






零、准备步骤
1.下载VM

2.下载Centos镜像

3.下载hadoop
4.下载FinalShell

5.下载jdk文件
![]()
6.下载hive,数据仓库学习大数据专业的用的到
![]()
一、开始安装虚拟机(按着步骤顺序安装)


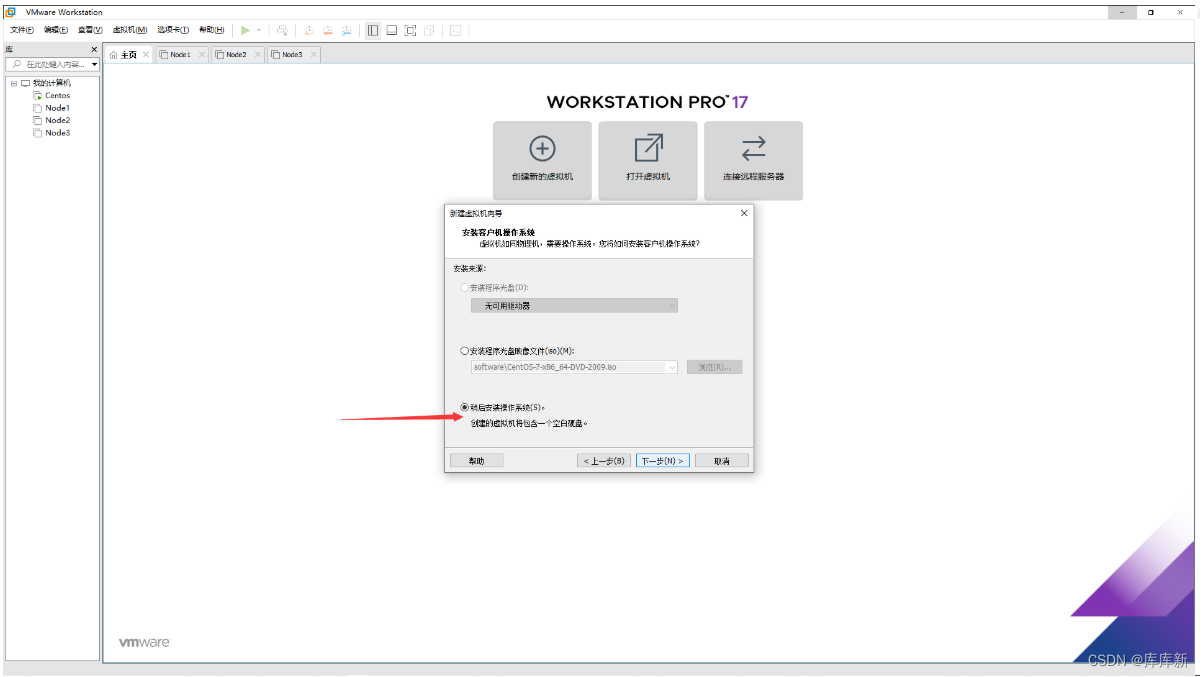



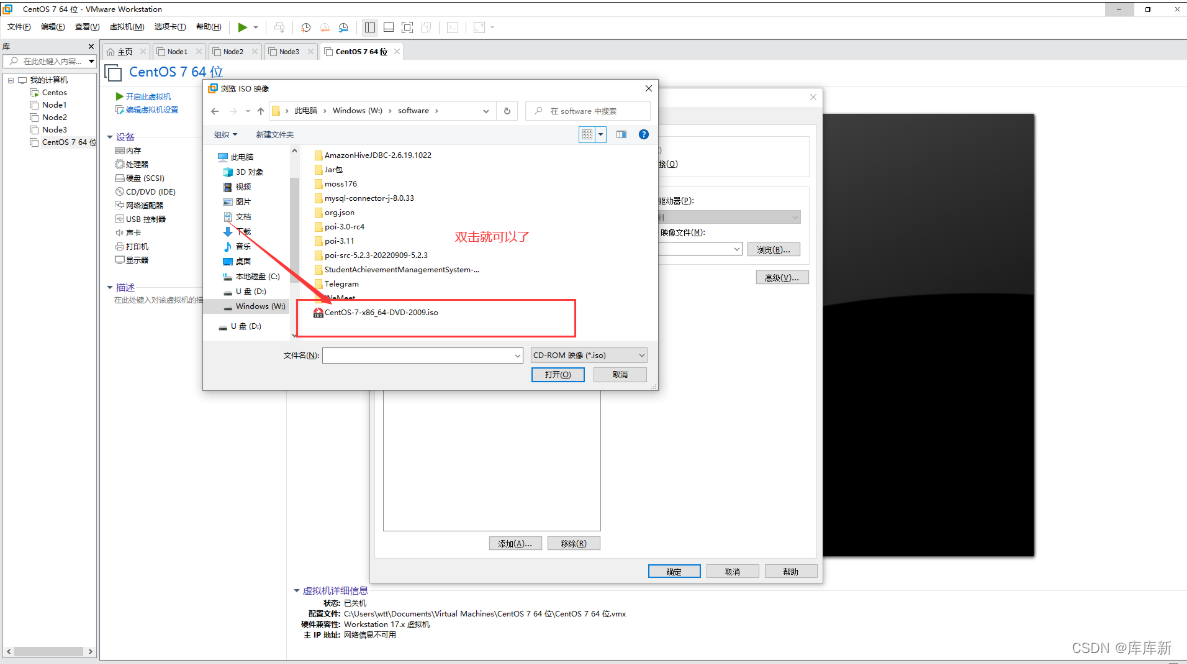
注:开启虚拟机把鼠标放入屏幕点击后消失,使用键盘上下键进行选择
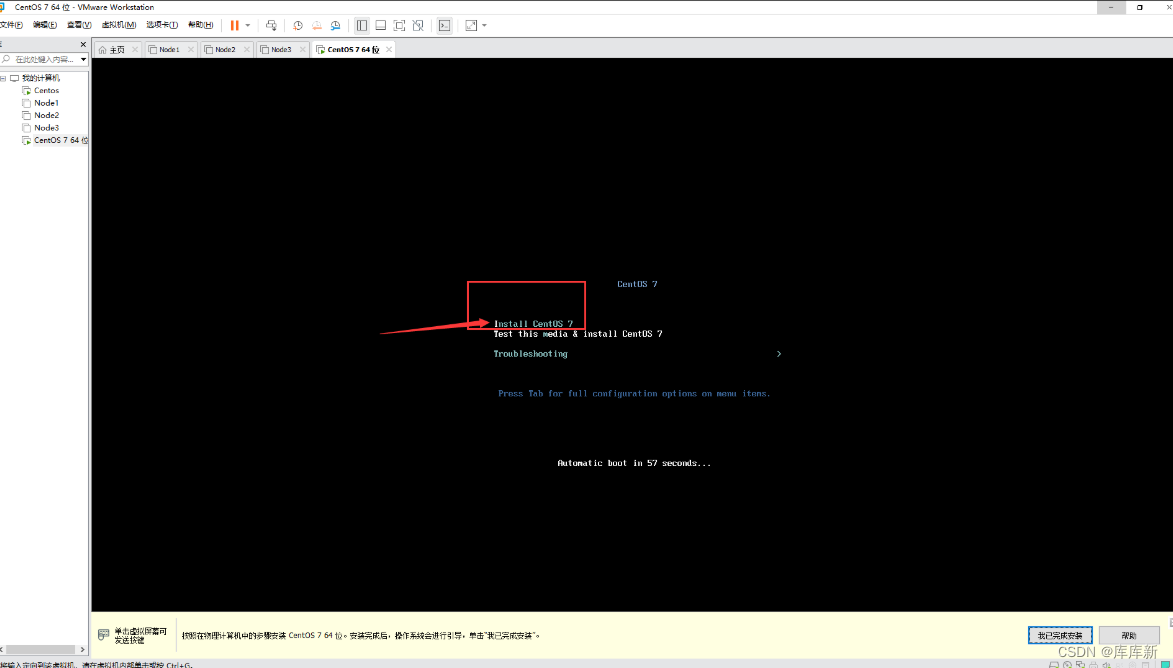

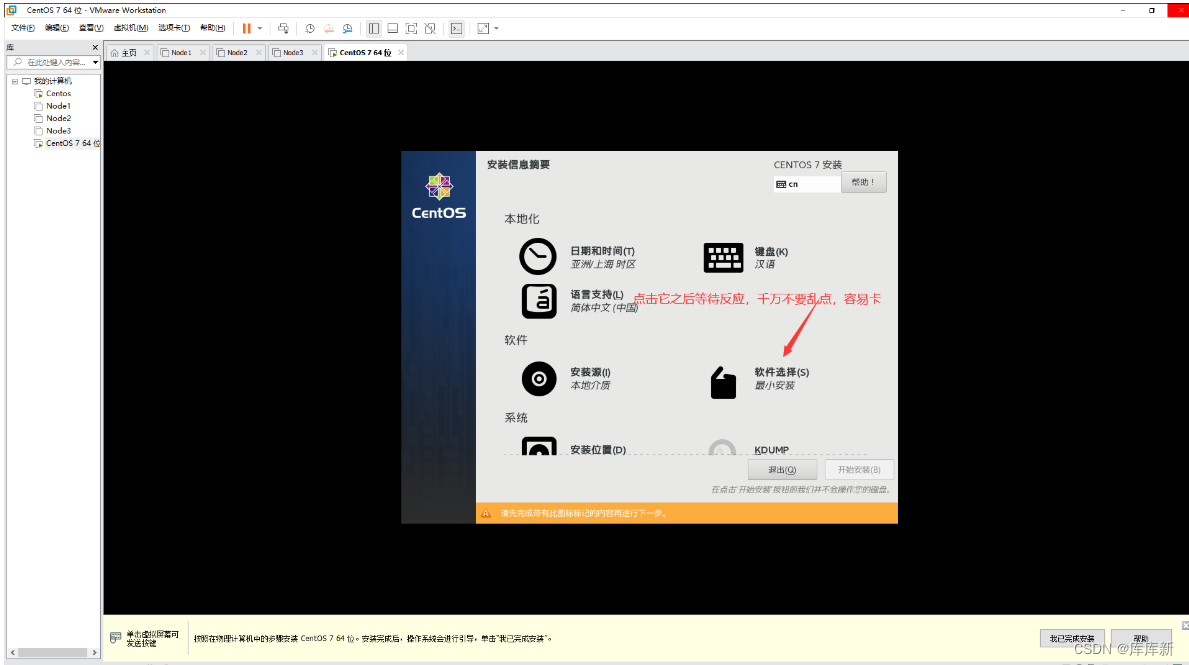


注:点击之后,什么都不动,再点击完成(因为它自动帮我们分区了)
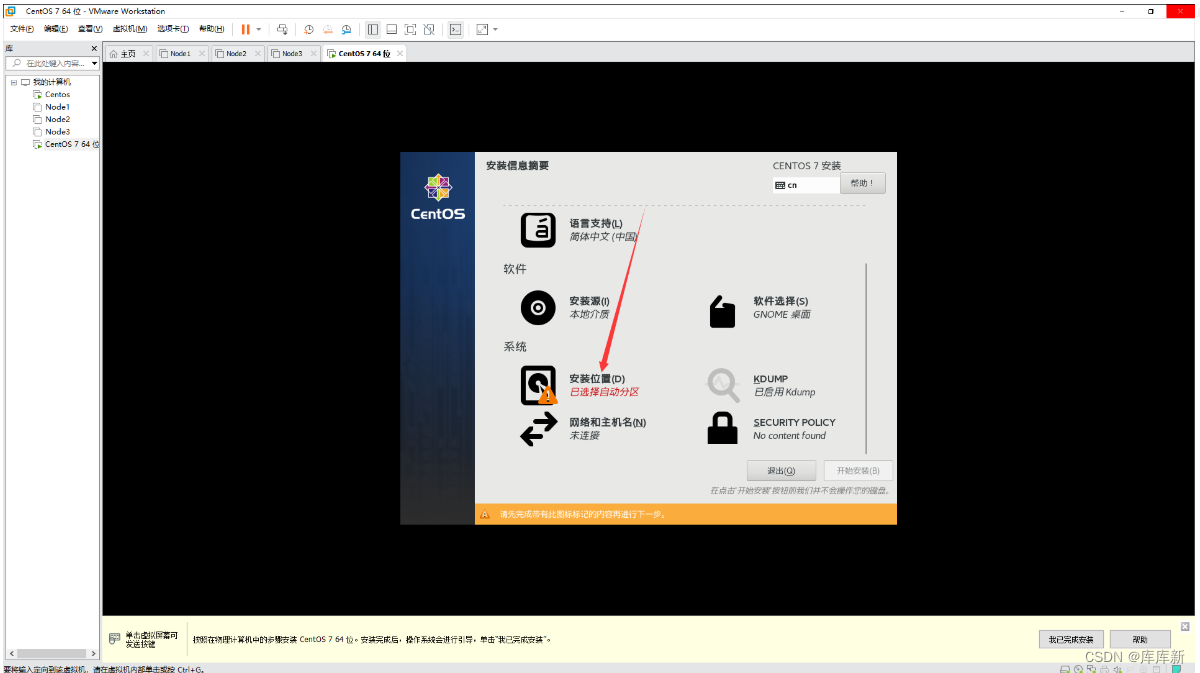

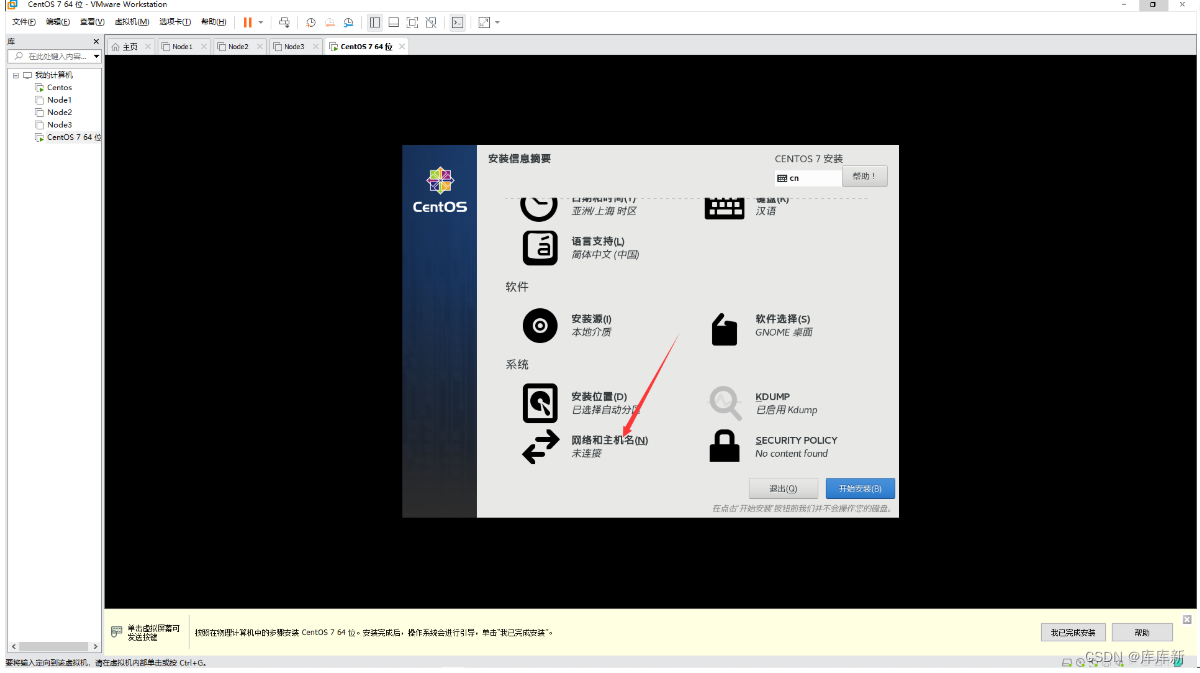
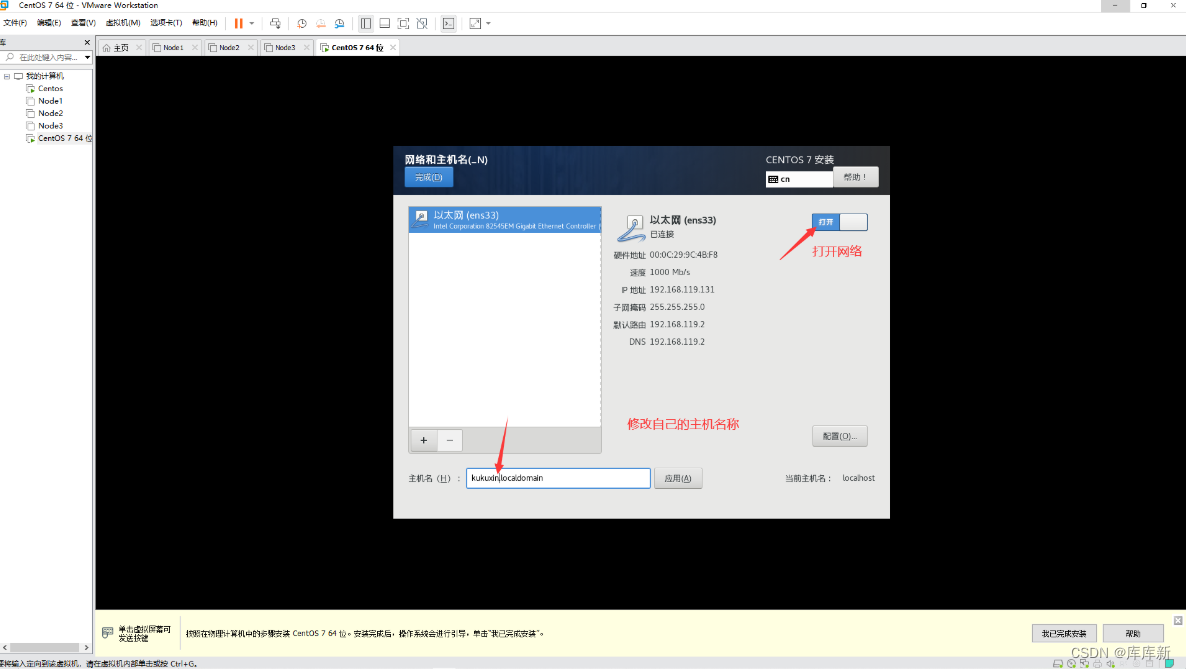
注:我们配置一下网络和主机名,打开它
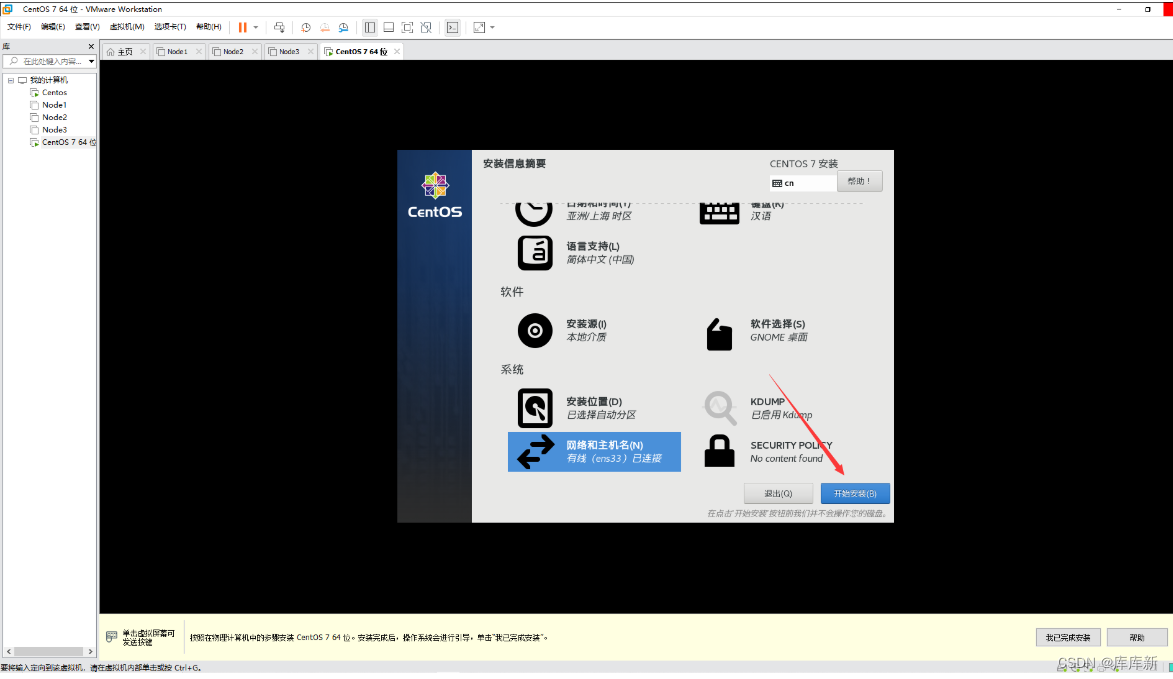

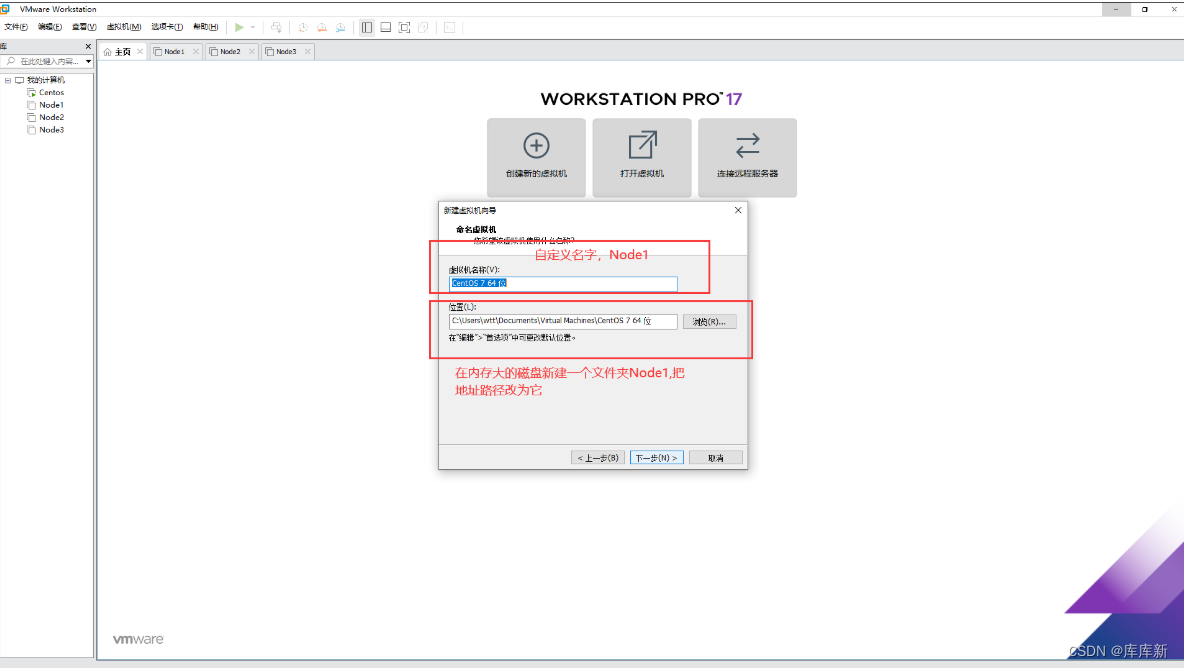
注:安装好后,对Node1进行完全克隆搭建完全分布式(自己提前在磁盘创建目录Node1(已经创建过了)、Node2、Node3),复制克隆的时候把虚拟机先关机

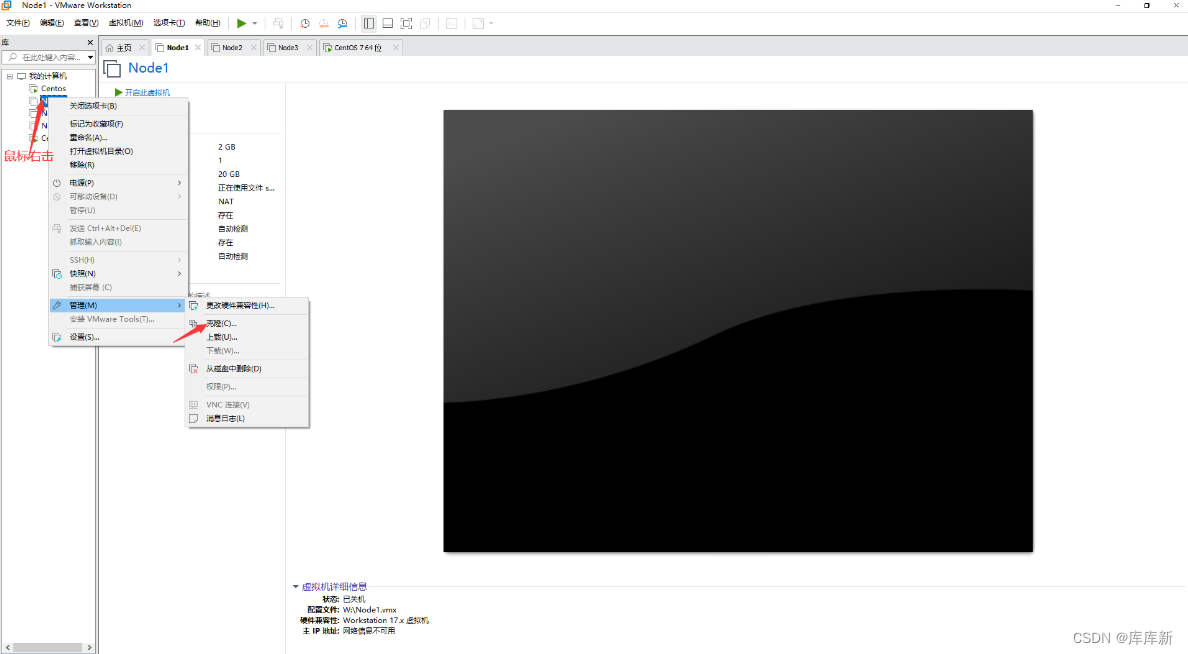

至此我们三台虚拟机已经搞好了,下面进行基础的配置
---------------------------------------------------------------------------------------------------------------------------------
二、对三台虚拟机完成主机名、固定IP、SSH免密登录等系统设置
2.1、修改三台虚拟机主机名
(相关操作需要在三台虚拟机都要进行哦!!!)
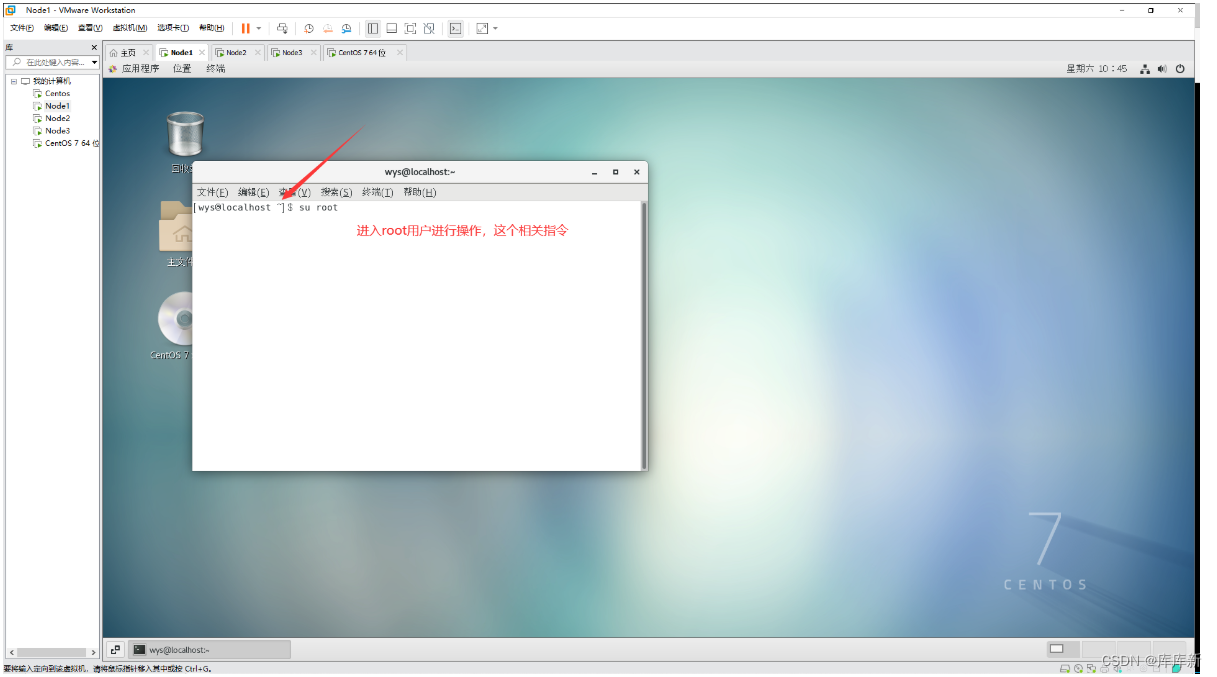
1.su root 进入root用户进行操作
2.hostnamectl set-hostname node1 设置主机名称指令
3.systemctl restart network 重启一下网络
2.2修改三台虚拟机IP地址
1.点击编辑、点击虚拟网络编辑器、点击NAT设置,记住这些参数
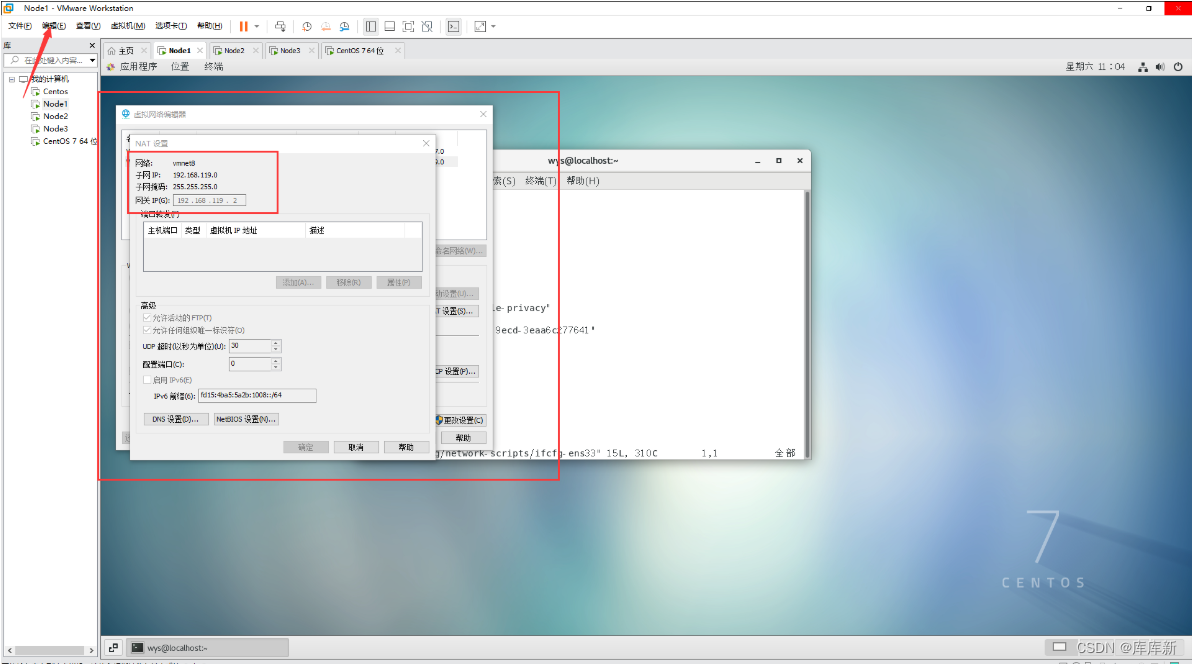
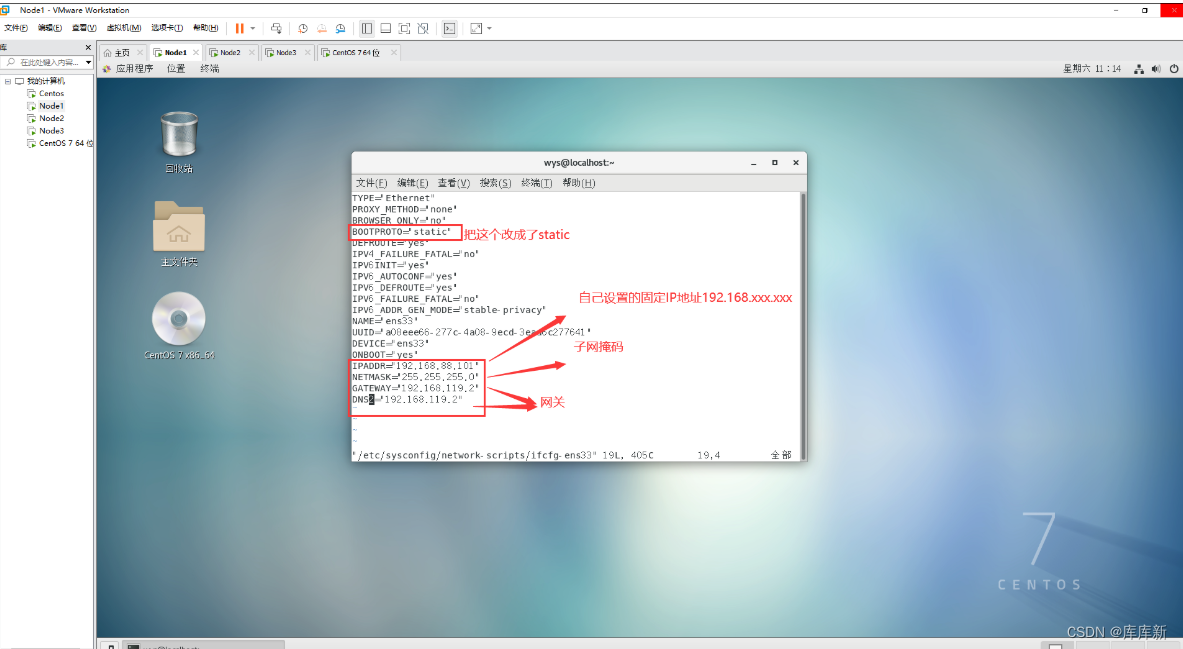
2.指令:vim /etc/sysconfig/network-scripts/ifcfg-ens33
3.保存按键盘ESC 输入 :wq
4.vim /etc/sysconfig/network-scripts/ifcfg-ens33 进入后增加数据:
IPADDR="192.168.88.132"
NETMASK="255.255.255.0"
GATEWAY="192.168.88.2"
DNS2="192.168.88.2"
5.重启:systemctl restart network
2.3主机映射
在自己电脑C盘打开这个文件夹 C:\Windows\System32\drivers\etc


注:在三台虚拟机里面添加IP和主机名
指令:vim /etc/hosts

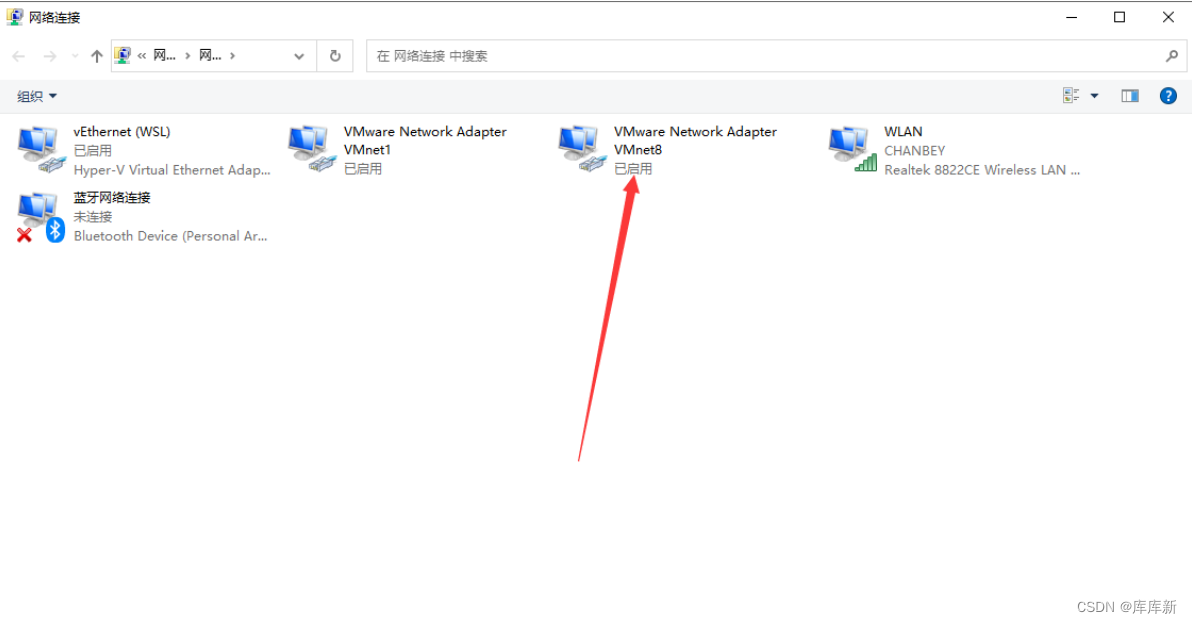
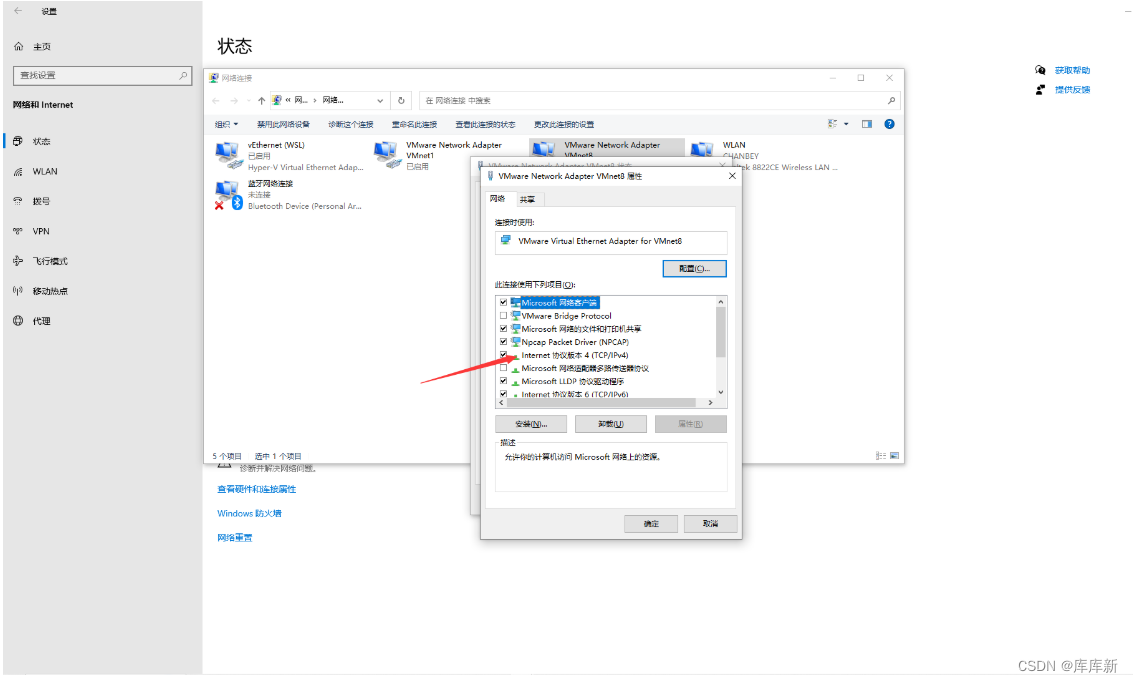
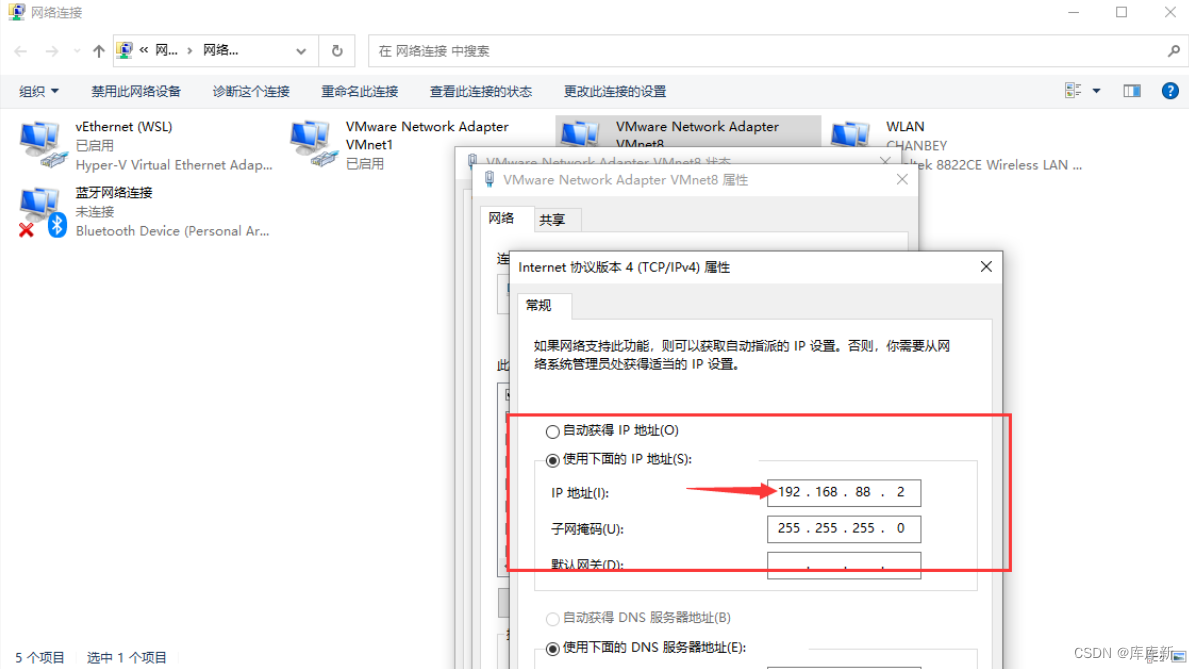
这个是自己电脑的IP只不过把后面几位数字改成0-255内的数字
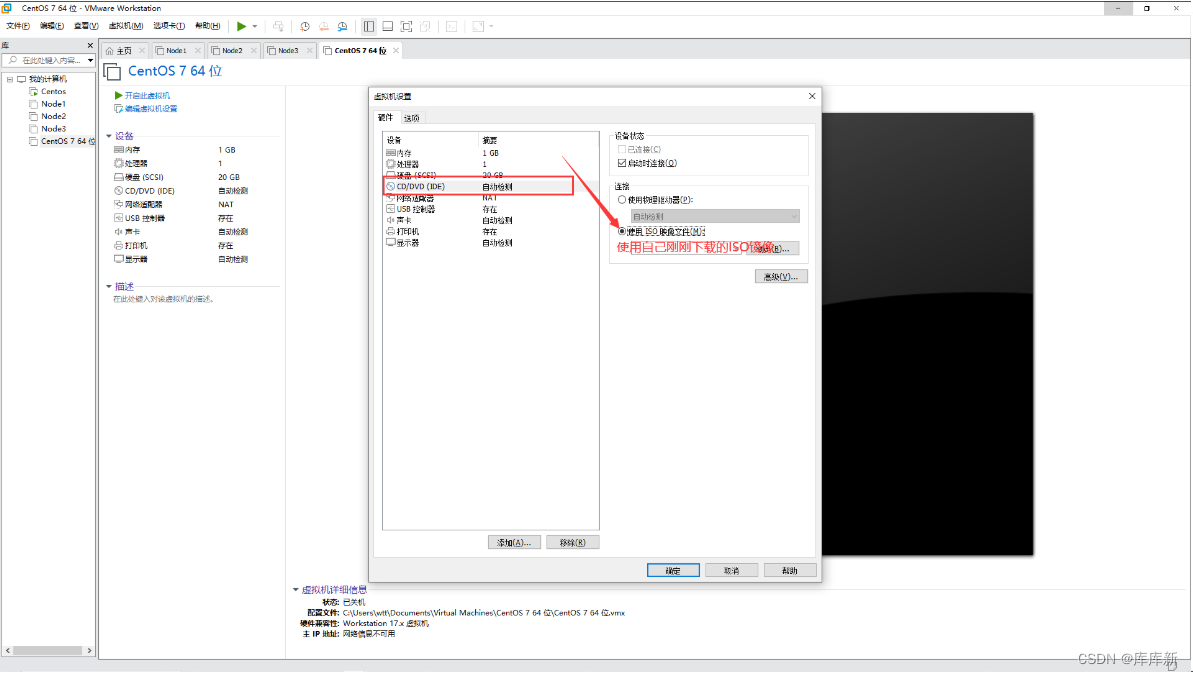
如果远程连接不了虚拟机在虚拟机里面下载这个文件
指令:yum install openssh-server -y
如果遇到虚拟机ping不通外网,查看自己的设置的VM8ip地址,和虚拟机里面的ip地址要对应
下面操作最好使用finalshell登录,可以粘贴复制很方便
2.4免密登录
免密指令:
每台都执行!!!
ssh-keygen -t rsa -b 4096
执行以上代码成功后,每台再执行这三条语句
ssh-copy-id node1
ssh-copy-id node2
ssh-copy-id node3
2.5其他用户
因为在企业用户中或者工作中我们一般不会用root用户,所以我们创建一个hadoop用户
useradd hadoop
passwd hadoop
123456
进入hadoop用户后再次进行免密登录执行2.4操作
三、配置环境
3.1传入hadoop、jdk、hive到指定文件夹里面。(这里我们创建一个/kkx/server文件夹,mkdir /kkx/server在根目录下面,后面我们把所有的安装软件放在里面)
指令:
1.cd
2.mkdir /kkx/server
3.cd /kkx/server
把放置在windows目录里面的压缩包Hadoop、jdk、hive通过finalshell直接拖进去
然后解压 tar -zxvf hadoop-3.2.4.tar.gz (另外两个也一样)
3.2、解压后我们进入/kkx/server目录设置软连接
指令: ln -s /kxx/server/jdk1.8.0_361 jdk
ln -s /kkx/server/hadoop-3.2.4 hadoop
3.3、设置环境变量:
vim /etc/profile
export JAVA_HOME=/kkx/server/jdk export PATH=$PATH:$JAVA_HOME/bin
HADOOP_HOME export HADOOP_HOME=/kkx/server/Hadoop
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin
让环境变量生效
source /etc/profile
查看一下是否成功,
java -version
hadoop version
如果成功就会显示版本信息,如果没有成功自己根据上面操作在检查一下,实在不会最后在评论区大家一下解决
3.4
集群化软件之间需要通过端口互相通信,未了避免出现网络不通的问题,我们可以简单的在集群内部关闭防火墙
systemctl stop firewalld
systemctl disable firewalld
3.5关闭SELinux
指令:vim /etc/sysconfig/selinux
将SELINUX=enforcing改为SELINUX=disabled
保存退出,重启虚拟机 PS:disabled(千万别打错!!!)
init 6 虚拟机重启
init 0 虚拟机关机
3.6、同步时区
1.安装ntp软件
yum install -y ntp
2.更新时区
rm -f /etc/localtime;
sudo ln -s /usr/share/zoneinfo/Asia/Shanghai /etc/localtime
3.同步时间
ntpdate -u ntp.aliyun.com
4.开启ntp服务并设置开机自启
systemctl start ntpd
systemctl enable ntpd
(遇到问题:yum安装软件报Cannot find a valid baseurl for repo: base/7/x86_64错误
解决方法:
cd /etc/yum.repos.d/
 问题就是这个
问题就是这个CentOS-Base.repo文件,解决方法就是:将这个文件后缀名修改使这个文件无效
问题就是这个CentOS-Base.repo文件,解决方法就是:将这个文件后缀名修改使这个文件无效)
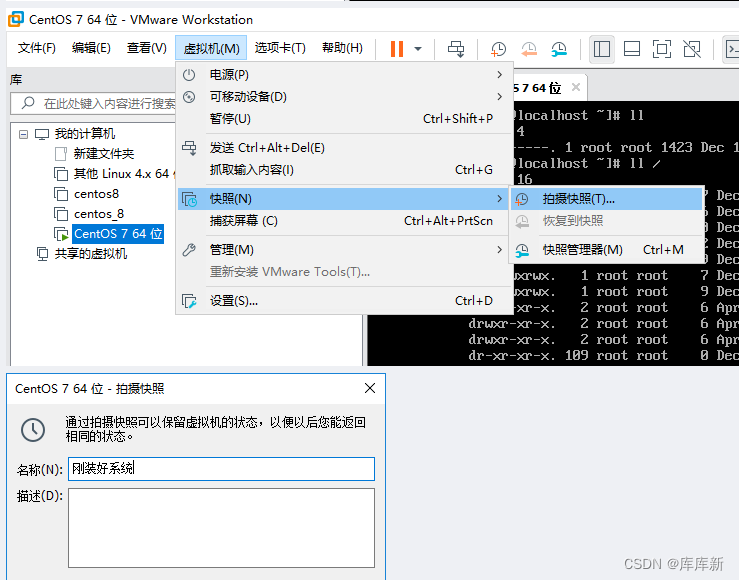
四、截至目前基础已经配置的差不多了,将虚拟机拍摄快照
五、安装hadoop
5.1
进入hadoop/etc/hadoop里面对workers文件、hadoop-env.sh文件进行修改
1.删掉localhost 在workers文件增加
node1
node2
node3
2.hadoovim hadoopp-env.sh在首行增加内容:
export JAVA_HOME=/kkx/server/jdk
export HADOOP_HOME=/kkx/server/hadoop export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export HADOOP_LOG_DIR=$HADOOP_HOME/logs
3.修改core-site.xml文件
在<configuration>里面插入以下代码,注意代码不要搞错了!!
<property>
<name>fs.defaultFS</name>
<value>hdfs://node1:8020</value>
</property>
<property>
<name>io.file.buffer.size</name>
<value>131072</value>
</property>
文件系统 hdfs://node1:8020为整个HDFS内部的通讯地址,
表名DataNode将和node1的端口通讯,node1是NameNode所在机器,
此配置固定node1必须启动NameNode进程。
4.修改hdfs-site.xml
<property>
<name>dfs.datanode.data.dir.perm</name>
<value>700</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/data/nn</value>
</property>
<property>
<name>dfs.namenode.hosts</name>
<value>node1,node2,node3</value>
</property>
<property>
<name>dfs.blocksize</name>
<value>268435456</value>
</property>
<property>
<name>dfs.namenode.handler.count</name>
<value>100</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/data/dn</value>
</property>
解析:
key:dfs.datanode.data.dir.perm
hdfs文件操作系统,默认创建的文件权限设置
值:700即:rwx------
key:dfs.namenode.name.dir
含义:NameNode元数据的存储位置
值:/data/nn,在node1节点的data/nn目录下
key:dfs.namenode.hosts
含义:NameNode允许那几个DataNodel连接
值:node1、node2、node3这三台服务器被授权
key:dfs.blocksize
含义:hdfs默认块大小
值:268425456(256MB)
key:dfs.namenode.handler.count
含义:namenode处理的并发线程数
值:100,以100个并行度处理文件的管理系统
key:dfs.datanode.data.dir
含义:从节点DataNode的数据存储目录
值:/data/dn,即数据存放在node1、node2、node3,三台机器的、data/dn内
5.创建文件存储的目录
在node1
mkdir -p /data/nn
mkdir -p /data/dn
在node2、node3
mkdir -p /data/dn
5.在node1的server目录下拷贝hadoop文件给node2、node3
scp -r hadoop- 3.2.4 node2:'/kkx/server/'
scp -r hadoop- 3.2.4 node3:'/kkx/server/'
并在node2、node3为hadoop配置软链接
ln -s /kkx/server/hadoop-3.2.4 /kkx/server/hadoop
修改hadoop文件夹中的bin和sbin环境变量方便使用里面的脚本vim /etc/profile
export HADOOP_HOME=/kkx/server/hadoop export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
source /etc/profile
在三台机器授权为hadoop用户
chown -R hadoop:hadoop /data
chown -R hadoop:hadoop /export
六、在创建的hadoo用户启动进入hadoop用户
hdfs namenode -format
start-all.sh 开启所有集群
目前已经可以操作基本hadoop以及mapreduce执行任务了
后面我们再配置一下yarn
下面是相关操作
#start-dfs.sh #启动HDFS stop-dfs.sh #停止HDFS
#start-yarn.sh #启动YARN stop-yarn.sh #停止YARN
#start-all.sh #启动HDFS和YARN stop-all.sh #停止HDFS和YARN
#mr-jobhistory-daemon.sh start historyserver #启动historyserver mr-jobhistory-daemon.sh start #historyserver #停止historyserver
6.1配置YARN集群
在mapred-env.sh添加
export JAVA_HOME=/kkx/server/jdk
export HADOOP_JOB_HISTORYSERVER_HEAPSIZE=1000
export HADOOP_MAPREO_ROOT_LOGGER=INFO,RFA
编辑mapred-site.xml
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
<description>MapReduce的运行框架设置为YARN</description>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>node1:10020</value>
<description>历史服务通讯端口node1:10020</description>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>node1:19888</value>
<description>历史服务器web端口为node1的19888</description>
</property>
<property>
<name>mapreduce.jobhistory.intermediate-done-dir</name>
<value>/data/mr-history/tmp</value>
<description>历史信息在HDFS的记录临时路径</description>
</property>
<property>
<name>mapreduce.jobhistory.done-dir</name>
<value>/data/mr-history/done</value>
<description>历史信息在HDFS的记录路径</description>
</property>
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=$HADOOP_HOME</value>
<description>MapReduce HOME 设置为HADOOP_HOME</description>
</property>
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=$HADOOP_HOME</value>
<description>MaapReduce HOME 设置为HADOOP_HOME</description>
</property>
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=$HADOOP_HOME</value>
<description>MapReduce HOME 设置为HADOOP_HOME</description>
</property>
6.2编辑 yarn.site-xml配置
<property>
<name>yarn.resourcemanager.hostname</name>
<value>node1</value>
<description>ResourceManager设置在node1节点</description>
</property>
<property>
<name>yarn.nodemanager.local-dirs</name>
<value>/data/nm-local</value>
<description>NodeManager中间数据本地存储路径</description>
</property>
<property>
<name>yarn.nodemanager.log-dirs</name>
<value>/data/nm-log</value>
<description>NodeManager数据日志本地存储路径</description>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
<description>为MapReduce程序开启Shuffle服务</description>
</property>
<property>
<name>yarn.log.server.url</name>
<value>http://node1:19888/jobhistory/logs</value>
<description>历史服务器URL</description>
</property>
<property>
<name>yarn.web-proxy.address</name>
<value>node1:8089</value>
<description>代理服务器主机和端口</description>
</property>
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
<description>开启日志聚合</description>
</property>
<property>
<name>yarn.log-nodemanager.remote-app-log-dir</name>
<value>/tmp/logs</value>
<description>程序日志HDFS的存储路径</description>
</property>
<property>
<name>yarn.resourcemanager.scheduler.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.scheduler.fair.FairScheduler</value>
<description>选择公平调度器</description>
</property>
6.3、配置完成
分发给其他节点
scp mapred-env.sh mapred-site.xml yarn-env.sh yarn-site.xml node2:'写入hadoop存放这个文件的路径'
scp mapred-env.sh mapred-site.xml yarn-env.sh yarn-site.xml node3:'写入hadoop存放这个文件的路径'
查看路径的方法是pwd
至此集群基本搭建完成,后面有什么需求还可以再进行追加配置
















 862
862











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











