







爬虫项目
项目介绍
通过Python代码对 中国蔬菜网的蔬菜数据信息进行爬取,将爬取结果在Pycharm终端进行输出以及存储在csv文件中。
项目准备
本项目要使用到分别是csv、requests、lxml这三个第三方库。
如果没有这些库的朋友,可以通过在终端运行
// 如果要安装其他的库,只需要将下面的lxml替换成相应的库即可
pip install lxml
当这些所有依赖包都准备好之后,就可以开始写代码了。
项目代码
爬虫代码
url1='http://www.vegnet.com.cn/Price/List_ar500000_p2.html?marketID=361'
title='重庆观音桥市场有限公司'
chazhao='查找'
list=[title,chazhao]
res=requests.get(url1)
yemadata=res.text
html1=etree.HTML(yemadata)
yema=html1.xpath('//div[3]/div[2]/div[2]/div[2]/a/@href')
print(title)
tbale=html1.xpath('//div[3]/div[2]/div[2]/p/b/text()')
print(tbale)
for yemaint in range(10):
url="http://www.vegnet.com.cn/"+yema[yemaint]
response=requests.get(url=url)
# #2.获取数据<>
data=response.text
html=etree.HTML(data)
# print("蔬菜网"+str(yemaint+1)+"页数据:")
for i in range(25):
text=html.xpath('//div[3]/div[2]/div[2]/div[1]/p' + str([i + 1]) + '/span/text()')
text.insert(2,list[0])
text.insert(7,list[1])
存储代码
// 存储代码(将数据存储到csv文件)
dit={
'日期':text[0],
'品种':text[1],
'批发市场':text[2],
'最低价格':text[3],
'最高价格':text[4],
'平均价格':text[5],
'计量单位':text[6],
'找产品':text[7],
}
print(dit)
##将爬取的数据存放到shuju.csv文件之中
f = open('shuju.csv', mode='a', encoding='utf-8', newline='')
csvmon = csv.DictWriter(f, fieldnames=[
'日期',
'品种',
'批发市场',
'最低价格',
'最高价格',
'平均价格',
'计量单位',
'找产品',
])
csvmon.writerow(dit)
完整代码
import csv
from lxml import etree
import requests
url1='http://www.vegnet.com.cn/Price/List_ar500000_p2.html?marketID=361'
title='重庆观音桥市场有限公司'
chazhao='查找'
list=[title,chazhao]
res=requests.get(url1)
yemadata=res.text
html1=etree.HTML(yemadata)
yema=html1.xpath('//div[3]/div[2]/div[2]/div[2]/a/@href')
print(title)
tbale=html1.xpath('//div[3]/div[2]/div[2]/p/b/text()')
print(tbale)
for yemaint in range(10):
url="http://www.vegnet.com.cn/"+yema[yemaint]
response=requests.get(url=url)
# #2.获取数据<>
data=response.text
html=etree.HTML(data)
# print("蔬菜网"+str(yemaint+1)+"页数据:")
for i in range(25):
text=html.xpath('//div[3]/div[2]/div[2]/div[1]/p' + str([i + 1]) + '/span/text()')
text.insert(2,list[0])
text.insert(7,list[1])
# text=str(text).replace(',','').replace('\'','')
# 字典将获取到的数据进行存储
dit={
'日期':text[0],
'品种':text[1],
'批发市场':text[2],
'最低价格':text[3],
'最高价格':text[4],
'平均价格':text[5],
'计量单位':text[6],
'找产品':text[7],
}
print(dit)
##将爬取的数据存放到shuju.csv文件之中
f = open('shuju.csv', mode='a', encoding='utf-8', newline='')
csvmon = csv.DictWriter(f, fieldnames=[
'日期',
'品种',
'批发市场',
'最低价格',
'最高价格',
'平均价格',
'计量单位',
'找产品',
])
csvmon.writerow(dit)
# with open('me1.csv', mode='w', encoding='utf-8', newline='') as f:
# csvmon = csv.DictWriter(f, fieldnames=[
# '日期','品种' ,'批发市场' , '最低价格', '最高价格', '平均价格', '计量单位', '找产品' ])
# csvmon.writerow(dit)
运行结果
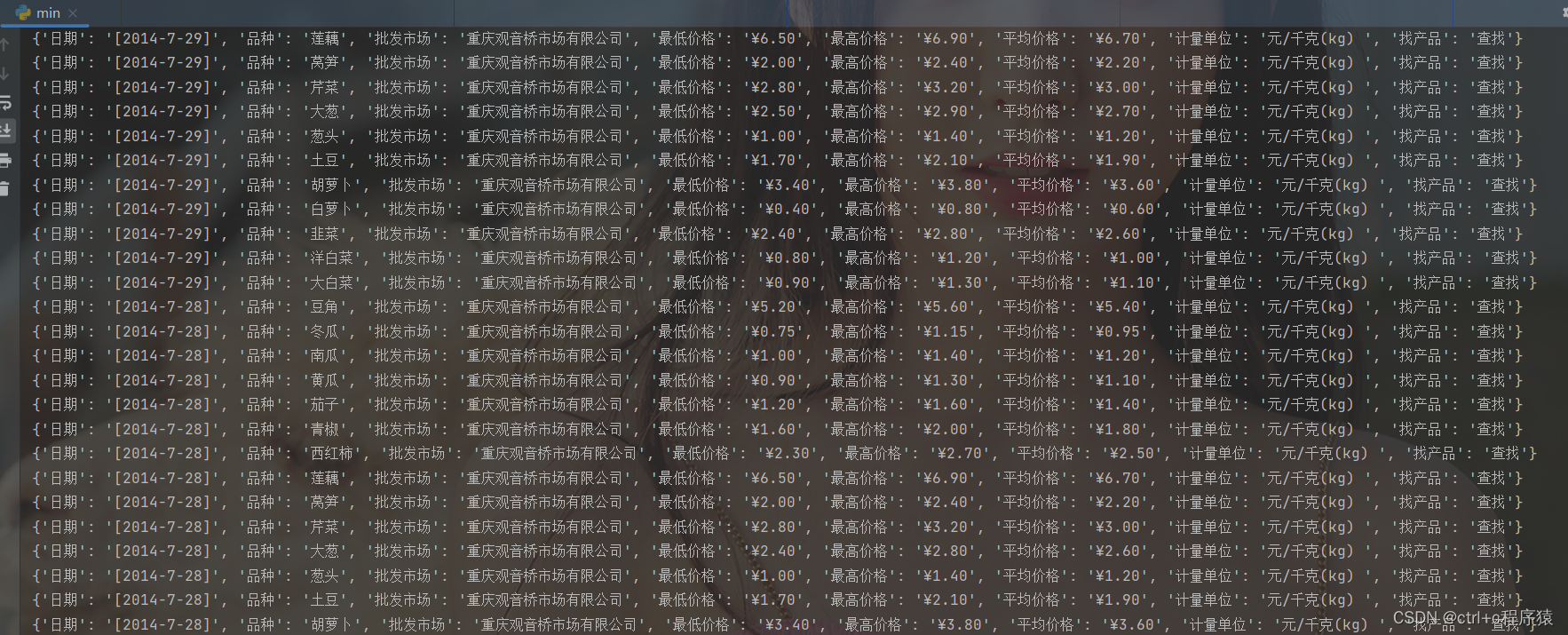
终端结果
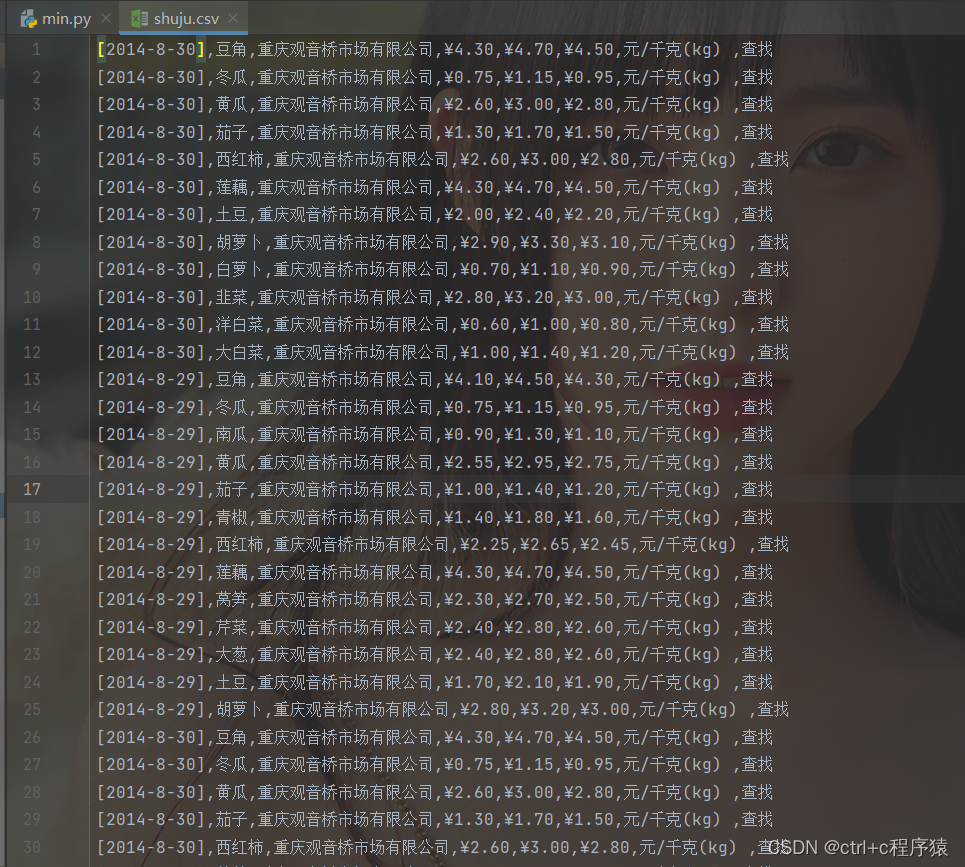
文件结果
整个项目就到此结束了,有问题的小伙伴欢迎留言!!!


















 313
313

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











