







文本相似度的计算广泛的运用在信息检索,搜索引擎, 文档复制等处:
因此在各种不同的情况与任务中,有不同的文本相似度计算。
方法1 编辑距离
编辑距离又称Levenshtein距离,是指将一个字符串转为另一个字符串所需的字符编辑次数,包括以下三种操作:
插入 - 在任意位置插入一个字符
删除 - 将任意一个字符删除
替换 - 将任意一个字符替换为另一个字符
编辑距离可以用来计算两个字符串的相似度,它的应用场景很多,其中之一是拼写纠正(spell correction)。 编辑距离的定义是给定两个字符串str1和str2, 我们要计算通过最少多少代价cost可以把str1转换成str2.
举个例子:
输入: str1 = “geek”, str2 = “gesek”
输出: 1
插入 's’即可以把str1转换成str2
输入: str1 = “cat”, str2 = “cut”
输出: 1
用u去替换a即可以得到str2
输入: str1 = “sunday”, str2 = “saturday”
输出: 3
我们假定有三个不同的操作: 1. 插入新的字符 2. 替换字符 3. 删除一个字符。 每一个操作的代价为1.
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
# @Author: yudengwu
# @Date : 2020/5/28
def edit_dist(str1, str2):
# m,n分别字符串str1和str2的长度
m, n = len(str1), len(str2)
# 构建二位数组来存储子问题(sub-problem)的答案
dp = [[0 for x in range(n + 1)] for x in range(m + 1)]
# 利用动态规划算法,填充数组
for i in range(m + 1):
for j in range(n + 1):
# 假设第一个字符串为空,则转换的代价为j (j次的插入)
if i == 0:
dp[i][j] = j
# 同样的,假设第二个字符串为空,则转换的代价为i (i次的插入)
elif j == 0:
dp[i][j] = i
# 如果最后一个字符相等,就不会产生代价
elif str1[i - 1] == str2[j - 1]:
dp[i][j] = dp[i - 1][j - 1]
# 如果最后一个字符不一样,则考虑多种可能性,并且选择其中最小的值
else:
dp[i][j] = 1 + min(dp[i][j - 1], # Insert
dp[i - 1][j], # Remove
dp[i - 1][j - 1]) # Replace
return dp[m][n]
str1="重庆是一个好地方"
str2="重庆好吃的在哪里"
str3= "重庆是好地方"
c=edit_dist(str1,str2)
c1=edit_dist(str1,str3)
print("c:",c)
print("c1:",c1)
结果:
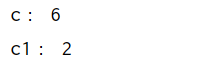
2.余弦相识度计算方法
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
# @Author: yudengwu
# @Date : 2020/5/28
import numpy as np
import jieba
#读取停用词
def stopwordslist(filepath):
stopwords = [line.strip() for line in open(filepath, 'r', encoding='gbk').readlines()]
return stopwords
# 加载停用词
stopwords = stopwordslist("停用词.txt")
def cosine_similarity(sentence1: str, sentence2: str) -> float:
"""
:param sentence1: s
:param sentence2:
:return: 两句文本的相识度
"""
seg1 = [word for word in jieba.cut(sentence1) if word not in stopwords]
seg2 = [word for word in jieba.cut(sentence2) if word not in stopwords]
word_list = list(set([word for word in seg1 + seg2]))#建立词库
word_count_vec_1 = []
word_count_vec_2 = []
for word in word_list:
word_count_vec_1.append(seg1.count(word))#文本1统计在词典里出现词的次数
word_count_vec_2.append(seg2.count(word))#文本2统计在词典里出现词的次数
vec_1 = np.array(word_count_vec_1)
vec_2 = np.array(word_count_vec_2)
#余弦公式
num = vec_1.dot(vec_2.T)
denom = np.linalg.norm(vec_1) * np.linalg.norm(vec_2)
cos = num / denom
sim = 0.5 + 0.5 * cos
return sim
str1="重庆是一个好地方"
str2="重庆好吃的在哪里"
str3= "重庆是好地方"
sim1=cosine_similarity(str1,str2)
sim2=cosine_similarity(str1,str3)
print("sim1 :",sim1)
print("sim2:",sim2)
结果:
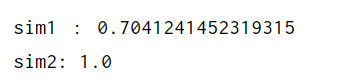
方法3 :利用gensim包分析文档相似度
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
# @Author: yudengwu
# @Date : 2020/5/28
import jieba
from gensim import corpora,models,similarities
#读取停用词
def stopwordslist(filepath):
stopwords = [line.strip() for line in open(filepath, 'r', encoding='gbk').readlines()]
return stopwords
# 加载停用词
stopwords = stopwordslist("停用词.txt")
str1="重庆是一个好地方"
str2="重庆好吃的在哪里"
str3= "重庆是好地方"
def gensimSimilarities(str1,str2,str3):
all_doc = []
all_doc.append(str1)
all_doc.append(str2)
all_doc.append(str3)
# 以下对目标文档进行分词,并且保存在列表all_doc_list中
all_doc_list = []
for doc in all_doc:
doc_list = [word for word in jieba.cut(doc) if word not in stopwords]
all_doc_list.append(doc_list)
# 首先用dictionary方法获取词袋(bag-of-words)
dictionary = corpora.Dictionary(all_doc_list)
# 以下使用doc2bow制作语料库
corpus = [dictionary.doc2bow(doc) for doc in all_doc_list]
# 使用TF-IDF模型对语料库建模
tfidf = models.TfidfModel(corpus)
index = similarities.SparseMatrixSimilarity(tfidf[corpus], num_features=len(dictionary.keys()))
sim = index[tfidf[corpus]]
return sim
sim=gensimSimilarities(str1,str2,str3)
print(sim)
结果为:
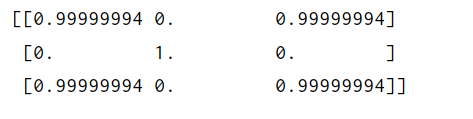

















 4894
4894











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











