







ArrayList
ArrayList 和 LinkedList
- 线程安全:两者都不是线程安全的。
- 底层数据结构:ArrayList底层使用的是Object数据;LinkedList底层使用的是双向循环链表。
- 内存占用:ArrayList在list列表的结尾处会预留一部分空间;LinkedList存储的每一个元素都需要比ArrayList更多的空间。
- 随机访问:ArrayList实现了
RandomAccess接口,可以通过下标迅速获取对象;LinkedList不支持元素随机访问。 - 插入删除:ArrayList采用数组存储,插入和删除的时间复杂度受元素位置影响,近似o(n);LinkedList采用链表存储,插入和删除的时间复杂度不收元素位置影响,近似o(1)。
为什么现在不推荐使用Vector?
Vector实现了动态数组,和ArrayList很相似。JDK需要向下兼容,因此Vector仍然可以用,但不推荐使用了。究其原因,有以下几条:
- Vector使用
sychronized来保证线程安全,效率相对较低,就像StringBuffer比StringBuilder效率更低一样。此外,Vector只能在尾部进行插入和删除,使其效率更低。 - Vector在空间用完之后,扩容直接扩大一倍;而ArrayList扩大一半,更加节省空间。
- Vector在分配内存时需要连续的内存空间,如果数据太多了容易分配失败。
ArrayList的扩容机制
ArrayList的扩容本质上就是先计算出新的扩容后的数组的size并实例化,然后将原数组的内容copy到新数组中去。默认情况下,扩容后的容量是原本容量的1.5倍。
HashMap的扩容机制与ArrayList类似,不过HashMap扩容后容量为原来的2倍。
HashMap
HashMap的底层数据结构
在JDK1.7和JDK1.8中,HashMap的底层实现有所不同。
- 在JDK1.7中,HashMap由“数组+链表”实现。数组是HashMap的主体,链表用于解决哈希冲突。
- 在JDK1.8中,HashMap由“数组+链表+红黑树”实现。当链表过长,就会严重影响HashMap的性能。链表搜索复杂度为o(n),而红黑树的搜索复杂度为o(logn)。因此,在JDK1.8中,引入了红黑树,链表在一定条件下会转换为红黑树。
- 当链表长度超过8且数据总量超过64,链表会转换为红黑树(红黑树还原为链表的阈值为6,是为了避免两者频繁的相互转换)
- 在链表转换为红黑树前会进行判断,如果数组长度小于64,会有限进行数组扩容,而不是转换为红黑树。
那么为什么不直接用红黑树呢?
因为红黑树需要左旋、右旋、变色等操作来保持平衡,而单链表不需要。当元素个数小于8个,单链表已经能够保证查询的性能。元素大于8个时,红黑树的查询时间为o(logn),远优于链表的o(n),但是会降低新增元素的效率。如果一开始就用红黑树,一方面元素太少单链表的查询性能已经够用,另一方面新增元素的速率降低,造成性能浪费。
解决哈希冲突的方法
- 再散列法:p=H(key),p1=H§…同一个散列函数多次散列
- 再哈希法:R1=H1(key),R2=H2(key)…提供多个散列函数,发生冲突了就换函数
- 拉链法:将哈希值相同的元素构造成为一个单链表,适用于经常需要插入删除的情况,HashMap解决哈希冲突使用的就是拉链法
- 建立公共溢出区:将哈希表分为公共表和溢出表,当溢出发生时,所有溢出的数据统一放到溢出区
HashMap的加载因子
HashMap的默认加载因子为0.75,是对时间和空间都较为平衡的选择:
- 当内存空间很多而对时间效率要求很高时,可以降低加载因子Load Factor
- 当内存空间紧张而对时间效率要求不高时,可以提高加载因子的值,最大可以大于1
HashMap的put的流程
- 根据key计算出hashcode值,再计算出hash值,找到该元素在数组中存储的位置。
- 如果数组是空的,则调用
resize()进行初始化。 - 如果没有哈希冲突,直接放入数组中。
- 如果发生冲突,且key已经存在,覆盖掉原value。
- 如果发生冲突后是链表
- 如果链表长度不大于8,直接在链表中插入键值对;
- 如果链表长度大于8,数组容量小于64则进行数组扩容,数组容量大于64,则将链表转换为红黑树。
- 如果发生冲突后是红黑树,将节点挂到树上。
HashMap的key的常用类型
HashMap的key通常使用String、Integer这种不可变类,String最为常用。
- 因为字符串不可变,通常在创建的时候hashcode就已经缓存,无需重新计算。
- 从HashMap中获取对象需要用到
equals()和hashcode(),那么key对象对应的类就必须正确的重写这两个方法。String、Integer这些类很规范的重写了这两个方法。
HashMap为什么线程不安全
- 多线程扩容可能导致死循环。扩容就意味着rehash,JDK1.7中的HashMap使用头插法插入元素,多线程环境下可能会导致环形链表出现,形成死循环。因此在JDK1.8中改为尾插法,扩容时保持链表元素的原有顺序,解决了此问题。
- 多线程put可能导致元素丢失。多线程执行put操作,如果计算出的索引位置相同,前一个key会被后一个key覆盖掉。JDK1.7和1.8均有此问题。
- put和get并发,可能导致get到null。线程1执行put导致扩容rehash,线程2可能get到null。JDK1.7和1.8均有此问题。
HashMap和HashSet的区别
HashMap实现Map接口,存储键值对,通过key来计算hashcode值,速度较HashSet快。
HashSet底层其实就是HashMap,实现Set接口,存储对象,通过成员对象来计算hashcode,对象的hashcode值可能相同因此还需要equals方法。HashSet的add方法其实就是调用HashMap的put方法,存入的key是对象,value是一个始终相同虚值。
public boolean add(E e) {
return map.put(e, PRESENT)==null;// 调用HashMap的put方法,PRESENT是一个至始至终都相同的虚值
}
为什么链表变红黑树阈值为8
作者在源码中有注释,是因为泊松分布。理想状态下使用随机hash码的情况下,容器中节点的分布遵循泊松分布。链表中元素为8个时概率已经很小了,因此选用8。
ConcurrentHashMap
ConcurrentHashMap底层数据结构
ConcurrentHashMap在JDk1.7和1.8中有着不同的实现。
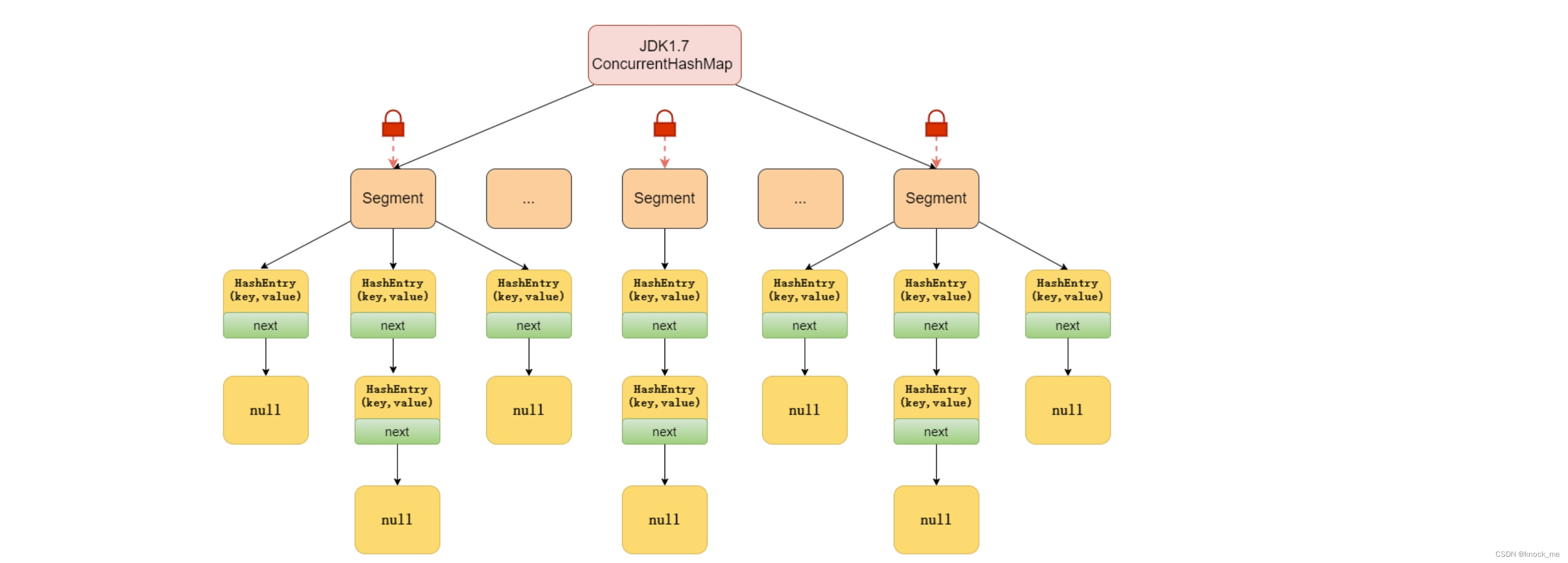
在JDK1.7中,ConcurrentHashMap由Segment数组结构和HashEntry组成。整个哈希表分为数多段Segment,每段多个HashEntry。其中,Segment继承自ReentrantLock,是一种可重入锁。HashEntry存储键值对。从下图可以看出,在JDK1.7中数据分段存储,每一段数据配一把锁。当一段数据被线程占用时,其他段数据可以被另外的进程访问,能够实现段之间的并发。
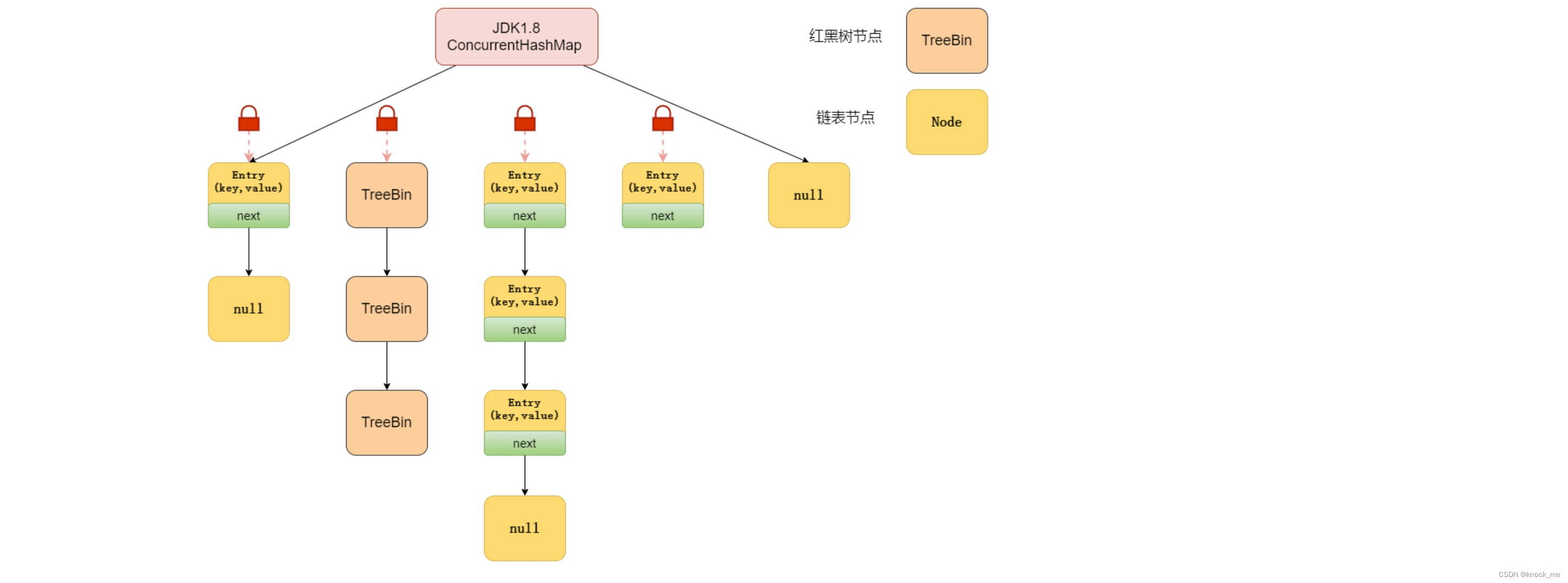
在JDK1.8中,ConcurrentHashMap和HashMap一样,采用数据+链表+红黑树的结构。锁的实现上,抛弃了Segment分段锁,转而采用CAS+sychronized实现更低粒度的锁。每次只会锁住链表的头结点或者红黑树的根节点,大大提高了并发度。
ConcurrentHashMap的put流程
在JDK1.7中,
- 首先尝试获取锁。获取失败,则自旋获取锁。若自旋64次仍未成功,改为阻塞获取锁。
- 获取到锁后,
- 在当前Segment中通过key的hashcode定位到HashEntry。
- 遍历HashEntry,看key是否重复,来决定是覆盖原有value还是新建HashEntry加入当前Segment。
- 释放Segment锁。
在JDK1.8中,
- 根据key计算出hash值。
- 判断是否需要初始化数组。
- 定位到数组的对应位置,拿到首节点,判断首节点
- 如果为空,通过
CAS方式尝试添加。 - 如果
f.hash = MOVED = -1,说明别的线程在扩容,参与一起扩容。 - 如果都不满足,锁住当前首节点,将目标元素插入链表或红黑树。
- 如果为空,通过
- 链表长度达到8时,数组扩容或者将链表转换为红黑树。
get方法是否需要加锁
不需要;Node的元素val和指针next都被volatile修饰,多线程环境下线程A修改val或者next时对线程B是可见的。这也是ConcurrentHashMap比其他并发集合效率高的原因,比如HashTable,用Collections.sychronized()包装的HashMap。
其中,HashTable给整个哈希表加了一把全表锁,效率很低。Collections.sychronized()则是使用SychronizedMap来实现的。
此外,HashEntry被volatile修饰,是为了保证扩容时的可见性,与get不需要加锁没有关系。
是否支持key或value为null
不支持;会报空指针错误。
value不能为null,因为如果支持存入null,通过get(key)得到null就不知道是key对应的value为null还是没有key。而HashMap就能存入null,这是因为HashMap可以通过containsKey(key)来判断是否存在key。而ConcurrentHashMap使用在多线程场景下,若一开始线程A通过key获取到null是因为没有对应key,而此时线程B添加<key,null>,然后A通过containsKey()进行判断就会发现key存在,会造成歧义,与真实情况不符。
key不能为null,设计之初就不允许,避免可能导致的潜在错误。ConcurrentHashMap作者本身也很不喜欢集合可以存储null。在找相关资料时还看了一个很有趣的故事==>ConcurrentHashMap作者现身解释为何不允许null。
ConcurrentHashMap并发度
默认并发度为16,可以通过构造函数进行设置。如果设置了构造函数,会使用大于等于该值的2的次幂作为并发度。比如你设置并发度为15,则会使用16;设置17,则会使用32。
迭代器是强一致性还是弱一致性?
HashMap的迭代器是强一致性,修改会导致报错ConcurrentModificationException,但是对现有key的value进行修改是允许的。
ConcurrentHashMap的迭代器是弱一致性。使用迭代器遍历所有元素,遍历过程中元素可能发生变化。如果变化发生在已遍历的部分,迭代器不会反映出来;如果变化发生在未遍历部分,迭代器就会发现并反映出来,这就是弱一致性。
集合问题
Collection怎么实现比较
- 实体类实现
Comparable接口,并重写compareTo(T t)方法。因为在实体类内部实现的,所以叫做内部比较器。下面的代码就表示People首先按照薪水由低到高排序,薪水一样的人就按照id从小到大排序。实现接口并重写方法的实体类可以使用Arrays.sort()进行排序。
@Override
public int compareTo(Object o) {
People peo = (People) o;
if (salary < peo.salary) //薪水低排在前面
return -1;
if (salary > peo.salary)
return 1;
if (id < peo.id) { //id小排在前面
return -1;
}
if (id > peo.id) {
return 1;
}
return 0;
}
- 用一个比较类来实现
Comparator接口,而实体类无需实现。因为是在实体类外部实现,所以叫外部比较器。下面的代码表示薪水由低到高进行排序。以下面比较器为例,进行People对象排序时需要用到Collections.sort(peoples, new SalaryCompare());
//外部比较类
class SalaryCompare implements Comparator<People> {
@Override
public int compare(People o1, People o2) {
//o1 - o2是升序,o2 - o1是降序
return o1.salary - o2.salary;
}
}
Iterator 和 ListIterator
- Iterator可以遍历所有类型的集合,如Map、Set、List,但只能正向遍历;ListIterator只能遍历List类型的集合,但可以正向或反向遍历。
- Iterator无法新增或修改元素;ListIterator可以添加元素并使用
set()修改集合中的元素。 - Iterator无法获取集合中元素的索引,因为Map、Set类型没有索引;ListIterator可以获取元素在集合中的索引。
快速失败fail-fast和安全失败fail-safe
-
fail-fast
- 机制:迭代器遍历一个集合对象时,如果在遍历过程中对集合内容进行了修改,会抛出
Concurrent Modification Exception异常。java.util包下的集合类都是快速失败,也即非线程安全。 - 原理:采用快速失败机制的集合,迭代器在遍历时直接访问原集合对象,并使用一个modCount变量表示修改次数。集合在遍历过程中内容发生的任何变化,都会增加modCount的值。当迭代器每次使用
next()或者hasNext()之前,都会检测modCount是否为期望值。如果是,继续遍历;如果不是,抛出异常,终止遍历。 - 注意:抛出异常是检测到
modCount != exceptedmodCount,如果集合发生变化后modCount刚好设置为expectedmodCount值,则不会抛出异常。因此,不能依据这个异常是否抛出来进行并发编程,这个异常只建议用于检测并修改bug。
- 机制:迭代器遍历一个集合对象时,如果在遍历过程中对集合内容进行了修改,会抛出
-
fail-safe
- 机制:采用安全失败机制的集合,迭代器在遍历时先复制原有集合,然后在拷贝的集合上进行遍历。java.util.concurrent包下的集合类都是安全失败,可以多线程下并发使用,线程安全。
- 原理:迭代时在拷贝的集合上进行,遍历过程中对原有集合的修改不会被迭代器检测到,所以不会抛出
Concurrent Modification Exception异常。 - 缺点:迭代器无法访问修改后的内容。















 153
153











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









