






一、列表(list)
1.列表的内置函数为 list 。列表可以是普通列表、混合列表,也可以是空列表,列表中可以添加列表。列表内容可以是整数,可以是浮点数,也可以是字符串。元素的位置是从“0”开始的。
2.新建列表:
新建列表 变量 = []
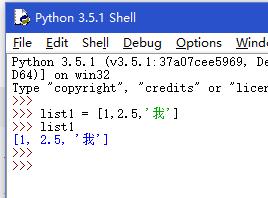
3.len() 函数可以获取列表元素的个数

4.用索引访问列表中每一个元素的位置列表[位置]
A.可以正向搜索(默认起始位置为“0”)
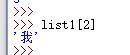
B.也可以逆向搜索(默认起始位置为“-1”)
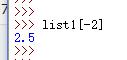
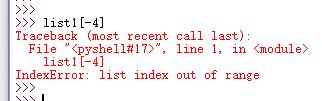
C.当索引超出了范围时,Python会报一个IndexError错误。
D.列表页可以包含列表,要定位被包含列表中某一位置的元素,可以采取 列表[包含列表位置][被包含列表位置] 的方法

或 被包含列表[位置] 的方法

5.更改列表中的元素
A.在列表中,可以通过 .append 方式增加元素到末尾位置。

B.通过 .insert() 方法增加元素并指定其在列表中的位置
list.insert(位置,’增加的元素’)

C.列表的扩展,将多个元素加入列表中
列表.extend([])

列表的扩展应采用 变量“点” extend([]) 的方式,不要采用 + (连接操作符)的方式,会出现违规操作,因为 + 两边的元素必须一致。
D.通过 .pop() 方法删除列表中的元素
列表.pop(),默认删除最后一个元素
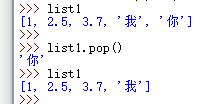
由于 pop() 有返回值,因此可以采用赋值的方法,倒序删除

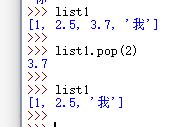
列表.pop(位置),删除指定位置元素
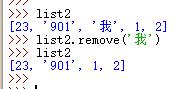
E.变量.remove(元素名称) 知道元素名称进行删除
F.delete 方法
del列表[元素位置]
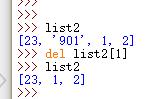
或者 del空格列表赋值的变量,整个列表被删除
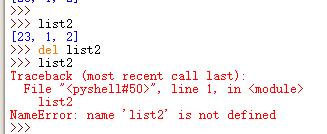
最后提示“没有这个列表”,表示删除成功。
G.替换元素,可以直接将新元素赋值给指定位置

6.一个元素的列表,调用元素种类读取。

7.切片
为了一次性获取列表中更多的元素,可以采用 切片/分片/slice 的方法
A.切片,通过分号隔开索引值,复制列表。其中,冒号左边为开始(包含开始索引值),冒号右边为结束(不包含结束索引值)。

B.同理,可以在开始位置或是结束位置不填写索引值,则复制的列表包含开始/结束的位置;也可以只填写冒号,获取整个列表的复制。

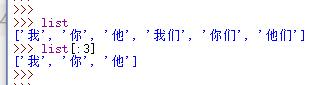

C.切片是复制整个列表,所以适用于需要修改列表同时又要保留原列表的情况;赋值是元素值完全相同的两个列表。

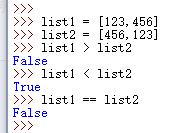
8.列表比较大小
列表比较大小,是以索引值第 0 个位置的大小判定, 0 位置的索引值大,当前列表就大,反之亦然。
9.列表相乘,列表中元素数量增倍,但是数值不变。

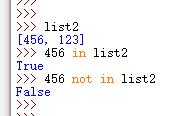
10.成员关系操作符
通过 in 和 not in 确定成员关系
对于确定列表中的列表的成员关系,应当在一层列表中引入二层列表

11.列表内置函数(BIF)及部分常用内置函数(BIF)
dir(list)

A.count():用于计算某元素在列表中出现的次数
列表.count(需要查询的元素)

count(sub[,start[,end]]),start 表示此位置之前的舍去(不含此位置),end 表示此位置之后的舍去(不含此位置)。

B.index():返回参数在列表中的位置。
列表.index(需要查询位置的元素)
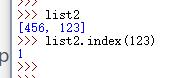
如果一个列表中有多个相同的元素分布在不同的位置,Index默认只查找第一个元素的位置,可以划定位置范围查找其他相同元素(只找排列在最前面的)。

列表.index(需要查找位置的元素,查找起始位置,查找结束位置)
C.reverse():将整个列表原地反转,前后的值互相调换位置。
列表.reverse()

D.排序
sort():默认从小到大进行排队
列表.sort()

如果列表需要从大到小排序,可以先通过 sort 从小到大排序,再用 reverse 反转;另外还有一个方法是调用 sort 中的 reverse 参数
列表.sort(reverse = True)

.sort(reverse) 中的 reverse 默认值是 False,所以要改为 True 。
二、元组(tuple)
1.新建一个元组,与字符串不同,元组内的元素要加上英文逗号。tuple 一旦初始化,元素指向不能改变。

2.tuple 陷阱:
当定义一个只有一个元素的 tuple,如果如下图定义,则定义的不是 tuple,只是一个数,这是因为括号()既可以表示 tuple,又可以表示数学公式中的小括号,这就产生了歧义,因此,Python 规定,这种情况下,按小括号进行计算,计算结果自然是1。
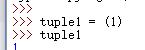
所以,只有1个元素的tuple定义时必须加一个英文逗号消除歧义。

3.“可变的”元组
例:
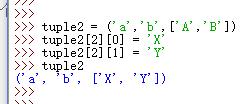
tuple所谓的“不变”是说,tuple的每个元素,指向永远不变。即指向’a’,就不能改成指向’b’,指向一个list,就不能改成指向其他对象,但指向的这个list本身是可变的!
所以,如果需要建一个“不可变”的元组,那就需要元组内的每一个元素都是“不可变”的。

4.数字乘以元组,* 相当于重复操作符,不再有乘法意义。

5.删除元组
del元组
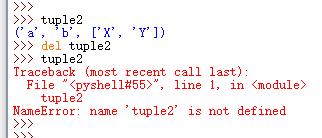
6.适用于元组的操作符
1.拼接操作符
2.重复操作符
3.关系操作符(>、<、 ==、!=)
4.逻辑操作符(and、or、not)
5.成员操作符(in、not in)
三、序列
1.列表、元组和字符串的共同点
A.都可以通过索引得到每一个元素;
B.默认索引值总是从零开始;
C.可以通过分片的方法得到一个范围内的元素的集合;
D.共用重复操作符、拼接操作符、成员关系操作符。
2.生成空列表
>>> a = list()
>>> a
[]
3.将字符串转换为单独列出的列表
b = 'Python'
>>> b = list(b)
>>> b
['P', 'y', 't', 'h', 'o', 'n']
4.将元组转换为列表
b = (1,2,3,4,5)
>>> b = list(b)
>>> b
[1, 2, 3, 4, 5]
5.将列表转换为元组
b = [1,2,3,4,5]
>>> b = tuple(b)
>>> b
(1, 2, 3, 4, 5)
6.max(sub) 返回序列或参数集合中的最大值(数据类型必须一致)
>>> c = (11,23,56,3,789)
>>> max(c)
789
7.min(sub) 返回序列或参数集合中的最小值(数据类型必须一致)
>>> min(11,23,56,3,789)
3
8.sum(iterable[, start=0]) 返回序列 iterable 和可选参数 start 的总和(可以是数据类型(整数、浮点数),字符串不能实现此操作)
A.sum(iterable)
>>> d = (1,2,3,4,5)
>>> sum(d)
15
B.sum(iterable,star)
>>> d = (1,2,3,4,5)
>>> sum(d)
15
>>> sum(d,15)
30
9.sorted() 默认由小到大排序
>>>c = (11,23,56,3,789)
>>> sorted(c)
[3, 11, 23, 56, 789]
10.reversed() 返回迭代器对象 ,如果将 reversed 表示的迭代器对象返回为列表,可以通过 list() 或是 tuple() 。
>>> c = (11,23,56,3,789)
>>> reversed(c)
<reversed object at 0x00000238FF8811D0>
>>> list(reversed(c))
[789, 3, 56, 23, 11]
>>> tuple(reversed(c))
(789, 3, 56, 23, 11)
11.enumerateenumerate() 枚举,生成由每个元素的 index(索引) 值和 item 值组成的元组。
>>> enumerate(d)
<enumerate object at 0x00000238FF884EA0>
>>> list(enumerate(d))
[(0, 1), (1, 22), (2, 345), (3, 43), (4, 576), (5, 60)]
>>> tuple(enumerate(d))
((0, 1), (1, 22), (2, 345), (3, 43), (4, 576), (5, 60))
元素前面都加了元 其所在列表的索引值
12.zip() 返回由各个参数的序列组成的集合。
A.
>>> e = (11,23,41,36,77,90)
>>> f = (43,76,45,22,11,489,123,65)
>>> zip(e,f)
<zip object at 0x00000238FF880F88>
>>> list(zip(e,f))
[(11, 43), (23, 76), (41, 45), (36, 22), (77, 11), (90, 489)]
>>> tuple(zip(e,f))
((11, 43), (23, 76), (41, 45), (36, 22), (77, 11), (90, 489))
B.
>>> e = [11,23,41,36,77,90]
>>> f = [43,76,45,22,11,489,123,65]
>>> zip(e,f)
<zip object at 0x00000238FF888548>
>>> list(zip(e,f))
[(11, 43), (23, 76), (41, 45), (36, 22), (77, 11), (90, 489)]
>>> tuple(zip(e,f))
((11, 43), (23, 76), (41, 45), (36, 22), (77, 11), (90, 489))
成对打包,元素相对多的集合,多出来的元素舍弃不要。
四、字典(dict)
1.字典用 dict{} 表示;创建一个空字典:
>>> dict = {}
>>> dict
{}
2.字典是映射类型,元组、列表、字符串都是序列类型;
3.字典的两个关键字:键 (key) 键值可以是整型变量、整形、变量、字符串、字符。
值 (value)
另外也被称为 hash(哈希值)
4.键(key)+值(value)的组合成为“项”(item)。
5.字典也可以用 a = dict() 创建。
6.新建字典
方法A.
>>> dict1 = {1:'one',2:'two',3:'three'}
>>> dict1
{1: 'one', 2: 'two', 3: 'three'}
>>> print('需要打印出的字典索引:',dict1[2])
需要打印出的字典索引: two
或调用位置参数:
>>> dict1[3]
'three'
方法B.
>>> dict1 = dict((('p',1),('y',2),('t',3),('h',4),('o',5),('n',6)))
>>> dict1
{'p': 1, 't': 3, 'n': 6, 'o': 5, 'h': 4, 'y': 2}
方法C.
dict1 = dict(p='1',y='2',t='3',h='4',o='5',n='6')
>>> dict1
{'p': '1', 't': '3', 'n': '6', 'o': '5', 'h': '4', 'y': '2'}
7.新建/增加字典。给键赋值;如果键不存在,则创建一个新的键的值。
新建
>>> dict1
{1: 'one', 2: 'two', 3: 'three'}
>>> dict1[4] = 'four'
>>> dict1
{1: 'one', 2: 'two', 3: 'three', 4: 'four'}
或
增加
>>> dict1
{1: 'one', 2: 'two', 3: 'three', 4: 'four'}
>>> dict1[5] = 'five'
>>> dict1
{1: 'one', 2: 'two', 3: 'three', 4: 'four', 5: 'five'}
8.字典的使用方法
A.dict.fromkeys(s[,v]) 创建和返回一个新的字典,s 是字典的键值;v 是键对应的值,只能是一个可选参数,如果 v 的值没有提供的话,默认就是 none 。
a.
>>> dict2 = dict.fromkeys((1,2,3))
>>> dict2
{1: None, 2: None, 3: None}
b.
>>> dict2.fromkeys((1,2,3),'Python')
{1: 'Python', 2: 'Python', 3: 'Python'}
c.注意,由于 v 的值只提供一个参数,所以如下输入会成为这样的输出效果:
>>> dict2.fromkeys((1,2,3),('Python','PHP','C++'))
{1: ('Python', 'PHP', 'C++'), 2: ('Python', 'PHP', 'C++'), 3: ('Python', 'PHP', 'C++')}
d.dict.fromkeys(s[,v]) 并不能修改(增/删)字典,如果尝试修改 .fromkeys 方法创建的字典,其实是创建了一个新字典。
dict2 = dict.fromkeys((1,2,3),'Python')
>>> dict2
{1: 'Python', 2: 'Python', 3: 'Python'}
9.访问字典的方法:
keys() 返回字典键的引用
values() 返回字典值的引用
items() 返回字典项目的引用
A.
dict3 = dict.fromkeys(range(20),'Python')
>>> dict3
{0: 'Python', 1: 'Python', 2: 'Python', 3: 'Python', 4: 'Python', 5: 'Python', 6: 'Python', 7: 'Python', 8: 'Python', 9: 'Python', 10: 'Python', 11: 'Python', 12: 'Python', 13: 'Python', 14: 'Python', 15: 'Python', 16: 'Python', 17: 'Python', 18: 'Python', 19: 'Python'}
B. for each 循环,迭代对象中每一个键
for eachkey in dict3.keys():
print(eachkey)
0
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
C. for each 循环,迭代对象中每一个值
>>> for eachvalue in dict3.values():
print(eachvalue)
Python
Python
Python
Python
Python
Python
Python
Python
Python
Python
Python
Python
Python
Python
Python
Python
Python
Python
Python
Python
D. for each 循环,迭代对象中的项目
>>> for eachitem in dict3.items():
print(eachitem)
(0, 'Python')
(1, 'Python')
(2, 'Python')
(3, 'Python')
(4, 'Python')
(5, 'Python')
(6, 'Python')
(7, 'Python')
(8, 'Python')
(9, 'Python')
(10, 'Python')
(11, 'Python')
(12, 'Python')
(13, 'Python')
(14, 'Python')
(15, 'Python')
(16, 'Python')
(17, 'Python')
(18, 'Python')
(19, 'Python')
>>>
10.get(s[,v]) 方法
A.当检索一个不存在的键的时候,字典会报错,可以用 get 方法返回错误的值,以便获取更好的体验。
报错:
dict3 = dict.fromkeys(range(20),'Python')
>>> print(dict3[20])
Traceback (most recent call last):
File "<pyshell#62>", line 1, in <module>
print(dict3[20])
KeyError: 20
B.通过 get 方法,提供较好的体验:
>>> dict3.get(20)
>>> print(dict3.get(20))
None
C.get(s[,v]) v 为可选参数,提供一个返回参数。
>>> dict3.get(32,'不存在')
'不存在'
>>>
11.成员资格操作符 in , not in
如果不知道一个键是否存在于字典中,可以采用 in 和 not in 的方法。
>>> 1 in dict3
True
>>> 100 in dict3
False
>>> 1 not in dict3
False
>>> 100 not in dict3
True
>>>
12.清空字典
>>> dict3 = dict.fromkeys(range(20),'Python')
>>> dict3
{0: 'Python', 1: 'Python', 2: 'Python', 3: 'Python', 4: 'Python', 5: 'Python', 6: 'Python', 7: 'Python', 8: 'Python', 9: 'Python', 10: 'Python', 11: 'Python', 12: 'Python', 13: 'Python', 14: 'Python', 15: 'Python', 16: 'Python', 17: 'Python', 18: 'Python', 19: 'Python'}
>>> dict3.clear()
>>> dict3
{}
>>>
13.shallow copy - 浅拷贝
>>> a = {1:'one',2:'two'}
>>> b = a.copy()
>>> c = a
>>> a
{1: 'one', 2: 'two'}
>>> b
{1: 'one', 2: 'two'}
>>> c
{1: 'one', 2: 'two'}
>>> id(a)
2123546038984
>>> id(b)
2123546668360
>>> id(c)
2123546038984
>>> c[3] = 'three'
>>> a
{1: 'one', 2: 'two', 3: 'three'}
>>> b
{1: 'one', 2: 'two'}
>>> c
{1: 'one', 2: 'two', 3: 'three'}
>>>
注意浅拷贝和赋值的区别
14.pop 和 popitem
A. pop = 给定键弹出对应的值
>>> a = {1:'one',2:'two',3:'three'}
>>>> a.pop(2)
'two'
>>> a
{1: 'one', 3: 'three'}
>>>
B.popitem = 给定键弹出对应的项(不按照顺序,随机弹出)
>>> a
{1: 'one', 2: 'two', 3: 'three', 4: 'four'}
>>> a.popitem()
(1, 'one')
>>>
15.setdefault = 自动添加字典中找不到的对应的键
>>> a.setdefault('five')
>>> a
2: 'two', 3: 'three', 4: 'four', 'five': None}
>> a.setdefault(6,'six')
six'
>>> a
2: 'two', 3: 'three', 4: 'four', 6: 'six', 'five': None}
>>>
16.update = 利用一个字典或映射关系去更新另外一个字典
>>> a
{2: 'two', 3: 'three', 4: 'four', 6: 'six', 'five': None}
>>> b = {7:'seven'}
>>> a.update(b)
>>> a
{2: 'two', 3: 'three', 4: 'four', 6: 'six', 7: 'seven', 'five': None}
五、集合(set) = {} 内的参数没有映射关系
1.集合内的元素都是唯一的,重复的元素会被自动剔除掉。
>>> c = {'a','b','c','d','a','b','c'}
>>> c
{'d', 'c', 'b', 'a'}
2.集合的排列是无序的,集合中的元素不能被索引
>>> c[3]
Traceback (most recent call last):
File "<pyshell#27>", line 1, in <module>
c[3]
TypeError: 'set' object does not support indexing
>>>
3.创建集合
A.将元素用 {} 括起
>>> num = {'元','素'}
>>> type(num)
<class 'set'>
>>>
B. 用 set() 创建
列表:
>>> d = set([1,2,3,4])
>> type(d)
<class 'set'>
元组:
>>> d = set((1,2,3,4))
>>> type(d)
<class 'set'>
字符串:
>>> d = set('Python')
>>> type(d)
<class 'set'>
>>>
4.去除列表中重复的元素
>>> e = [1,2,3,4,5,5,4,3]
>>> e = list(set(e))
>>> e
[1, 2, 3, 4, 5]
>>>
5.访问、增/删集合中的值
A.用 for 循环读去集合中的值
>>> e = {1,2,3,4,5}
>>> for each in e:
print(each)
1
2
3
4
5
>>>
B.通过 in 和 not in 判断
>>> e
{1, 2, 3, 4, 5}
>>> 1 in e
rue
>>> 10 in e
False
>>> 1 not in e
False
>>> 10 not in e
True
>>>
C.增加 set 中的值
>>> e.add(6)
>>> e
{1, 2, 3, 4, 5, 6}
>>>
D.删除 set 中的值
>>> e.remove(2)
>>> e
{1, 3, 4, 5, 6}
>>>
6.不可变的集合(frozenset 方法)
>>> f = frozenset([1,2,3,4,'ni','wo','ta'])
>>> f.add(8)
Traceback (most recent call last):
File "<pyshell#82>", line 1, in <module>
f.add(8)
AttributeError: 'frozenset' object has no attribute 'add'
>>> f.remove(2)
Traceback (most recent call last):
File "<pyshell#83>", line 1, in <module>
f.remove(2)
AttributeError: 'frozenset' object has no attribute 'remove'
>>>
六、数据结构的一些技巧
1.列表推导式(list comprehension),也叫列表解析式。格式为list = [item for item in iterable]。
普通写法:
>>> for i in range(1,11):
print(i)
1
2
3
4
5
6
7
8
9
10
>>> 列表推导式写法:
>>> print(a)
[1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
>>> 以此类推:
>>> b = [i**2 for i in range(1,10)]
>>> print(b)
[1, 4, 9, 16, 25, 36, 49, 64, 81]
>>> c = [i+1 for i in range(1,10)]
>>> print(c)
[2, 3, 4, 5, 6, 7, 8, 9, 10]
>>> d = [i for i in range(1,10) if i%2 == 0]
>>> print(d)
[2, 4, 6, 8]
>>> [letter.lower() for letter in 'ABCDEFGHIJKLMN']
['a', 'b', 'c', 'd', 'e', 'f', 'g', 'h', 'i', 'j', 'k', 'l', 'm', 'n']
>>> 2.字典推导式
普通写法:
>>>
>>> a = {0:1,1:2,2:3,3:4}
>>> for i in a.items():
print(i)
(0, 1)
(1, 2)
(2, 3)
(3, 4)
>>> b = {i:i+1 for i in a}字典推导式写法:
>>> print(b)
{0: 1, 1: 2, 2: 3, 3: 4}
>>> 3.循环列表时获取元素的索引(enumerate)
>>> a = ['a','b','c','d']
>>> for i,j in enumerate(a):
print(j,'is',i+1)
a is 1
b is 2
c is 3
d is 4
>>> 














 3108
3108

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









