







国际计算语言学年会(Annual Meeting of the Association for Computational Linguistics,简称ACL)是由国际计算语言学协会(Association for Computational Linguistics)主办的学术盛会,每年举办一次。作为计算语言学和自然语言处理领域最具影响力的会议之一,第62届ACL即将于8月11日至16日在泰国首都曼谷隆重举办。近日,ACL正式公布了论文录用名单,快手凭借其在人工智能领域的深厚积累,成功入选四篇论文。这些研究涵盖了快手独立自研的快意大语言模型在多轮对话、复杂推理、RLHF等领域的深入探索与最新进展,以及MoE在搜索技术上的创新应用。

论文01:Parrot: Enhancing Multi-Turn Instruction Following for Large Language Models
| 论文地址:https://arxiv.org/pdf/2310.07301
| 论文作者:Yuchong Sun,Che Liu,Kun Zhou,Jingwen Huang,Ruihua Song,Xin Zhao,Fuzheng Zhang,Di Zhang
| 论文简介:人们经常需要通过与大语言模型(Large Language Models, LLMs)进行多轮对话来获取所需的答案或更多信息。然而,目前的研究往往忽视了LLMs在遵循多轮指令方面的能力,包括训练数据集、训练方法和评估标准等方面。为了解决这一问题,本文提出了一个名为Parrot的方案,旨在提升LLMs在多轮指令遵循方面的表现。
首先,我们介绍了一种高效的方法,用于收集多轮交互的指令数据,例如使用指代和省略。我们利用预训练模型和诸如ShareGPT等公开的人机对话日志,通过监督式微调(Supervised Fine-Tuning, SFT)过程,训练一个提问模型(Ask Model),该模型模拟用户提问并与大型模型进行对话,以此生成超过10轮的多轮对话数据。其次,我们提出了一种上下文感知的偏好优化策略CaPO(Context-Aware Preference Optimization)。该策略通过对多轮对话数据的上下文进行编辑(如删除、替换、添加噪音等),构建具备上下文感知的正负样本对,从而进一步增强LLMs在多轮互动中处理复杂指令的能力。此外,为了定量评估LLMs在多轮指令遵循方面的表现,我们构建了一个基于现有基准MT-Bench的扩展评估基准,称为MT-Bench++。这个新的评估基准包含8轮对话,能够更全面地测试和评估LLMs在多轮指令遵循方面的能力。

*本篇为快意大模型团队与中国人民大学合作研究
论文02:Just Ask One More Time! Self-Agreement Improves Reasoning of Language Models in (Almost) All Scenarios
| 论文地址:https://arxiv.org/abs/2311.08154
| 论文作者:Lei Lin,Jiayi Fu,Pengli Liu,Qingyang Li,Yan Gong,Junchen Wan,Fuzheng Zhang,Zhongyuan Wang,Di Zhang
| 论文简介:尽管思想链(CoT)提示与语言模型相结合在复杂推理任务上取得了令人鼓舞的结果,但CoT提示中使用的朴素贪婪解码通常会导致重复性和局部最优性。
为了解决这个缺点,集成优化尝试获取多个推理路径来获得最终的答案集合。然而,当前的集成优化方法要么简单地采用基于规则的后处理(例如 Self-Consistency),要么基于多个与任务相关的人工注释训练一个额外的模型以在多个推理路径中选择最佳的一个,但无法泛化到输入问题类型未知或推理路径答案格式未知的现实场景中。为了避免它们的局限性,我们提出了Self-Agreement,这是一种通用的集成优化方法,适用于几乎所有输入问题类型和推理路径答案格式可能已知或未知的现实场景。Self-Agreement首先从语言模型的解码器中采样,生成一组不同的推理路径,然后通过再次提示语言模型在采样的推理路径中选择最一致的答案来确定最佳答案。Self-Agreement在六个公开的推理基准上同时取得了出色的表现和卓越的泛化能力。


*本篇为快意大模型团队自研
论文03:Improving Large Language Models via Fine-grained Reinforcement Learning with Minimum Editing Constraint
| 论文地址:https://arxiv.org/abs/2401.06081
| 论文作者:Zhipeng Chen,Kun Zhou,Xin Zhao,Junchen Wan,Fuzheng Zhang,Di Zhang,Jirong Wen
| 论文简介:强化学习已被广泛应用于大语言模型的训练过程中,旨在减少大语言模型产生预期外的回复,例如,减少有害的回复和消除回复中的错误信息。然而,现有的强化学习方法主要采用实例级别的奖励作为监督信号。在复杂推理任务中(如数学推理),这类粗粒度的监督信号无法引导模型关注到推理过程中细粒度的错误,从而影响强化学习在提升大语言模型推理能力方面的效果。因此,强化学习训练无法找到实际导致模型响应不正确的特定部分或步骤。
为了解决强化学习无法提供细粒度监督信号的问题,我们提出了一种新的强化学习算法RLMEC (Reinforcement Learning with Minimum Editing Constraint )。不同于传统强化学习算法中使用判别式模型作为奖励模型,RLMEC使用一个生成式模型作为奖励模型。模仿人类学习者的学习方式,策略模型(即待训练的大语言)针对题目生成解答,生成式奖励模型标注解答中每一个词元是否正确。此外,生成式奖励模型通过尽可能少的修改策略模型的解答得到正确答案,该正确答案可以引导策略模型纠正自己的错误。为了实现这一目标,RLMEC算法训练生成式奖励模型在最小编辑约束下对错误答案进行改写。这个训练任务可以训练生成式奖励模型为强化学习训练提供词元级别的监督信号。基于生成式奖励模型,我们设计了词元级别的强化学习目标进行训练,并设计了一种基于模仿学习的正则化方法来稳定强化学习过程。这两个目标都侧重于修正错误解答中的关键词元,减少其他不重要词元对模型训练的影响。在8个复杂推理任务上的实验结果证明了我们方法的有效性。
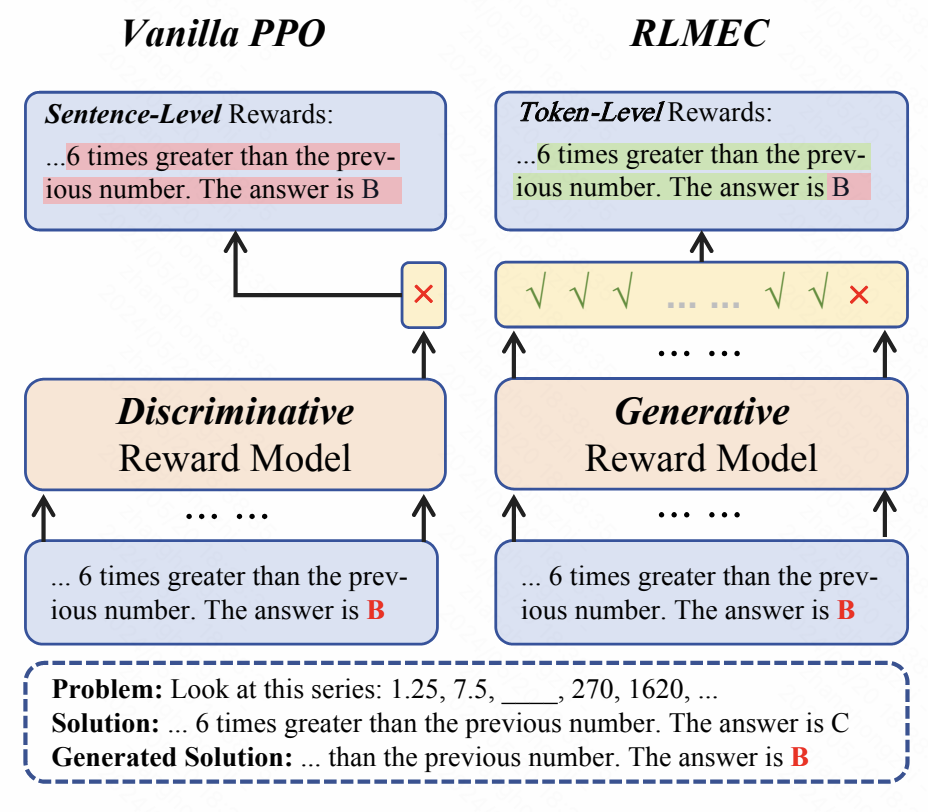
*本篇为快意大模型团队与中国人民大学合作研究
论文04:Harder Task Needs More Experts: Dynamic Routing in MoE Models
| 论文地址:https://arxiv.org/abs/2403.07652
| 论文作者:Quzhe Huang,Zhenwei An,Nan Zhuang,Mingxu Tao,Chen Zhang,Yang Jin,Kun Xu,Kun Xu,Liwei Chen,Songfang Huang,Yansong Feng
| 论文简介:传统的混合专家模型(Mixture of Experts,MoE)通常采取 Top-K 路由的方式,为每个输入 token 激活固定数量的专家,这种做法忽视了不同任务、不同输入之间的难度差异,一些更困难的任务往往需要更多的参数量进行求解。
为了更好地在激活参数量和模型效果之间取得平衡,本文提出了一种动态路由的方式,在选取激活专家网络时,采用 Top-P 路由的策略,选择置信度最高的若干专家网络,使其累积置信度恰好超过预设的阈值 p。这种方法可以根据输入 token 的难度,让模型自适应地灵活调整激活专家的数量。
一些通用评估任务上的实验表明,相比传统的固定 Top-2 路由策略,动态 Top-P 路由策略在取得 0.7% 效果提升的同时,只激活了不到 Top-2 路由策略 90% 的参数。同时,进一步的分析发现,模型在浅层更倾向于激活更多数量的专家网络,在高层更倾向于激活更少数量的专家网络,这为未来的模型结构设计能够提供一些指导意义。
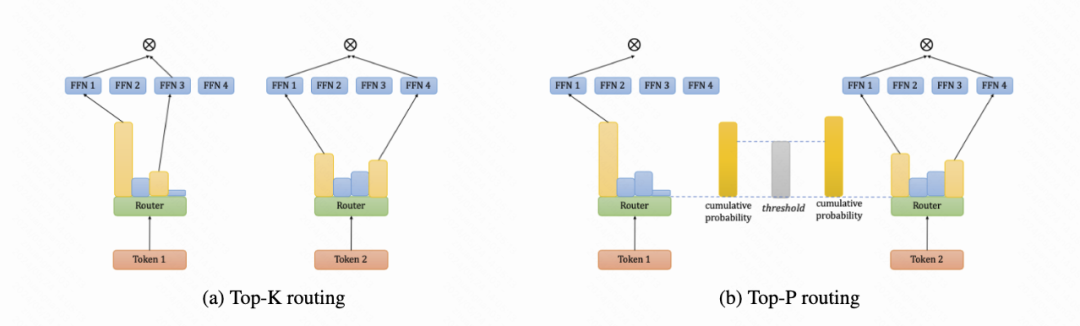
*本篇为搜索技术部与北京大学合作研究
END


















 4032
4032

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









