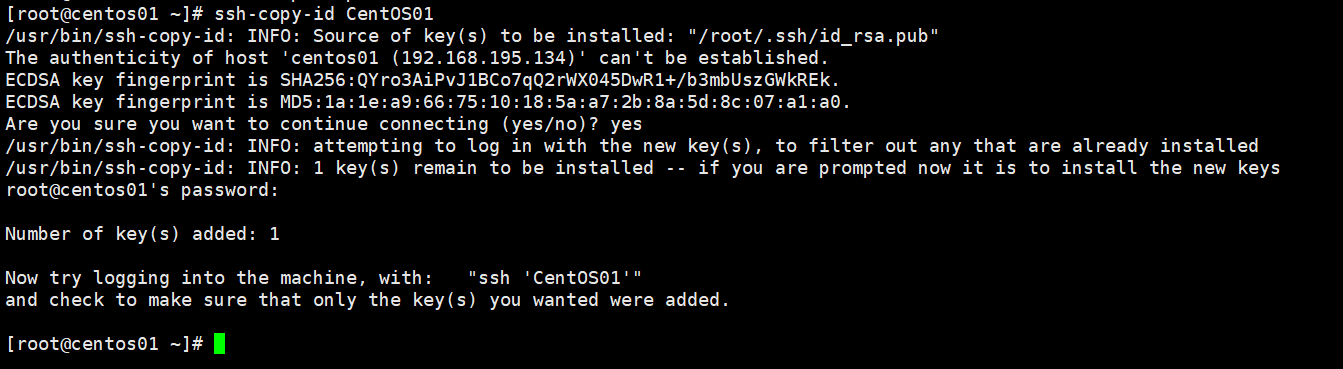
ssh-copy-id +虚拟机名称如图所示:
"Are you sure you want to continue connecting (yes/no)?" 这里要输入"yes"
root@centos01's password:这里输入自己设置的root密码

像这样就是成功的
复制公钥的文件给其他虚拟机
命令如下:
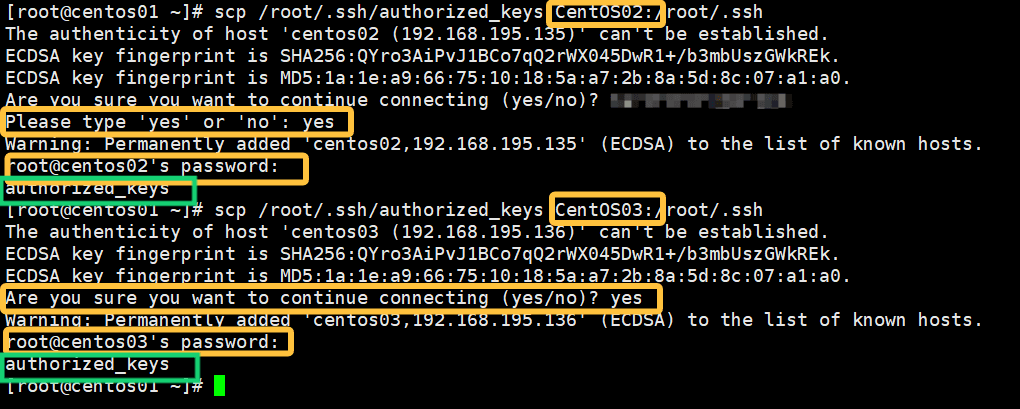
scp /root/.ssh/authorized_keys +除上个命令所写的虚拟机名称:/root/.ssh如图所示
"Are you sure you want to continue connecting (yes/no)?" 这里要输入"yes"
root@centos01's password:这里输入自己设置的root密码
返回了“authorized_keys”说明成功了
第三步
一.从Windows传入安装包给虚拟机并安装
1.安装rz插件
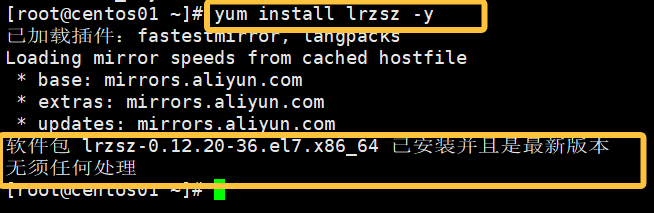
命令如下:
yum install lrzsz -y如图所示表示成功
其余几台同等操作
2.确定是否有自带jdk
命令如下:
java -version如图所示可以看到是存在自带jdk的
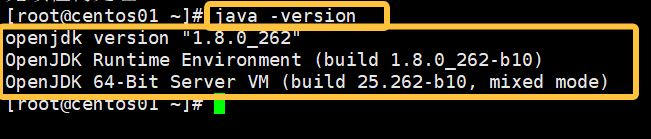
其余几台同等操作
3.搜索jdk
命令如下:
rpm -qa | grep jdk如图所示有4个自带的jdk,我们需要把带open的jdk全部卸载
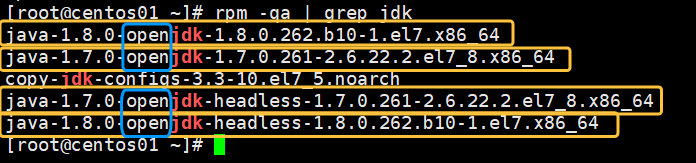
其余几台同等操作
4.卸载open jdk
命令如下:
rpm -e --nodeps +自带open jdk的所有字符如图所示,可以看出来带open的jdk都已经删除了
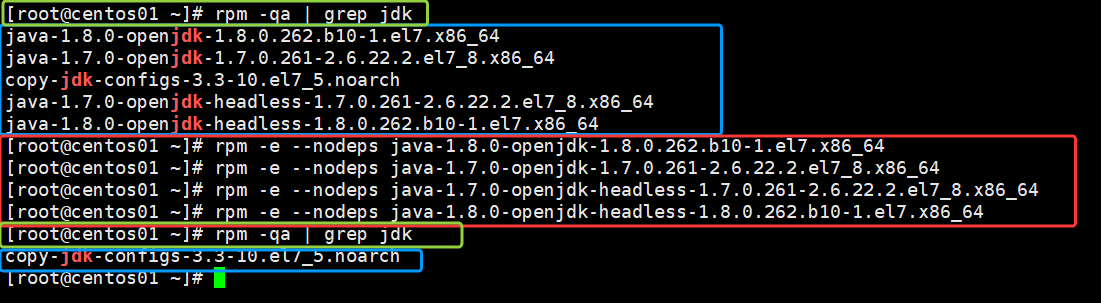
其余几台同等操作
5.安装jdk
切换到目录/export/software:
cd /export/software如图所示,像这样就说明成功进入目录了

上传jdk安装包
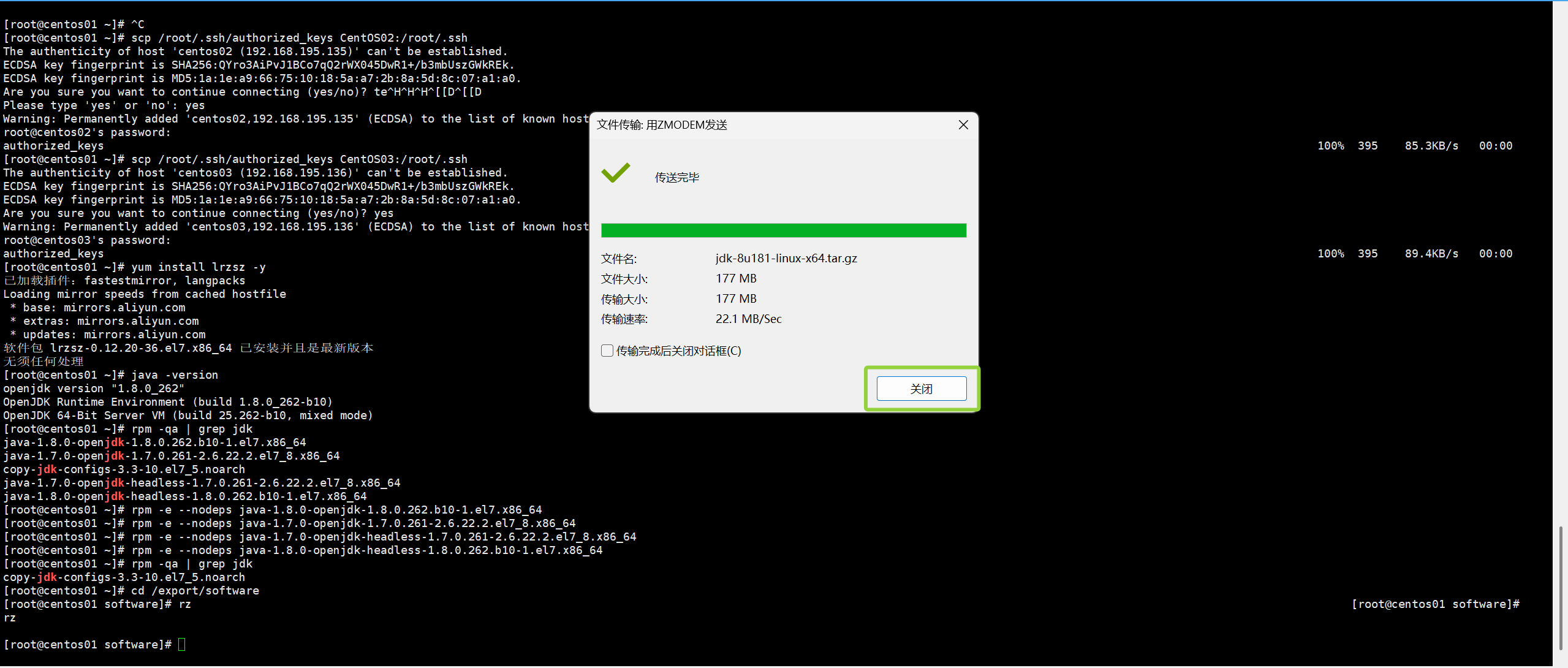
rz如图所示,输入“rz”后选择所需安装包文件
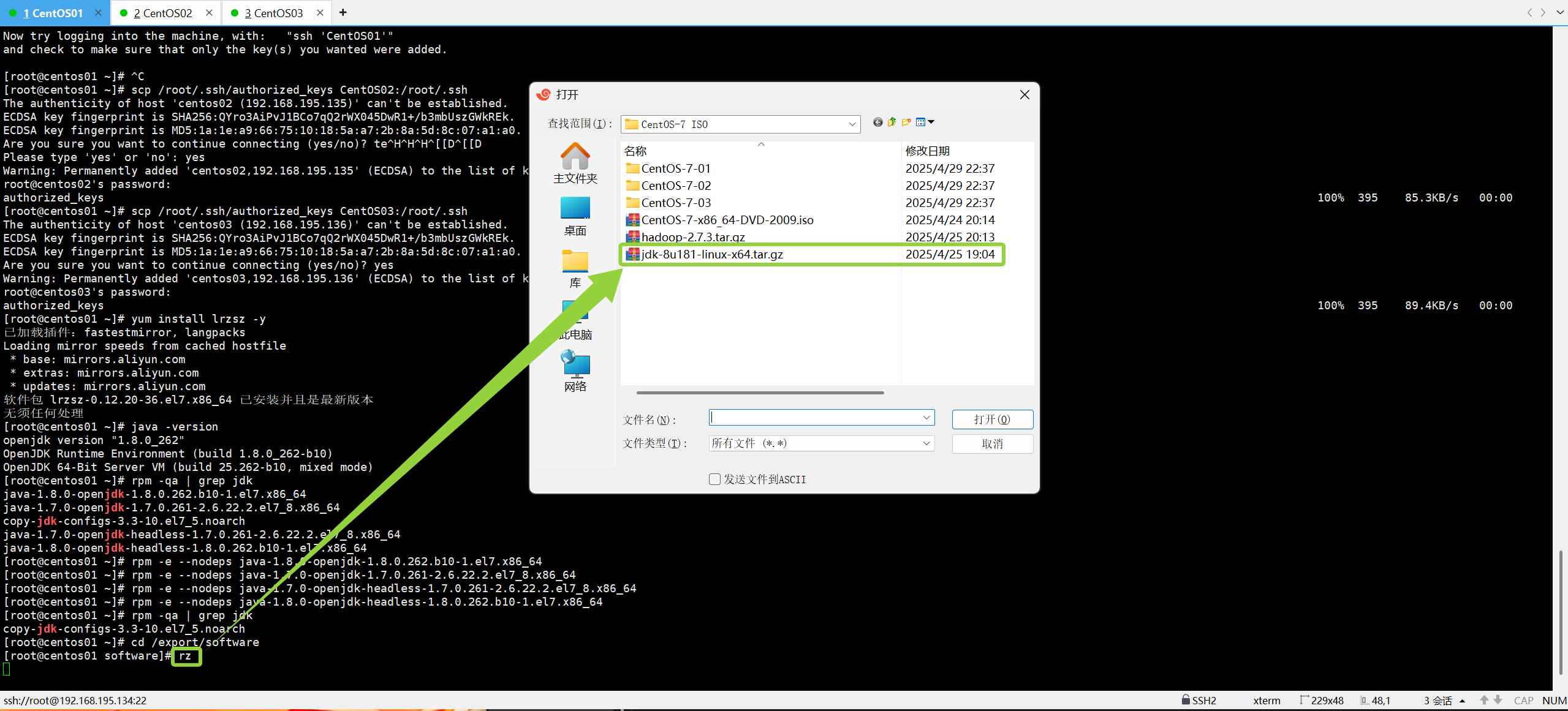
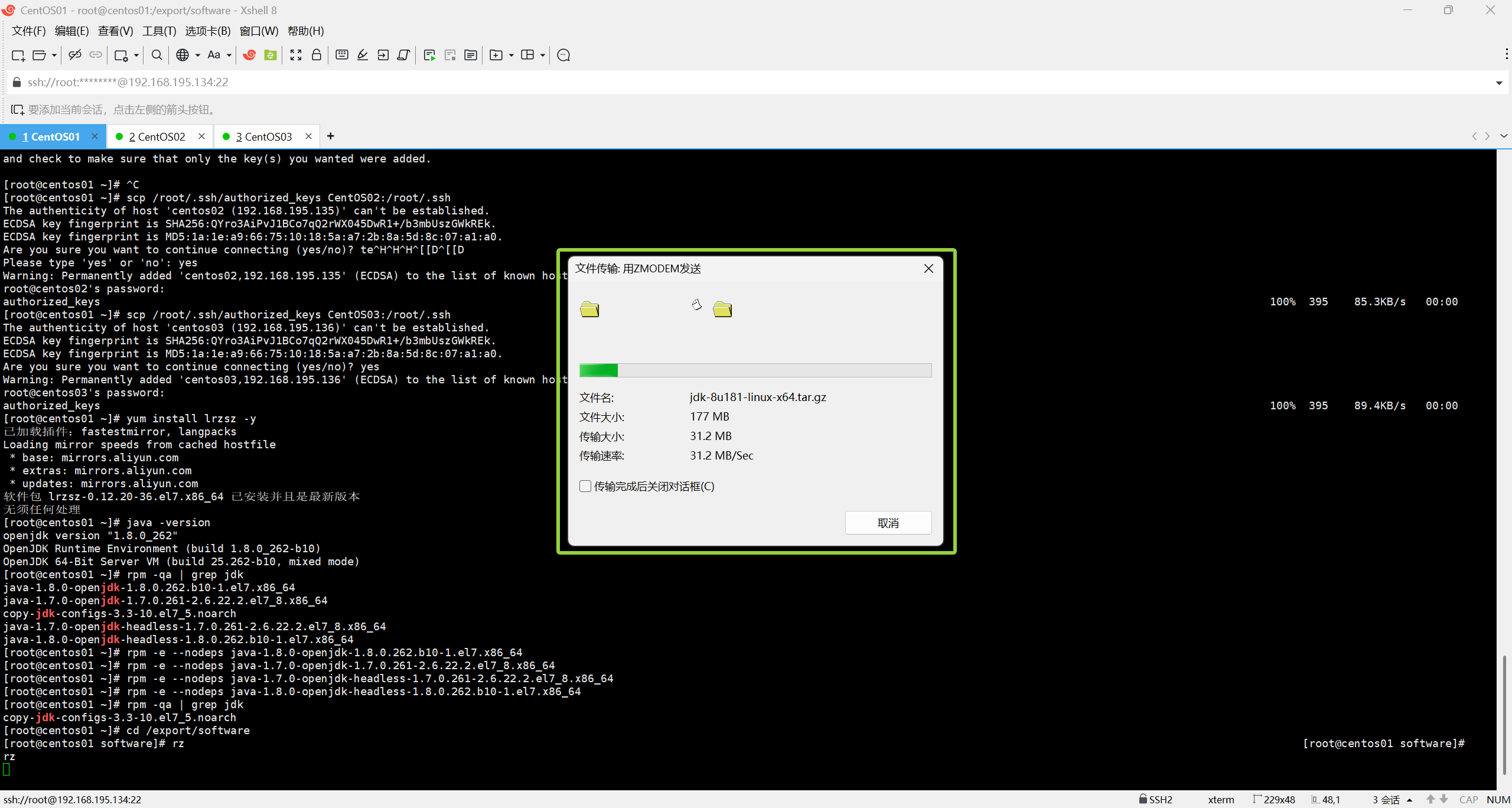
像这样就已经传输成功了
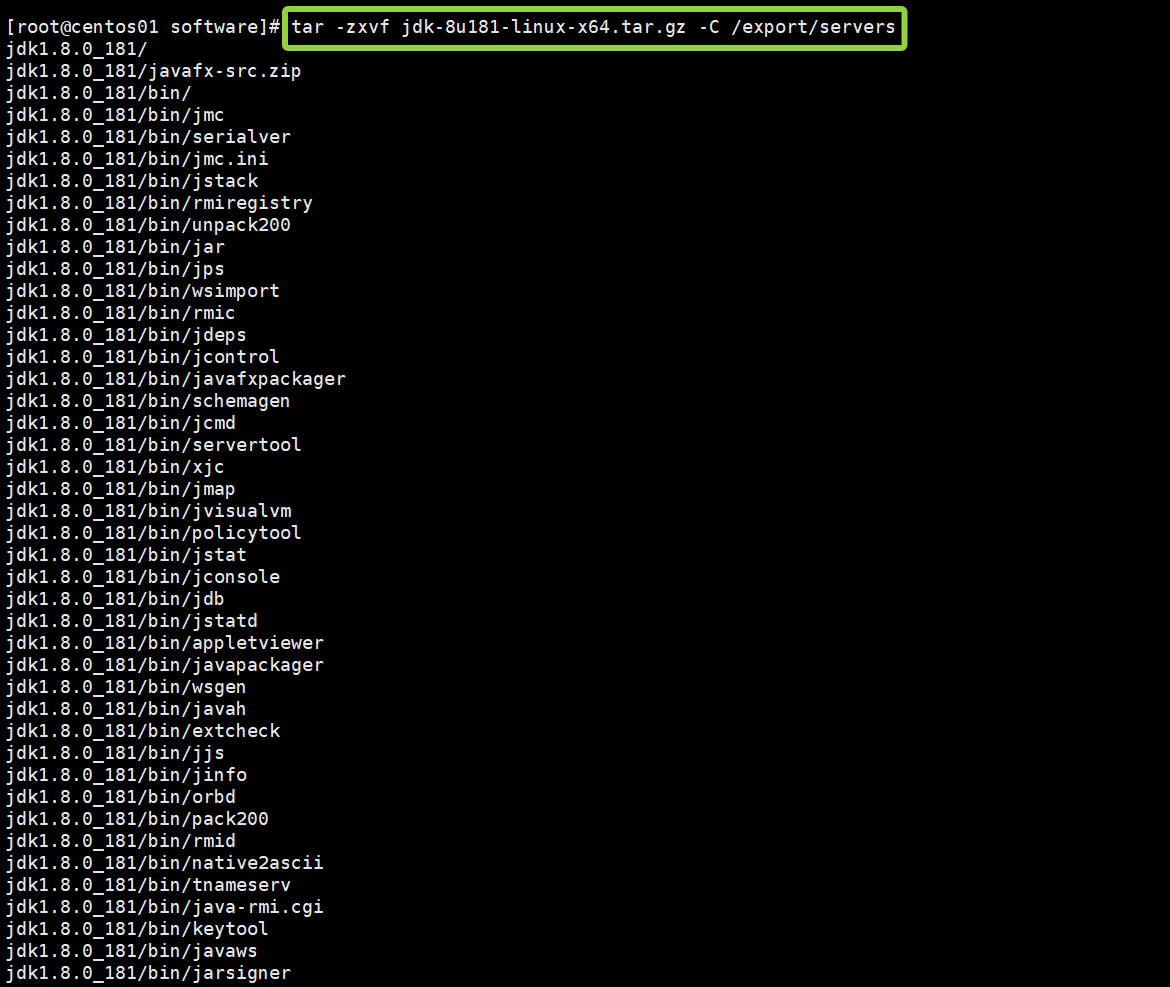
解压缩安装包:
tar -zxvf +jdk的全称 -C /export/servers如图所示,像这样就代表成功了

切换到解压后的路径
cd /export/servers/进行重命名
mv +JDK解压缩后的文件夹名 它的新名字
二.配置JDK环境变量
命令:
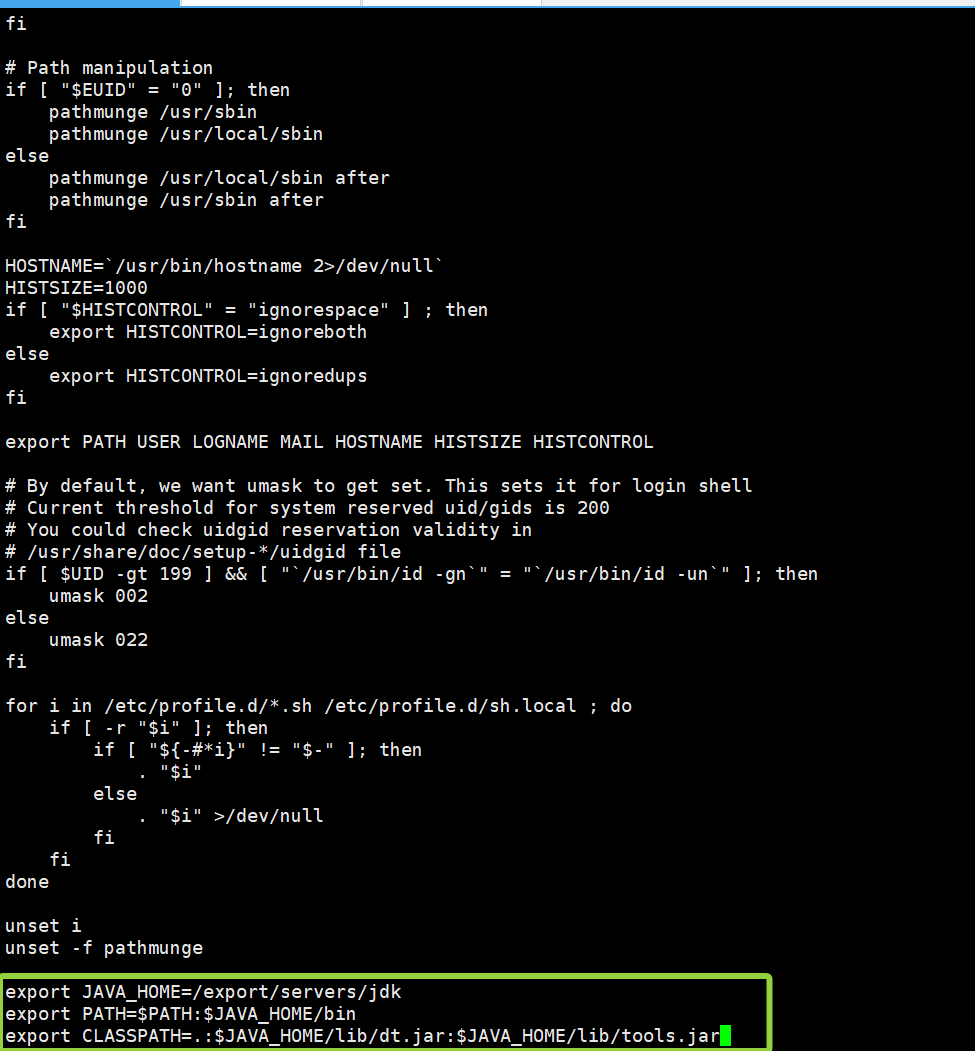
vi /etc/profile添加一下内容:
export JAVA_HOME=/export/servers/jdk
export PATH=$PATH:$JAVA_HOME/bin
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar如图所示,“i”键添加好内容以后,“Shift+:”组合键 然后输入"wq",保存并退出

重新加载环境变量
source /etc/profile
完成后验证:
java -version如图所示验证成功了

出现权限不够则,添加权限
chmod -R +x /export/servers/jdk/bin/java
第四步
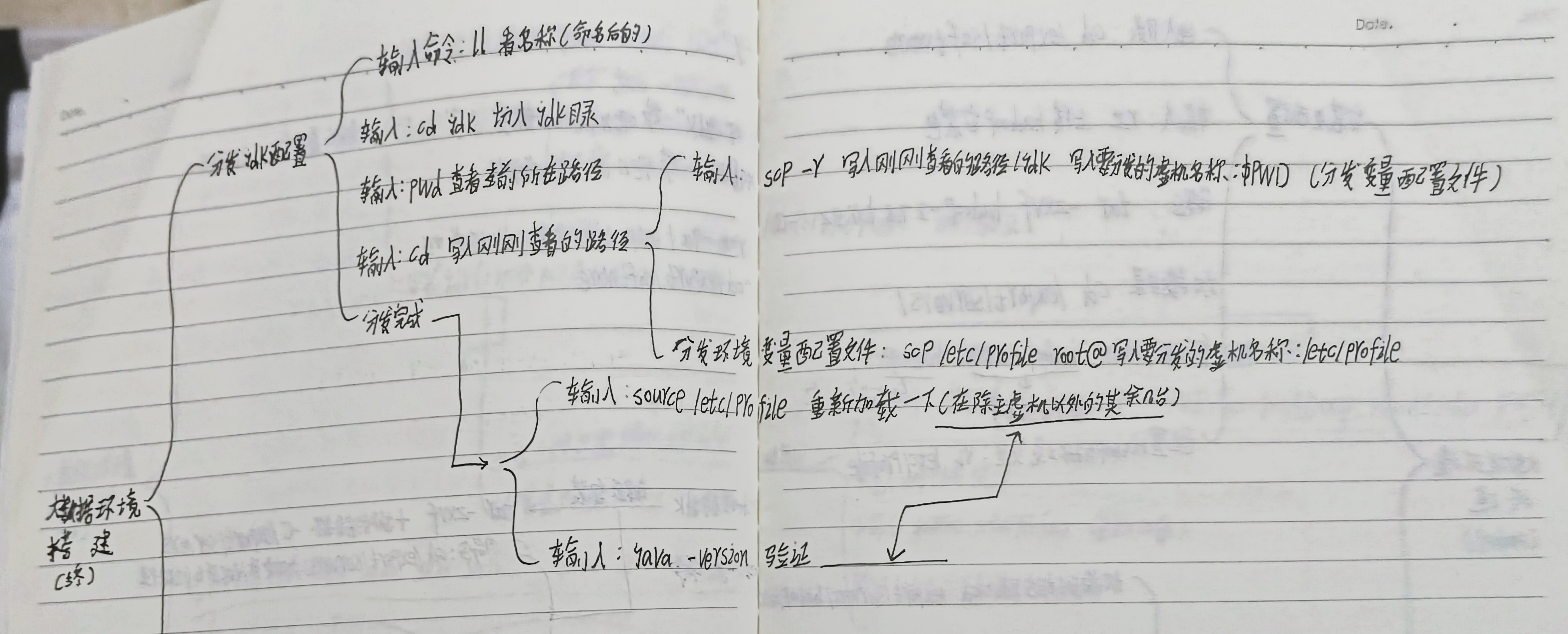
1.分发JDK配置
查看命名后的名称 命令:
ll切入jdk目录
cd jdk查看当前所在路径
pwd进入当前路径
cd +刚刚使用pwd查看到的路径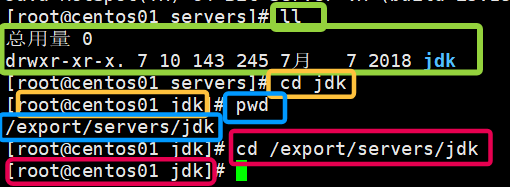
分发变量配置文件
scp -r +刚刚pwd查看的路径 +要分发的虚拟机名称:$PWD如图所示


分发环境变量配置文件
scp /etc/profile root@+要分发的虚拟机名称:/etc/profile如图所示

2.分发完成后
重新加载(在除了主虚拟机外的其余几台使用命令)
source /etc/profile

验证(在每台虚拟机里使用)
java -version

第五步

一.Hadoop安装
进入目录
cd /export/software传入安装包
rz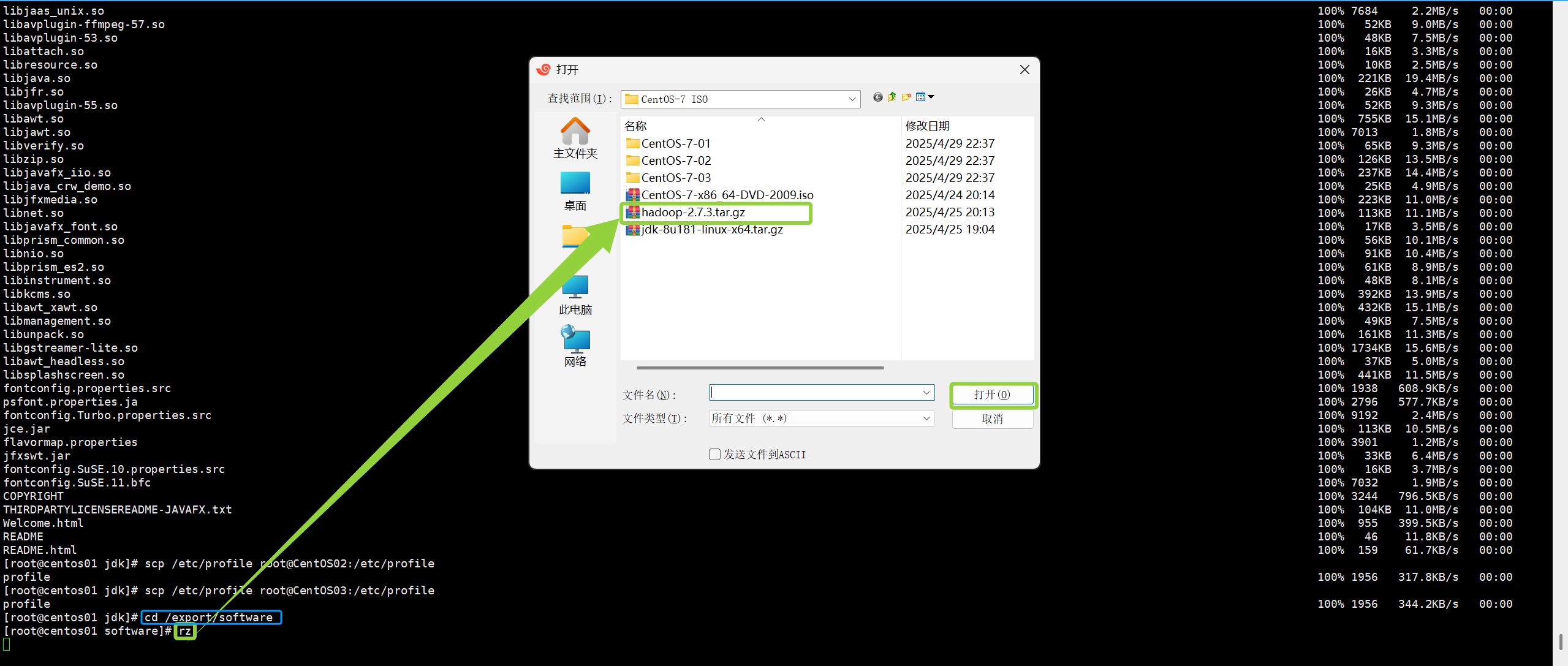
如图如果传入失败那就多传几遍
解压安装包
tar -zxvf +Hadoop安装包名 -C /export/servers
切换目录
cd /export/servers
重命名Hadoop
mv +Hadoop解压缩后的文件夹名 它的新名字
二.配置Hadoop环境变量
命令:
vi /etc/profile添加以下内容
export HADOOP_HOME=/export/servers/hadoop
export PATH=:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH如图所示,“i”键添加好内容以后,“Shift+:”组合键 然后输入"wq",保存并退出
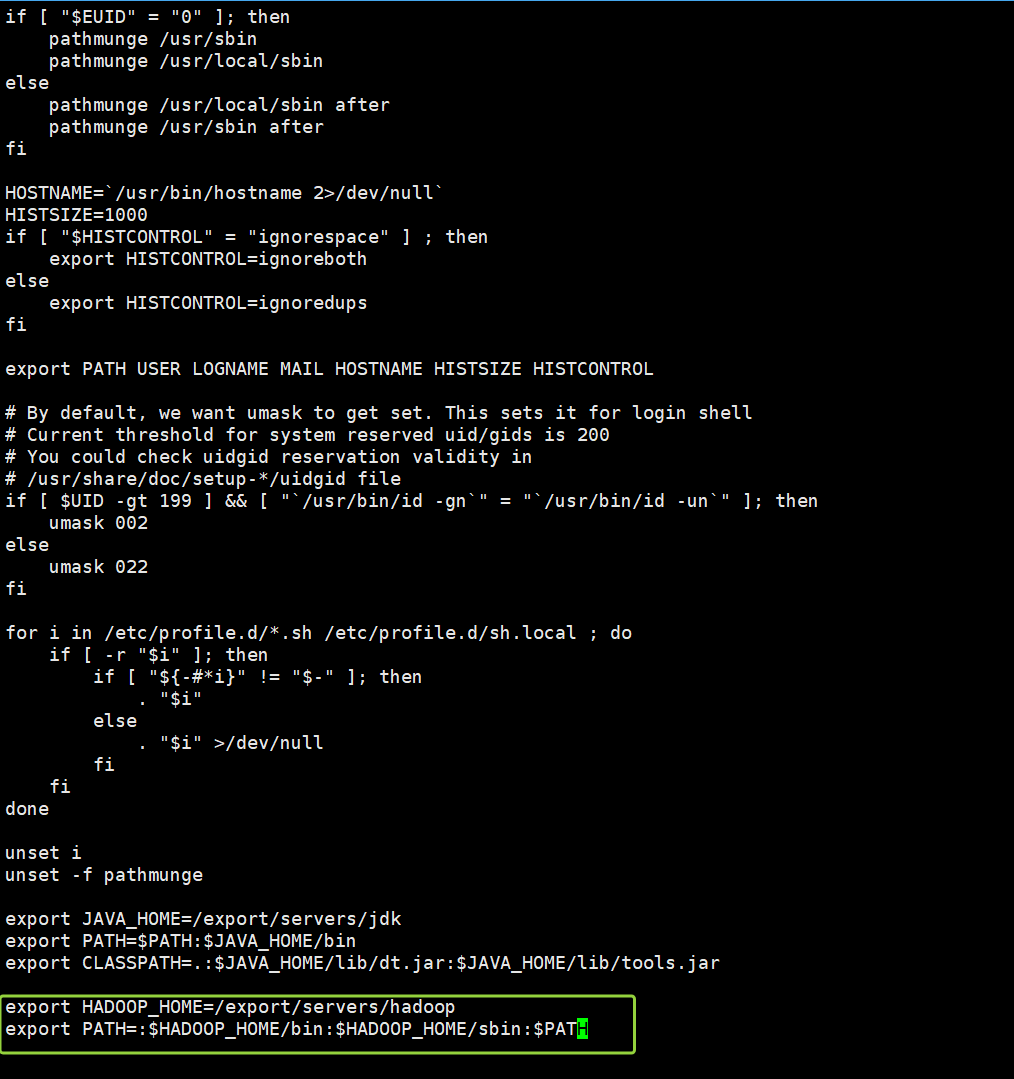

重新加载:
source /etc/profile验证Hadoop:
hadoop version如图就是成功了

三.Hadoop集群主要文件配置
切换到相应目录
cd /export/servers/hadoop/etc/hadoop1.打开并修改 hadoop-env.sh文件
vi hadoop-env.sh'''
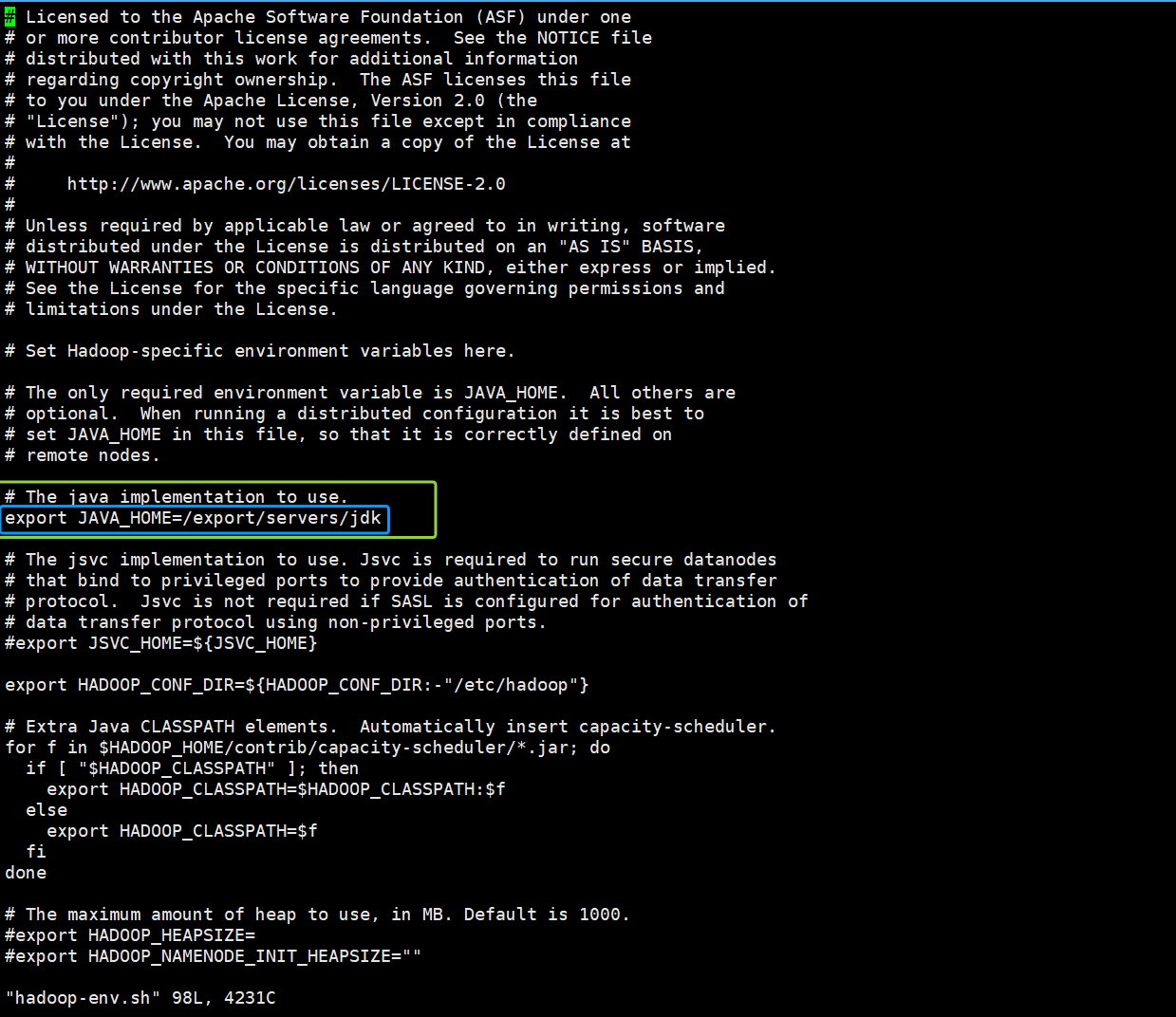
# The java implementation to use.
export JAVA_HOME=${JAVA_HOME}
'''
把# The java implementation to use.下的export JAVA_HOME=${JAVA_HOME},修改为以下内容
export JAVA_HOME=/export/servers/jdk如图所示,“i”键添加好内容以后,“Shift+:”组合键 然后输入"wq",保存并退出

2.修改core-site.xml文件
vi core-site.xml在<configuration></configuration>标签里添加以下内容
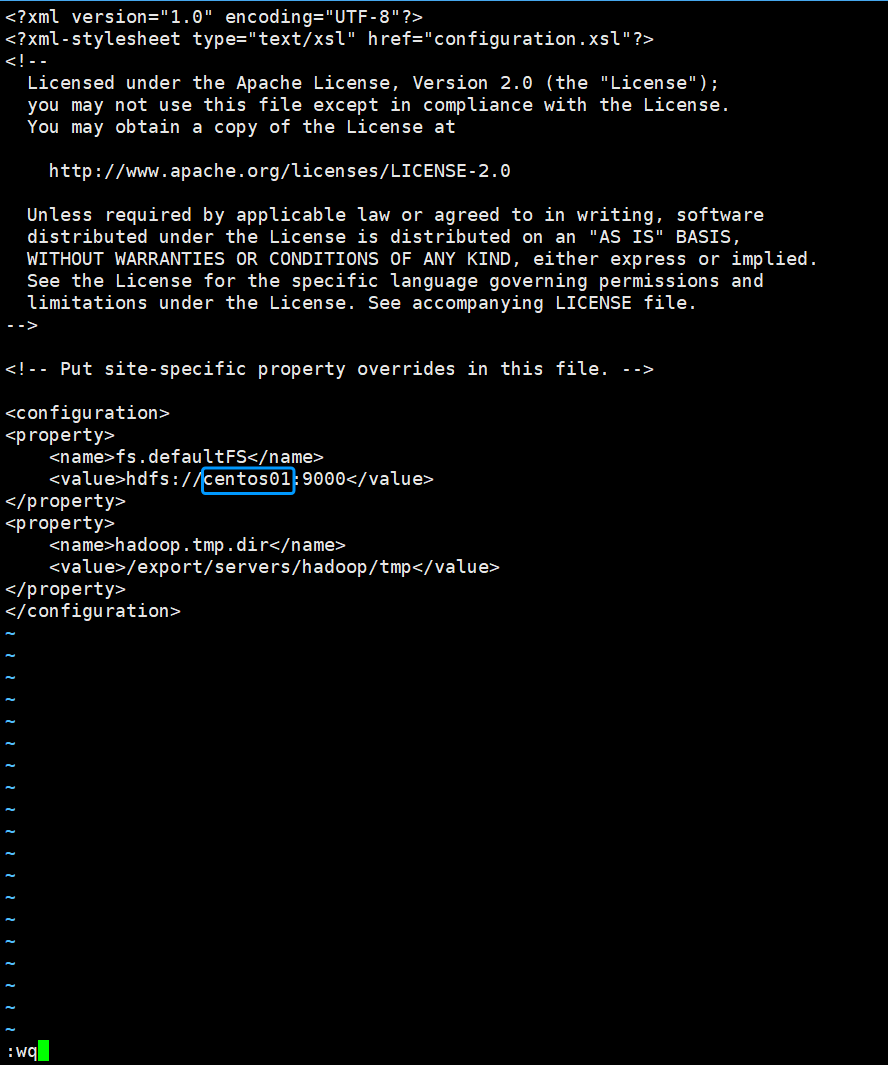
<property>
<name>fs.defaultFS</name>
<value>hdfs://写主机名:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/export/servers/hadoop/tmp</value>
</property>如图所示,“i”键添加好内容以后,“Shift+:”组合键 然后输入"wq",保存并退出
第六步

一.修改hdfs-site.xml文件
vi hdfs-site.xml在<configuration></configuration>标签里添加以下内容
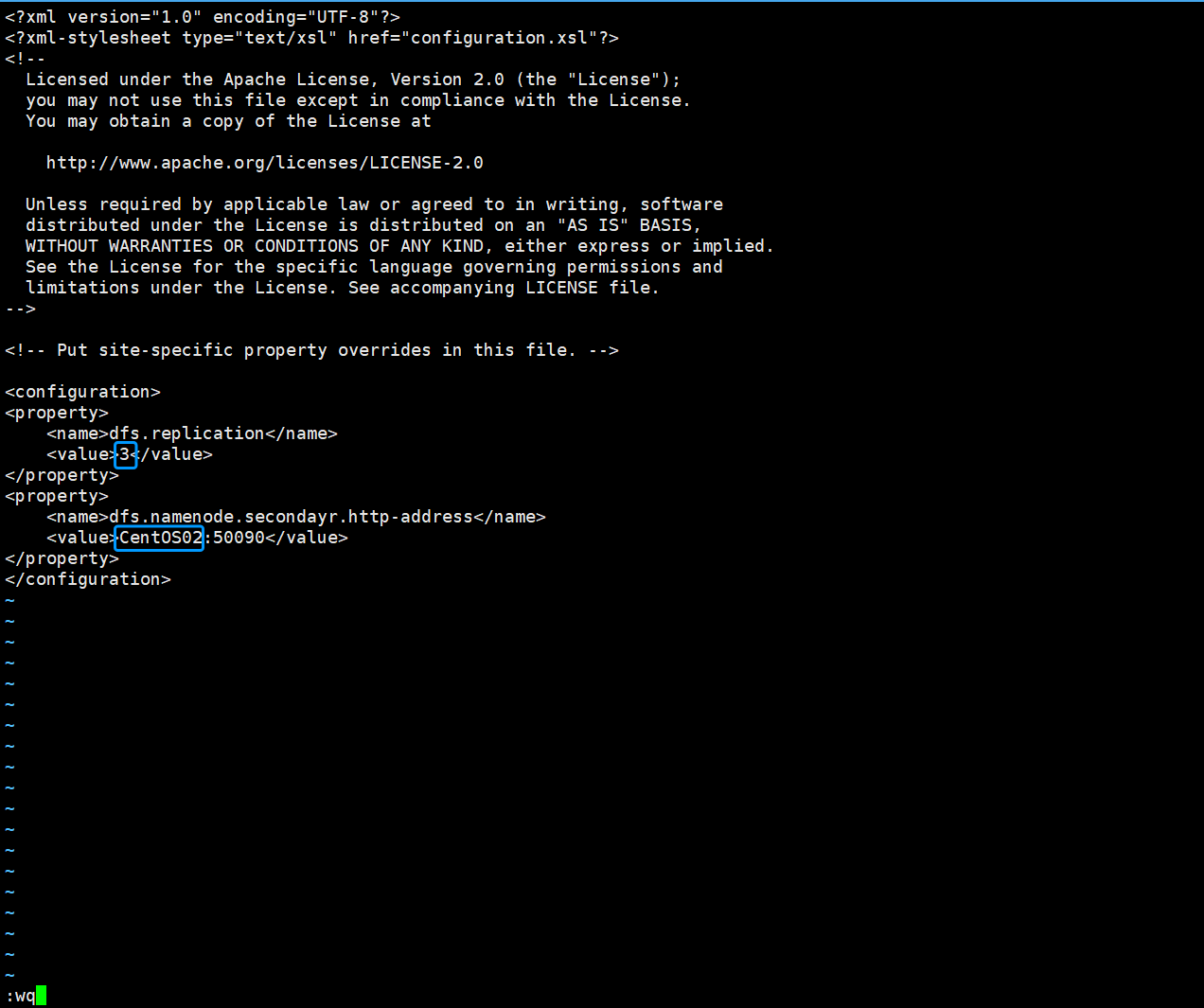
<property>
<name>dfs.replication</name>
<value>写虚拟机数量</value>
</property>
<property>
<name>dfs.namenode.secondayr.http-address</name>
<value>写第二台虚拟机名:50090</value>
</property>如图所示,“i”键添加好内容以后,“Shift+:”组合键 然后输入"wq",保存并退出
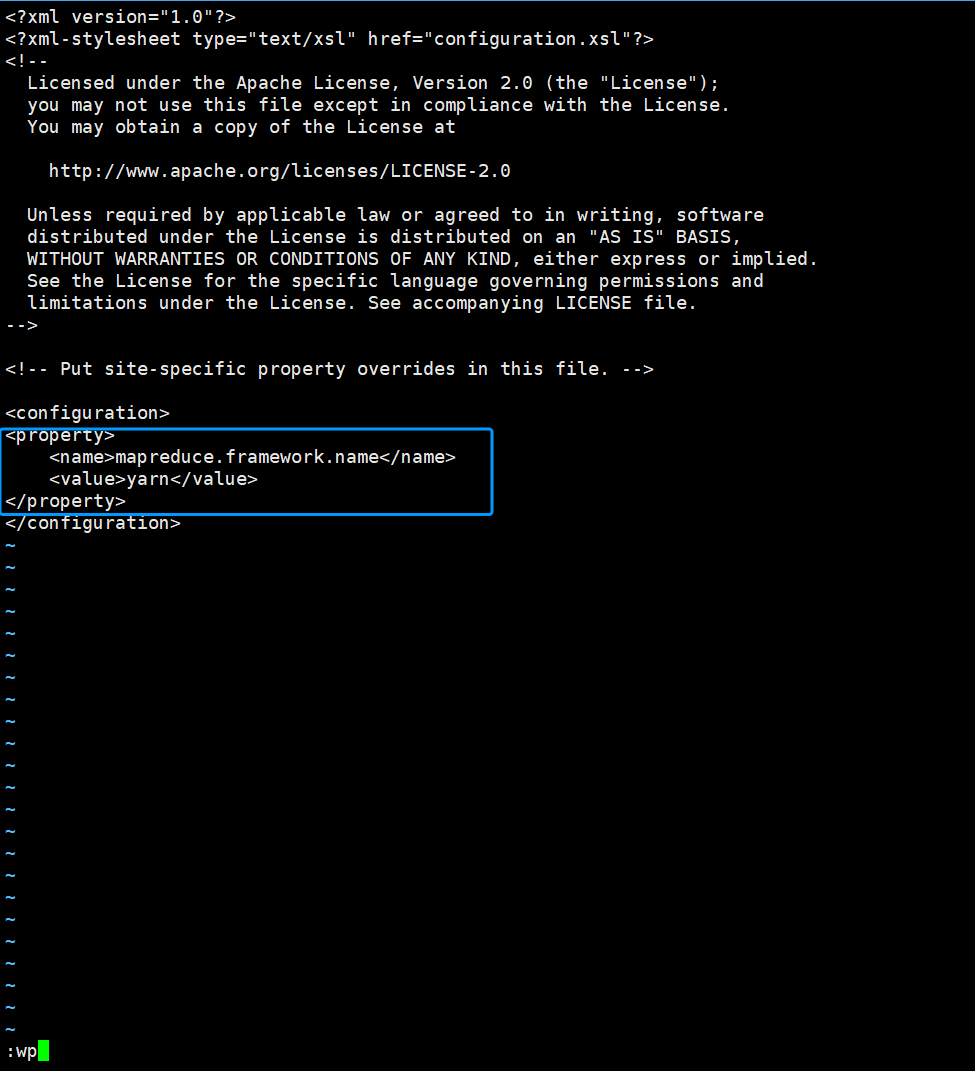
二.修改mapred-site.xml文件
这里需先拷贝一下mapred-site.xml.template文件并命名为mapred-site.xml
cp mapred-site.xml.template mapred-site.xml进入内容
vi mapred-site.xml在<configuration></configuration>标签里添加以下内容
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
如图所示,“i”键添加好内容以后,“Shift+:”组合键 然后输入"wq",保存并退出
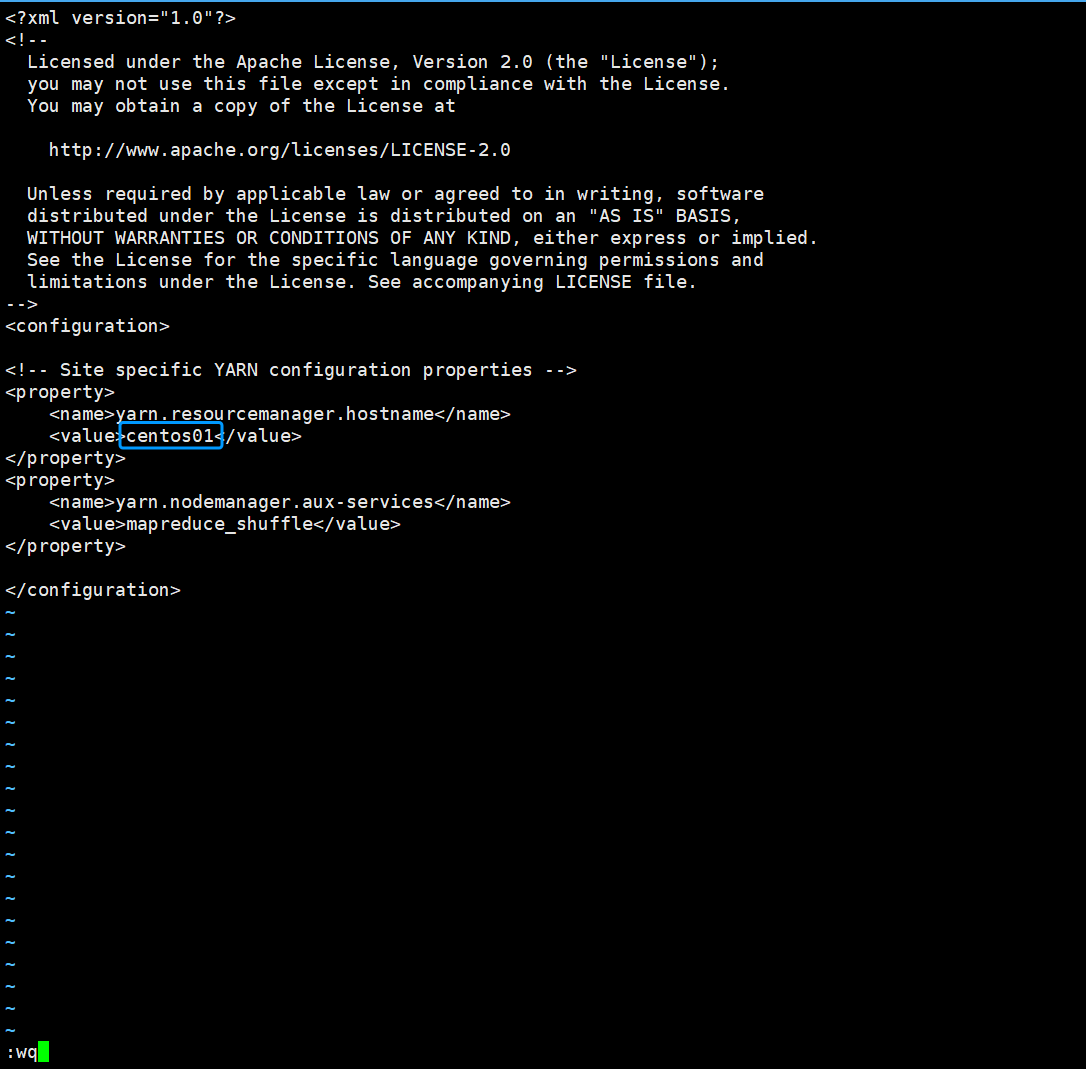
三.修改yarn-site.xml文件
vi yarn-site.xml在<configuration></configuration>标签里添加以下内容
<property>
<name>yarn.resourcemanager.hostname</name>
<value>写主机名</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>如图所示,“i”键添加好内容以后,“Shift+:”组合键 然后输入"wq",保存并退出
三.修改slaves
vi slaves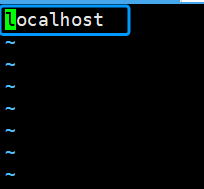
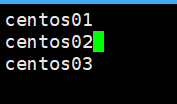
把“localhost”替换为以下内容
主机名1
主机名2
......如图所示,“i”键添加好内容以后,“Shift+:”组合键 然后输入"wq",保存并退出

第七步

一.配置环境变量的分发
scp /etc/profile 虚拟机名:/etc/profilescp -r /export/ 虚拟机名:/



二.重新加载环境变量(主机以外的)
source /etc/profile三.给节点格式化(主机上操作)
hdfs namenode -format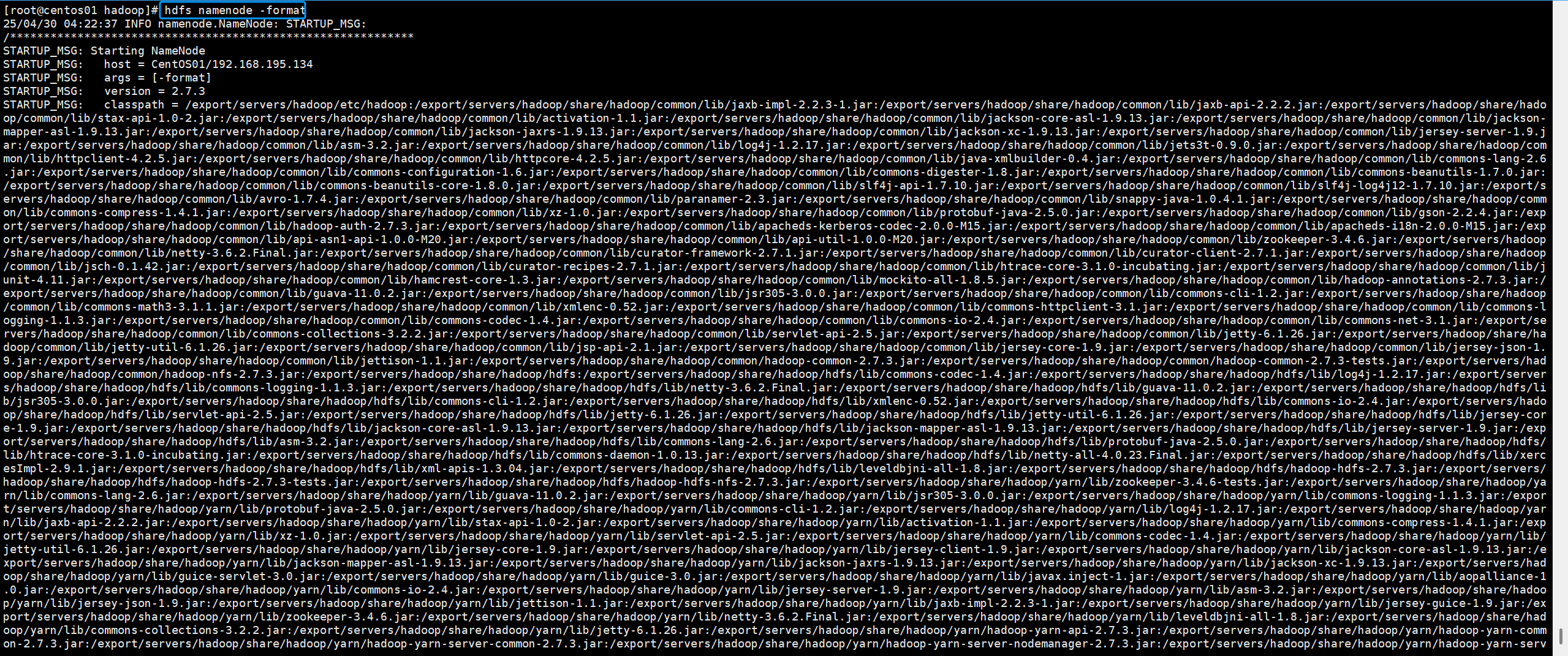
四.关闭防火墙
如果在关闭防火墙时需要权限则输入这个命令
chmod 777 /export/servers/jdk/bin/jds所有虚拟机都要关
systemctl stop firewalld
关闭防火墙开机自启动(所有虚拟机都要关)
systemctl disable firewalld
其余几台同等操作
五.启动
1.启动所有YARN服务进程(主机上操作)
start-yarn.sh
2.启动整个Hadoop进程(主机上操作)
start-all.sh六.关闭
1.关闭所有YARN服务进程(主机上操作)
stop-yarn.sh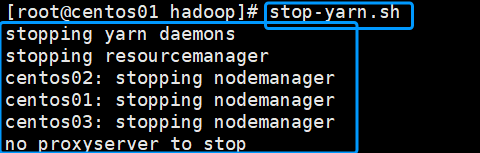
2.关闭整个Hadoop进程(主机上操作)
stop-all.sh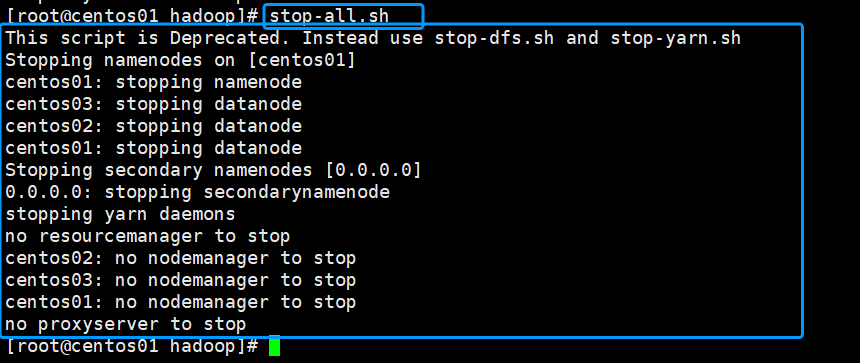
第八步
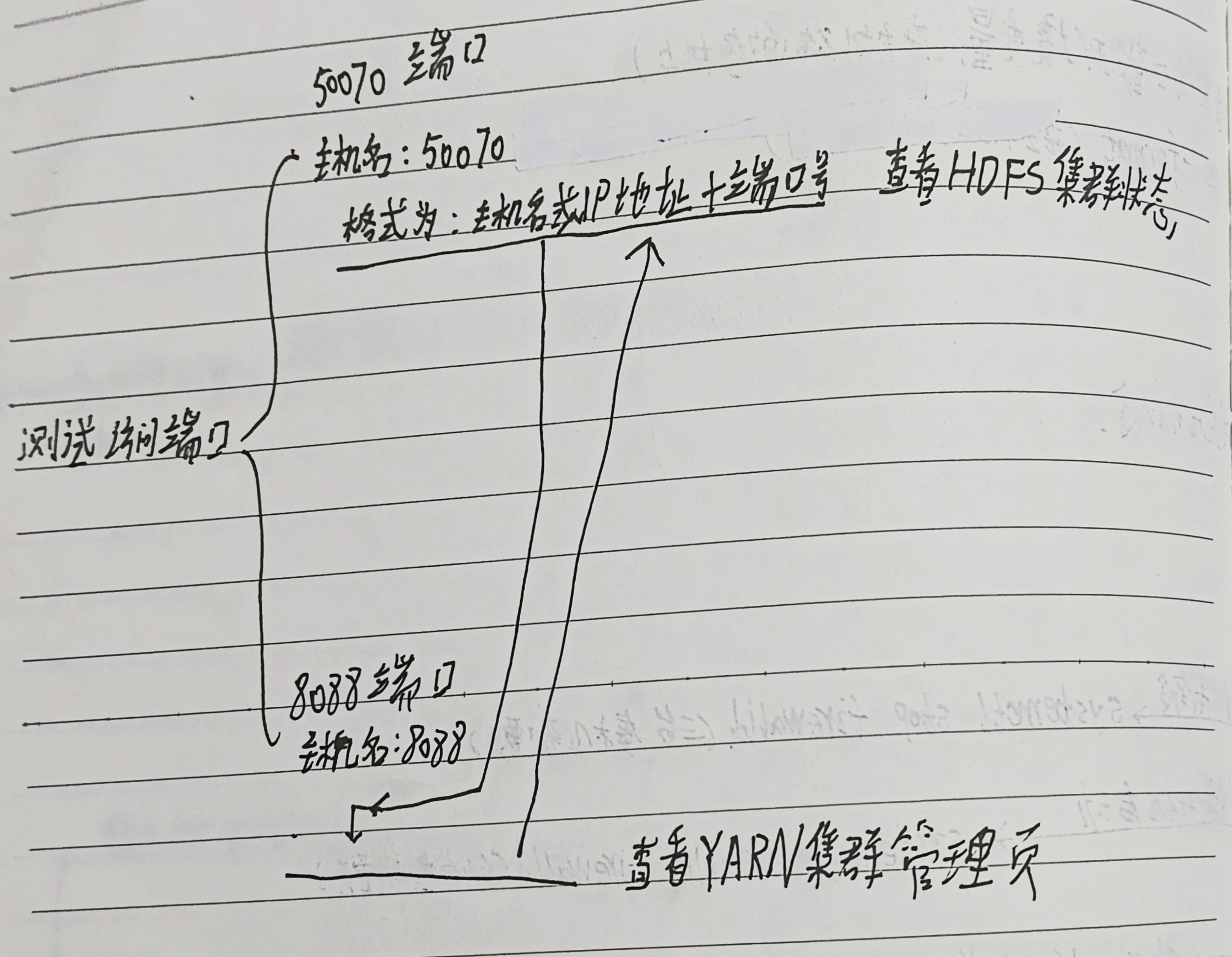
测试访问端口(浏览器)
主机名或IP地址+端口号 查看HDFS集群状态
主机名或IP地址:+50070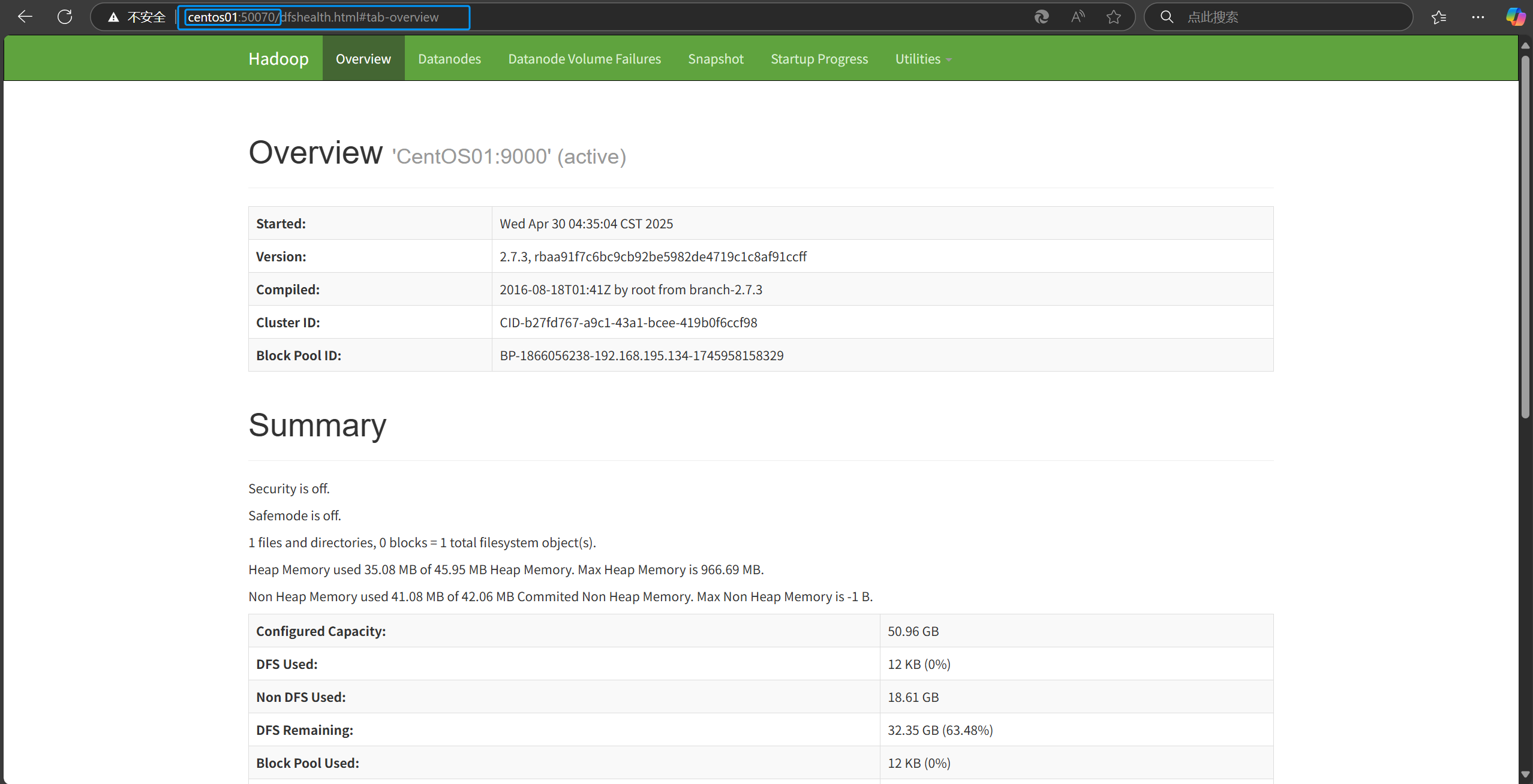
主机名或IP地址+端口号 查看YARN集群管理页
主机名或IP地址:+8088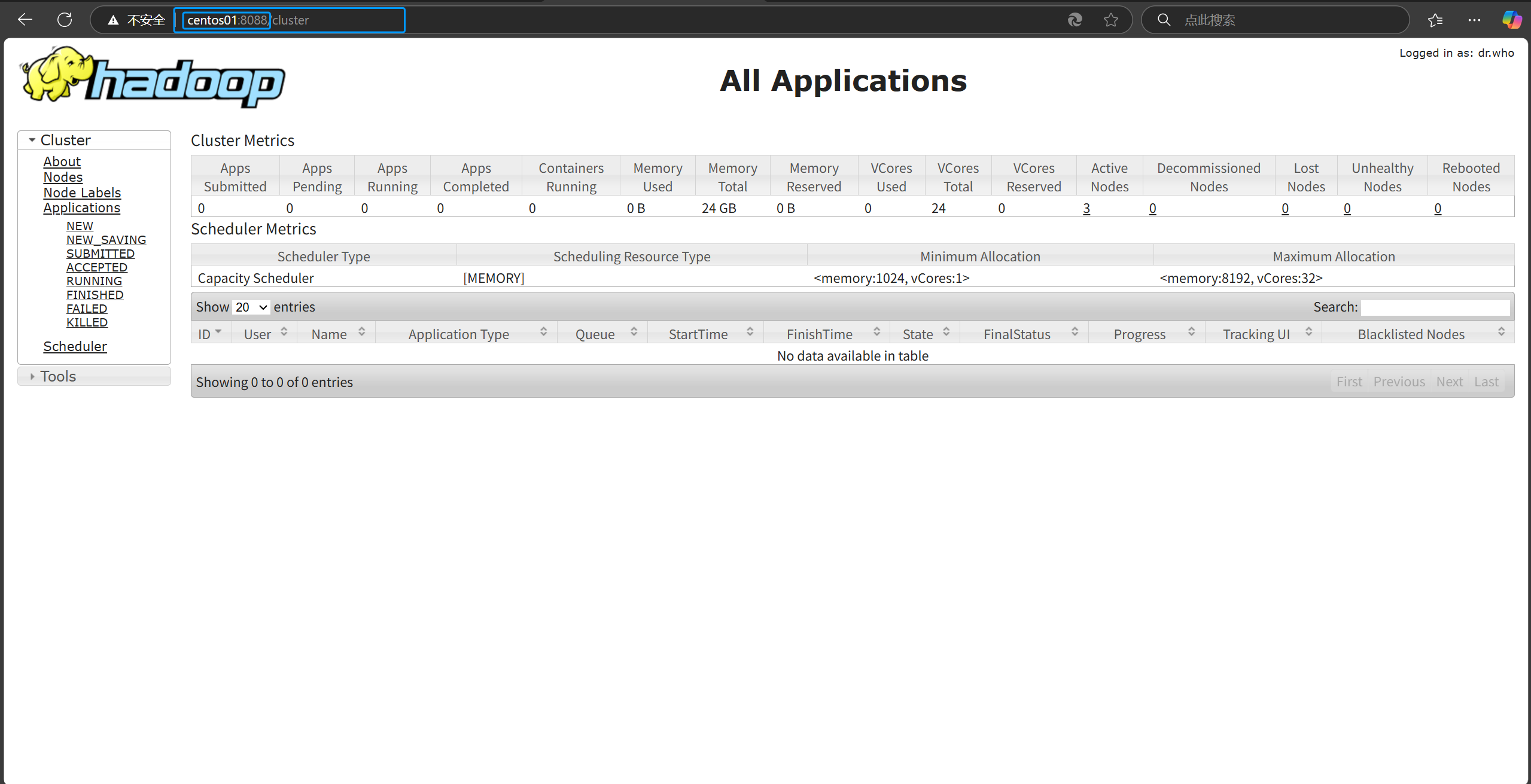
大数据环境搭建完成!!!

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









