







| 论文名称 | 发表时间 | 发表期刊 | 期刊等级 | 研究单位 |
| LibvDiff: Library Version Difference Guided OSS Version Identification in Binaries | 2024年 | ICSE | CCF A | 中科院信工所 |
1. 引言
1.1 研究背景
开源软件(OSS)已被广泛采用来加速软件开发。Forrester 的调查报告显示,从 2015年的 36% 上升到 2020 年的 75%,OSS 的平均复用率有了明显增长。此外,Gartner 的研究表明,超过 90% 的商业软件都集成了 OSS。OSS 的广泛复用也使下游软件面临潜在风险。例如,OpenSSL 中的 Heartbleed 漏洞曾使数百万网站和服务器遭受风险,glibc 中的 Ghost 漏洞已经影响了广泛的 Linux 系统。OSS的漏洞通常隐藏在特定的版本范围内,并在某个版本之后进行修补。识别软件中OSS的版本一方面可以缓解由OSS引入的同源漏洞,另一方面可以在新漏洞发布时通过漏洞影响范围关联及时发出警报。开源软件广泛使用,OSS版本识别问题亟待解决
1.2 现存问题
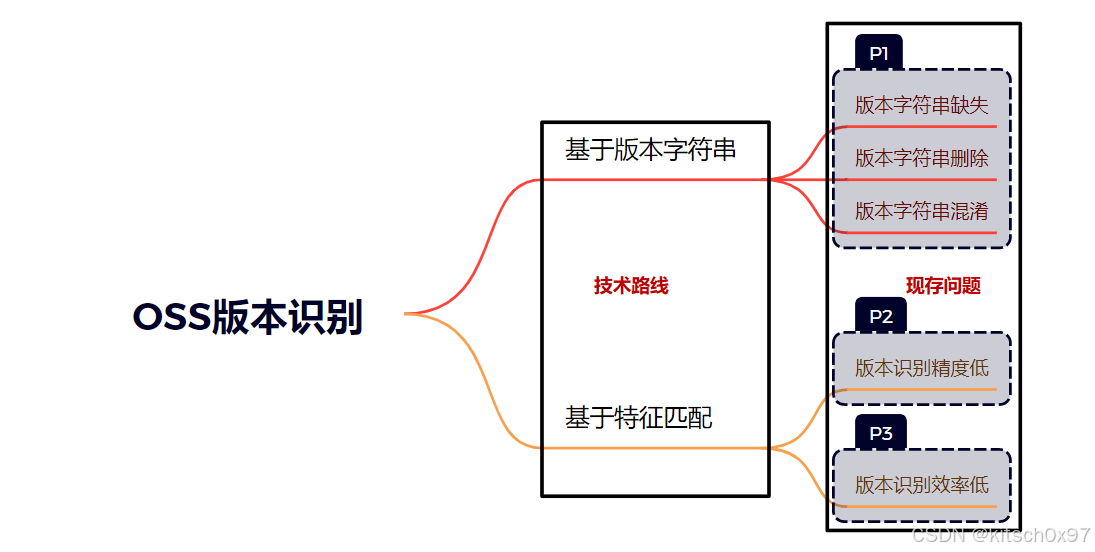
目前OSS版本识别的研究大致可以分为基于版本字符串的版本识别于基于特征匹配的版本识别:
基于版本字符串的版本识别:通过检测 OSS 版本相关的字符串来识别 OSS 版本。然而,在某些情况下版本字符串特征并不可靠(P1)。具体来说,引起不稳定的原因包括:存在不包含版本字符串的OSS;OSS版本字符串可能被开发人员删除或在编译过程丢失;存在与真实版本字符串类似的混淆字符串。版本字符串缺失、版本字符串删除、版本字符串混淆
基于特征匹配的版本识别:通过从源代码或二进制文件中提取不同类型的特征作为签名,并根据匹配特征数量生成的匹配分数来识别 OSS 版本。这类方法一定程度上解决了基于字符串方法存在的问题,但仍存在版本识别精度(P2)和版本识别效率(P3)上的问题。具体来说,引起这些问题的原因包括:OSS版本之间的代码差异可能是函数级的,且函数在编译过程中函数名称被隐藏;OSS规模较大,随着候选版本数量和目标二进制文件数量的增加,版本识别所需的时间将显著增加。版本识别精度问题、版本识别效率问题
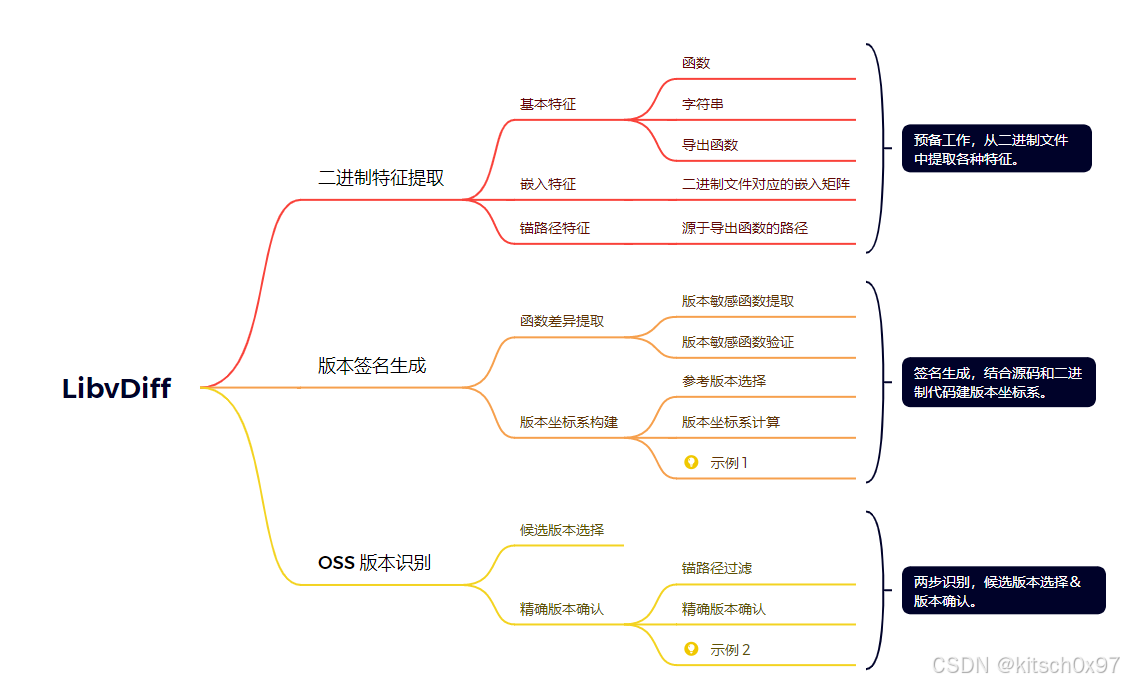
1.3 研究内容
论文提出一种基于库版本差异的OSS版本识别技术LibvDiff,可以实现OSS版本高效、准确的识别。具体来说,LibvDiff主要包括敏感特征生成模块、候选版本生成模块、候选函数生成模块以及版本识别模块。
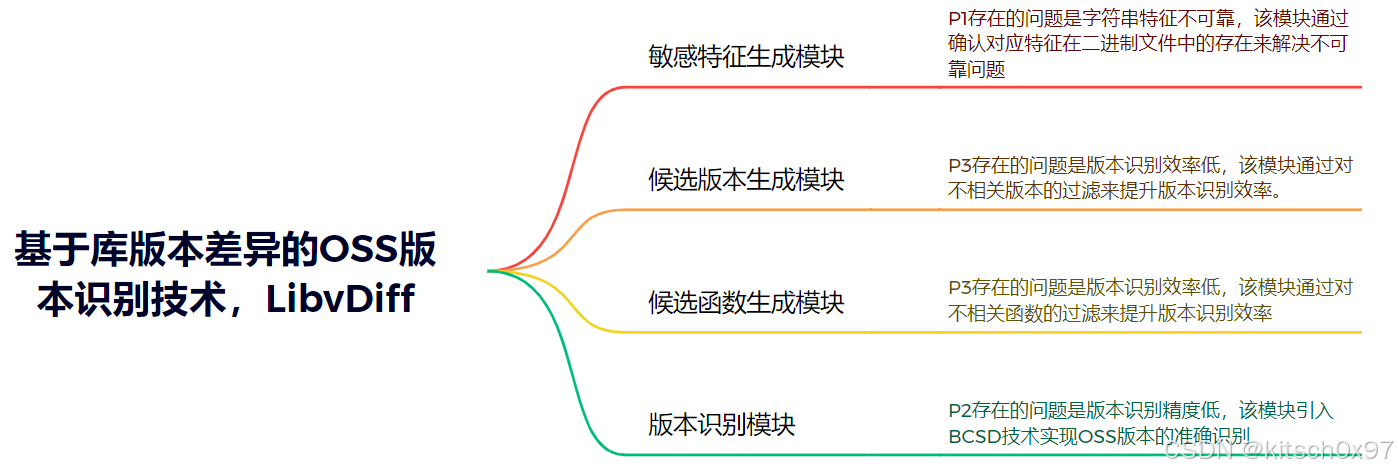
在敏感特征生成模块中,LibvDiff首先比较不同版本的源代码来提取函数和字符串的变化,之后确认它们在已编译的二进制文件中的存在,最后实现版本敏感的特征的生成。P1存在的问题是字符串特征不可靠,该模块通过确认对应特征在二进制文件中的存在来解决不可靠问题
在候选版本生成模块中,LibvDiff引入候选版本过滤器(CVF),该过滤器基于专门设计的版本坐标系(将版本之间的差异映射到二维平面来量化版本之间的差异)和基本特征(导出函数名称与字符串)实现不相关版本的高效过滤。P3存在的问题是版本识别效率低,该模块通过对不相关版本的过滤来提升版本识别效率。在候选函数生成模块中,LibvDiff引入锚路径过滤器(APF),该过滤器利用导出函数和其他内部函数之间的调用关系来过滤目标二进制文件中的不相关函数。P3存在的问题是版本识别效率低,该模块通过对不相关函数的过滤来提升版本识别效率
在版本识别模块中,LibvDiff采样BCSD技术来检索二进制文件中函数,并将其与候选版本中的函数进行比较,以确定OSS的版本。P2存在的问题是版本识别精度低,该模块引入BCSD技术实现OSS版本的准确识别
1.4 实验结果
论文进行了广泛的交叉编译实验,旨在展示 LibvDiff 的可扩展性。研究团队从特定编译设置中提取版本签名,并通过使用不同架构(X86、X64、ARM和PPC)以及优化级别(O0、O1、O2和O3)编译的二进制文件来识别版本。开源软件被分为两个数据集(D1 和 D2),D1 包含版本字符串,而 D2 则不包含。研究结果显示,LibvDiff 在所有编译设置中的版本识别方面表现出卓越的精度,在 D2 数据集中的准确率比第二名基线方法 B2SFinder 高出了54.6%。为验证 LibvDiff 的CVF 和 APF 的改进效果,论文进行了消融实验。结果显示,LibvDiff 的准确率分别提高了 29.5% 和25.9%,同时识别时间成本分别降低了 73.9% 和 36.9%。LibvDiff 在所有实验中表现出优秀的性能,候选版本过滤(CVF) 和 锚路径过滤(APF)对版本识别均有改进效果
团队将 LibvDiff 应用于包含 351 个不同固件映像的真实固件数据集,并对识别结果进行了全面分析。成功检测到由 286 个 CVE 引发的27,440 个漏洞,其中有 46.2% 的漏洞尽管固件镜像发布时已有补丁,但仍然影响固件。此外,他们发现开发人员在更新各种开源软件上表现出明显差异,而不同供应商可能会使用相同的开源软件二进制文件。使用 LibvDiff 对真实世界中的 OSS 进行检测
2. 研究动机
论文将两个不同版本的 FreeType 软件(VER-2-5-4 ,VER-2-5-5)作为示例,如下图所示。具体来说,这两个版本都不包含任何与版本相关的字符串,因此无法使用此类字符串来识别版本。此外,两个版本之间的字符文本或函数名称等简单特征没有明显变化。两个版本的软件仅在FT_Get _Glyph_Name 和 t42_parse_sfnts 两个函数的内容上存在差异。
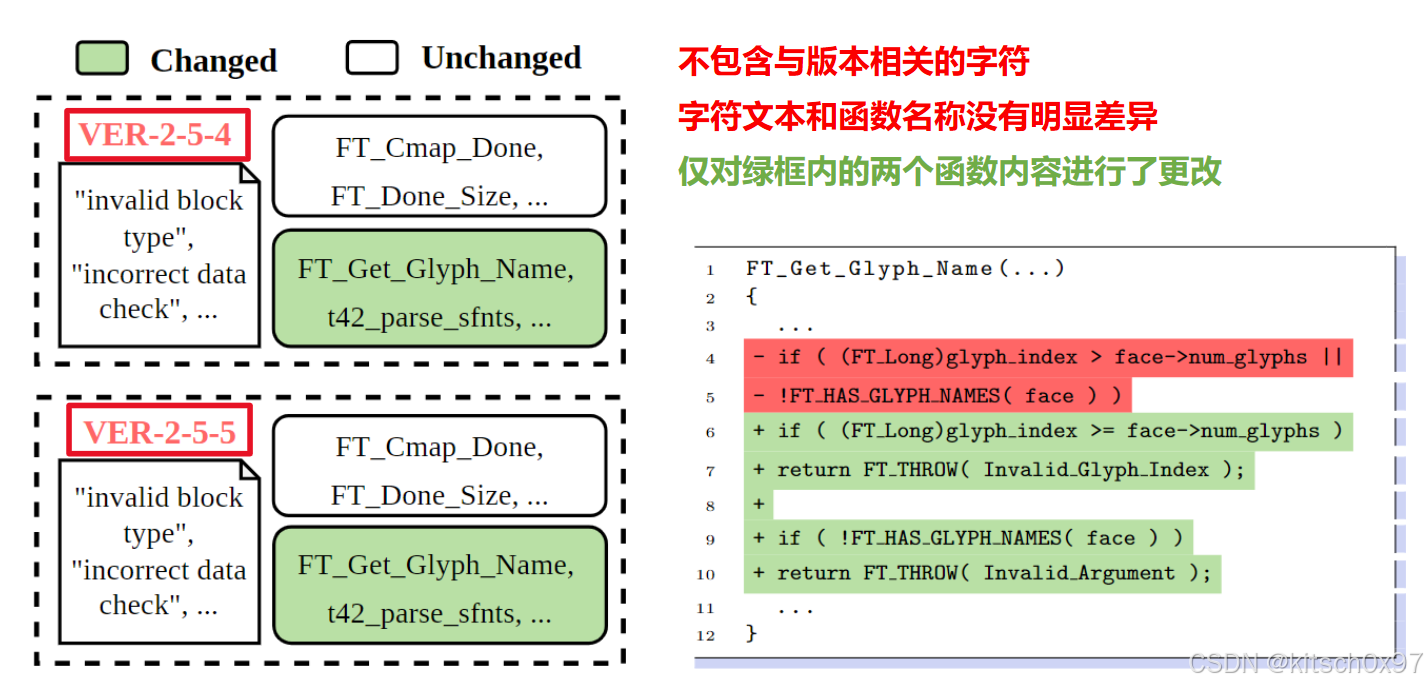
传统的 OSS 版本识别方法,即使是那些不仅考虑版本字符串还考虑动态表中的函数名称的方法,在这种情况下都无法识别软件版本。因此,需要考虑更细粒度的代码修改情况以实现 OSS 版本的准确识别。为了解决这个问题,论文通过 LibvDiff 捕获不同版本之间的差异并验证这些差异在目标二进制文件中的存在,最终区分不同版本并正确识别真实版本。
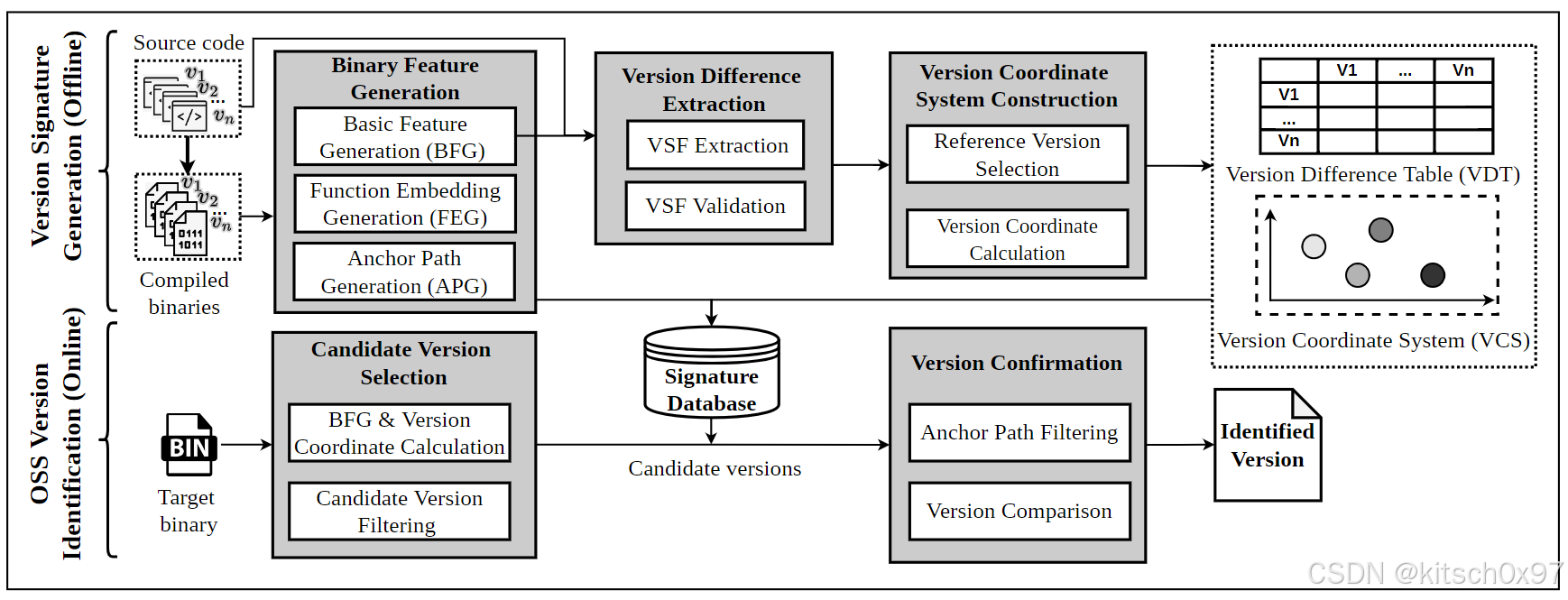
版本签名生成:LibvDiff 为提供的源代码和不同版本的编译二进制文件生成三类版本签名:二进制特征、版本敏感特征和版本坐标。二进制特征用于捕获代码更改,版本敏感特征用于记录版本之间的函数更改,版本坐标用于衡量版本之间的差距。首先,LibvDiff 从编译的二进制文件中生成必要的二进制特征。然后,对比不同版本源代码的差异,并实现版本敏感特征(VSF)的提取。最后,LibvDiff 建立一个版本坐标系,并通过将版本映射到该系统来表示版本之间的差距。
OSS 版本识别:对于给定的二进制文件,LibvDiff 通过验证版本签名的存在来识别特定 OSS 的版本。首先,LibvDiff 以与前一阶段相同的方式生成二进制文件的二进制特征和版本坐标。随后,根据版本坐标和基本特征选择与目标二进制文件接近的版本,从而获得候选版本。最终,通过使用精心设计的 RVG 算法对候选版本进行逐一比较来确认版本。
3. 版本签名生成
为了区分不同版本的开源软件,论文最初生成了三种特征,这些特征可用于轻量级过滤或提高版本识别的效率和精度。各个版本之间字符串文字和函数的变化被概括为版本差异。利用这些差异,论文构建了一个版本坐标系,其中每个开源软件版本都由唯一的坐标表示。
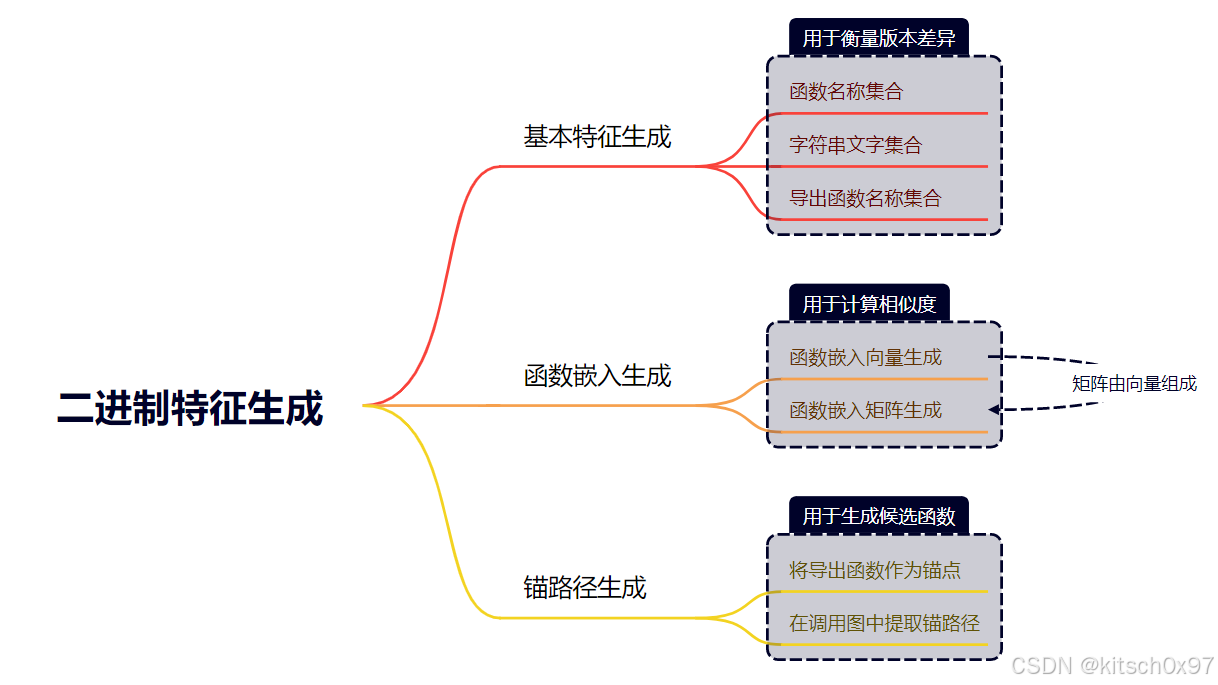
3.1 二进制特征生成(面向二进制)
为了捕获不同版本之间的代码更改,LibvDiff 直接从编译的二进制文件生成三种类型的特征:基本特征、函数嵌入特征和锚路径特征。基本特征直接从编译的二进制文件中提取
3.1.1 基本特征生成
从 𝑣𝑖 的二进制文件中提取的基本特征表示为 𝐵𝐹𝑣𝑖 = (函数名称集合,字符串文字集合,导出函数名称集合)。这些特征并非直接从源代码中提取,而是从编译后的二进制文件中获取,以确保特征在源码和二进制代码中的一致性。这是因为源代码的某些部分,比如测试和示例代码,可能未能编译进主要的二进制文件中。二进制文件 → 基本特征(三个集合)
3.1.2 函数嵌入生成
函数嵌入是由 BCSD 工具生成的函数向量表示,用于计算函数之间的相似度。 对于版本 𝑣𝑖,函数嵌入表示为 𝐹𝐸𝑣𝑖 = (ℎ1, ℎ2, ..., ℎ𝑛),其中 ℎ𝑗 代表第 𝑗 个函数的向量。论文使用 Asteria 作为 BCSD 工具来生成函数嵌入,用于计算目标二进制文件和 OSS 二进制文件之间的函数相似度。 二进制文件 → 嵌入特征(一个矩阵)
3.1.3 锚路径生成
锚路径 (AP) 是源自导出函数(Exported Function)并终止于二进制文件调用图(CG)中的任何内部函数(Internal Function)的路径。 AP 利用与导出函数关联的顺序调用关系来识别目标函数,其主要目标是通过识别相似的顺序调用关系来定位潜在的目标函数,从而有效地减少版本确认过程中函数检索的搜索空间。由于在剥离的二进制文件中导出函数与调用图具有稳定性和完整性,因此AP 可以在不同版本二进制文件之间建立粗略的函数对应关系。
在论文中,调用图(CG)被精确定义为有向图 𝐶𝐺 = (𝑉,𝐸),其中 𝑉 = {𝑓1,...,𝑓𝑛 } 表示函数节点的集合,𝐸 = {(𝑓𝑖, 𝑓𝑗 ) |𝑓𝑖 ∈ 𝑉 , 𝑓𝑗 ∈ 𝑉 } 表示函数调用边的集合。 在CG定义的基础上,锚路径边(APE)被定义为(𝑓𝑖, 𝑐, 𝑓𝑗 ), 𝑓𝑖 ∈ 𝑉 , 𝑓𝑗 ∈ 𝑉 , 𝑐 ∈ {𝑒, 𝑟 },其中 𝑐 代表调用方向,𝑒, 𝑟 分别表示被调用方向和调用方向。 例如,如果函数 𝑓𝑖 调用函数 𝑓𝑗,则从 𝑓𝑖 到 𝑓𝑗 的 APE 为 (𝑓𝑖, 𝑒, 𝑓𝑗 )(𝑓𝑗 是 𝑓𝑖 被调用函数),同理从 𝑓𝑗 到 𝑓𝑖 的 APE 是 (𝑓𝑗 , 𝑟, 𝑓𝑖 )(𝑓𝑖 是 𝑓𝑗 的调用者函数)。基于上述定义,从导出函数(锚点)出发到目标函数结束的的锚路径可表示一个 APE 序列,如下所示:
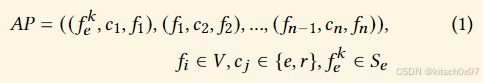
对于每个导出函数,锚路径生成算法递归遍历其被调用者和调用者,直到遇到另一个导出函数或耗尽图中的所有节点。 二进制文件 → 调用图 → 锚路径(一个序列)

3.2 函数差异提取(面向源代码)
版本差异是不同版本组件中特征变化的表示,通过分析两个特定版本之间的差异更容易从源代码中提取版本敏感特征(VSF)。基于上述考虑,LibvDiff 从源代码中提取 VSF,并根据编译的二进制文件生成的函数名称和字符串来验证它们的存在。版本敏感特征提取与验证
3.2.1 版本敏感特征提取
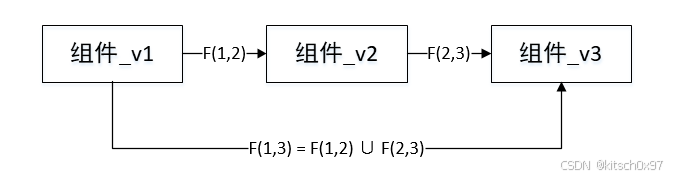
为了精确提取源代码中的 VSF,LibvDiff 通过解析两个不同版本的git diff 结果来分析 git 存储库,并将修改后的特征记录为原始 VSF。 此外,为了提高提取效率,论文只提取相邻版本之间的原始 VSF,因为 OSS 版本对的数量可能很多(例如,具有 10 个版本的 OSS 可能有45个版本对)。 对于非相邻版本,论文通过取其中所有相邻版本的原始 VSF 并集来构造它们的原始 VSF。
论文将两个不同版本组件间的 VSF 表示为 F =(版本敏感函数,版本敏感字符串)= ({𝑓1, 𝑓2, ..., 𝑓𝑚 }, {𝑠1, 𝑠 2、. ..,𝑠𝑛})。 通过git diff 从源码中提取版本敏感特征
# 下载并进入minizip项目
git clone https://github.com/zlib-ng/minizip-ng.git
cd minizip-ng
# 获取版本信息
git tag
# 提取版本差异
git diff v1.0.1beta v1.2.0beta
3.2.2 版本敏感特征验证
通过二进制特征中的基本特征验证(函数名称,字符串)在二进制代码层面确定版本敏感特征(版本敏感函数名称,版本敏感字符串)是否存在,并将版本 𝑣𝑖 和 𝑣𝑗 之间的版本差异表示为 𝑉𝐷 = (函数增加集合,函数删除集合,函数更新集合,字符串增加集合,字符串删除集合) ,如下式所示:
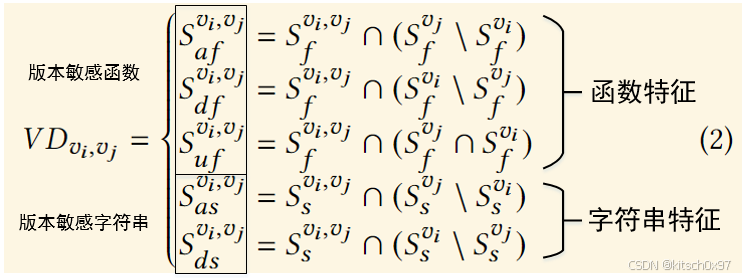
3.3 版本坐标系构建
为了缩小目标二进制文件可能的版本范围并提高版本识别的效率,论文引入了版本坐标系(VCS)来量化所有版本之间的位置关系。 VCS 由一个参考版本和所有版本的版本坐标组成。 所有版本和参考版本之间的差异反映在它们在 VCS 中的坐标位置上。 对于目标二进制文件,论文可以通过将其映射到 VCS 并排除太远的版本来快速定位相似的版本。
3.3.1 参考版本选择
参考版本被用于提供版本差异和构建版本轴。最初,版本按其发布日期排序,然后选择包含足够版本敏感特征(VSF)以便后续检测其他版本中修改特征的两个版本。为了方便起见,选择最旧版本 𝑣𝑜 和最新版本 𝑣𝑛 作为参考版本。选择最旧与最新版本作为参考版本
3.3.2 版本坐标计算
在VCS中,每个版本的版本坐标是一个元组,其中的值表示目标二进制文件和两个参考版本之间的差距。 为了提高效率,仅使用导出的函数名称作为计算版本坐标的特征,因为它们是稳定的并且将保留在二进制文件中。 𝑣𝑖 相对于参考版本 𝑣𝑜 和 𝑣𝑛 的版本坐标可以计算如下:

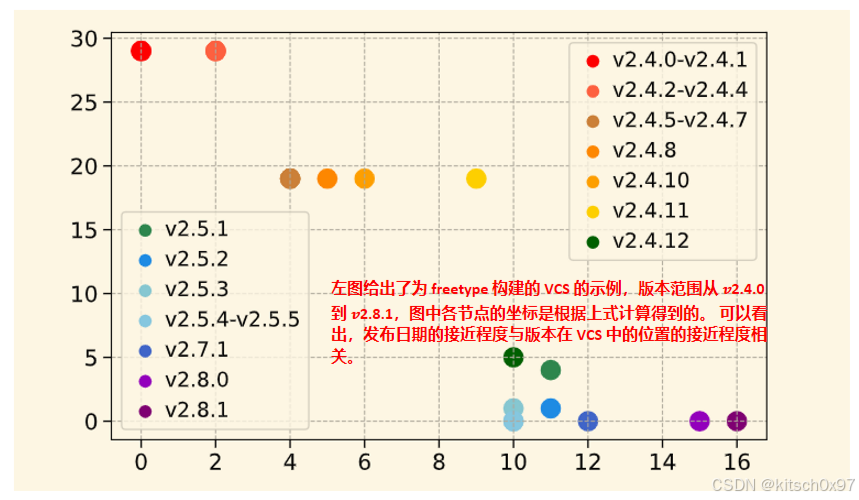
3.3.3 版本坐标示例
4. OSS 版本识别
OSS 版本识别的目标是确定目标二进制文件 𝐵 使用的版本。 为了提高效率,论文通过定位目标二进制文件在版本坐标系(VCS)中的位置来过滤掉大量版本,而不是直接与 𝐵 进行比较。 随后,剩余版本被视为候选版本,并与 𝐵 进行比较以确定最终的识别版本。
4.1 候选版本选择
首先生成目标文件的基本特征(导出的函数名称和字符串文字),之后目标文件的版本坐标(表示为 𝑉𝐶𝐵 = (𝑋𝐵, 𝑌𝐵))。为了缩小版本范围,论文提出了一种候选版本过滤器(CVF),它通过两个步骤过滤候选版本。 首先,对于版本 𝑉𝐶𝑣𝑖 = (𝑋𝑖, 𝑌𝑖 ) 的版本,当 𝑉𝐶𝑣𝑖 满足条件时保留:
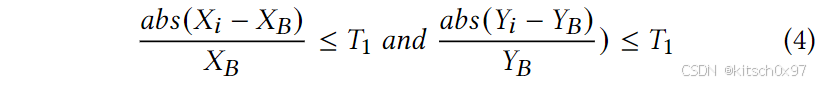
其中 𝑇1 表示相似版本定位的阈值。 换句话说,任何足够接近 𝐵 的版本都将被保留为潜在候选版本。 其次,论文通过版本比较,进一步筛选版本差异中新增和删除基本功能的版本。 如果两个版本无法通过添加和删除的基本功能直接区分,则两个版本都将保留为候选版本。 否则,匹配较少功能的版本将被过滤掉。生成候选版本
4.2 版本确认
论文进一步将候选版本与目标二进制文件 𝐵 进行比较,以根据 CVF 过滤后的候选版本精确识别 OSS 版本。 版本确认的核心思想是目标二进制文件使用的版本比其他版本能够匹配更多的签名。 它有两个阶段:锚路径过滤和版本比较。
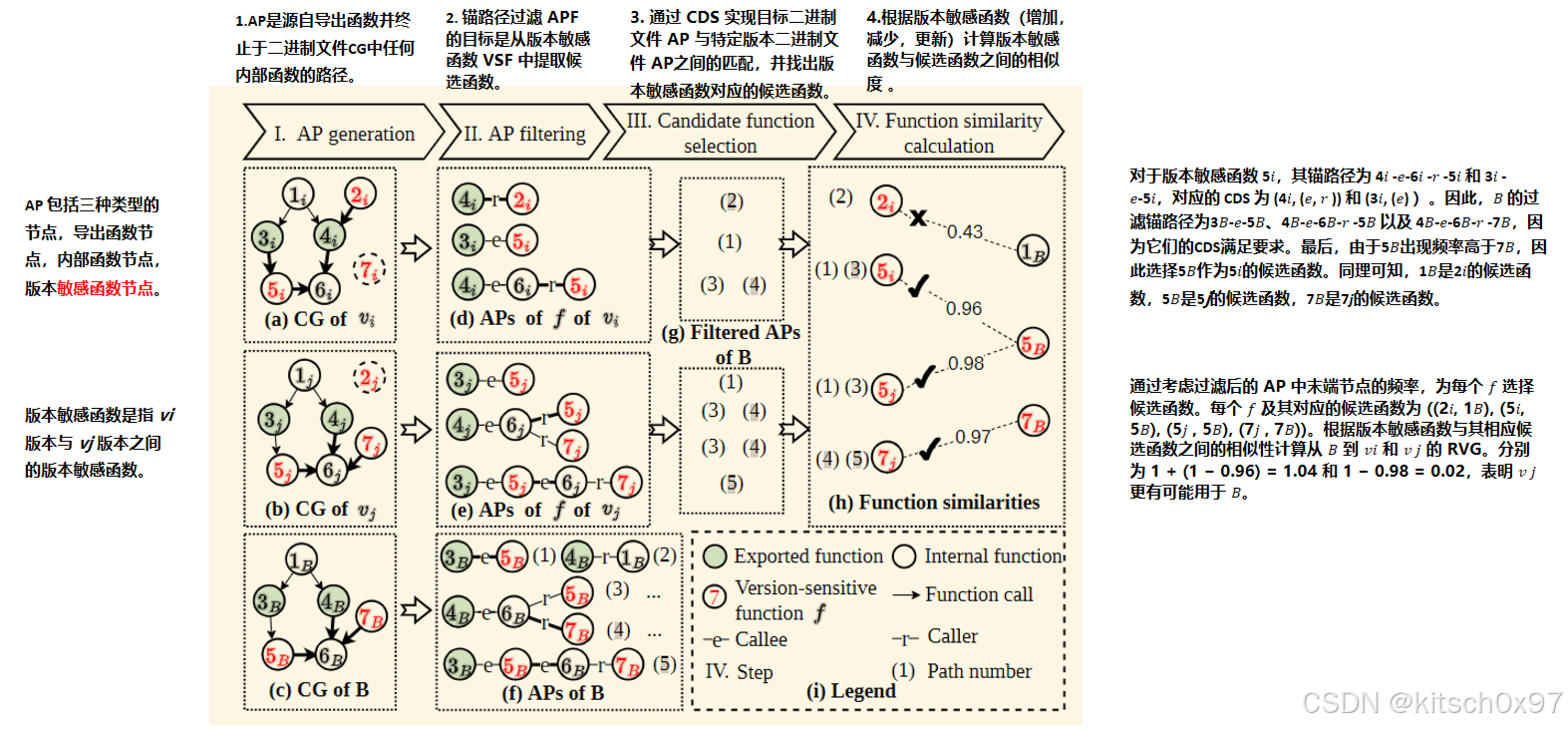
4.2.1 锚路径过滤
锚路径过滤器(APF)可以从版本敏感函数中提取候选函数,其核心思想是同源函数具有相同的锚路径(目标函数->候选函数)。 由于内部函数名称在剥离的二进制文件中丢失,论文进一步引入调用方向序列(CDS)的概念来表示目标二进制文件中的函数。 CDS 忽略特定函数的名称,并包括导出的函数以及等式 (1) 中定义的 AP 内的所有调用方向。它的定义如下:
![]()
在 CDS 的帮助下,论文可以从导出的函数开始,按照调用方向找到 AP 末尾的目标函数 𝑓(通过CDS实现目标函数的表示)。 需要注意的是,一个函数可能具有从不同的导出函数开始的多个 AP。 具体来说,首先生成目标二进制文件的所有 AP。之后基于 AP 与 CDS 生成两个集合 𝑆𝐴𝑃 = {𝐴𝑃1, 𝐴𝑃2, ..., 𝐴𝑃𝑛 } 和 𝑆𝐶𝐷𝑆 = {𝐶𝐷𝑆1, 𝐶𝐷𝑆2,...,𝐶𝐷𝑆𝑛 }。 然后,CDS 与 AP 不匹配的 AP将被过滤掉。 最终,论文统计过滤后 AP 的末端节点的数量,并选择使用频率最高的节点作为 𝑓 的候选函数(目标函数->候选函数)。
频繁调用的末端节点:通常是核心功能或关键模块,反映了程序的整体控制流和关键路径。选择这些高频末端节点作为候选函数 𝑓,可以确保所选函数在程序的实际运行中有较高的代表性,有助于准确反映程序的行为特征,提高错误引导路径识别的有效性和准确性。
4.2.2 版本比较
论文采用参考版本差距 (RVG) 的概念来量化两个提供的候选版本 𝑣𝑖 和 𝑣𝑗 相对于目标二进制文件 𝐵 的版本差异。 考虑到 𝑣𝑖 和 𝑣𝑗 之间的版本差异,论文使用 RVG 算法来估计从 𝐵 到 𝑣𝑖 和 𝑣𝑗 的 RVG。 该算法的基本原理是检测 𝐵 中添加和删除的函数,并评估 𝐵 与提供的候选版本 𝑣𝑖 和 𝑣𝑗 之间更新函数的相似度。 具体来说,论文基于 4.2.2 中 𝑉𝐷 ,论文尝试检索 𝐵 中添加和删除的函数(第 2 到 10 行),并计算两个版本中更新函数的差距(第 11 到 18 行)。
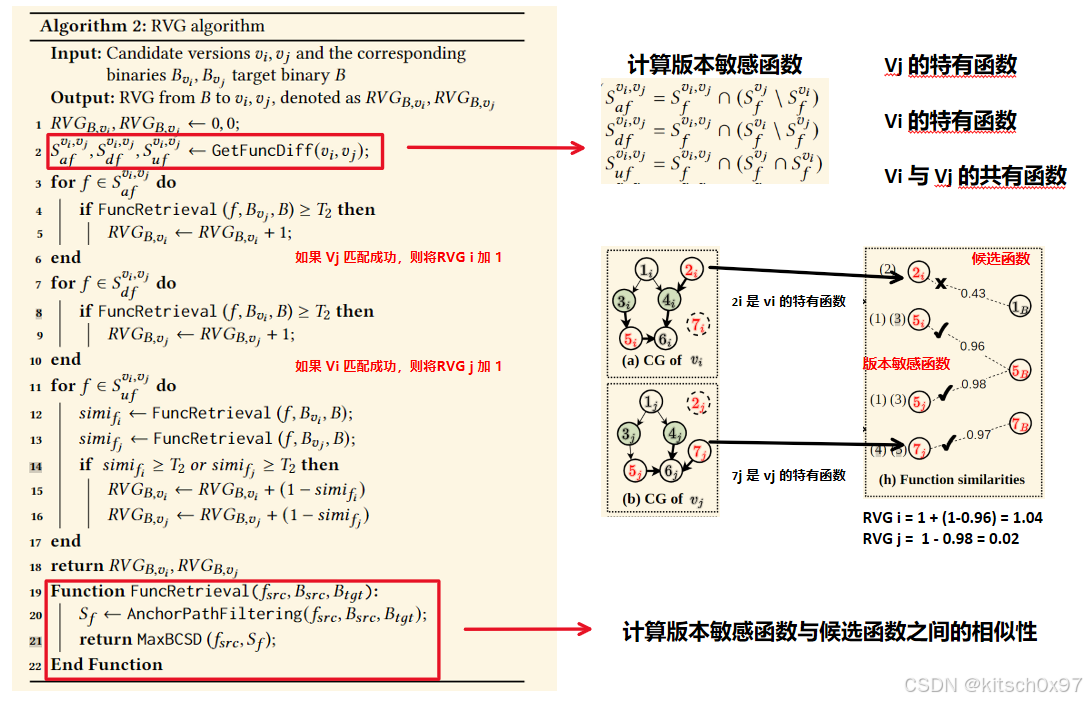
4.2.3 版本识别示例



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









