






一、算法分析基础
- 算法 是一组有穷的规则,它规定了解决某一特定 类型问题的一系列运算。
- 算法的五个重要特性:确定性、能行性、输入、输出、有穷性
-
算法的执行时间是算法中所有运算执行时间的总和

- 限界函数的定义

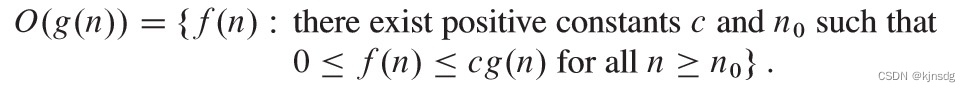
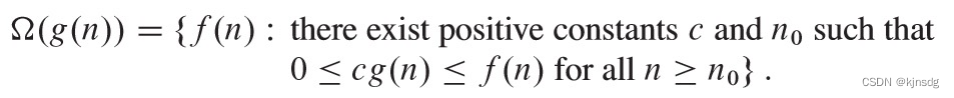
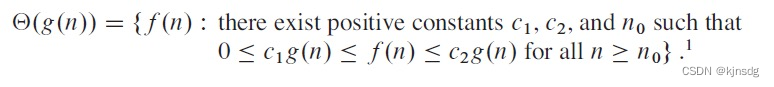
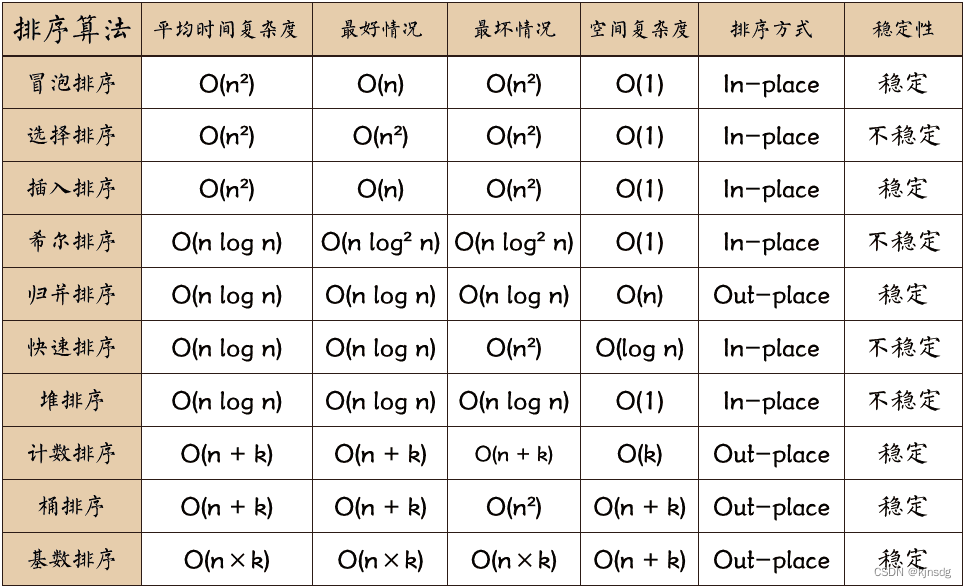
- 排序算法比较
二、分治策略
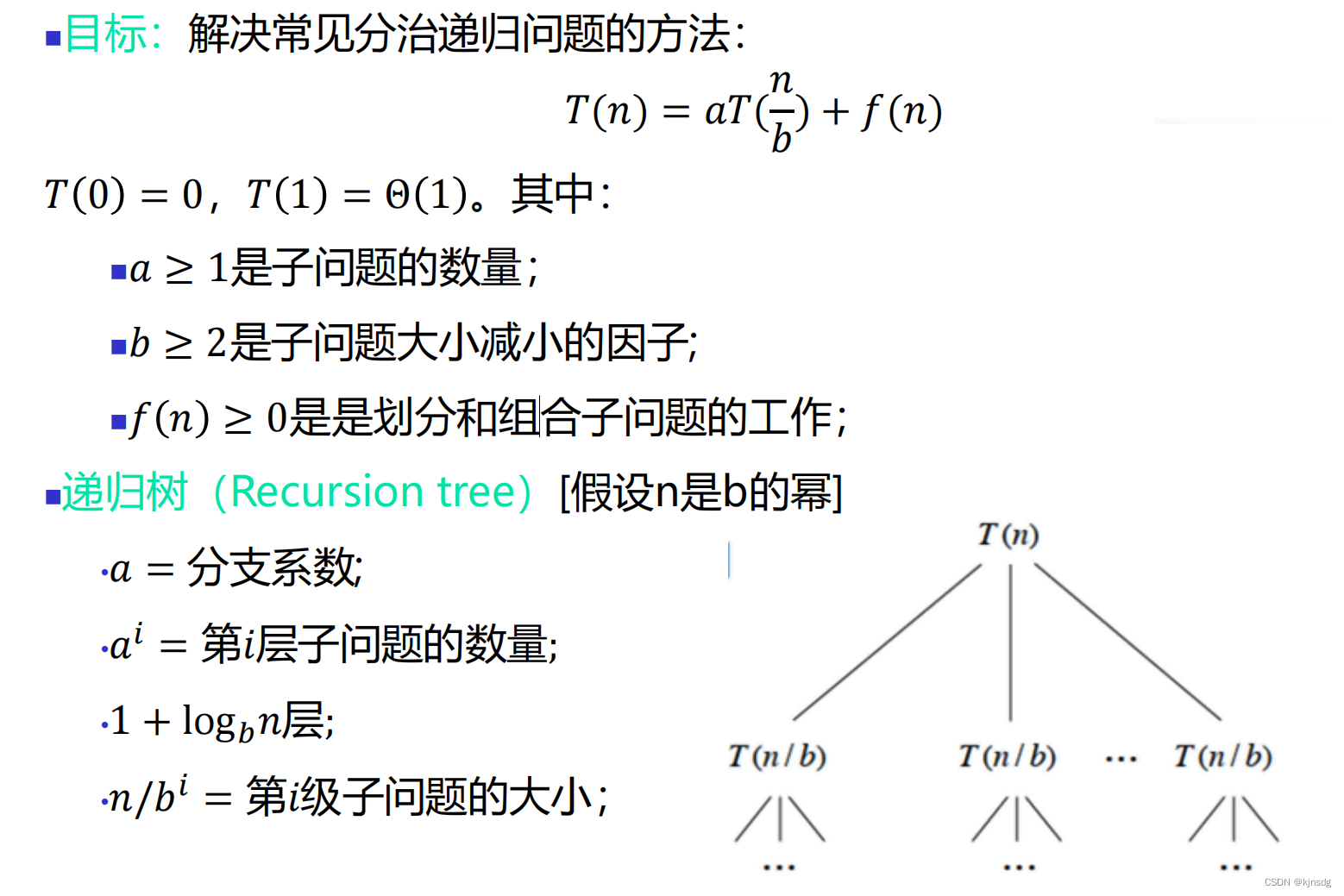
- 主定理:


例题:
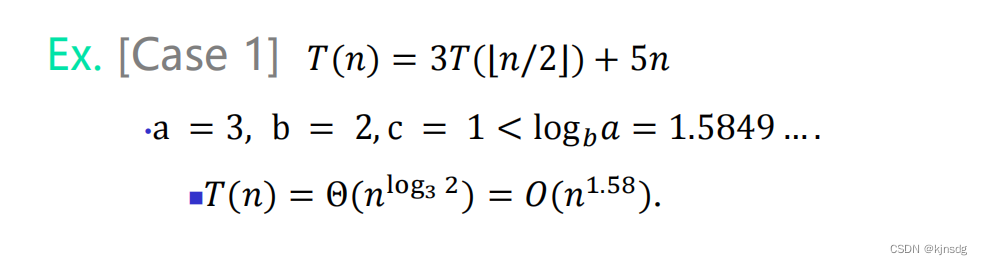
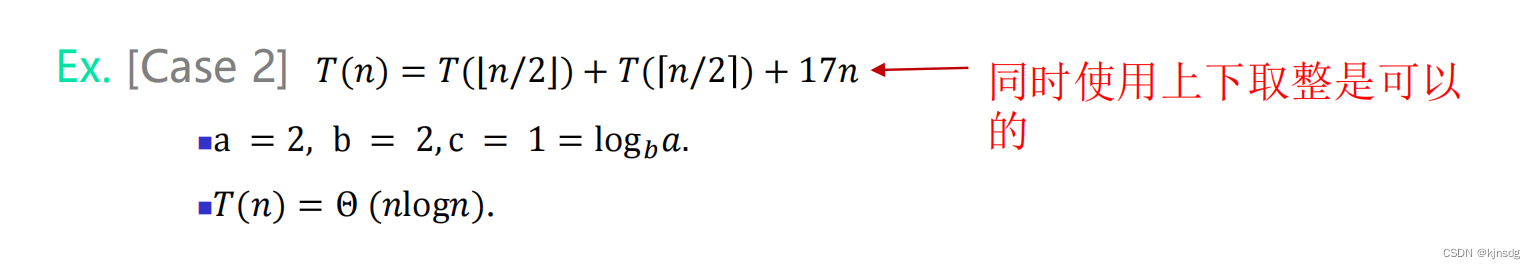
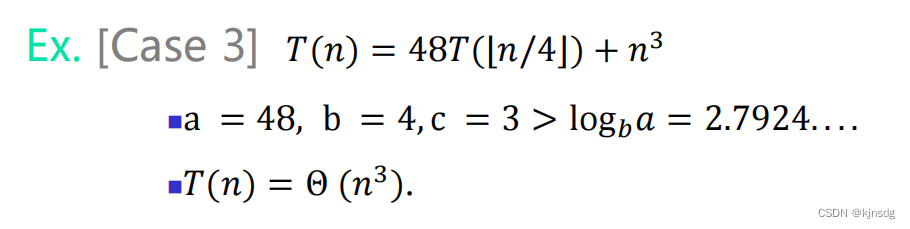
部分情况会使得主定理不适用,如下:

- 主定理的一般化?

三、贪心策略
-
贪心选择性质 :可以通过做出局部最优(贪心)选择来构造全局最优解的性质。
-
属于贪心策略的经典算法有:Dijkstra算法,最小生成树算法(Prim和Kruscal),Huffman编码。
四、动态规划
-
动态规划算法的基本要素:
最优子结构性质:问题的最优解包含着它的子问题的最优解。即不管前面的策略如何,此后的决策必须是基于当前状态(由上一次决策产生)的最优决策。
重叠子问题:在用递归算法自顶向下解问题时,每次产生的子问题并不总是新问题,有些问题被反复计算多次。对每个子问题只解一次,然后将其解保存起来,以后再遇到同样的问题时就可以直接引用,不必重新求解。
- 0-1背包问题最优子结构的证明
- 最长公共子序列问题(LCS)

例如 求X=<A,B,C,B,D,A,B>和Y=<B,D,C,A,B,A>的LCS,转移图如下
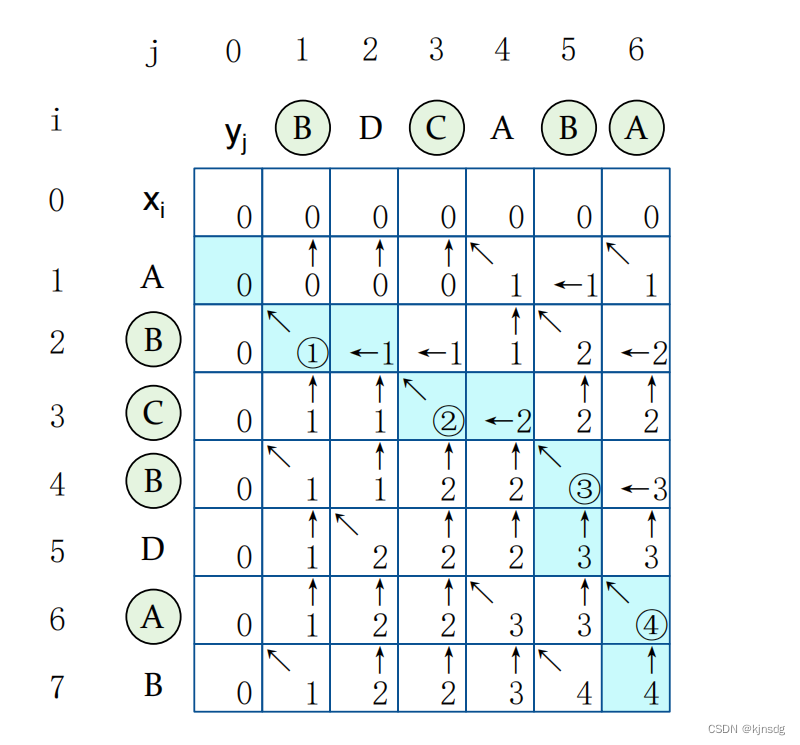
五、二叉堆与优先序列
- 堆的操作

- 堆是一个完全二叉树
–
所有叶子在同一层或者两个连续层
–
最后一层的结点占据尽量左的位置
- 堆性质
–
为空
,
或者最小元素在根上
–
两棵子树也是堆
-
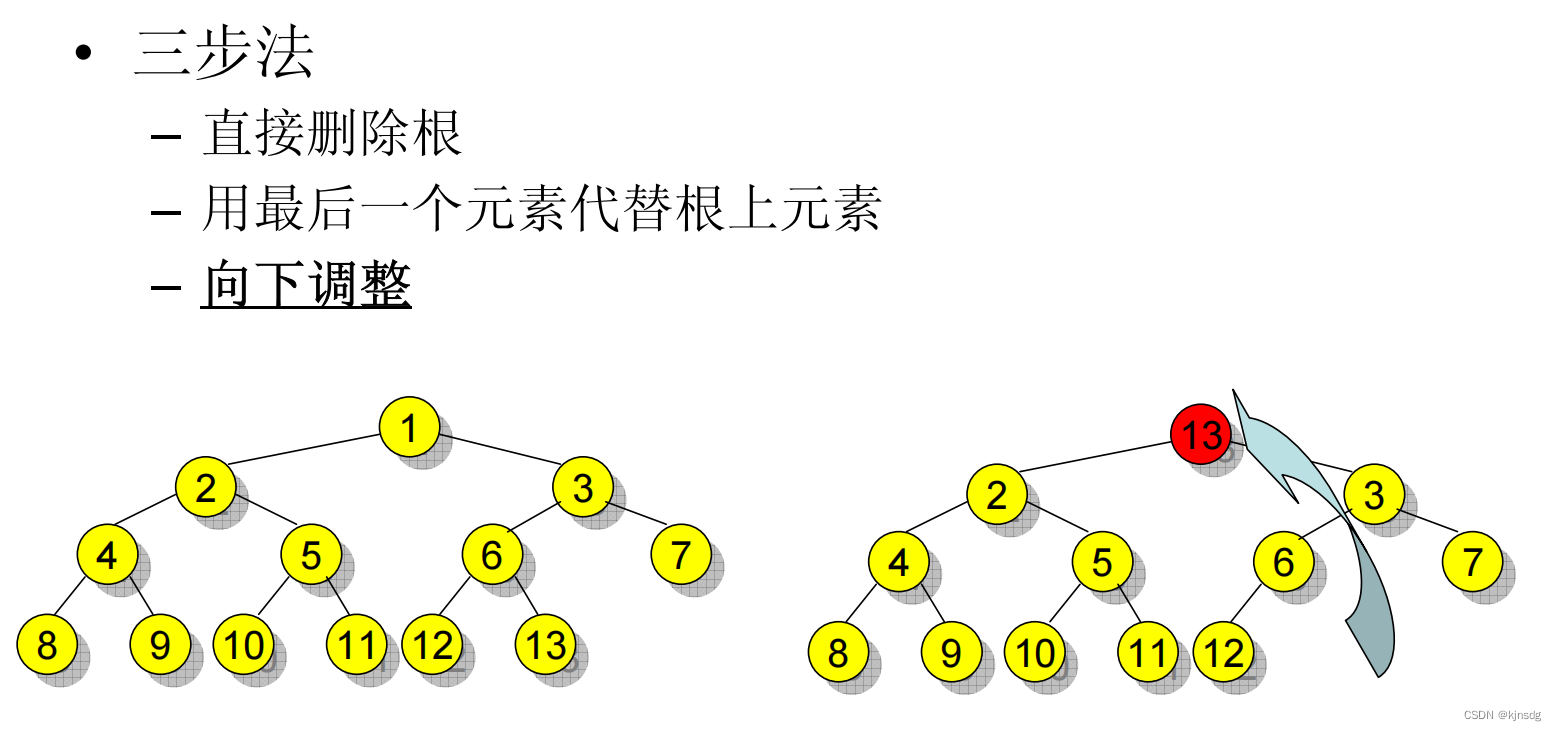
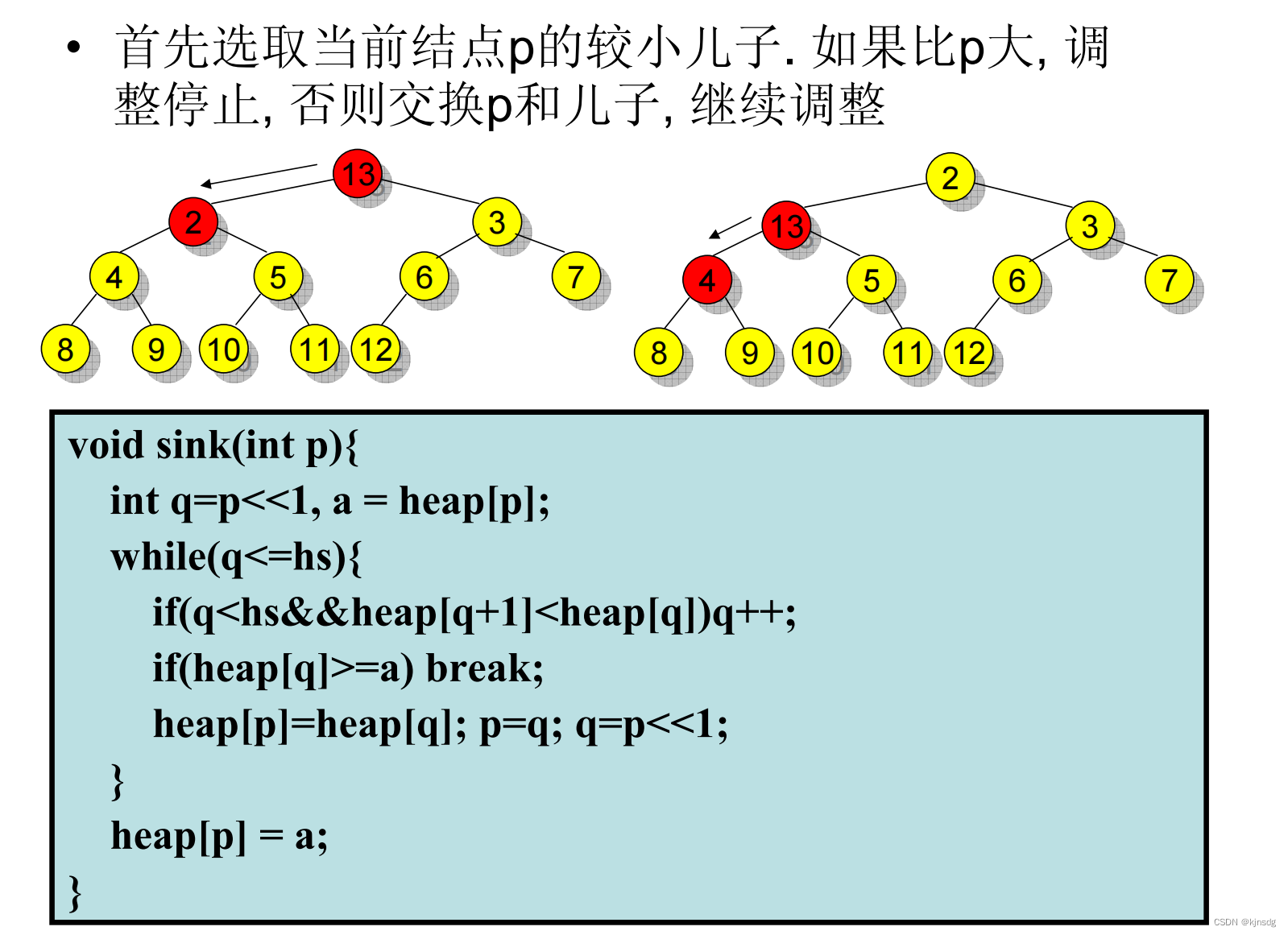
删除最小值元素
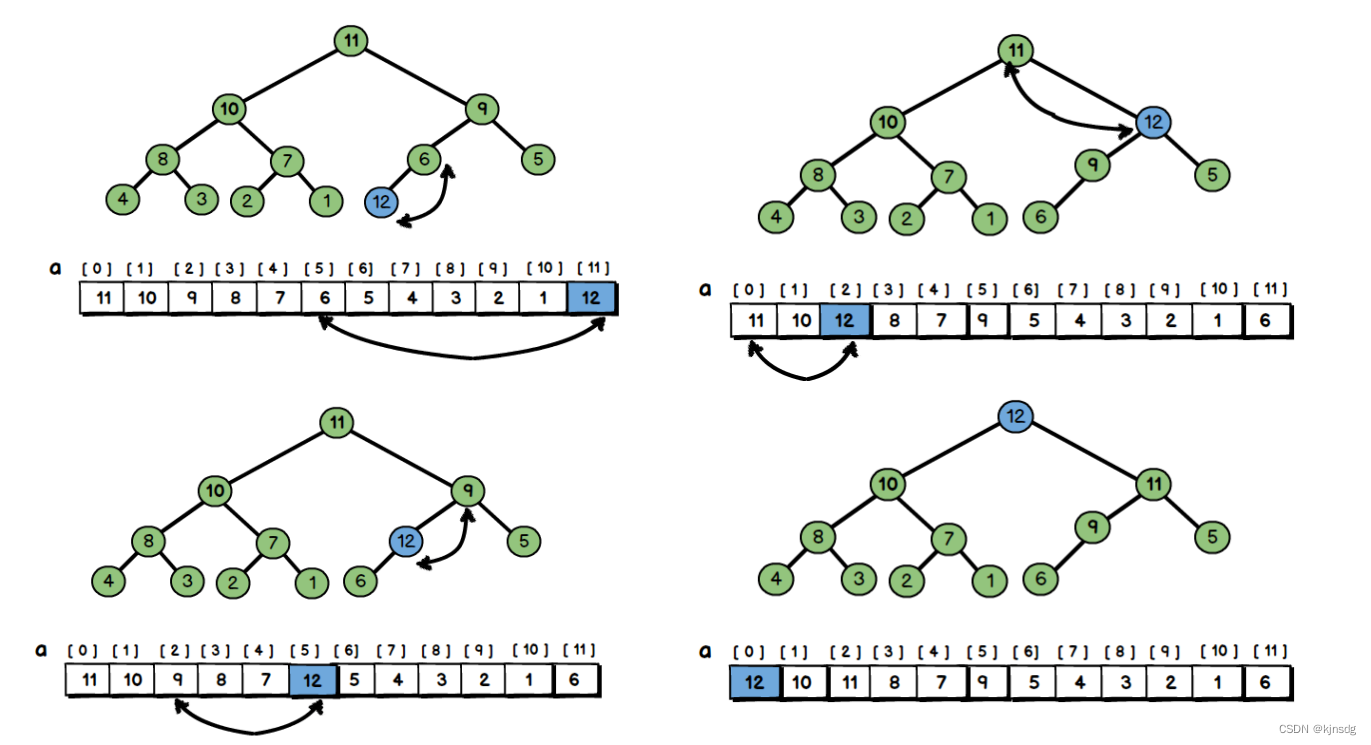
- 二叉堆的插入
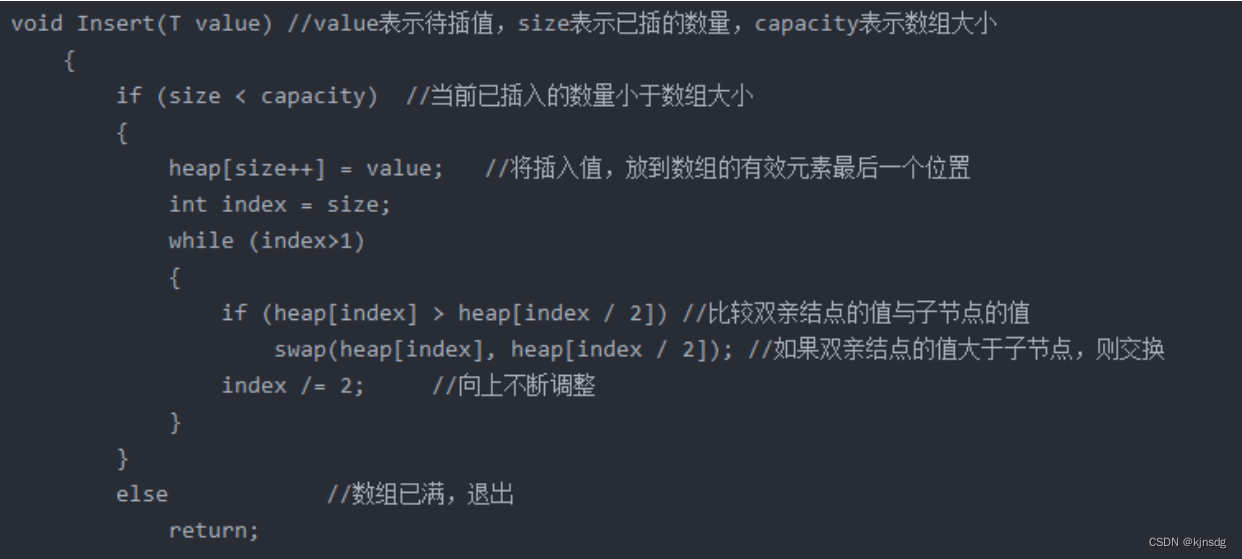
- 二叉堆的删除
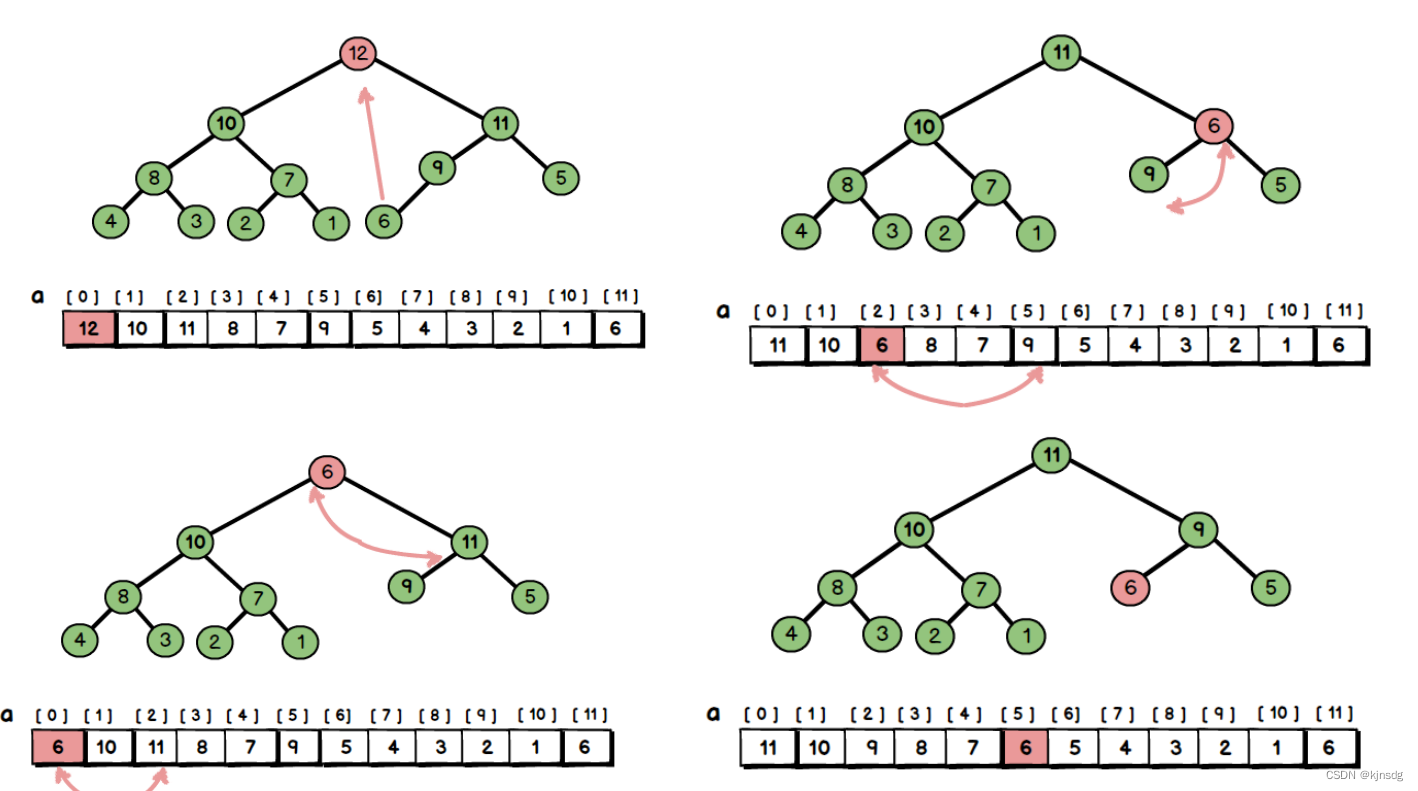

- 二叉堆的建立
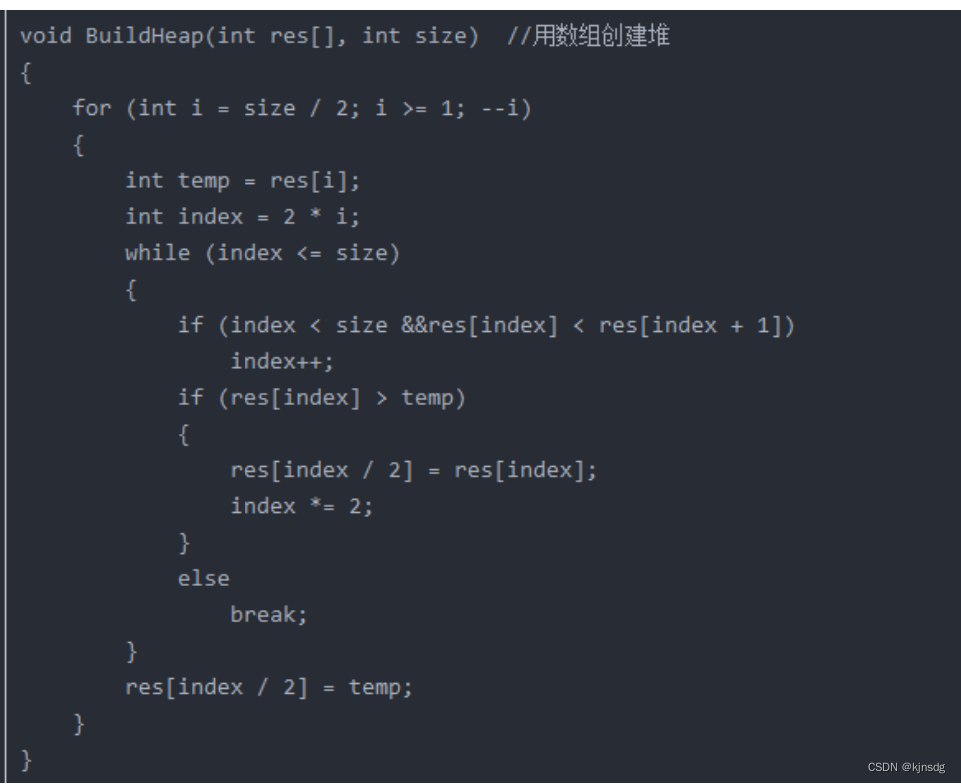
- 时间复杂度

六、并查集
- 【算法与数据结构】—— 并查集
- 重点在于路径压缩部分,和并查集完美结合后的find()函数,用简洁的三行代码实现。
int find(int x){//查询并更新x的祖先节点
if(x != p[x])
p[x] = find(p[x]);//p[x]表示x的祖先节点
return p[x];
}七、线段树
- 超详解线段树
- 建议在了解线段树基本原理和相关操作后,去做洛谷的线段树模板三道题:线段树 1, 线段树2, 线段树3,静下心来把这三道题做完,耐下性子去de线段树那无穷无尽的bug后,会对线段树的认识和掌握会有质的提升。
八、树状数组
九、二叉树和平衡树
十、最小生成树
- D-search和BFS和DFS

- Prim算法,朴素算法复杂度为O(n^2),使用优先队列的话时间复杂度是O(mlogn)
核心代码如下:
int prim() {//类比dijkstra算法
memset(dist, 0x3f, sizeof dist);
dist[1] = 0;//初始化
int res = 0;
for (int i = 1; i <= n; i++) {
int t = -1;
for (int j = 1; j <= n; j++)
if (!st[j] && (t == -1 || dist[j] < dist[t]))
t = j;
st[t] = 1;
if (dist[t] == 0x3f3f3f3f) return 0x3f3f3f3f;
res += dist[t];
for (int j = 1; j <= n; j++)dist[j] = min(dist[j], g[t][j]);
}
return res;
}- Kruscal算法,时间复杂度为O(mlogm)
核心代码如下:
int kruskal() {//kruskal可以看作是并查集的应用
sort(edges, edges + m);//首先排序,是“关键一步
for (int i = 1; i <= n; i++)p[i] = i;
int res = 0, cnt = 0;//res记录最小生成树长度,cnt记录节点数
for (int i = 0; i < m; i++) {
int a = edges[i].a, b = edges[i].b, w = edges[i].w;
a = find(a), b = find(b);
if (a != b) {//a和b不在一个集合就连接起来
p[a] = b;
res += w;
cnt++;
}
}
if (cnt != n - 1)return INF;
else return res;
}
十一、单源最短路径
- 如何理解最短路径中的“松弛”操作
- 一文弄懂Bellman-Ford(贝尔曼福特算法)
- 图算法 - 单源最短路径
- Bellman-Ford算法属于动态规划算法。
- Dijkstra算法,使用堆优化后,时间复杂度为O(mlogn)
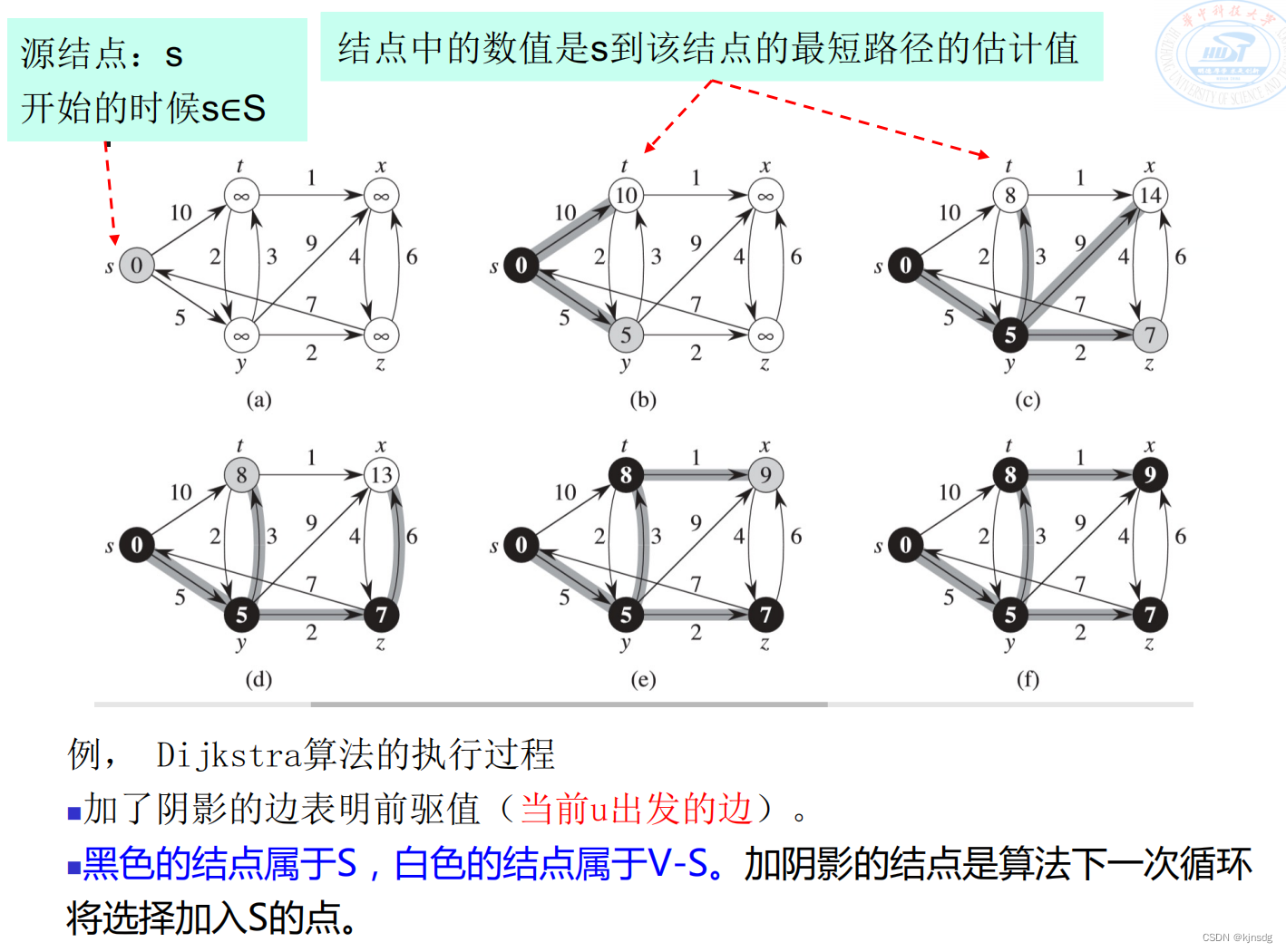

核心代码:
int dijkstra() {
memset(dist, 0x3f, sizeof dist);
dist[1] = 0;
priority_queue<PII, vector<PII>, greater<PII>> heap;//使用优先队列,省去找最短边的步骤
//优先队列可看 https://blog.csdn.net/weixin_57761086/article/details/126802156
heap.push({ 0, 1 });
//优先队列默认按照first的值进行排序
while (heap.size()) {
auto t = heap.top();
heap.pop();
int ver = t.second;//first存的是边权,即原点到ver的距离,second存的是ver点
if (st[ver]) continue;//排除冗余
st[ver] = true;
for (int i = h[ver]; i != -1; i = ne[i]) {
int j = e[i];
if (dist[j] > dist[ver] + w[i]) {
dist[j] = dist[ver] + w[i];
heap.push({ dist[j], j });
}
}
}
if (dist[n] == 0x3f3f3f3f) return -1;
return dist[n];
}
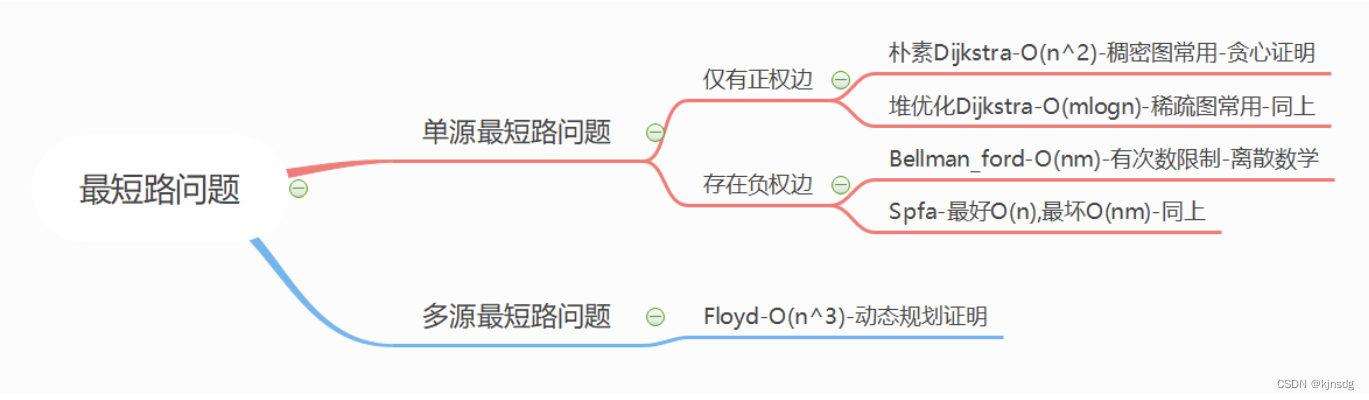
十二、多源最短路径
- Floyd求最短路
- 最短路总结,摘自acwing郡呈大佬

十三、拓扑排序
- AOV与AOE网
- 拓扑排序1,总的时间复杂度:O(n+e)

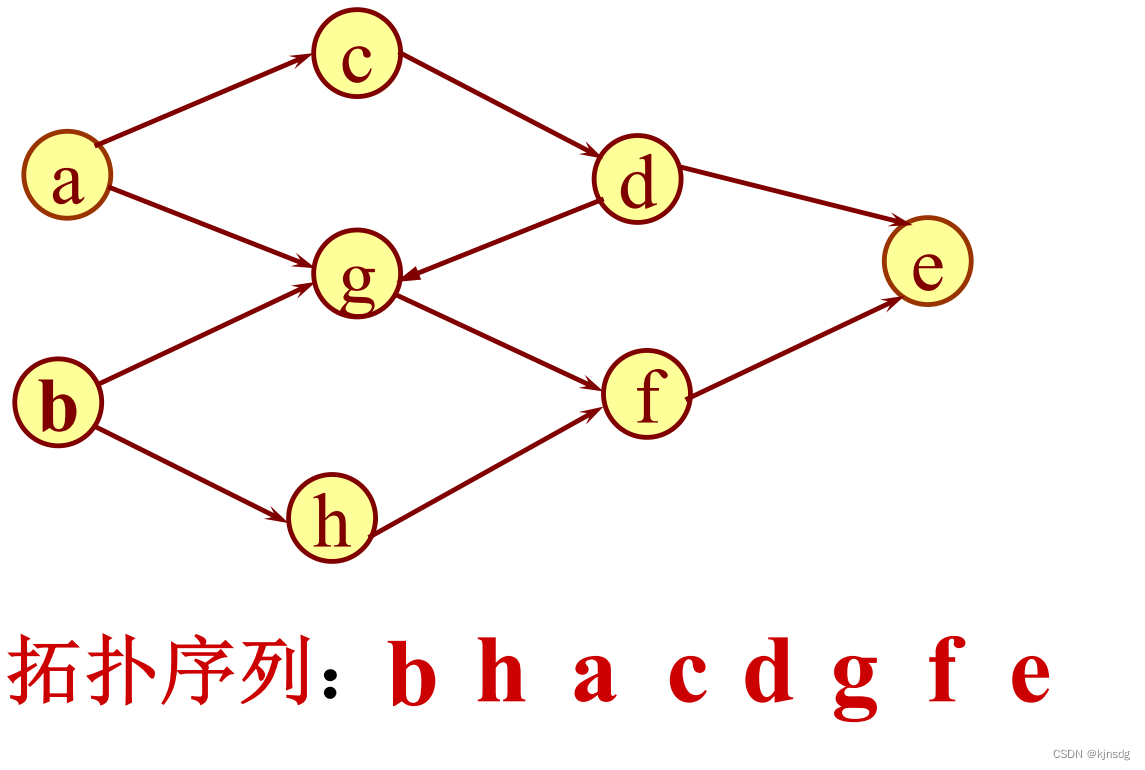
- 拓扑排序2


-
路径最长的路径叫做关键路径,影响工程进度的活动叫 关键活动,关键路径上的活动一定是 关键活动
- 10分钟了解关键路径及如何求得关键路径
- 图解:什么是关键路径?
- 核心代码:
void topsort(){
for(int i = 1; i <= n; i++){//遍历一遍顶点的入度。
if(d[i] == 0)//如果入度为 0, 则可以入队列
q[++tt] = i;
}
while(tt >= hh){//循环处理队列中点的
int a = q[hh++];
for(int i = h[a]; i != -1; i = ne[i]){//循环删除 a 发出的边
int b = e[i];//a 有一条边指向b
d[b]--;//删除边后,b的入度减1
if(d[b] == 0)//如果b的入度减为 0,则 b 可以输出,入队列
q[++tt] = b;
}
}
if(tt == n - 1){//如果队列中的点的个数与图中点的个数相同,则可以进行拓扑排序
for(int i = 0; i < n; i++){//队列中保存了所有入度为0的点,依次输出
cout << q[i] << " ";
}
}
else//如果队列中的点的个数与图中点的个数不相同,则可以进行拓扑排序
cout << -1;//输出-1,代表错误
}十四、KMP

- yxc的简易版的KMP代码:
#include <iostream>
using namespace std;
const int N = 100010, M = 1000010;
int n, m;
int ne[N];
char s[M], p[N];
int main()
{
cin >> n >> p + 1 >> m >> s + 1;
for (int i = 2, j = 0; i <= n; i ++ )
{
while (j && p[i] != p[j + 1]) j = ne[j];
if (p[i] == p[j + 1]) j ++ ;
ne[i] = j;
}
for (int i = 1, j = 0; i <= m; i ++ )
{
while (j && s[i] != p[j + 1]) j = ne[j];
if (s[i] == p[j + 1]) j ++ ;
if (j == n)
{
printf("%d ", i - n);
j = ne[j];
}
}
return 0;
}十五、网络流






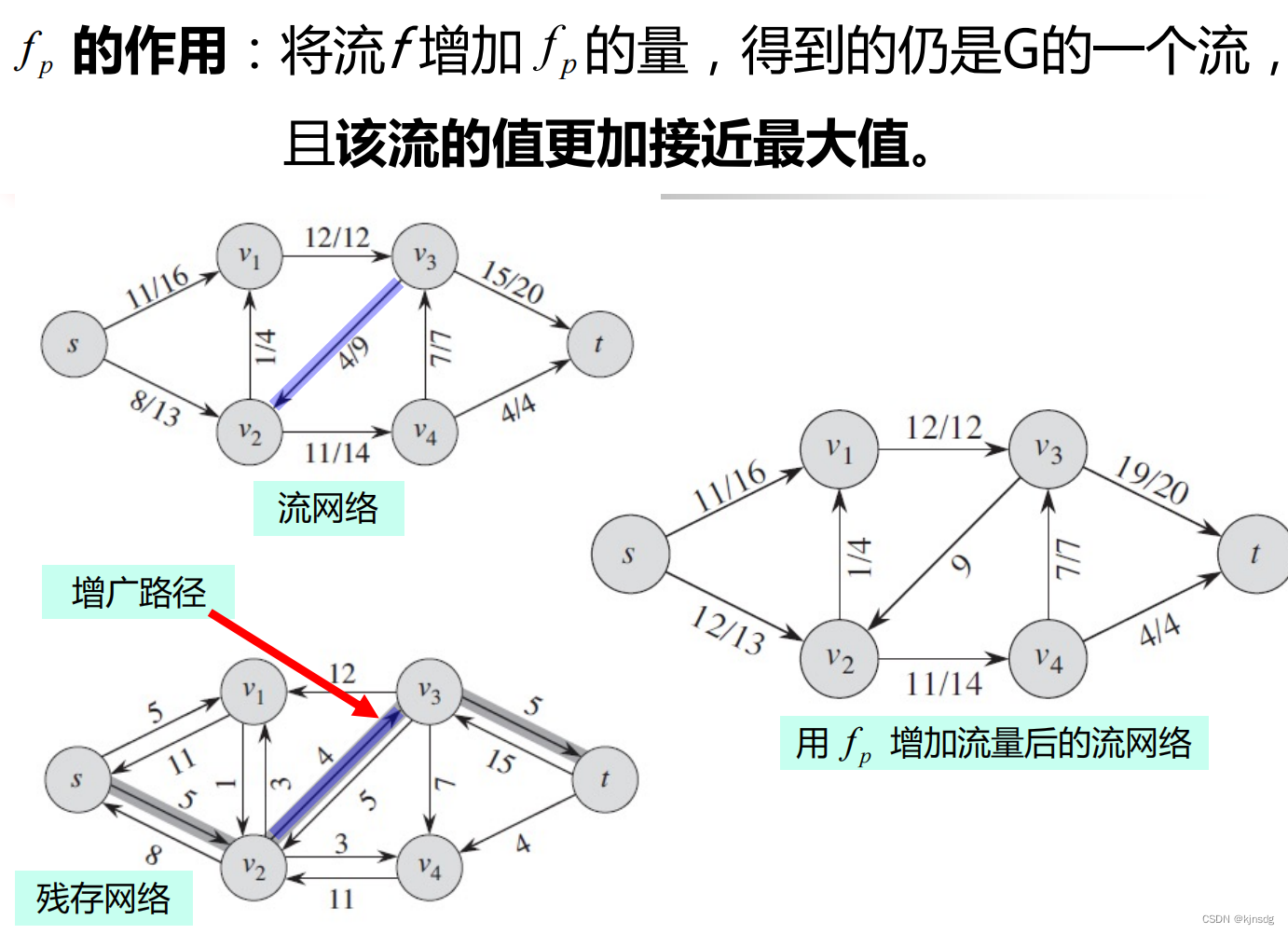

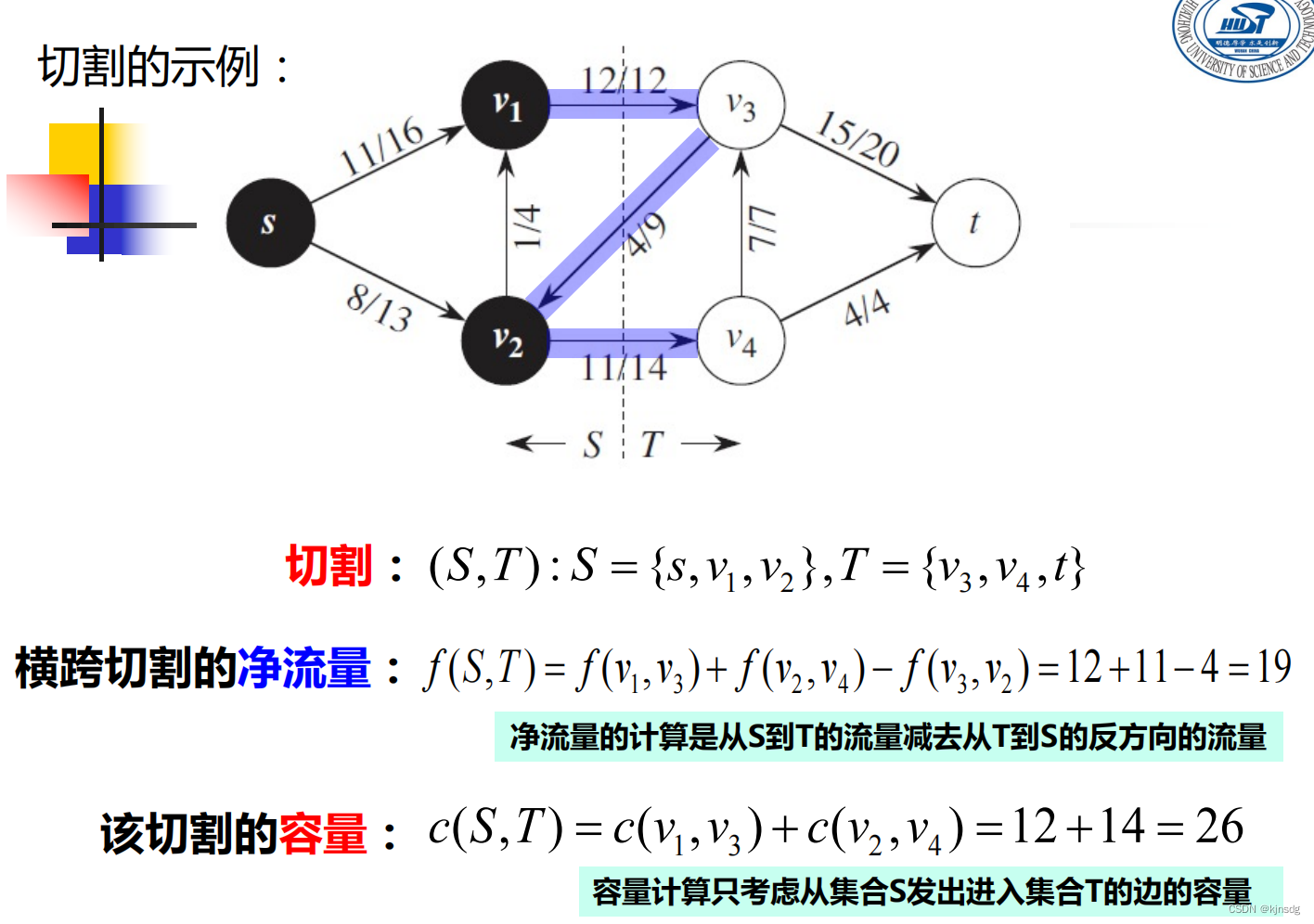
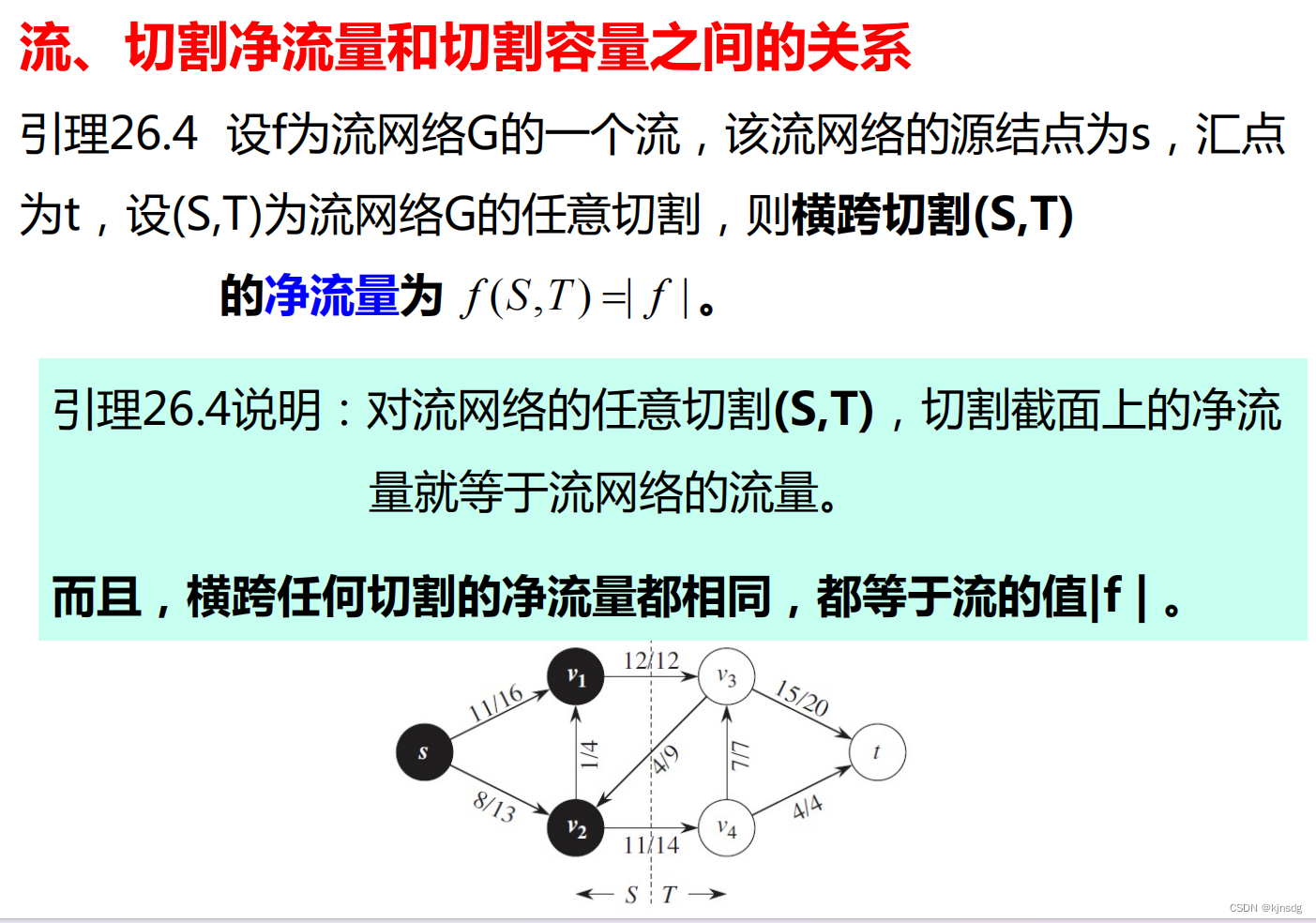




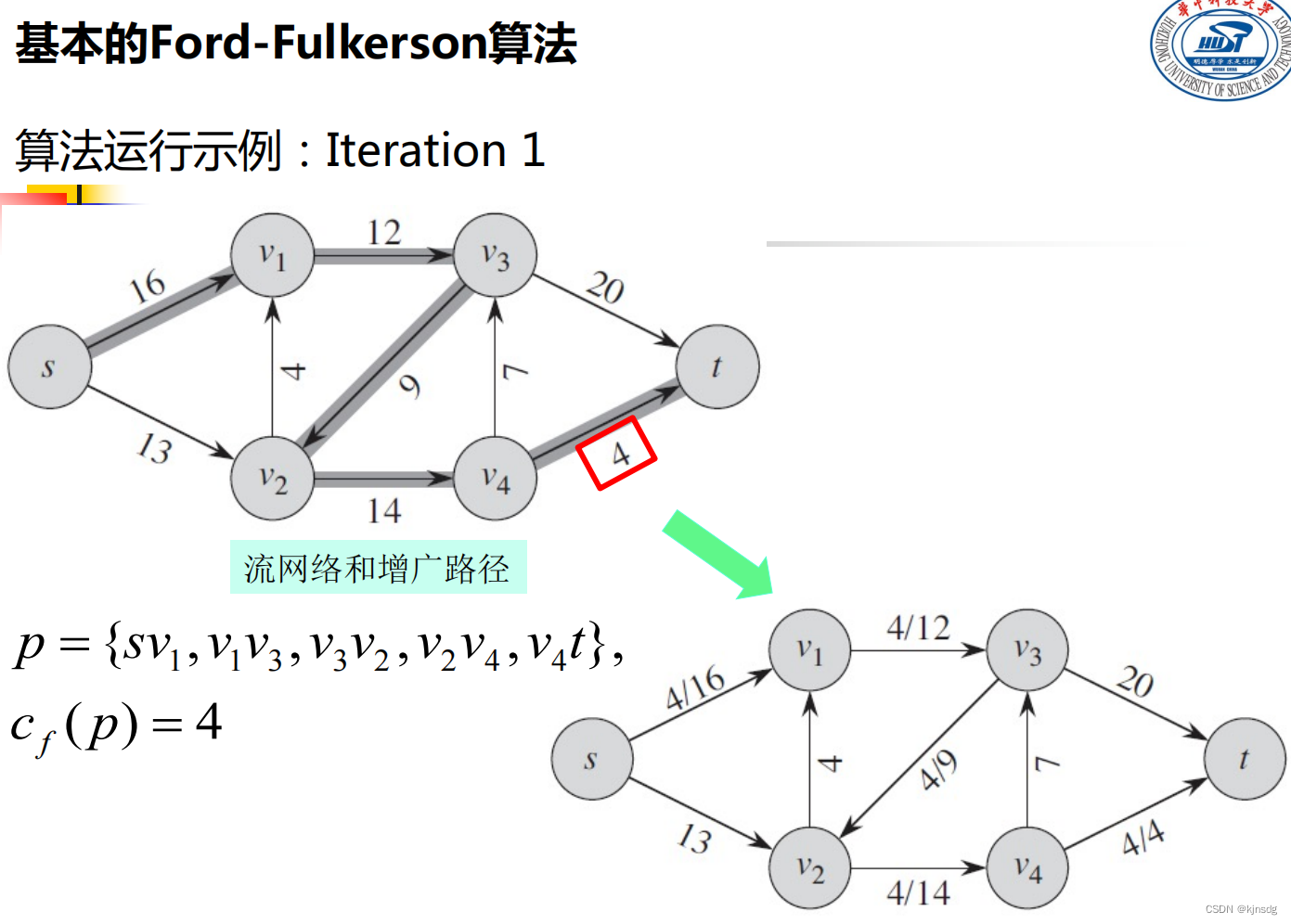
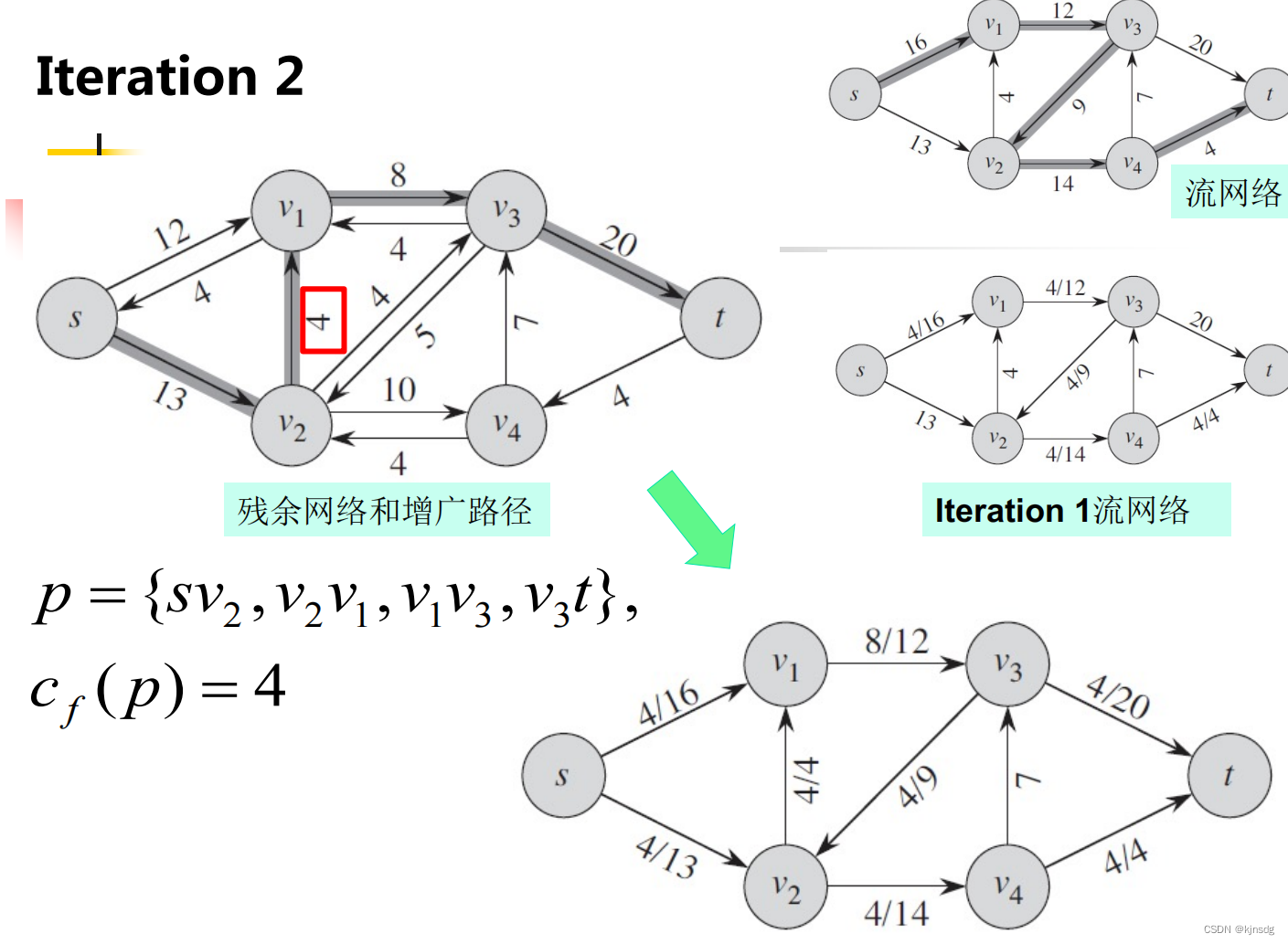
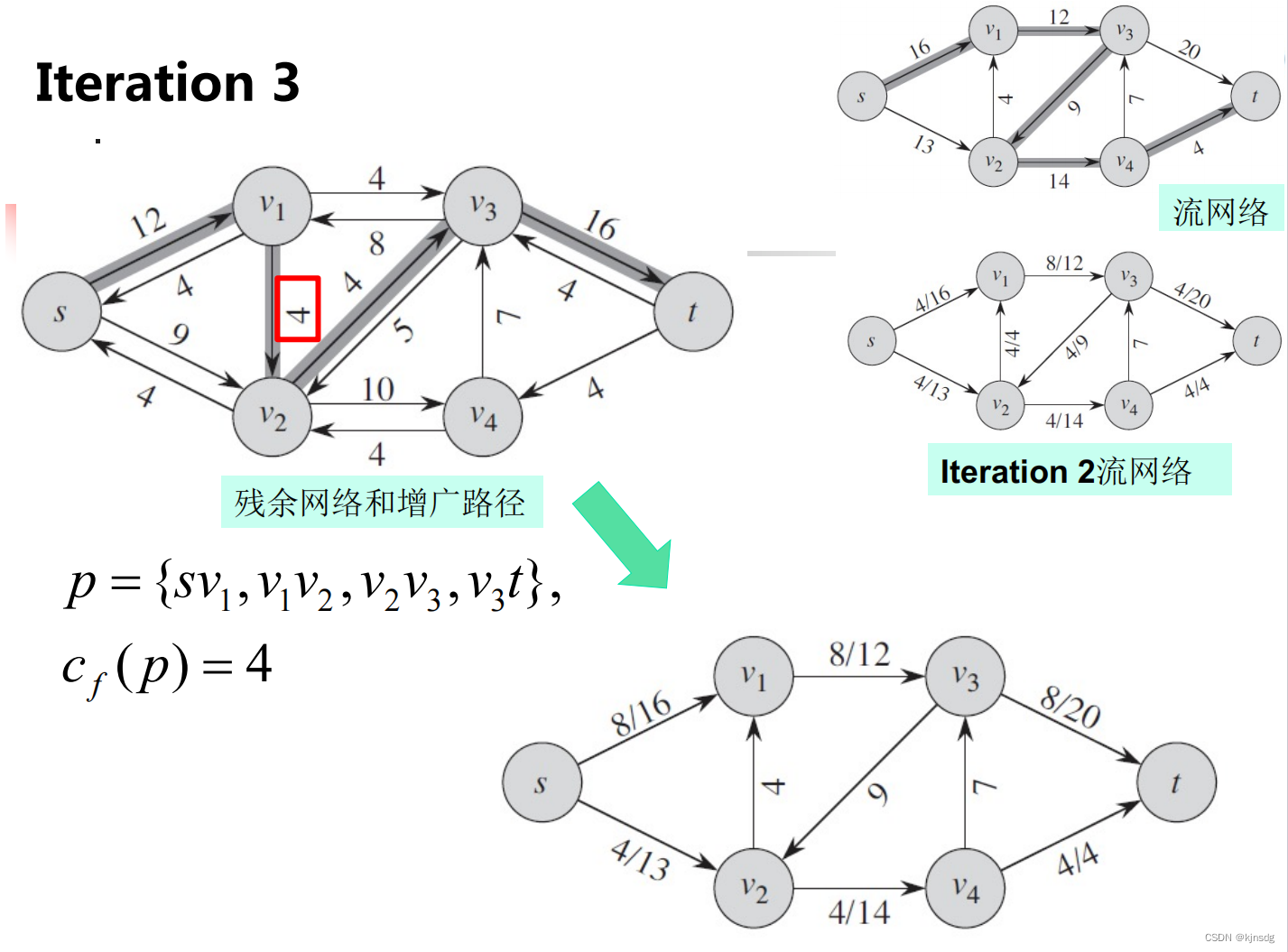

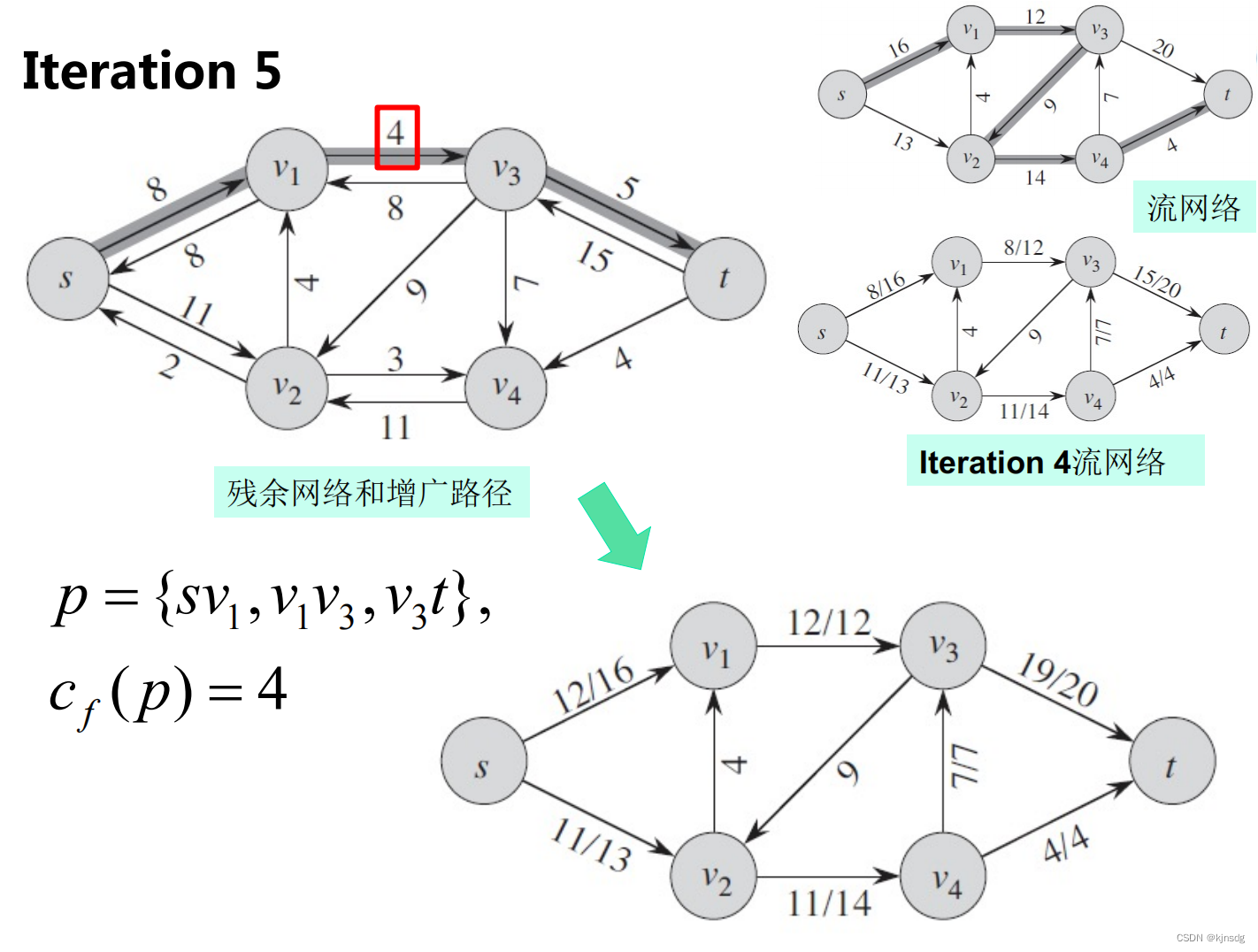
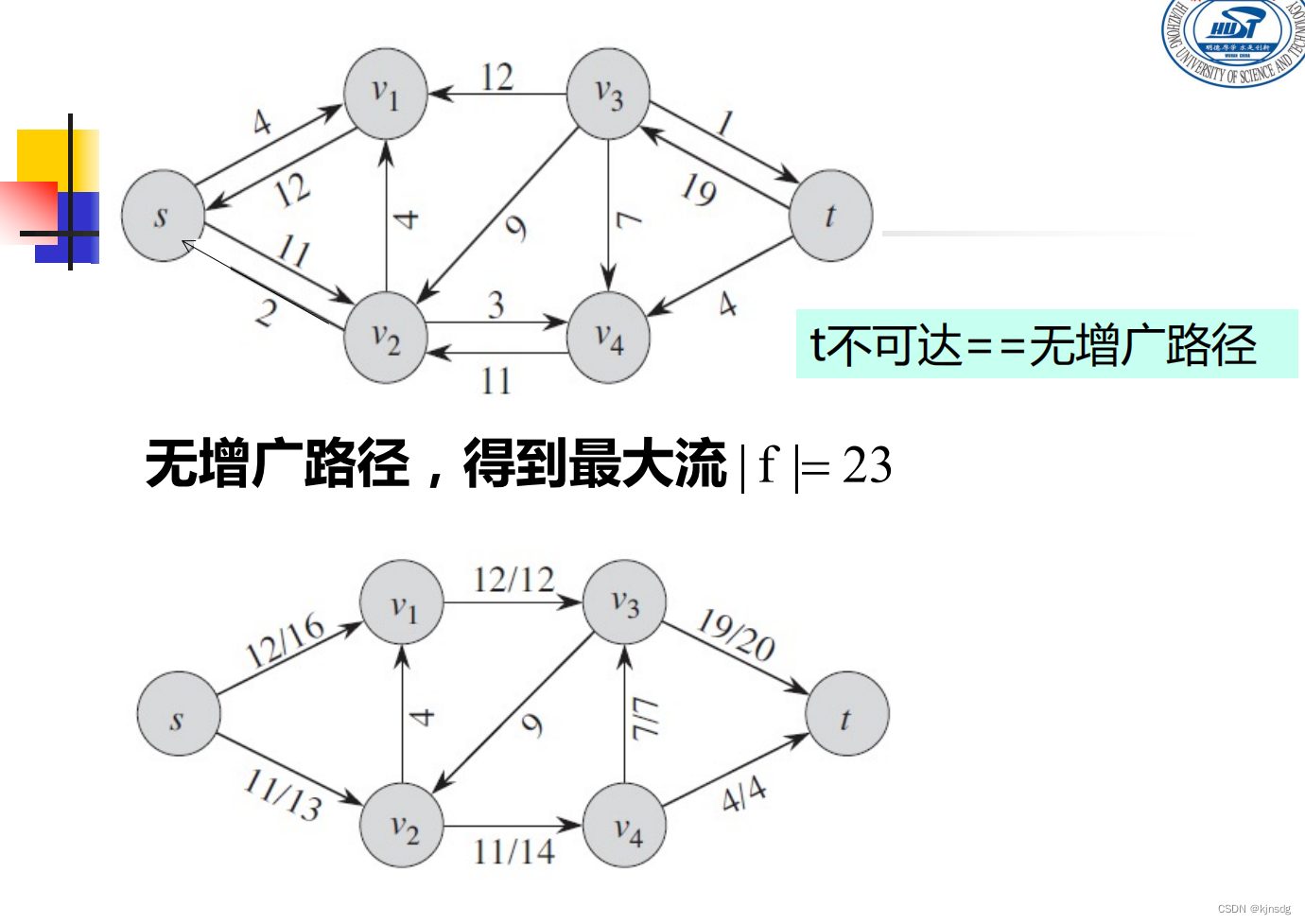
十六、NP-Completeness


























 723
723











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









