







Stage在提交过程中,会产生两种Task,ShuffleMapTask和ResultTask。在ShuffleMapTask执行过程中,会产生Shuffle结果的写磁盘操作。
![]()
![]()

![]()
![]()

![]()
1. ShuffleMapTask.runTask
此方法是Task执行的入口。
override def runTask(context: TaskContext): MapStatus = {
// Deserialize the RDD using the broadcast variable.
val ser = SparkEnv.get.closureSerializer.newInstance()
val (rdd, dep) = ser.deserialize[(RDD[_], ShuffleDependency[_, _, _])](
ByteBuffer.wrap(taskBinary.value), Thread.currentThread.getContextClassLoader)
metrics = Some(context.taskMetrics)
var writer: ShuffleWriter[Any, Any] = null
try {
val manager = SparkEnv.get.shuffleManager
writer = manager.getWriter[Any, Any](dep.shuffleHandle, partitionId, context)
writer.write(rdd.iterator(partition, context).asInstanceOf[Iterator[_ <: Product2[Any, Any]]])
return writer.stop(success = true).get
} catch {
...
}
}
(1)从SparkEnv中获取ShuffleManager对象;
(2)ShuffleManager对象将创建ShuffleWriter对象;
(3)通过ShuffleWriter对象进行shuffle结果写操作。
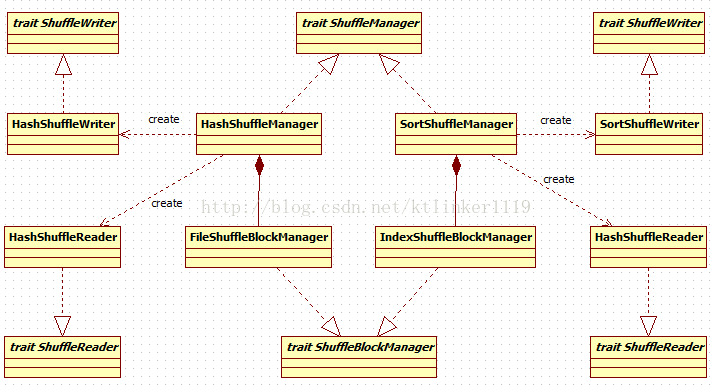
ShuffleManager是一个trait,它有两个具体实现:
HashShuffleManager和SortShuffleManager。
在Spark1.3中,默认使用
SortShuffleManager实现。代码如下:
val shortShuffleMgrNames = Map(
"hash" -> "org.apache.spark.shuffle.hash.HashShuffleManager",
"sort" -> "org.apache.spark.shuffle.sort.SortShuffleManager")
val shuffleMgrName = conf.get("spark.shuffle.manager", "sort")
val shuffleMgrClass = shortShuffleMgrNames.getOrElse(shuffleMgrName.toLowerCase, shuffleMgrName)
val shuffleManager = instantiateClass[ShuffleManager](shuffleMgrClass)
具体代码见SparkEnv.create方法。
2. 类关系图
3. HashShuffleManager
private[spark] class HashShuffleManager(conf: SparkConf) extends ShuffleManager {
private val fileShuffleBlockManager = new FileShuffleBlockManager(conf)
...
HashShuffleManager通过FileShuffleBlockManager来管理Shuffle Block。
3.1. HashShuffleWriter
HashShuffleManager.getWriter方法创建该对象。
private[spark] class HashShuffleWriter[K, V](
shuffleBlockManager: FileShuffleBlockManager,
handle: BaseShuffleHandle[K, V, _],
mapId: Int,
context: TaskContext)
extends ShuffleWriter[K, V] with Logging {
private val dep = handle.dependency
private val numOutputSplits = dep.partitioner.numPartitions
private val metrics = context.taskMetrics
// Are we in the process of stopping? Because map tasks can call stop() with success = true
// and then call stop() with success = false if they get an exception, we want to make sure
// we don't try deleting files, etc twice.
private var stopping = false
private val writeMetrics = new ShuffleWriteMetrics()
metrics.shuffleWriteMetrics = Some(writeMetrics)
private val blockManager = SparkEnv.get.blockManager
private val ser = Serializer.getSerializer(dep.serializer.getOrElse(null))
private val shuffle = shuffleBlockManager.forMapTask(dep.shuffleId, mapId, numOutputSplits, ser,
writeMetrics)
...
HashShuffleWriter构造体中最重要的工作就是调用FileShuffleBlockManager.forMapTask方法来创建ShuffleWriterGroup对象。
3.1.1. ShuffleWriterGroup
/** A group of writers for a ShuffleMapTask, one writer per reducer. */
private[spark] trait ShuffleWriterGroup {
val writers: Array[BlockObjectWriter]
/** @param success Indicates all writes were successful. If false, no blocks will be recorded. */
def releaseWriters(success: Boolean)
}
如果注释所描述,ShuffleWriterGroup就是writer的集合。
3.1.2. FileShuffleBlockManager.forMapTask
def forMapTask(shuffleId: Int, mapId: Int, numBuckets: Int, serializer: Serializer,
writeMetrics: ShuffleWriteMetrics) = {
new ShuffleWriterGroup {
shuffleStates.putIfAbsent(shuffleId, new ShuffleState(numBuckets))
private val shuffleState = shuffleStates(shuffleId)
private var fileGroup: ShuffleFileGroup = null
...
}
}
参数说明:
(1)mapId:RDD分区的编号;
(2)numBuckets:reudce的数量,即Shuffle输出的分区个数。
HashShuffleManager支持两种创建Writer的方法:consolidate和非consolidate方式,通过spark属性进行设置:
private val consolidateShuffleFiles =
conf.getBoolean("spark.shuffle.consolidateFiles", false)3.1.2.1. 非consolidate方式
forMapTask代码的else部分。
} else {
Array.tabulate[BlockObjectWriter](numBuckets) { bucketId =>
val blockId = ShuffleBlockId(shuffleId, mapId, bucketId)
val blockFile = blockManager.diskBlockManager.getFile(blockId)
// Because of previous failures, the shuffle file may already exist on this machine.
// If so, remove it.
if (blockFile.exists) {
if (blockFile.delete()) {
logInfo(s"Removed existing shuffle file $blockFile")
} else {
logWarning(s"Failed to remove existing shuffle file $blockFile")
}
}
blockManager.getDiskWriter(blockId, blockFile, serializer, bufferSize, writeMetrics)
}
}
(1)创建长度为numBuckets的BlockObjectWriter数组并遍历数组;
(2)根据ShuffleId、mapid和bucketId创建ShuffleBlockId对象;
(3)根据ShuffleBlockId对象创建文件;
(4)创建DiskBlockObjectWriter对象。
文件名结构:
shuffel_{$shuffleId}_{$mapId}_{$reduceId}
其中:mapId是RDD分区的编号,reduceId即代码中的bucketId,及Shuffle输出分区的编号。
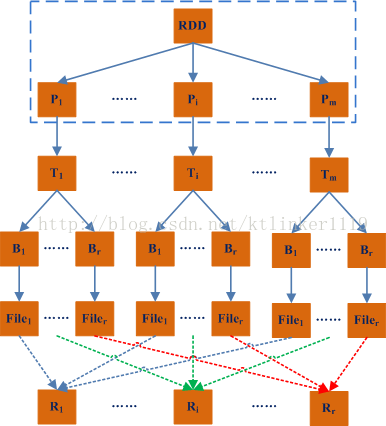
从代码和文件结构可以看出,每个分区即每个ShuffleMapTask都会创建和reduce数量一致的文件数量。
如果一个RDD分区的数量为M,即有M个map task;如果Shuffle输出分区个数为R,那么非consolidate方法将总共会创建M*R个文件。
当M和R很大时,即使这些文件分布在多个节点,也会是一个不小的数字。
Map和Reduce的映射关系示意图如下
:
说明:P表示RDD的分区,T表示partition对应的Task,B表示Bucket,File为Bucket对应的文件,R表示Reduce即Shuffle的输出分区。
3.1.2.2. consolidate方式
forMapTask代码的if部分。
val writers: Array[BlockObjectWriter] = if (consolidateShuffleFiles) {
fileGroup = getUnusedFileGroup()
Array.tabulate[BlockObjectWriter](numBuckets) { bucketId =>
val blockId = ShuffleBlockId(shuffleId, mapId, bucketId)
blockManager.getDiskWriter(blockId, fileGroup(bucketId), serializer, bufferSize,
writeMetrics)
}
}
(1)获取或创建可以使用ShuffleFileGroup对象;
接下来的流程和非consolidate方式相同,区别在创建
DiskBlockObjectWriter时,是从ShuffleFileGroup中获取文件对象。
下面看看
ShuffleFileGroup是如何创建的,代码如下:
private def newFileGroup(): ShuffleFileGroup = {
val fileId = shuffleState.nextFileId.getAndIncrement()
val files = Array.tabulate[File](numBuckets) { bucketId =>
val filename = physicalFileName(shuffleId, bucketId, fileId)
blockManager.diskBlockManager.getFile(filename)
}
val fileGroup = new ShuffleFileGroup(shuffleId, fileId, files)
shuffleState.allFileGroups.add(fileGroup)
fileGroup
}
(1)获取文件id,fileId;
(2)
创建长度为numBuckets的File数组并遍历数组来初始化数组元素;
(3)根据shuffleId、bucketId和fileId创建block文件名;
(4)创建shuffle输出文件;
(5)创建ShuffleFileGroup对象,其本质上就是一个File数组。
文件名结构:
merged_shuffle_{$shuffleId}_{$bucketId}_{$fileId}
从代码和文件结构可以看出,每个分区即每个ShuffleMapTask都会对应一个上述的文件。当多个ShuffleMapTask在一个core上串行执行时,它们会将数据写入相同的文件;当多个ShuffleMapTask在一个worker上并行执行时,从代码可以看出,文件名发生变化的只有FileId部分,所以在一个节点上所产生的文件数量最多为cores*R(其中cores表示分配个app的core的数量,R为reudce数量)。
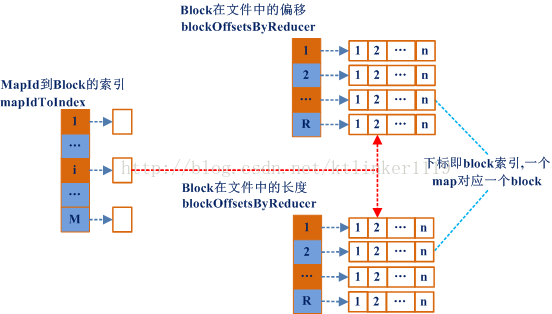
由于多个map将block数据写入同一个文件,每个block占用文件的一个段,因此需要一个数据结构来保存给block在文件中的偏移和block长度。
ShuffleFileGroup类中定义了三个结构来实现这个功能,代码如下:
/**
* Stores the absolute index of each mapId in the files of this group. For instance,
* if mapId 5 is the first block in each file, mapIdToIndex(5) = 0.
*/
private val mapIdToIndex = new PrimitiveKeyOpenHashMap[Int, Int]()
/**
* Stores consecutive offsets and lengths of blocks into each reducer file, ordered by
* position in the file.
* Note: mapIdToIndex(mapId) returns the index of the mapper into the vector for every
* reducer.
*/
private val blockOffsetsByReducer = Array.fill[PrimitiveVector[Long]](files.length) {
new PrimitiveVector[Long]()
}
private val blockLengthsByReducer = Array.fill[PrimitiveVector[Long]](files.length) {
new PrimitiveVector[Long]()
}
Map和Reduce映射示意图:
在同一core运行的Tasks会共享同一文件,而在一个Executor中并行执行的Tasks拥有各自独立的文件。
mapId和block偏移映射示意图(ShuffleFileGroup)
:
mapIdToIndex是一个hash表,存储mapid到block索引之间的映射关系。通过mapId可以获取对应Block编号,通过block的编号就可以获取map输出到每个分区的偏移和长度。
4. SortShuffleManager
private[spark] class SortShuffleManager(conf: SparkConf) extends ShuffleManager {
private val indexShuffleBlockManager = new IndexShuffleBlockManager(conf)
private val shuffleMapNumber = new ConcurrentHashMap[Int, Int]()
...
SortShuffleManager通过IndexShuffleBlockManager来管理Shuffle Block。
4.1. SortShuffleWriter.write
override def write(records: Iterator[_ <: Product2[K, V]]): Unit = {
......
val outputFile = shuffleBlockManager.getDataFile(dep.shuffleId, mapId)
val blockId = shuffleBlockManager.consolidateId(dep.shuffleId, mapId)
val partitionLengths = sorter.writePartitionedFile(blockId, context, outputFile)
shuffleBlockManager.writeIndexFile(dep.shuffleId, mapId, partitionLengths)
mapStatus = MapStatus(blockManager.shuffleServerId, partitionLengths)
}
(1)创建数据文件,文件名格式:
shuffle_{$shuffleId}_{$mapId}_{$reduceId}.data
reduceId值为0
(2)创建ShuffleBlockId对象,其中的reduceId值为0;
(3)将shuffle输出分区写入数据文件;
(4)将分区索引信息写入索引文件,索引文件名格式:
shuffle_{$shuffleId}_{$mapId}_{$reduceId}.index
(5)创建MapStatus对象并返回。
Map和Reduce映射示意图:
可见,在SortShuffleManager下,每个map对应两个文件:data文件和index文件。
其中.data文件存储Map输出分区的数据,.index文件存储每个分区在.data文件中的偏移量及数据长度。
4.2. IndexShuffleBlockManager.writeIndexFile
def writeIndexFile(shuffleId: Int, mapId: Int, lengths: Array[Long]) = {
val indexFile = getIndexFile(shuffleId, mapId)
val out = new DataOutputStream(new BufferedOutputStream(new FileOutputStream(indexFile)))
try {
// We take in lengths of each block, need to convert it to offsets.
var offset = 0L
out.writeLong(offset)
for (length <- lengths) {
offset += length
out.writeLong(offset)
}
} finally {
out.close()
}
}
实际只存储了每个分区的偏移,通过偏移来计算每个分区的长度。














 798
798











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









