







 本文提出了一种新的勒索软件检测方法,采用静态分析,通过Frequent Pattern Mining从原始字节中提取特征,使用 Gain Ratio 进行特征选择,确定1000个特征为最优。利用随机森林分类器,在树数为100、种子数为1时,实现了97.74%的检测准确率。相较于动态分析,此方法减少了处理时间和复杂性,但样本预处理中特征选取的限制和特征选择方法的优化是未来研究方向。
本文提出了一种新的勒索软件检测方法,采用静态分析,通过Frequent Pattern Mining从原始字节中提取特征,使用 Gain Ratio 进行特征选择,确定1000个特征为最优。利用随机森林分类器,在树数为100、种子数为1时,实现了97.74%的检测准确率。相较于动态分析,此方法减少了处理时间和复杂性,但样本预处理中特征选取的限制和特征选择方法的优化是未来研究方向。
| 论文名称 | 发表时间 | 发表期刊 | 期刊等级 | 研究单位 |
| Ransomware Detection using Random Forest Technique | 2020年 | ICT Express | SCI 3区 | 纳赫林大学信息工程学院 |
0. 概述
如今,勒索软件已成为计算世界的严重威胁,需要立即考虑以避免经济和道德勒索。因此,确实需要一种能够检测和阻止此类攻击的新方法。以往的检测方法大多采用动态分析技术,过程复杂。本研究提出了一种基于静态分析的勒索软件检测新方法。该方法的显着特点是通过使用Frequent Pattern Mining直接从原始字节中提取特征来省去反汇编过程,从而显着提高了检测速度。使用Gain Ratio技术进行特征选择,表明 1000 个特征是检测过程的最佳数量。当前的研究涉及使用随机森林分类器,全面分析树和种子数量对勒索软件检测的影响。结果表明,树数为 100、种子数为 1 时,在耗时和准确度方面取得了最佳结果。实验评估表明,该方法对于勒索软件的检测准确率可以达到97.74%。
1. 相关工作
勒索软件检测技术主要分为三类,分别是基于静态特征的勒索软件检测、基于动态特征的勒索软件检测、基于混合特征的勒索软件检测。
基于静态特征:Zhang等人从勒索软件中提取操作码(opcode)序列特征,并使用五种机器学习技术对勒索软件进行检测。Baldwin等人从勒索软件中提取操作码(opcode)序列特征,并使用SVM分类器对勒索软件进行分类
基于动态特征:(1)Takeuchi等人从勒索软件中提取API调用特征,并使用SVM分类器进行勒索软件检测。(2)Vinayakumar等人从勒索软件中提取API调用特征,并使用MLPP分类器对勒索软件进行检测。(3)Kharraz等人构建名为UNVEIL的动态分析系统进行勒索软件检测。(4)Homayoun等人从勒索软件的活动日志中提取特征,并使用MLP、Bagging、Random Forest、J48进行勒索软件检测。(5)Wecksten等人分析了四种类型的加密勒索软件的行为,证明勒索软件攻击本质上依赖于vssadmin.exe软件,用户应该避免使用该软件。(6)Tseng等人从勒索软件中提取流量特征,并使用深度学校的方法进行勒索软件检测。(7)Chen等人通过GAN自动生成勒索软件的动态特征。
基于动态特征的勒索软件检测虽然具有较高的检测精度,但这种分析需要相对较长的时间来进行前期的处理和分析,存在实时性方面的问题。同时,如果勒索软件对环境进行指纹识别,勒索软件分析的有效性也将大打折扣。
基于混合特征:(1)在三个不同层面(汇编、函数调用库)上运用动态分析和静态分析,设计名为CRSTATIC工具实现勒索软件的检测。(2)Shaukat等人使用动态和静态分析的混合系统,结合机器学习技术对勒索软件进行检测。(3)Ferrante等人提出一种基于混合特征的Android勒索软件检测方法。
2. 研究内容
研究内容主要由三部分组成,分别是预处理部分、特征选择部分、样本分类部分。其中,预处理部分需要进行特征提取、频率模式挖掘、规范化三个步骤,从原始良性软件和勒索软件中提取特征;特征选择部分使用增益比技术进一步提取上一步特征中的关键特征;样本分类部分基于样本特征,通过随机森林进行勒索软件检测。
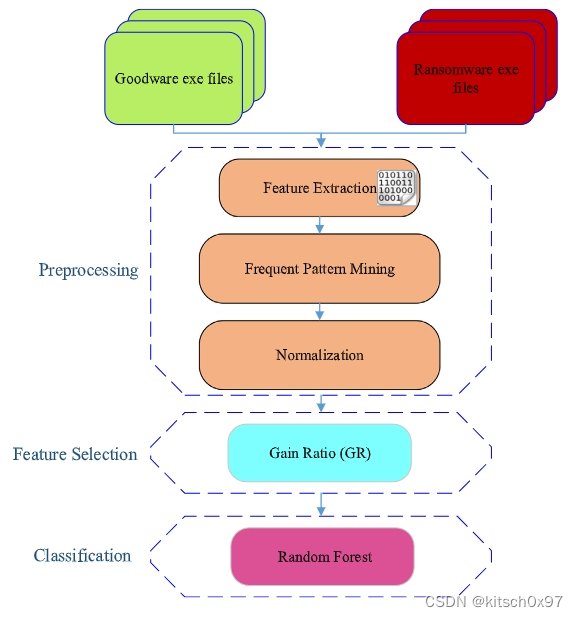
图1. 主要研究内容
3. 具体实现
样本收集
需要收集足够多的勒索软件样本与良性软件样本,勒索软件样本包括34个勒索软件家族(AvosLocker、BlackBasta、BlackCat等)的279个勒索软件,良性软件样本包含970各种常用软件,需要注意的是这些软件均为PE格式文件。具体来说,勒索软件样本的收集包括四个步骤,分别是勒索软件威胁情报收集、勒索软件威胁情报处理、勒索软件样本下载、勒索软件样本清洗,如图1所示。良性软件的收集直接从DikeDataset抽取1000个良性软件样本,并筛选出970个PE格式的良性软件样本。
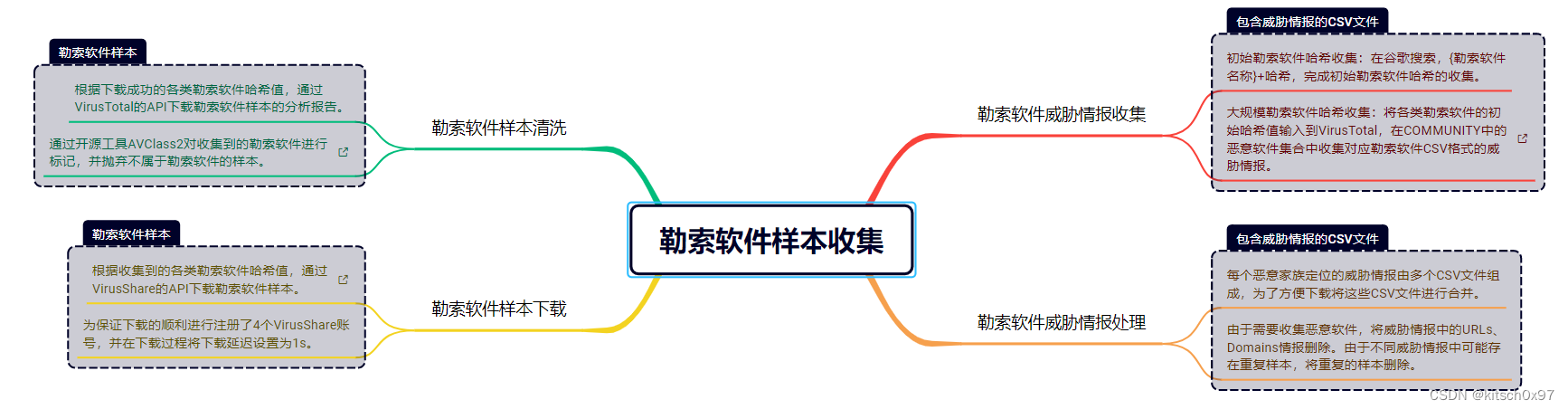
图2. 勒索软件样本收集
针对所有收集到的样本,分析PE文件IMAGE_FILE_HEADER中Machine信息,并统计所有样本的指令集信息,发现绝大部分样本均为x86指令集。
file.seek(0x3C)
pe_offset = int.from_bytes(file.read(4), 'little')
file.seek(pe_offset + 0x04)
machine_type = int.from_bytes(file.read(2), 'little')
if machine_type == 0x014C:
return "x86"
elif machine_type == 0x0200:
return "Itanium"
elif machine_type == 0x8664:
return "x64"
else:
return "Unknown machine type"样本预处理
特征提取:首先将1249个PE文件(勒索软件和良性软件)转换为字节流,之后通过下面的方法从PE文件中提取4-gram特征,然后统计每个特征出现的次数,最后选取特征频率较高的前10000个特征作为原始特征集。
def generate_4gram_features(byte_stream):
features = []
byte_array = np.frombuffer(byte_stream, dtype=np.uint8)
length = byte_array.shape[0]
window_size = 4
for i in range(length - window_size + 1):
window = byte_array[i:i + window_size]
window_value = 0
for j in range(window_size):
window_value += window[j] * (256 ** (window_size - j - 1))
features.append(window_value)
return features频率模式挖掘:首先针对每个样本(勒索软件或良性软件)通过上面提到的方法提取4-gram特征,之后通过下面的方法提取对应样本的特征,最后收集所有样本的特征生成原始数据集。
def generate_feature_count_row(all_features, features):
col_names = all_features.iloc[:, 0].tolist()
data = {col: 0 for col in col_names}
col_counts = Counter(features)
for key in data.keys():
count = col_counts.get(key, 0)
data[key] = count
return data规范化:对样本中的非标签值进行归一化处理。
scaler = MinMaxScaler()
normalized_df = normalization_df.apply(lambda x: pd.Series(scaler.fit_transform(x.values.reshape(-1, 1)).flatten()), axis=1)
normalized_df.columns = normalization_df.columns
normalized_df['Label'] = normalization_df['Label']样本特征选择
通过sklearn对原始数据集中的特征进行特征选择
selector = SelectKBest(score_func=mutual_info_classif, k=1000)
X_selected = selector.fit_transform(X, y)
selected_feature_indices = selector.get_support(indices=True)
selected_features_df = pd.DataFrame(X_selected, columns=X.columns[selected_feature_indices])
selected_features_df['Label'] = y
print(selected_features_df)
勒索软件检测
通过随机森林进行勒索软件检测,检测精度为98.4%,实验表明该方法可以实现勒索软件的检测。
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
rf_classifier = RandomForestClassifier(n_estimators=100, random_state=42)
rf_classifier.fit(X_train, y_train)
y_pred = rf_classifier.predict(X_test)
confusion_mat = confusion_matrix(y_test, y_pred)
confusion_df = pd.DataFrame(confusion_mat, index=['Actual 0', 'Actual 1'], columns=['Predicted 0', 'Predicted 1'])
print(confusion_df)4. 存在问题
问题1:在样本预处理过程中,我们通过从4-gram特征中选取特征频率较高的前10000个特征作为原始特征集。这样做的主要原因是,4-gram特征特征有30000000之多,我们现在的机器无法有效处理如此多的特征。
问题2:在特征选择和分类模型构建的过程中,直接使用现有的方法,是否可以选择其他方法以提升勒索软件检测的性能。
















 9848
9848

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









