









 本文收录于《深入浅出讲解自然语言处理》专栏,此专栏聚焦于自然语言处理领域的各大经典算法,将持续更新,欢迎大家订阅!
本文收录于《深入浅出讲解自然语言处理》专栏,此专栏聚焦于自然语言处理领域的各大经典算法,将持续更新,欢迎大家订阅! 个人主页:有梦想的程序星空
个人主页:有梦想的程序星空 个人介绍:小编是人工智能领域硕士,全栈工程师,深耕Flask后端开发、数据挖掘、NLP、Android开发、自动化等领域,有较丰富的软件系统、人工智能算法服务的研究和开发经验。
个人介绍:小编是人工智能领域硕士,全栈工程师,深耕Flask后端开发、数据挖掘、NLP、Android开发、自动化等领域,有较丰富的软件系统、人工智能算法服务的研究和开发经验。 如果文章对你有帮助,欢迎
如果文章对你有帮助,欢迎
关注、
点赞、收藏、订阅。
相似度算法主要任务是衡量对象之间的相似程度,是信息检索、推荐系统、数据挖掘等的一个基础性计算。现有的关于相似度计算的方法,基本上都是基于向量的,也即计算两个向量之间的距离,距离越近越相似。
1、欧式距离
欧几里得度量(euclidean metric)(也称欧氏距离)是一个通常采用的距离定义,指在维空间中两个点之间的真实距离,或者向量的自然长度(即该点到原点的距离),在二维和三维空间中的欧氏距离就是两点之间的实际距离。
欧氏距离是最常用的距离计算公式,衡量的是多维空间中各个点之间的绝对距离,当数据很稠密并且连续时,这是一种很好的计算方式。
最初用于计算欧几里得空间中两个点的距离,假设是
维空间的两个点,它们之间的欧几里得距离是:
可以看出,当时,欧几里得距离就是平面上两个点的距离。当用欧几里得距离表示相似度,一般采用以下公式进行转换:距离越小,相似度越大。
范围在之间,值越大,说明
越小,也就是距离越近,则相似度越大。
欧式距离相似度算法需要保证各个维度指标在相同的刻度级别,比如对身高、体重两个单位不同的指标使用欧氏距离可能使结果失效。并且,欧氏距离适合比较稠密的矩阵。
注意:欧氏距离不适用于布尔向量之间的计算。
2、余弦相似度
余弦相似度就是通过一个向量空间中两个向量夹角的余弦值作为衡量两个个体之间差异的大小。
公式如下:
范围:,两向量越相似,向量夹角越小,余弦相似度越大;值为负时,两向量负相关。
余弦距离使用两个向量夹角的余弦值作为衡量两个个体间差异的大小。
相比欧氏距离,余弦距离更加注重两个向量在方向上的差异。
余弦相似度主要的应用场景有:
1)推荐系统中的协同过滤;
2)计算文本的相似性;
欧式距离和余弦相似度的区别:
余弦相似度衡量的是维度间取值方向的一致性,注重维度之间的差异,不注重数值上的差异;
而欧氏距离度量的正是数值上的差异性。
3、皮尔逊相关系数
皮尔逊相关系数一般用于计算两个定距变量间联系的紧密程度。假设有两个变量X,Y,则它们之间的相关系数为:
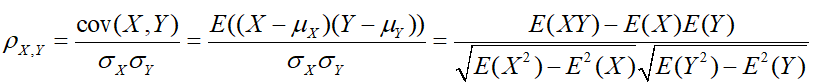
皮尔森相关系数是衡量线性关联性的程度,p的一个几何解释是其代表两个变量的取值根据均值集中后构成的向量之间夹角的余弦。
皮尔逊相似度计算结果在之间,-1表示负相关, 1表示正相关。
当相关系数为0时,X和Y两变量无关系。
当X的值增大(减小),Y值增大(减小),两个变量为正相关,反之,为负相关。
皮尔逊相似度衡量两个变量是不是同增同减,即两个变量的变化趋势是否一致。
它不适合计算布尔值向量之间的相关度,适合处理评分的数据,且是稠密的数据,稀疏数据不适合。
当两个变量的标准差都不为零时,相关系数才有定义,皮尔逊相关系数适用于:
1)两个变量之间是线性关系,都是连续数据。
2)两个变量的总体是正态分布,或接近正态的单峰分布。
3)两个变量的观测值是成对的,每对观测值之间相互独立。
4、杰卡德相似系数
Jaccard(杰卡德)相似性系数主要用于计算符号度量或布尔值度量的样本间的相似度。
Jaccard(Jaccard similarity coefficient)相似系数等于样本集A和B交集的个数和样本集A和B并集个数的比值,在[0,1]之间,当两个样本完全一致时,结果为1,当两个样本完全不同时,结果为 0,用符号表示:
Jaccard(杰卡德)距离:与杰卡德相似系数相反,用两个集合中不同元素所占元素的比例来衡量两个集合(样本)的区分度。
由于Jaccard相似系数主要用于计算符号度量或布尔值度量的个体间的相似度,无法衡量差异具体值的大小,只能获得“是否相同”这个结果,所以Jaccard系数只关心个体间共同具有的特征是否一致这个问题。
Jaccard系数主要的应用场景有:
1)过滤相似度很高的新闻,或者网页去重;
2)考试防作弊系统;
3)论文查重系统;
如何选择相似度算法:
1)余弦相似度或者皮尔逊相关系数适合用户评分数据(实数值);
2)杰卡德相似度适用于隐式反馈数据,如:0/1、布尔值、是否收藏(点击、加购物车等);
5、常用距离公式汇总
明氏距离(Minkowski Distance)的推广:为曼哈顿距离,
为欧氏距离,切比雪夫距离是明氏距离取极限的形式。
标准欧氏距离的思路:将各个维度的数据进行标准化:标准化后的值 = ( 标准化前的值 - 分量的均值 ) /分量的标准差,然后计算欧式距离,如下:
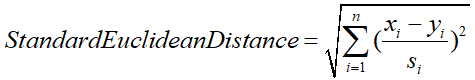
关注微信公众号【有梦想的程序星空】,了解软件系统和人工智能算法领域的前沿知识,让我们一起学习、一起进步吧!



















 210
210

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











