







 本文探讨了分类任务中类别不平衡的问题,提出了三种解决方案:欠采样,过采样和阈值移动。欠采样通过减少多数类样本,如EasyEnsemble算法;过采样通过增加少数类样本,如SMOTE算法;阈值移动则是调整分类器的决策阈值,如在逻辑回归中改变正例预测条件。这些策略有助于改善分类器在不平衡数据集上的性能。
本文探讨了分类任务中类别不平衡的问题,提出了三种解决方案:欠采样,过采样和阈值移动。欠采样通过减少多数类样本,如EasyEnsemble算法;过采样通过增加少数类样本,如SMOTE算法;阈值移动则是调整分类器的决策阈值,如在逻辑回归中改变正例预测条件。这些策略有助于改善分类器在不平衡数据集上的性能。
类别不平衡(class-imbalance),是指分类任务中不同类别的训练样例数目差别很大的情况(例如,训练集正类样例10个,反类样例90个),本文假设正类样例较少,反类样例较多。
现有解决方案大体分为三类,如下文所示。
欠采样(undersampling)
欠采样方法,即去除一些反类样例,使得正、反类样例数量接近。
EasyEnsemble为欠采样的代表性算法,利用继承学习机制,将反例划分为若干个集合,供不同学习器使用,这样对每个学习器来看都进行了欠采样,但在全局来看却不会丢失重要信息。
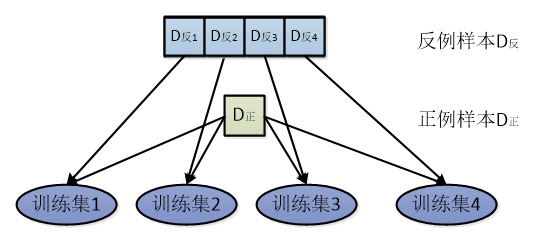
上图为EasyEnsemble示意图,若反例样本是正例样本数量的4倍,将反例样本随机划分成4个集合,每个集合分别和全部正例样本组成不同的训练集,每个训练集由不同学习器进行学习,这样,每个训练集的数据都是平衡的,全局来看又不会舍弃掉任何反例样本。
过采样(oversampling)
过采样,即增加一些正例,使得正、反类样例数量接近。
SMOTE,过采样的代表性算法,通过对训练集的正例进行插值,来产生额外的正例。
阈值移动(threshold-moving)
阈值移动,直接基于原始训练集进行学习,但是修改分类器预测时的决策过程;下面以逻辑回归(logistics regression)为例,进行说明。
逻辑回归(logistics regression),即对数几率回归,其模型可以表示为:
y = 1 1 + e − ( w T x + b ) y=\frac{1}{1+e^{-(w^\mathrm{T}x+b)}} y=1+e−(wTx+b)1
即:
ln y 1 − y = w T x + b \ln{\frac{y}{1-y}}=w^\mathrm{T}x+b ln
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 4589
4589

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









