






webpack默认的:
1.mode : 打包模式
默认值production : 生产模式(压缩,混淆,加密....... 不可读)
development :开发模式(代码不会压缩 混淆)
2.output: 出口文件(对象类型)
path : 设置出口文件夹(必须是绝对路径)
默认值:
${__dirname}/distfilename: 设置出口js文件名 (相对于path路径)
默认值:
main.js3.entry : 出口文件
默认值(相当于项目根目录):
./src/index.js
loader和plugin区别
loader直译为"加载器"。webpack将一切文件视为模块,但是webpack原生是只能解析js文件,如果想将其他文件也打包的话,就会用到loader。 所以loader的作用是让webpack拥有了加载和解析非JavaScript文件的能力。
说人话: loader就是用于解析文件的
例如:css-loader 、style-loader、image-loader
Plugin直译为"插件"。Plugin可以扩展webpack的功能,让webpack具有更多的灵活性。 在 webpack 运行的生命周期中会广播出许多事件,Plugin 可以监听这些事件,在合适的时机通过 webpack 提供的 API 改变输出结果。
说人话:插件就是拓展功能的
例如:html-webpack-plugin
webpack工作流程
1.初始化参数:从配置文件(package.config.js)读取与合并参数,得出最终的参数
2.开始编译:用上一步得到的参数初始化 Compiler 对象,加载所有配置的插件,开始执行编译
3.确定入口:根据配置中的 entry 找出所有的入口文件
4.编译模块:从入口文件出发,调用所有配置的 Loader 对模块进行翻译,再找出该模块依赖的模块,再递归本步骤直到所有入口依赖的文件都经过了本步骤的处理
5.完成模块编译:在经过第4步使用 Loader 翻译完所有模块后,得到了每个模块被翻译后的最终内容以及它们之间的依赖关系
6.输出资源:根据入口和模块之间的依赖关系,组装成一个个包含多个模块的 Chunk(组块),再把每个 Chunk 转换成一个单独的文件加入到输出列表,这步是可以修改输出内容的最后机会
7。输出完成:在确定好输出内容后,根据配置确定输出的路径和文件名,把文件内容写入到文件系统。如果没有配置,就按默认出入口文件输出.
常见响应码
常见的响应码有哪些?
200 : 请求成功
302 : 重定向
400 : 参数错误
401 : 未认证(没有登录)
404 : 路径错误
403 : 没有权限(没有权限)
405 : 请求方法未找到
413 : 文件大小超过限制
500 : 服务器内部错误
1xx(消息)
代表请求已被接受,需要继续处理。这类响应是临时响应,只包含状态行和某些可选的响应头信息,并以空行结束
常见的有:
- 100(客户端继续发送请求,这是临时响应):这个临时响应是用来通知客户端它的部分请求已经被服务器接收,且仍未被拒绝。客户端应当继续发送请求的剩余部分,或者如果请求已经完成,忽略这个响应。服务器必须在请求完成后向客户端发送一个最终响应
- 101:服务器根据客户端的请求切换协议,主要用于websocket或http2升级
2xx(成功)
代表请求已成功被服务器接收、理解、并接受
常见的有:
-
200(成功):请求已成功,请求所希望的响应头或数据体将随此响应返回
-
201(已创建):请求成功并且服务器创建了新的资源
-
202(已创建):服务器已经接收请求,但尚未处理
-
203(非授权信息):服务器已成功处理请求,但返回的信息可能来自另一来源
-
204(无内容):服务器成功处理请求,但没有返回任何内容
-
205(重置内容):服务器成功处理请求,但没有返回任何内容
-
206(部分内容):服务器成功处理了部分请求
3xx(重定向)
表示要完成请求,需要进一步操作。 通常,这些状态代码用来重定向
常见的有:
-
300(多种选择):针对请求,服务器可执行多种操作。 服务器可根据请求者 (user agent) 选择一项操作,或提供操作列表供请求者选择
-
301(永久移动):请求的网页已永久移动到新位置。 服务器返回此响应(对 GET 或 HEAD 请求的响应)时,会自动将请求者转到新位置
-
302(临时移动): 服务器目前从不同位置的网页响应请求,但请求者应继续使用原有位置来进行以后的请求
-
303(查看其他位置):请求者应当对不同的位置使用单独的 GET 请求来检索响应时,服务器返回此代码
-
305 (使用代理): 请求者只能使用代理访问请求的网页。 如果服务器返回此响应,还表示请求者应使用代理
-
307 (临时重定向): 服务器目前从不同位置的网页响应请求,但请求者应继续使用原有位置来进行以后的请求
4xx(请求错误)
代表了客户端看起来可能发生了错误,妨碍了服务器的处理
常见的有:
- 400(错误请求): 服务器不理解请求的语法
- 401(未授权): 请求要求身份验证。 对于需要登录的网页,服务器可能返回此响应。
- 403(禁止): 服务器拒绝请求
- 404(未找到): 服务器找不到请求的网页
- 405(方法禁用): 禁用请求中指定的方法
- 406(不接受): 无法使用请求的内容特性响应请求的网页
- 407(需要代理授权): 此状态代码与 401(未授权)类似,但指定请求者应当授权使用代理
- 408(请求超时): 服务器等候请求时发生超时
5xx(服务器错误)
表示服务器无法完成明显有效的请求。这类状态码代表了服务器在处理请求的过程中有错误或者异常状态发生
常见的有:
- 500(服务器内部错误):服务器遇到错误,无法完成请求
- 501(尚未实施):服务器不具备完成请求的功能。 例如,服务器无法识别请求方法时可能会返回此代码
- 502(错误网关): 服务器作为网关或代理,从上游服务器收到无效响应
- 503(服务不可用): 服务器目前无法使用(由于超载或停机维护)
- 504(网关超时): 服务器作为网关或代理,但是没有及时从上游服务器收到请求
- 505(HTTP 版本不受支持): 服务器不支持请求中所用的 HTTP 协议版本
请求报文和响应报文组成部分
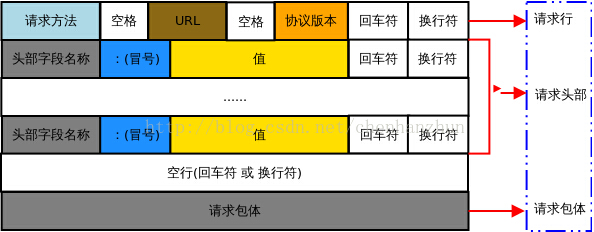
HTTP 请求报文由请求行、请求头部、空行 和 请求包体 4 个部分组成,如下图所示:
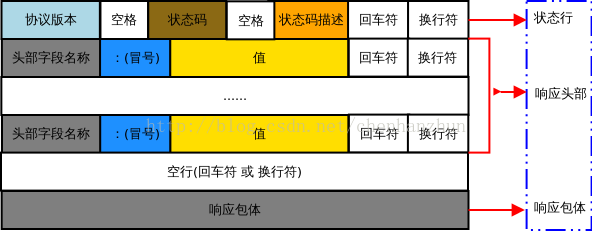
HTTP 响应报文由状态行、响应头部、空行 和 响应包体 4 个部分组成,如下图所示:
GET 方法 POST 方法
数据传输⽅式:get 通过 URL 传输数据 (地址栏拼接参数), post 通过请求体传输;
数据安全: get 数据暴露在 URL 中,可通过浏览历史记录、缓存等很容易查到数据信息; post 数据因为在请求主体内,所以有⼀定的安全性保证。
数据类型: get 只允许 ASCII 字符; post ⽆限制
GET ⽆害 刷新、后退等浏览器操作是⽆害的; post 可能会引起重复提交表单
get是安全且幂等(这⾥的安全是指只读特性,就是使⽤这个⽅法不会引起服务器状态变化。 幂等的概念是指同⼀个请求⽅法执⾏多次和仅执⾏⼀次的效果完全相同) post是⾮安全(会引起服务器端的变化)、⾮幂等
从
w3schools得到的标准答案的区别如下:
- GET 在浏览器回退时是无害的,而 POST 会再次提交请求。
- GET 产生的 URL 地址可以被 Bookmark,而 POST 不可以。
- GET 请求会被浏览器主动 cache,而 POST 不会,除非手动设置。
- GET 请求只能进行 url 编码,而 POST 支持多种编码方式。
- GET 请求参数会被完整保留在浏览器历史记录里,而 POST 中的参数不会被保留。
- GET 请求在 URL 中传送的参数是有长度限制的,而 POST 没有。
- 对参数的数据类型,GET 只接受 ASCII 字符,而 POST 没有限制。
- GET 比 POST 更不安全,因为参数直接暴露在 URL 上,所以不能用来传递敏感信息。
- GET 参数通过 URL 传递,POST 放在 Request body 中
函数防抖和节流
1、防抖:是一种防止代码被频繁执行的思想
防抖函数:是结合延迟函数封装的一个自定义函数,事件被频繁触发时,会重新执行延迟函数,时间会被重新计算
2、节流:是指一种在指定事件防止函数被频繁调用的思想
节流函数:结合时间戳来封装的函数,在指定的时间会执行一次代码(调用一次函数)
小结:
防抖函数和节流函数是一种自定义的函数,都是为了防止代码被频繁执行,但是防抖和节流的思想各不同,防抖可以结合延迟函数实现,节流可以结合时间戳实现。
防抖: 在一段时间内,多次触发事件,只会执行最后一次
节流: 在一段时间内,多次触发事件,只会执行一次
闭包
闭包是一个可以访问其他函数内部变量的函数,主要作用是解决变量污染问题,也可以用来延长局部变量的生命周期。闭包在 js 中使用比较多,几乎是无处不在的。一般大多数情况下,在回调函数中闭包用的是最多的。
任何闭包的使用场景都离不开这两点:
- 创建私有变量
- 延长变量的生命周期
递归
递归就是函数直接或者间接调用自身的一种方法,来解决比较复杂的函数逻辑。
优点: 1. 解决重复执行任务 2. 处理不定层级数据
缺点: 1. 时间 空间的消耗较大 2. 重复计算 3.栈溢出
使用场景:树形菜单,递归组件,快速排序















 790
790











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









