







预备知识
二叉树的遍历
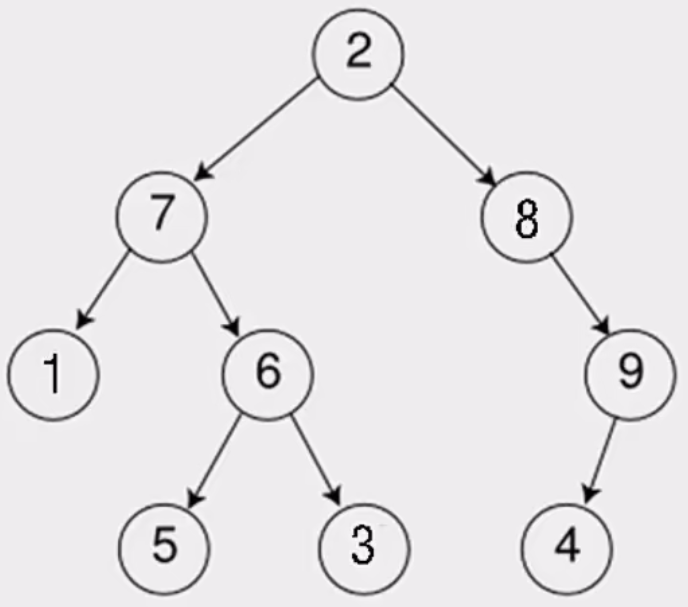
- 先根(序)遍历(根左右);
- 2 7 1 6 5 3 8 9 4
- 中根遍历(左根右);
- 1 7 5 6 3 2 8 4 9
- 后根遍历(左右根);
- 1 5 3 6 7 4 9 8 2
根据遍历结果确定二叉树
- 给定先根和中根遍历结果,是否可以唯一确定这棵二叉树?YES
- 先根遍历的第一个元素是根节点,即
2是根; - 在中根遍历中,根节点
2将序列分为左右子树:- 左子树中根遍历:
1, 7, 5, 6, 3(位于2左边); - 右子树中根遍历:
8, 4, 9(位于2右边);
- 左子树中根遍历:
- 通过递归重复上述过程,可以唯一构造出整棵树;
- 先根遍历的第一个元素是根节点,即
- 给定中根和后根遍历呢?YES
- 后根遍历的最后一个元素是根节点,即
2是根; - 在中根遍历中,根节点
2将序列分为左右子树:- 左子树中根遍历:
1, 7, 5, 6, 3; - 右子树中根遍历:
8, 4, 9;
- 左子树中根遍历:
- 通过递归重复上述过程,可以唯一构造出整棵树;
- 后根遍历的最后一个元素是根节点,即
- 给定先根和后根遍历呢?NO(除非二叉树满足一定条件,如每个非叶节点都有两个子节点)
- 先根和后根遍历无法直接区分左右子树的边界。例如,以下两棵不同的二叉树可能有相同的先根和后根遍历结果:
- 树1:根为
A,左子节点为B; - 树2:根为
A,右子节点为B; - 两棵树的先根遍历均为
A, B,后根遍历均为B, A,但结构不同。
- 树1:根为
- 先根和后根遍历无法直接区分左右子树的边界。例如,以下两棵不同的二叉树可能有相同的先根和后根遍历结果:
导引问题:从递归说起
-
斐波那契数列:
- f(0) = 1
- f(1) = 1
- f(n) = f(n-1) + f(n-2)
-
递归代码:
// 首先分析问题的“递归特征”——除了规模,其它一样 // 计算斐波那契数列的第n项 // 斐波那契数列定义:F(0)=1, F(1)=1, F(n)=F(n-1)+F(n-2) (n≥2) int fibo(int a) { // 先写出口(无需递归的特殊情况):如果n是0或1,直接返回1 if(a == 0 || a == 1) return 1; // 递归情况:否则返回前两项的和 else return fibo(a - 1) + fibo(a - 2); }
例1:n的全排列
-
输入一个正整数n,请按照字典序输出 1~n 的全排列,每个排列输出一行,每个数字后面跟一个空格;
-
Sample Input:
3 -
Sample OutPut:
1 2 3 1 3 2 2 1 3 2 3 1 3 1 2 3 2 1
-
-
问题的递归特征是什么?
- 如果第 1 个数确定,剩余的问题就是其余 n-1 个数的全排列;
- 如果前 k 个数已经排好,剩余的问题就是其余 n-k 个数的全排列;
-
以上面的输入输出样例为例:
- 确定了第一个数是
1,剩下的就是 2 个数的全排列,即2 3的全排列;- 然后确定第二个数……
- ……
- 确定了第一个数是
2,剩下的就是 2 个数的全排列,即1 3的全排列; - 确定了第一个数是
3,剩下的就是 2 个数的全排列,即1 2的全排列;
- 确定了第一个数是
-
代码:
#include <bits/stdc++.h> using namespace std; int n; // num数组是保存一次全排列的结果 // vis数组是一个标记数组 ,作用是记录数字是否已经被使用 int num[10], vis[10]; void dfs(int step); int main() { while(scanf("%d", &n) == 1) // 输入n代表求的是1~n的全排列,也是循环n次 { memset(vis, 0, sizeof(vis)); // 给vis数组初始化为全0数组 dfs(1); // 从第一个位置开始 } return 0; } void dfs(int step) { // 递归终止条件:当step超过n时,说明已经填完所有位置 if(step == n + 1) { // 输出当前排列 for(int i = 1; i <= n; i++) printf("%d ", num[i]); printf("\n"); return; } for(int i = 1; i <= n; i++) { // 循环遍历从1到n的数字 if(vis[i] == 0) { // 如果数字i还未被使用 num[step] = i; // 当前step位置选择数字i vis[i] = 1; // 标记数字i已被使用 dfs(step + 1); // 递归处理下一个位置 vis[i] = 0; // 回溯:取消数字i的标记,以便其他分支可以使用 // 当前数字i的所有可能排列已处理完毕,循环将继续尝试下一个可用数字(i+1) } } } -
步骤表格:
调用层次 step i 的值 vis数组 num数组 描述 1 1 1 [1,0,0] [1,0,0] 选择1,标记vis[1]=1,进入dfs(2) 2 2 1 [1,0,0] [1,0,0] i=1已被使用,跳过 2 2 2 [1,1,0] [1,2,0] 选择2,标记vis[2]=1,进入dfs(3) 3 3 1 [1,1,0] [1,2,0] i=1已被使用,跳过 3 3 2 [1,1,0] [1,2,0] i=2已被使用,跳过 3 3 3 [1,1,1] [1,2,3] 选择3,标记vis[3]=1,进入dfs(4) 4 4 - [1,1,1] [1,2,3] 输出排列: 1 2 3,返回 3 3 3 [1,1,0] [1,2,0] 回溯,vis[3]=0 2 2 2 [1,0,0] [1,0,0] 回溯,vis[2]=0 2 2 3 [1,0,1] [1,3,0] 选择3,标记vis[3]=1,进入dfs(3) 3 3 1 [1,0,1] [1,3,0] i=1已被使用,跳过 3 3 2 [1,1,1] [1,3,2] 选择2,标记vis[2]=1,进入dfs(4) 4 4 - [1,1,1] [1,3,2] 输出排列: 1 3 2,返回 3 3 2 [1,0,1] [1,3,0] 回溯,vis[2]=0 2 2 3 [1,0,0] [1,0,0] 回溯,vis[3]=0 1 1 1 [0,0,0] [0,0,0] 回溯,vis[1]=0 1 1 2 [0,1,0] [2,0,0] 选择2,标记vis[2]=1,进入dfs(2) 2 2 1 [1,1,0] [2,1,0] 选择1,标记vis[1]=1,进入dfs(3) 3 3 1 [1,1,0] [2,1,0] i=1已被使用,跳过 3 3 2 [1,1,0] [2,1,0] i=2已被使用,跳过 3 3 3 [1,1,1] [2,1,3] 选择3,标记vis[3]=1,进入dfs(4) 4 4 - [1,1,1] [2,1,3] 输出排列: 2 1 3,返回 3 3 3 [1,1,0] [2,1,0] 回溯,vis[3]=0 2 2 1 [0,1,0] [2,0,0] 回溯,vis[1]=0 2 2 2 [0,1,0] [2,0,0] i=2已被使用,跳过 2 2 3 [0,1,1] [2,3,0] 选择3,标记vis[3]=1,进入dfs(3) 3 3 1 [1,1,1] [2,3,1] 选择1,标记vis[1]=1,进入dfs(4) 4 4 - [1,1,1] [2,3,1] 输出排列: 2 3 1,返回 3 3 1 [0,1,1] [2,3,0] 回溯,vis[1]=0 2 2 3 [0,1,0] [2,0,0] 回溯,vis[3]=0 1 1 2 [0,0,0] [0,0,0] 回溯,vis[2]=0 1 1 3 [0,0,1] [3,0,0] 选择3,标记vis[3]=1,进入dfs(2) 2 2 1 [1,0,1] [3,1,0] 选择1,标记vis[1]=1,进入dfs(3) 3 3 1 [1,0,1] [3,1,0] i=1已被使用,跳过 3 3 2 [1,1,1] [3,1,2] 选择2,标记vis[2]=1,进入dfs(4) 4 4 - [1,1,1] [3,1,2] 输出排列: 3 1 2,返回 3 3 2 [1,0,1] [3,1,0] 回溯,vis[2]=0 2 2 1 [0,0,1] [3,0,0] 回溯,vis[1]=0 2 2 2 [0,1,1] [3,2,0] 选择2,标记vis[2]=1,进入dfs(3) 3 3 1 [1,1,1] [3,2,1] 选择1,标记vis[1]=1,进入dfs(4) 4 4 - [1,1,1] [3,2,1] 输出排列: 3 2 1,返回 3 3 1 [0,1,1] [3,2,0] 回溯,vis[1]=0 2 2 2 [0,0,1] [3,0,0] 回溯,vis[2]=0 2 2 3 [0,0,1] [3,0,0] i=3已被使用,跳过 1 1 3 [0,0,0] [0,0,0] 回溯,vis[3]=0 -
扩展1:如果现在题目从求1~n的全排列,变成了求 m~n 的全排列(m<n),该怎么做?
-
直接修改
dfs中的for循环,让i从m开始遍历到n,而不是从1开始:void dfs(int step) { if (step == (n - m + 1) + 1) { // 排列长度变为 (n - m + 1) for (int i = 1; i <= (n - m + 1); i++) cout << num[i] << " "; cout << endl; return; } for (int i = m; i <= n; i++) { // 遍历 m~n 的数字 if (!vis[i]) { num[step] = i; vis[i] = 1; dfs(step + 1); vis[i] = 0; // 回溯 } } } -
排列的长度不再是
n,而是n - m + 1(即m, m+1, ..., n共n - m + 1个数字); -
例如
m=2, n=4,则排列长度为3(数字2, 3, 4的全排列);
-
-
扩展2:如果现在题目又发生了变化,现在不求 m~n 的全排列,而是给出初始值m,然后 n 个数,这 n 个数并不是连续的(比如m=2,n=3,这n个数是
2 5 7),求这组数的全排列,该怎么做?-
可以先用一个数组存储可选数字,再生成全排列:
vector<int> nums; // 存储 m~n 的数字 bool vis[10]; // 标记是否使用过 int ans[10]; // 存储当前排列 void dfs(int step) { if (step == nums.size() + 1) { for (int i = 1; i <= nums.size(); i++) cout << ans[i] << " "; cout << endl; return; } for (int i = 0; i < nums.size(); i++) { // 从 nums 数组中取出可以排列的数字 if (!vis[i]) { ans[step] = nums[i]; vis[i] = 1; dfs(step + 1); vis[i] = 0; // 回溯 } } } int main() { int m = 2, n = 4; for (int i = m; i <= n; i++) // 初始化可选数字 nums.push_back(i); dfs(1); return 0; }
-
-
扩展3:如果现在题目再次发生了变化,给出任意一组数,求这组数的全排列,该怎么做?
-
基于交换的回溯法(无重复数字):通过交换数组元素的位置生成排列,避免使用
vis数组#include <iostream> #include <vector> using namespace std; void backtrack(vector<int>& nums, int start, vector<vector<int>>& res) { if (start == nums.size()) { res.push_back(nums); // 找到一个排列 return; } for (int i = start; i < nums.size(); i++) { swap(nums[start], nums[i]); // 交换当前位置 backtrack(nums, start + 1, res); // 递归下一层 swap(nums[start], nums[i]); // 回溯,恢复交换 } } vector<vector<int>> permute(vector<int>& nums) { vector<vector<int>> res; backtrack(nums, 0, res); return res; } int main() { vector<int> nums = {2, 3, 5}; auto res = permute(nums); for (auto& p : res) { for (int num : p) cout << num << " "; cout << endl; } return 0; } -
基于DFS+剪枝(允许重复数字):用
vis数组标记已用数字,并通过排序+剪枝跳过重复数字#include <iostream> #include <vector> #include <algorithm> using namespace std; void dfs(vector<int>& nums, vector<bool>& vis, vector<int>& path, vector<vector<int>>& res) { if (path.size() == nums.size()) { res.push_back(path); return; } for (int i = 0; i < nums.size(); i++) { if (vis[i]) continue; // 已使用过,跳过 // 剪枝:如果当前数字和前一个相同,且前一个未被使用,则跳过(避免重复) if (i > 0 && nums[i] == nums[i - 1] && !vis[i - 1]) continue; vis[i] = true; path.push_back(nums[i]); dfs(nums, vis, path, res); path.pop_back(); // 回溯 vis[i] = false; } } vector<vector<int>> permuteUnique(vector<int>& nums) { vector<vector<int>> res; vector<bool> vis(nums.size(), false); vector<int> path; sort(nums.begin(), nums.end()); // 必须先排序才能剪枝 dfs(nums, vis, path, res); return res; } int main() { vector<int> nums = {1, 1, 2}; auto res = permuteUnique(nums); for (auto& p : res) { for (int num : p) cout << num << " "; cout << endl; } return 0; } -
使用STL的
next_permutation(最简洁):C++标准库的next_permutation会自动生成下一个排列#include <iostream> #include <vector> #include <algorithm> using namespace std; vector<vector<int>> permute(vector<int>& nums) { vector<vector<int>> res; sort(nums.begin(), nums.end()); // 必须先排序 do { res.push_back(nums); } while (next_permutation(nums.begin(), nums.end())); return res; } int main() { vector<int> nums = {2, 1, 1}; // 允许重复 auto res = permute(nums); for (auto& p : res) { for (int num : p) cout << num << " "; cout << endl; } return 0; }
-
深度优先搜索的基本模型
-
深度优先搜索的关键在于解决“当下该如何做”;
-
至于下一步怎么做,则与当前一样(只是参数不同而已)
-
深度优先搜索的基本模型:
void dfs(int step) { 特殊情况处理(一般是结束递归的情况) 枚举当前每一种可能for(i = 1; i <= n; ++i) 在枚举的每一种可能中,递归dfs(step + 1); }
例2 骨头的诱惑
-
一只小狗在一个古老的迷宫里找到一根骨头,当它叼起骨头时,迷宫开始颤抖,它感觉到地面开始下沉。它才明白骨头是一个陷阱,它拼命地试着逃出迷宫。
迷宫是一个N×M 大小的长方形,迷宫有一个门。刚开始门是关着的,并且这个门会在第 T 秒钟开启,门只会开启很短的时间(少于一秒),因此小狗必须恰好在第 T 秒达到门的位置。每秒钟,它可以向上、下、左或右移动一步到相邻的方格中。但一旦它移动到相邻的方格,这个方格开始下沉,而且会在下一秒消失。所以,它不能在一个方格中停留超过一秒,也不能回到经过的方格。小狗能成功逃离吗?请你帮助它;-
Sample Input:
4 4 5 // 迷宫是4×5的长方形,门会在第 5 秒开启 S.X. // S是起始位置、.是可以走的位置、X是墙的位置、D是门的位置 ..X. ..XD .... // 要 7 秒才走的到门的位置,所以不可以逃离 3 4 5 S.X. ..X. // 5 秒就可以走到门的位置,所以可以逃离 ...D 0 0 0 -
Sample Output:
NO YES
-
-
这个问题可以归类为网格图中的路径搜索问题,类似于经典的“迷宫问题”或“网格行走问题”;
- 但与普通迷宫问题不同的是:
- 时间精确性:必须在恰好T步时到达终点;
- 不可重复访问:路径不能有重复的格子(因为走过的格子会消失);
- 这类似于哈密尔顿路径问题(经过每个格子恰好一次的路径),但更宽松,因为不需要经过所有格子;
- 但与普通迷宫问题不同的是:
-
解法:回溯搜索(DFS + 剪枝)
- 从起点出发,尝试所有可能的方向;
- 每次移动后,标记当前格子为已访问;
- 如果到达门的位置且时间为T,则成功;
- 如果时间超过T或无法继续移动,则回溯;
- 然而,纯回溯的复杂度是指数级的(大约O(4^T)),对于较大的N、M、T会非常低效。因此,必须通过剪枝来减少搜索空间;
-
剪枝的核心思想是提前排除不可能到达目标的情况,从而减少不必要的搜索。以下是针对本题的剪枝策略:
-
最短路径剪枝
- 小狗至少需要 D 步到达门。比如小狗至少要 6 步才可以到达门,但是门在第 5 秒就关了;
- 剪枝条件:
if (T < D) return false;
-
剩余步数无法到达剪枝
-
即使 T >= D,在每一步移动时,检查当前剩余的时间是否足够小狗从当前位置走到门的位置。如果不够,就直接剪枝;
-
实现:在DFS过程中,设当前位置为
(x, y),剩余时间为t,则:if (|x - ex| + |y - ey| > t) return false;
-
-
可访问格子不足剪枝
-
迷宫共有 N×M 个格子,小狗需要移动T步(访问T+1个格子,包括起点);
-
剪枝条件:
if (T + 1 > N * M) return false;(因为至少需要T+1个格子才能走T步不重复);
-
-
连通性剪枝
-
起点和门必须在同一个连通区域中(即存在至少一条路径连接它们)。
-
实现:可以用BFS或DFS预先检查连通性。如果不连通,直接返回false;
-
-
奇偶性剪枝
- 从起点(sx, sy)到门(ex, ey)的最短曼哈顿距离为
D = |sx - ex| + |sy - ey|; - 如果 D 和 T 的奇偶性不同,则无法恰好用 T 步到达门;
- 剪枝条件:
if (D % 2 != T % 2) return false;
- 从起点(sx, sy)到门(ex, ey)的最短曼哈顿距离为
-
-
下面重点解释一下奇偶性剪枝:
-
曼哈顿距离(Manhattan Distance):
- 从当前位置
(x, y)到门(ex, ey)的最短步数是|x - ex| + |y - ey|(即只能上下左右移动); - 例如,如果小狗在
(2, 3),门在(4, 5),那么最短距离是|4-2| + |5-3| = 2 + 2 = 4步;
- 从当前位置
-
在奇偶性剪枝中,可以把迷宫的地图看成这样:
0 1 0 1 0 1 1 0 1 0 1 0 0 1 0 1 0 1 1 0 1 0 1 0 0 1 0 1 0 1- 从为 0 的格子走一步,必然走向为 1 的格子;
- 从为 1 的格子走一步,必然走向为 0 的格子;
- 即:0 -> 1或 1 -> 0 必然需要奇数步,0 -> 0 或 1 -> 1 必然需要偶数步;
-
所以:
- 如果起点和门的奇偶性相同(比如
0 → 0),则必须走偶数步; - 如果起点和门的奇偶性不同(比如
0 → 1),则必须走奇数步;
- 如果起点和门的奇偶性相同(比如
-
如果 T 的奇偶性和 D(最短步数)的奇偶性不一致,说明无法在 T 步到达门,可以直接剪枝;
-
-
代码:
#include <bits/stdc++.h> using namespace std; char Map[9][9]; // 迷宫地图(最大 8x8,索引从 1 开始) int n, m, t; // 迷宫行数、列数、门开启时间 int di, dj; // 门的位置 (di, dj) bool escape; // 是否成功逃脱的标志 int dir[4][2] = { {0, -1}, {0, 1}, {1, 0}, {-1, 0} }; // 移动方向(左、右、下、上) void dfs(int si, int sj, int cnt); int main() { int i, j, si, sj; // 循环变量和起点坐标 while (cin >> n >> m >> t) // 输入迷宫行数、列数、门开启时间 { if (n == 0 && m == 0 && t == 0) break; int wall = 0; // 统计墙的数量 // 读取迷宫地图 for (i = 1; i <= n; i++) for (j = 1; j <= m; j++) { cin >> Map[i][j]; if (Map[i][j] == 'S') // 记录起点坐标 { si = i; sj = j; } else if (Map[i][j] == 'D') // 记录门的位置 { di = i; dj = j; } else if (Map[i][j] == 'X') // 统计墙的数量 wall++; } // 剪枝:如果可走格子数 <= 需要的时间t,直接输出NO // 为什么 =t 也不行? // 时间t其实也是需要走的步数,那么要走完这t步,实际上需要t+1个格子。而可走格子数 = t,就不可行 if (n * m - wall <= t) { cout << "NO" << endl; continue; // 跳过本次循环的剩余部分 } escape = 0; // 初始化逃脱标志为false Map[si][sj] = 'X'; // 标记起点为已访问(相当于墙) dfs(si, sj, 0); // 开始深度优先搜索。传入起始坐标和所花的时间 if (escape) cout << "YES" << endl; else cout << "NO" << endl; } return 0; } void dfs(int si, int sj, int cnt) { int i, temp; // 边界检查:如果越界则返回 if (si > n || sj > m || si <= 0 || sj <= 0) return; // 成功条件:当前步数等于t且到达门的位置 if (cnt == t && si == di && sj == dj) escape = 1; if (escape) return; // 如果已经找到解,直接返回 // 剩余步数无法到达剪枝 // t - cnt:剩余时间 // (abs(si - di) + abs(sj - dj)):当前最短步数 D temp = (t - cnt) - abs(si - di) - abs(sj - dj); // 如果剩余时间不足以到达门,或奇偶性不符,则剪枝 if (temp < 0 || temp % 2 == 1) return; // 为什么上面是 temp % 2 == 1,而不是 temp % 2 == 0? // temp = (t - cnt) - D // 如果 (t - cnt) 和 D 的奇偶性 相同,则 temp 是 偶数(因为 偶数 - 偶数 = 偶数,奇数 - 奇数 = 偶数) // 如果 (t - cnt) 和 D 的奇偶性 不同,则 temp 是 奇数(因为 偶数 - 奇数 = 奇数,奇数 - 偶数 = 奇数) // 如果 temp % 2 == 1,说明 (t - cnt) 和 D 的奇偶性不同,即剩余步数的奇偶性和最短路径的奇偶性不匹配,必须剪枝 // 反之,如果 temp % 2 == 0,说明奇偶性匹配,可以继续搜索。 // 按照左、右、下、上的顺序,尝试四个方向 for (i = 0; i < 4; i++) { // 检查下一个位置是否可走(即不是墙) if (Map[si + dir[i][0]][sj + dir[i][1]] != 'X') { // 标记为已访问(不走回头路) Map[si + dir[i][0]][sj + dir[i][1]] = 'X'; // 递归搜索 dfs(si + dir[i][0], sj + dir[i][1], cnt + 1); // 回溯:恢复为可走状态 Map[si + dir[i][0]][sj + dir[i][1]] = '.'; } } return; }



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











