







转载请注明出处:https://blog.csdn.net/kong_gu_you_lan/article/details/119101667
本文出自 容华谢后的博客
往期回顾:
0.写在前面
今天一起来学习下正则中的匹配模式,所谓的匹配模式,就是指正则中的一些 改变元字符匹配行为 的方式,比如匹配时不区分英文字母的大小写。
还记得我们在第二篇文章中学过的贪婪模式、非贪婪模式和独占模式吗,这些模式会改变正则中量词的匹配行为,今天来看一些和量词无关的匹配模式,一共有4种,分别是不区分大小写模式、点号通配模式、多行匹配模式、注释模式。
1.不区分大小写模式
顾名思义,不区分大小写模式就是我想要匹配目标字符串中的Cat,我不关心是大猫CAT,还是小猫cat,只要给我匹配上就可以了。
模式修饰符是通过 (?模式标识) 的方式来表示的,我们只需要把模式修饰符放在对应的正则前面,就可以使用指定的模式了,
不区分大小写的英文是 Case-Insensitive,模式标识用首字母的小写来表示就是 (?i),上面提到的栗子正则可以这么写 (?i)cat,看下:
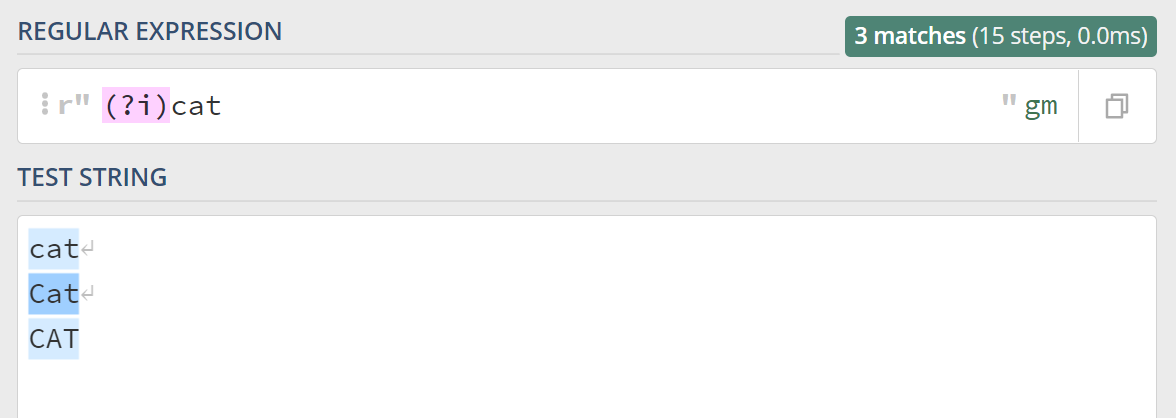
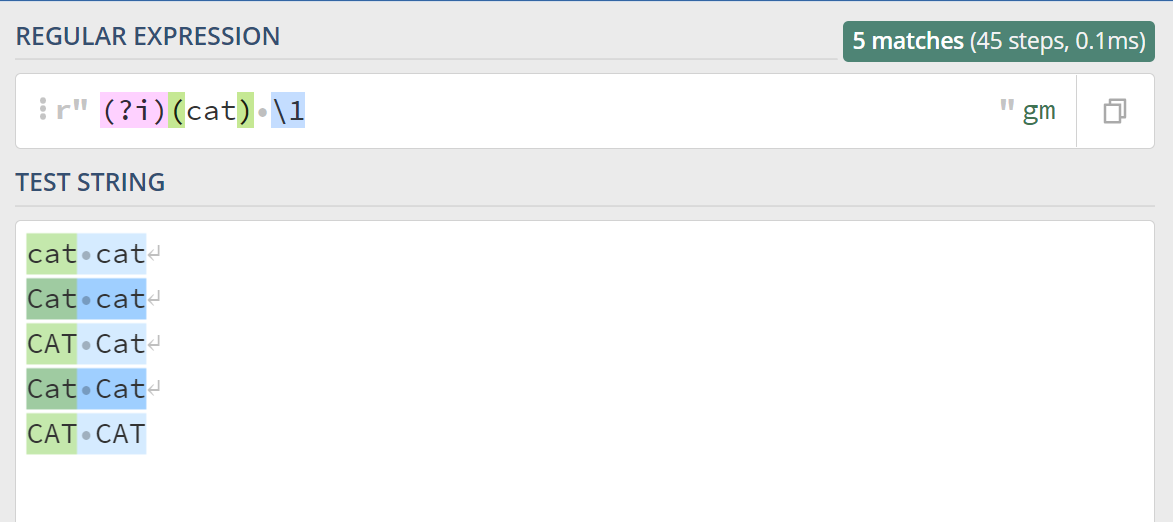
上一篇文章中,我们学习了分组与引用,如果匹配两个猫就是 (?i)(cat) \1:
对应的 Python 代码如下:
import re
result = re.findall(r"(?i)(cat) (\1)", "cat cat CAT Cat")
print(result)
输出:[('cat', 'cat'), ('CAT', 'Cat')]
可以看到,前后两个cat大小写不一致,也可以匹配上,如果我们想要匹配前后大小写一致的猫该怎么办呢,可以在外面加上一层括号 ((?i)cat) \1,看下:
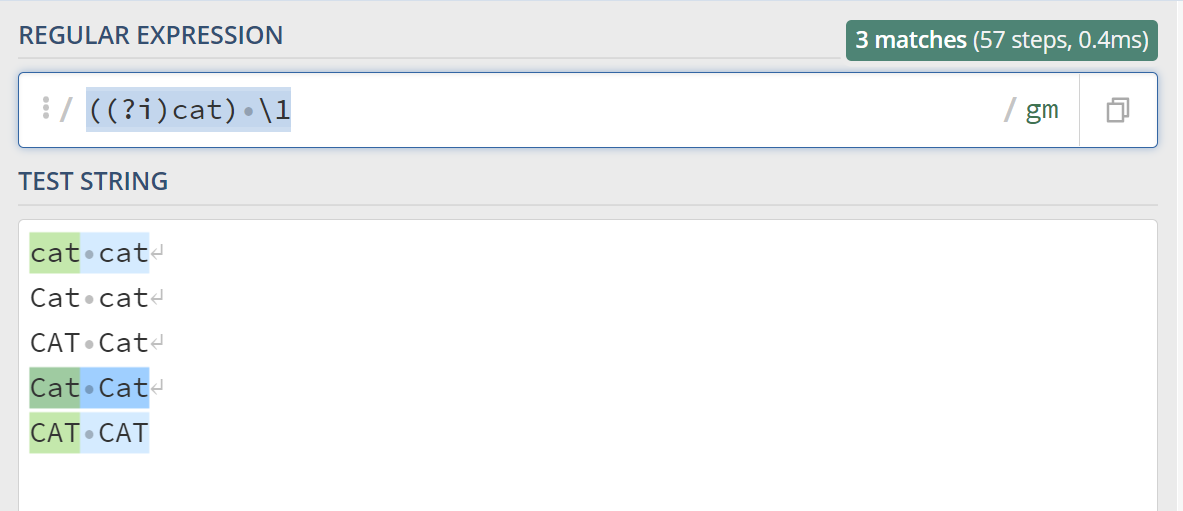
测试链接:https://regex101.com/r/tPXuGX/1
注意:在 Python 语言中,使用 re 库调用上面的正则会报下面的异常,换成 regex 库就可以,但是不能准确的匹配两个大小写一致的 cat。
DeprecationWarning: Flags not at the start of the expression
import regex
result = regex.findall(r"((?i)cat) (\1)", "cat cat CAT Cat")
print(result)
输出:[('cat', 'cat'), ('CAT', 'Cat')]
2.点号通配模式
在第一篇文章中,我们学习了元字符的相关知识,还记的英文的点 . 代表什么含义吗,它可以匹配任意字符,但是不能匹配换行。当我们需要匹配真正的任意字符时,可以使用 [\s\S] 或 [\d\D] 或 [\w\W] 等来表示。
但是这样写不够优雅,所以正则提供了一种模式,让英文的 . 能够匹配上换行在内的所有字符,这种模式就叫做点号通配模式。
点号通配模式,在很多地方被称为单行模式,英文表示为 Single Line,取其首字母,所以单行模式对应的修饰符是 (?s),举个栗子:
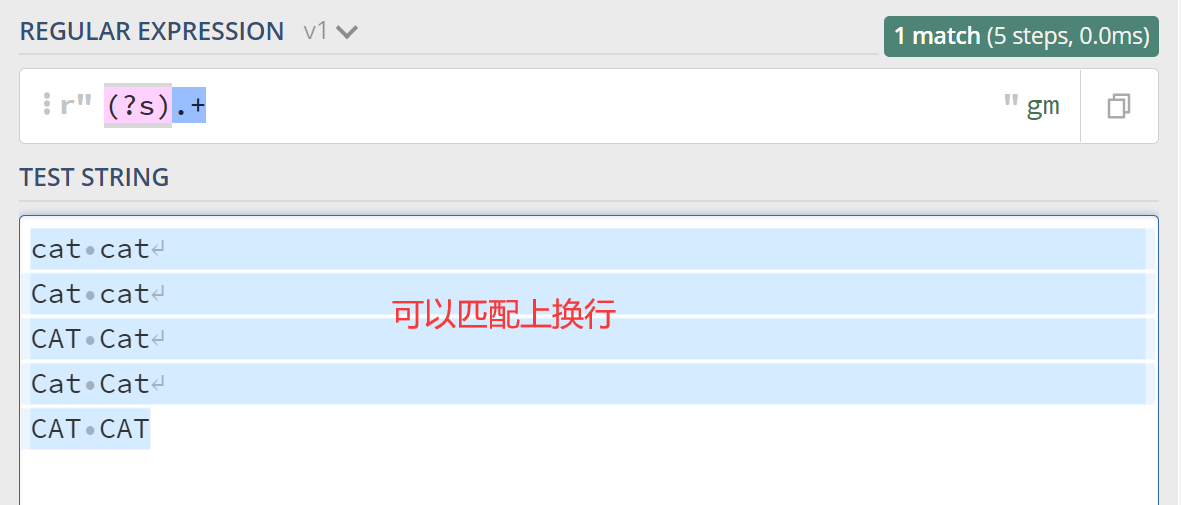
3.多行匹配模式
在正则中 ^ 用于匹配整个目标字符串的开头,$ 用户匹配整个目标字符串的结尾:
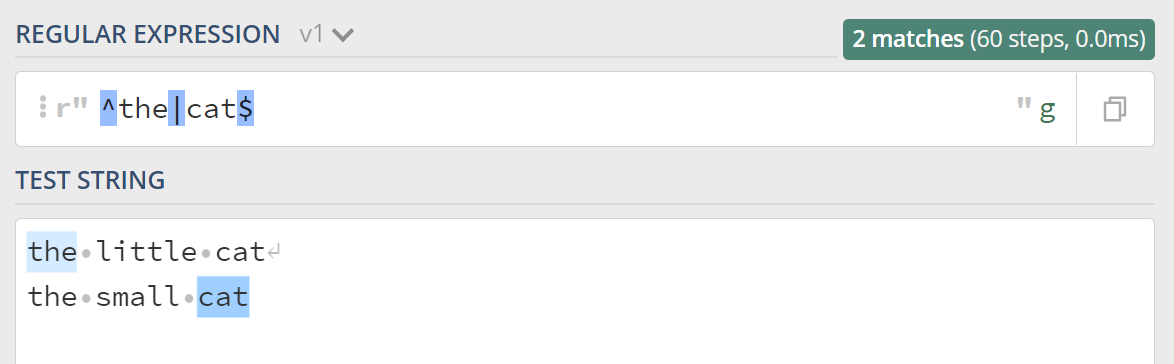
如果我们想要让表达式匹配上每行的开头和结尾呢,多行匹配模式就上场了,多行的英文是 Multiline,所以多行模式对应的修饰符是 (?m),看下效果:
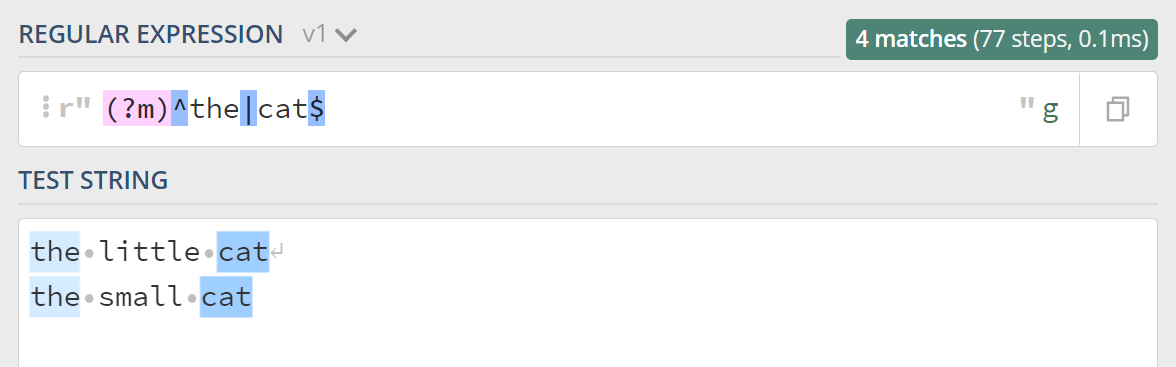
4.注释模式
当我们写了一大长串的表达式之后,当时可能只有你和上帝知道它什么意思,过了半年,就只有上帝知道它什么意思了。
注释的英文是 Comment,所以注释模式对应的修饰符是 (?#comment),注意没有用首字母,还多了一个 # 号,拿我们之前写的 IPv4 地址匹配正则举个例:
^(?:[1-9][0-9]?|1[0-9][0-9]|2[0-4][0-9]|25[0-5])(?#comment IP地址第一个值)(?:\.(?:0|[1-9][0-9]?|1[0-9][0-9]|2[0-4][0-9]|25[0-5])){3}(?#comment IP地址后三个值)$
在很多编程语言中也提供了 x 模式来书写正则,也可以起到注释的作用,以 Python 为例:
import re
regex = r'''(?mx) # 使用多行模式和x模式
^ # 开头
(\d{4}) # 年
(\d{2}) # 月
$ # 结尾
'''
result = re.findall(regex, '202006\n202106')
print(result)
输出:[('2020', '06'), ('2021', '06')]
在 x 模式下,所有的换行和空格都会被忽略,如果要匹配的话,可以把换行和空格转义,或者放在字符组中:
import re
regex = r'''(?mx) # 使用多行模式和x模式
^ # 开头
(\d{4}) # 年
[ ] # 空格
(\d{2}) # 月
$ # 结尾
'''
result = re.findall(regex, '2020 06\n2021 06')
print(result)
输出:[('2020', '06'), ('2021', '06')]
5.写在最后
最后在总结下上面讲到的内容:
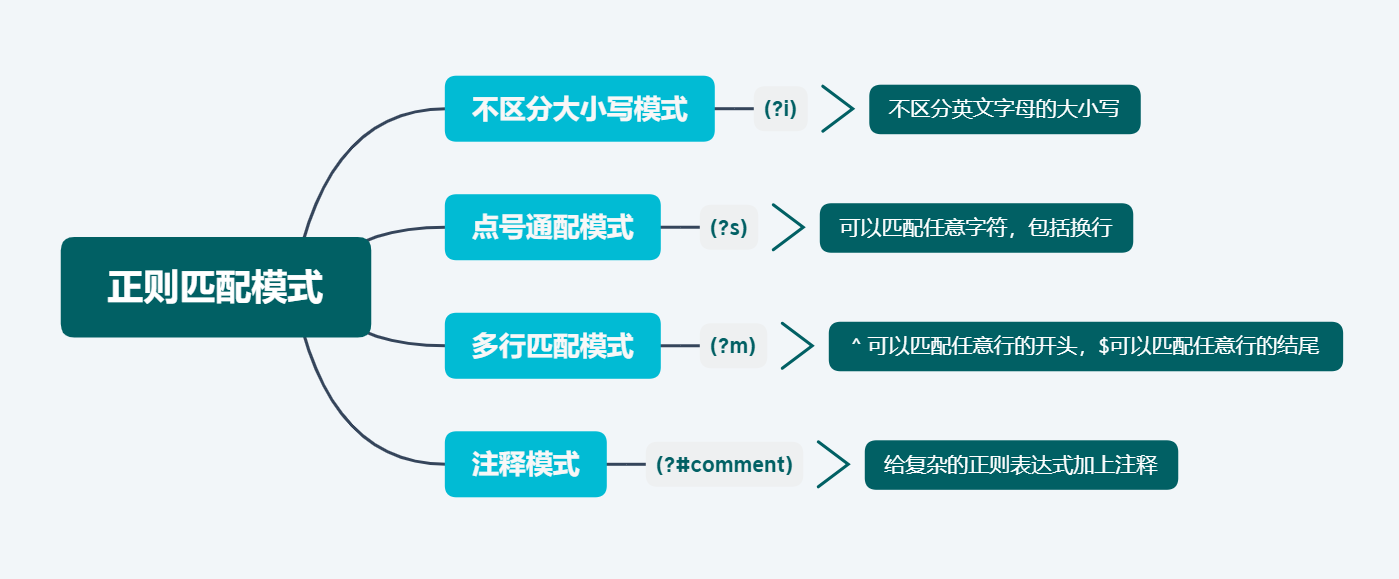
到这里,正则表达式的4种常见匹配模式就讲完了,如果有问题可以给我留言评论,谢谢。
正则表达式在线校验工具:https://regex101.com/


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









