









PCAP是一种经常在计算机网络研究中被使用的文件格式。其按时间先后顺序记录了经过某条链路的数据报文。
PCAP文件格式较为简单,主要有三个组成部分:PCAP文件头部、PCAP数据包头部以及数据包数据。
在PCAP中,数据包是按照时间先后顺序存储的。而已有的如libpcap和WinPcap等程序库也是基于数据包为单元对象进行封装的。而在PCAP中,并没有“流”(具有相同五元组:源IP地址,目的IP地址,源端口,目的端口和协议的数据包串)这个概念。
在捕获报文得到的PCAP文件中,绝大多数情况都同时存在着不止一条流,而PCAP是按照包的到达时间顺序记录报文的。所以,流在PCAP文件中的存储顺序是分隔的,是不连续的。这种情况就比较类似操作系统中的进程地址空间,操作系统中进程的地址空间在逻辑上是连续的,以32位系统为例,其拥有4G的逻辑空间地址。但其在实际物理内存地址上是离散的,是进程的用户不可知的。而操作系统本身负责了逻辑地址与物理地址之间的相互转换。这样进程的用户就更容易专注于完成进程本身的功能,而不是处理复杂而繁琐的物理地址。这样的进程将会更健壮、更稳定。
在提出了“流”这一概念时,需要有与之对应的实现,这个实现可以是直接的,也可以是表示一个间接的转换。
我们可以对原始的PCAP文件进行流提取,因为直接分析顺序杂乱的数据包将会遇到困难:一方面不方便后续流参数提取模块的编写。另一方面,负责提出参数的研究人员以及分类算法编写人员将需要陷入具体的PCAP文件格式细节中,需要了解PCAP中数据包的存储顺序,这样将不便于研究工作的开展。
而当进行了流提取以后,对于流特征的分析和提取以及相关的研究讨论,便可集中在具体的流本身上,达到了与实际存储位置解耦合的效果,也方便多个人讨论时,集中“注意力”。
流提取的效果示意图如下:
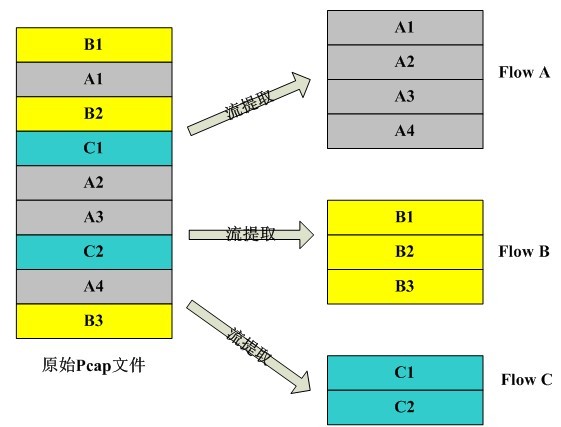
上图所示,左边即为原始的PCAP文件示意图,一共有A、B、C三条流,其中A1表示流A中第一个数据包,A2表示流A中第二个数据包,依此类推。在原始PCAP文件中,单个流中的报文是按到达顺序存储的,但是对于不同流之间的报文是穿插着的。通过流提取模块对PCAP文件流进行提取,在不改变原始PCAP文件存储内容的条件下,可以得到逻辑上相互独立的流。单条流中,原始的报文顺序没有发生改变,这保证了我们在分析时不会出现时间先后顺序的错误,同时,将不同流之间的报文“逻辑”上分离了,便于我们对A、B、C三条流分别进行分析。对于研究流分类参数的研究人员,其只需要关注A、B、C三条流,而不需要关心A、B、C在原始的PCAP文件中是如何存储的。















 3812
3812

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









