






目录
前言
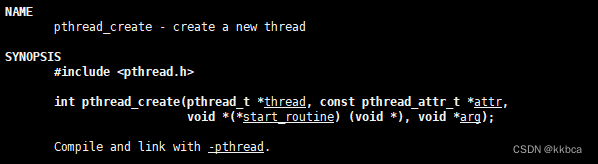
之前我们学习过Linux的线程库thread,他是使用 POSIX 标准,而Windows中的线程库,使用的其他标准,在C++11之前他们的接口是不一样的,对代码的编写就很麻烦,Linux一套,Windows一套。C++11出来之后,引入了标准的线程库,使得在不同平台上编写具有可移植性的多线程代码变得更加容易。
一、线程库的构造
之前我们创建线程,都要先pthread_t 创建一个线程tid,然后把线程id,线程属性,一个函数指针,还有参数都传递过去。如果参数较多,我们还得封装成一个结构体,把结构体地址传过去。这并不是很方便,也不是很体面。
1.默认构造
C++11提供了线程的默认构造(创建线程,但不启动)

使用方法很简单,创建即可,一般要配合移动构造使用。(后面会讲)
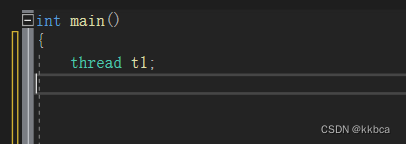
2.带参构造
带参构造,第一个参数为可调用对象(函数指针,仿函数,lambda函数,包装器)并且函数返回值并不限制,第二个参数为可变参数包,也就是我们不需要再有一个线程id,和设置线程属性,同时也不需 要再封装成一个结构体了,直接将参数传递给参数包,他自动解析就可以了。
![]()
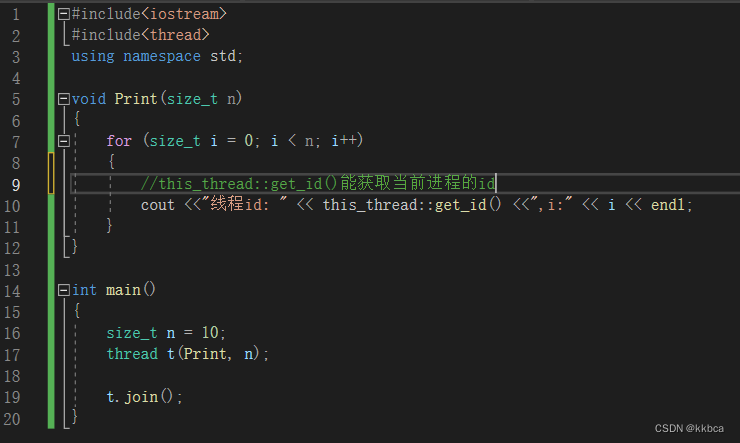
现在我们来使用一下C++11的线程构造,如下,让 t 线程去执行Print函数。其中this_thread作用域下的get_id()能获取当前进程的id。
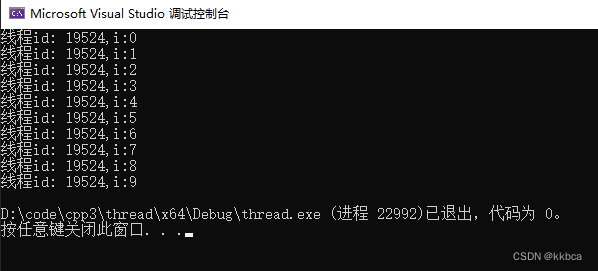
运行发现让id为19524的线程去执行了函数。
多个参数也很简单,直接传递参数即可,不再需要使用结构体。
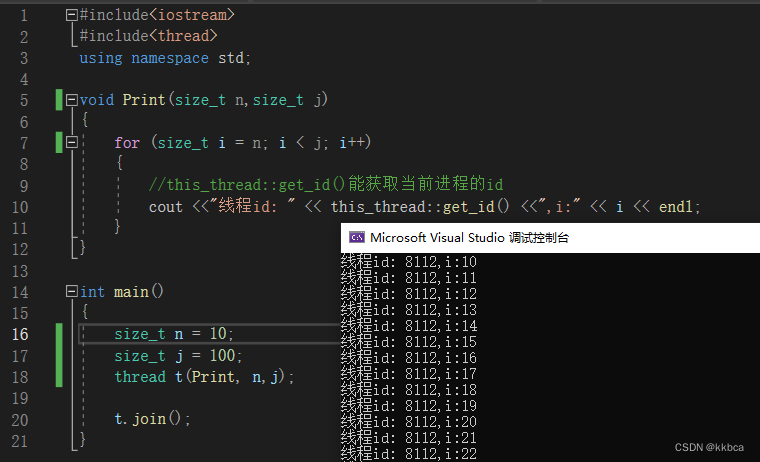
3.拷贝构造与赋值拷贝(不支持)
thread库并不支持拷贝构造与赋值拷贝,如果允许拷贝构造或拷贝赋值,那么会导致多个线程对象管理同一个底层线程,这可能会引发竞争条件和资源管理问题。
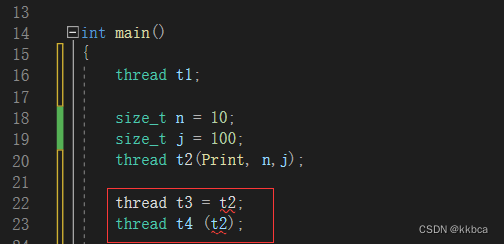
4.移动构造
线程的移动构造是在线程即将死亡(被回收)的时候,把资源给另外一个线程。因为这样线程依然只属于一个人,不会造成多个线程对象管理同一个底层线程的情况。
同时他能配合默认构造一起使用,因为默认构造,你根本都没传递函数,你怎么能让线程去处理任务呢?配合移动构造,就能让默认构造的线程也跑起来。
move是将t2转为将亡值。t1去夺舍t2。
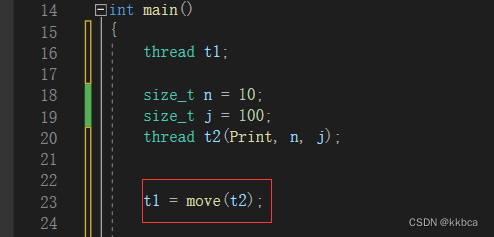
同时,这样我们也可以使用容器管理线程了。因为反正有默认构造,vector只传入 int 整形就是在进行默认构造。后面再通过移动赋值让线程运行。
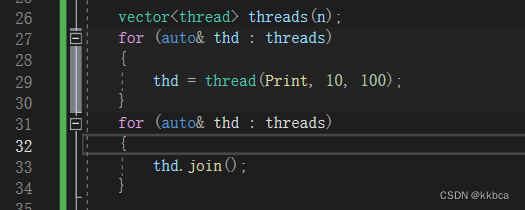
小总结:
- 带参构造,创建可执行线程
- 先创建空线程对象,移动构造或者移动赋值将右值对象转移过去
二、线程调用lambda函数
我们知道,线程需要调用一个可调用对象,让他去执行这个可调用对象,从而让线程运行起来。其中运用最多的就是普通函数和lambda函数,这是因为让线程执行任务,我们只需要把任务说明白就行,包装器更适合提取函数的类型,仿函数又不够轻量化。
线程调用lambda函数比较简单,代码如下,在lambda捕获列表进行捕获就可以了。
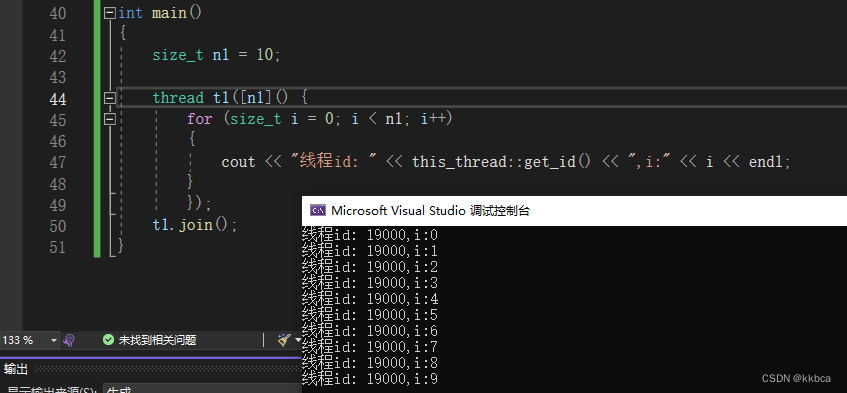
三、线程安全与锁
1.lambda中的线程与锁
我们定义一个变量,让两个线程同时去对这个变量做++操作,按道理结果应该是20000,但是有可能结果不如我们的预期,这就是多线程导致的数据安全问题,++x并不是原子操作。
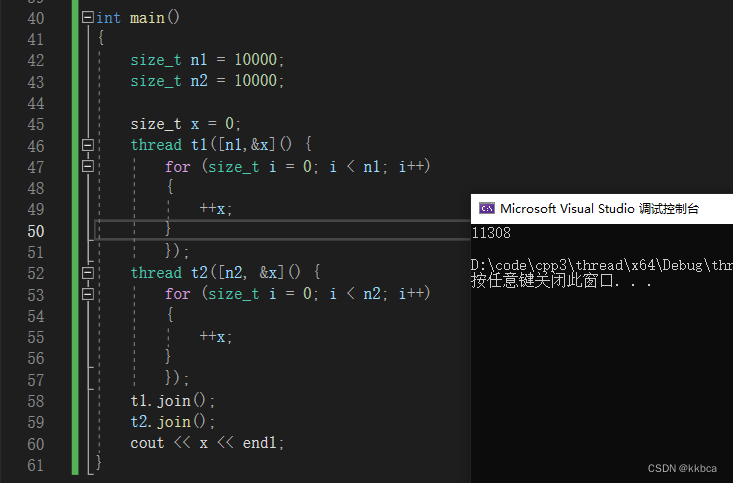
我们需要对临界资源进行上锁,来保证临界资源的安全。C++11的mutex库提供的mutex默认构造,直接使用即可

代码如下,对++x进行加锁与解锁
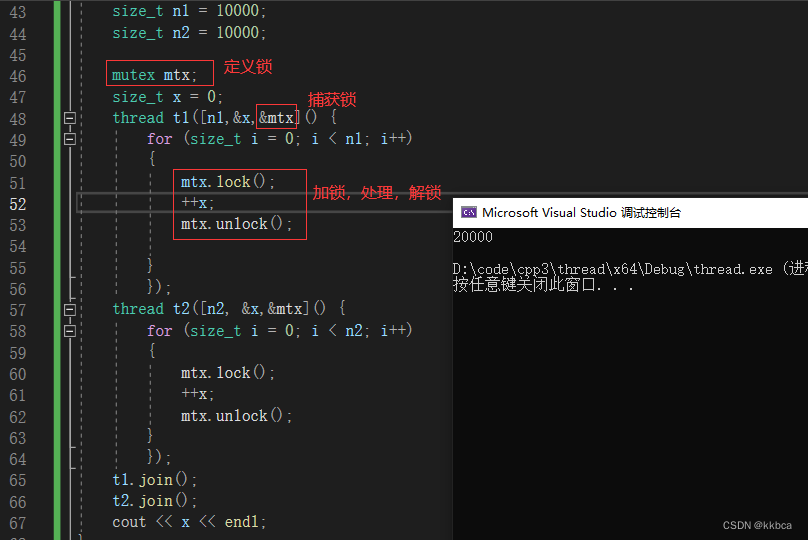
2.函数指针中的线程与锁
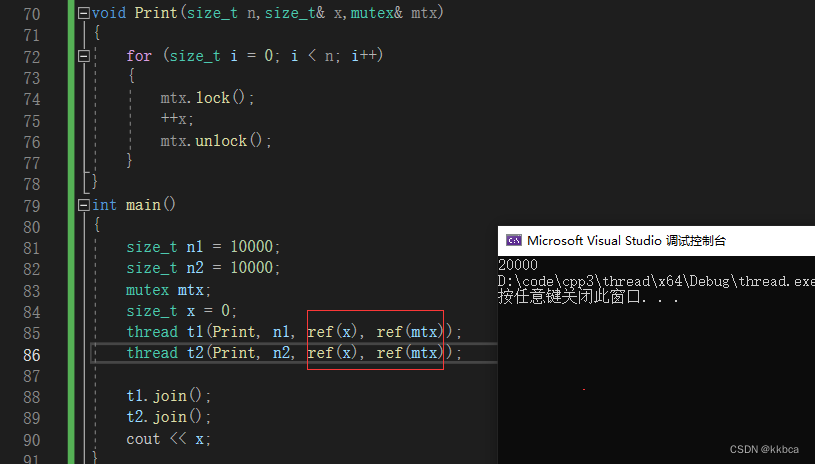
在函数指针中,我们也传递一把锁,让他去保护临界资源x,这里都传递的是引用,按照之前的学习,我们的代码是没有问题的,这里却发生报错,编译不通过。
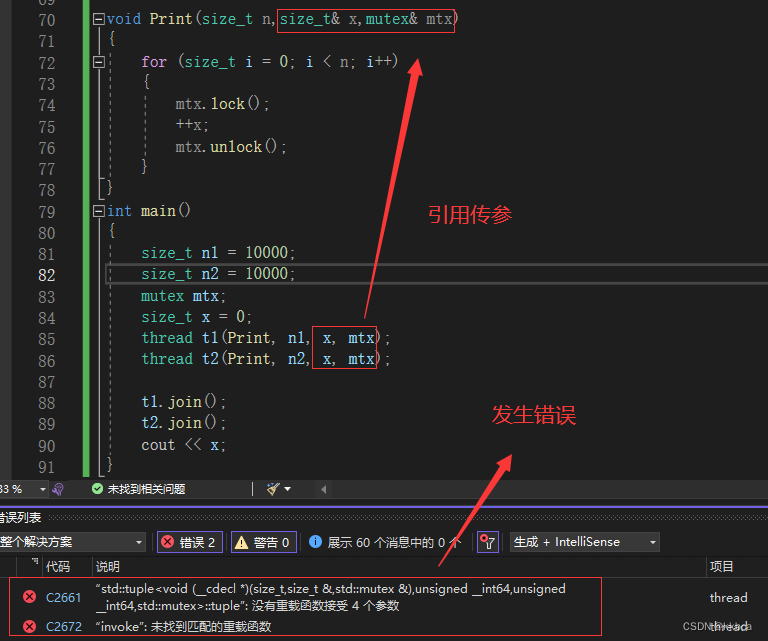
这是因为你传递的参数是传递给thread带参构造的可变参数包的,并不是我们看到的直接传参,他还会有一些处理。
thread 构造函数会对传递的参数进行拷贝或移动,然后将这些拷贝或移动后的参数传递给线程函数,导致在新线程中修改的实际是拷贝或移动后的引用,而不是原始的引用,因此会发生错误。
![]()
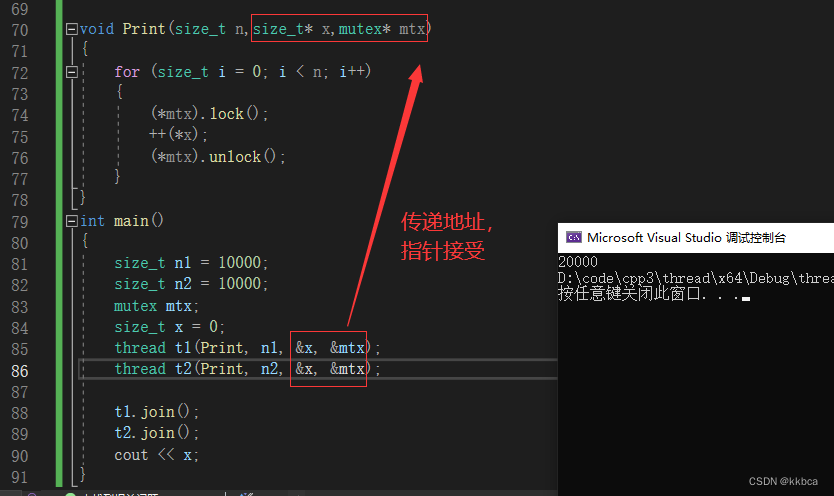
添加ref代表强制引用, 因此我们这里记住添加ref就好。
这确实比较麻烦,我们也可以选择用指针,就可以避免这些问题。
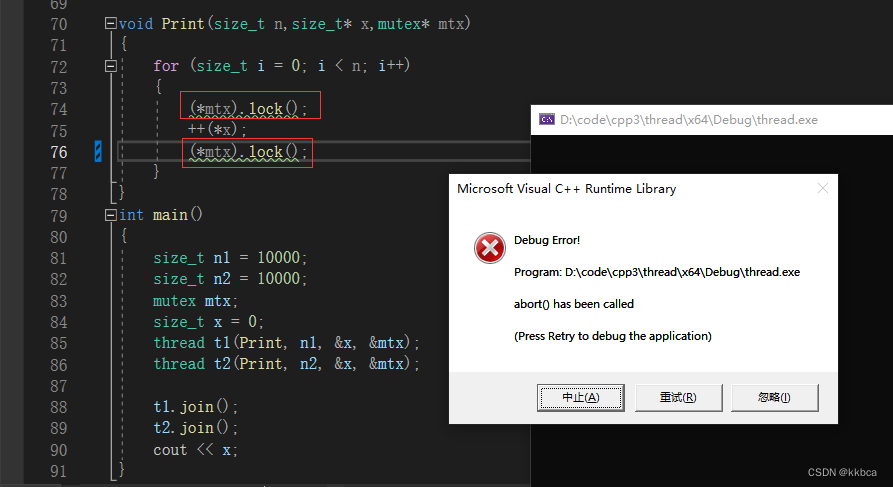
3.trylock()
锁的lock()如果现在申请不到锁,就会在锁的等待队列上等待,直到轮到了自己,才会申请锁成功。而trylock()申请锁失败不会进入等待队列进行等待,而是返回false,继续往后执行。
4.recursive_mutex
revursive_mutex是递归互斥锁,线程在持有锁的情况下,再递归调用自己的函数,如果是普通的互斥锁就会发生死锁,此时需要使用递归互斥锁,防止死锁。

5.lock_gurad守卫锁
再我们对临界资源进行加锁解锁时,可能会发生一些意外,比如把解锁写错了,写成加锁
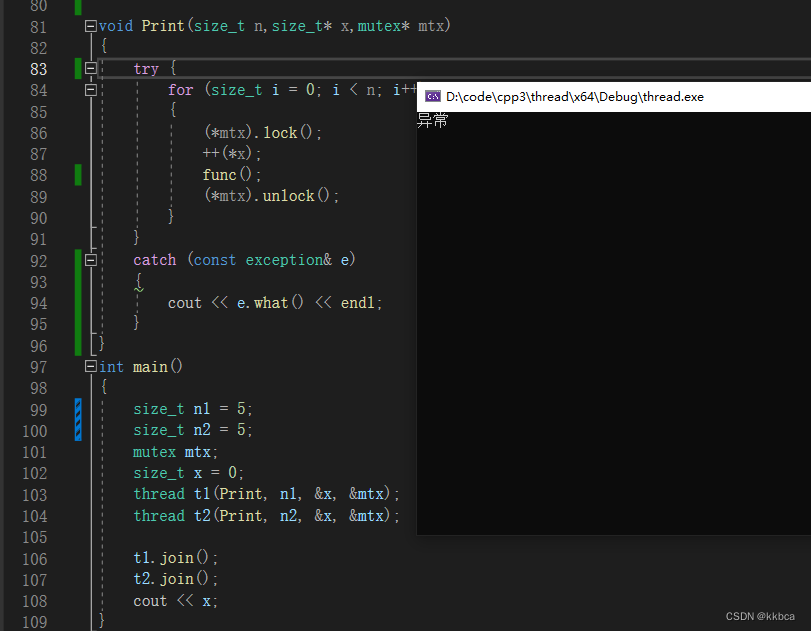
当然,这个错误比较低级,但如果临界区代码发生了异常呢?
大家看如下代码,我们在加锁与解锁中模拟了一个异常情况。

如果发生了异常,catch 块中的代码会被执行,然后程序会继续执行 try-catch 块之后的代码,而不会回到抛出异常的地方继续执行,于是我们的锁就不会解锁,后续线程想申请锁,就申请不到了,这会导致死锁的发生。
因此我们需要利用RAII的思想,使用lock_guard来守护线程,也就是把锁资源交给一个类,让类构造时申请资源,析构时自动释放资源。
使用如下代码进行mutex资源守护,注意成员变量和构造参数一定要引用,因为锁是不支持拷贝的,使用引用代表指的一直是这一把锁。
template<class Lock>
class LockGuard
{
public:
LockGuard(Lock& lk)
:_lk(lk)
{
_lk.lock();
}
~LockGuard()
{
_lk.unlock();
}
private:
Lock& _lk;
};那么线程使用上了LockGuard,出了作用域会自动析构,也就是说你catch捕获异常的时候,我就会析构了,然后释放锁资源,就不会死锁了。
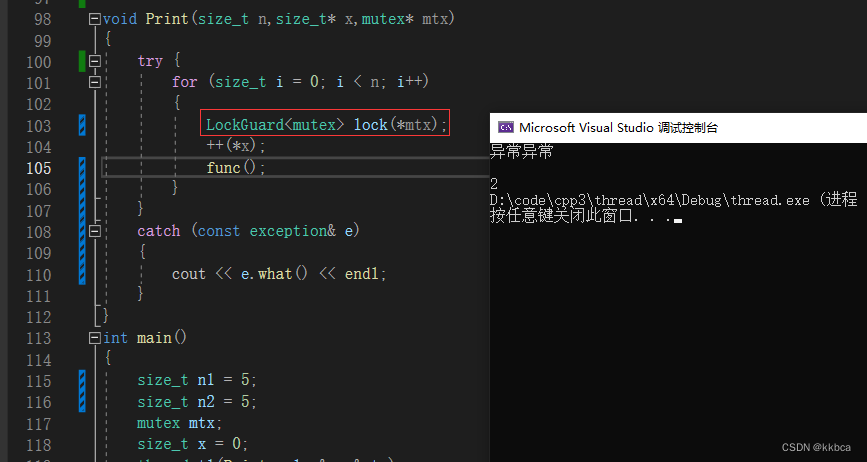
std库也给我们设计好了 lock_guard,拿来用就可以了。

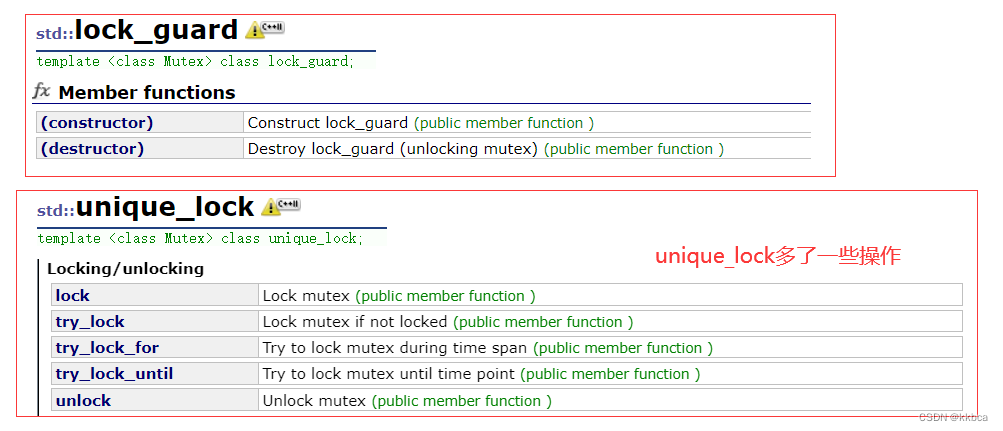
6.unique_lock
unique_lock也可以完成守卫锁的任务,他比守卫锁多了手动的加锁与解锁,同时可以与time_mutex进行配合。
四、条件变量
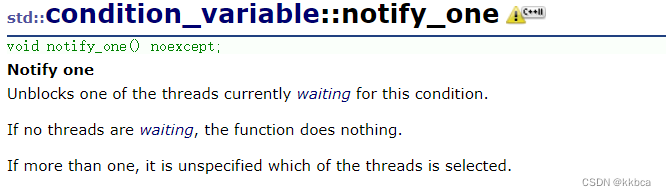
condition_variable就是条件变量,他只有默认构造。同时wait函数需要传递的锁是unique_lock类型。传入unique_lock就是要让wait先去解锁之后再去等待,lock_guard不支持手动解锁

条件变量本质就是通知,告诉等待你可以去再申请锁了。notify_one是通知某一个线程,notify_all通知所有线程。如果没有线程等待,就不做处理。
如下代码,就运用了条件变量,实现让线程1线程2轮流打印。
首先是使用unique_lock进行加锁,一开始flag为false,因此t1线程不会去等待,肯定是t1线程先打印,再将flag置为true,再通知t2线程。
此时t2线程要么在锁的地方阻塞住,要么就比t1线程更先运行,已经判断过flag为 false了,在wait中进行等待,被通知了就继续运行了,因此就可以实现交替打印了。
#include<iostream>
#include<thread>
#include<vector>
#include<mutex>
using namespace std;
int main()
{
int n = 20;
bool flag = false;
mutex mtx;
condition_variable cv;
thread t1([n, &flag,&mtx,&cv] {
for (int i = 1; i <= n; i++)
{
if(i%2==1)
{
unique_lock<mutex> lock(mtx);//加锁,出作用域自动解锁
if (flag)
{
cv.wait(lock);//wait先解锁在去等待队列等待
}
cout << i << endl;
flag = true;
cv.notify_one();//信号变量通知其他线程取消等待
}
}
});
thread t2([n, &flag, &mtx, &cv] {
for (int i = 1; i <= n; i++)
{
if (i % 2 == 0)
{
unique_lock<mutex> lock(mtx);//加锁,出作用域自动解锁
if (!flag)
{
cv.wait(lock);//wait先解锁在去等待队列等待
}
cout << i << endl;
flag = false;
cv.notify_one();//信号变量通知其他线程取消等待
}
}
});
t1.join();
t2.join();
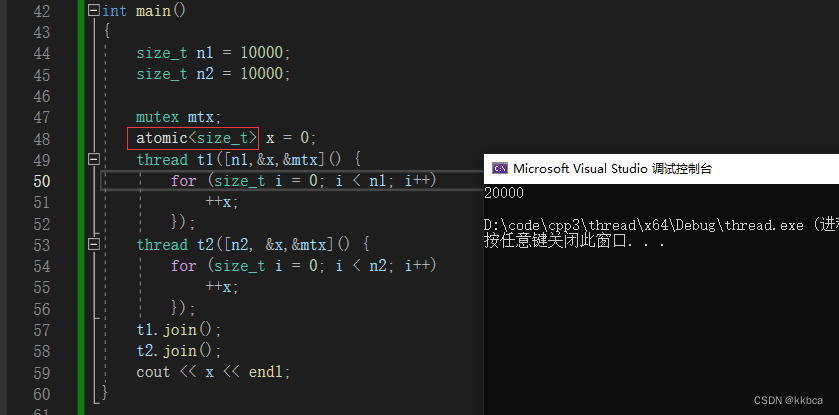
}五、atomic
前面我们的代码临界区都不算很长,此时使用互斥锁的效率就会变得很低,因为互斥锁保证原子操作,会导致线程切换时间片浪费的情况。
比如线程 thread_1 加锁了,正在++x,还没有解锁,此时时间片到了。被切换了,线程 thread_2 来了,想去申请锁,却一直申请不到,就会在等待队列等待,白白浪费了自己的时间片。C++11提供了atomic来保证变量的原子性。

当然,只建议对内置类型的处理,如果传入的类型是自定义类型,代码比较长的话,那还是用互斥锁吧。
他主要设计到了CAS(compare and swap)操作,如下代码代替了++x;
其中 atomic_compare_exchage_wead 用于比较并交换操作。它用于在原子方式下比较内存中的值&x和给定的期望值&old,如果它们相等,则将新值newval写入内存,并返回 true;否则不写入,并返回 false。
也就是会再去检查内存中x的值,发现是x==old的,证明此时其他线程并没有参与进来,那么你写入新值返回true就完事,如果发现内存中x的值与old不相等,也就不会写入并返回false。
六、shared_ptr的多线程问题
我们知道,多个 shared_ptr 可以共同拥有同一个对象,这里面有一个引用计数。当我们去拷贝shared_ptr的时候,都会对该引用计数进行++操作。
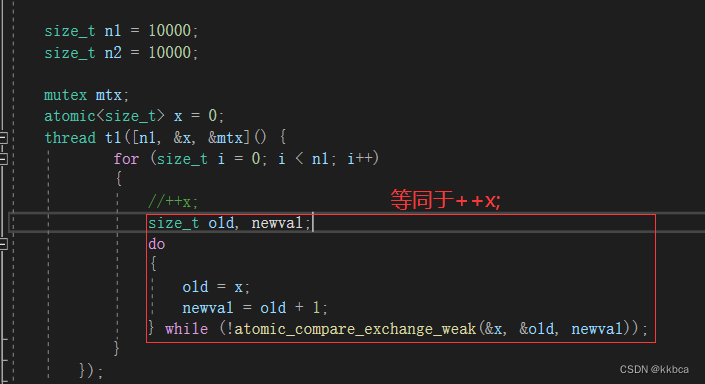
如果是多线程的情况下,去拷贝会不会发生问题呢?
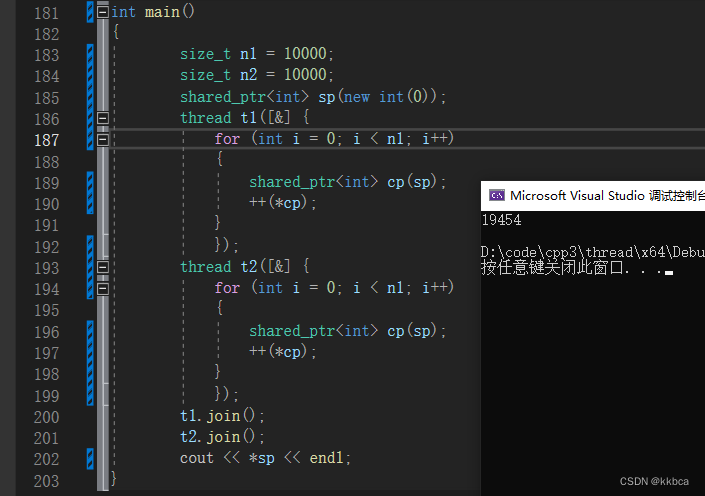
如下代码,本应该对 (*sp)++了20000次,结果却不是20000。
当我们对资源加锁后,发现*sp的值就是我们预想的了。
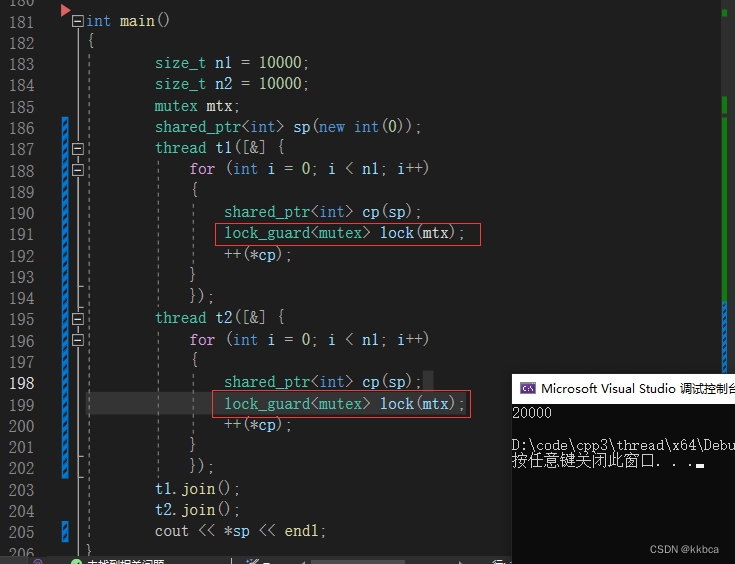
由此可得出结论:shared_ptr本身是线程安全的,但是他保护的资源不是线程安全的。
七、懒汉模式中的线程安全问题
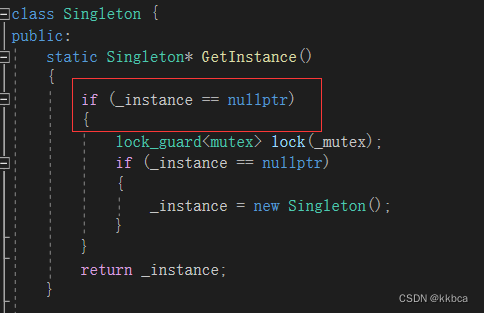
懒汉模式是在需要时才会创建对象实例,而不是在程序启动时就创建,因此我们之前只有一个执行流执行的时候,只需要判断他的成员变量指针 _instance 是否为空就可以了,为空就创建再返回,不为空就直接返回该指针。

但如果是多线程的情况,可能有很多线程一起起来访问,可能会执行很多new Singleton()。导致数据不一致问题,因此我们得进行加锁。
但如果仅仅是加锁,那么每次线程调用GetInstance()的时候都要去申请锁,效率会很低下。

因此我们可以再在最外层判断一下_instance是否为nullptr,双重保险,让效率提升,如果不为nullptr,那么就直接返回,不用再申请锁了。















 2342
2342

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









