







云网络产品和技术浅析
云计算时代,资源的虚拟化和资源调配的自动化,为用户提供了弹性的计算、存储和网络资源,进而支持快速和简捷的业务部署。作为互联互通的网络基础设施,如何实现网络的虚拟化,从而支持工作负载的快速变化和物理基础设施的调配,为工作负载提供端到端的网络资源响应,成为急需解决的核心问题。
网络虚拟化的本质是要实现底层物理网络的抽象,能够在逻辑上对网络资源进行分片或者整合,从而满足各种应用对于网络的不同需求。而云网络,是以云为中心,面向应用和租户的虚拟化网络基础设施,具备按需、弹性、随处可获得、可计量的特征,也面向租户与应用的虚拟化,云网络可以把网络设备虚拟,并通过服务的方式提供给多个用户使用,同时又具有极致性能。
企业采用 4 种不同的方法部署云资源,公有云,它通过 Internet 共享资源并向公众提供服务;私有云,它不进行共享且经由通常本地托管的私有内部网络提供服务;混合云,它根据其目的在公有云和私有云之间共享服务;一个社区云,它仅在组织之间(例如与政府机构)共享资源。
本文主要是以介绍公有云为主,主要从三个方面介绍,包括云网络产品,云网络虚拟化,云网络性能,重点关注业界主要的云厂商。
1 云网络产品
云网络产品目前主要是经过三次大的变更,从最初的经典网络,到私有网络,再到连接更大范围的云联网。云网络的发展也是数字化,全球化发展的一个缩影。
1.1 经典(基础)网络
在2006年,aws推出s3和ec2,提供云上服务器,在2010年,阿里云推出Classic经典网络对云计算用户提供支持。腾讯云类似的产品为基础网络。这些是云网络早期的产品,对云网络的主要需求是提供公网接入能力,云网络的特点是云上所有用户的公共网络资源池,所有云服务器的内网 IP 地址都由云厂商统一分配,无法自定义网段划分、IP 地址。
1.2 私有网络
在2011年,随着移动互联网发展,越来越多企业的应用上云,企业对云上网络安全隔离能力和互访能力、企业数据中心与云上网络互联,构建混合云的能力,以及在云上多地域部署业务后的多地域网络互联能力都提出了很多的需求,经典网络或者基础网络已经无法满足这些需求。aws支持云上VPC(私有网络,Virtual Private Cloud),其中VPC是用户在云上建立的一块逻辑隔离的网络空间,在私有网络内,用户可以自由定义网段划分、IP 地址和路由策略。而后陆续推出nat网关,vpn网关,对等连接等云产品,极大丰富了云网络连接的能力。
1.3 云联网
近几年,随着全球化高速发展,大数据与AI应用风起云涌,企业的全球扩张,需要云网络提供更大更灵活的接入能力,催生了aws的Transit Gateway,阿里云的云企业和云连接网,腾讯云的云联网,来实现全球互联互通。同时SDWAN接入服务,包括硬件和软件方案也不断的推出和完善。
从产品层面看,云网络经过经典网络,VPC网络,云联网,sdwan接入,云网络的范围得到了延展。从聚焦数据中心,到聚焦数据中心之间互联,进一步通过sdwan接入能力把企业的接入网进行了虚拟化。云网络产品不仅连接计算/存储,线下逐渐发展到连接企业的总部/分支与各种移动终端,企业可以在云上构建整个服务生态系统;
云网络从核心技术来看,是对网络编址和网络性能的优化。经典网络和VPC网络的在编址上,使用Overlay技术,就是将很多块数据一起打包,即在物理网络之上叠加了一个租户的虚拟层,从而一次将多块数据一起运到正确的地址,从而提高网络的效率。在网络性能上,通过重构网络设备形态持续提升数据转发性能,以虚拟交换机为例,服务器从10G升级到了25G,再到100G,经历了经典网络的Linux内核交换机,DPDK交换机,物理网卡交换机(智能网络,P4等)。
本文会对云网络虚拟化技术和网络性能技术做简要介绍。
2 云网络拓扑
一般的云网络是分Region提供服务,Region之间也要能互通,Region内部署Host(母机或者宿主机),在Host上进行实例的虚拟化,主要是子机的虚拟化,子机通过母机网络出口访问本Region的其他母机内的子机,有直通模式,也有部分流量需要经过Gateway(网关设备),跨Region的流量底层要经过云网络的大网。对于云网络虚拟化和性能提升来说,主要是从母机上的子机虚拟化和网关设备进行着手。
为了更直观看一下云网络需要做的事情,我们看看Google的整个网络构成。
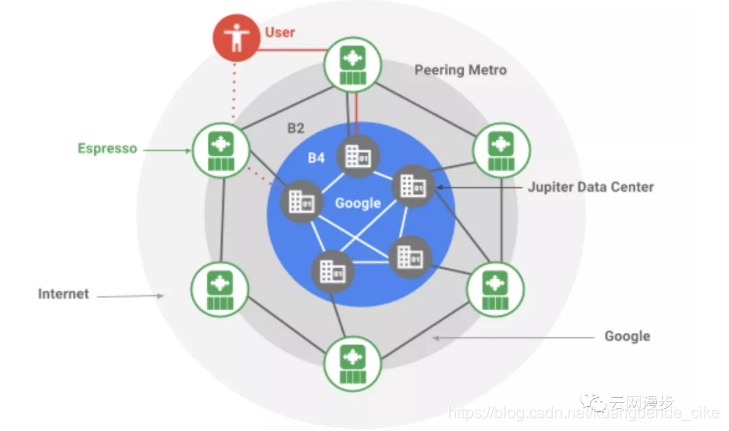
其中,B4 侧重于数据中心之间的连接;Andromeda 则负责网络功能的可视化,提供监控和管理功能;Jupiter 负责处理单个数据中心内的流量;Espresso 主要负责与互联网服务提供商的对等连接。
B4 WAN互连:Google构建B4网络实现了数据中心的连接,以便在各个园区网之间实时复制数据。
Andromeda:Google的Andromeda是一个网络功能虚拟化(NFV)堆栈。
Jupiter:Google通过SDN来构建Jupiter,Jupiter是一个能够支持超过10万台服务器规模的数据中心互联架构,支持超过1 Pb/s的总带宽来承载其服务。
Espresso将SDN扩展到Google网络的对等边缘,连接到全球其他网络。Espresso使得Google能够根据网络连接实时性的测量动态智能化地为个人用户提供服务
随着企业应用程序迁移到云,云网络也有新的特征,也需要新的技术手段来应对公有云网络的多样和复杂的需求,不过Google网络实现还是很大的参考价值,例如SDN网络设计,NFV平台,硬件加速的搭建等,在云网络都有所体现。
3.云网络虚拟化
网络虚拟化的本质是对底层网络的物理拓扑进行抽象,在逻辑上对网络资源进行分片或整合,从而满足各种应用对网络的不同的需求。下面从云网络的隔离技术,和私有网络的子机的迁移为分析,来介绍云网络虚拟化的技术。
3.1 物理网络
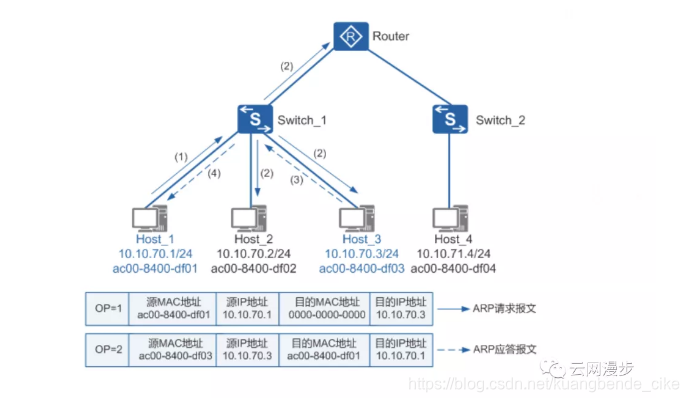
一般情况下,传统的物理网络架构分为接入层和核心层,接入层有接入交换机连接虚拟机,然后核心交换机汇聚接入交换机流量。
在局域网中,当主机或其它三层网络设备有数据要发送给另一台主机或三层网络设备时,它需要知道对方的网络层地址(即IP地址)。但是仅有IP地址是不够的,因为IP报文必须封装成帧才能通过物理网络发送,因此发送方还需要知道接收方的物理地址(即MAC地址),这就需要一个从IP地址到MAC地址的映射。ARP即可以实现将IP地址解析为MAC地址。主机或三层网络设备上会维护一张ARP表,用于存储IP地址和MAC地址的关系。
在物理网络中,IP地址和交换机是关联的,由于广播域的限制,虚拟机无法在机房内随意迁移。如果广播域大的话,发送一个广播的ARP请求报文,会极大的增加网络负担,同广播域的所有设备都需要接收和处理这个广播的ARP请求报文,也极大的影响了网络中设备的运行效率。
为了解决上述问题,引入了VLAN技术。
3.2 VLAN网络
VLAN(Virtual Local Area Network)即虚拟局域网,是将一个物理的LAN在逻辑上划分成多个广播域的通信技术。
典型的VLAN应用组网。两台交换机放置在不同的地点,比如写字楼的不同楼层。每台交换机分别连接两台计算机,他们分别属于两个不同的VLAN,比如不同的企业客户。
VLAN的优点
限制广播域:广播域被限制在一个VLAN内,节省了带宽,提高了网络处理能力。
增强局域网的安全性:不同VLAN内的报文在传输时是相互隔离的,即一个VLAN内的用户不能和其它VLAN内的用户直接通信。
提高了网络的健壮性:故障被限制在一个VLAN内,本VLAN内的故障不会影响其他VLAN的正常工作。
灵活构建虚拟工作组:用VLAN可以划分不同的用户到不同的工作组,同一工作组的用户也不必局限于某一固定的物理范围,网络构建和维护更方便灵活。IP地址与交换机无关,虚拟机可以在同一个二层网络内迁移。
而云网络,面临更大的挑战。
服务器虚拟化技术的广泛部署,极大地增加了数据中心的计算密度;同时,为了实现业务的灵活变更,虚拟机VM(Virtual Machine)需要能够在网络中不受限迁移,这给传统的“二层+三层”数据中心网络带来了新的挑战。
虚拟机规模受设备表项规格限制:服务器虚拟化后,VM的数量比原有的物理机发生了数量级的增长,而接入侧二层设备的MAC地址表规格较小,无法满足快速增长的VM数量。
虚拟机迁移范围受限:虚拟机迁移是指将虚拟机从一个物理机迁移到另一个物理机。为了保证虚拟机迁移过程中业务不中断,则需要保证虚拟机的IP地址保持不变,这就要求虚拟机迁移必须发生在一个二层网络中。而传统的二层网络,将虚拟机迁移限制在了一个较小的局部范围内。
网络隔离能力限制:VLAN作为当前主流的网络隔离技术,在标准定义中只有12比特,因此可用的VLAN数量仅4096个。对于公有云或其它大型虚拟化云计算服务这种动辄上万甚至更多租户的场景而言,VLAN的隔离能力无法满足。
为了应对上述的挑战,业界提出了NVo3(Network Virtualization over Layer 3)技术方案。NVo3基于IP/MPLS作为传输网,在其上通过隧道连接的方式,构建大规模的二层租户网络。目前业界主流的解决方案是GRE和VxLAN
3.3 隧道(Overlay)网络
Overlay网络技术,在物理IP网络基础上建立叠加逻辑网络(Overlay logical Network),屏蔽底层物理网络的差异,实现网络资源的虚拟化,使得多个逻辑上彼此隔离的网络分区,以及多种异构的虚拟网络可以在同一个共享的物理网络基础设施上共存。
Overlay网络的主要思想可以归纳为解藕,独立,控制三个方面。解藕是指网络的控制从网络物理硬件中脱离出来,交给虚拟化的Overlay逻辑物理处理。独立是指Overlay网络承载于物理IP网络之上,因此只要IP可达,那么相应的虚拟化网络就可以部署,而无须对原有物理网络架构作出任何改变,Overlay网络可以便捷地在现有网络上部署和实施。控制是指叠加的逻辑网络将以软件可编程的方式被统一控制,网络资源可以和计算资源,存储资源一起被统一的调度和按需交付。
Overlay网络实现方案包括VxLAN、NVGGRE、NVP、等,不同的云厂商使用的虚拟化方案有所差别,而产品呈现基本上是一致。
虚拟局域网扩展(VxLAN)
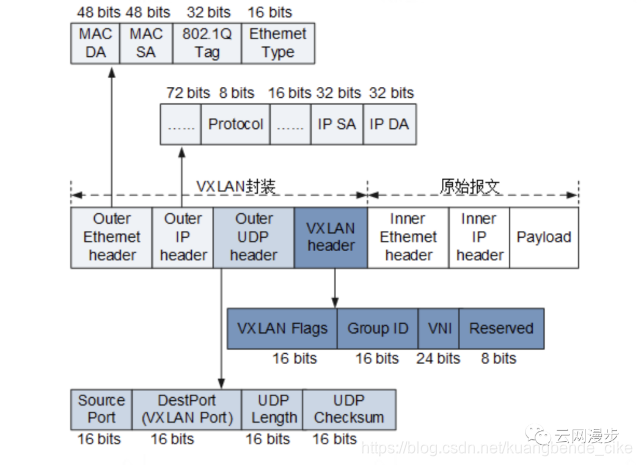
VxLAN(Virtual Extensible Local Area Network, 虚拟局域网扩展)是基于隧道的一种网络虚拟化技术,隧道是一个虚拟的点对点的连接,提供了一条通路使封装的数据报文能够在这个通路上传输,并且在通路的两端分别对数据报文进行封装及解封装。
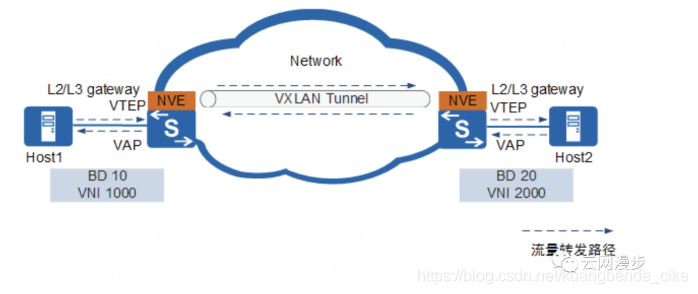
VxLAN将二层报文用三层协议进行封装,可以对二层网络在三层范围内进行扩展。
VxLAN应用于数据中心内部,使虚拟机可以在互通的三层网络范围内进行迁移,而不需要改变IP地址和MAC地址,保证业务的连续性。
VxLAN协议头使用了24bit表示VLAN ID,可以支持1600多万个VLAN ID。
通用路由封装GRE
GRE也是基于隧道的一种网络虚拟化技术方案,GRE使用IP报文作为传输协议,可以封装多种不同的协议。
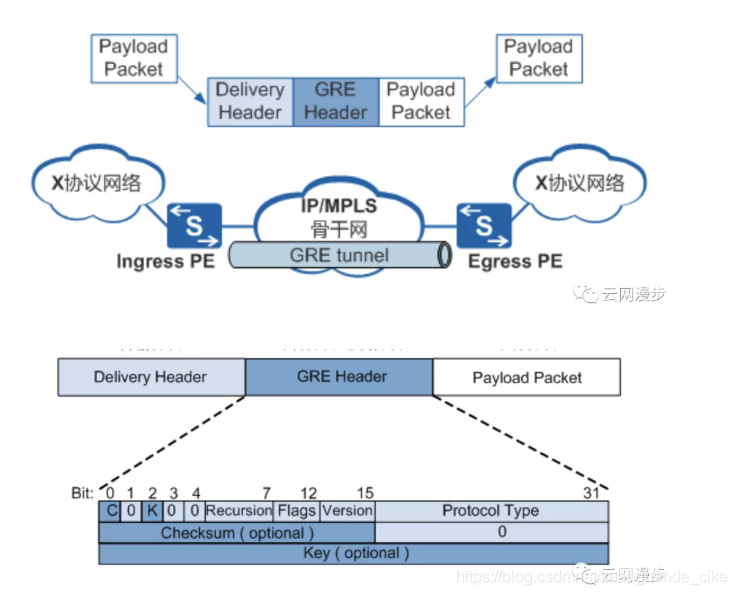
当设置K标志位(报文中的2 bit)为1时,增加的Key Field(32 bits)可用于同一个隧道内的多个网络进行隔离。
3.4 云网络母机虚拟化技术
云网络虚拟化技术,除了Overlay技术外,我们也看一下在母机或者宿主机的网络虚拟化的技术实现,主要以Linux网络虚拟化技术为例进行介绍。
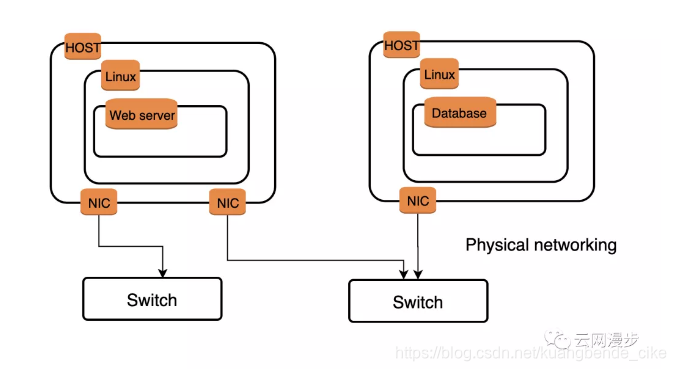
在一个传统的物理网络里,可能有一组物理Host,上面分别运作着各种各样的应用。为了彼此之间能够相互通信,物理Host都拥有一个或者多个的网卡(NIC),网卡被连接到物理交换机设备上。
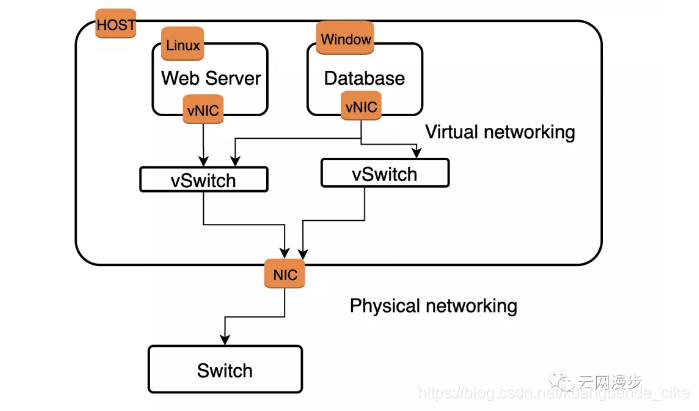
在虚拟化技术引入后,应用可以部署在虚拟机上,虚拟机的网络功能有虚拟网卡实现(vNIC),vNIC等同于物理的网卡。为了实现传统物理等同的网络架构,Switch也被虚拟化为虚拟交换机。各个vNIC连接在vSwitch的端口中,最后这些vSwitch通过物理Host的物理网卡访问外部的物理网络。
从图中可以看出,一个虚拟的二层网络架构,主要是完成两种设备的虚拟化:NIC设备与交换设备。
我们以一个简单的母机的子机的虚拟化方案作为举例,vm有虚拟网卡,虚拟网卡绑定到Linux Bridge(网桥)上,再做GRE或者VxLAN的封装,通过母机的物理网络访问其他物理Host内的子机,其中可以用不同的VxLAN分隔网络,实现私有网络VPC功能。

4 云网络性能
云网络的性能主要从包转发的效率来,从用户使用云产品的维度看,用户即需要单台虚拟机性能好,也需要在虚拟机相互通信时性能好。从上面的云网络的简要拓扑看,我们主要是优化母机的上子机和虚拟交换机的性能,还有一个是优化中间转发的网关设备的性能,对应内部物理网络,要从带宽角度的进行优化和提升能力。
虚拟交换机的技术实现主要经历三个阶段,Linux内核交换机, DPDK交换机,智能网卡交换机。对于网关设备,也开始走向可编程交换机(P4)实现更大的网络性能。
4.1 Linux内核交换机
数据平面的性能在很大程度上取决于网络I/O的性能,而网络数据包从网卡到用户空间的应用程序需要经历多个阶段。以Linux网络数据包的处理流程为例,处理动作可以概括如下。
数据包到达网卡设备
网卡设备依据配置进行DMA操作
网卡发送中断,唤醒处理器
驱动软件填充读写缓冲区数据结构
数据报文到达内核协议栈,进行高层处理
如果最终应用在用户态,数据从内核搬移到用户态
如果最终应用在内核态,在内核继续进行。
在这个过程的多个阶段都存在着不可忽视的开销。
网卡中断
随着10Gbit/s,40Gbit/s,100Gbit/s的网络接口出现,网卡面对大量的高速数据将会引发频繁的中断,每次中断都会引起一次上下文切换,操作系统都需要保存和恢复相应的上下文,造成比较高的时延,并引发吞吐量下降。
内存拷贝
在进行用户态和内核态的网络数据的交换时,数据要在内核空间和用户空间拷贝,每次拷贝都会占用大量的CPU、内存带宽等资源,代价很大。
锁
在Linux内核空间的网络协议栈的实现中,存在大量的共享资源访问,多个进程需要对一共享资源进行操作时,就需要通过锁的机制来保证数据的一致性。加锁需要时间,也会降低整个系统的并发性能。
缓冲命中
缓存能够有效提升系统的性能,如果存在频繁的跨核调用,由此带来的缓存不命中会造成严重的数据写时延,从而降低系统的整体性能。
从前面的分析可以得知网络IO实现的方式、Linux内核的瓶颈,以及数据流过内核存在不可控因素,这些都是在内核中实现,内核是导致瓶颈的原因所在,要解决问题需要绕过内核。所以主流解决方案都是旁路网卡IO,绕过内核直接在用户态收发包来解决内核的瓶颈。
4.2 DPDK交换机
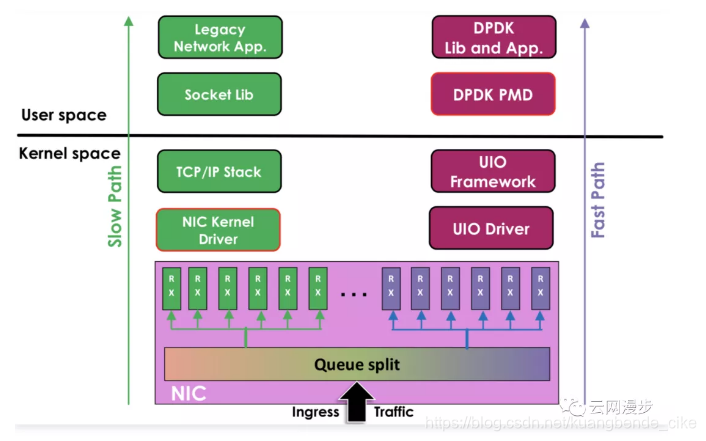
左边是原来的方式数据从 网卡 -> 驱动 -> 协议栈 -> Socket接口 -> 业务
右边是DPDK的方式,基于UIO(Userspace I/O)旁路数据。数据从 网卡 -> DPDK轮询模式-> DPDK基础库 -> 业务
DPDK的核心思想可以归纳为几个方面
轮询模式:DPDK使用轮询网卡是否有网络报文来接收或者发送。在报文吞吐量大的时候,性能与时延的改善比较明显。
用户态驱动:DPDK通过用户态驱动的开发框架在用户态操作设备及数据包,避免了不必要的用户态和内核态之间的数据拷贝和系统调用。
降低访问存储开销:使用大页、预取、缓存对齐的技术,保证访问存储的效率。
亲和性和独占:利用线程的CPU亲和绑定的方式,将特定线程绑定指定到固定的核上工作,避免线程在不同核间频繁切换带来的开销,也能提升并行处理的能力。
批处理:DPDK可以进行批处理数据包。
利用新硬件技术:利用新硬件的指令,例如vector指令并行处理多个报文,原子指令避免锁开销等。
充分挖掘外部设备的潜力:主要是利用网卡的功能,实现网络的加速。
4.3 智能网卡交换机
传统网卡,仅实现数据链路层和物理层的功能,而端系统CPU负责处理网络协议栈中更高层的逻辑。CPU按照网络协议栈中传输层、路由层的逻辑,负责数据包的封装和解封;网卡则负责更底层的数据链路层帧的封装和解封,以及物理层电气信号的相应处理。
智能网卡,普遍卸载了部分传输层和路由层的处理逻辑(如校验和计算、传输层分片重组等),来减轻CPU的处理负担,甚至有些网卡如RDMA网卡还将整个传输层的处理都卸载到网卡硬件上,以完全解放CPU。
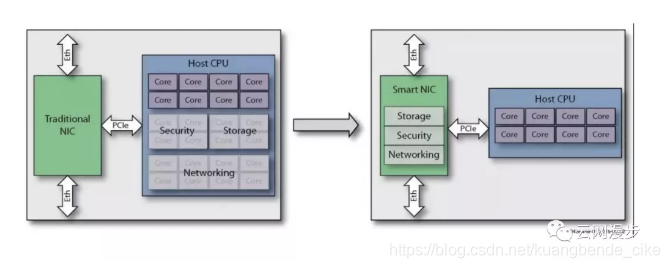
具体来说,传统网卡面向的用户痛点包括:
随着VXLAN等overlay协议以及OpenFlow、Open vSwitch(OVS)等虚拟交换技术的引入,使得基于服务器的网络数据平面的复杂性急剧增加。
网络接口带宽的增加意味着在软件中执行这些功能会给CPU资源造成难以承受的负载,留给运行应用程序的CPU资源很少或根本没有。
传统网卡固定功能的流量处理功能无法适应SDN和NFV。
4.4 可编程交换机(P4)
P4(Programming Protocol-Independent Packet Processors)是一种数据面的高级编程语言,主要是解决数据平面的可编程问题,打破了硬件设备对转发平面的限制,让数据包的解析和转发流程也能通过编程去控制。云厂商可以根据云网络的需求,对硬件进行编程定义。
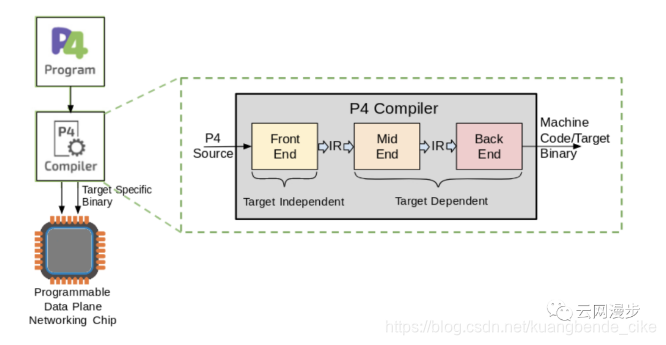
P4带来了许多好处,包括:
所有可编程网络设备的开源语言。易于移植。
由于P4程序可以由用户编写,因此有助于保留新IP的所有权。现在,不再需要与芯片厂商或他们的客户共享新的功能规范,从而保留知识产权保护。
P4使新协议的部署更加简单,消耗的时间更少。
在不同应用程序中使用的网络设备需要不同的协议集。使用P4,用户可以根据应用程序仅实现所需的协议,并删除其应用程序不需要的协议。因此,可以有效地利用现有资源。
编程数据平面现在使用软件编写程序,使用P4编译和加载硬件,从而提供软件重用、数据隐藏、库创建、硬件和软件组件分离、软件升级和调试方便等优点。
5 总结
本文简要介绍了云网络产品的演进,云网络的需求,和云网络使用的技术, 也欢迎和大家一起交流,学习。














 986
986











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









