






目录
model bias vs optimization issue
三、自动调整学习率(Adaptive Learning Rate)
如何调整模型

1.model bias
通常是模型过于简单
- 对model增加features
- 对model增加layers

2.optimization issue 优化问题
未知参数会止步于local minnima,最后的loss会不够小
model bias vs optimization issue
比较不同layer层数的model,如果layer大的model反而在训练集和测试集上效果差,则可能为optimization issue
3.overfitting
overfitting通常在训练集上效果好,在测试集上效果差
可能发生在model的flexible过大,或者说layer过多的情况

解决方法:
- 增加训练数据
- 数据增强(data augmentation)
- 增加model限制
- 较少的参数或共享参数(如不使用全连接神经网络,使用卷积神经网络)
- 较少的特征输入
- Early Stopping
- Regularization
- Dropout

Tip: test loss大不代表一定是overfitting,建议先检查training loss
4.cross Validation 交叉验证
将数据集划分为训练集和验证集,通过model在验证集上的loss来判断一个模型的好坏
N-fold cross Validation
n种验证集情况下的loss进行平均后再比较

5.Mismatch
训练集与测试集的分布不同
一、局部最小值和鞍点
在local minima与saddle point处梯度都为零,统称为critical point(驻点)
如果模型参数优化止步于鞍点,则还可以继续优化
二、批次(batch)与动量(momentum)
shuffle:每一个epoch之前会重新随机划分batch,使得每一轮中的batch中内容不同
为什么training时要使用batch来计算loss?
- 在GPU并行计算场景下,1~1000的batch size下计算一次loss并求梯度的时间几乎一致;而bs越小,一个epoch中的update次数越多,则计算时间很大,故选择较大的bs,可以缩短训练时间。

- bs越大,update次数少,容易让loss止步于驻点而暂停更新此时training acc小;bs越小,update次数多,loss止步于驻点后可以在下一次batch中更新,此时training acc大。
- bs越大,testing acc越高;bs越小,testing acc越低。

梯度下降法结合Momentum?
每一步参数移动的方向为 该点梯度反方向与前一步方向的叠加 来调整参数,从而避免local minima的影响。

三、自动调整学习率(Adaptive Learning Rate)
当training stuck时,不一定是走到了驻点,大多数情况下是由于learning rate的大小
- learinging rate太大,则步伐太大,会越过最低点
- learinging rate太小,则步伐太小,难以收敛到最低点
不同情况下所需的lr大小?
- 梯度大的情况下需要小的学习率
- 梯度小的情况小需要大的学习率

Tip:指第i个参数,
指对第i个参数的第t次update
如何求解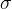 ?
?
- 均方根(Root Mean Square)
- RMSProp
调整每个梯度的影响度,从而使每step对梯度影响的反应较合理

- Adam:RMSProp+Momentum
如何调整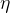 ?
?
- Learing Rate Decay

- Warm Up

梯度下降法的优化策略?
- 考虑梯度方向:步伐考虑动量
- 考虑梯度大小:自适应性学习率

四、独热编码
独热编码表示输出结果可将classification issue转化为regression issue

如何输出独热编码?
- 使用多组权重和均值得到向量的不同元素

- 使用softmax函数对输出归一化,并让向量每个元素值之间的差距更大


- 使用cross-entroy来表示预测值
与真实值
之间的差异
cross-entroy比MSE计算差异更适用于分类问题
















 2174
2174

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









