









记录涉及使用pandas处理数据的一些方法和错误
Pandas读取数据相关
1.读取csv文件
df_source = pd.read_csv('[file_path].csv', encoding='UTF-8')
2.读取.xlsx文件
df_source = pd.read_excel('[file_path].xlsx', encoding='utf-8') # 原始dataframe
Pandas DataFrame操作
1.获取dataframe某一列的数据
df_source = pd.read_excel('[file_path].xlsx', encoding='utf-8') # 原始dataframe
df_extract_left = df_source['[col_name]']
2.获取某几列的数据
df_source = pd.read_excel('[file_path].xlsx', encoding='utf-8')
col_n = ['col_name1', 'col_name2', 'col_name3', 'col_name4']
df_extract_right = pd.DataFrame(df_source ,columns=col_n)
3.Data Frame左连接操作
针对连个不同dataframe列名做左连接
df_merge = pd.merge(df_left, df_right, how='left', left_on='[左表的列名]', right_on='【右表的列名】')
左连接N->N的连接测试
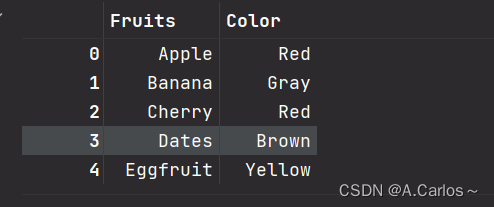
左表
left_dict = {
'Fruits':['Apple','Banana','Cherry','Dates','Eggfruit'],
'Color': ['Red', 'Gray', 'Red', 'Brown', 'Yellow']
}
df_left = pd.DataFrame(left_dict)
df_left
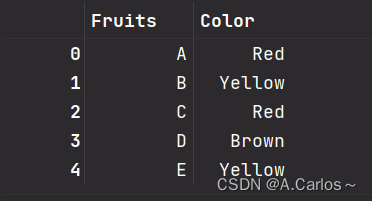
右表
right_dict = {
'Fruits':['A','B','C','D','E'],
'Color': ['Red', 'Yellow', 'Red', 'Brown', 'Yellow']
}
df_right = pd.DataFrame(right_dict)
df_right
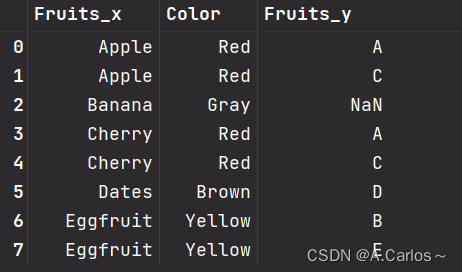
连接处理
df = pd.merge(df_left, df_right, how='left', left_on='Color', right_on='Color')
df
4.处理 dataframe 某一列的值
具体要求: 删除dataframe某一列中的换行符 \r\n
注意!!!!!!!!
replace(‘\\n’,‘’) 无法得到正确的结果的
# 去除列多余的字符 \r\n
df['要处理列的列名'] = df.apply(lambda x:str(x['要处理列的列名']).replace('\r','').replace('\n','') ,axis=1)
df
5.根据dataframe某一列的值对其他列做聚合
要求 : 根据某一列的值 做group by后 ,属于同一group的其他列的字符串做一个拼接
例如
- a “111”
- a “222”
- b “333”
- 结果
- a ”111,222“
- b “333”
df2 = df.groupby('group by的列')['做字符串拼接的列'].apply(lambda x:x.str.cat(sep=","))
df2
要求 : 对dataframe的两列进行聚合,并对第三列进行求和
例如:
- a “111” 3
- a “222” 5
- a “111” 6
- b “112” 4
- b “222” 4
- b “222” 2
结果
- a “111” 9
- a “222” 5
- b “112” 4
- b “222” 6
df.groupby(by=['聚合列1','聚合列2'])['第三列'].sum().reset_index(drop=False)
6. 删除某几列的数据
利用索引删除多行,不能写0:2
df.drop([0, 1])
利用列名删除多列
df.drop(labels=[‘id’,‘class’], axis=1)
7. 筛选出某列中符合条件的行
df[df['列名'] == '待筛选的值']
8. groupby后多行合并为一行
例如 group 1:
| col_a | col_b | col_c
| aaa | type1 | 1000
| aaa | type2 | 2000
结果:
| col_a | type1 | type2
| aaa | 1000 | 2000
def concat_df(x):
df_res = pd.pivot(x, index='col_a', columns='col_b', values="col_c")
df_res.insert(0,'col_a',x.iloc[0,0]) #调试时发现结果缺失col_a列,故添加该列值
return df_res
df_res = df.groupby('col_a').apply(lambda x : concat_df(x))
9. 删除dataframe中某一列的符合条件的行
df_res=df.drop(df[df['列名']=='条件'].index)
10. groupby后遍历
(1) for循环遍历(推荐)
for name,df_group in df.groupby(by=['key']):
# name为当前group的key值 str类型
# df_group为当前的子group dataframe类型
(2) apply 匿名函数遍历 此方法在涉及到全局变量的赋值使用时不太方便
# x为每个group的dataframe
name,df_group in df.groupby(by=['key']).apply(lamdba x : print(x))
举例:
df2 = pd.DataFrame([['Tom', 16], ['Nancy', 18], ['Jack', 15],['Tom', 18],['Jack', 13],['Jack', 115]],columns=['cola','colb'])
cola colb
Tom 16
Nancy 18
Jack 15
Tom 18
Jack 13
Jack 115
# 方法一:
for name,df_group in df2.groupby(by=['cola']):
# 只演示第一个group的值
print(name) # Jack
print(df_group)
cola colb
Jack 15
Jack 13
Jack 115
# 方法二
df2.groupby(by=['cola']).apply(lambda x: print(x))
cola colb
2 Jack 15
4 Jack 13
5 Jack 115
cola colb
1 Nancy 18
cola colb
0 Tom 16
3 Tom 18
11. dataframe更改列名
df.rename(columns={'two':'twotwo'},inplace=True)
12. dataframe隔行相减
需求:假设有以下dataframe,要计算每两行之间的时间差
date
2019-08-29 09:20:37
2019-08-29 09:21:23
2019-08-29 09:22:09
…
df_res = pd.DataFrame()
df['DATE1'] = df['DATE'].shift(1)
df_time = (df['DATE'] - df['DATE1']).dt.total_seconds()
df_time.dropna(axis=0,inplace=True)
df_res = pd.concat([df_res,df_time])
12. dataframe删除值为空的列或者行
df.dropna(axis=0,inplace=True) # axis = 0 为行 axis = 1为列 ,inplace = True表示替换原df
13. dataframe删某列值中符合条件的行
需求 :现在有2个dataframe,要求删除在df2中某列包含该值的行,该值为df1中的某列所出现的值
df1
a b c d
1 2 3 3
2 …
3 …
df2
a b c d
1 2 3 3
2 …
3 …
4…
5…
6…
结果
a b c d
4…
5…
6…
df2=df2[~df2['a'].isin(df1['a'].unique())]
14.统计dataframe每一列出现的不同值的最小值
count_min = min(df['列名'].value_counts())
# 返回一个series
15.统计两列中数值相同的行数
df1
a b c d
1 2 3 3
2 2 3 4
3 3 4 5
统计a,b两列值相同的行的个数
结果 2
len(set(df1['a']) & set(df1['b']))
16.删除DataFrame两列中值相同的行
df1
a b c d
1 2 3 3
2 2 3 4
3 3 4 5
删除a,b列值相同的行 结果
a b c d
1 2 3 3
df1.loc[~(df1['a']==df1['b'])]
16.df判断某列值为True,将另外一列对应的值相加
df1
a b
T 2
F 2
T 3
b列中的某几个值相加,这些值为a列中对应值为T的
结果 5
df.loc[df['a']==True,'b'].sum()















 916
916











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









