







项目介绍
今天无聊没事写了一个python的爬虫项目,用于对CSDN问答区的内容进行爬取并在终端呈现出来。
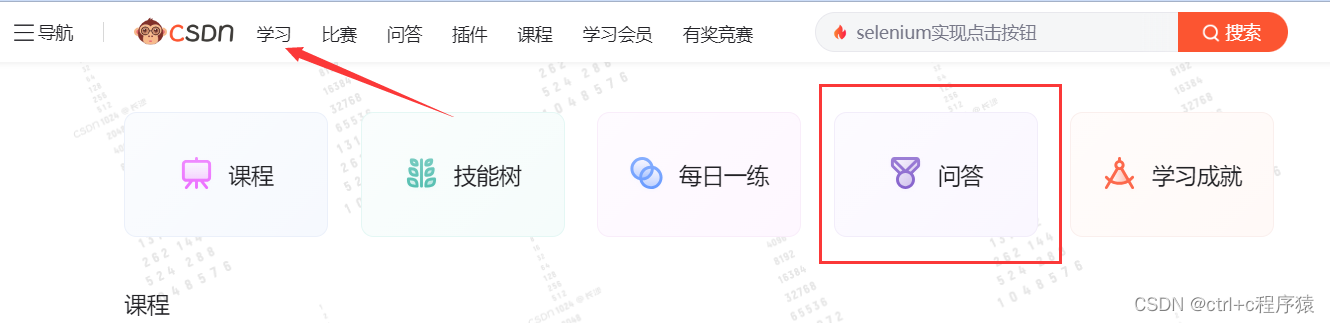
此次爬取的内容主要包括问题主页主页标题以及子页的链接
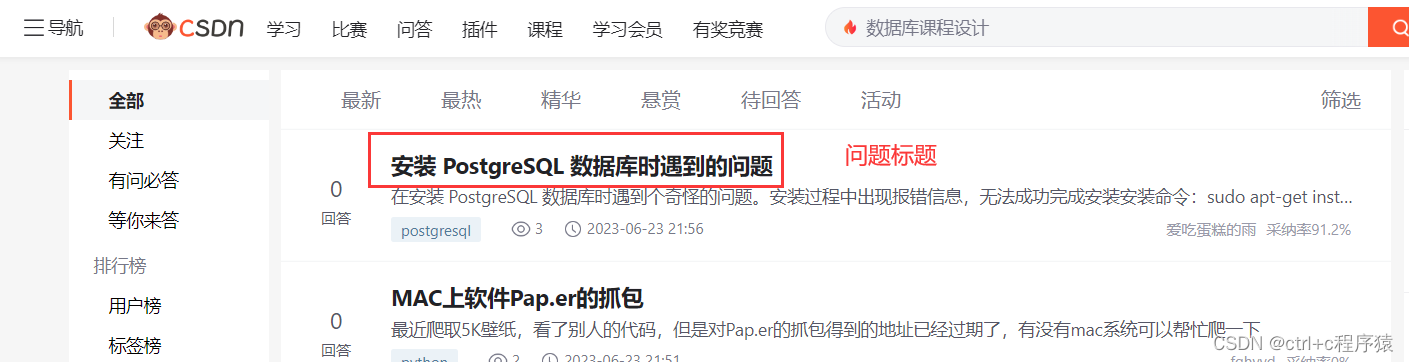
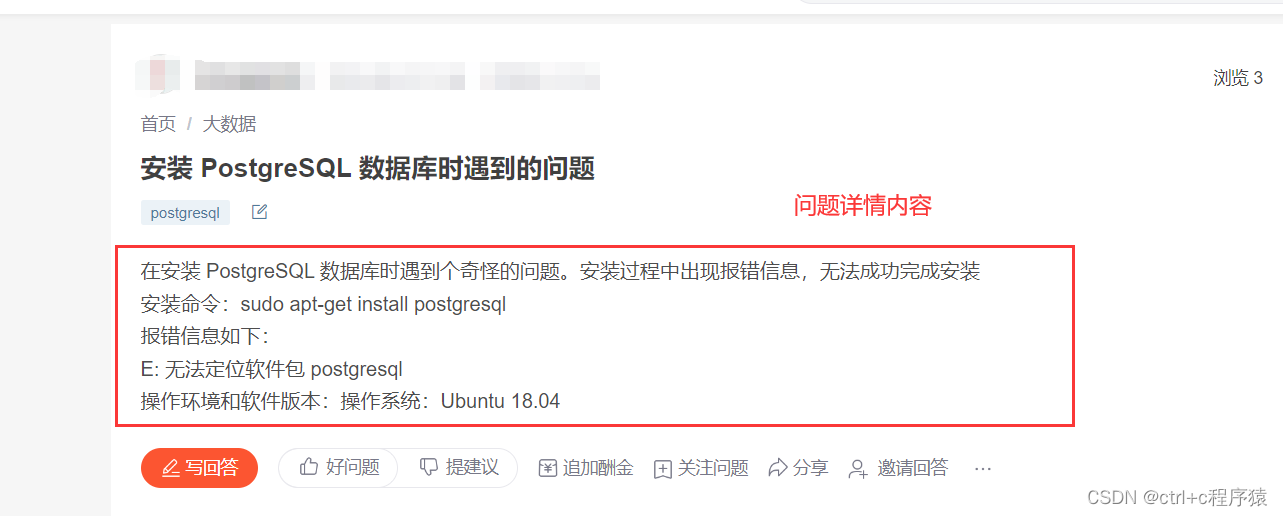
以及详情页页面的具体问题内容
此次项目主要使用到的是Python中的lxml库,使用它可以轻松处理XML和HTML文件,还可以用于web爬取。
项目准备
如果自己电脑环境还没有lxml这个库的同学,可以在终端使用下面的命令进行相应的安装
// 如果要安装其他的库,只需要将下面的lxml替换成相应的库即可
pip install lxml
安装案例截图

本项目还会涉及到requests这个库
如果也没有,请遵循以上方法
项目源代码
from lxml import etree
import requests
#要爬取的链接
url1='https://ask.csdn.net/?utm_source=homepage&spm=1002.2000.3001.9196'
#爬虫头文件,用于伪装
headers = {
'user-agent':
'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.138 Safari/537.36'
}
res=requests.get(url1,headers=headers)
yemadata=res.text
html1=etree.HTML(yemadata)
#定义爬取的问题数量,这里我暂定的十个
page =10
# yema=html1.xpath('//*[@id="__layout"]/main/div/div/div[2]/div[2]/div/div[1]/div/p/text()')
# print(yema)
# tbale=html1.xpath('//*[@id="__layout"]/main/div/div/div[2]/div[2]/div/div[1]/div/div[1]/a/@href')
titleinfo=[]
for number in range(page):
yema =html1.xpath('//*[ @id="__layout"]/main/div/div/div[2]/div[2]/div/div'+ str([number + 1]) +'/div/div[1]/a/h2/text()')
yema =str(yema).replace("'",'')
titleinfo.append(yema)
for yemaint in range (page):
#获取问题详情子页面的链接和问题的标题
urls=html1.xpath('//*[@id="__layout"]/main/div/div/div[2]/div[2]/div/div'+ str([yemaint + 1]) +'/div/div[1]/a/@href')
#url代表每个主页问题的详情页面链接
#这里是通过replace来对获取到的内容,将不重要的内容进行替换
url=str(urls).replace("['",'').replace("']",'')
#打印问题标题和详情页链接
print(titleinfo[yemaint]+'\t'"链接地址:"+url)
#获取问题的ID属性
questionID=url.replace('https://ask.csdn.net/questions/','')
#子页面请求,获取详情问题的内容
request=requests.get(url)
yemadata=request.text
html2=etree.HTML(yemadata)
quest = html2.xpath('//*[@id="content-'+questionID+'"]/div/p/text()')
#问题内容
question =str(quest).replace("'",'').replace(' ','').replace('[','').replace(']','').replace(',','')
if len(question)!=0:
print('代号' + questionID + '问题:'+question+'')
print()
else:
print('代号' + questionID +'涉及图片处理,目前暂不支持')
print()
运行效果展示

通过代码运行,我们想要的结果就呈现到了我们的终端。
项目扩展优化
上面我们通过运行项目,将我们的所爬取的数据在终端进行了展示。这里就有同学表示,这样的展示效果看着不过瘾!
那好,我们通过将爬取的数据进行传递,在我们的HTML前端展示出来。
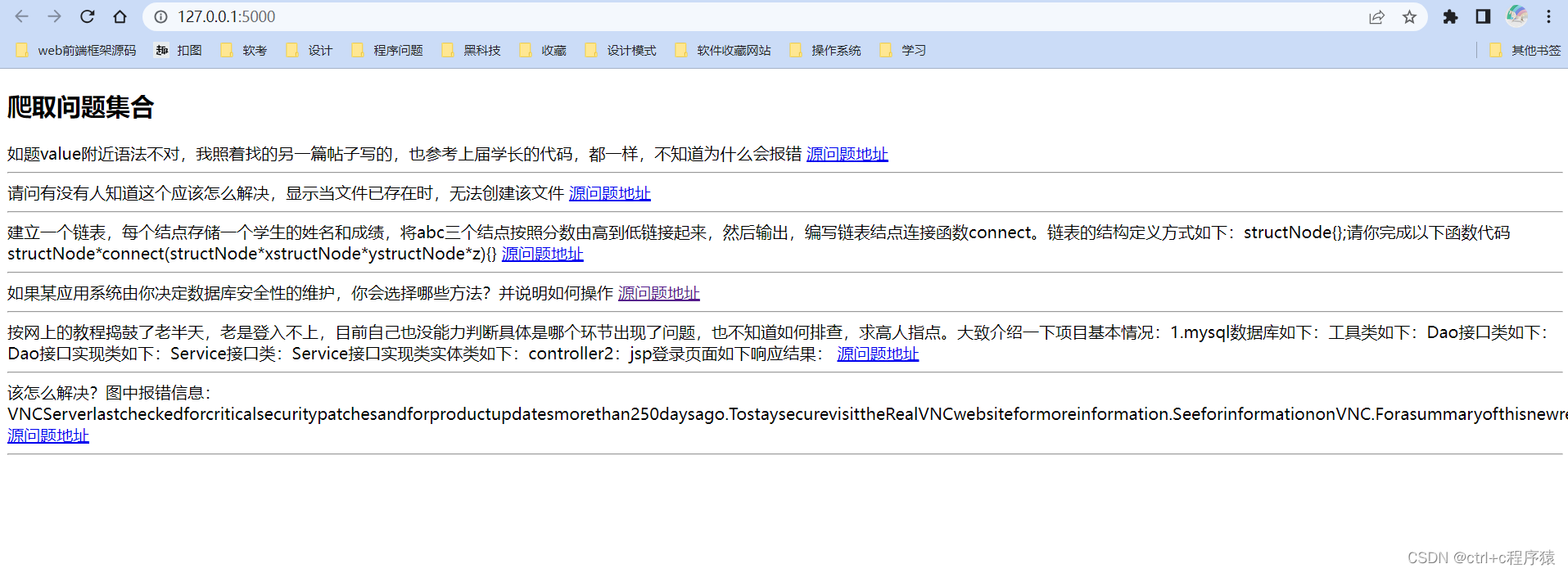
后面运用Flask库实现数据呈现在web网页。虽然没有CSS修饰丑陋了一点,但是要实现的要求还是完成了。
后面还可以直接通过a标签访问到问题的来源。
修改后的代码如下:有需要的朋友可以借鉴
from flask import Flask, render_template
from lxml import etree
from lxml import etree
import requests
import openai
import requests
url1 = 'https://ask.csdn.net/?utm_source=homepage&spm=1002.2000.3001.9196'
headers = {
'user-agent':
'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.138 Safari/537.36'
}
QuestionList = []
StrList = []
anser = []
res = requests.get(url1, headers=headers)
yemadata = res.text
html1 = etree.HTML(yemadata)
page = 10
# yema=html1.xpath('//*[@id="__layout"]/main/div/div/div[2]/div[2]/div/div[1]/div/p/text()')
# print(yema)
# tbale=html1.xpath('//*[@id="__layout"]/main/div/div/div[2]/div[2]/div/div[1]/div/div[1]/a/@href')
titleinfo = []
for number in range(page):
yema = html1.xpath(
'//*[ @id="__layout"]/main/div/div/div[2]/div[2]/div/div' + str([number + 1]) + '/div/div[1]/a/h2/text()')
yema = str(yema).replace("'", '')
titleinfo.append(yema)
for yemaint in range(page):
# 获取问题子页面的域名和问题的标题
urls = html1.xpath(
'//*[@id="__layout"]/main/div/div/div[2]/div[2]/div/div' + str([yemaint + 1]) + '/div/div[1]/a/@href')
url = str(urls).replace("['", '').replace("']", '')
# print(titleinfo[yemaint]+'\t'"链接地址:"+url)
# 获取问题的ID属性
questionID = url.replace('https://ask.csdn.net/questions/', '')
# 子页面请求
request = requests.get(url)
yemadata = request.text
html2 = etree.HTML(yemadata)
yema = html2.xpath('//*[@id="content-' + questionID + '"]/div/p/text()')
# 问题内容
question = str(yema).replace("'", '').replace(' ', '').replace('[', '').replace(']', '').replace(',', '')
if len(question) != 0:
StrList.append(url)
QuestionList.append(question)
# print('代号' + questionID + '问题:'+question+'')
# print()
# else:
# print('代号' + questionID +'涉及图片处理,目前暂不支持')
# print()
app = Flask(__name__)
@app.route('/')
def index():
# render_template方法:渲染模板
# 参数1: 模板名称 参数n: 传到模板里的数据
return render_template('index.html',
my_url=StrList,
my_int=QuestionList,
)
if __name__ == '__main__':
app.run(debug=True)
以上是python的代码
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>CSDN问题内容</title>
</head>
<body>
<h2>爬取问题集合</h2>
{{ my_int[0] }} <a href="{{my_url[0]}}">源问题地址</a>
<br><hr>
{{ my_int[1] }} <a href="{{my_url[1]}}">源问题地址</a>
<br><hr>
{{ my_int[2] }} <a href="{{my_url[2]}}">源问题地址</a>
<br> <hr>
{{ my_int[3] }} <a href="{{my_url[3]}}">源问题地址</a>
<br> <hr>
{{ my_int[4] }} <a href="{{my_url[4]}}">源问题地址</a>
<br> <hr>
{{ my_int[5] }} <a href="{{my_url[5]}}">源问题地址</a>
<hr>
</body>
</html>
HTML代码
因为我使用的是Flask库的模板功能,所以HTML前端的页面一定要像下面这样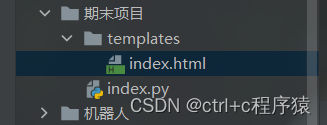
html页面一定要放在templates目录下,这样才可以访问到。
如果有什么问题,可以后台进行私信我!

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











