







对这块一直都比较迷,昨天有空看了下,就写篇博客记录下。
1.前言
如何证明一个算法的优劣,一般来说,我们不可能去上机一一亲自测试,一群素昧谋面的甲乙丙丁等人,整理出一个理论叫做时间复杂度。十分感谢这些可爱的人。
2.概念
我们只需要知道算法花费的时间多少就行了。而且一个算法花费时间的多少和算法中的语句的执行次数成正比例。哪个算法的执行次数多,他花费的时间就多。一个算法中的语句执行次数被称为语句频度或时间频度。记为T(n)。算法的时间复杂度是指执行算法所需要的计算工作量。
在刚才提到的时间频度中,n称为问题的规模,当n不断变化时,时间频度T(n)也会不断变化。但有时我们想知道它变化时呈现什么规律。为此,我们引入时间复杂度概念。
一般情况下,算法中基本操作重复执行的次数是问题规模n的某个函数,用T(n)表示,若有某个辅助函数f(n),使得当n趋近于无穷大时,T(n)/f(n)的极限值为不等于零的常数,则称f(n)是T(n)的同数量级函数。记作T(n)=O(f(n)),称O(f(n)) 为算法的渐进时间复杂度,简称时间复杂度。
在各种不同算法中,若算法中语句执行次数为一个常数,则时间复杂度为O(1),另外,在时间频度不相同时,时间复杂度有可能相同,如T(n)=n^2+3n+4与T(n)=4n^2+2n+1它们的频度不同,但时间复杂度相同,都为O(n^2)。
3.常见的时间复杂度
常数阶O(1),对数阶O(log2n)(以2为底n的对数,下同),线性阶O(n),
线性对数阶O(nlog2n),平方阶O(n^2),立方阶O(n^3),…,
指数阶O(2^n)。随着问题规模n的不断增大,上述时间复杂度不断增大,算法的执行效率越低。
常见的算法时间复杂度由小到大依次为:
Ο(1)<Ο(log2ⁿ)<Ο(n)<Ο(nlog2ⁿ)<Ο(n²)<Ο(n³)<…<Ο(2ⁿ)<Ο(n!)

注1:快速的数学回忆,loga b = y 其实就是 a y = b。所以,log2 4 = 2,因为 2² = 4。同样 log2 8 = 3,因为 2³ = 8。我们说,log2ⁿ 的增长速度要慢于 n,因为当 n = 8 时,log2ⁿ = 3。
注2:通常将以 10 为底的对数叫做常用对数。为了简便,N 的常用对数 log10 N 简写做 lg N,例如 log10 5 记做 lg 5。
注3:通常将以无理数 e 为底的对数叫做自然对数。为了方便,N 的自然对数 logeⁿ 简写做 ln N,例如 loge ³ 记做 ln 3。
注4:在算法导论中,采用记号 lg n = log2 n ,也就是以 2 为底的对数。改变一个对数的底只是把对数的值改变了一个常数倍,所以当不在意这些常数因子时,我们将经常采用 “lg n”记号,就像使用 O 记号一样。计算机工作者常常认为对数的底取 2 最自然,因为很多算法和数据结构都涉及到对问题进行二分。
4.求解算法的时间复杂度
具体步骤是:
⑴ 找出算法中的基本语句;
算法中执行次数最多的那条语句就是基本语句,如果是循环,通常是最内层循环的循环体。
⑵ 计算基本语句的执行次数的数量级;
只需计算基本语句执行次数的数量级,这就意味着只要保证基本语句执行次数的函数中的最高次幂正确即可,可以忽略所有低次幂和最高次幂的系数。这样能够简化算法分析,并且使注意力集中在最重要的一点上:增长率。
⑶ 用大Ο记号表示算法的时间性能。
将基本语句执行次数的数量级放入大Ο记号中。
如果算法中包含嵌套的循环,则基本语句通常是最内层的循环体,如果算法中包含并列的循环,则将并列循环的时间复杂度相加。例如:
for (i=1; i<=n; i++)
x++;
for (i=1; i<=n; i++)
for (j=1; j<=n; j++)
x++; 第一个for循环的时间复杂度为o(n),第二个for循环的时间复杂度为o(n²),则时间复杂度的总和为o(n+n²)=o(n²)
再举几个其他例子。
(1)、O(1)
temp=i;
i=j;
j=temp; 以上三条单个语句的频度均为1,该程序段的执行时间是一个与问题规模n无关的常数。算法的时间复杂度为常数阶,记作T(n)=O(1)。
注意:如果算法的执行时间不随着问题规模n的增加而增长,即使算法中有上千条语句,其执行时间也不过是一个较大的常数。此类算法的时间复杂度是O(1)。
(2)、O(n²)
2.1. 交换i和j的内容
sum=0; (一次)
for(i=1;i<=n;i++) (n+1次)
for(j=1;j<=n;j++) (n+1次)
sum++; 解:因为Θ(n²+2n+1)=n²(Θ即:去低阶项,去掉常数项,去掉高阶项的常参得到),所以T(n)= =O(n²);
2.2.
for (i=1;i<n;i++)
{
y=y+1; ①
for (j=0;j<=(2*n);j++)
x++; ②
} 解: 语句1的频度是n-1
语句2的频度是(n-1)*(2n+1)=2n²-n-1
f(n)=2n²-n-1+(n-1)=2n²-2;
又Θ(2n²-2)=n2
该程序的时间复杂度T(n)=O(n²).
一般情况下,对步进循环语句只需考虑循环体中语句的执行次数,忽略该语句中步长加1、终值判别、控制转移等成分,当有若干个循环语句时,算法的时间复杂度是由嵌套层数最多的循环语句中最内层语句的频度f(n)决定的。
(3)、O(n)
a=0;
b=1; ①
for (i=1;i<=n;i++) ②
{
s=a+b; ③
b=a; ④
a=s; ⑤
} 解: 语句1的频度:2,
语句2的频度: n,
语句3的频度: n-1,
语句4的频度:n-1,
语句5的频度:n-1,
T(n)=2+n+3(n-1)=4n-1=O(n).
(4)、O(log2ⁿ)
i=1; ①
hile (i<=n)
i=i*2; ② 解: 语句1的频度是1,
设语句2的频度是f(n), 则:2^f(n)<=n;f(n)<=log2ⁿ
取最大值f(n)=log2ⁿ,
T(n)=O(log2ⁿ)
(5)、O(n³)
for(i=0;i<n;i++)
{
for(j=0;j<i;j++)
{
for(k=0;k<j;k++)
x=x+2;
}
} 解:当i=m, j=k的时候,内层循环的次数为k当i=m时, j 可以取 0,1,…,m-1 , 所以这里最内循环共进行了0+1+…+m-1=(m-1)m/2次所以,i从0取到n, 则循环共进行了: 0+(1-1)*1/2+…+(n-1)n/2=n(n+1)(n-1)/6所以时间复杂度为O(n3).
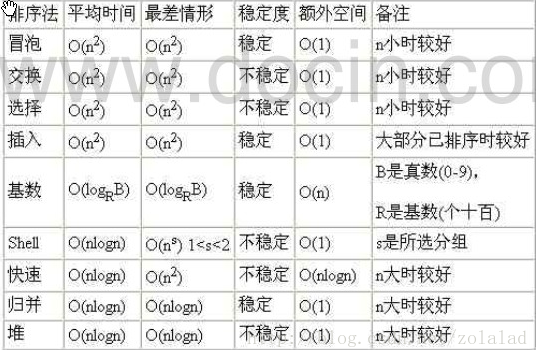
(6)常用的算法的时间复杂度















 6293
6293

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









