







对于股票市场长期的判断,普通上班族没有多少时间和资料可以分析。那么,就应该借助基金机构选择的股票来分析,借助各基金经理管理的股票基金来统计,哪些股票是基金经理或团队分析购买的。所以选择的是股票型基金,最终将分析得出哪类股票是机构最多选择的,那只股票是机构购买最多的。利用基金经理们分析的结果,我们可选择相应的几只股票进行长期投资。
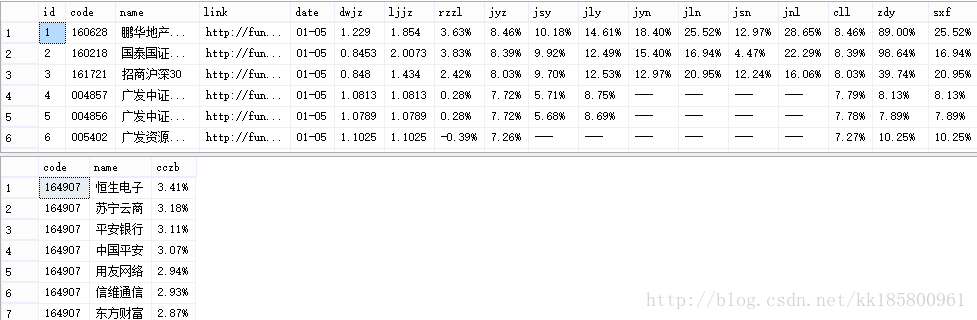
先看看股票型基金,然后遍历某基金的股票持仓。
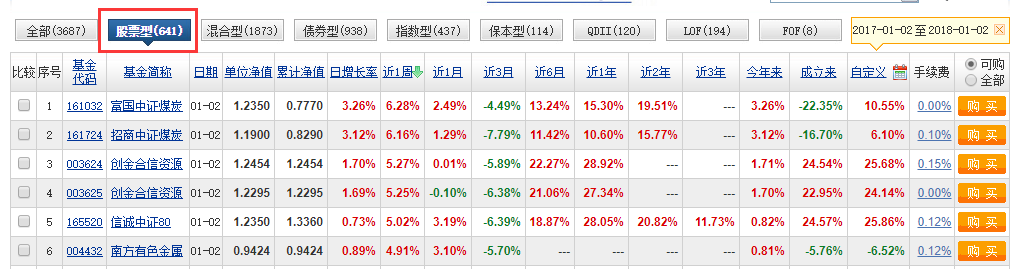
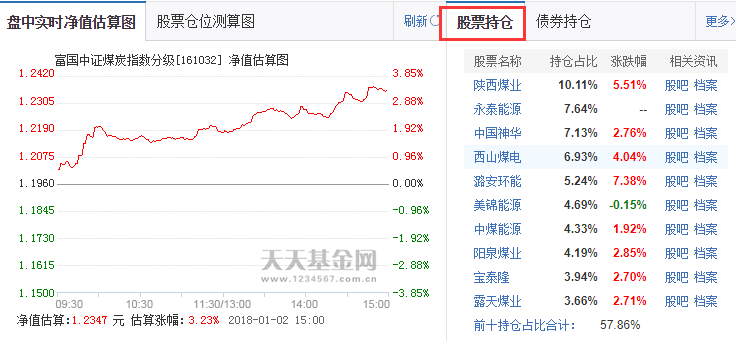
所以选择股票类型的基金后,除了读取页面信息,还应该读取链接网址。比较好的是,在分页的最右边有一个“不分页”的选项,点击后所有数据都在一页中显示,这就方便很多了!

以下是读取页面信息的脚本:
# -*- coding: utf-8 -*-
# python 3.5
import re
import time
import pymssql
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
class FUND(object):
def __init__(self):
self.url = 'http://fund.eastmoney.com/data/fundranking.html'
self.driver = webdriver.PhantomJS()
#self.driver = webdriver.Chrome("D:/Python35/selenium/webdriver/chromedriver/chromedriver.exe")
self._conn = self.GetConnect()
if(self._conn):
self._cur = self._conn.cursor()
#数据库连接
def GetConnect(self):
conn = False
try:
conn = pymssql.connect(host="HZC",user="kk",password="kk",database ="StockDB")
except Exception as err:
print("连接数据库失败, %s" % err)
else:
return conn
#执行语句
def ExecNonQuery(self, sql):
flag = False
try:
self._cur.execute(sql)
self._conn.commit()
flag = True
except Exception as err:
flag = False
self._conn.rollback()
print("执行失败, %s" % err)
else:
return flag
def GetURL(self):
print("[-] 打开网址: %s" % self.url)
self.driver.get(self.url)
def SetURL(self,url):
print("[-] 设置网址: %s" % url)
self.url = url
#股票型(641) & 不分页
def GetSelectStockType(self):
typetext = None
displaytext = None
typetext = self.driver.find_element_by_xpath("//ul[@id='types']/li[@class='at']").text.strip()
elems = self.driver.find_elements_by_xpath("//div[@id='pagebar']")
for e in elems:
displaytext = e.get_attribute('style')
return typetext,displaytext
def DoSelectStockType(self):
print("[-] 选择股票类型")
try:
#self.driver.find_element_by_xpath("//ul[@id='types']/li[2]").click()
element = WebDriverWait(self.driver,10).until(EC.presence_of_element_located((By.XPATH,"//ul[@id='types']/li[2]")))
element.click()
time.sleep(3)
except:
pass
def DoSelectShowAll(self):
print("[-] 显示所有")
try:
#self.driver.find_element_by_xpath("//input[@id='showall']").click()
element = WebDriverWait(self.driver,10).until(EC.presence_of_element_located((By.ID,"showall")))
element.click()
time.sleep(3)
except:
pass
def GetBaseInfo(self):
print("[-] 基本信息")
dict = {}
typetext,displaytext = self.GetSelectStockType()
while not re.match("股票型", typetext) or re.match("block", displaytext):
print(" waiting……")
time.sleep(1)
typetext,displaytext = self.GetSelectStockType()
#print(typetext,displaytext)
table = self.driver.find_element_by_xpath("//table[@id='dbtable']/tbody")
for row in table.find_elements_by_xpath(".//tr"):
col = row.find_elements(By.TAG_NAME, "td")
id = col[1].text
code = col[2].text
name = col[3].text
link = col[3].find_element(By.TAG_NAME, "a").get_attribute("href")
date = col[4].text
dwjz = col[5].text
ljjz = col[6].text
rzzl = col[7].text
jyz = col[8].text
jsy = col[9].text
jly = col[10].text
jyn = col[11].text
jln = col[12].text
jsn = col[13].text
jnl = col[14].text
cll = col[15].text
zdy = col[16].text
sxf = col[17].text
sql = """INSERT INTO [TTStocks]([id],[code],[name],[link],[date],[dwjz],[ljjz],[rzzl],[jyz],[jsy],[jly],[jyn],[jln],[jsn],[jnl],[cll],[zdy],[sxf])
VALUES (%s, '%s', '%s', '%s', '%s', %s, %s, '%s', '%s', '%s', '%s', '%s', '%s', '%s', '%s', '%s', '%s', '%s')""" % \
(id,code,name,link,date,dwjz,ljjz,rzzl,jyz,jsy,jly,jyn,jln,jsn,jnl,cll,zdy,sxf)
self.ExecNonQuery(sql)
dict[code] = link
print(id,name)
self.GetDetialStocks(dict)
def GetDetialStocks(self,dict):
for k,v in dict.items():
#print('%s = %s' % (k,v))
self.SetURL(v)
self.GetURL()
table = self.driver.find_element_by_xpath("//li[@id='position_shares']/div[@class='poptableWrap']/table/tbody")
text = table.find_element_by_xpath(".//tr[2]").text.strip()
if text != "暂无数据":
for row in table.find_elements_by_xpath(".//tr"):
col = row.find_elements(By.TAG_NAME, "td")
if len(col)!=0:
print(k,col[0].text)
sql = "INSERT INTO TTStocksDetial(code,name,cczb) VALUES ('%s','%s','%s')" %(k,col[0].text,col[1].text)
self.ExecNonQuery(sql)
if __name__ == "__main__":
f = FUND()
f.GetURL()
f.DoSelectStockType()
f.DoSelectShowAll()
f.GetBaseInfo()
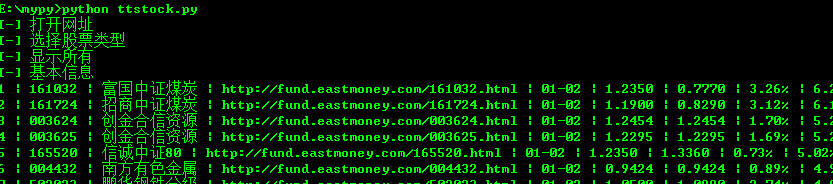
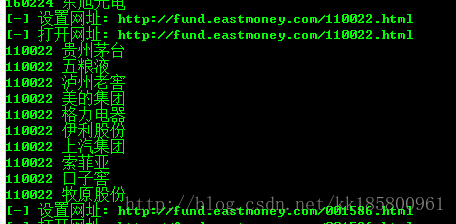
接下来这些数据将存入数据库,读取每条记录的同时,也将模拟打开链接网址,读取 “股票持仓”情况。















 2430
2430

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









