







 本文探讨了无主节点备份的数据库系统,如Dynamo-style的Cassandra、Riak和Voldemort。无主节点备份允许所有节点接收写入,提供高可用性和低延迟,但也带来了并发写入和数据一致性挑战。通过Quorum Consistency、Sloppy Quorums和Hinted Handoff等机制,系统尝试在可用性和一致性之间找到平衡。同时,文章还讨论了并发写入的检测和处理,如Last Write Wins策略和版本向量在处理并发冲突中的作用。
本文探讨了无主节点备份的数据库系统,如Dynamo-style的Cassandra、Riak和Voldemort。无主节点备份允许所有节点接收写入,提供高可用性和低延迟,但也带来了并发写入和数据一致性挑战。通过Quorum Consistency、Sloppy Quorums和Hinted Handoff等机制,系统尝试在可用性和一致性之间找到平衡。同时,文章还讨论了并发写入的检测和处理,如Last Write Wins策略和版本向量在处理并发冲突中的作用。
无主节点备份
目前讨论的备份方法都基于这样一个想法,客户端将写入请求发送至一个节点,然后数据库系统将写入备份至其他节点;主节点决定了写入顺序。
一些数据库系统采用了其他方法,允许所有节点接收客户端的写入,无主从节点之分,也就是无主节点。这个想法在关系型数据库时代几乎被遗忘。它曾经在Amazon用于内部的 Dynamo系统后流行过, Riak, Cassandra, 和Voldemort这些无主节点备份模型也受Dynamo启发,这类数据库称为Dynamo-style。
一些无主节点的实现中,客户端直接将请求发送至多个节点,然后由调节节点发送至剩下的节点,不同于主节点,调节节点不会强制写入顺序。我们会看到,设计上的不同会有用途上的极大差异。
在节点停机时写入数据库
假设一个数据库有三个备份,如果是采用主从结构备份,主节点故障时,故障转移后才能继续写入数据库。在无主节点模式下,不需要故障转移,写入会平行发送至所有的三个节点,两个节点收到请求,故障节点丢失了;我们认为单个备份中有两个收到则写入成功,客户端忽略掉故障节点,如图5-10:

如果故障节点恢复了,客户端开始从该节点读取,那么客户端会收到过时的数据。为应对这个问题,客户端会同时向三个节点发送请求,或从正常节点那里收到最新的数据,从刚恢复的节点那里收到过时的数据,然后使用版本数据判断哪个值是最新的。
读取修复和负熵
备份模式应该保证最终所有节点上的数据相同,当一个故障节点重新加入集群,它该如何赶上丢掉的写入?
有两种机制:
写修复:当客户端平行地从多个节点读取时,会探测到哪个返回的数据是过时的。如图5-10, 用户2345从节点1,2读取到版本7的数据,从节点3读取到版本6的数据,可以判断节点3上的数据是过时的,然后将新值写入节点3。这个方法适用于读频繁的系统。
负熵进程:一些数据库系统有后台进程持续检查各个备份间的数据差异。不同于有主节点的日志备份系统,负熵进程复制数据是无顺序的,而且复制完成前的延迟很长。
不是所有的系统都能实现两种机制。没有负熵进程,读取很少的系统一些备份可能会丢失值,因为只有读取应用才会进行读取修复。
Quorums for reading and writing
在例5-10中,如果三个节点中有两个写入成功,那么判断写入成功,如果三个中只有一个成功呢?我们如何推断?
如果我们知道三个中有两个写入成功,那么可以判断至多只有一个节点写入失败;如果从至少两个节点读取,那么可以保证读取到的节点至少有一个是最新的,不论第三个节点是故障或者响应慢,我们保证能获取到最新的值。
假设有n个节点,每次写入保证至少w个节点写入成功,每次至少从r个节点读取数据,示例中n=3,w=2,r=2. 只要w+r>n, 我们预计能在读取时获取最新的值,因为读取的节点至少有一个是最新的。r和w被分别称为读取和写入的quorum。
在 Dynamo类型数据库中,参数n,w,r一般是人为配置的。一般n设置为奇数,w和r等于(n+1)/2. 当然也可以视情况而定,比如在读取频繁的系统中,可以设置为w=n,r=1,这能加快读取,但是只要一个节点故障,系统的写入就停止了。
满足w+r>n的条件,可以让系统允许以下故障:
如果 w<n, 我们可以在一个节点不能用的情况下处理写入。
如果 r< n, 我们可以在一个节点不能用的情况下处理读取。
n=3,r=2,w=2的情况,我们可以允许一个节点故障。
n=5,w=3,r=3的情况,我们可以允许两个节点故障,如图5-11
一般而言,读取和写入会同时发送至n个节点,w和r参数决定了我们要等待多少个节点,比如,我们在读取和写入时需要等待多少个节点回复操作成功。

如果操作节点数少于w或r,那么读取或者写入就返回失败。操作失败的原因很多,我们只需要判断成功与否,而不需要辨别原因。
Quorum Consistency的限制
如果有n个节点,设置参数时保证w+r > n,可以保证写入的节点和读取的节点会互相覆盖,这样至少有一个节点上是最新的值。但是即便是w+r > n,在一些边缘情况下,也会返回旧值。
1、如果使用 Sloppy Quorum,可能在w节点上写入,在r个节点上读取,写入和读取之间没有交集。
2、如果同时发生两个写入,那么安全的方法就是合并写入。如果使用时间戳来节点哪个写入胜出,那么可能会因为时钟偏移而丢失写入。
3、如果写入时同时发生读取,这是写入可能只发生在部分节点上,这种情况下,没法确定是否返回最新值。
4、如果写入只在部分节点上成功,并且总共写入成功的节点数少于w,写入成功后也不会回滚。这意味着如果少量节点报告写入错误,那么接下来的写入可能返回旧值,也可能返回新值。
5、如果一个有着新值的节点故障了,恢复数据后带着旧值,那么节点中有着新值的节点数就小于w,这就破坏了Quorum条件。
6、即便一切工作正常,还是会碰到一些极端例子。
因此Quorum表面上能保证能获取到最近写入的值,但是事实上没有那么简单。参数w和r只能降低读到旧值的概率,不能提供绝对的保证。
Sloppy Quorums 和 Hinted Handoff
合理配置quorums的数据库不仅能允许几个节点的故障(不需要进行故障转移),也能容忍几个节点的缓慢的回复。因为请求不需要等待n个节点全部做出回复,只需要w或者r个节点回复即可。这些特性让无主节点配置的配置能够有高可用和低延迟。
但是quorums并不能像想象中的能容纳故障。一个网络中断就能切断客户端和大量数据库节点的连接。尽管那些节点依然存在,但是对于客户端而言,看不到的节点已经故障。剩下的数量可能小于w或者r,客户端没法达到quorum的条件。
在大的集群中,客户端可能因为网络问题只能联系到部分节点,因而达不到quorum条件,那么在数据库设计者面前有一个权衡:
1、对于无法达到quorum条件的读取和写入都返回错误。2、或者任何时候都接受写入,存储到客户端能联系上的节点,但是并不属于配置中的n个节点,也就是quorum配置外的额外的节点。
第二个被称为sloppy quorum:读取和写入依然需要w和r个成功恢复才能判断成功,但是可以包含设计的n个节点(称为 home)之外的节点。打个比方就是,你把自己锁在外面了,但是你可以在邻居家的沙发上借宿一晚。
一旦网络问题修复了,存储在临时节点上的写入会被发送到合适的“home”节点。这被称为 hinted handoff。(你拿到钥匙后就可以回家了)
Sloppy quorums对于应对持续增长的写入要求很有用,只要有w个节点可用就可以写入。但是这意味着有时即便是满足w+r>n,也不能保证拿到最新值,因为最新值可能存储在额外的节点上。因此 Sloppy quorums不是传统的quorums,在hinted off完成前不能保证正确的读取。
Dynamo类型数据库中,quorums一般是可以选择的。在Riak中是默认使用的,在 Cassandra 和 Voldemort中默认是禁用的。
多数据中心操作
我们之前讨论过多数据中心使用多主节点备份方式。无主节点的情况,适用于多数据中心的操作。
Cassandra 和 Voldemort在无主节点模型的框架内实现的多数据中心的操作是:n包含所有数据中心的所有节点,并且可以配置一个数据中心的n值。每个写入会发送到所有的节点,客户端需要等待本地数据中心一定数量的节点的返回值,这通常不受跨数据中心的延迟和中断的影响。
Riak维护客户端和本地的一个数据中心的连接,n描述的是一个数据中心的节点数。跨数据中心备份是在后台异步进行,类似于多主节点备份。
检测并发写入
Dynamo允许多个客户端同时写入相同的键,这意味着写入冲突,在读取修复和 hinted handoff时也会出现冲突。
问题就是因为网络延迟的部分节点错误,不同的写入会以不同的顺序到达不同的节点。如图5-12:
节点1收到写入,但没有收到B;节点2先收到A,再收到B;节点3先收到B,再收到A。

如果节点只是按照接收顺序写入,就没法达到最终一致。如何达成最终一致?一个期望是数据库系统能自己实现,但是遗憾的是,目前绝大多数的实现方法都很难达到目的,如果你想避免丢失数据,需要深入理解数据库内部是如何处理冲突的。后续会介绍一些处理冲突的方法,先看看一些问题。
Last write win 最终写入胜出(丢弃并发写入)
一个达到最终一致的方法就是声明节点只需要存储“最近”写入的值,丢弃掉或者覆盖掉“旧”值。因此,只要有方法定义“最近”,就能达到最终一致。
“最近”这个说法其实有误导,比如图5-12,客户端并不知道那个写入先发生,说哪个先发生并没有什么意义,我们可以说这些写入都是“并发”,顺序未定。
即便是写入没有顺序,我们也可以定义它们的顺序。例如我们可以给每个写入打上时间戳,时间戳最大的就是“最近”的写入,然后丢弃掉其他的写入。这个冲突解决算法,称为last write wins(LWW)。 Cassandra只支持这种算法,Riak中是可选的方法之一。
LWW能达到最终一致,但是代价就是损失持久化性:即便是有多个写入修改相同的键值,写入都返回成功,但是实际只有一个写入成功,其他的都丢弃掉了。而且也可能丢弃掉非并发值,后续会讨论。
如果是类似缓存这种允许丢失数据的场景,丢弃写入是可以接受的场景,可以使用LWW;如果是不能接受数据丢失的场景,就不要使用了。
使用LWW唯一安全方式就是确保每个键值只会被写入一次,然后维持不变,因此避免后续的冲突。例如,一个推荐使用 Cassandra的方式是使用UUID做为键值,这样每个写入操作都有唯一键值。
“happens-before”关系和并发
我们如何决定两个操作是否是并发?可以看一些例子
1、在图5-9中,两个写入操作不是并发的:A的插入操作先于B的增长操作,因为B要增长的值是A操作插入的。换句话说,B的操作是在A操作上构建的,所以B操作必须晚于A发生,我们称B逻辑上依赖A。
2、在图5-12中,两个操作是并发的:一个客户端开始操作时,并不知道另一个客户端也在操作,他们之间没有逻辑依赖。
如果B知道A,或者依赖A,或者在A之上构建,那么A先行发生于B。一个操作是否先行发生于B决定是否是并发操作。实际上我们可以简单认为,操作间没有先行发生关系,那么它们就是并发的。
因此,如果有两个操作A,B,它们之间有三种关系,A先于B,B先于A,A与B并发。我们需要算法来判断两个操作是否是并发。如果操作是先行发生关系,那么先进行的操作会被后续操作覆盖掉,如果是并发关系,我们需要解决冲突。
捕捉先行发生关系
我们来看看一个算法如何决定两个算法是并发的,或者是先行发生。先看看只有一个节点的情况,再推广至多个节点的无主节点的数据库。
图5-13显示了两个客户端同时向相同购物车添加货物的场景:开始是空购物车,两个客户端做了5次写入:
1、客户1添加milk,这是第一次写入,数据库写入成功然后设置版本号1,然后回应操作成功和版本号1.
2、客户2添加egg,不知道客户1同时添加了milk(客户2认为egg是第一个加进购物车的)。服务端给写入设置为版本2,然后分别存储milk和egg为不同的值。然后将两个值都返回给客户端,并且返回版本号2.
3、客户1看不见客户2的写入,添加flour,所以认为购物车中应该为[milk, flour]。 将版本号1和值发送至服务端。服务端能从版本号分辨出写入[milk,flour]接替先前的写入[milk], 但是与[egg]产生并发。因此将[milk,flour]设置版本号3,覆盖掉版本号1的写入[milk],保留版本号2 [egg],然后将版本号2,3的值都返回给客户端。
4、同时客户端2添加了ham,没有意识到客户1添加了flour。客户2上次接收了egg和milk,所以购物车最后合并为[ham,egg,milk]。将这个值和版本号2发送给服务端。服务端检测到版本号2,覆盖了[egg],但是和[milk,flour]并发,所以剩下的两个值是版本号3的[milk, flour],版本号4的[egg, milk , ham]。
5、最后客户1添加bacon。它之前收到了[milk,flour]和[egg],合并后为[milk,flour,egg,bacon],然后将合并后值和版本号3发送至服务端。这覆盖掉了[milk,flour],但是与[ham,egg,milk]并发,所以服务端保存了两个并发值。

数据流如图5-14所示,箭头表明哪个操作先于哪个操作,客户端没有从服务端拿到最新的值,因为永远有其他并发操作,但是旧数据最终被覆盖,没有丢失值。
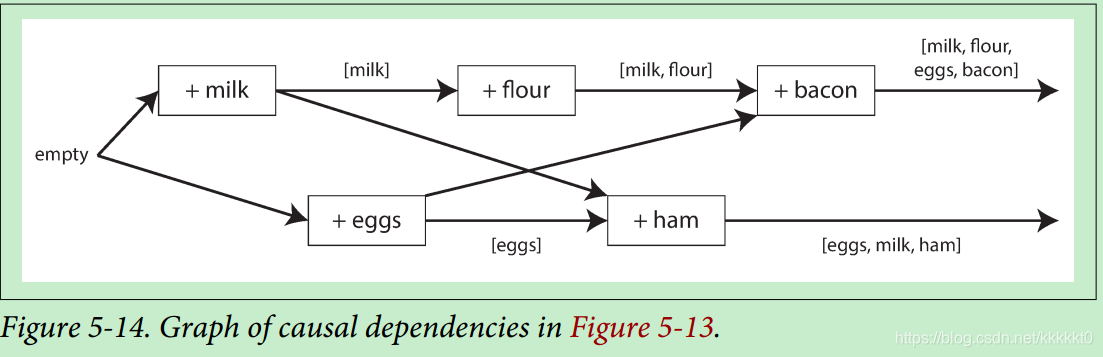
注意,服务端通过版本号来判断两个操作是否并发,算法如下:
1、服务端给每个键维护一个版本号,每次写入时都会增加,然后将新值和版本号一起存储。
2、当客户端读取键时,服务端返回未被覆写的值和最新的版本号。客户端在读取前必须读取版本号。
3、当客户端写入键时,必须包含上次读取到的版本号,必须合并上次读取到的值(写入请求的返回就类似读取,返回所有并发值)。
4、当服务端接收到带有版本号的写入时,它可以覆盖掉相同或者较低版本号的值(因为以及合并过新值了),但是必须保留更高版本号的值(那些值是并发写入)。
当写入带有版本号,这能告诉我们这次写入依赖的前置状态是什么。如果写入没有版本号,那么它和其他值产生并发,不会覆盖任何值,会作为后续读取值的一部分。
合并并发写入值
算法保证不会暗地里删掉数据,但是需要向后合并并发写入的值,Riak称这些值为“同辈”siblings。
合并同辈值类似于处理多主节点备份中的冲突,简单的方法是依据时间戳或者版本号选择一个值,但是这会丢失数据。在购物车例子中,一个合理的合并方法就是union。如图5-14,两个最后的同辈值是 [milk, flour, eggs,bacon] 和 [eggs, milk, ham],合并后为 [milk, flour, eggs, bacon, ham]。
但是如果只是允许添加物品,而不允许删除物品,就会出问题。如果合并前,用户在购物车中删除了某个物品,同时另一个同辈值包含了这个物品,那么合并后,被删除的物品还是会添加进购物车。为了避免这个问题,需要给在合并时要删除物品打上删除标记,称为 tombstone,墓石。
因为处理合并的代码很复杂而且容易出错,需要设计一些容易处理自动处理合并的数据结构。例如Riak的称为CRDT的数据结构能够合理地合并数据,包括保留删除项。
版本向量
图5-13只用了一个节点。使用多个节点,且无主节点时算法会有什么改变?
图5-13使用了一个版本号来捕捉操作间的依赖关系,在多节点的情况,这是不够的。我们需要给每个节点上的每个键准备一个版本号。每个节点在写入的时候增加版本号,然后跟踪其他节点上的版本号,这个信息表明哪些值要覆写,哪些值要保留为同辈。
所有节点上的版本号的集合称为版本向量,version vector。一个很少使用但是很有意思的变体为: dotted version vector(Riak使用它)。非常类似我们之前看的购物车的例子。
类似图5-13的例子,客户端读取的时候,服务端会同时发送版本向量,然后写入时,客户端需要同时发送版本向量,让服务端确认写入时覆写还是并发。
类似于单节点的例子,应用需要合并同辈值。版本向量保证了从一个节点读取然后写回其他节点的操作的安全性。这样会产生同辈值,但是只要正确合并,就不会丢失数据。
总结
这章我们看到了备份问题。备份有如下目的:
高可用:维系系统运作,即便是一个或数个机器停机
断联操作:允许客户端在网络中断的情况下工作
延迟:让用户再地理上靠近数据,加快交互速度
可扩展:能够处理单一机器无法处理的高写入量
尽管目标很简单——在多个机器上维护相同数据的备份,但是备份被证明是相当麻烦的。需要仔细考虑并发问题和任何事情都出错的情况。最少需要处理部分节点不可用的情况和网络问题(这还没有算上更隐蔽的问题,比如因为软件bug而导致的数据损坏)。
我们讨论了三种备份方式:
单主节点备份:客户端将所有的写入发送至一个节点(主节点),然后主节点将数据发送至其他节点,可以从任何节点读取数据,但是从节点读取的数据可能不是最新的。
多主节点备份:客户端将写入发送至多个主节点。主节点将数据发送至其他从节点。
无主节点备份:客户端将写入同时发送至多个节点,以及同时从多个节点读取,为了检测和纠正过期的数据。
每个方法各有优劣。单主节点很流行,因为结构简单,不需要担心并发问题。多主节点和无主节点鲁棒性更强,更能应对节点故障,网络问题和延迟,代价是很难满足合理性,以及提供较弱的一致性保证。
进行备份可以是同步的,也可以是异步的,这对于系统应对故障的方式影响很大。仅管异步备份在系统平缓运行时很宽,但是需要考虑延迟增长时和服务故障时的问题。如果主节点故障,你可以将一个从节点选举为新的主节点,但是最近提交的数据可能丢失。
我们看到了备份延迟带来的问题,以及讨论了一些有助于应对延迟的一致性模型:
写后读取一致:用户应该永远能看到自己提交的数据。
单调性读取:用户在某个时间点看到的数据,不应该让用户再哪个时间点前看到。
前缀一致读取:用户看到的数据要满足合理的顺序,例如,看到提问先于回答。
最后,我们讨论了多主节点和无主节点备份方法带来的并发问题:因为它们允许多个写入同时进行,可能产生冲突。我们测试了一个算法来决定一个操作是否先于其他操作或者它们是并发的。我们也接触了一些方法用于合并并发更新来解决冲突。

















 1281
1281

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









