






零、前言
软件构造的目标:
Safe from bugs.
Easy to understand.
Ready for change.
务必牢记。
主要参考资料:上课的讲义PPT,MIT 6.005(MIT 6.031的早年版本),MIT 6.031
鉴于MIT 6.031课程在2021年秋季之后不再使用Java,而是转向了TypeScript,而学校的授课内容仍然以Java为主,因此,对于这门课程的学习或参考,主要关注2021年春季使用Java的课程内容。
在MIT课程中有所介绍,但我觉得需要上这门课的应该是个人都懂的,本文就不再赘述。如递归,正则表达式,上下文无关语言。
MIT课程有所介绍但是老师上课没有介绍的本文也不进行重点描述,如有需要可以自行阅读MIT 6.031。如并发,多线程,线程安全。
本文将以哈工大软件构造课程开展的三次实验为主线,逐一介绍软件构造这一课程学习中需要注意的事项。
在参与前两次实验时,我对软件构造的概念和流程尚处于初识阶段,未能深刻领悟其各个环节的重要性。然而,经过第三次实验的历练,我首次独立完成了从需求抽象出抽象数据类型(ADT)的整个过程,并成功实现了这一设计,进而编写了相应的用户界面。最初,由于时间紧张,这一界面是基于命令行程序构建的,但随着项目DDL的延期,我有了更多的时间,因此决定将其重构为GUI,以提升用户体验和交互的直观性。
写博客的目的在于让阅读的人明白作者想表达的内容。这本身也是复习的一部分。
一、Java的基本特性
这一节将简略描述,因为这是软件构造学习前就该掌握的。
Java的整体语法,以及整个语言的语法感觉都和C++非常类似。但是在Java中没有多继承,友元,指针。
1.类型检查
一般而言,编程语言的类型检查分为三类:
1.静态类型检查:静态类型检查发生在程序编译时。通过对程序的静态分析,检查所有涉及值的使用的操作、调用和赋值。在程序运行前排除潜在的类型错误。
2.动态类型检查:动态类型检查发生在程序运行时。当程序执行到涉及具体数据值的操作时,会进行类型检查。如果没有在运行时发现类型错误,程序将继续执行,否则将报错并中止程序。动态检查的典型例子如Python。
3.无检查:编译器完全不干活,所有错误检查都交给程序员。
一般而言:静态类型检查 >> 动态 >> 无检查
Java是一门静态类型语言,在运行前使用静态类型检查每个变量和表达式的类型是否匹配。如果类型不匹配,编译器会报错并阻止代码的继续编译。但Java也动态地捕捉除以0,数组越界之类的错误。
2.数组、集合类
Java数组是相同类型数据的集合。一旦声明并初始化,数组的大小就不能改变。数组可以是基本数据类型(如int, double, char等)或对象类型(如String, Integer等)。
Java的java.util.Collections框架提供了一系列用于操作集合的类和接口。这些集合类包括List、Set、Queue和Map等。与数组不同,集合的大小可以在运行时动态改变。
在Java中可以使用for-each循环或迭代器来遍历数组或集合:
例:
List<String> list = new ArrayList<>();
list.add("Apple");
list.add("Banana");
//for-each
for (String fruit : list) {
System.out.println(fruit);
}
//Iterator
Iterator<String> iterator = list.iterator();
while (iterator.hasNext()) {
String fruit = iterator.next();
System.out.println(fruit);
}3.变更值 vs. 改变变量的引用
改变变量的引用一般指
在Java中,对于一个不可变的数据类型,如String s="a";,然后s+="b",此时a从指向值"a"的内存地址变为了指向值"ab"的内存地址。
对于一个可变的数据类型,如StringBuilder sb = new StringBuilder("a");,然后sb.append("b");,此时sb指向的对象变更为了"ab"。
这在每个对象只有一个引用的时候没有问题。但是,当一个对象有多个指向它的引用的时候,问题就产生了:假如StringBuilder sb和sb2都指向同一个对象,此时对sb的修改会导致sb2的值改变,而这往往不是我们所希望的。为了避免这种副作用,当我们需要保持原始对象不变并创建一个新的对象时,应该使用不可变类型(如String)或者显式地创建新的可变对象实例(如通过new关键字)。
使用快照图能更好地说明这一点:
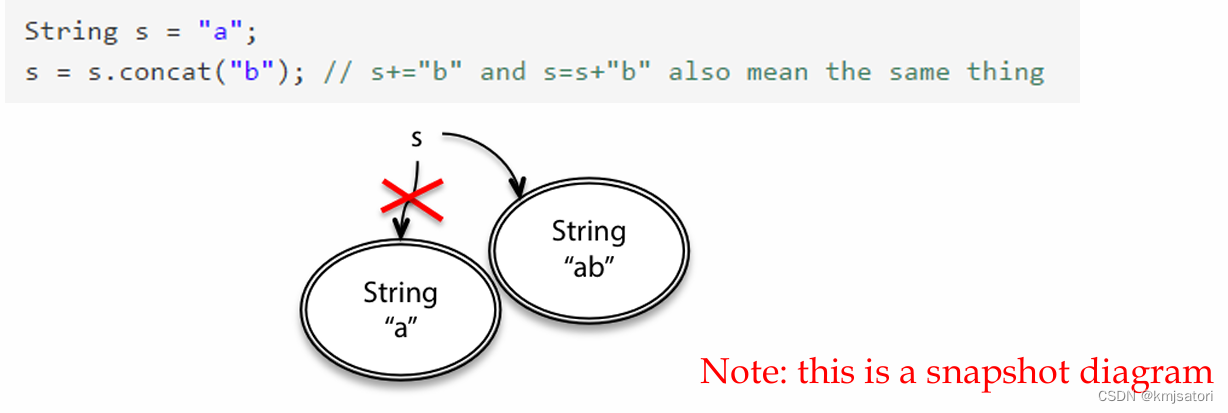


对于原始数据类型和对象类型,在声明时加上final可以阻止变量的引用被改变,这一点由编译器静态检查。
4.== vs. equals()
一句话,==比较的是引用,而.equals()比较的是对象的内容。
例:
String x = "abc";
String y = x;
String z = new String("abc");
System.out.println(x.equals(y));
//returns true because x and y have the same characters
System.out.println(x == y);
//returns true because x and y point to the same object
System.out.println(x.equals(z));
//returns true because x and z have the same characters
System.out.println(x == z);
//returns false because x and z point to different objects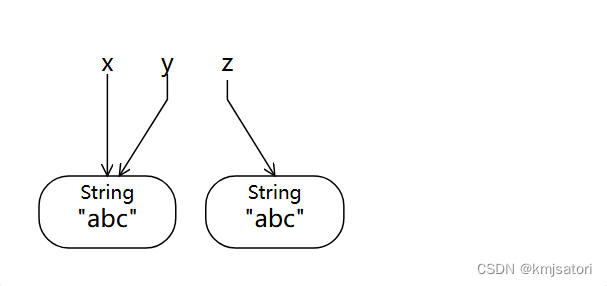
二、测试优先的编程
测试的主要目的是发现程序中存在的错误(即缺陷或bug),确保软件的质量,并验证软件是否满足预定的需求和规格。
测试优先的编程首先写Spec,然后基于Spec写对应的测试用例,最后才写具体实现。
这样做的好处是:可以明确需求,提高代码质量,减少错误,文档化,增强可读性。先写测试最大的好处是可以节省大量的调试时间。
Spec是指,对于代码行为或功能的期望描述(作者观点),具体将在下文讨论。这里先着重讨论测试用例。
1.测试用例
测试用例=输入 + 执行条件 + 期望结果,一个合理的测试用例集合应该是正确,透彻也不繁琐的。
测试用例应该做到Fail Fast。
设计测试用例的策略:对输入进行等价类划分。例如:对于大整数的乘法,将输入划分为很大的数,很小的数,±1和0.注意不要遗漏的分界条件。注意要将你的测试策略写成文档,方便查看你的代码的其他人检查你的测试用例是否合理。
2.单元测试和回归测试
单元测试是针对程序的最小可测试部分(如方法、类等)进行的测试。
单元测试程序的一个部分时,不应该依赖其他部分的正确性。
在确保单元测试正确的基础上,可以进行集成测试,用于确保程序的各个部分正确组合在了一起。
回归测试指当程序遇到bug时,将引发bug的输入作为测试用例添加到测试用例集合中。
回归测试用于确保在修改程序后,新代码没有引入新的错误,并且现有功能仍然按预期工作。
3.自动化测试和代码覆盖度
在Java中,我们可以使用JUint进行自动化测试,并且使用EclEmma检查测试对程序的覆盖情况。
代码覆盖度分为三个层级:
第一层指语句覆盖,要求每一条可执行语句都至少执行一次;
第二层指分支覆盖,要求程序中的每一个分支(如if-else、switch语句中的每个case)都至少被执行一次。
第三层指路径覆盖,要求测试覆盖程序中所有可能的执行路径。这是最高级别的覆盖率度量,但在实践中往往因为路径数量庞大而难以实现。即使是中等规模的程序,其可能的执行路径数量也可能是天文数字,因此实现完全的路径覆盖是不切实际的。
4.黑/白盒测试
测试分为黑盒测试和白盒测试:黑盒测试指对程序外部表现出来的行为的测试,白盒测试指对程序内部代码的测试。
黑盒测试一般是直接对着Spec写的测试用例,白盒测试一般在实现写完后,查看测试的覆盖情况时,发现有部分代码对于所有的测试用例都没有运行过,此时追加的可以运行到这些闲置代码的一些测试用例。白盒测试关注程序的内部实现,验证程序是否按照预定的逻辑和路径执行。
5.Code Review
由其他人逐行检查原始作者的代码,并指出相应的问题。
Code Review不仅可以提高代码质量,在交流中也可以提高程序员的水平。
一个好代码应该具备如下的特征:
Don't repeat yourself (DRY)
如果两块相似代码块中出现bug,有可能只修复了一边而另一边被遗漏。遇到相似代码块应该尽量抽象成一个函数并且在需要的地方调用它。
Comment where needed
注释很重要,无需多言。但是要注意的是,不应该做把代码逐行翻译为自然语言的工作,这是毫无意义的。只在有必要的地方注释。
while (n != 1) { // test whether n is 1 (don't write comments like this!)
++i; // increment i
l.add(n); // add n to l
}
/*
*看不到我
*/
int sum = n*(n+1)/2; // Gauss's formula for the sum of 1...n (OK)Fail fast
编写代码时,设计应该要更容易发现潜在的Bug。例:
public static int dayOfYear(int month, int dayOfMonth, int year){
// ...
}
//这并不好,对于客户端而言dayOfYear(9,1,2024)和dayOfYear(1,9,2024)容易出歧义
//可以做如下更改:
public enum Month { JANUARY, FEBRUARY, MARCH, ..., DECEMBER };
public static int dayOfYear(Month month, int dayOfMonth, int year) {
// ...
//还可以加入参数范围的检查:
if (month < 1 || month > 12) {
throw new IllegalArgumentException();
}
}Avoid magic numbers
不要在代码中出现莫名其妙的数字,如有必要,声明一个final常量,并且对常量起一个合适的名称来使用它,以增强代码可读性。
理由如下:数字的可读性不如一个好的命名;常量将来可能会有改变;常数可能依赖于其他常数,等等。
One purpose for each variable
如果一个变量在不同的地方被反复使用,这可能会带来潜在的bug,而且变量的名字可能也会造成可读性上的困扰。
Use good names
不要使用形如tmp, temp, data之类的变量名,因为所有的变量都是临时的也都是数据。这种变量名只能反映出程序员的懒惰。可以用你设置这些变量的目的来命名它们。
Use whitespace to help reader
不解释。
Don't use globle variables
使用全局变量的缺点时不知道变量在哪里会被修改,这对debug来说非常不利。
Method should return results, not print them
直接打印违背了ready for change原则,也不利于方法结果的利用。
Avoid special case code
其实作者也没有太明白这一准则的含义和原因?尽可能的减少代码中对特殊情况的特殊处理,如字符串为"",数组为空。这可能是因为:特殊情况代码通常会使代码的逻辑更加复杂,难以理解和维护。随着时间的推移,这样的代码可能会变得更加混乱,因为新的开发人员可能不理解这些特殊情况的来龙去脉;为每一个特殊情况编写独立的代码块会增加出错的机会,因为每一个这样的代码块都需要单独测试和维护。
三、Spec
Spec全程Specification,指规格、细则或说明书。Spec描述了一段代码的期望的输入,期望的行为和输出。
对于一个Spec,只关心它的行为,而不关心内部实现。只要行为无误,内部实现你爱怎么写怎么写。
1.为什么要使用Spec?
可以简单地让代码满足easy to understand, ready for change和safe from bugs三大要求。可读性不解释,只需要阅读spec而不用逐行读代码就可以理解代码的功能;一个Spec给予了开发者在不知道具体的客户端使用环境的情况下,自由选择具体实现的自由;很多bug源于对代码需求的不理解,一个好的Spec可以将这类bug拒之门外。
作者在三次实验中,也明显感觉到,先写Spec的代码开发速度是要比不写Spec快的:先写好Spec可以让思路更加清晰,减少潜在的bug和debug的时间。
2.Spec的格式
以方法为例,一个方法的spec应该包括:
前置条件。即方法接受的参数应该满足说明条件。
方法的效果。描述返回值,对可变对象做的操作,可能抛出的异常等。
Spec不应该涉及到内部的具体实现。
Java中的Spec形如:
/**
* Find a value in an array.
* @param arr array to search, requires that val occurs exactly once
* in arr
* @param val value to search for
* @return index i such that arr[i] = val
*/
static int find(int[] arr, int val)3.如何设计一个Spec
其实很简单,只需要用自然语言描述你的方法接受什么输入,要干什么,产生什么输出即可。
需要关注三个维度:确定性,陈述性(原文declarative,暂译为陈述性),强度
确定性:指对于给定的输入只有一个输出,还是存在一系列输出的集合都符合spec?
陈述性:指是否只给出了输出应该是什么样子,还是给出了输出具体的计算方法?
强度:如果把实现看作一个从输入集到输出集的映射,那么这个Spec能否允许有多或是少的合法的实现?(这样说也许有点抽象)换个说法,一个Spec允许有更多可能的输入(更弱的前置条件),更确定的输出(更强的后置条件),那么这个Spec就是更”强“的。
一个好的Spec应该是连贯一致的,提供有用信息的,强度应该不太强也不太弱(太弱可能会导致bug,太强会导致实现很难写)并且尽可能使用抽象数据类型(ADT,将在下文着重介绍)
四、抽象数据类型(ADT)
抽象数据类型,顾名思义,是抽象的数据类型。ADT通过省略或隐藏低级细节,以更简洁、高级的概念呈现,其核心理念包括抽象、模块化、封装、信息隐藏和关注点分离,旨在提升软件的健壮性、易理解性和易修改性。
1.确定可变性和操作
即确认该ADT应该是可变的或是不可变的。ADT的操作可以分为四类:
Creator:用于创建某个类型的新对象。通常通过构造函数或静态方法(如工厂方法)来实现。
Producer:基于该类型的已存在对象来构建出一个新的对象。如在String类型中的concat()方法
Observer:获取该类型对象的某个属性值或状态,但不改变它。如在List类型中的size()方法
Mutator:改变对象的某个属性或状态。不可变的数据类型没有Mutator。
一个抽象数据类型是由它的操作定义的。我们不关心它的具体内部实现,我们只关心它的行为。要设计一个抽象的Bool类,我大可以用字符串"false"表示true,用"true"表示false而完全不违背Spec。
一个好的ADT应该用少数简单的操作来实现强大的功能。
2.表示独立性(Representation independence)
表示独立性是指用户(或客户端)在使用ADT时,无需关心其内部的具体实现细节。即ADT的内部表示(如数据结构的选择)的变化,不应影响外部的行为和客户端的使用。
3.Abstraction Functions & Rep Invariants
一个好的ADT一定有不变的成员变量(使用final修饰)并保有一些不变量。不变量指在ADT对象的整个声明周期中始终为true的一些属性。简而言之,它描述了程序中某些东西应该始终保持不变的条件。例如:
不可变性:一个对象一旦创建,其值在其整个生命周期内都不应改变。例如,Java中的String类型就是不可变的。
变量类型:例如,int i意味着i始终是一个整数。
变量之间的关系:例如,在遍历列表时,i作为索引,那么0 <= i < list.size()就是一个在循环体内始终成立的不变性条件。
接下来介绍抽象函数和表示不变性:
抽象函数(Abstraction Functions)
从数学的角度来看,抽象函数定义了一个从对象的内部表示空间(Rep Space)到抽象数据值(也称为抽象状态)的映射。这个映射描述了对象内部成员(即其内部状态或实现细节)如何表示一个抽象数据类型所定义的逻辑状态或值。
表示不变性(Rep Invariants)
是指对象内部状态必须满足的一组条件或属性,这些条件或属性在对象的生命周期内始终保持为真。从数学的角度来看,表示不变性可以被视为从对象的内部表示空间(Rep Space)到布尔值(Boolean)的一个映射函数。
在这个函数中,我们定义了一个或多个规则,这些规则用于检查对象的内部状态是否满足预期的约束条件。如果满足,函数返回true,表示对象的当前状态是合法的;如果不满足,函数返回false,表示对象的当前状态是非法的。
假设我们有一个用字符串表示字母集合的抽象数据类型(ADT),这个ADT要求字符串中的字母是不允许重复的。在这种情况下,表示不变性(RI)可以定义为从字符串到布尔值的一个映射函数,该函数检查字符串中的字母是否唯一。
假设:RI(s) = true 如果 s 中的所有字母都是唯一的
= false 如果 s 中存在重复的字母
那么
RI("abc") = true 因为 "abc" 中的所有字母都是唯一的
RI("abbc") = false 因为 "abbc" 中包含重复的字母 'b'
这样,RI函数就为我们提供了一个数学上严谨的方式来检查对象(在这个例子中是字符串)的内部状态是否满足我们的约束条件(即字母是否唯一)。
在程序中我们应该将RI函数写为checkRep(),并且在每个可能造成内部状态变更的方法结尾调用checkRep()来检查表示不变性。
4.将AF、RI和Safety from Rep写为文档
AF应该精确地定义如何将具体内部状态解释为抽象数据。
RI应该准确解释决定内部状态有效与否的原因。
Safety from Rep应该描述如何防止表示泄露。表示泄露指对象的内部表示(或实现细节)被不当地暴露给外部使用者,使得外部使用者能够直接访问或修改这些内部表示,从而破坏了ADT的封装性和抽象性。
以一个表示有理数的ADT为例:
// Immutable type representing a rational number.
public class RatNum {
private final int numerator;
private final int denominator;
// Rep invariant:
// denominator > 0
// numerator/denominator is in reduced form, i.e. gcd(|numerator|,denominator) = 1
// Abstraction function:
// AF(numerator, denominator) = numerator/denominator
// Safety from rep exposure:
// All fields are private, and all types in the rep are immutable.
// Operations (specs and method bodies omitted to save space)
public RatNum(int n) { ... }
public RatNum(int n, int d) { ... }
...
}5.使用接口、泛型构建ADT
在Java中,接口(Interface)是一个强大的工具,它定义了一组方法(即ADT的运算)的规范,但不包含这些方法的具体实现。这些方法的实现可以在不同的类中完成,只要它们遵循接口所定义的规范(Spec)。使用接口的好处包括:
1.行为规范:接口只规定了行为应该遵守的规约,具体的实现是自由的。
2.多种实现:允许有不同的实现共同存在。例如,一种实现可能在时间性能上较优但内存占用大,而另一种实现可能相反。这使得我们可以根据具体的应用场景选择合适的实现。
3.静态类型检查:利用Java的静态类型检查可以排除潜在的错误,同时也方便其他程序员理解代码。
关于子类型,Java使用extends(用于类)和implements(用于接口)关键字来声明。如果A是B的子类型,那么A是一种特殊的B,所有的A都应该遵守B的规范,但反之则不然。子类型通常会自动继承父类型的public和protected成员变量和方法。
子类型可以重写父类型的方法(使用@Override注解),也可以定义父类型中原本没有的新方法。
在Java中,所有类型都隐式地继承自一个公共的父类Object。当自定义ADT时,建议重写toString()方法以便于调试和日志记录。如果ADT是不可变的,还应重写equals()和hashCode()方法,以确保它们在HashSet、HashMap等集合类中的正确使用。重写equals()方法时,新的方法应满足等价关系的性质:传递性、自反性和对称性。
泛型:Java的泛型允许ADT处理多种数据类型。例如,Java的容器类如List<T>和Set<T>就是泛型的典型应用。可以定义泛型类,也可以定义泛型接口。
枚举:枚举类型(enum)在ADT或其成员变量只有有限个可能值时特别有用。例如,表示月份的枚举可以这样定义:
public enum Month { JANUARY, FEBRUARY, MARCH, ..., DECEMBER };这样,Month枚举就提供了月份的一个固定集合,并且可以在其中定义附加的方法和属性。枚举中也可以有rep,Observer方法,Producer方法,也可在Month枚举中附加。
6.equals()和hashCode()
上文提到,==和equals()的差别在于,==比较的是引用,而.equals()比较的是对象的内容。而所有对象默认继承的是Object类的equals():
public class Object {
...
public boolean equals(Object that) {
return this == that;
}
}这其实就退化为了==。因此,在自定义ADT时,需要重写equals()方法。如何重写呢?
我们先来介绍一下等价性。
行为等价性(Behavioral Equivalence)
行为等价性指的是两个对象在方法调用上具有相同的行为。也就是说,当你对两个对象执行相同的操作时,甚至是Mutator对其中之一调用改变了状态而不对另一者做改变时,它们应该产生相同的结果或副作用。这并不意味着它们的内部表示或状态必须相同,而是它们的可观察行为必须相同。
观察等价性(Observational Equivalence)
观察等价性关注的是从外部观察两个对象时它们是否表现得相同。这通常意味着比较它们的equals()方法和hashCode()方法的行为。如果两个对象在逻辑上被认为是等价的(即它们表示相同的数据或状态,或者所有Observer方法都无法找出它们的区别),那么它们的equals()方法应该返回true,并且它们的hashCode()方法应该返回相同的值。
对于不可变的数据类型而言,行为等价性和观察等价性是同一个意思。对可变的就不一定了。一般而言,我们从观察等价性的角度来设计equals()。
在自定义ADT时,重写equals()和hashCode()方法是实现观察等价性的关键。默认的equals()方法(来自Object类)只进行引用比较,这在大多数情况下是不符合需求的。
下面是一个如何重写equals()方法的例子,它考虑了类型检查和成员变量的值比较:
public class Duration {
private int hours;
private int minutes;
// ... 其他成员变量和构造方法 ...
@Override
public boolean equals(Object obj) {
// 检查是否为null和类型匹配
if (this == obj) return true;
if (obj == null || getClass() != obj.getClass()) return false;
// 强制类型转换为Duration
Duration that = (Duration) obj;
// 检查成员变量是否相等
return this.hours == that.hours &&
this.minutes == that.minutes;
// ... 检查其他成员变量 ...
}
}对不可变数据类型而言,hashCode()也必须重写,确保观察等价的对象具有相同的hashCode(),否则,等价的对象被映射为不同的哈希值会导致HashSet、HashMap等集合类无法正确使用:
@Override
public int hashCode() {
return Objects.hash(hours, minutes); // 使用Java 7及以上版本的Objects.hash方法
// ... 对于更早的版本,可能需要手动计算哈希码 ...
}对可变的数据类型请不要重写hashCode(),用过phthon的人都知道可变数据类型不能作为Map的Key和集合的元素,所以不需要。
总结:
对于不可变类型:
行为等价性与观察等价性是一致的。
equals() 方法必须被重写以比较抽象值。
hashCode() 方法也必须被重写以将抽象值映射到一个整数。
对于可变类型:
行为等价性与观察等价性是不同的。
equals() 方法通常不应该被重写,而应该继承自 Object 类的实现,该实现比较的是引用,就像 == 运算符一样。如果需要比较,建议定义一个新方法,如same()。
同样地,hashCode() 方法也不应该被重写,而应该继承 Object 类的实现,该实现将引用映射到一个整数。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









