






ArrayList
扩容规则
new ArrayList() 会使用长度为零的数组
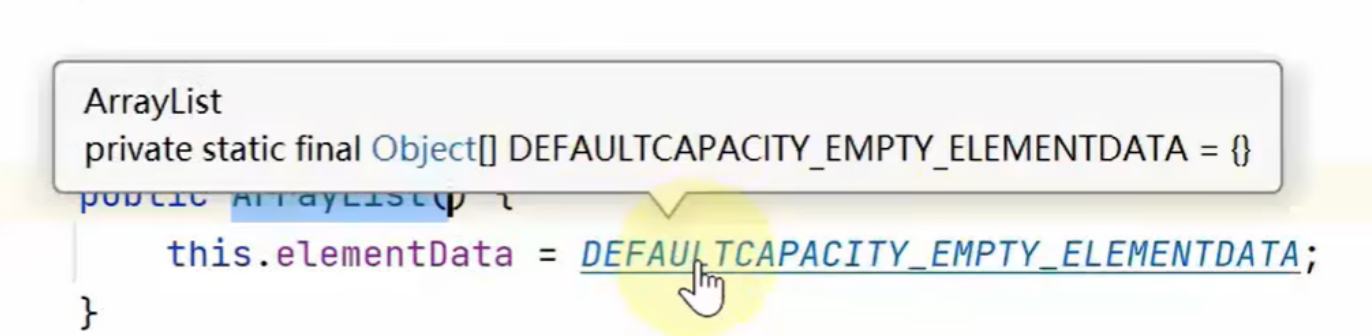
new ArrayList(int initialCapacity) 会使用指定容量的数组
public ArrayList(Collection<? extends E> c) 会使用 c 的大小作为数组容量
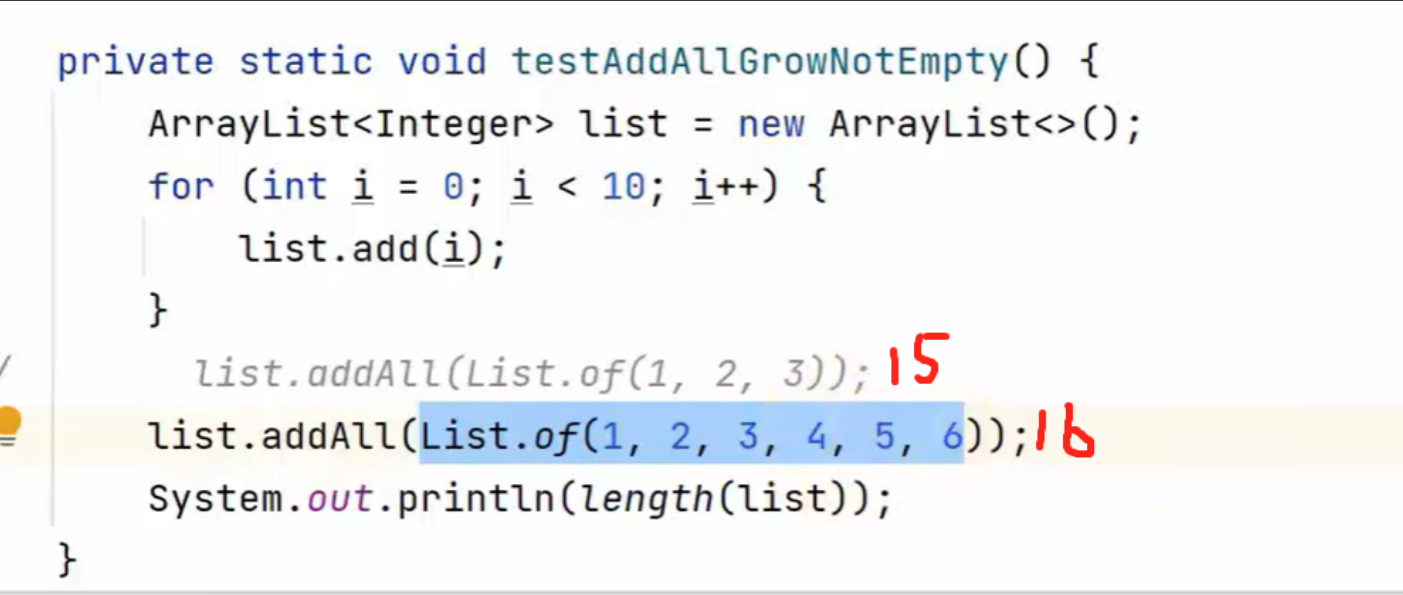
add(Object o) 首次扩容为 10,再次扩容为上次容量的 1.5 倍。(使用无参构造后加入第一个元素,此时会新建一个长度为10的数组,把元素放在index0的位置,然后用新数组替换掉原数组)(如果容量为15,此时扩容后容量为多少呢?底层为先移位15>>1=7,然后7+15=22)
addAll(Collection c) 没有元素时,扩容为 Math.max(10, 实际元素个数) (不然的话如果加11个元素,要先扩容为10,再扩容到15,两次扩容效率不高),有元素时为 Math.max(原容量 1.5 倍, 实际元素个数)
Iterator
掌握什么是 Fail-Fast、什么是 Fail-Safe
fail-fast 一旦发现遍历的同时其他人来修改,则立刻抛异常(ArrayList 是 fail-fast 的典型代表,遍历的同时不能修改,尽快失败)
fail-safe 发现遍历的同时其他人来修改,应当能有应对策略,例如牺牲一致性来让整个遍历运行完成。(CopyOnWriteArrayList 是 fail-safe 的典型代表,遍历的同时可以修改,原理是读写分离)
FailFast源码分析
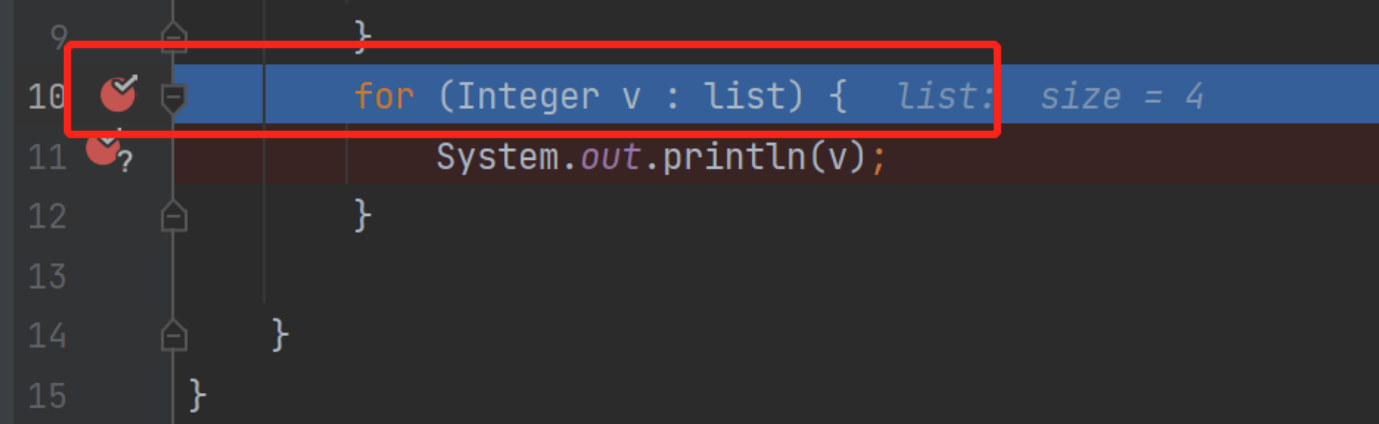
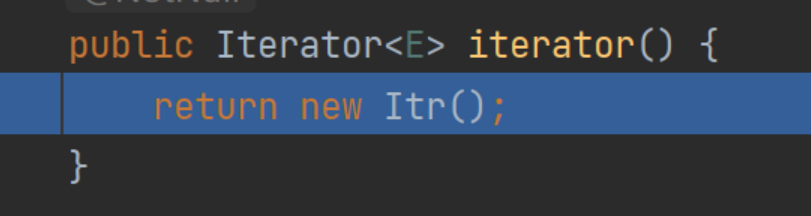
for循环底层实际上是调用迭代器对象
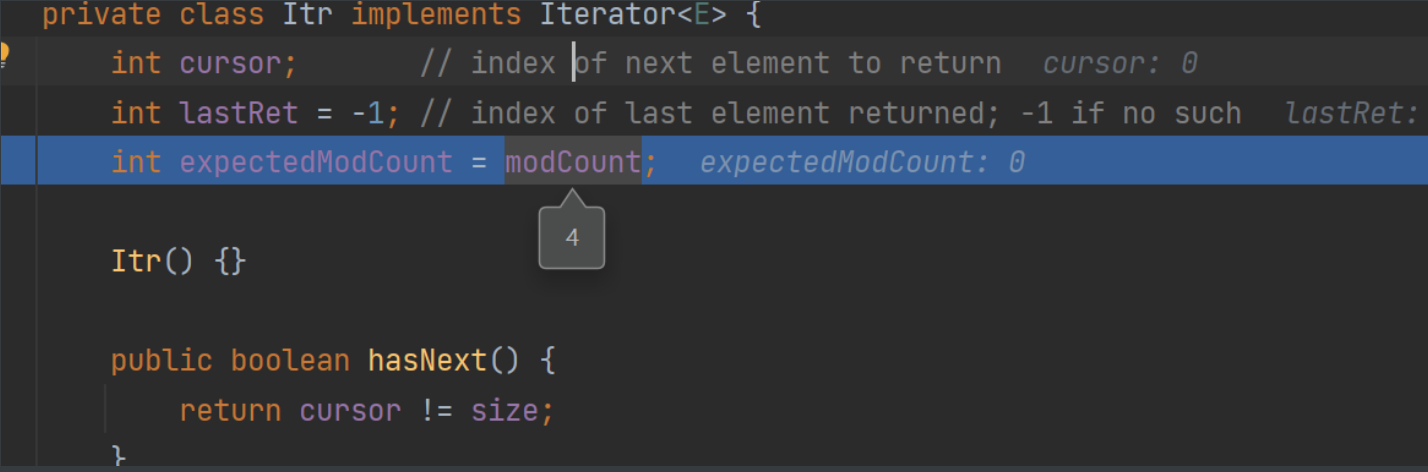
迭代器对象中的expectedModCount存储遍历前list中的元素数量

然后此时迭代器调用next()方法
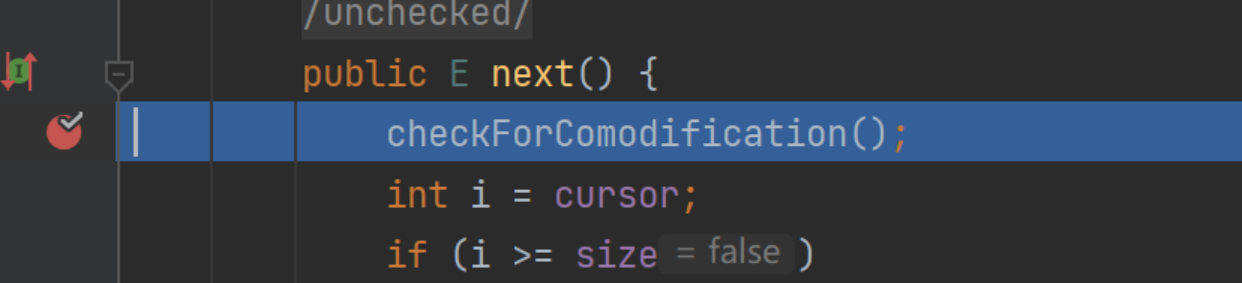

此时expectedModCount已经不等于list中的元素数量,所以抛异常
FailSafe源码分析

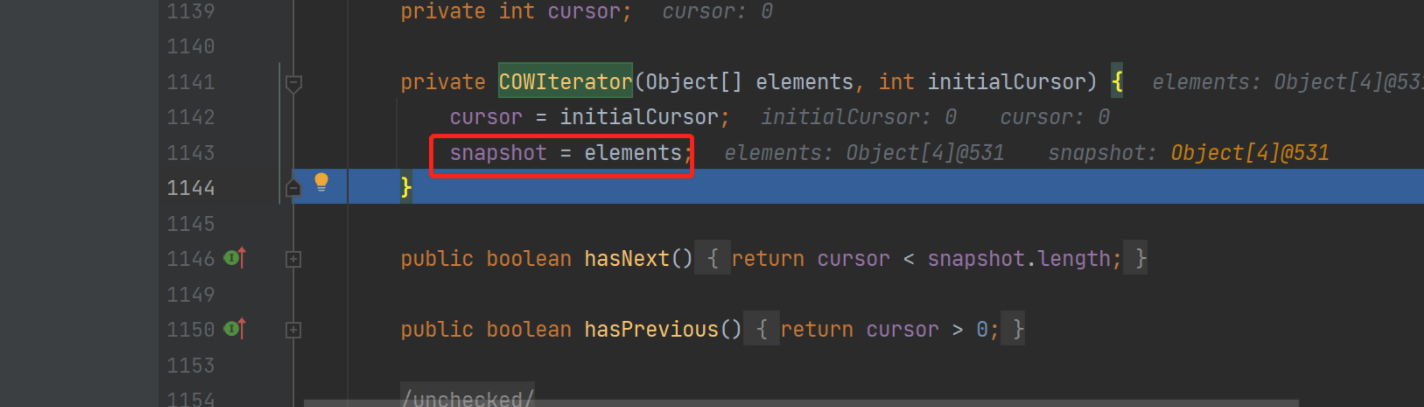
将原数组的地址保存在迭代器对象中
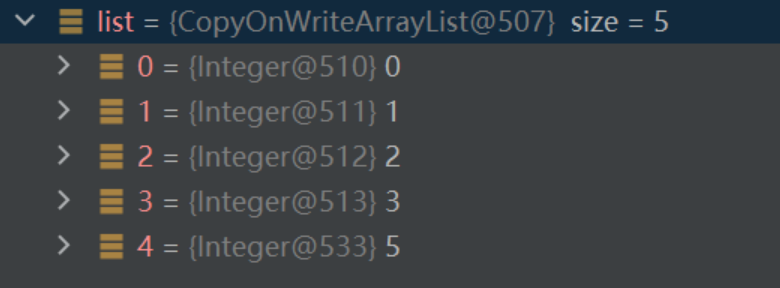
此时list中新增元素,而迭代器对象中的备份还是原数字地址

而list里面其实已经是5了,原因在于copyonwritearraylist的add方法
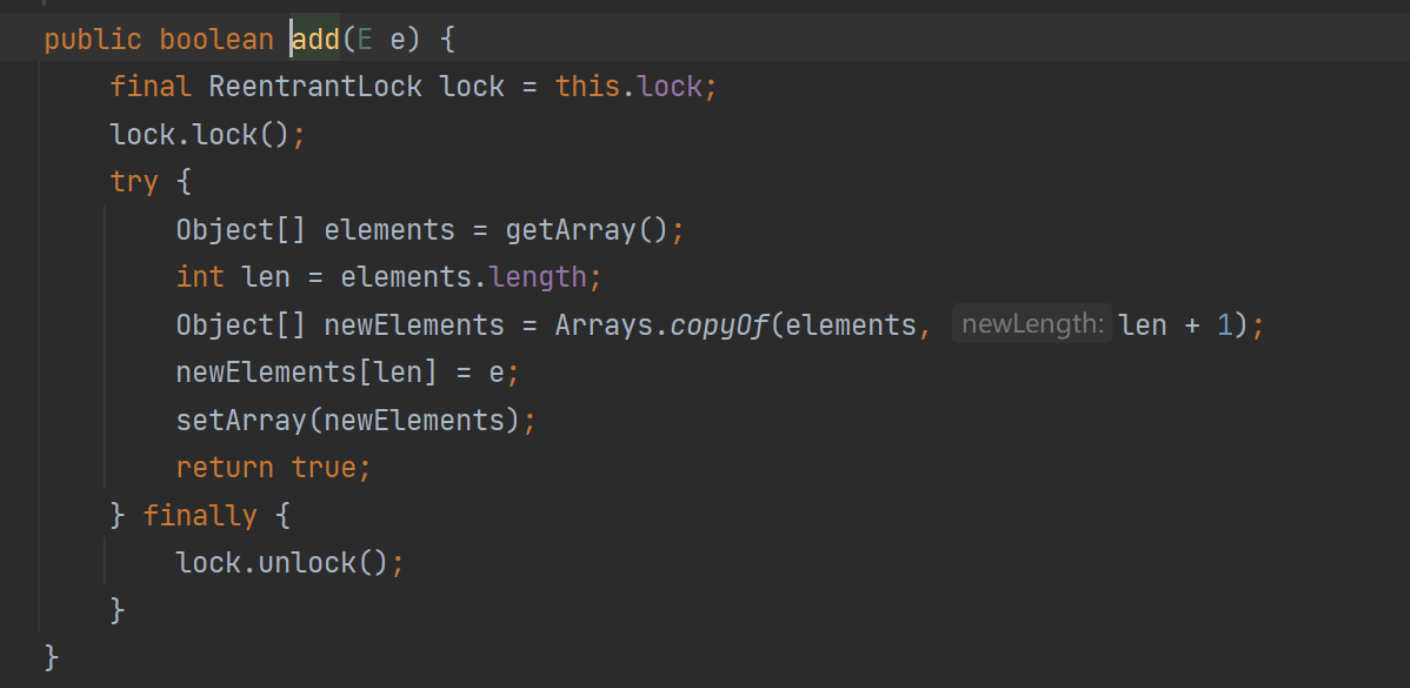
每次add时原来数组复制一份长度+1,所以遍历时遍历的是旧数据,而每次添加时会生成一个新数组
LinkedList
能够说清楚 LinkedList 对比 ArrayList 的区别,并重视纠正部分错误的认知
LinkedList
基于双向链表,无需连续内存
随机访问慢(要沿着链表遍历)
头尾插入删除性能高(中间插入的话LinkedList比ArrayList慢,因为移动指针的过程非常慢)
占用内存多

linkedlist的内存占用比arraylist多好几倍
ArrayList
基于数组,需要连续内存
随机访问快(指根据下标访问)
尾部插入、删除性能可以,其它部分插入、删除都会移动数据,因此性能会低
可以利用 cpu 缓存,局部性原理

没实现这个接口的话只能通过迭代器的next找元素,否则可以通过.get(下标)获取元素。
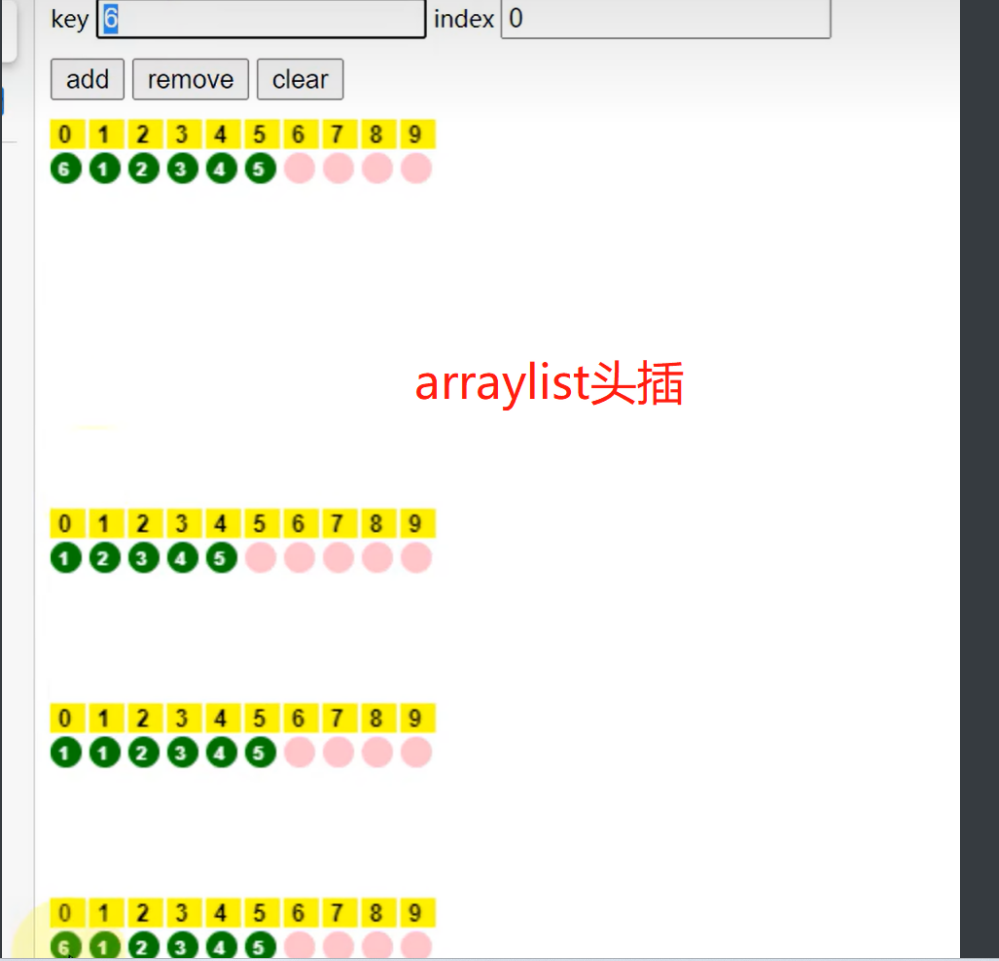
且插入的位置越靠前,需要移动的元素越多,效率越低。
局部性原理
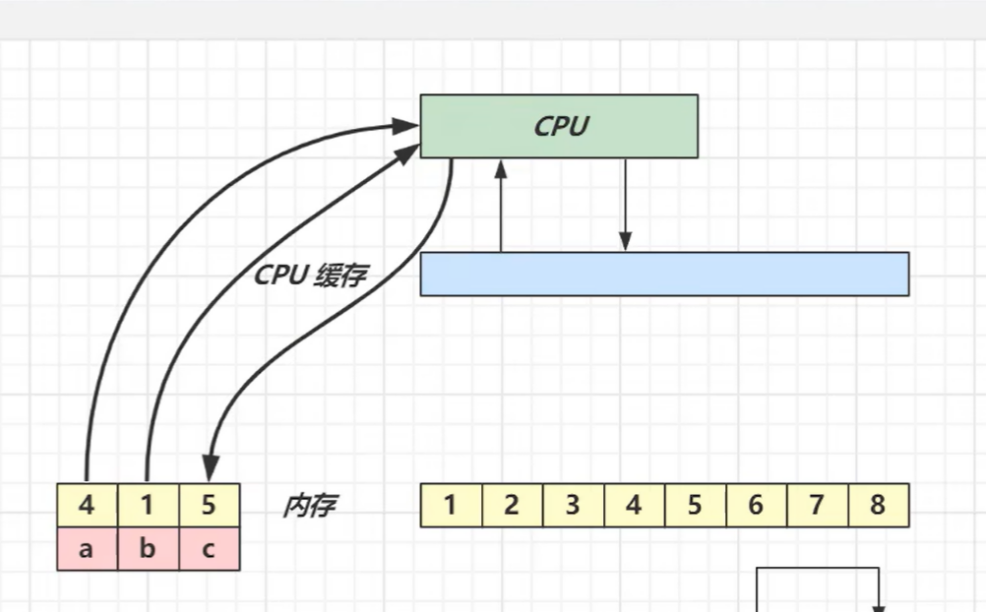
cpu要进行计算的话,数还是来自于内存中的。从内存中读到a和b,然后计算写到内存c中。这个读取写入内存的时间要几百ns,而cpu计算是少于ns级别的。所以需要在cpu跟内存中间加一个cpu的缓存。
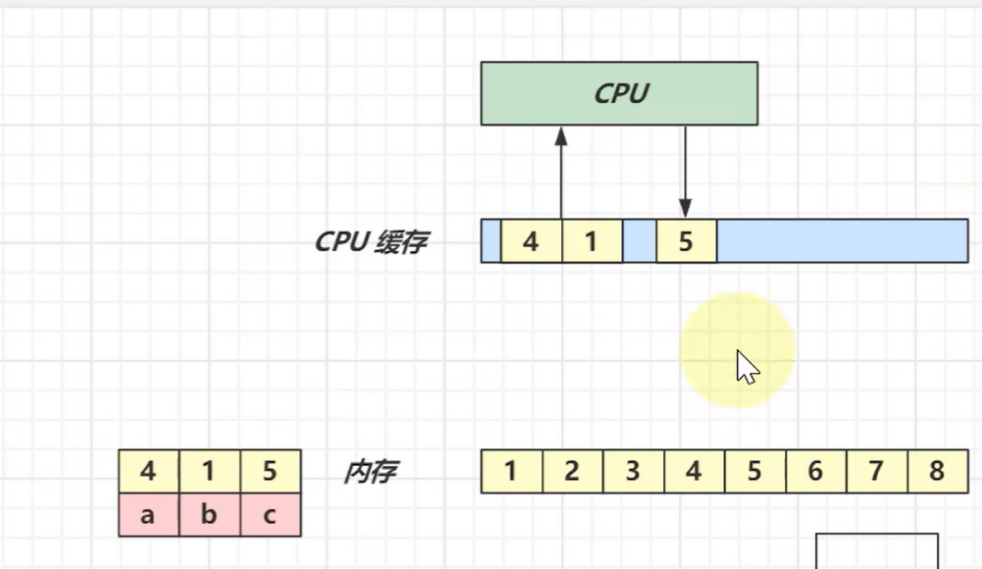
读数据从cpu缓存中读。写数据写到cpu缓存,之后再与内存进行同步
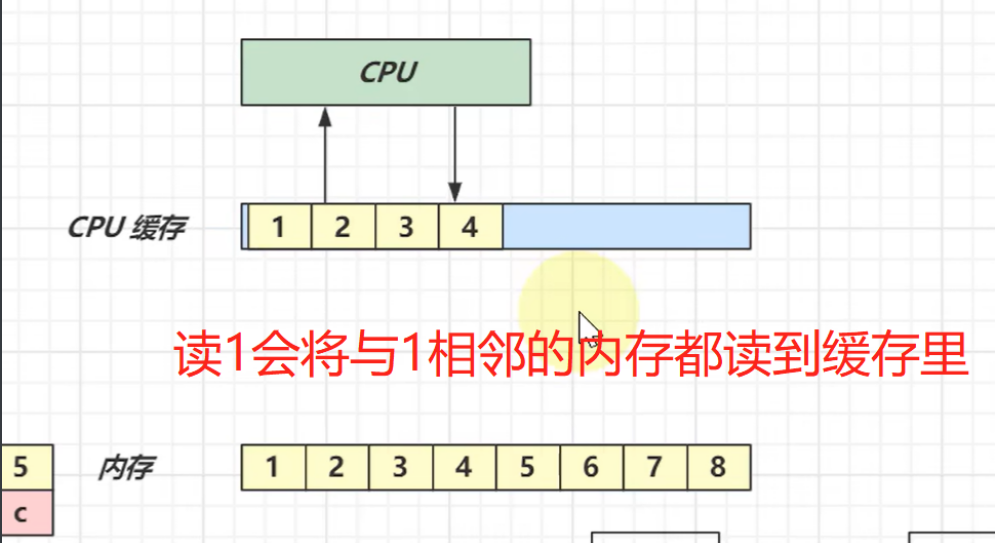
局部性原理:读一个数据时,这个数据相邻的数据也有很大的可能被访问到
数组跟局部性原理能很好地配合使用,但是链表就不行了(内存不连续)。















 185
185











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









