






将某张表中数据,分别存储到不同的区域中

其实:就是每个分区,就是一张独立的表。都要存储该分区数据的数据,索引等信息。
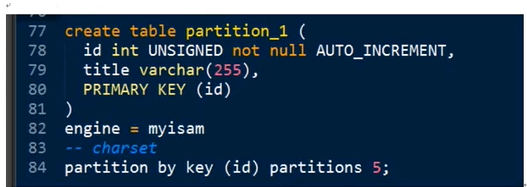
创建分区:在创建表时,指定分区的选项:
create table table_name(
定义
)
Partition by 分区算法 (分区参数) 分区选项。
分区算法:
Mysql 提供4钟
key,hash 取余算法
list,range 条件算法

注意:分区与存储引擎无关,是mysql逻辑层完成的。
通过变量查看当前mysql是否支持分区
















05-13
 2585
2585
2585
“相关推荐”对你有帮助么?
-

 非常没帮助
非常没帮助 -

 没帮助
没帮助 -

 一般
一般 -

 有帮助
有帮助 -

 非常有帮助
非常有帮助
提交

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









